Diagnostics
DragonRadio can be used to diagnose Colosseum anomalies by running the SCE Qualification scenario.
The SCE Qualification scenario was one of two scenarios used to qualify radios for the DARPA SC2 competition (the other scenario tested the collaboration protocol). It is a simple scenario that nonetheless exercises both the radio and the MCHEM. A full description of the scenario is available as part of the Freshdesk knowledge base. The DragonRadio tools implement the scoring mechanism proscribed by DARPA as part of the competition. Unfortunately, the document describing the scoring procedure is no longer publicly available. There were two primary scoring procedures corresponding to the final two phases of the competition, pahse 2 and phase 3.
A diagnostic run should use the following inputs:
- Radio image
dragonradio-main-20211102(available in thecommondirectory on the Colosseum). - Batch configuration file diagnostic.json
- Radio configuration diagnostic.conf
In this configuration, DragonRadio is able to consistently meet all traffic mandates and attain an almost perfect SC2 score. DragonRadio should always have a phase 2 score of 100 and a phase 3 score that is very close to 11100. At most, a few nodes will lose 1–3 phase 3 points.
The DragonRadio tools can score reservations and diagnose common problems. Common Colosseum anomalies include the following:
- Cross-talk. Reservation nodes receive transmissions from nodes that are not part of the reservation. Since DragonRadio nodes only recognize transmissions from other DragonRadio nodes, the tools will only report cross-talk from other DragonRadio nodes. Examples include the following reservations: 124672, 124671, 124664, 124663, 124640, 124639.
- Null RF channels.A node will not hear any traffic from any other node, i.e., it appears to have no RF channel. Examples include the following reservations: 126189, 126187, 126179.
- RF channel failure in later scenario stages. The SCE Qualification scenario has 5 distinct stages with different SNR levels. RF channels appear to fail for some nodes in later phases. Examples include the following reservations: 126182, 126183.
- UHD errors/failures. When UHD prints "x300 fw communication failure" to stderr, it usually indicates a faulty USRP. Nodes that produce this error often show extensive UHD errors before a failure. Examples of reservations with UHD errors/failures are 126281 and 126290.
Cross-talk should never happen, but it is reasonable to think that the RF channel problems may be due to DragonRadio bugs. However, when these problems are observed, they are completely reproducible with the same set SRNs, and the problem does not occur with other sets of SRNs. For example, in reservations 126187 and 126179, both of which use SRNs 1, 3, 4, 5, 8, 9, 10, 12, 13, and 18, node 18 never receives any packets from any other node. The same exact radio image/configuration/batch job shows a near-perfect score on other groups of SRNs.
The DragonRadio tools are packages as a docker container, available at mainland/dragontools:latest.
docker run -it --rm \
-u $(id -u):$(id -g) \
-v "/etc/passwd:/etc/passwd:ro" \
-v "/etc/group:/etc/group:ro" \
-v /colosseum/mirror:/common_logs \
-v ~/.cache:/cache \
-e DISPLAY \
-v "/tmp/.X11-unix:/tmp/.X11-unix:rw" \
mainland/dragontools:latest
The extra docker arguments have the following purposes:
- The user running the container is "imported" to the container with the
-uand first two volume mapping (-v) arguments. - Colosseum logs are mounted in the container with the
-v /colosseum/mirror:/common_logsargument. The container volume/common_logsis meant to contain logs. Logs are located at/colosseum/mirroron my machine; you should substitute the location of your logs files. - A data cache is mounted with the
-v ~/cache:/cache. The data cache is used to avoid re-computing traffic and score information. You can mount whatever directory you like as the cache. - The
-e DISPLAYand-v "/tmp/.X11-unix:/tmp/.X11-unix:rw"arguments enable graphical applications in the container. This is required for plotting scores.
There are three primary tools that can be used to diagnose reservations:
-
sc2-diagnostics. Check node connectivity, display SC2 scores, and report nodes that lost phase 3 points. -
sc2-score. Compute SC2 scores and can produce a variety of reports. See the help (-h) for descriptions of the various options. The most useful flag is--problem-flows, which shows all traffic flows that lost points ordered by number of points lost. -
plot-score. Plot SC2 scores. The--plot-soreflag will plot the Phase 3 score. -
plot-radio-metric. Plot DragonRadio metrics. The most useful flag is--evm, which shows the EVM metric reported by DragonRadio for each received packet. This can help diagnose differences in RF channels and timing differences between the RF emulator and traffic generator. -
plot-eventsPlot DragonRadio events. The most useful flag is--usrp, which plots USRP errors.
Let's run basic diagnostics on reservation 126179, which seems to have a node with no RF channels.
$ sc2-diagnostics /common_logs/RESERVATION-126179
Reservation SRNS: 1, 3, 4, 5, 8, 9, 10, 12, 13, 18
The following nodes transmitted traffic but did not receive any traffic: 18
SRN 18 did not hear from the following nodes: 1, 3, 4, 5, 8, 9, 10, 12, 13
Node 1 encountered UHD warnings
Node 3 encountered UHD warnings
Node 9 encountered UHD warnings
SRN 18 lost 2220 points
SRN 4 lost 41 points
Phase 2 score: 80/100
Phase 3 score: 8839/11100
This demonstrates that SRN 18 did not received any RF traffic. As expected, it lost a significant number of points. SRN 4 also lost an usually large number of points.
Reservation 126182 seemed to be fully connected, but some of the RF channels appeared to fail during later stages of the scenario. We'll go straight to running the sc2-score tool for this reservation.
$ sc2-score /common_logs/RESERVATION-126182 --problem-flows
Flow 5057 (Qual_3); 59 -> 58; lost 111 points (0.00%)
Flow 5058 (Qual_3); 59 -> 60; lost 111 points (0.00%)
Flow 5077 (Qual_4); 59 -> 58; lost 111 points (0.00%)
Flow 5078 (Qual_4); 59 -> 60; lost 111 points (0.00%)
Flow 5086 (Qual_5); 52 -> 59; lost 111 points (0.00%)
Flow 5095 (Qual_5); 58 -> 53; lost 111 points (0.00%)
Flow 5096 (Qual_5); 58 -> 59; lost 111 points (0.00%)
Flow 5097 (Qual_5); 59 -> 58; lost 111 points (0.00%)
Flow 5098 (Qual_5); 59 -> 60; lost 111 points (0.00%)
Flow 5017 (Qual_1); 59 -> 58; lost 3 points (97.30%)
Flow 5018 (Qual_1); 59 -> 60; lost 3 points (97.30%)
Flow 5031 (Qual_2); 56 -> 54; lost 2 points (98.20%)
Flow 5088 (Qual_5); 53 -> 54; lost 1 points (99.10%)
Flow 5089 (Qual_5); 54 -> 52; lost 1 points (99.10%)
Flow 5090 (Qual_5); 54 -> 56; lost 1 points (99.10%)
Flow 5092 (Qual_5); 56 -> 57; lost 1 points (99.10%)
Flow 5094 (Qual_5); 57 -> 58; lost 1 points (99.10%)
Phase 2 score: 91/100
Phase 3 score: 10088/11100
We can see that in stages 3, 4, and 5, node 59 has a number of issues. It's possible that nodes 52 and 58 only had trouble in stage 5 because they were communicating with a "troubled" node 59.
We can also plot the score for reservation 126182:
$ plot-score /common_logs/RESERVATION-126182 --plot-score
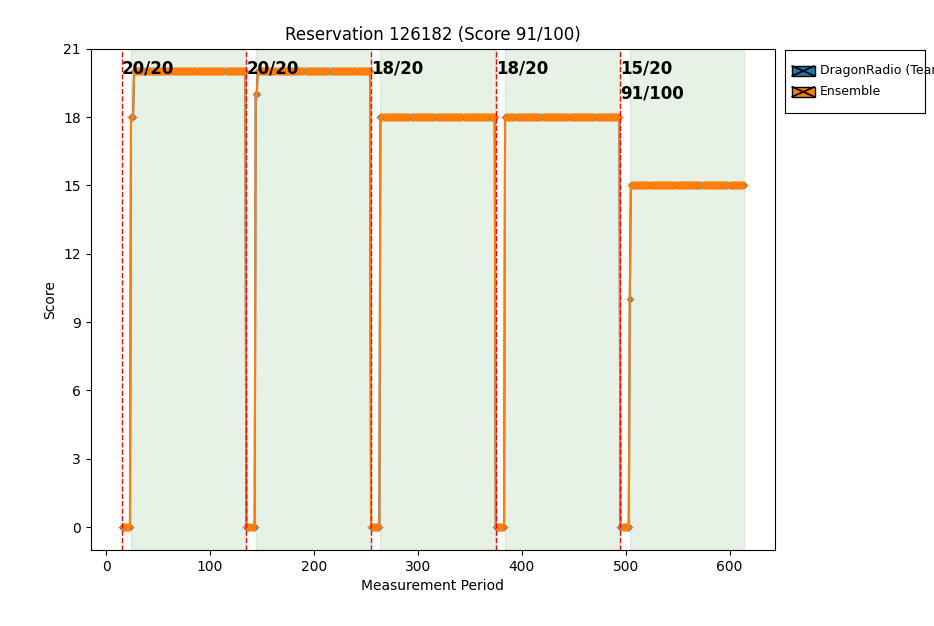
We can see that issues occur in stages 3, 4, and 5, as reported by sc2-score.
Let's dig in by looking at the reported EVM.
$ plot-radio-metric /common_logs/RESERVATION-126182 --evm
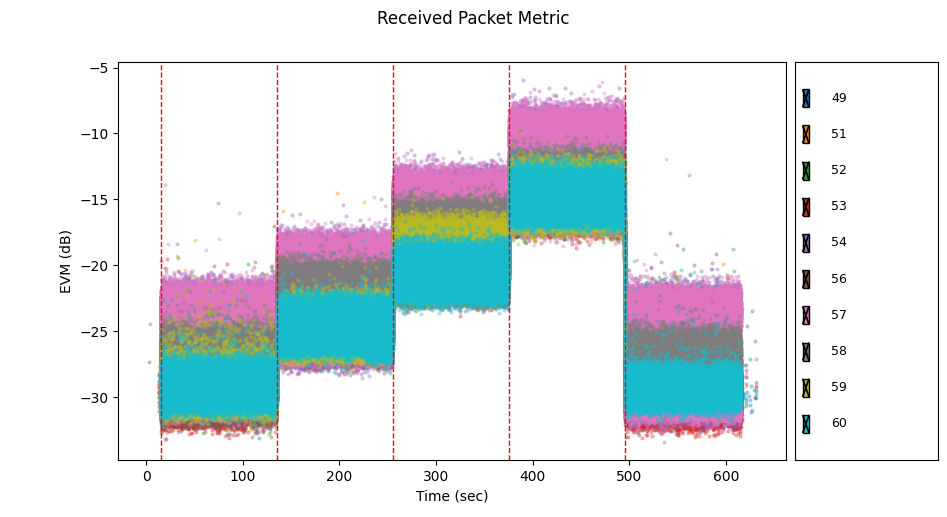
We can notice immediately that node 57 demonstrates unusually high EVM across all 5 stages of the scenario. We can click the checkboxes to show a subset of the nodes. Let's hide node 57.
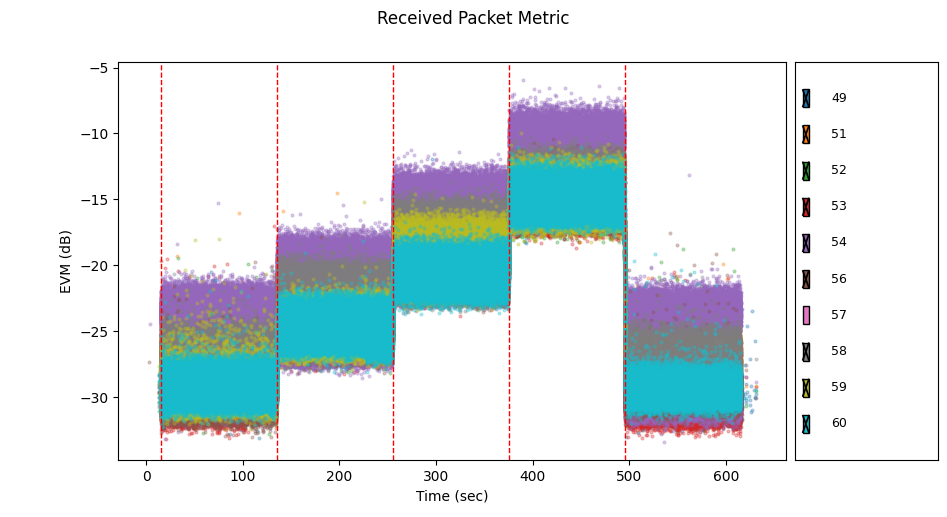
Now we see that node 54 also demonstrates unusually high EVM (it was previously obscured by node 57). Let's disable node 54 too.
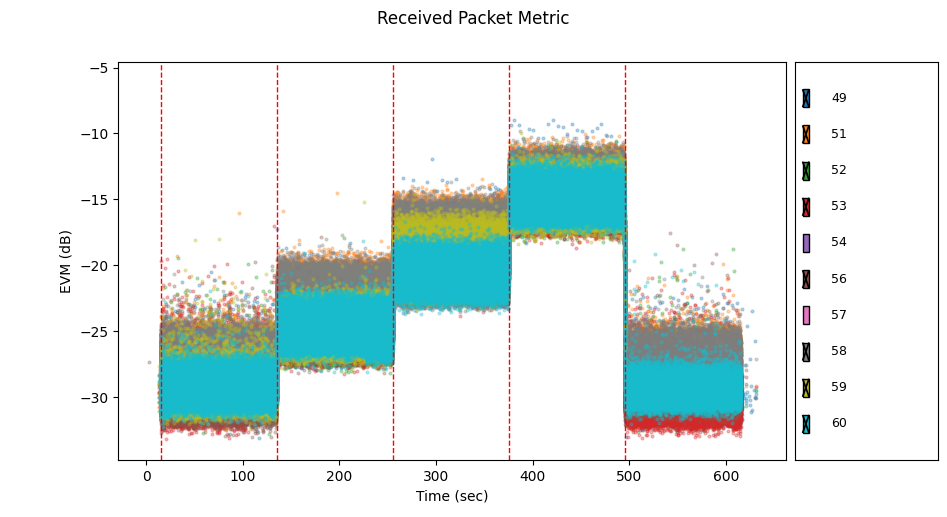
The rest of the nodes look like they have similar RF channels. Let's look at node 59 by itself.
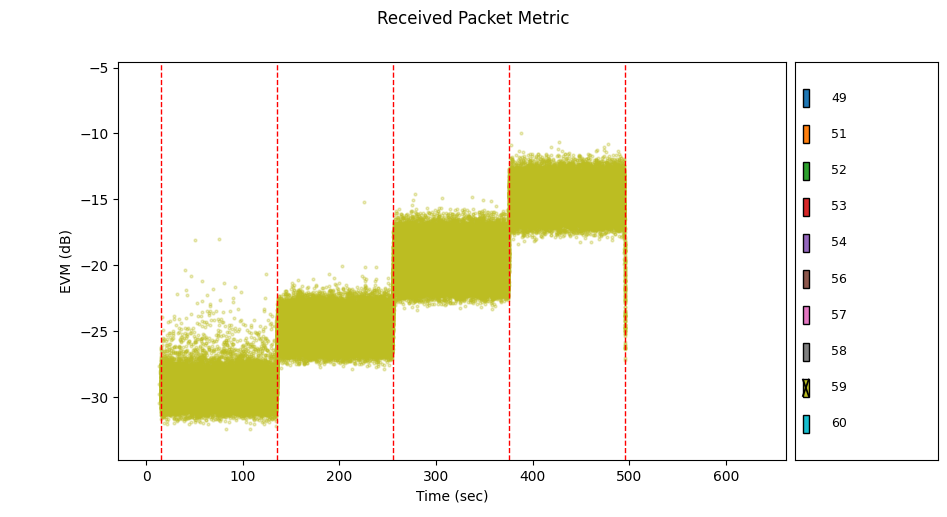
Node 59 stopped receiving any RF traffic in stage 5. No wonder nodes 52 and 58 had trouble communicating with it in stage 5.
Let's start by running the standard diagnostics on reservation 126281.
$ sc2-diagnostics /common_logs/RESERVATION-126281
Reservation SRNS: 34, 37, 38, 39, 41, 43, 44, 45, 46, 47
Node 39 encountered UHD warnings
Node 43 encountered UHD warnings
SRN 43 lost 60 points
SRN 47 lost 3 points
SRN 44 lost 1 points
SRN 38 lost 1 points
Phase 2 score: 100/100
Phase 3 score: 11035/11100
A few UHD warnings aren't out of the ordinary, but SRN 43 lost a large number of points. Let's see what's going on by plotting USRP events for all SRNs in this reservation (the --annotate flag will display the event description when we hover over an event):
$ plot-events /common_logs/RESERVATION-126181 --usrp --annotate
.png)
We see node 43 has an usually large number of USRP errors. We can zoom in:
_43.png)
ERROR_CODE_OVERFLOW errors are unusual--they indicate a hardware problem. SRN 43 has a lot of them, so its USRP is suspect. Let's look at the next reservation we ran that included SRN 43:
$ sc2-diagnostics /common_logs/RESERVATION-126290
Reservation SRNS: 34, 37, 38, 39, 41, 43, 44, 45, 46, 47
The following nodes encountered UHD errors: 43
SRN 34 did not hear from the following nodes: 38, 41, 46
SRN 37 did not hear from the following nodes: 46
SRN 43 did not hear from the following nodes: 34, 38, 41, 46
Log file /common_logs/RESERVATION-126290/dragon-radio-mainland-20220529-1d521043-srn34-RES126290/node-034/radio.h5
appears to be corrupt.
Log file /common_logs/RESERVATION-126290/dragon-radio-mainland-20220529-1d521043-srn37-RES126290/node-037/radio.h5
appears to be corrupt.
Log file /common_logs/RESERVATION-126290/dragon-radio-mainland-20220529-1d521043-srn43-RES126290/node-043/radio.h5
appears to be corrupt.
2024-12-10 13:48:21,921:root:ERROR:Could not read logs for SRN 34
2024-12-10 13:48:21,921:root:ERROR:Could not read logs for SRN 37
2024-12-10 13:48:23,057:root:ERROR:Could not read logs for SRN 43
SRN 44 missing traffic in following stages: 1,2,3,4,5
SRN 46 missing traffic in following stages: 1
SRN 47 missing traffic in following stages: 1,3,4
SRN 34 lost 2220 points
SRN 38 lost 2220 points
SRN 44 lost 2220 points
SRN 46 lost 1665 points
SRN 41 lost 1665 points
SRN 47 lost 555 points
SRN 39 lost 555 points
Phase 2 score: 0/100
Phase 3 score: 0/11100
The message "Log file...appears to be corrupt" indicates that DragonRadio node did not cleanly close its log file. This can happen when the radio crashes or when a thread hangs. The beginning of the output shows that SRN 43 had a UHD error. Looking in the stderr.log log for that SRN, we see a large number of ERROR_CODE_OVERFLOW errors as well as this:
UHD Error:
x300 fw communication failure #1
EnvironmentError: IOError: x300 fw poke32 - reply timed out
This UHD error can result from either a faulty USRP or a faulty network card connecting the SRN to the USRP. Re-flashing and/or power cycling the USRP can sometimes fix the error.