This is the unofficial implementation of the core two-stream model from Generalizing Face Forgery Detection with High-frequency Features (CVPR 2021) in Pytorch. The original paper [here](Generalizing Face Forgery Detection With High-Frequency Features (thecvf.com))
The overall network is shown as follows
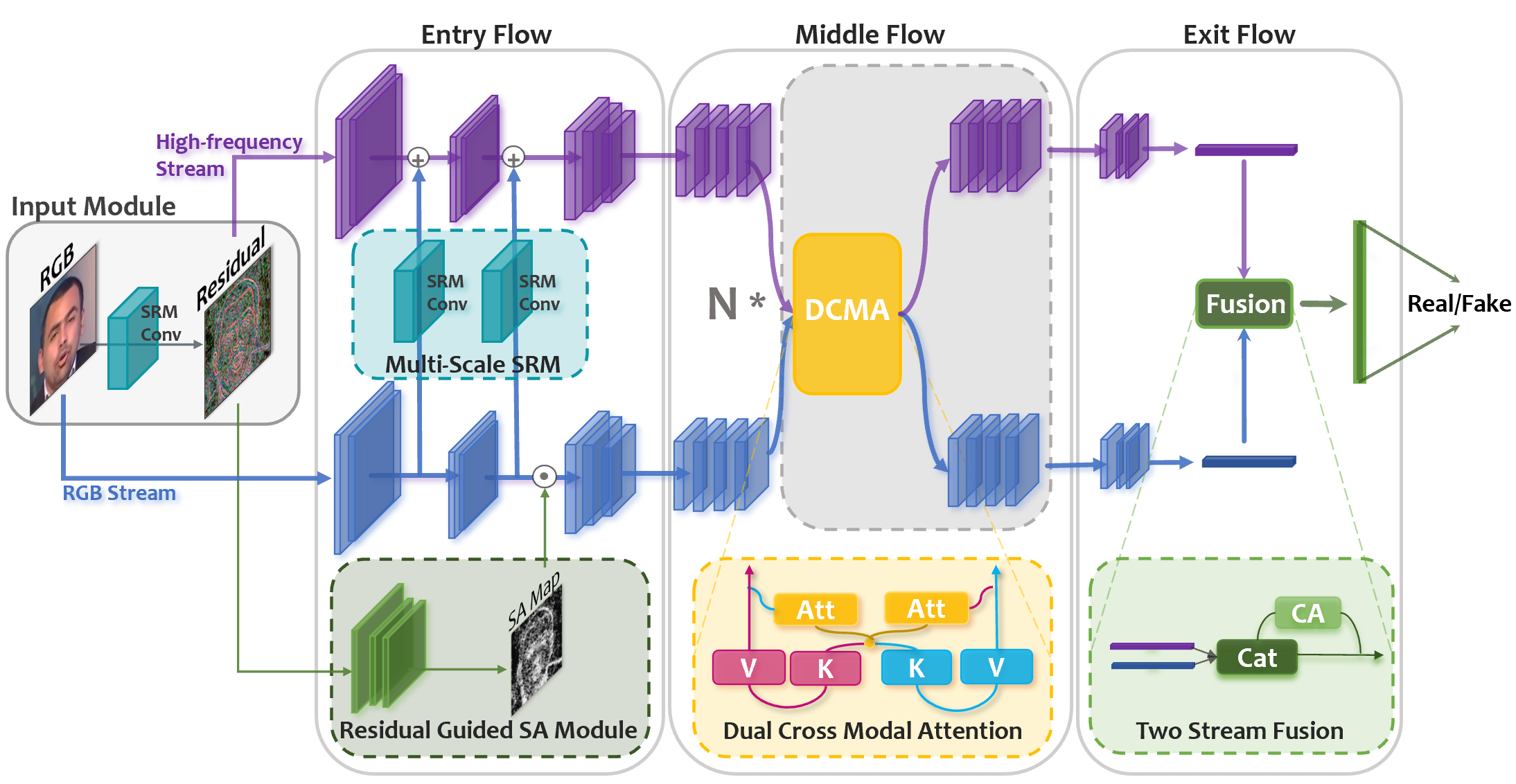
- pytorch 1.7
- dlib
- cv2
- tqdm
- Linux
|-- compare.py # compare the results of testdata labels
|-- components # modules of the network
| |-- __init__.py
| |-- __pycache__
| |-- attention.py # attention module
| |-- srm_conv.py # srm_conv module
|-- dataset.py # load the train data or val data
|-- loss # Loss Function
| |-- __pycache__
| |-- am_softmax.py # am_softmax loss
|-- model_core.py # the main network in this paper
|-- networks # baseline network
| |-- __pycache__
| |-- xception-b5690688.pth # pretrained baseline network
| |-- xception.py # baseline network
|-- test.py # test code
|-- train.py # train code
- For the test, run the test.py and set the args
python test.py --cuda_id 0 --test_dir /home/train --pre_model /home/model
- For the train, run the train.py and set the args
python train.py --cuda_id 0 --train_label /home/label --train_dir /home/train --val_dir /home/val --save_model /home/result
- Note
The size of training images is 256x256
The label of training images is a xxx.csv file(including all images' label: filename and label)