
Sentiment analysis and natural language processing is a growing practice within the financial industry. Using NLP, many analysts generate their reports from textual data (ex. News articles, Twitter tweets etc) and now with “transformers,” these analyses can be powerful in understanding market volatility and momentum. However, one can argue that traditional sentiment analysis can sometimes lack in depth, as we can misconstrue written language, not being able to capture the many facets that contribute to an individual’s genuine expression that which we mark as sentiment. It is our thought that by utilizing NLP with audio feature extraction, classifying received sentiment into categories should be more realistic for “ground truth.”
Our data was self-ensembled and extracted from over 11,0000 YouTube videos and, from them we extract audio specific features. Because these YouTube videos contained over 130,000 useful sentence segements (utterances) annotating each audio individually would be a tedious task. To remedy this, we implemented an automated method that makes use of Googles BERT transformer. From the audio speech to text transcription + annotation, we then performed a series of steps that created audio sentence/phrase segments paired with its respective class. The final training/validation dataset after augmentations resulted in more than 300,000 "bullish", "bearish" and "neutral" audio signals and mel-spectrograms. By automating the process we have developed an end to end approach for audio annotation with respect to financial based speech, significantly improving workflow efficency.
We trained our data using four classical models:
- Logistic Regression
- Support Vector Classifier (SVC) x2
- XGBoost
And a few deep learning neural networks (CNNs):
- Tested: ResNet50, VGG16, EfficientNetB0 and B7
- Tested: 4 unique architectures from scratch
The notebooks in this repository contain redacted cells for privacy. The report and presentation is also password protected. If you'd like to view the full code and summaries, email me at: aranciojr@gmail.com.
- Approach
- Findings
- Future Work
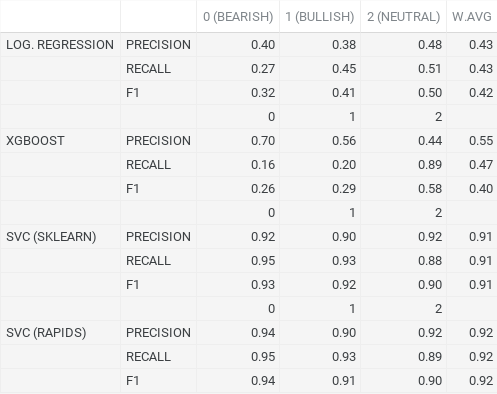
SVC models performed the best, with the accelerated version achieving a weighted avg precision, recall and f1-score of 0.94, 0.95, 0.94 respectively. The non-accelerated sklearn version scored the same in recall, however, precision was slightly lower than the accelerated version for neutral audios. Sticking with the SVC model produced using RAPIDS, it received its highest score in recall with the bearish class, correctly identifying positive cases of bearish 95% of the time. Precision (0.94) and F1 (0.94) were also the highest for the bearish class, so we were able to correctly identify bearish audios 94% of the time based off of precision and looking at F1 score, we can see that our predictions for these audios were accurate also 94% of the time. Due to the fact that we had an imbalanced dataset, class specific recall is the most important metric here and viewing the weighted average of these metrics, we can still notice a tremendous leap in performance from the other classical models we produced. Both logistic regression and XGBoost scored rather poorly in comparison.
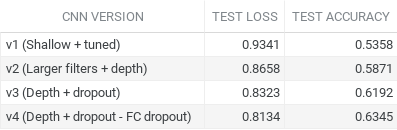
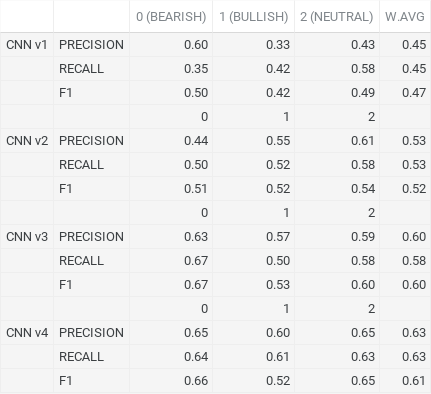
Out of our four models the last version (v4) produced the best results. It achieved a test loss of approx. 0.8134 and an accuracy of 0.6345. This was nearly a 100% increase in score from our original v1 model. The difference between the two was a drastic increase of architecture depth, where we increased the amount of Conv2D layers as well as their filter sizes. V4 also contained multiple dropout layers, each dropout placed directly after a MaxPooling block. However, going from v3 to v4 we removed the dropout layer at the end of the fully connected layer.
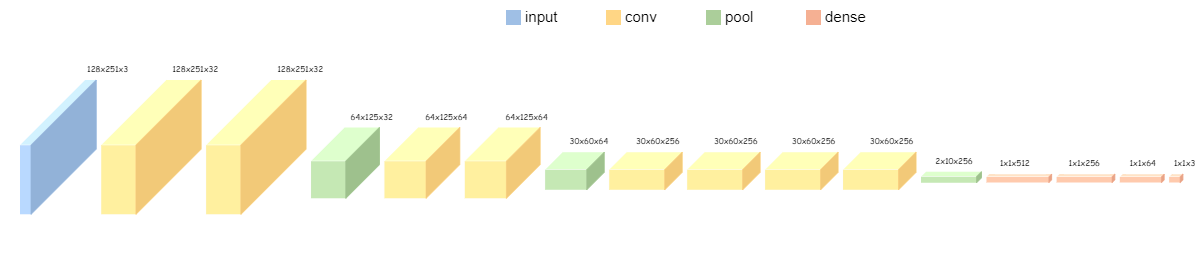
Current focus is:
- Restructure ensembled data (possibly collect more).
- Gain more balanced distribution.
- Re-evaluate augmentation approach.
- Try different feature extraction methods -evaluate results.
Longterm
- Improve CNN performance.
- Incorporate LSTM into CNN architecture for more temporal features.
- Perform blind test comparing human classification vs. machine classification.
For a more detailed explanation, read the report here.