- 快速起步
- 使用 docker 部署项目
- 例子
- 系统介绍
- 装饰器
- 工具类 PuppeteerUtil
- PuppeteerUtil.defaultViewPort
- PuppeteerUtil.addJquery
- PuppeteerUtil.jsonp
- PuppeteerUtil.setImgLoad
- PuppeteerUtil.onResponse
- PuppeteerUtil.onceResponse
- PuppeteerUtil.downloadImg
- PuppeteerUtil.links
- PuppeteerUtil.count
- PuppeteerUtil.specifyIdByJquery
- PuppeteerUtil.scrollToBottom
- PuppeteerUtil.parseCookies
- PuppeteerUtil.useProxy
- PuppeteerUtil 例子
- NetworkTracing
- 数据库
- 日志
- 调试
- 相关知识
- 控制界面
- 问题
- 更新日志
npm install -g typescript
推荐使用 IDEA
IDEA一定要下载 Ultimate 版本,否则有很多功能无法使用

IDEA中 nodejs 和 javascript 配置

ppspider_example github 地址
https://github.com/xiyuan-fengyu/ppspider_example
需要先安装git,并在IDEA中配置git的可执行文件的路径

点击 IDEA 底下工具栏的 Terminal,打开命令行面板,输入如下命令安装依赖
npm install
在安装依赖过程中,puppeteer会自动下载chromium,国内用户大概率下载失败
如果 chromium 下载失败,可以删除 node_modules/puppeteer 文件夹,如下更改 chromium 镜像地址,然后继续安装依赖
# win 系统
set PUPPETEER_DOWNLOAD_HOST=https://npm.taobao.org/mirrors/
# unix 系统
export PUPPETEER_DOWNLOAD_HOST=https://npm.taobao.org/mirrors/
npm install
tsc 是 typescript 的编译工具,将 typescript 代码编译为 js,之后便可右键 js 文件运行了(通过nodejs执行)
tsc 在运行期间会监听 ts 文件变化,自动编译有变动的 ts 文件
运行方式:
1.(推荐)右键 package.json,点击 Show npm Scripts,双击 auto build
2.在 IDEA 中打开一个 terminal, 运行 tsc
右键运行 lib/quickstart/App.js
用浏览器打开 http://localhost:9000 可以实时查看爬虫系统的运行情况
https://github.com/xiyuan-fengyu/ppspider_docker_deploy
- 监控网站访问速度,实时统计结果可视化,可以查看打开一个网页过程中的所有请求的具体情况 ppspider-webMonitor
- 通过cron表达式动态设置任务并行数 DynamicParallelApp
- 如果用户希望一些队列在应用启动后不立即执行,需要等到特殊条件达成后开始执行,可以参考这里 QueueWaitToRunApp
- 网页截图,支持超长网页截图 ScreenshotApp
- B站视屏信息和评论抓取 BilibiliApp
- 为单个page设置代理 Page Proxy
- QQ音乐信息和评论 QQ Music
- request + cheerio 抓取静态网站的例子 CheerioApp
- Twitter 主题评论和用户信息抓取 TwitterApp
- Depth-First-Search,DFS 深度优先搜索例子(通常情况下用 DefaultQueue 是广度优先搜索) DepthFirstSearchApp
- request + cheerio 抓取静态网站的例子 QuotesToScrapeApp
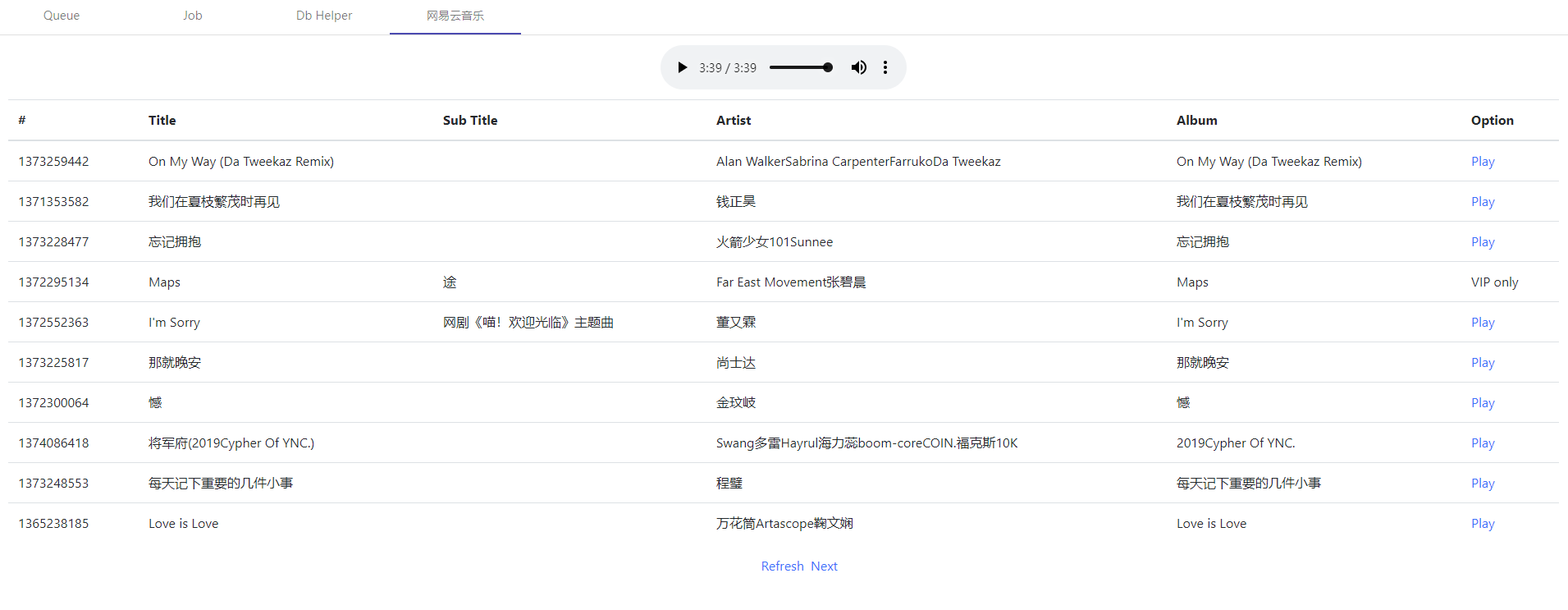
- 网易云音乐下载 Music163App
- 代理池 ProxyPool
- Bandcamp Music download
- 设置job的最大尝试次数 SetMaxTryApp
- Page.evaluate 执行 async function PuppeteerEvalAsyncApp
- AddToQueue/FromQueue name 属性使用正则表达式,动态创建一组队列 AddToRegexQueue
- 滑块验证码 PuppeteerUtil.dragJigsaw
- 无头模式下,请求返回结果不正常的处理办法 HandlBadRequestOnHeadlessApp
申明形式
export function TheDecoratorName(args) { ... }
使用方式
@TheDecoratorName(args)
乍一看和java中的注解一样,但实际上这个更为强大,不仅能提供元数据,还能对类或方法的属性行为做修改装饰,实现切面的效果,ppspider中很多功能都是通过装饰器来提供的
接下来介绍一下实际开发中会使用到的装饰器
export function Launcher(appConfig: AppConfig)
申明整个爬虫系统的启动入口
其参数类型为
export type AppConfig = {
workplace: string; // 系统的工作目录
queueCache?: string; // 运行状态保存文件的路径,默认为 workplace + "/queueCache.json"
dbUrl?: string; // 数据库配置,支持 nedb 或 mongodb;少量数据用 nedb,url格式为:nedb://本地nedb存储文件夹;若应用要长期执行,生成数据量大,建议使用 mongodb,url格式为:mongodb://username:password@host:port/dbName;默认:"nedb://" + appInfo.workplace + "/nedb"
tasks: any[]; // 任务类
dataUis?: any[]; // 需要引入的DataUi
workerFactorys: WorkerFactory<any>[]; // 工厂类实例
webUiPort?: 9000 | number; // UI管理界面的web服务器端口,默认9000
logger?: LoggerSetting; // 日志配置
}
export function OnStart(config: OnStartConfig)
用于声明一个在爬虫系统启动时执行一次的子任务;后续可以在管理界面上点击该任务名后面的重新执行的按钮即可让该任务重新执行一次
参数说明
export type OnStartConfig = {
urls: string | string[]; // 要抓取链接
running?: boolean; // 系统启动后该队列是否处于工作状态
parallel?: ParallelConfig; // 任务并行数配置
exeInterval?: number; // 两个任务的执行间隔时间
exeIntervalJitter?: number; // 在 exeInterval 基础上增加一个随机的抖动,这个值为左右抖动最大半径,默认为 exeIntervalJitter * 0.25
timeout?: number; // 任务超时时间,单位:毫秒,默认:300000ms(5分钟),负数表示永不超时
maxTry?: number; // 最大尝试次数,默认:3次,负数表示一直尝试
description?: string; // 任务描述
filterType?: Class_Filter; // 添加任务过滤器,默认是 BloonFilter;保存状态后,系统重启时,不会重复执行;如果希望重复执行,可以用 NoFilter
defaultDatas?: any; // 该类任务统一预设的job.datas内容
}
使用例子 @OnStart example
export function OnTime(config: OnTimeConfig) { ... }
用于声明一个在特定时刻周期性执行的任务,通过cron表达式设置执行时刻
参数说明(cron以外的属性说明参考 OnStartConfig)
export type OnTimeConfig = {
urls: string | string[];
cron: string; // cron表达式,描述了周期性执行的时刻;不清楚cron表达式的可以参考这里:http://cron.qqe2.com/
running?: boolean;
parallel?: ParallelConfig;
exeInterval?: number;
exeIntervalJitter?: number;
timeout?: number;
maxTry?: number;
description?: string;
defaultDatas?: any; // 该类任务统一预设的job.datas内容
}
使用例子 @OnTime example
这两个装饰器必须一起使用,@AddToQueue 将被装饰的方法的返回结果添加到队列中,@FromQueue 从队列中获取 Job 并执行
export function AddToQueue(queueConfigs: AddToQueueConfig | AddToQueueConfig[]) { ... }
export type AddToQueueConfig = {
// 队列名
name: string;
// 队列类型, 目前提供了 DefaultQueue(先进先出),DefaultPriorityQueue(优先级队列)
queueType?: QueueClass;
// 过滤器类型,目前提供了 NoFilter(不进行过滤),BloonFilter(布隆过滤器)
filterType?: FilterClass;
}
一个 @AddToQueue 可以配置一个或多个队列;可以在多个地方用 @AddToQueue 往同一个队列中添加 Job ,队列类型由第一次申明处的 queueType 决定,但每一处的 filterType 可以不一样
@AddToQueue 装饰的方法的返回结果必须符合 AddToQueueData 的形式
export type CanCastToJob = string | string[] | Job | Job[];
export type AddToQueueData = Promise<CanCastToJob | {
[queueName: string]: CanCastToJob
}>
当 @AddToQueue 配置了多个队列信息时,返回类型必须是
Promise<{
[queueName: string]: CanCastToJob
}>
格式的数据;可以使用 PuppeteerUtil.links 方法方便的获取想要的连接,这个方法的返回结果正好是 AddToQueueData 格式的,具体的用法后面会介绍
@FromQueue,从队列从获取任务执行,同一个队列只能定义一个FromQueue
export function FromQueue(config: FromQueueConfig) { ... }
export type FromQueueConfig = {
name: string; // 队列名
running?: boolean;
parallel?: ParallelConfig;
exeInterval?: number;
exeIntervalJitter?: number;
timeout?: number;
maxTry?: number;
description?: string;
defaultDatas?: any; // 该类任务统一预设的job.datas内容
}
使用例子 @AddToQueue @FromQueue example
export function JobOverride(queueName: string) { ... }
在将 job 添加到队列之前对 job 的信息进行重写修改
同一个队列只能设置一个 JobOverride
最常用的使用场景:很多时候多个带有额外参数或尾缀的url实际指向同一个页面, 这个时候可以提取出url中的唯一性标识,
并将其作为 job 的 key,用于重复性校验,避免重复抓取
实际上 OnStart, OnTime 两种类型的任务也是通过队列管理的,采用 DefaultQueue(NoFilter) 队列,队列的命名方式为
OnStart_ClassName_MethodName,所以也可以通过 JobOverride 对 job 进行修改
JobOverride example
export function Serializable(config?: SerializableConfig) { ... }
export function Transient() { ... }
@Serializable 用于标记在序列化和反序列化中,需要保留类信息的类,没有这个标记的类的实例在 序列化之后会丢失类的信息
@Transient 用于标记类成员,在序列化时忽略该字段。注意:类静态成员不参与序列化
这两个主要为关闭系统时保存运行状态提供支持,在实际使用的时候,如果有些类成员和运行状态没有直接关联,不需要序列化保存的
时候,一定要用 @Transient 来忽略该字段,可以减小序列化后文件的大小
example
export function RequestMapping(url: string, method: "" | "GET" | "POST" = "") {}
@RequestMapping 用于声明 HTTP rest 接口,提供远程动态添加任务的能力,返回抓取结果需要自行实现(例如异步url回调)
RequestMapping example
仿造 java spring @Bean @Autowired 的实现,提供实例依赖注入的功能
example
在控制界面定制动态界面的功能,为数据可视化、用户交互提供了扩展支持,通过 Angular 动态编译组件实现,简化了数据通信(主动请求数据和被动接受推送数据)
需要在 @Launcher appConfig.dataUis 中导入 DataUi 定义类
系统内置了一个DbHelperUi,引入这个DataUi后,在UI界面上添加一个名为“Db Helper”的tab页,可以辅助查询数据库中的数据
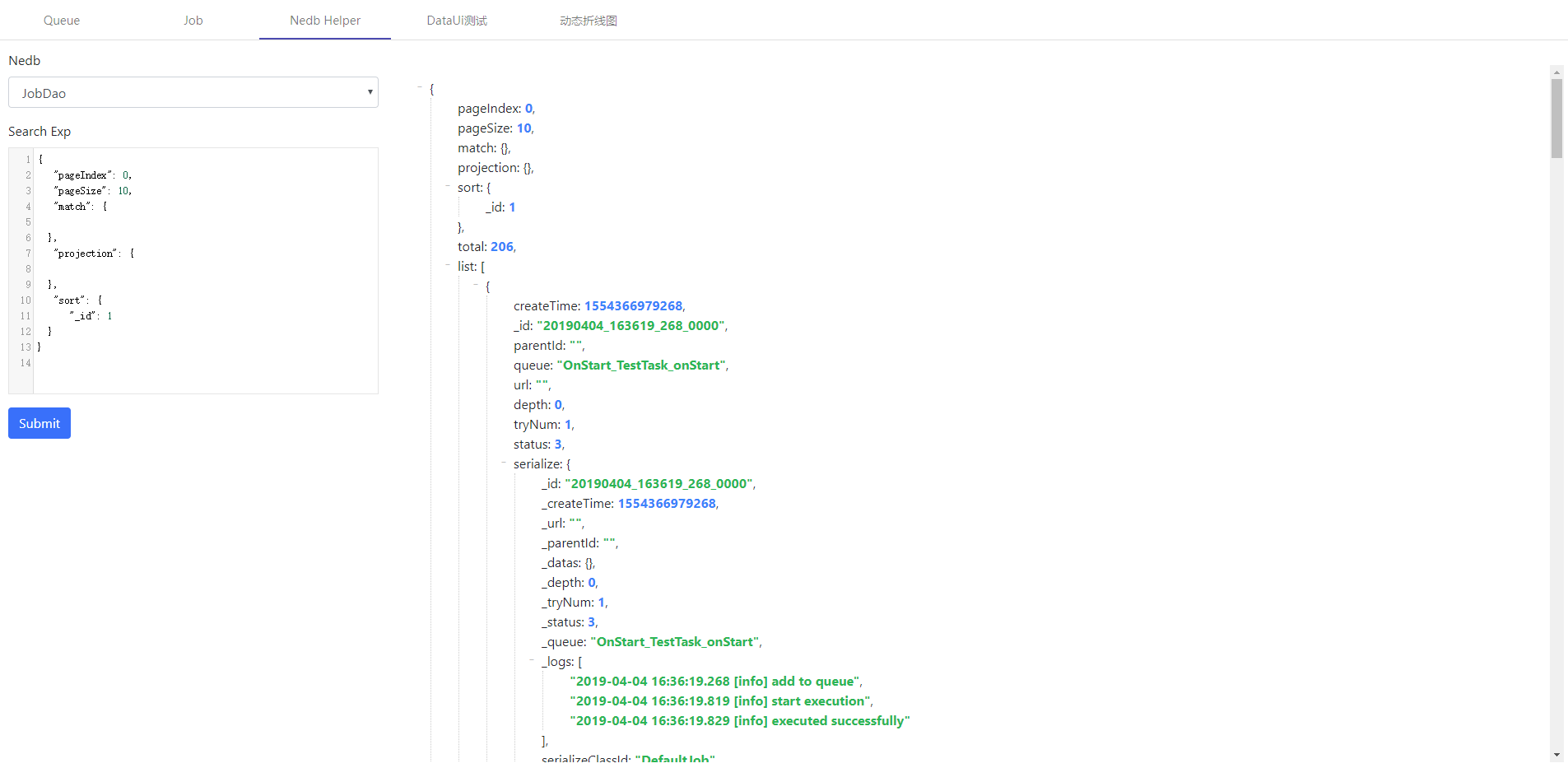
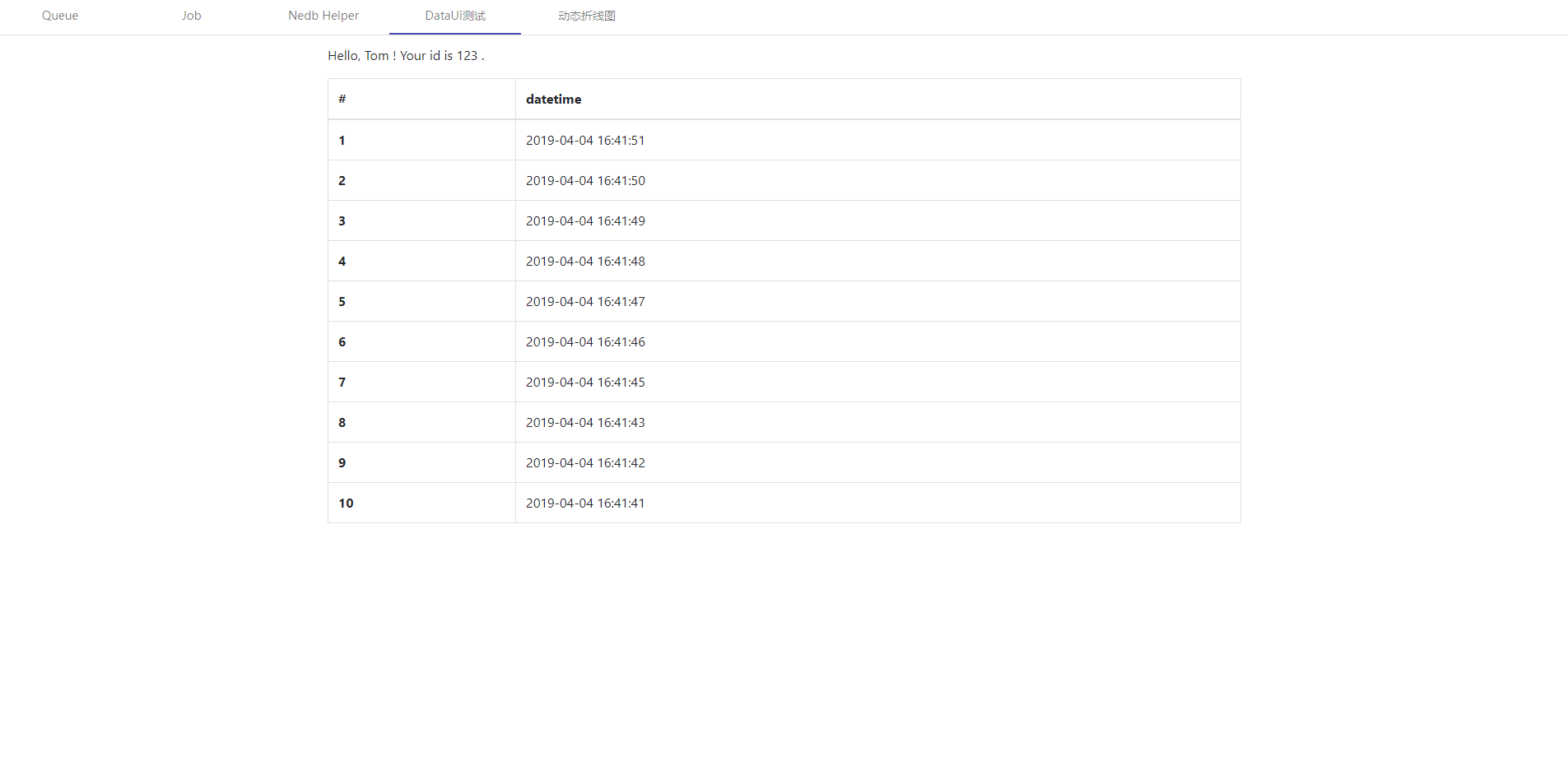
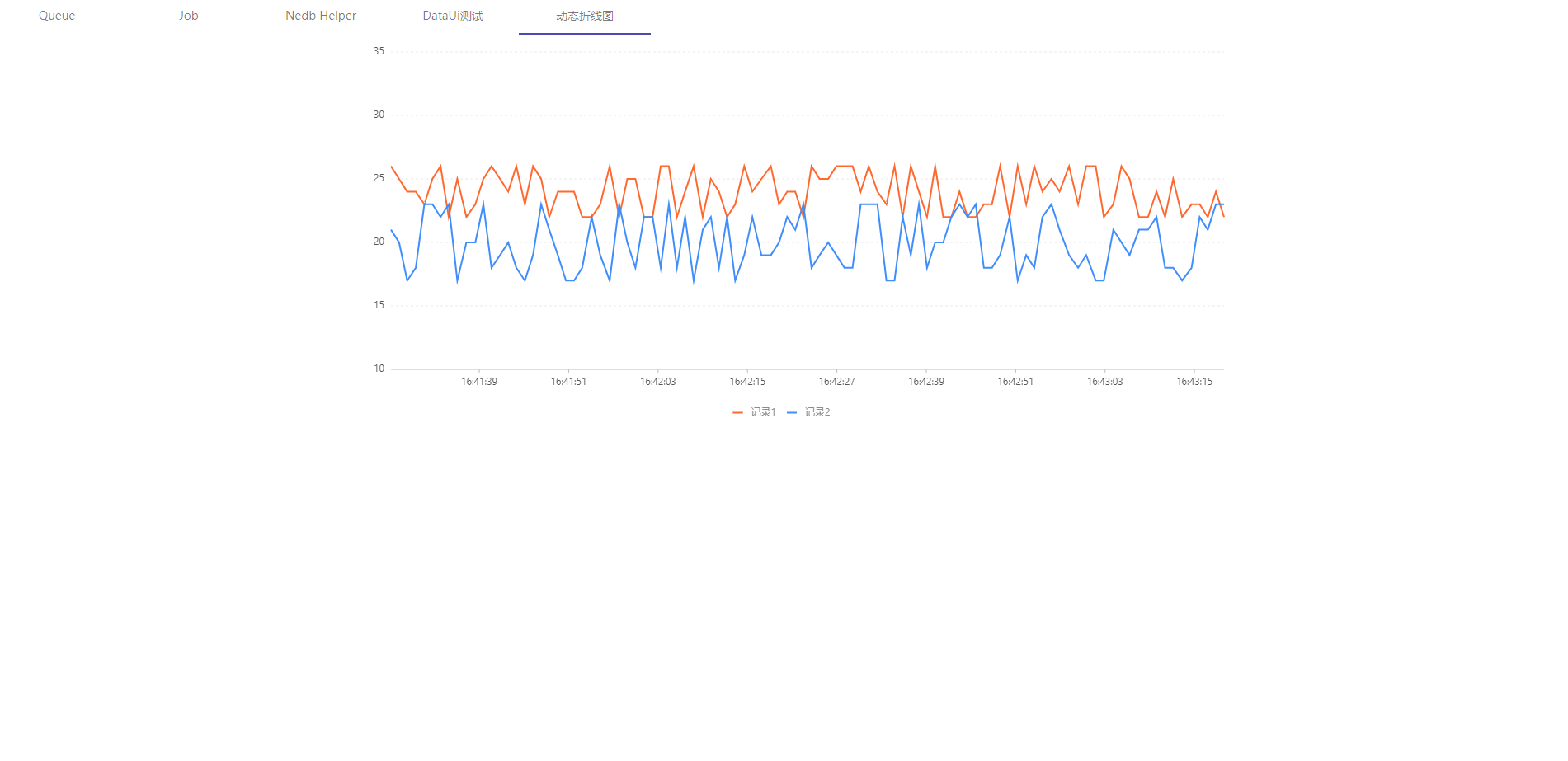
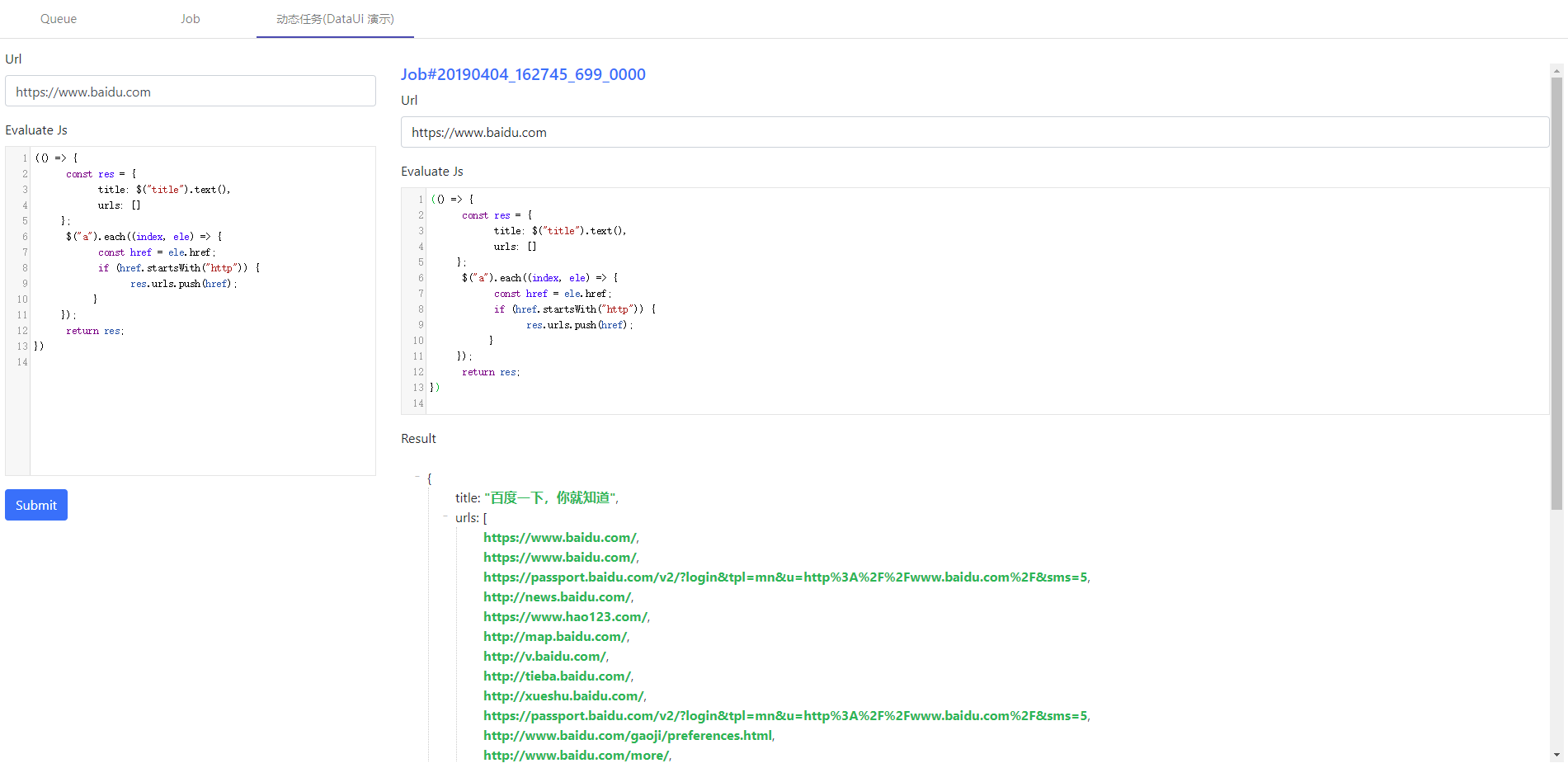
example 3 网页截图工具
支持超长网页截图
将 page 的窗口分辨率设置为 1920 * 1080
向 page 中注入 jquery,页面刷新或跳转后失效,所以这个方法必须在 page 加载完成之后调用
用于解析jsonp数据中的json
禁止或启用图片加载
用于监听接口的返回结果,可以设置监听次数
用于监听接口的返回结果,仅监听一次
下载图片
获取网页中的连接
获取满足 selector 的元素个数,不支持jQuery的selector
使用 jQuery(selector) 查找节点, 并为其中没有 id 的节点添加随机 id,
最后返回一个所有节点 id 的数组
使用场景:
Page 中所有涉及到使用selector查找节点的方法都是使用 document.querySelector / document.querySelectorAll
但是document.querySelector / document.querySelectorAll 不支持jQuery的高级selector
例如 "#someId a:eq(0)", "#someId a:contains('next')"
这时候可以通过这个方法为这些元素添加特殊的id,然后在通过 #specialId 去操作对应的节点
页面滚动到最底部
将cookie字符串解析为 SetCookie 数组,然后就可以通过 page.setCookie(...cookieArr) 来设置cookie
cookie字符串获取方式
通过 chrome -> 按下F12打开开发者面板 -> Application面板 -> Storage:Cookies: -> 右侧cookie详情面板 -> 鼠标选中所有,Ctrl+c 复制所有
得到的cookie字符串形式如下
PHPSESSID ifmn12345678 sm.ms / N/A 35
cid sasdasdada .sm.ms / 2037-12-31T23:55:55.900Z 27
为单个page设置动态的代理
用于记录打开一个页面过程中的请求情况 NetworkTracing example
目前提供了 nedb 和 mongodb 支持,分别通过 NedbDao, MongodbDao 进行封装
通过 @Launcher 的 dbUrl 参数设置数据库连接,之后便可以通过 appInfo.db 来操作数据库,具体可用的方法参考 src/common/db/DbDao
nedb 是一个 server-less 数据库,不需要额外安装服务端,数据会持久化到本地文件,url格式:nedb://nedbDirectoryPath,当存储数据量较大时,数据查询速度较慢,且每次重启应用需要加载数据,耗时较多,所以只适用于数据量较小的应用场景
mongodb 需要额外安装mongo服务端,url格式: mongodb://username:password@host:port/dbName,适用于数据量较大的场景
应用启动后,会自动创建一个 job collection,用于保存执行过程中的任务记录
通过 src/common/util/logger.ts 中定义的 logger.debug, logger.info, logger.warn, logger.error 方法输出日志
输出的日志中包含时间,等级,源文件位置这些额外信息
logger.debugValid && logger.debug("test debug");
logger.info("test info");
logger.warn("test warn");
logger.error("test error");
通过 Page.evaluate, Page.evaluateOnNewDocument, Page.evaluateHandle 执行的代码,
实际上是通过 chrome devtools protocol 运行在 chromium 中,这些代码我们称为注入代码
这些代码并不是直接由Nodejs执行,所以在IDEA中并不能直接调试
其他直接由Nodejs执行的代码是可以在IDEA中直接调试的
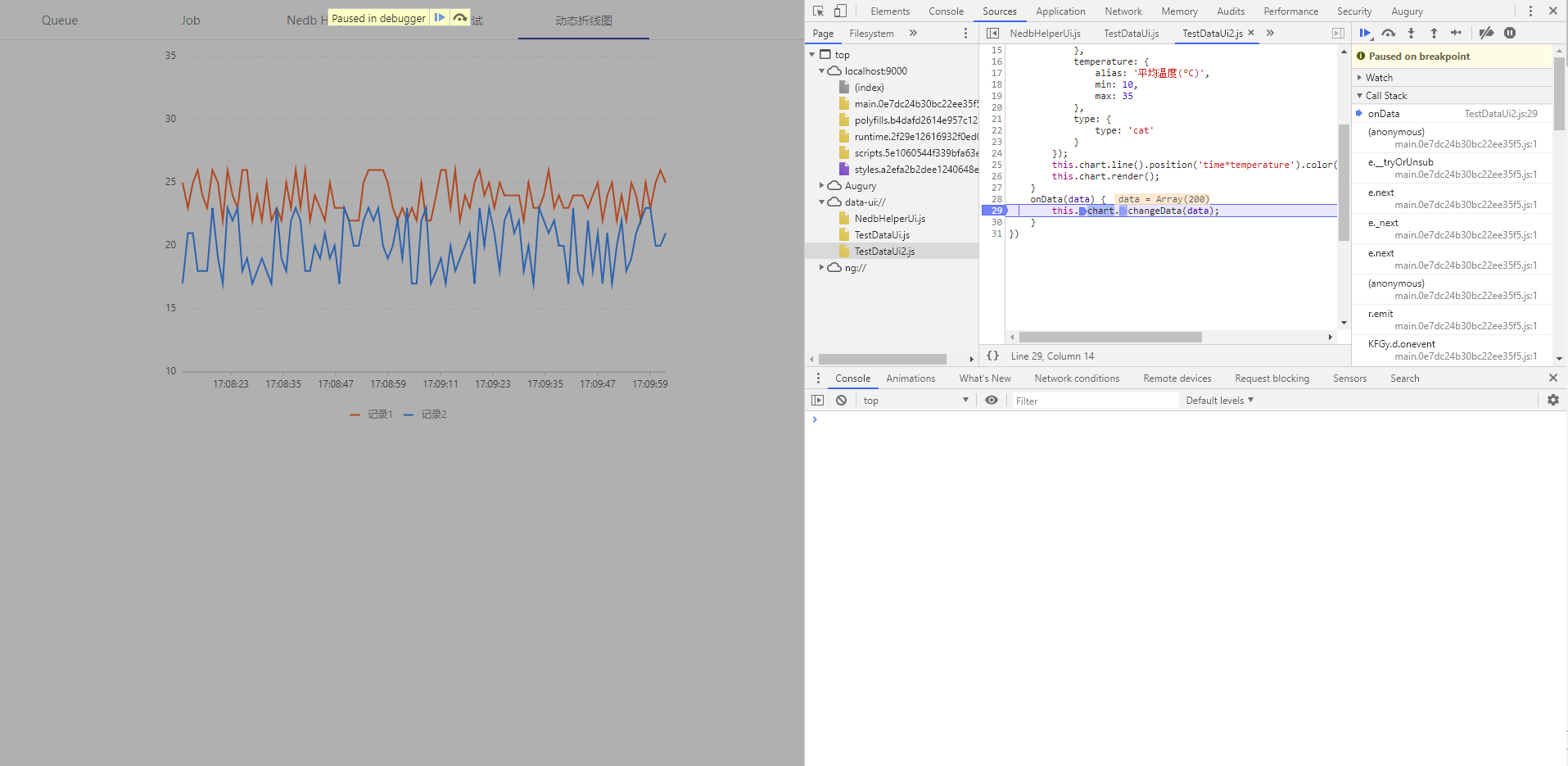
下面是注入代码的调试方式
在构造 PuppeteerWorkerFactory 时,设置参数 headless = false, devtools = true ,chromium 执行到 debugger 会自动断点
Inject js debug example
import {Launcher, PuppeteerWorkerFactory} from "ppspider";
import {TestTask} from "./tasks/TestTask";
@Launcher({
workplace: __dirname + "/workplace",
tasks: [
TestTask
],
workerFactorys: [
new PuppeteerWorkerFactory({
headless: false,
devtools: true
})
]
})
class App {
}
然后在要调试的注入代码前加一行 debugger;
import {Job, OnStart, PuppeteerWorkerFactory} from "ppspider";
import {Page} from "puppeteer";
export class TestTask {
@OnStart({
urls: "http://www.baidu.com",
workerFactory: PuppeteerWorkerFactory
})
async index(page: Page, job: Job) {
await page.goto(job.url());
const title = await page.evaluate(() => {
debugger;
const title = document.title;
console.log(title);
return title;
});
console.log(title);
}
}
另外,开发者在开发 DataUi 时,界面部分也是在浏览器中调试
http://www.runoob.com/jquery/jquery-syntax.html
通过 PuppeteerUtil.addJquery 将 jQuery 注入到 page 中后,就可以愉快地使用 jQuery 获取页面中想要的信息了
https://github.com/GoogleChrome/puppeteer/blob/master/docs/api.md
对 chrome devtools protocol 的封装
在抓取页面的时候,基本上都是在和 Page 打交道,所以 Page 相关的Api需要着重了解
https://github.com/louischatriot/nedb
基于内存和日志的serverless轻量级数据库,类Mongodb的查询方式
src/common/db/NedbDao.ts 对nedb的加载,数据压缩,基础查询做了进一步封装,方便用户继承使用
https://docs.mongodb.com/manual/reference/method/js-collection/
https://angular.io/
DataUi 是基于 angular 运行时动态编译的 Component,如果要编写复杂的 DataUi,有必要了解 Angular 的知识
https://antv.alipay.com/zh-cn/g2/3.x/demo/index.html
web ui中集成了 G2,方便在DataUi中实现数据可视化
https://v3.bootcss.com/css/
web ui中集成了 bootstrap, jquery,方便在DataUi中可以直接使用bootstrap和jquery编写ui界面
使用浏览器打开 http://localhost:9000
Queue 面板可以查看和管理整个系统中子任务的运行情况
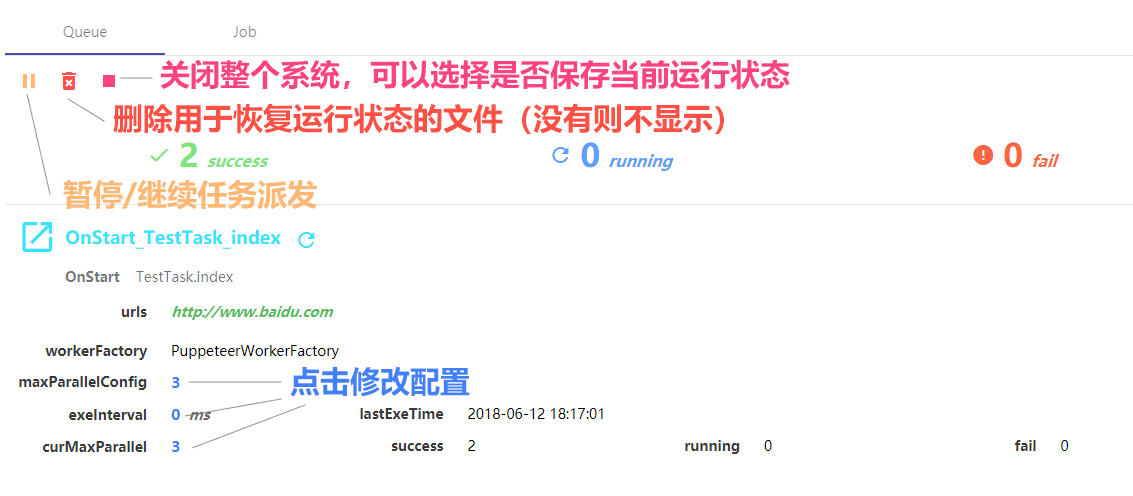
Job 面板可以对所有子任务实例进行搜索,查看任务详情
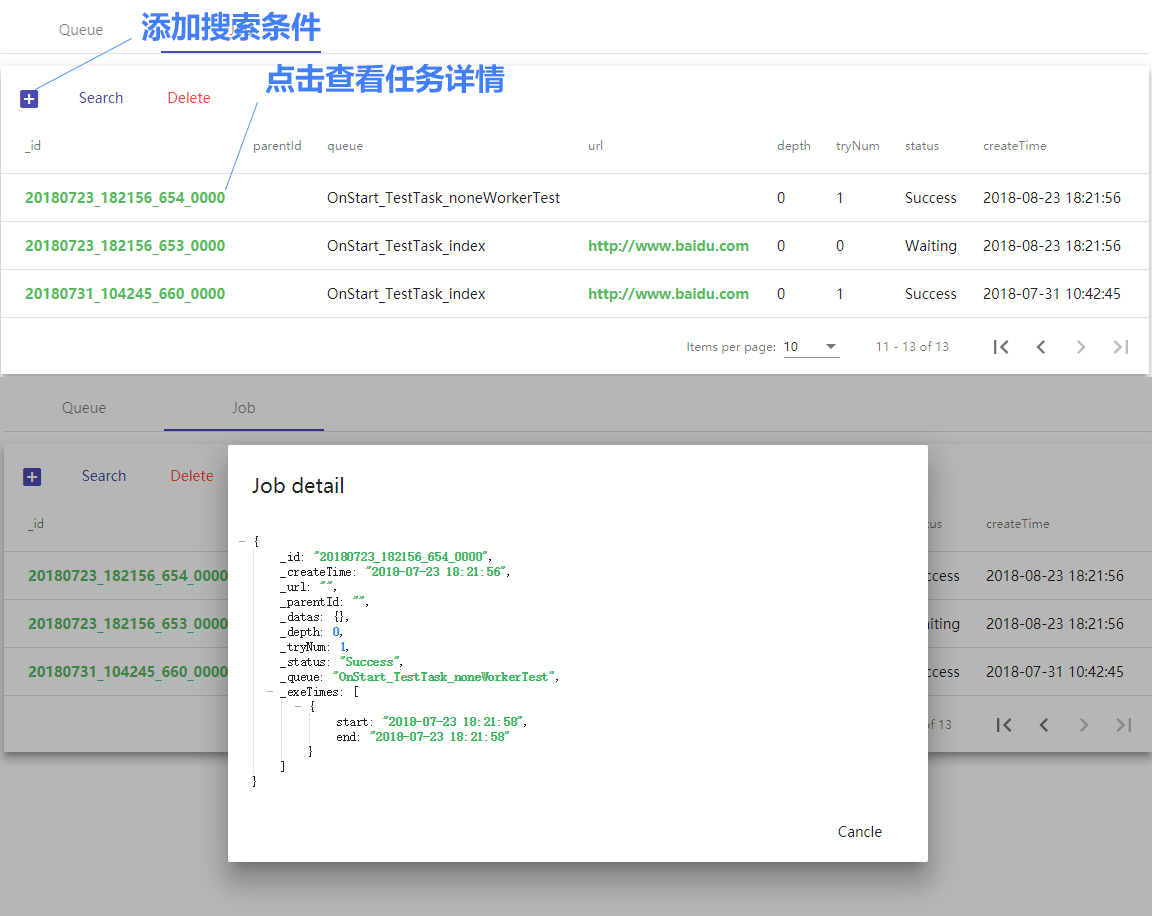
- 在idea中使用debug模式运行时,运行较长一段时间后,代码可能会停在某一行,就像断点停住一样,
这是因为内存不足导致的,可以在添加node参数 --max-old-space-size=8192
这个情况在之前的版本中常有出现,主要是nedb存储读取过程,序列化和反序列化过程实现不当导致的, 新版本(v2.1.2)已经进行了优化 - 使用 v2.2.0+ 版本时,@OnStart, @OnTime, @FromQueue 移除了 workerFactory 属性,如果要使用 puppeteer page 抓取网页,
可以通过
引入 Page class,然后在回调函数的参数列表中声明一个 page: Page 参数即可。如果通过 import {Page} from "puppeteer" 引入,引入的 Page 只是一个 interface,通过 reflect-metadata 无法在运行时判定 参数类型,导致 page 参数无法正常注入,这个错误在启动过程中就会检查出来。
import {Page} from "ppspider";
2020-12-07 v2.2.4-preview.1607350101966
- 修改puppeteer默认的userDataDir,防止puppeteer意外崩溃的情况下,产生过多临时文件夹
- QueueManager_JobExecuted 事件传递参数中增加 worker 的信息
- 重写 EventBus,使得可以等待异步通知
2020-04-07 v2.2.3
- 解决跨域情况下,page.frames可能找不到iframe的bug
- 优化 PuppeteerUtil.dragJigsaw 实现,提高准确度
2019-09-04 v2.2.3-preview.1578363288631
- 修复任务中断的bug
2019-09-04 v2.2.3-preview.1577332807380
- 修复bug:Job被UI界面中断后不再重试
- 任务和队列配置增加maxTry参数,支持maxTry小于0时一直尝试
- 任务和队列配置增加defaultDatas,作为job.datas的预设值
- UI界面增加切换队列running状态的操作
- UI界面增加timeout/maxTry/defaultDatas的修改配置功能
2019-09-04 v2.2.3-preview.1574909694087
- OnStart任务可配置使用 BloonFilter(默认,保存状态后重启不重复执行)或NoFilter(保存状态后重启重复执行)
- 修复db分页查询中的bug
- 添加 OnEvent 注解,用于监听系统事件,目前仅一种实际应用 OnEvent Example
2019-09-04 v2.2.3-preview.1569208986875
- 修复 src/common/db/MongodbDao.ts 中 remove 方法中的空指针bug
- JobOverride 回调方法增加参数,用于传递 parent job
- 序列化过程忽略没有使用@Serializable标记的类信息
- 修复 PuppeteerUtil 中 RegExp 匹配问题
- RequestUtil 增加 SocksProxyAgent
2019-07-31 v2.2.2
- @Bean @Autowired bug修复,@Autowired支持类型识别
- RequestUtil 增加多行headers字符串解析方法,simple方法增加 headerLines 属性,方便传入多行headers字符串, simple方法增加可选handler参数,方便监听请求结果
- PuppeteerUtil.useProxy 代理请求时,自动添加 cookies
- Page.evaluate, evaluateOnNewDocument, evaluateHandle,
$eval, $ $eval 支持 async function 参数 - Page 的引入方式修正
- 增加 UserAgents 工具类,用于随机获取 user-agent
- AddToQueue FromQueue name支持正则表达式(例子)
- 默认设置 Page 分辨率为 1920 * 1080, 默认设置 navigator.webdriver=false
- 增加模拟拖动滑块的方法 PuppeteerUtil.drag
- 增加方法 PuppeteerUtil.triggerAndWaitRequest,用于触发并监听一个请求
- 增加方法 PuppeteerUtil.triggerAndWaitResponse,用于触发并监听一个请求的应答
- 提供两种滑块验证码的破解方案
从左拖动到最右边的滑块验证码 PuppeteerUtil.dragBar
需要拖动到合适位置完成拼图的滑块验证码 PuppeteerUtil.dragJigsaw
2019-06-22 v2.2.1
-
通过 typescript 和 reflect-metadata 提供的反射机制,重写 @OnStart, @OnTime, @FromQueue 回调函数注入worker实例的方式; 移除了 @OnStart, @OnTime, @FromQueue 参数中的workerFactory属性,框架通过回调方法的参数类型判定 是否需要 传递 job 参数,是否需要传递 worker 实例(如果需要,传递哪一种 worker 实例),参数列表的顺序和个数也不再固定。 但也有限制,参数列表中,最多一个Job类型的参数,以及最多一个有对应 WorkerFactory 定义的 Worker 类型(目前仅提供了 Page, 注意是 ppspider 包中提供的 class Page,而不是 @types/puppeteer 中定义的 interface Page)。
因为这个更改,需要对一些代码进行升级,需要移除 @OnStart, @OnTime, @FromQueue 参数中的 workerFactory 属性,回调函数 参数列表中如果要用到 page: Page,需要将 import {Page} from "puppeteer" 改为 import {Page} from "ppspider",其他除了 job: Job 的参数都删除掉。参数列表的顺序和名字都可以随意定义,如果回调方法中没有用到 job: Job,也可以把这个参数删掉。
-
修复 @AddToQueue 不和 @OnStart / @OnTime / @FromQueue 一起使用时失效的bug
-
增加 docker 部署方案
2019-06-13 v2.1.11
- 修复 PuppeteerWorkerFactory.overrideMultiRequestListenersLogic 中 once listener 的实现
- FileUtil.write 的content参数类型 增加 Buffer 类型
- QueueManager.loadFromCache 加载缓存过程中,设置队列的 lastExeTime
- 更改 ui 中的部分依赖:bootstrap(3.4.1), g2(@antv/g2, @antv/data-set)
- ui 中 window 增加 __awaiter 定义,使得在 DataUi 中可以使用 async, await 关键字
- ui 中 window 增加 loadScript 定义,使得在 DataUi 中可以方便地加载第三方js
- JobOverride 支持异步回调方法;JobOverride 调用回调方法的时机调整
2019-06-06 v2.1.10
- 重写 Page 添加/移除/查询 request listener 的过程,保证一个page只有一个request listener(theOnlyRequestListener), 用户添加的request listener将通过 theOnlyRequestListener 调用,在用户定义的 request listener 中可以不再纠结是否需要调用 request.continue()
- 重写 AddToQueue 将方法返回结果添加到队列的实现,使得 Filter 支持异步校验
- 采用 request 重写 PuppeteerUtil.useProxy 的代理过程,将代理过程封装到 RequestUtil.simple 方法中
- UI界面上增加 fail / failed 的说明,队列的failed显示两个数目:尝试失败的次数,最大尝试次数后仍失败的任务数
2019-06-03 v2.1.9
- 修复 PuppeteerUtil.useProxy 代理请求出现异常后,应用崩溃的bug
2019-06-02 v2.1.8
- 增加新的方法:PuppeteerUtil.useProxy,用于支持设置page动态代理
- 更新puppeteer版本:1.17.0
2019-05-28 v2.1.6
- 修复 MongodbDao 中URL模块引用错误的bug
- 修复 PuppeteerUtil.parseCookie 解析日期的bug
2019-05-24 v2.1.3
- ui界面Job面板,createTime改为文本输入,精确到毫秒
- 修复删除job的bug
- 调整 cron 动态设置 parallel 的功能,使得应用启动后立即设置一次parallel
2019-05-21 v2.1.2
- 重写 序列化/反序列化 过程,解决大对象序列化失败的问题
- 删除 DefaultJob, 将 interface Job 改为 class Job,其中的方法都改为了对应的字段,这一改动导致历史 QueueCache 数据不兼容
- 重写 Nedb 加载和保存的过程,使其支持大量数据的读写
- 重写 NedbDao,提供新的 mongodb支持: MongodbDao,两者对数据的读写是兼容的;用户可直接使用 @Launcher dbUrl 来配置数据库,通过 appInfo.db 来操作数据库
2019-05-09 v2.0.5
- 更改cron依赖包:later -> cron
- 调整OnTime Job计算下一次执行时间的逻辑
2019-05-08 v2.0.4
- 升级 puppeteer 版本v1.15.0
- 重写序列化和反序列化过程,解决大对象序列化失败的问题
由于这项更改,如果需要继续使用旧的 queueCache.json 中保存的运行状态,可参考如下方案对这个文件进行升级
在 @Launcher tasks 中引入 UpgradeQueueCacheTask
将旧的 queueCache.json 更名为 queueCache_old.json,放到 workplace 目录下
启动一次 app,将在 workplace 目录下生成 queueCache.txt
在 @Launcher tasks 中移除 UpgradeQueueCacheTask
2019-04-29 v2.0.3
- ui界面切换tab页时,不销毁之前的tab页
- 修复bug: PuppeteerUtil.links 传递 Regex 参数时获取不到连接
- 修复bug: nedb 在压缩数据过程中,采用字符串拼接的方式来构建新的数据内容, 当数据量较大时,会出现内存溢出
2019-04-29 v2.0.2
- 使用ansi-colors输出彩色日志
2019-04-22 v2.0.1
- 增加 RequestUtil,将request封装为promise风格的调用方式
- 修改NedbHelperUi.defaultSearchExp的声明方式,避免ts编译过程中报错
2019-04-04 v2.0.0
- QueueManager 中同一个队列的多个任务线程不再共用一个等待间隔
- QueueManager 在执行一个任务过程中,可以强行中断一个任务的执行(UI Job面板提供交互按钮)
代码的方式appInfo.eventBus.emit(Events.QueueManager_InterruptJob, JOB_ID, "your interrupt reason"); - 运行过程中可以保存运行状态
- 新增 @Bean @Autowired 装饰器,提供依赖注入的编程方式
- 新增 @DataUi @DataUiRequest 装饰器,提供自定义UI tab页的功能,用户可以自定义数据可视化页面、可交互工具
2019-01-28 v0.1.22
- 自动清除标记为 filtered 的job记录
- 在UI中的Job面板,可以搜索任务,点击状态为失败或成功的任务后面的按钮,可以将这个job重新加入队列.
2018-12-24 v0.1.21
- 任务增加超时时间的配置,默认 300000ms
- 任务执行过程中记录日志,方便分析执时间和失败原因
2018-12-10 v0.1.20
- 修复用户定义的 Task 实例重复生成的bug
2018-11-19 v0.1.19
- 修复 logger 打印 Error 始终为 {} 的问题
- UI界面搜索添加条件时,如果是选择类型的,则采用checkbox可勾选多项的方式
- 更新puppeteer版本
2018-09-19 v0.1.18
- 把代码中对 index.ts 中导出类的引用地址改为原路径,这样在编辑器中用户更容定位到源代码位置
- 任务报错时打印任务的具体信息
- 任务失败次数只统计重复尝试失败后的次数
- logger 打印日志的几个方法的参数列表改为不定项参数列表,不再接受 format 参数(format 只能统一设定),不定参数列表作为消息列表,消息之间自动换行; logger 在打印日志时,如果参数是 object 类型,自动采用 JSON.stringify(obj, null, 4) 将 obj 转换为字符串
- OnStart, OnTime, FromQueue 三种任务的参数配置增加可选属性 exeIntervalJitter,类型为 number,单位为毫秒, 让任务执行间隔在 (exeInterval - exeIntervalJitter, exeInterval + exeIntervalJitter) 范围内随机抖动, 不设置时默认 exeIntervalJitter = exeInterval * 0.25
- 为三种任务的 config 增加属性 running,用于控制这个队列是否暂停工作,默认为 true, 可通过 mainMessager.emit(MainMessagerEvent.QueueManager_QueueToggle_queueName_running, queueNameRegex: string, running: boolean) 来更改多个队列的工作情况
- JobManager 和 nedb 相关的代码使用 NedbDao 重写
- 增加装饰器 @RequestMapping, 用于声明 HTTP rest 接口,提供远程动态添加任务的能力,返回抓取结果需要自行实现(例如异步url回调)
2018-08-24 v0.1.17
- ui 任务详情弹框中增加递归查询父任务的功能,所有连接的改为 target="_blank"
- 系统的实时信息推送方式由 周期推送 改为 事件驱动延迟缓存推送
- 更新 puppeteer 版本为 1.7.0
- 增加 NoneWorkerFactory , 不需要显式手动实例化 ,用于处理不需要使用 puppeteer 的任务
- logger 时间戳 SSS 格式化 0 补位
- 可以创建url为空字符串的任务
2018-07-31 v0.1.16
- 修复无法设置 maxParallelConfig=0 的bug
- 更新 puppeteer 版本为 1.6.1-next.1533003082302, 临时修复 puppeteer 1.6.1 的 response 丢失的bug
2018-07-30 v0.1.15
- 修改 PuppeteerUtil.addJquery 方法的实现
调整jQuery的注入方式,因为有一些网站因为安全原因
无法通过 page.addScriptTag 注入 - 修复 PuppeteerWorkerFactory.exPage 计算js执行错误位置的bug
- 修复 CronUtil.next 的bug:
OnTime队列最后一个任务(记为A)执行之后,立即添加的OnTime任务中第一个任务的执行时间和A执行时间可能重复
2018-07-27 v0.1.14
- logger打印添加等级判断, 增加修改配置的方法, @Launcher 中增加日志配置
- DefaultJob datas 方法参数可选
- 在 PuppeteerWorkerFactory 中对 get 方法创建的 Page 实例的
$eval, $ $eval, evaluate, evaluateOnNewDocument, evaluateHandle 几个方法进行切面增强, 当注入的js执行出现异常时能够打印出具体的位置 - 对序列化的实现方式做更改
- 源代码添加中文注释(英文后续补上)
- 更新 Puppeteer 版本
2018-07-24 v0.1.13
- 增加 logger 工具类,引入 source-map-support,用于在输出错误信息和日志时,能正确输出原ts文件的位置
2018-07-23 v0.1.12
- 实现 @Transient 字段装饰器,用于在序列化时忽略该字段
2018-07-19 v0.1.11
- 系统关闭等待任务的最长时间改为 60秒 ,之后仍未完成的任务认为执行失败, 并重新添加到队列
- 修复图片下载过程中url匹配不正确的问题
2018-07-16 v0.1.8
- 重写序列化和反序列化,解决对象循环依赖的问题