We read every piece of feedback, and take your input very seriously.
To see all available qualifiers, see our documentation.
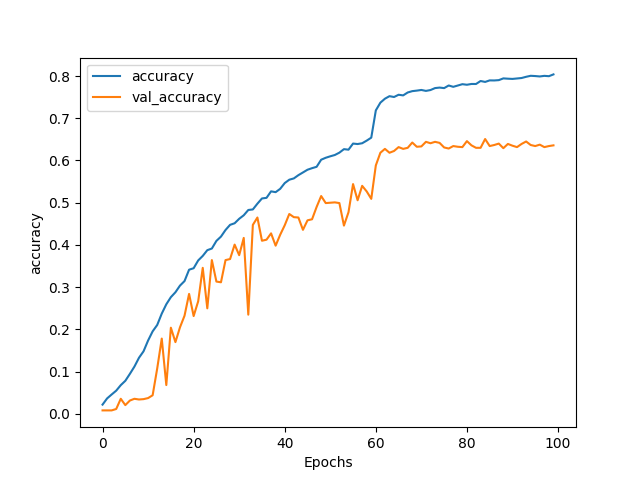
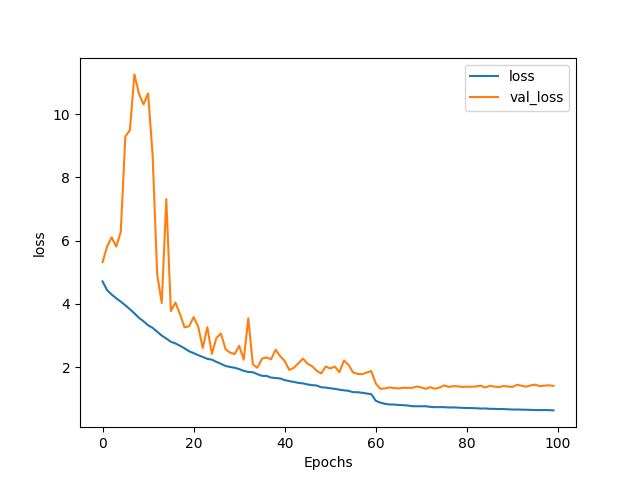
dataset: http://vision.stanford.edu/aditya86/ImageNetDogs/