English | 简体中文
高性能&高定制化的Tumblr下载工具。
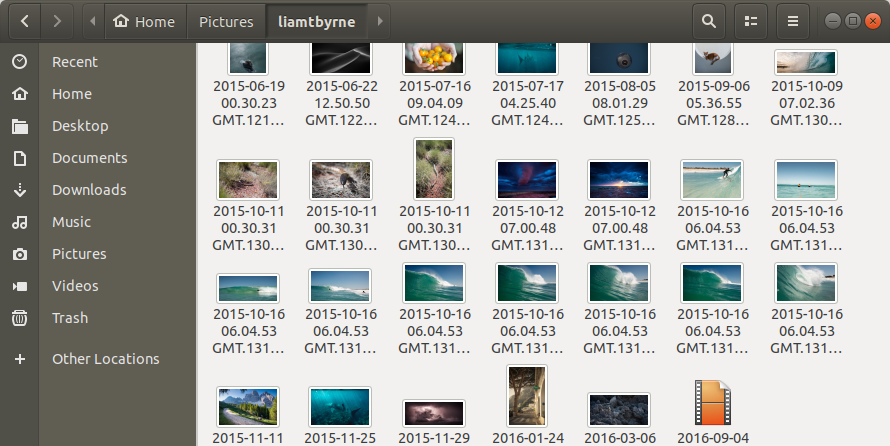
- 丰富的命令行。
- 支持多线程下载。
- 确保文件完整性。
- 支持自定义文件名格式。
- 支持同时处理多个tumblr站点。
- 兼容Python2和Python3。
$ git clone git@github.com:tzw0745/tumblr-crawler-cli.git
$ cd tumblr-crawler-cli
$ pip install -r requirements.txt # -i https://pypi.tuna.tsinghua.edu.cn/simple/
$ python tumblr-crawler.py --help大陆用户推荐使用清华大学TUNA的pypi源以提高pip的安装速度;
注意: 如果想使用socks代理,需要再安装一个第三方模组:pySocks
$ pip install pySocksusage: tumblr-crawler.py [-h] [-p] [-v] [-d SAVE_DIR] [-f FN_FMT] [-x PROXY]
[-n THREAD_NUM] [--min MIN_SIZE] [--overwrite]
[--interval INTERVAL] [--retries RETRIES]
sites [sites ...]
Crawler Tumblr Photos and Videos
positional arguments:
sites tumblr sites
optional arguments:
-h, --help show this help message and exit
-p, --photo whether to download photo
-v, --video whether to download video
-d SAVE_DIR, --dir SAVE_DIR
download file save directory
-f FN_FMT, --format FN_FMT
filename format
-x PROXY, --proxy PROXY
http request agent, support http/socks
-n THREAD_NUM, --thread THREAD_NUM
number of download threads, default is 5
--min MIN_SIZE minimum size of downloaded files, default is 0k
(unlimited)
--overwrite overwrite file (if it exists)
--interval INTERVAL http request interval, default is 0.5 (seconds)
--retries RETRIES http request retries, default is 3- 下载Tumblr @liamtbyrne和@lizclimo上所有的图片和视频:
$ python tumblr-crawler.py liamtbyrne lizclimo- 指定下载文件类型:
$ python tumblr-crawler.py -p liamtbyrne # 只下载图片
$ python tumblr-crawler.py --video liamtbyrne # 只下载视频- 下载文件到其它文件夹:
$ python tumblr-crawler.py -d /somedir/ liamtbyrne- 设置文件名格式:
$ python tumblr-crawler.py -f "{date:%Y-%m-%d %H.%M.%S} GMT.{post_id}.{uid}" liamtbyrne # 默认
$ python tumblr-crawler.py --format {uid} liamtbyrne第一个例子下载文件的名称:"2015-10-16 06.04.53 GMT.13126.5pzVb1s7wpcjo10.jpg" 第二个例子下载文件的名称:"5pzVb1s7wpcjo10.jpg"
{uid}是必须的,其它可选参数包括:
{post_id}:tumblr post id, 类似13126;{type}:video或photo;{date}:tumblr post的时间日期,支持详细设定;{timestamp}:unix时间戳,比如1541405838。
- 设置网络代理:
$ python tumblr-crawler.py --proxy http://127.0.0.1:1080 liamtbyrne # http proxy
$ python tumblr-crawler.py -x socks5h://127.0.0.1:1080 liamtbyrne # socket5 proxy- 设置更多下载线程以提高下载速度:
$ python tumblr-crawler.py -n 20 liamtbyrne- 只希望下载超过一定大小的文件:
$ python tumblr-crawler.py --min 0.5m liamtbyrne # 只下载超过512k的文件
$ python tumblr-crawler.py --min 100k liamtbyrne # 只下载超过100k的文件- 配置文件。
- ……
- 2018年12月17日:
- 增加图片url兼容性。
- 2018年12月05日:
- 支持inline格式图片url。
- 2018年11月05日:
- 增加文件名格式设置。
- 2018年10月09日:
- 修改命令行参数。
- 2018年10月06日:
- 增加最小文件体积设置。
- 2018年10月04日:
- 异步&多线程解析tumblr站点;
- 优化代码结构;
- 修改命令行参数。
- 2018年10月03日:
- 优化媒体文件提取兼容性。
- 2018年09月29日:
- 使用临时文件机制以确保文件被完整下载;
- 程序结束时提示文件总数;
- 修复命令行参数BUG;
- 修复多线程BUG。
- 2018年09月28日:
- 第一个版本。