Enabling semantic search on user-specific data is a multi-step process that includes loading, transforming, embedding and storing data before it can be queried.
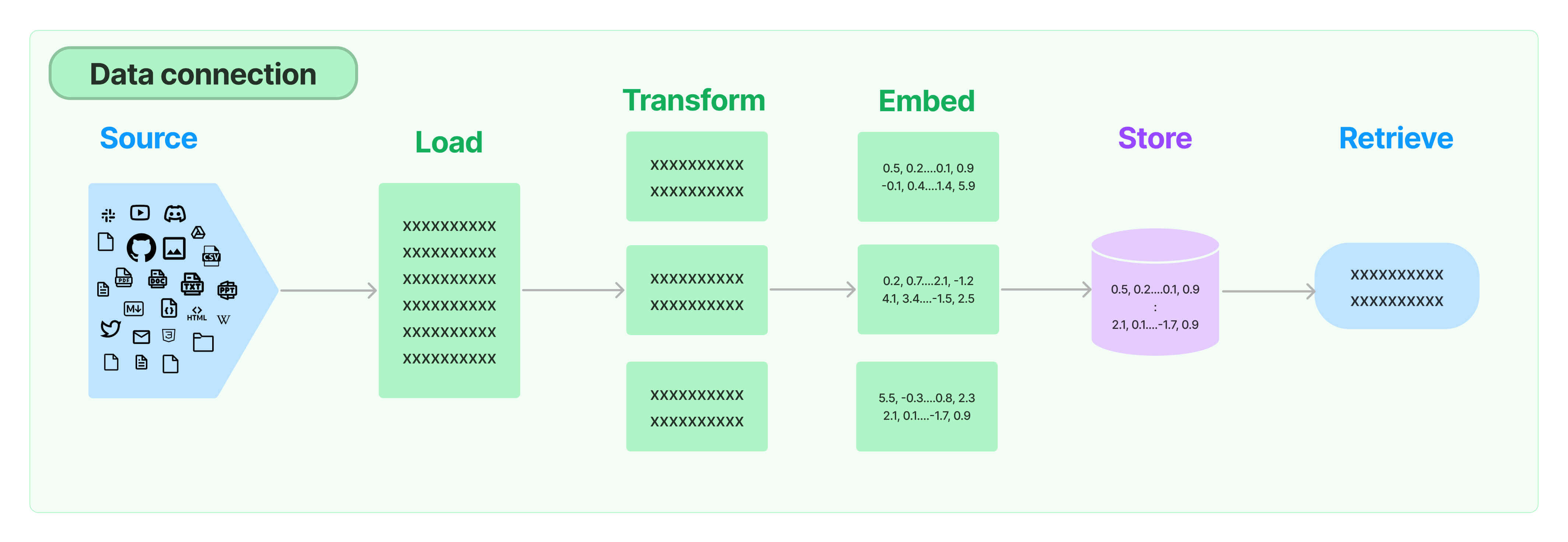
That graphic is from the team over at LangChain, whose goal is to provide a set of utilities to greatly simplify this process.
In this tutorial, we'll walk through each of these steps, using MongoDB Atlas as our Store. Specifically, we'll use the AT&T and Bank of America Wikipedia pages as our data source. We'll then use libraries from LangChain to Load, Transform, Embed and Store:

Once the source is store is stored in MongoDB, we can retrieve the data that interests us:

- MongoDB Atlas Subscription (Free Tier is fine)
- Open AI API key
- Get the code:
git clone https://github.com/wbleonard/atlas-langchain.git- Update params.py with your MongoDB connection string and Open AI API key.
- Create a new Python environment
python3 -m venv env- Activate the new Python environment
source env/bin/activate- Install the requirements
pip3 install -r requirements.txt- Load, Transform, Embed and Store
python3 vectorize.py- Retrieve
python3 query.py -q "Who started AT&T?"There's no lacking for sources of data: Slack, YouTube, Git, Excel, Reddit, Twitter, etc., and LangChain provides a growing list of integrations that includes this list and many more.
For this exercise, we're going to use the WebBaseLoader to load the Wikipedia pages for AT&T and Bank of America.
from langchain_community.document_loaders import WebBaseLoader
# Step 1: Load
loaders = [
WebBaseLoader("https://en.wikipedia.org/wiki/AT%26T"),
WebBaseLoader("https://en.wikipedia.org/wiki/Bank_of_America")
]
docs = []
for loader in loaders:
for doc in loader.lazy_load():
docs.append(doc)Now that we have a bunch of text loaded, it needs to be split into smaller chunks so we can tease out the relevant portion based on our search query. For this example we'll use the recommended RecursiveCharacterTextSplitter. As I have it configured, it attempts to split on paragraphs ("\n\n"), then sentences("(?<=\. )"), then words (" ") using a chunk size of 1000 characters. So if a paragraph doesn't fit into 1000 characters, it will truncate at the next word it can fit to keep the chunk size under 1000 chacters. You can tune the chunk_size to your liking. Smaller numbers will lead to more documents, and vice-versa.
# Step 2: Transform (Split)
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0, separators=[
"\n\n", "\n", r"(?<=\. )", " "], length_function=len)
docs = text_splitter.split_documents(docs)Embedding is where you use an LLM to create a vector representation text. There are many options to choose from, such as OpenAI and Hugging Face, and LangChang provides a standard interface for interacting with all of them.
For this exercise we're going to use the popular OpenAI embedding. Before proceeding, you'll need an API key for the OpenAI platform, which you will set in params.py.
We're simply going to load the embedder in this step. The real power comes when we store the embeddings in Step 4.
# Step 3: Embed
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(openai_api_key=params.OPENAI_API_KEY)You'll need a vector database to store the embeddings, and lucky for you MongoDB fits that bill. Even luckier for you, the folks at LangChain have a MongoDB Atlas module that will do all the heavy lifting for you! Don't forget to add your MongoDB Atlas connection string to params.py.
# Step 4: Store
from pymongo import MongoClient
from langchain_mongodb.vectorstores import MongoDBAtlasVectorSearch
client = MongoClient(params.MONGODB_CONN_STRING)
collection = client[params.DB_NAME][params.COLL_NAME]
# Insert the documents in MongoDB Atlas with their embedding
docsearch = MongoDBAtlasVectorSearch.from_documents(
docs, embeddings, collection=collection, index_name=index_name
)The final step before we can query the data is to create a search index on the stored embeddings.
If you're on Atlas dedicated compute, Langchain can do this for you.
# Step 5: Create Vector Search Index
# THIS ONLY WORKS ON DEDICATED CLUSTERS (M10+)
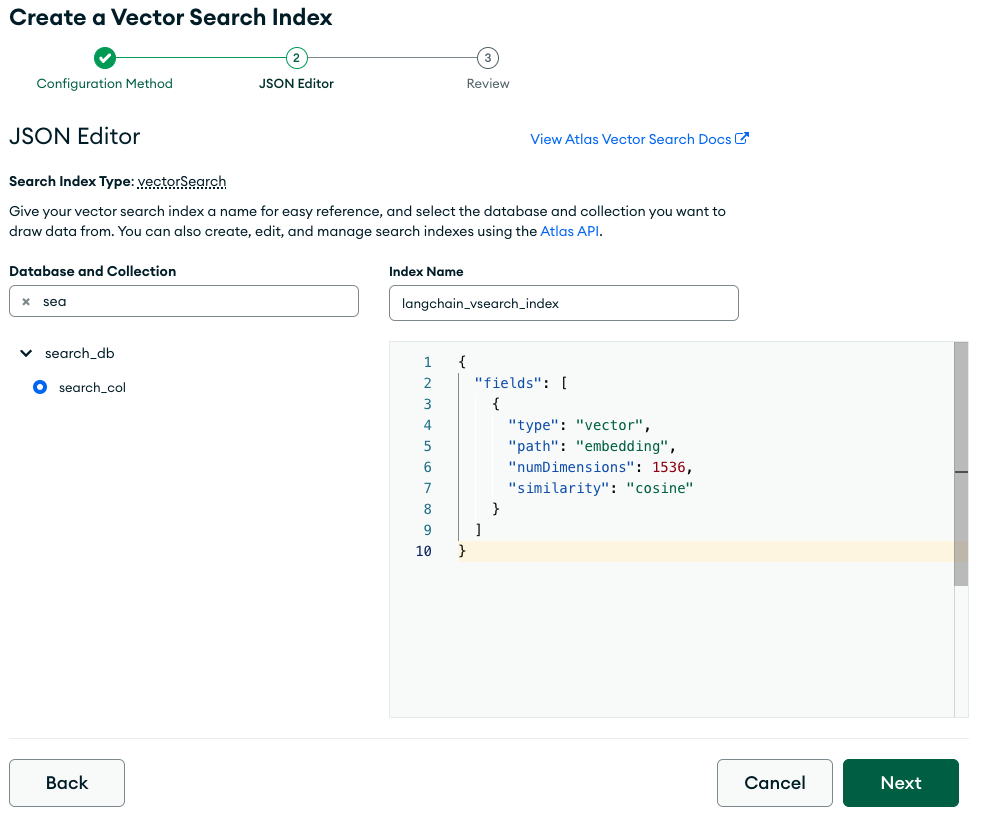
docsearch.create_vector_search_index(dimensions=1536, update=True)If you are on shared compute (M0, M2 or M5), in the Atlas console, create a Atlas Vector Search langchain_vsearch_index with the following definition:
{
"fields": [
{
"type": "vector",
"path": "embedding",
"numDimensions": 1536,
"similarity": "cosine"
}
]
}
You'll find the complete script in vectorize.py, which needs to be run only once or when new data sources are added.
python3 vectorize.pyWe could now run a search, using methods like similirity_search or max_marginal_relevance_search and that would return the relevant slice of data, which in our case would be an entire paragraph. However, we can continue to harness the power of the LLM to contextually compress the response so that it more directly tries to answer our question.
from pymongo import MongoClient
from langchain_mongodb.vectorstores import MongoDBAtlasVectorSearch
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
# Initialize MongoDB python client
client = MongoClient(params.MONGODB_CONN_STRING)
collection = client[params.DB_NAME][params.COLL_NAME]
# initialize vector store
vectorStore = MongoDBAtlasVectorSearch(
collection, OpenAIEmbeddings(openai_api_key=params.OPENAI_API_KEY), index_name=params.INDEX_NAME
)
# perform a search between the embedding of the query and the embeddings of the documents
print("\nQuery Response:")
print("---------------")
docs = vectorStore.max_marginal_relevance_search(query, K=1)
#docs = vectorStore.similarity_search(query, K=1)
print(docs[0].metadata['title'])
print(docs[0].page_content)
# Contextual Compression
llm = OpenAI(openai_api_key=params.OPENAI_API_KEY, temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=vectorStore.as_retriever()
)python3 query.py -q "Who started AT&T?"
Your question:
-------------
Who started AT&T?
AI Response:
-----------
AT&T - Wikipedia
"AT&T was founded as Bell Telephone Company by Alexander Graham Bell, Thomas Watson and Gardiner Greene Hubbard after Bell's patenting of the telephone in 1875."[25] "On December 30, 1899, AT&T acquired the assets of its parent American Bell Telephone, becoming the new parent company."[28]