【一文看懂IP地址:含义、分类、子网划分、查与改、路由器与IP地址 - 今日头条】https://m.toutiao.com/is/eR5AHfq/
首先 UDP 是不需要和 TCP一样在发送数据前进行三次握手建立连接的,想发数据就可以开始发送了。并且也只是数据报文的搬运工,不会对数据报文进行任何拆分和拼接操作。
具体来说就是:
- 在发送端,应用层将数据传递给传输层的 UDP 协议,UDP 只会给数据增加一个 UDP 头标识下是 UDP 协议,然后就传递给网络层了
- 在接收端,网络层将数据传递给传输层,UDP 只去除 IP 报文头就传递给应用层,不会任何拼接操作
UDP 不止支持一对一的传输方式,同样支持一对多,多对多,多对一的方式,也就是说 UDP 提供了单播,多播,广播的功能。
发送方的UDP对应用程序交下来的报文,在添加首部后就向下交付IP层。UDP对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界。因此,应用程序必须选择合适大小的报文
首先不可靠性体现在无连接上,通信都不需要建立连接,想发就发,这样的情况肯定不可靠。
并且收到什么数据就传递什么数据,并且也不会备份数据,发送数据也不会关心对方是否已经正确接收到数据了。
再者网络环境时好时坏,但是 UDP 因为没有拥塞控制,一直会以恒定的速度发送数据。即使网络条件不好,也不会对发送速率进行调整。这样实现的弊端就是在网络条件不好的情况下可能会导致丢包,但是优点也很明显,在某些实时性要求高的场景(比如电话会议)就需要使用 UDP 而不是 TCP。
UDP只会把想发的数据报文一股脑的丢给对方,并不在意数据有无安全完整到达。
UDP 头部包含了以下几个数据:
- 两个十六位的端口号,分别为源端口(可选字段)和目标端口
- 整个数据报文的长度
- 整个数据报文的检验和(IPv4 可选 字段),该字段用于发现头部信息和数据中的错误
因此 UDP 的头部开销小,只有八字节,相比 TCP 的至少二十字节要少得多,在传输数据报文时是很高效的
-
为什么要长连接?
===> 网页里肯定还包含了CSS、JS等等一系列资源,如果你是短连接(也就是每次都要重新建立TCP连接)的话,那你每打开一个网页,基本要建立几个甚至几十个TCP连接。
-
HTTP1.1 默认是 tcp长连接。 “Connection :keep-alive”
在HTTP 1.0中,客户端每发起一个http 请求,等收到接收方的应答之后就断开TCP。下一个请求再需要发送时,要重新建立TCP连接。
在HTTP 1.1中,客户端每发起一个http请求之后,服务器可以通过keep alive的方式告知客户端,同时保持之前建立的TCP连接。下一个http请求和应答从而能够避免再次建连,通过已有连接继续发送。
-
长连接并不是永久连接的。如果一段时间内(具体的时间长短,是可以在header当中进行设置的,也就是所谓的超时时间),这个连接没有HTTP请求发出的话,那么这个长连接就会被断掉。(否则的话,TCP连接将会越来越多,直到把服务器的TCP连接数量撑爆到上限为止)
-
**长轮询:**服务器如果检测到库存量没有变化的话,将会把当前请求挂起一段时间(这个时间也叫作超时时间,一般是几十秒)。在这个时间里,服务器会去检测库存量有没有变化,检测到变化就立即返回,否则就一直等到超时为止。(长轮询还是短轮询,都不太适用于客户端数量太多的情况)
-
建议服务器对于每个长连接每隔一段时间自动断开,对应nginx服务器的参数配置如下,值得注意的是现在市面上很多浏览器都内置了这个功能。
keepalive_timeout 120 (应该是秒为单位)
-
Http长连接和Keep-Alive以及Tcp的Keepalive https://blog.csdn.net/weixin_37672169/article/details/80283935
开启Keep-Alive的优缺点: 优点:Keep-Alive模式更加高效,因为避免了连接建立和释放的开销。 缺点:长时间的Tcp连接容易导致系统资源无效占用,浪费系统资源。
当保持长连接时,如何判断一次请求已经完成? Content-Length Content-Length表示实体内容的长度。浏览器通过这个字段来判断当前请求的数据是否已经全部接收。 所以,当浏览器请求的是一个静态资源时,即服务器能明确知道返回内容的长度时,可以设置Content-Length来控制请求的结束。但当服务器并不知道请求结果的长度时,如一个动态的页面或者数据,Content-Length就无法解决上面的问题,这个时候就需要用到Transfer-Encoding字段。
Transfer-Encoding Transfer-Encoding是指传输编码,在上面的问题中,当服务端无法知道实体内容的长度时,就可以通过指定Transfer-Encoding: chunked来告知浏览器当前的编码是将数据分成一块一块传递的。当然, 还可以指定Transfer-Encoding: gzip, chunked表明实体内容不仅是gzip压缩的,还是分块传递的。最后,当浏览器接收到一个长度为0的chunked时, 知道当前请求内容已全部接收。
Keep-Alive timeout: Httpd守护进程,一般都提供了keep-alive timeout时间设置参数。比如nginx的keepalive_timeout,和Apache的KeepAliveTimeout。这个keepalive_timout时间值意味着:一个http产生的tcp连接在传送完最后一个响应后,还需要hold住keepalive_timeout秒后,才开始关闭这个连接。 当httpd守护进程发送完一个响应后,理应马上主动关闭相应的tcp连接,设置 keepalive_timeout后,httpd守护进程会想说:”再等等吧,看看浏览器还有没有请求过来”,这一等,便是keepalive_timeout时间。如果守护进程在这个等待的时间里,一直没有收到浏览器发过来http请求,则关闭这个http连接。
Tcp的Keepalive: 连接建立之后,如果客户端一直不发送数据,或者隔很长时间才发送一次数据,当连接很久没有数据报文传输时如何去确定对方还在线,到底是掉线了还是确实没有数据传输,连接还需不需要保持,这种情况在TCP协议设计中是需要考虑到的。 TCP协议通过一种巧妙的方式去解决这个问题,当超过一段时间之后,TCP自动发送一个数据为空的报文(侦测包)给对方,如果对方回应了这个报文,说明对方还在线,连接可以继续保持,如果对方没有报文返回,并且重试了多次之后则认为链接丢失,没有必要保持连接。
tcp keep-alive是TCP的一种检测TCP连接状况的保鲜机制。tcp keep-alive保鲜定时器,支持三个系统内核配置参数: net.ipv4.tcp_keepalive_intvl = 15 net.ipv4.tcp_keepalive_probes = 5 net.ipv4.tcp_keepalive_time = 1800 keepalive是TCP保鲜定时器,当网络两端建立了TCP连接之后,闲置(双方没有任何数据流发送往来)了tcp_keepalive_time后,服务器就会尝试向客户端发送侦测包,来判断TCP连接状况(有可能客户端崩溃、强制关闭了应用、主机不可达等等)。如果没有收到对方的回答(ack包),则会在 tcp_keepalive_intvl后再次尝试发送侦测包,直到收到对方的ack,如果一直没有收到对方的ack,一共会尝试 tcp_keepalive_probes次,每次的间隔时间在这里分别是15s, 30s, 45s, 60s, 75s。如果尝试tcp_keepalive_probes,依然没有收到对方的ack包,则会丢弃该TCP连接。TCP连接默认闲置时间是2小时,一般设置为30分钟足够了。
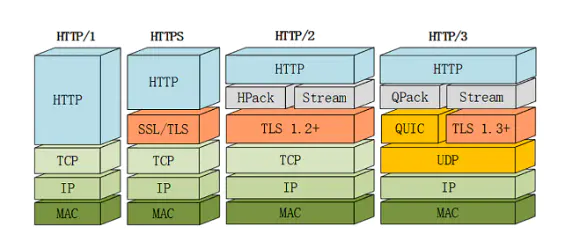
Http1.0与Http1.1,Http2.0的区别
http 2.0采用二进制的格式传送数据,不再使用文本格式传送数据 http2.0对消息头采用hpack压缩算法,http1.x的版本消息头带有大量的冗余消息 http2.0 采用多路复用,即用一个tcp连接处理所有的请求,真正意义上做到了并发请求,流还支持优先级和流量控制 http2.0支持server push,服务端可以主动把css,jsp文件主动推送到客户端,不需要客户端解析HTML,再发送请求,当客户端需要的时候,它已经在客户端了。
-
Http1.0一次只能处理一个请求和响应,Http1.1一次能处理多个请求和响应
-
多个请求和响应过程可以重叠
-
增加了更多的请求头和响应头,比如Host、If-Unmodified-Since请求头等
http请求头: accept:浏览器通过这个头告诉服务器,它所支持的数据类型。如:text/html, image/jpeg accept-Charset:浏览器通过这个头告诉服务器,它支持哪种字符集。 accept-encoding:浏览器通过这个头告诉服务器,它支持哪种压缩格式。 accept-language:浏览器通过这个头告诉服务器,它的语言环境。 host:浏览器通过这个头告诉服务器,它想访问哪台主机。 if-modified-since:告诉服务器我这缓存中有这个文件,该文件的时间是… referer:浏览器通过这个头告诉服务器,客户机是哪个页面来的(防盗链)。 User-Agent:告诉服务器我的浏览器内核 Connection:浏览器通过这个头告诉服务器,请求完后是断开链接还是维持链接。 Date:浏览器发送数据的请求时间
请求方式:POST,GET,HEAD,DELETE,PUT
http响应头: location:服务器通过这个头告诉浏览器跳到哪里。 server:服务器通过这个头告诉浏览器服务器的型号。 content-encoding:服务器通过这个头告诉浏览器数据的压缩格式。 content-length:服务器通过这个头告诉浏览器回送数据的长度。 content-language:服务器通过这个头告诉浏览器语言环境。 content-type:服务器通过这个头告诉浏览器回送数据的类型。 Last-Modified:告诉浏览器该资源上次更新时间是什么 refresh:服务器通过这个头告诉浏览器定时刷新。 content-disposition:服务器通过这个头告诉浏览器以下载方式打开数据。 transfer-encoding:服务器通过这个头告诉浏览器数据是以分块方式回送的 Set-Cookie: 以下三个表示服务器通过这个头告诉浏览器不要缓存 expires:-1 cache-control:no-cache pragma:no-cache
Connection:close/Keep-Alive Date:Tue,11 Jul 2000 18:23:51
(1)有些网站对及时性比较高,我们不缓存页面
response.setDateHeader("Expires",-1);
//为了保证兼容性
response.setHeader("Cache-Control","no-cache")
response.setHeader("Pragma","no-cache")
(2)有些网站要求网页缓存一定时间,比如缓存一个小时
response.setDateHeader("Expires",System.currentimeMillis()*3600*1000*24); Http协议的主要特点
- 支持客户/服务器模式
- 简单快速:客户向服务端请求服务时,只需传送请求方式和路径。
- 灵活:允许传输任意类型的数据对象。由Content-Type加以标记。
- 无连接:每次响应一个请求,响应完成以后就断开连接。
- 无状态:服务器不保存浏览器的任何信息。每次提交的请求之间没有关联。
非持续性和持续性
HTTP1.0默认非持续性;HTTP1.1默认持续性
持续性:浏览器和服务器建立TCP连接后,可以请求多个对象
非持续性:浏览器和服务器建立TCP连接后,只能请求一个对象
非流水线和流水线
类似于组成里面的流水操作
- 流水线:不必等到收到服务器的回应就发送下一个报文。
- 非流水线:发出一个报文,等到响应,再发下一个报文。类似TCP。
http 各个版本之间的区别
1.0 与 1.1
- http1.0一次只能处理一个请求,不能同时收发数据
- http1.1可以处理多个请求,能同时收发数据
- http1.1增加可更多字段,如cache-control,keep-alive.
2.0
-
http 2.0采用二进制的格式传送数据,不再使用文本格式传送数据
-
http2.0对消息头采用hpack压缩算法,http1.x的版本消息头带有大量的冗余消息
-
http2.0 采用多路复用,即用一个tcp连接处理所有的请求,真正意义上做到了并发请求,流还支持优先级和流量控制(HTTP/1.x 虽然通过 pipeline也能并发请求,但是多个请求之间的响应会被阻塞的,所以 pipeline 至今也没有被普及应用,而 HTTP/2 做到了真正的并发请求。同时,流还支持优先级和流量控制。)
-
http2.0支持server push,服务端可以主动把css,jsp文件主动推送到客户端,不需要客户端解析HTML,再发送请求,当客户端需要的时候,它已经在客户端了。
Http 3.0
Google 在推SPDY的时候就已经意识到了这些问题,于是就另起炉灶搞了一个基于 UDP 协议的“QUIC”协议,让HTTP跑在QUIC上而不是TCP上。 而这个“HTTP over QUIC”就是HTTP协议的下一个大版本,HTTP/3。它在HTTP/2的基础上又实现了质的飞跃,真正“完美”地解决了“队头阻塞”问题。
HTTP1.1新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT
- GET: 通常用于请求服务器发送某些资源。
- HEAD: 请求资源的头部信息, 并且这些头部与 HTTP GET 方法请求时返回的一致。使用场景:下载一个大文件前先获取其大小再决定是否要下载, 以此可以节约带宽资源。
- OPTIONS: 用于获取目的资源所支持的通信选项。
- POST: 发送数据给服务器,是非幂等的
- PUT: 跟POST方法很像,也是想服务器提交数据。但是,它们之间有不同。PUT指定了资源在服务器上的位置,而POST不需要指定资源在服务器的位置,是幂等的
- DELETE: 用于删除指定的资源
- PATCH: 用于对资源进行部分修改
- CONNECT: HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器
- TRACE: 回显服务器收到的请求,主要用于测试或诊断
put 和 post 区别
POST:用于提交请求,可以更新或者创建资源,是非幂等的(创建新的)
e g:在我们的支付系统中,一个api的功能是创建收款金额二维码,它和金额相关,每个用户可以有多个二维码,如果连续调用则会创建新的二维码,这个时候就用POST。
PUT: 用于向指定的URI传送更新资源,是幂等的(同一个)
e g:用户的账户二维码只和用户关联,而且是一一对应的关系,此时这个api就可以用PUT,因为每次调用它,都将刷新用户账户二维码。
如果从 RESTful API 的角度来理解,PUT 方法是这么工作的:
假设后台支持 RESTful API,我可以通过下面的请求发布这篇文章:
PUT https://gdutxiao.github.io/2018/04/16/http-put-vs-post HTTP/1.1
{
/* 文章内容正文 */
}
使用 PUT 方法时,客户端需要在 HTTP 请求中明确指定地址 K。
正如 Java 的例子一样,PUT 方法应当支持幂等性。如果是同一个对象 V,PUT 多次与 PUT 一次返回的结果应该是相同的。客户端可以利用 PUT 的幂等性安全地重试请求,保证客户端的请求至少被服务端处理一次。
如果把上面发布文章的例子用 HTTP POST 方法重写,它可能会是下面这样:
POST https://gdutxiao.github.io/post-article HTTP/1.1
{
/* 文章内容正文 */
}
地址 K 不是由客户端指定的,而是由服务端生成的。比如,服务端可能会根据日期和文章标题,为本文分配一个地址。
POST 方法是不支持幂等性的。同一个请求被处理两次,应当生成两份对象。换句话说,客户端应该只发送一次 POST 请求,而客户端的请求至多会被服务端处理一次。
现在问题来了,如果真的遇到了网络故障,客户端应该如何重试 POST 请求呢?解决方法其实很简单,我们可以在 POST 请求中隐藏一个唯一的 token,服务端在处理请求后把 token 存入数据库,如果这个 token 之前遇到过,服务端就知道这是重复的 POST 请求,可以不再处理了。
HTTP协议(超文本传输协议)和 UDP(用户数据包协议),TCP 协议(传输控制协议)
TCP/IP是个协议组,可分为四个层次:网络接口层、网络层、传输层和应用层。
- 网络层:有IP协议、ICMP协议、ARP协议、RARP协议和BOOTP协议。
- 传输层:有TCP协议(准确性)与UDP协议(速度效率性),arq协议。
- 应用层:FTP、HTTP、TELNET、SMTP、DNS等协议。
TCP: 可靠/ 面向连接/ 面向字节流/ 传输慢/ 应用:FTP文件-pop邮件-telnet ssh远程登录(流量控制-差错控制-超时重发-停止等待机制-拥塞控制)
- 要先建连接,这会消耗时间,而且在数据传递时,确认机制、重传机制、拥塞控制机制等都会消耗大量的时间,而且要在每台设备上维护所有的传输连接,事实上,每个连接都会占用系统的CPU、内存等硬件资源。
- TCP有确认机制、三次握手机制,这些也导致TCP容易被人利用,实现DOS、DDOS、CC等攻击。
UDP:不可靠/无连接/面向报文/传输快/ 应用:QQ聊天-在线视频-网络语音电话(偶尔卡顿,传输快)
两种协议都是传输层协议--->为应用层提供 信息载体
- UDP是一个无状态的传输协议,所以它在传递数据时非常快。没有TCP的这些机制,UDP较TCP被攻击者利用的漏洞就要少一些。但UDP也是无法避免攻击的,比如:UDP Flood攻击
- 不可靠,不稳定 。因为UDP没有TCP那些可靠的机制,在数据传递时,如果网络质量不好,就会很容易丢包。
三次握手(检查双方具有 成功发消息的能力)
第一次握手:第一次连接时,客户端向服务器端发送SYN(syn=j),等待服务器端的确认,此时客户端进入SYN_SEND状态,SYN:同步序列号 (客户端发送给服务端-------->客户端发的能力)
第二次握手:服务器端收到客户端发来的SYN,必须向客户端发送ACK包(ack=j+1=k),同时自己必须发送一个SYN包,即syn+ack,此时进入SYN_REC状态 (服务端收到,再发送给客户端------->服务端发的能力)
第三次握手:客户端收到服务器端发来的syn+ack包,向服务器发送ack包(ack=k+1),发送完毕,此时进入ESTABLISH状态,连接成功,完成第三次连接。(客户端收到,再发给服务端-------客户端收到代表成功发送了,服务端收到了代表服务端成功发送了)
4次挥手
TCP建立连接要进行3次握手,而断开连接要进行4次,这是由于TCP的半关闭造成的,因为TCP连接是全双工的( 即数据可在两个方向上同时传递)所以进行关闭时每个方向上都要单独进行关闭,这个单方向的关闭就叫半关闭.
关闭的方法是一方完成它的数据传输后,就发送一个FIN来向另一方通告将要终止这个方向的连接.当一端收到一个FIN,它必须 通知应用层TCP连接已终止了这个方向的数据传送,发送FIN通常是应用层进行关闭的结果.
- 停止等待机制:是指每发送完一个分组,就会停止发送,必须等待收到对这个分组的确认才会继续发送下一个分组。
- 超时重传:是指每发送一个分组,就会为这个分组启动一个超时计数器,在规定的时间内没有受到确认,就会再次发送这个分组。
- 连续ARQ协议中,为提高信道利用率,通常采取的做法是发送方维持一个发送窗口,凡是位于该窗口内的分组都可以发送出去,无需等待确认,在接收方是采用累积确认,即对按需到达的分组后一个分组发送确认,表明在这个分组以前的所有分组都已正确接收到。
- 流量控制:是一个端到端的过程,是指接收方限制发送方的速率不要太快,使接收方来得及接收。
- 拥塞控制:是一个全局的过程,是只不要向网络注入太多的数据,导致链路或者路由器损坏。
洪水攻击:向服务器端发送大量的伪TCP连接请求,这时候服务器端会进入syn_receive半连接状态,服务器端会尝试发送多次包来确认,因为这些连接时假冒的,所以并不会完成第三次握手,导致服务器端保持大量的半连接状态,耗费资源,是TCP连接队列被塞满。
解决方法:
- 做一些应急处理,对这些IP地址的特征来禁止响应的IP地址字段的访问。
- 应急处理毕竟太被动,因为本机房的F5比较空闲,运维利用F5来挡攻击,采用方式:让客户端先和F5三次握手,连接建立之后F5才转发到后端业务服务器。
http和https的区别
https相当于http加上安全套接字,采用ssl加密技术
主要的区别
- 在osi模型中,http工作于应用层,https工作与传输层
- http传输的时候采用明文传输,https采用加密传输
- http不需要证书,https需要响应额证书
- http以http开头,默认端口是80,https 以https开头,默认的端口是243
上传视频的时候为什么不用 Http 协议?
因为上传视频的时候文件一般比较长,如果我们采用 post 请求的话,写到输出流中,它并不会直接写到服务器中,而是会缓存在内存中,会影响我们的执行效率。
https在客户端(浏览器)与服务端(网站)传输加密的数据大概经历一下流程
(总结:客户端 用证书公钥(让对称密钥进行安全传输) 对 客户端生成的密钥(对称加密,就一个)进行加密,传给服务器,服务器收到解密,拿到客户端公共的对称密钥。 最后进行数据传输(对称密钥对数据加密))
目的:两端安全拿到 对称密钥, 使用其进行数据传递
- 客户端将自己的has算法和加密算法发给服务器
- 服务器接收到客户端发来的加密算法和has算法,取出自己的加密算法与has算法,并将自己的身份信息以证书的形式发送给客户端,该证书信息包括公钥,网站地址,预计颁发机构等
- 客户端收到服务器发来的证书(即公钥),开始验证证书的合法性,如果证书信任,则生成一串随机的字符串数字作为私钥,并将私钥(密文)用证书(服务器的公钥)进行加密,发送给服务器
- 服务器收到客户端发来的数据之后,通过服务器自己的私钥进行解密客户端发来的数据(客户端的私钥),(这样双方都拥有私钥)再进行hash检验,如果结果一致,则将客户端发来的字符串(第3个步骤发送过来的字符串)通过加密发送给客户端
- 客户端解密,如果一致的话,就使用之前客户端随机生成的字符串进行对称加密算法进行加密
什么是SSL
SSL 由 Netscape 公司于1994年创建,它旨在通过Web创建安全的Internet通信。它是一种标准协议,用于加密浏览器和服务器之间的通信。它允许通过Internet安全轻松地传输账号密码、银行卡、手机号等私密信息。
SSL证书就是遵守SSL协议,由受信任的CA机构颁发的数字证书。
对称加密:通信双方使用相同的密钥进行加密。特点是加密速度快,但是缺点是需要保护好密钥,如果密钥泄露的话,那么加密就会被别人破解。常见的对称加密有AES,DES算法。
非对称加密:它需要生成两个密钥:公钥(Public Key)和私钥(Private Key)。
公钥顾名思义是公开的,任何人都可以获得,而私钥是私人保管的。相信大多程序员已经对这种算法很熟悉了:我们提交代码到github的时候,就可以使用SSH key:在本地生成私钥和公钥,私钥放在本地.ssh目录中,公钥放在github网站上,这样每次提交代码,不用麻烦的输入用户名和密码了,github会根据网站上存储的公钥来识别我们的身份。
公钥负责加密,私钥负责解密;或者,私钥负责加密,公钥负责解密。这种加密算法安全性更高,但是计算量相比对称加密大很多,加密和解密都很慢。常见的非对称算法有RSA。
1、加密和解密过程不同
对称加密:加解密使用同一个密钥。(常见的对称加密算法有DES、3DES、Blowfish、IDEA、RC4、RC5、RC6和AES)
非对称加密:采用了两个密钥,一般使用公钥进行加密,使用私钥进行解密。
2、加密解密速度不同
对称加密:解密的速度比较快,适合数据比较长时的使用。
非对称加密:和解密花费的时间长、速度相对较慢,只适合对少量数据的使用。
3、传输的安全性不同
对称加密:过程中无法确保密钥被安全传递,密文在传输过程中是可能被第三方截获的,如果密码本也被第三方截获,则传输的密码信息将被第三方破获,安全性相对较低。
非对称加密:私钥是基于不同的算法生成不同的随机数,私钥通过一定的加密算法推导出公钥,但私钥到公钥的推导过程是单向的,也就是说公钥无法反推导出私钥。所以安全性较高。
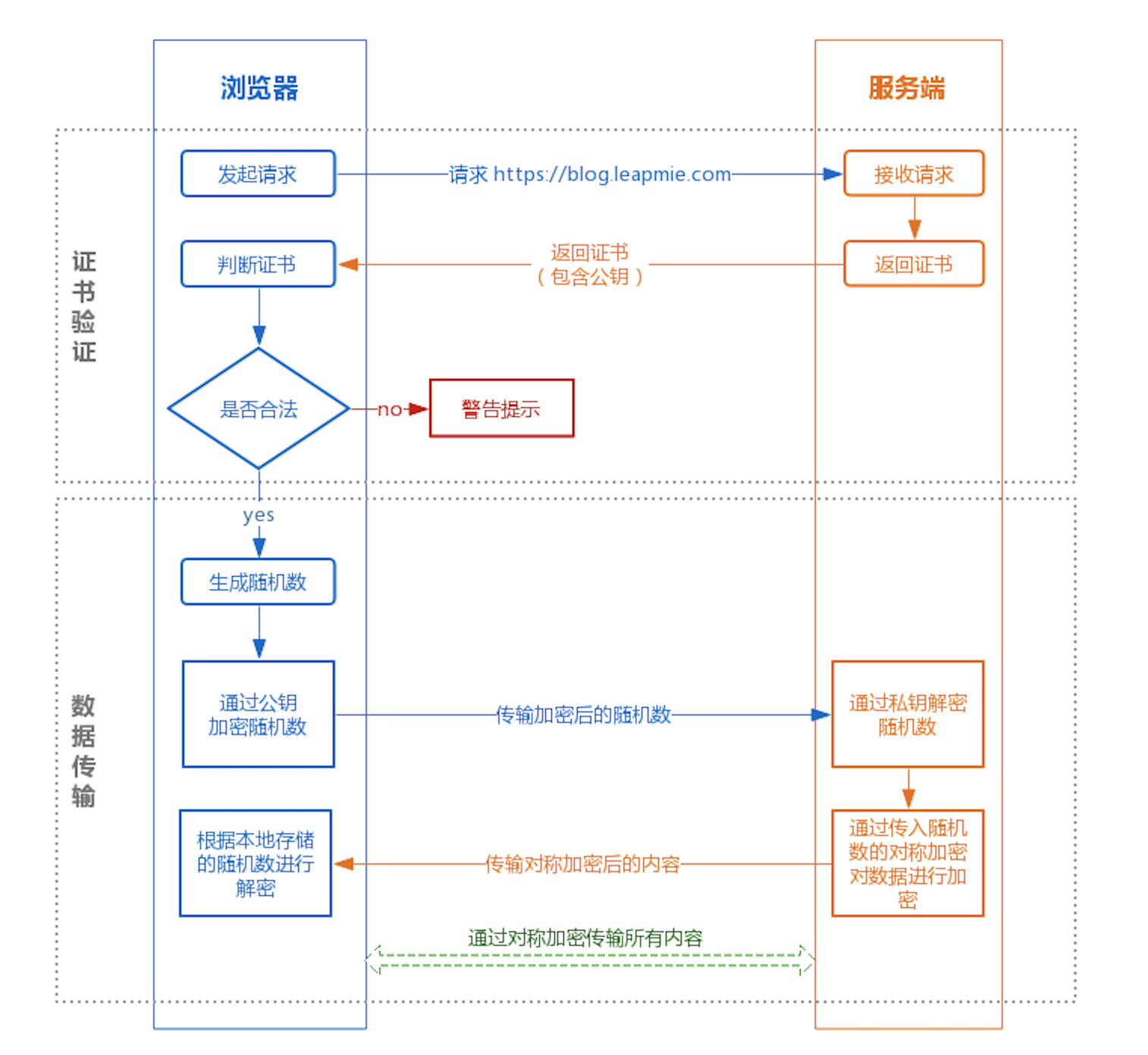
https 的连接过程大概分为两个阶段,证书验证阶段和数据传输阶段。
在证书验证阶段,使用非对称加密,需要公钥和私钥,假如浏览器的公钥泄漏了(并不知道加密的内容是什么),因为加密的数据只有用私钥才能解密。这样能最大程度确保随机数的安全。
内容传输为什么要使用对称机密
- 对称加密效率比较高
- 一对公私钥只能实现单向的加解密。只有服务端保存了私钥。如果使用非对称机密,相当于客户端必须有自己的私钥,这样设计的话,每个客户端都有自己的私钥,这很明显是不合理的,因为私钥是需要申请的。
中间人攻击
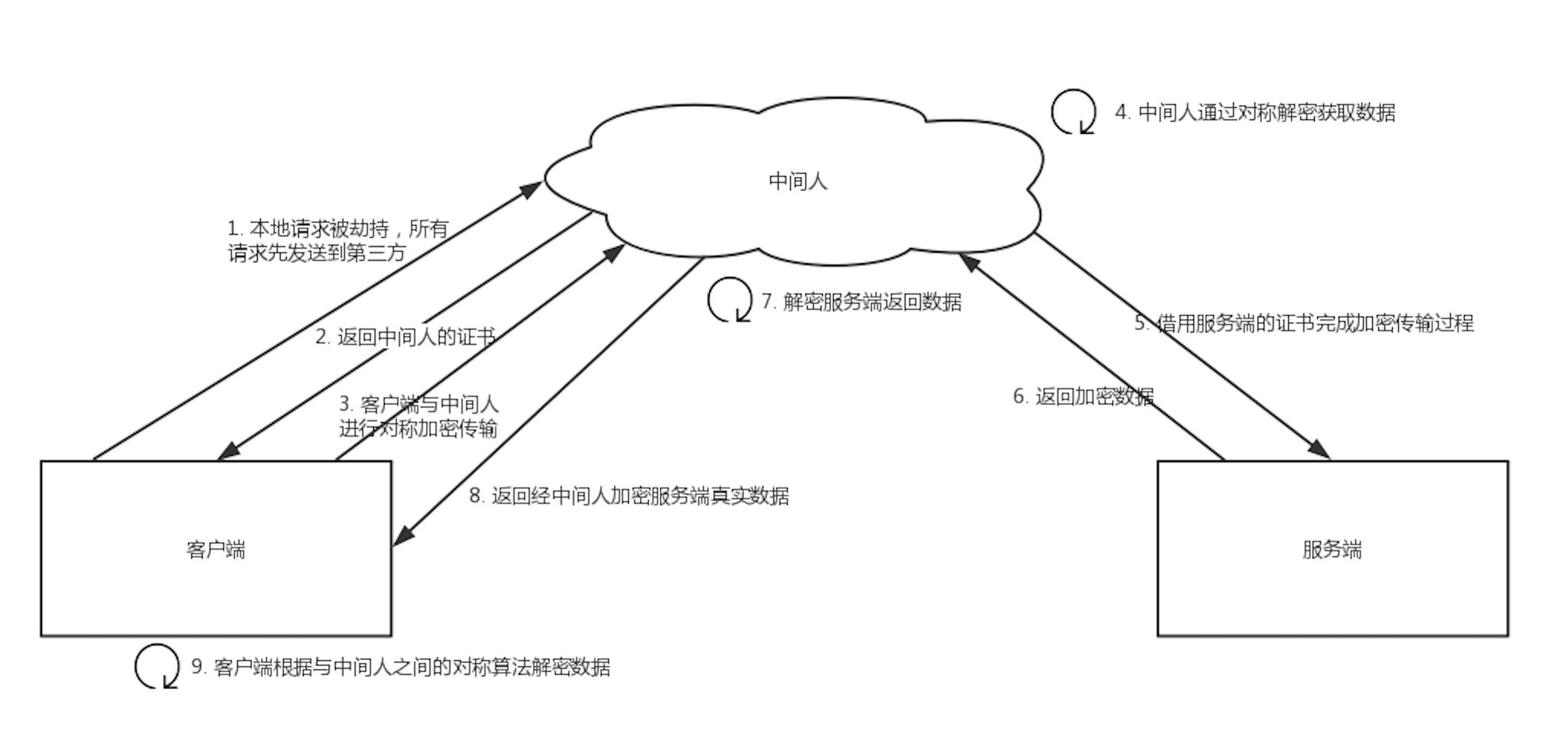
由于缺少对证书的验证,所以客户端虽然发起的是 HTTPS 请求,但客户端完全不知道自己的网络已被拦截,传输内容被中间人全部窃取。
https 是如何防止中间人攻击的
在https中需要证书,证书的作用是为了防止"中间人攻击"的。 如果有个中间人M拦截客户端请求,然后M向客户端提供自己的公钥,M再向服务端请求公钥,作为"中介者" 这样客户端和服务端都不知道,信息已经被拦截获取了。
========> 这时候就需要证明服务端的公钥是正确的.
怎么证明呢? (CA证书=SSL证书--SSL是基于对称+非对称 加密协议)
就需要权威第三方机构来公正了.这个第三方机构就是CA. 也就是说CA是专门对公钥进行认证,进行担保的,也就是专门给公钥做担保的担保公司。 全球知名的CA也就100多个,这些CA都是全球都认可的,比如VeriSign、GlobalSign等,国内知名的CA有WoSign。
浏览器是如何确保CA证书的合法性?
-
证书包含什么信息?
颁发机构信息、公钥、公司信息、域名、有效期、指纹......
-
证书的合法性依据是什么?
首先,权威机构是要有认证的,不是随便一个机构都有资格颁发证书,不然也不叫做权威机构。另外,证书的可信性基于信任制,权威机构需要对其颁发的证书进行信用背书,只要是权威机构生成的证书,我们就认为是合法的。所以权威机构会对申请者的信息进行审核,不同等级的权威机构对审核的要求也不一样,于是证书也分为免费的、便宜的和贵的。
-
浏览器如何验证证书的合法性?
浏览器发起HTTPS请求时,服务器会返回网站的SSL证书,浏览器需要对证书做以下验证:
-
验证域名、有效期等信息是否正确。证书上都有包含这些信息,比较容易完成验证;
-
判断证书来源是否合法。每份签发证书都可以根据验证链查找到对应的根证书,操作系统、浏览器会在本地存储权威机构的根证书,利用本地根证书可以对对应机构签发证书完成来源验证;
-
判断证书是否被篡改。需要与CA服务器进行校验;
-
判断证书是否已吊销。通过CRL(Certificate Revocation List 证书注销列表)和 OCSP(Online Certificate Status Protocol 在线证书状态协议)实现,其中 OCSP 可用于第3步中以减少与CA服务器的交互,提高验证效率。
以上任意一步都满足的情况下浏览器才认为证书是合法的。
-
https 可以抓包吗
HTTPS 的数据是加密的,常规下抓包工具代理请求后抓到的包内容是加密状态,无法直接查看。
但是,我们可以通过抓包工具来抓包。它的原理其实是模拟一个中间人。
通常 HTTPS 抓包工具的使用方法是会生成一个证书,用户需要手动把证书安装到客户端中,然后终端发起的所有请求通过该证书完成与抓包工具的交互,然后抓包工具再转发请求到服务器,最后把服务器返回的结果在控制台输出后再返回给终端,从而完成整个请求的闭环。
关于 httpps 抓包的原理可以看这一篇文章。
有人可能会问了,既然 HTTPS 不能防抓包,那 HTTPS 有什么意义?
HTTPS 可以防止用户在不知情的情况下通信链路被监听,对于主动授信的抓包操作是不提供防护的,因为这个场景用户是已经对风险知情。要防止被抓包,需要采用应用级的安全防护,例如采用私有的对称加密,同时做好移动端的防反编译加固,防止本地算法被破解。
如何防止抓包?
对于HTTPS API接口,如何防止抓包呢?既然问题出在证书信任问题上,那么解决方法就是在我们的APP中预置证书。在TLS/SSL握手时,用预置在本地的证书中的公钥校验服务器的数字签名,只有签名通过才能成功握手。由于数字签名是使用私钥生成的,而私钥只掌握在我们手上,中间人无法伪造一个有效的签名,因此攻击失败,无法抓包。
同时,为了防止预置证书被替换,在证书存储上,可以将证书进行加密后进行「嵌入存储」,如嵌入在图片中或一段语音中。这涉及到信息隐写的领域,这个话题我们有空了详细说。
关于 Android 中Https 请求如何防止中间人攻击和Charles抓包,可以看一下这一篇文章。
Android中Https请求如何防止中间人攻击和Charles抓包原理
预置证书/公钥更新问题
这样做虽然解决了抓包问题,但是也带来了另外一个问题:我们购买的证书都是有有效期的,到期前需要对证书进行更新。主要有两种方式:
提供预置证书更新接口。在当前证书快过期时,APP请求获取新的预置证书,这过渡时期,两个证书同时有效,直到安全完成证书切换。这种方式有一定的维护成本,且不易测试。 在APP中只预埋公钥,这样只要私钥不变,即使证书更新也不用更新该公钥。但是,这样不太符合周期性更新私钥的安全审计需求。一个折中的方法是,一次性预置多个公钥,只要任意一个公钥验证通过即可。考虑到我们的证书一般购买周期是3-5年,那么3个公钥,可以使用9-15年,同时,我们在此期间还可以发布新版本废弃老公钥,添加新公钥,这样可以使公钥一直更新下去。
客户端访问https网站
一般有两种方式实现,一是信任所有的证书,也就是跳过证书合法性校验这一步骤,对于这种做法肯定是有风险的;二是校验证书,证书合法才能访问。
第一种方式 :信任所有证书
解决证书不被系统承认的方法,就是跳过系统校验。要跳过系统校验,就不能再使用系统标准的SSLSocketFactory了,需要自定义一个。然后为了在这个自定义的SSLSocketFactory里跳过校验,还需要自定义一个X509TrustManager(Android采用的是X509验证),建立我们的验证规则,在其中忽略所有校验,即TrustAll。
// okhttp不验证绕过自己证书,使用android内置证书,直接通过所有的https连接
// 获取这个SSLSocketFactory
public static SSLSocketFactory getSSLSocketFactory() {
try {
SSLContext sslContext = SSLContext.getInstance("SSL");
sslContext.init(null, getTrustManager(), new SecureRandom());
return sslContext.getSocketFactory();
} catch (Exception e) {
throw new RuntimeException(e);
}
}使用这样的极端方式,虽然使用了HTTPS,实现了客户端和服务器端的通信内容得到了加密,嗅探程序无法得到传输的内容,但引生出来一种弊端,无法抵挡“中间人攻击”。例如,在内网配置一个DNS,把目标服务器域名解析到本地的一个地址,然后在这个地址上使用一个中间服务器作为代理,它使用一个假的证书与客户端通讯,然后再由这个代理服务器作为客户端连接到实际的服务器,用真的证书与服务器通讯。这样所有的通讯内容都会经过这个代理,而客户端不会感知,这是由于客户端不校验服务器公钥证书导致的,如charles抓包。