Data Serving Results
- All numbers using the Huawei ARM server. Clients and servers pinned to separate NUMA nodes, all DVFS off.
- 16 GB dataset (all scripts found in this repo)
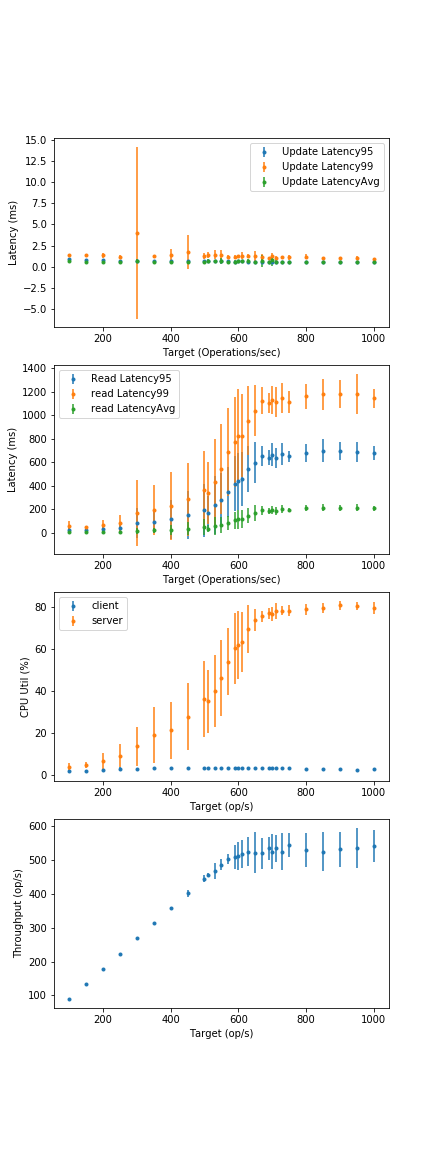
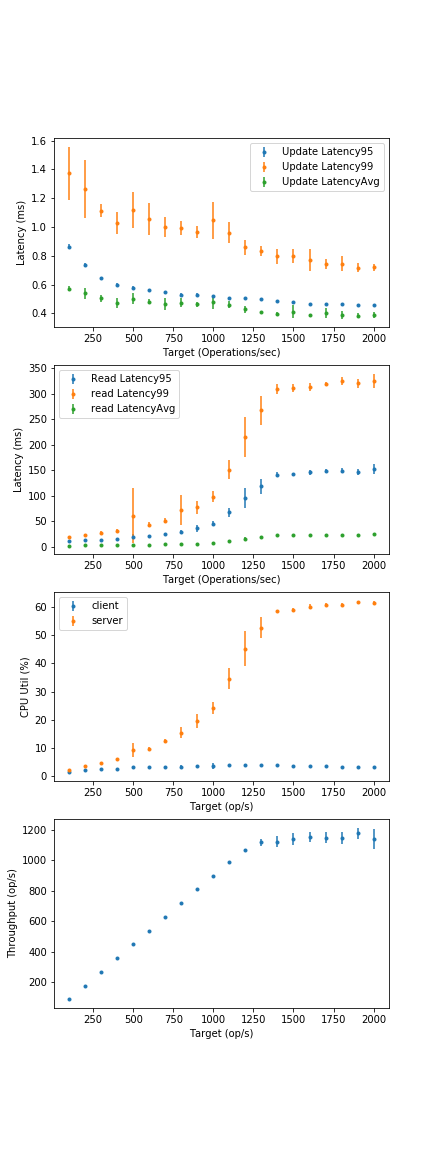
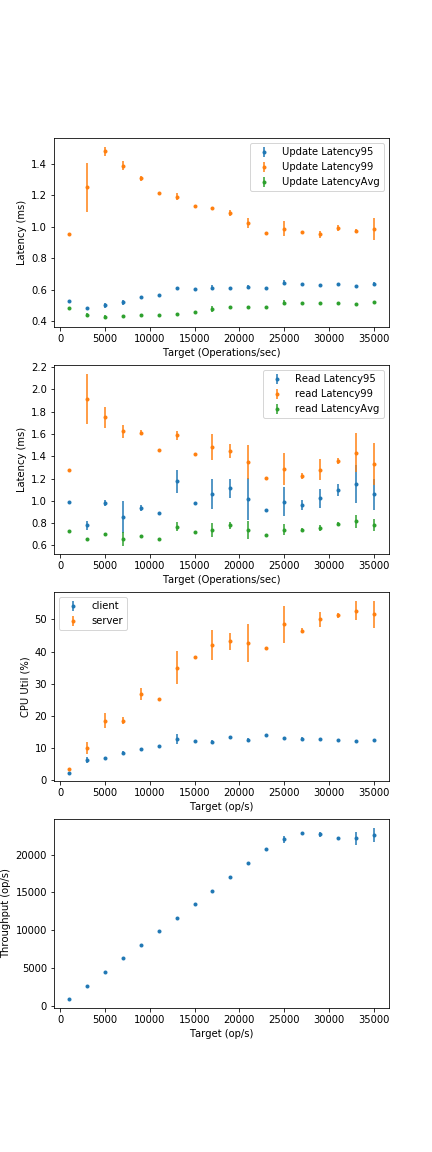
- What are the avg. and 99th percentile latencies for a fully-in-memory configuration at full CPU load? (Not realistic operation point, use a different piece of software if you want in-memory).
- From 40GB graphs, est. avg. latency: < 1ms, tail still not seen.
- What are the avg. and 99th percentile latencies for a "bigger-than-memory" configuration at full CPU load? (Experiment with buffer cache size, other Cassandra parameters on CS3 webpage).
- From 20GB graphs, estimate avg latency: 25-30ms. Tail latency: 300-500ms.
- How to get more load into the 16c configurations? Right now we saturate about 60% server utilization.
- need more client cores. Right now, bottlenecked by client-side queueing.
- Use more physical servers?
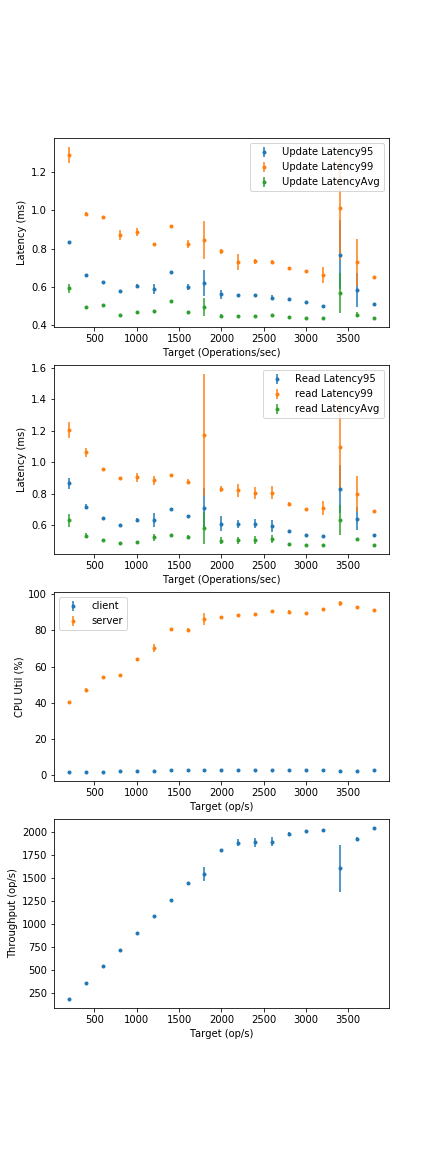
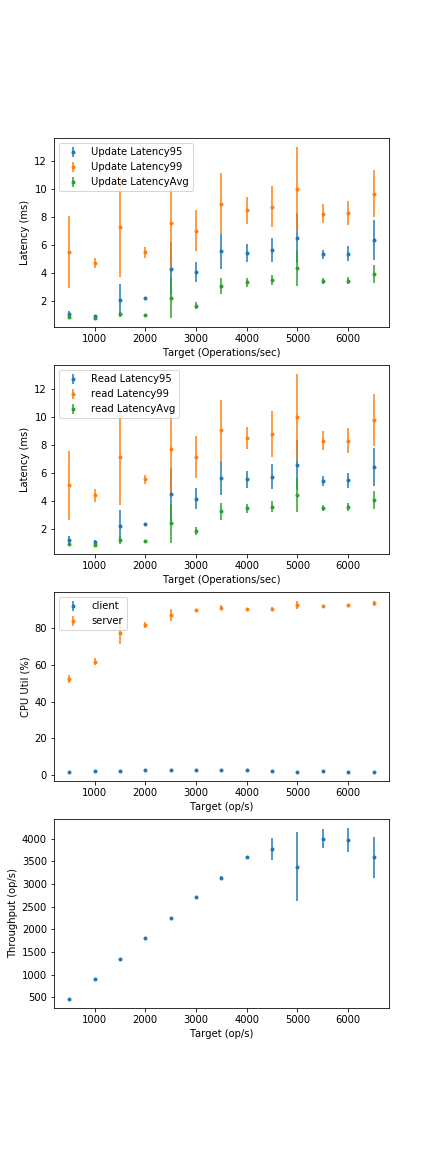
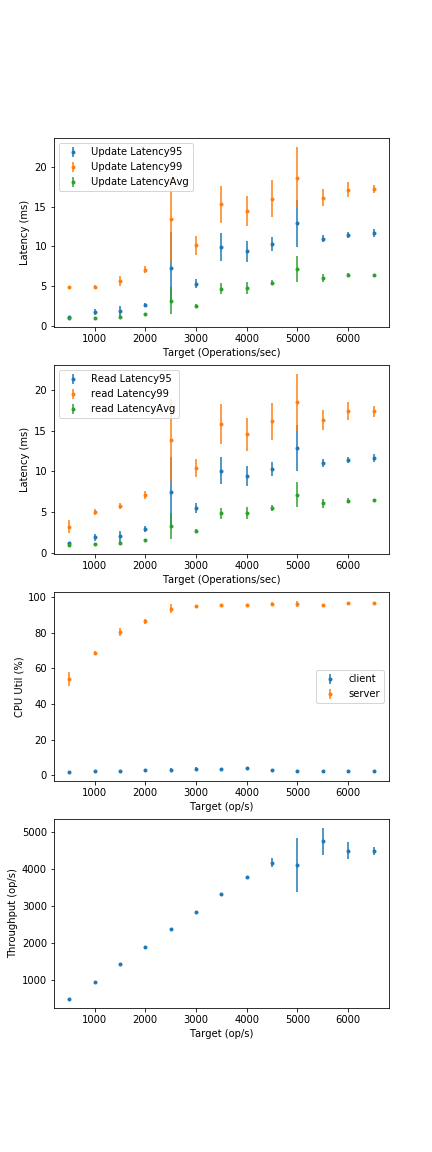
(All questions based on the 30 thread graph, since we actually begin to see server-side queueing there, which is representative behaviour)
- What are the avg. and 99th percentile latencies for a "bigger-than-memory" configuration at full CPU load? (Experiment with buffer cache size, other Cassandra parameters on CS3 webpage). What is the attained throughput?
- Rerun the 30 client thread exp. with a scaled-down memory/core ratio (use AWS or Google Compute Cloud as a baseline).
- How many server CPU cores need to be added before 30 client threads cannot reach 100% utilization?