There are several projects in this repository, which work in sync to execute this classifier pipeline. Order of execution is as follows -
- news-generator
- news-producer (also needs ZK + Kafka)
- news-consumer (also needs mongodb)
- model-trainer
- model-prediction
The diagram representing the architecture is as below -
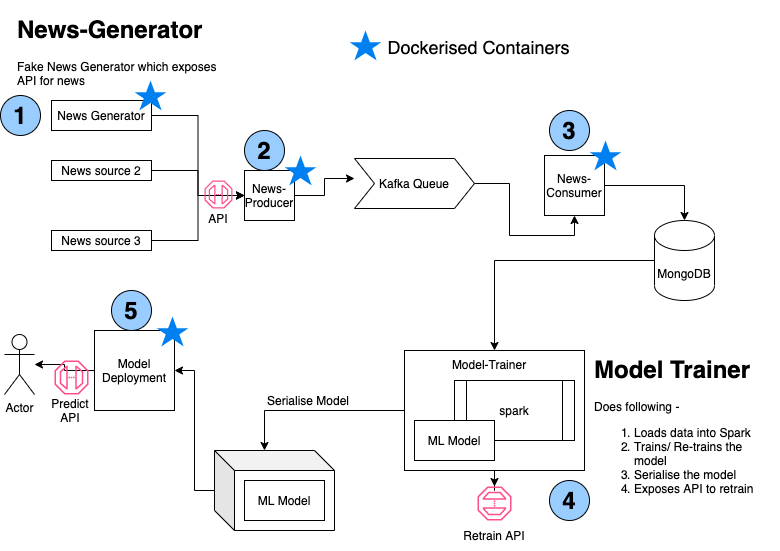
- This project is a fake news generator. This has a corpus of news, and it exposes the news as API.
- API documentation is automatically created using OpenAPI specs, once the project is hosted.
- This project consumes news from multiple sources, and pushes them to a kafka queue. Steps to setup kafka queue are in the README.md file of this project.
- As a proof of concept, It consumes the API from news-generator, in addition to rapidapi freenews
- It executes ALL news sources APIs independently as scheduled actors, with independent scheduling timeframe.
- This project consumes the "news feed" from kafka queue and pushes it to mongo DB for persistance
- This project loads the data from mongo DB into spark dataframe
- Uses this spark dataframe to train a Logistic Regressor (as classifier)
- persists the trained model and the pipeline
- Exposes an API for re-training the model based on new data
- Loads the trained model from storage
- Exposes an API for for prediction and returns the response
Setup requires following -
- docker + docker-compose/ dockercli + minikube + kubectl are installed
- kafka and zookeeper need to be setup. docker-compose script also has provision for containers of these, however, if running on a local machine, use them as services instead of containers.
- pyspark uses in-memory setup (to conserve memory on local machine), however the docker-compose file has necessary provision to setup spark cluster as well.
- Also added along is a POSTMAN project used for the APIs. Only change the IPs when trying them out!
Execution requires following -
- ensure advertised listener IP for kafka broker is present in server.properties of kafka, and is same as host machine IP.
- Run Zookeeper + Kafka and setup a topic (instructions are documented in News-Producer README.md)
- Change the volume mapping for model-prediction section to appropriate folder, and run docker-compose using following command -
HOST_IP=<<host machine ip>> docker-compose.yml up -d. This runs following projects - 3.1 news-generator 3.2 mongodb 3.3 news-producer 3.4 model-prediction 3.5 ZK (COMMENTED OUT - WON'T RUN, but can be uncommented if machine has sufficient memory allocated to docker) 3.6 Kafka (COMMENTED OUT - WON'T RUN, but can be uncommented if machine has sufficient memory allocated to docker) 3.7 Spark Master + Worker (COMMENTED OUT - WON'T RUN, but can be uncommented if machine has sufficient memory allocated to docker) 3.8 model-trainer (COMMENTED OUT - WON'T RUN, but can be uncommented if machine has sufficient memory allocated to docker) - run model-trainer as a service, and hit ${HOST_IP}:8000/retrain to persist a model and model pipeline
- Classifier is ready - use REST client (like postman) for prediction. Refer to README.md of model-prediction to understand how to access API specs
For any queries, reach out to Utkarsh Srivastava utkarshsrivastava.aiml@gmail.com
Lot can be improved!! Happy to discuss on this point
| Branch | Version | Release Date |
|---|---|---|
| Version 1 - basic structure | 1.0 | 2021-09-05 |
| Version 2 - dockerization, API exposure | 2.0 | 2021-09-08 |