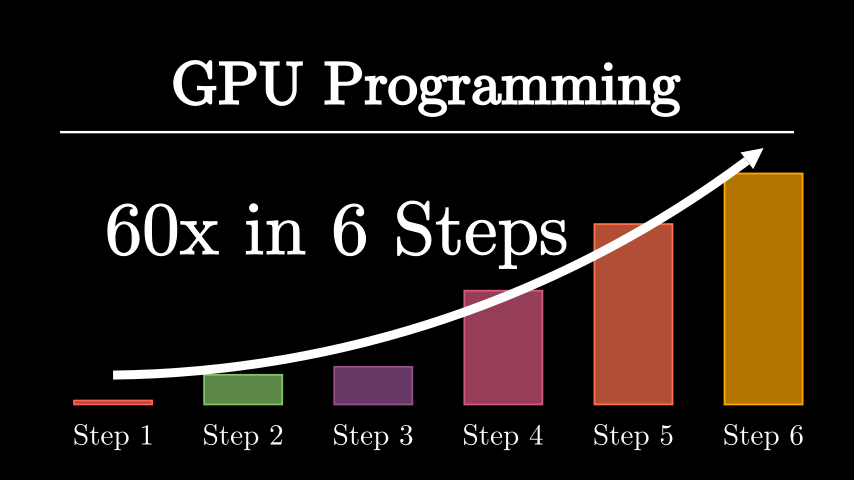
Accelerated General (FP32) Matrix Multiplication. Tested on NVIDIA RTX 3090 using Ubuntu 24.04.1 LTS with nvidia-driver-550 and CUDA 12.4.
Watch the YouTube video (click the image below)
- Eigen 3.4.0 (Put it in
lib)
Compile: make 00a_benchmark_cpu.out
Execute: ./00a_benchmark_cpu.out
Compile: make 00b_benchmark_cuBLAS.out
Execute: ./00b_benchmark_cuBLAS.out
Compile: make 01_benchmark_naive.out
Execute: ./01_benchmark_naive.out
Compile: make 02_benchmark_coalesced.out
Execute: ./02_benchmark_coalesced.out
Compile: make 03_benchmark_tiled.out
Execute: ./03_benchmark_tiled.out
Compile: make 04_benchmark_coarse_1d.out
Execute: ./04_benchmark_coarse_1d.out
Compile: make 05_benchmark_coarse_2d.out
Execute: ./05_benchmark_coarse_2d.out
Compile: make 06_benchmark_coarse_2d_vec.out
Execute: ./06_benchmark_coarse_2d_vec.out