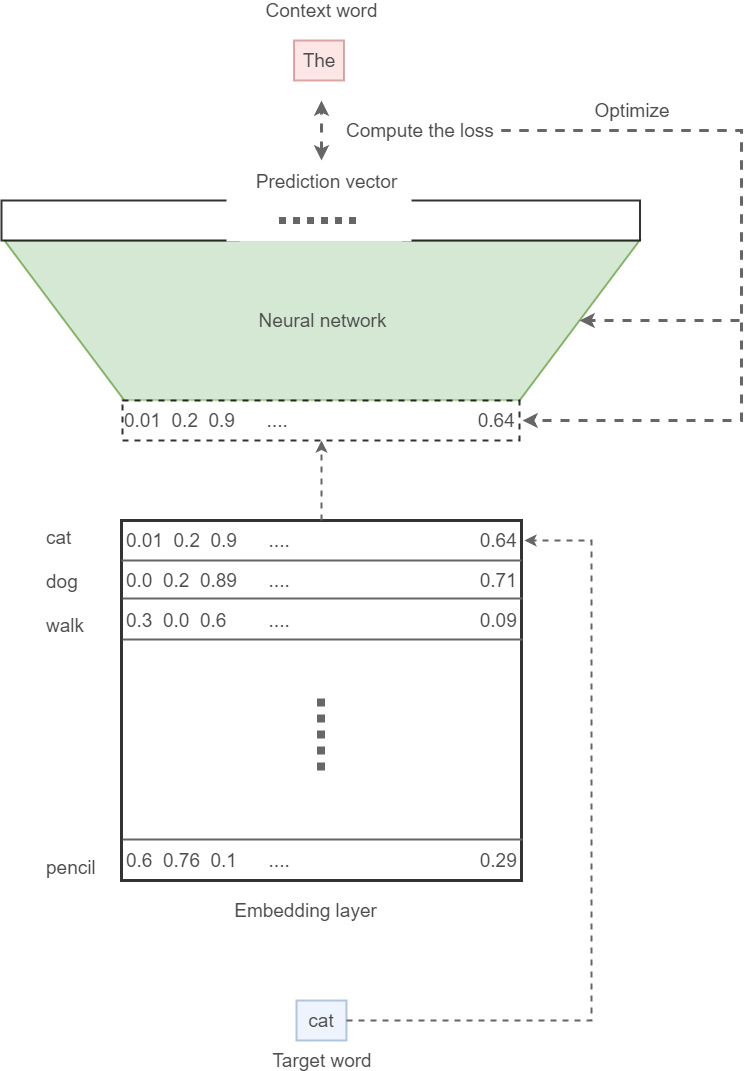
This project aim to utilize neural network to analyze sequence input from structured free-text medical records. At this stage, models are trained to give categorical output and optimized with categorical loss. In addition, a word embedding can be generated during training.
Antoine Bordes, et al. "Joint Learning of Words and Meaning Representations for Open-Text Semantic Parsing." AISTATS(2012) https://www.hds.utc.fr/~bordesan/dokuwiki/lib/exe/fetch.php?id=en%3Apubli&cache=cache&media=en:bordes12aistats.pdf
Alexis Conneau, et al. "Very Deep Convolutional Networks for Natural Language Processing." (2016) https://arxiv.org/abs/1606.01781
The original data was stored in .xls document, extracted from a medical record database. We prepare our training data with the following procedures:
- Remove any training data with missing item
- Remove non-english characters
- Remove all next-line character '\r\n'
- Assign an UUID to each set of training data.