This is a collection of real-world sample WFDownloader scripts in order to show how to program the WFDownloader software. The software supports scripting as a means to enable you support new websites on it. Note that some of the scripts may already be outdated by the time you view them. It is not a goal to keep the scripts up-to-date.
To program or write a script in the software read this introduction tutorial. Alternatively, you can watch this video introduction.
The sample scripts can be found in this folder and have been used on real websites as you can see from their names. Some are simple and just 2-3 lines of code while others could be 50 or more. It depends on the complexity of the site. In order to try any of the scripts
- Open the script for a particular site
- Copy the script and paste it into the editor in the software.
- Test it against real links of that site to see how it works or modify it to do what you want.
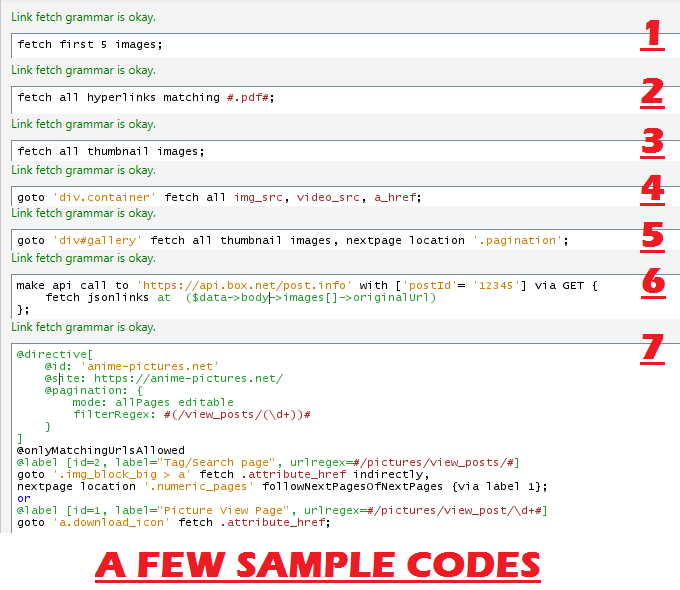
This is an image from the intro tutorial that shows the basic syntax of wfdownloader script.
Site example 1: cyberdrop.me found here
goto 'a.image' fetch .attribute_href customsubfolder pagetitle;
Site example 2: imagetwist.com found here
@label[id=2, label="gallery page", urlregex=#/p/#]
goto '.gallery' fetch a_href indirectly, nextpage location '.paging' followNextPagesOfNextPages {via label 1};
or
@label[id=1, label="image page", urlregex=#://[^/]+/(?!p/)\w+#]
goto 'img.pic' fetch .attribute_src;
Site example 3: acidimg.cc found here
goto 'img.centred' fetch .attribute_src
else goto 'form' submit htmlform {
goto 'img.centred' fetch .attribute_src
};
Site example 4: streamable.com found here
fetch all video_src;
You can find over a hundred of the above sample scripts here.
Here are a few sample WFDownloader scripts for pages that require scrolling down to see more content, also known as infinite scroll pages. You copy and edit them as you wish.
Infinite scroll example 1 - pdf download/link mode. Explanation here
The WFDownloader script below will download pdf links while scrolling down the given page
fetch via customhandler 'infinite_scroll_browser' with
[
'searchMode' = 'link',
'filterRegex' = '.pdf',
'linkGrabMode' = 'normal'
] customsubfolder pagetitle;
Infinite scroll example 2 - css/element mode. Explanation here
The WFDownloader script below uses css selectors to determine which html elements' links are to be collected while scrolling down the page.
fetch via customhandler 'infinite_scroll_browser' with
[
'searchMode' = 'element',
'cssSelector' = 'img',
'selectorAttribute' = 'src',
'minNumOfScrolls' = '15'
'maxNumOfScrolls' = '100'
] customsubfolder pagetitle;
To learn more about scripting WFDownloader for infinite scrolling, you can start here. Each Infinite scroll example builds on the previous.
All real-world sample scripts here.
For help with this, the best way is to write an email to support [at] wfdownloader.xyz. For other ways: