diff --git a/.github/workflows/check-all-broken-links.md b/.github/workflows/check-all-broken-links.md
new file mode 100644
index 0000000000..99f57b56df
--- /dev/null
+++ b/.github/workflows/check-all-broken-links.md
@@ -0,0 +1,17 @@
+name: Check .md README files for broken links
+
+on:
+ push: [master]
+
+jobs:
+ markdown-link-check:
+ runs-on: ubuntu-latest
+ # check out the latest version of the code
+ steps:
+ - uses: actions/checkout@v3
+
+ # Checks the status of hyperlinks in .md files in verbose mode
+ - name: Check links
+ uses: gaurav-nelson/github-action-markdown-link-check@v1
+ with:
+ use-quiet-mode: 'yes'
diff --git a/.github/workflows/check-broken-links.md b/.github/workflows/check-broken-links.md
new file mode 100644
index 0000000000..a753ec75ba
--- /dev/null
+++ b/.github/workflows/check-broken-links.md
@@ -0,0 +1,17 @@
+name: Check .md README files for broken links
+
+on: [pull_request]
+
+jobs:
+ markdown-link-check:
+ runs-on: ubuntu-latest
+ # check out the latest version of the code
+ steps:
+ - uses: actions/checkout@v3
+
+ # Checks the status of hyperlinks in .md files in verbose mode
+ - name: Check links
+ uses: gaurav-nelson/github-action-markdown-link-check@v1
+ with:
+ use-quiet-mode: 'yes'
+ check-modified-files-only: 'yes'
diff --git a/.github/workflows/test-cm-script-features.yml b/.github/workflows/test-cm-script-features.yml
new file mode 100644
index 0000000000..026c79e74d
--- /dev/null
+++ b/.github/workflows/test-cm-script-features.yml
@@ -0,0 +1,38 @@
+# This workflow will install Python dependencies, run tests and lint with a variety of Python versions
+# For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
+
+name: CM script automation features test
+
+on:
+ pull_request:
+ branches: [ "master", "dev" ]
+ paths:
+ - '.github/workflows/test-cm-script-features.yml'
+ - 'cm-mlops/**'
+ - '!cm-mlops/**.md'
+
+jobs:
+ build:
+
+ runs-on: ubuntu-latest
+ strategy:
+ fail-fast: false
+ matrix:
+ python-version: ["3.12", "3.11", "3.10", "3.9", "3.8"]
+
+ steps:
+ - uses: actions/checkout@v3
+ - name: Set up Python ${{ matrix.python-version }}
+ uses: actions/setup-python@v3
+ with:
+ python-version: ${{ matrix.python-version }}
+ - name: Install dependencies
+ run: |
+ python -m pip install cmind
+ cm pull repo --url=${{ github.event.pull_request.head.repo.html_url }} --checkout=${{ github.event.pull_request.head.ref }}
+ cm run script --quiet --tags=get,sys-utils-cm
+ - name: Test CM Script Features
+ run: |
+ python tests/script/test_install.py
+ python tests/script/test_docker.py
+ python tests/script/test_features.py
diff --git a/.github/workflows/test-cm-scripts.yml b/.github/workflows/test-cm-scripts.yml
new file mode 100644
index 0000000000..fc00a22f5a
--- /dev/null
+++ b/.github/workflows/test-cm-scripts.yml
@@ -0,0 +1,36 @@
+# This workflow will install Python dependencies, run tests and lint with a variety of Python versions
+# For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
+
+name: CM script automation test
+
+on:
+ pull_request:
+ branches: [ "master", "dev" ]
+ paths:
+ - '.github/workflows/test-cm-scripts.yml'
+ - 'cm-mlops/**'
+ - '!cm-mlops/**.md'
+
+jobs:
+ build:
+
+ runs-on: ubuntu-latest
+ strategy:
+ fail-fast: false
+ matrix:
+ python-version: ["3.12", "3.9"]
+
+ steps:
+ - uses: actions/checkout@v3
+ - name: Set up Python ${{ matrix.python-version }}
+ uses: actions/setup-python@v3
+ with:
+ python-version: ${{ matrix.python-version }}
+ - name: Install dependencies
+ run: |
+ python -m pip install cmind
+ cm pull repo --url=${{ github.event.pull_request.head.repo.html_url }} --checkout=${{ github.event.pull_request.head.ref }}
+ cm run script --quiet --tags=get,sys-utils-cm
+ - name: Test CM Script Automation
+ run: |
+ python tests/script/test_deps.py
diff --git a/.github/workflows/test-cm-tutorial-retinanet.yml b/.github/workflows/test-cm-tutorial-retinanet.yml
new file mode 100644
index 0000000000..8125920821
--- /dev/null
+++ b/.github/workflows/test-cm-tutorial-retinanet.yml
@@ -0,0 +1,35 @@
+# This workflow will install Python dependencies, run tests and lint with a variety of Python versions
+# For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
+
+name: CM tutorial retinanet
+
+on:
+ pull_request:
+ branches: [ "master", "dev" ]
+ paths:
+ - '.github/workflows/test-cm-tutorial-retinanet.yml'
+ - 'cm-mlops/**'
+ - '!cm-mlops/**.md'
+jobs:
+ build:
+
+ runs-on: ubuntu-latest
+ strategy:
+ fail-fast: false
+ matrix:
+ python-version: ["3.9"]
+
+ steps:
+ - uses: actions/checkout@v3
+ - name: Set up Python ${{ matrix.python-version }}
+ uses: actions/setup-python@v3
+ with:
+ python-version: ${{ matrix.python-version }}
+ - name: Install dependencies
+ run: |
+ python -m pip install cmind
+ cm pull repo --url=${{ github.event.pull_request.head.repo.html_url }} --checkout=${{ github.event.pull_request.head.ref }}
+ cm run script --quiet --tags=get,sys-utils-cm
+ - name: Test CM Tutorial Retinanet
+ run: |
+ python tests/tutorials/test_tutorial_retinanet.py
diff --git a/.github/workflows/test-cm-tutorial-tvm-pip.yml b/.github/workflows/test-cm-tutorial-tvm-pip.yml
new file mode 100644
index 0000000000..f4fbbe8215
--- /dev/null
+++ b/.github/workflows/test-cm-tutorial-tvm-pip.yml
@@ -0,0 +1,57 @@
+# This workflow will install Python dependencies, run tests and lint with a variety of Python versions
+# For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
+
+name: CM tutorial tvm pip install
+
+on:
+ pull_request:
+ branches: [ "master", "test" ]
+ paths:
+ - '.github/workflows/test-cm-tutorial-tvm-pip.yml'
+ - 'cm-mlops/**'
+ - '!cm-mlops/**.md'
+
+jobs:
+ test_vm_runtime:
+ runs-on: ubuntu-latest
+ strategy:
+ fail-fast: false
+ matrix:
+ python-version: ["3.9"]
+
+ steps:
+ - uses: actions/checkout@v3
+ - name: Set up Python ${{ matrix.python-version }}
+ uses: actions/setup-python@v3
+ with:
+ python-version: ${{ matrix.python-version }}
+ - name: Install dependencies
+ run: |
+ python -m pip install cmind
+ cm pull repo --url=${{ github.event.pull_request.head.repo.html_url }} --checkout=${{ github.event.pull_request.head.ref }}
+ cm run script --quiet --tags=get,sys-utils-cm
+ - name: Test CM Tutorial TVM pip install with VirtualMachine Runtime
+ run: |
+ python tests/tutorials/test_tutorial_tvm_pip_vm.py
+
+ test_ge_runtime:
+ runs-on: ubuntu-latest
+ strategy:
+ fail-fast: false
+ matrix:
+ python-version: ["3.9"]
+
+ steps:
+ - uses: actions/checkout@v3
+ - name: Set up Python ${{ matrix.python-version }}
+ uses: actions/setup-python@v3
+ with:
+ python-version: ${{ matrix.python-version }}
+ - name: Install dependencies
+ run: |
+ python -m pip install cmind
+ cm pull repo --url=${{ github.event.pull_request.head.repo.html_url }} --checkout=${{ github.event.pull_request.head.ref }}
+ cm run script --quiet --tags=get,sys-utils-cm
+ - name: Test CM Tutorial TVM pip install with GraphExecutor Runtime
+ run: |
+ python tests/tutorials/test_tutorial_tvm_pip_ge.py
diff --git a/.github/workflows/test-cm-tutorial-tvm.yml b/.github/workflows/test-cm-tutorial-tvm.yml
new file mode 100644
index 0000000000..5a08e3fc5a
--- /dev/null
+++ b/.github/workflows/test-cm-tutorial-tvm.yml
@@ -0,0 +1,36 @@
+# This workflow will install Python dependencies, run tests and lint with a variety of Python versions
+# For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
+
+name: CM tutorial tvm
+
+on:
+ pull_request:
+ branches: [ "test" ]
+ paths:
+ - '.github/workflows/test-cm-tutorial-tvm.yml'
+ - 'cm-mlops/**'
+ - '!cm-mlops/**.md'
+
+jobs:
+ build:
+
+ runs-on: ubuntu-latest
+ strategy:
+ fail-fast: false
+ matrix:
+ python-version: ["3.9"]
+
+ steps:
+ - uses: actions/checkout@v3
+ - name: Set up Python ${{ matrix.python-version }}
+ uses: actions/setup-python@v3
+ with:
+ python-version: ${{ matrix.python-version }}
+ - name: Install dependencies
+ run: |
+ python -m pip install cmind
+ cm pull repo --url=${{ github.event.pull_request.head.repo.html_url }} --checkout=${{ github.event.pull_request.head.ref }}
+ cm run script --quiet --tags=get,sys-utils-cm
+ - name: Test CM Tutorial TVM
+ run: |
+ python tests/tutorials/test_tutorial_tvm.py
diff --git a/.github/workflows/test-cm.yml b/.github/workflows/test-cm.yml
new file mode 100644
index 0000000000..ce3ee706d7
--- /dev/null
+++ b/.github/workflows/test-cm.yml
@@ -0,0 +1,69 @@
+# This workflow will install Python dependencies, run tests and lint with a variety of Python versions
+# For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
+
+name: CM test
+
+on:
+ pull_request:
+ branches: [ "master" ]
+ paths:
+ - '.github/workflows/test-cm.yml'
+ - 'cm/**'
+ - '!cm/**.md'
+
+jobs:
+ build:
+ strategy:
+ fail-fast: false
+ matrix:
+ python-version: ["3.7", "3.8", "3.9", "3.10", "3.11", "3.12"]
+ on: [ubuntu-latest]
+ runs-on: "${{ matrix.on }}"
+ steps:
+ - uses: actions/checkout@v3
+ - name: Set up Python ${{ matrix.python-version }}
+ uses: actions/setup-python@v3
+ with:
+ python-version: ${{ matrix.python-version }}
+ - name: Install dependencies
+ run: |
+ python -m pip install --upgrade pip
+ python -m pip install flake8 pytest
+ if [ -f requirements.txt ]; then pip install -r requirements.txt; fi
+ python -m pip install --ignore-installed --verbose pip setuptools
+ cd cm
+ python setup.py install
+ python -m cmind
+ cm pull repo --url=${{ github.event.pull_request.head.repo.html_url }} --checkout=${{ github.event.pull_request.head.ref }}
+ - name: Lint with flake8
+ run: |
+ # stop the build if there are Python syntax errors or undefined names
+ flake8 cm/cmind --count --select=E9,F63,F7,F82 --show-source --statistics
+ # exit-zero treats all errors as warnings. The GitHub editor is 127 chars wide
+ flake8 cm/cmind --count --exit-zero --max-complexity=10 --max-line-length=127 --statistics
+ - name: Test
+ run: |
+ python tests/test_cm.py
+
+ test_cm:
+ strategy:
+ fail-fast: false
+ matrix:
+ python-version: ["3.7", "3.8", "3.9", "3.10", "3.11", "3.12"]
+ on: [ubuntu-latest, windows-latest]
+ runs-on: "${{ matrix.on }}"
+ steps:
+ - uses: actions/checkout@v3
+ - name: Set up Python ${{ matrix.python-version }}
+ uses: actions/setup-python@v3
+ with:
+ python-version: ${{ matrix.python-version }}
+ - name: Install dependencies
+ run: |
+ python -m pip install --upgrade pip
+ python -m pip install cmind
+ cm pull repo --url=${{ github.event.pull_request.head.repo.html_url }} --checkout=${{ github.event.pull_request.head.ref }}
+ - name: Test CM
+ run: |
+ python tests/test_cm.py
+
diff --git a/.github/workflows/test-image-classification-onnx.yml b/.github/workflows/test-image-classification-onnx.yml
new file mode 100644
index 0000000000..62049d1c51
--- /dev/null
+++ b/.github/workflows/test-image-classification-onnx.yml
@@ -0,0 +1,36 @@
+# This workflow will install Python dependencies, run tests and lint with a variety of Python versions
+# For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
+
+name: image classification with ONNX
+
+on:
+ pull_request:
+ branches: [ "master", "dev" ]
+ paths:
+ - '.github/workflows/test-image-classification-onnx.yml'
+ - 'cm-mlops/**'
+ - '!cm-mlops/**.md'
+
+jobs:
+ build:
+
+ runs-on: ubuntu-latest
+ strategy:
+ fail-fast: false
+ matrix:
+ python-version: [ "3.12", "3.9"]
+
+ steps:
+ - uses: actions/checkout@v3
+ - name: Set up Python ${{ matrix.python-version }}
+ uses: actions/setup-python@v3
+ with:
+ python-version: ${{ matrix.python-version }}
+ - name: Install dependencies
+ run: |
+ python3 -m pip install cmind
+ cm pull repo --url=${{ github.event.pull_request.head.repo.html_url }} --checkout=${{ github.event.pull_request.head.ref }}
+ cm run script --quiet --tags=get,sys-utils-cm
+ - name: Test image classification with ONNX
+ run: |
+ cmr "python app image-classification onnx" --quiet
diff --git a/.github/workflows/test-mlperf-inference-bert-deepsparse-tf-onnxruntime-pytorch.yml b/.github/workflows/test-mlperf-inference-bert-deepsparse-tf-onnxruntime-pytorch.yml
new file mode 100644
index 0000000000..89760294a6
--- /dev/null
+++ b/.github/workflows/test-mlperf-inference-bert-deepsparse-tf-onnxruntime-pytorch.yml
@@ -0,0 +1,44 @@
+# This workflow will install Python dependencies, run tests and lint with a variety of Python versions
+# For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
+
+name: MLPerf inference bert (deepsparse, tf, onnxruntime, pytorch)
+
+on:
+ pull_request:
+ branches: [ "master", "dev" ]
+ paths:
+ - '.github/workflows/test-mlperf-inference-bert-deepsparse-tf-onnxruntime-pytorch.yml'
+ - 'cm-mlops/**'
+ - '!cm-mlops/**.md'
+
+jobs:
+ build:
+
+ runs-on: ubuntu-latest
+ strategy:
+ fail-fast: false
+ matrix:
+ # 3.12 didn't work on 20240305 - need to check
+ python-version: [ "3.11", "3.9" ]
+ backend: [ "deepsparse", "tf", "onnxruntime", "pytorch" ]
+ precision: [ "int8", "fp32" ]
+ exclude:
+ - backend: tf
+ - backend: pytorch
+ - backend: onnxruntime
+ - precision: fp32
+
+ steps:
+ - uses: actions/checkout@v3
+ - name: Set up Python ${{ matrix.python-version }}
+ uses: actions/setup-python@v3
+ with:
+ python-version: ${{ matrix.python-version }}
+ - name: Install dependencies
+ run: |
+ python3 -m pip install cmind
+ cm pull repo --url=${{ github.event.pull_request.head.repo.html_url }} --checkout=${{ github.event.pull_request.head.ref }}
+ cm run script --quiet --tags=get,sys-utils-cm
+ - name: Test MLPerf Inference Bert (DeepSparse, TF, ONNX, PyTorch)
+ run: |
+ cm run script --tags=run,mlperf,inference,generate-run-cmds,_submission,_short --submitter="cTuning" --model=bert-99 --backend=${{ matrix.backend }} --device=cpu --scenario=Offline --test_query_count=5 --precision=${{ matrix.precision }} --target_qps=1 -v --quiet
diff --git a/.github/workflows/test-mlperf-inference-gptj.yml b/.github/workflows/test-mlperf-inference-gptj.yml
new file mode 100644
index 0000000000..ea1a70fa86
--- /dev/null
+++ b/.github/workflows/test-mlperf-inference-gptj.yml
@@ -0,0 +1,38 @@
+# This workflow will install Python dependencies, run tests and lint with a variety of Python versions
+# For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
+
+name: MLPerf inference GPT-J
+
+on:
+ pull_request:
+ branches: [ "master1", "dev1" ]
+ paths:
+ - '.github/workflows/test-mlperf-inference-gptj.yml'
+ - 'cm-mlops/**'
+ - '!cm-mlops/**.md'
+
+jobs:
+ build:
+
+ runs-on: ubuntu-latest
+ strategy:
+ fail-fast: false
+ matrix:
+ python-version: [ "3.12", "3.9" ]
+ backend: [ "pytorch" ]
+ precision: [ "bfloat16" ]
+
+ steps:
+ - uses: actions/checkout@v3
+ - name: Set up Python ${{ matrix.python-version }}
+ uses: actions/setup-python@v3
+ with:
+ python-version: ${{ matrix.python-version }}
+ - name: Install dependencies
+ run: |
+ python3 -m pip install cmind
+ cm pull repo --url=${{ github.event.pull_request.head.repo.html_url }} --checkout=${{ github.event.pull_request.head.ref }}
+ cm run script --quiet --tags=get,sys-utils-cm
+ - name: Test MLPerf Inference GPTJ
+ run: |
+ cm run script --tags=run,mlperf,inference,generate-run-cmds,_submission,_short --submitter="cTuning" --model=gptj --backend=${{ matrix.backend }} --device=cpu --scenario=Offline --test_query_count=1 --precision=${{ matrix.precision }} --target_qps=1 --quiet
diff --git a/.github/workflows/test-mlperf-inference-mlcommons-cpp-resnet50.yml b/.github/workflows/test-mlperf-inference-mlcommons-cpp-resnet50.yml
new file mode 100644
index 0000000000..a28e86825f
--- /dev/null
+++ b/.github/workflows/test-mlperf-inference-mlcommons-cpp-resnet50.yml
@@ -0,0 +1,38 @@
+# This workflow will install Python dependencies, run tests and lint with a variety of Python versions
+# For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
+
+name: MLPerf inference MLCommons C++ ResNet50
+
+on:
+ pull_request:
+ branches: [ "master", "dev" ]
+ paths:
+ - '.github/workflows/test-mlperf-inference-mlcommons-cpp-resnet50.yml'
+ - 'cm-mlops/**'
+ - '!cm-mlops/**.md'
+
+jobs:
+ build:
+
+ runs-on: ubuntu-latest
+ strategy:
+ fail-fast: false
+ matrix:
+ python-version: [ "3.12", "3.9" ]
+ llvm-version: [ "15.0.6", "16.0.4", "17.0.6" ]
+
+ steps:
+ - uses: actions/checkout@v3
+ - name: Set up Python ${{ matrix.python-version }}
+ uses: actions/setup-python@v3
+ with:
+ python-version: ${{ matrix.python-version }}
+ - name: Install dependencies
+ run: |
+ python3 -m pip install cmind
+ cm pull repo --url=${{ github.event.pull_request.head.repo.html_url }} --checkout=${{ github.event.pull_request.head.ref }}
+ cm run script --quiet --tags=get,sys-utils-cm
+ cm run script --quiet --tags=install,prebuilt,llvm --version=${{ matrix.llvm-version }}
+ - name: Test MLPerf Inference MLCommons C++ ResNet50
+ run: |
+ cmr "app mlperf inference mlcommons cpp" -v --quiet
diff --git a/.github/workflows/test-mlperf-inference-resnet50.yml b/.github/workflows/test-mlperf-inference-resnet50.yml
new file mode 100644
index 0000000000..29b7b3cb59
--- /dev/null
+++ b/.github/workflows/test-mlperf-inference-resnet50.yml
@@ -0,0 +1,43 @@
+# This workflow will install Python dependencies, run tests and lint with a variety of Python versions
+# For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
+
+name: MLPerf inference resnet50
+
+on:
+ pull_request:
+ branches: [ "master", "dev" ]
+ paths:
+ - '.github/workflows/test-mlperf-inference-resnet50.yml'
+ - 'cm-mlops/**'
+ - '!cm-mlops/**.md'
+
+jobs:
+ build:
+
+ runs-on: ubuntu-latest
+ env:
+ CM_INDEX: "on"
+ strategy:
+ fail-fast: false
+ matrix:
+ python-version: [ "3.12", "3.9" ]
+ backend: [ "onnxruntime", "tf" ]
+ implementation: [ "python", "cpp" ]
+ exclude:
+ - backend: tf
+ implementation: cpp
+
+ steps:
+ - uses: actions/checkout@v3
+ - name: Set up Python ${{ matrix.python-version }}
+ uses: actions/setup-python@v3
+ with:
+ python-version: ${{ matrix.python-version }}
+ - name: Install dependencies
+ run: |
+ python3 -m pip install cmind
+ cm pull repo --url=${{ github.event.pull_request.head.repo.html_url }} --checkout=${{ github.event.pull_request.head.ref }}
+ cm run script --quiet --tags=get,sys-utils-cm
+ - name: Test MLPerf Inference ResNet50
+ run: |
+ cm run script --tags=run,mlperf,inference,generate-run-cmds,_submission,_short --submitter="cTuning" --hw_name=default --model=resnet50 --implementation=${{ matrix.implementation }} --backend=${{ matrix.backend }} --device=cpu --scenario=Offline --test_query_count=500 --target_qps=1 -v --quiet
diff --git a/.github/workflows/test-mlperf-inference-retinanet.yml b/.github/workflows/test-mlperf-inference-retinanet.yml
new file mode 100644
index 0000000000..4846aa2bd1
--- /dev/null
+++ b/.github/workflows/test-mlperf-inference-retinanet.yml
@@ -0,0 +1,41 @@
+# This workflow will install Python dependencies, run tests and lint with a variety of Python versions
+# For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
+
+name: MLPerf inference retinanet
+
+on:
+ pull_request:
+ branches: [ "master", "dev" ]
+ paths:
+ - 'cm-mlops/**'
+ - '.github/workflows/test-mlperf-inference-retinanet.yml'
+ - '!cm-mlops/**.md'
+
+jobs:
+ build:
+
+ runs-on: ubuntu-latest
+ strategy:
+ fail-fast: false
+ matrix:
+ python-version: [ "3.12", "3.9" ]
+ backend: [ "onnxruntime", "pytorch" ]
+ implementation: [ "python", "cpp" ]
+ exclude:
+ - backend: pytorch
+ implementation: cpp
+
+ steps:
+ - uses: actions/checkout@v3
+ - name: Set up Python ${{ matrix.python-version }}
+ uses: actions/setup-python@v3
+ with:
+ python-version: ${{ matrix.python-version }}
+ - name: Install dependencies
+ run: |
+ python3 -m pip install cmind
+ cm pull repo --url=${{ github.event.pull_request.head.repo.html_url }} --checkout=${{ github.event.pull_request.head.ref }}
+ cm run script --quiet --tags=get,sys-utils-cm
+ - name: Test MLPerf Inference Retinanet using ${{ matrix.backend }}
+ run: |
+ cm run script --tags=run,mlperf,inference,generate-run-cmds,_submission,_short --submitter="cTuning" --hw_name=default --model=retinanet --implementation=${{ matrix.implementation }} --backend=${{ matrix.backend }} --device=cpu --scenario=Offline --test_query_count=5 --adr.compiler.tags=gcc --quiet -v --target_qps=1
diff --git a/.github/workflows/test-mlperf-inference-rnnt.yml b/.github/workflows/test-mlperf-inference-rnnt.yml
new file mode 100644
index 0000000000..d6c1ae6a2e
--- /dev/null
+++ b/.github/workflows/test-mlperf-inference-rnnt.yml
@@ -0,0 +1,38 @@
+# This workflow will install Python dependencies, run tests and lint with a variety of Python versions
+# For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
+
+name: MLPerf inference rnnt
+
+on:
+ pull_request:
+ branches: [ "master", "dev" ]
+ paths:
+ - '.github/workflows/test-mlperf-inference-rnnt.yml'
+ - 'cm-mlops/**'
+ - '!cm-mlops/**.md'
+
+jobs:
+ build:
+
+ runs-on: ubuntu-latest
+ strategy:
+ fail-fast: false
+ matrix:
+ python-version: [ "3.12", "3.9" ]
+ backend: [ "pytorch" ]
+ precision: [ "fp32" ]
+
+ steps:
+ - uses: actions/checkout@v3
+ - name: Set up Python ${{ matrix.python-version }}
+ uses: actions/setup-python@v3
+ with:
+ python-version: ${{ matrix.python-version }}
+ - name: Install dependencies
+ run: |
+ python3 -m pip install cmind
+ cm pull repo --url=${{ github.event.pull_request.head.repo.html_url }} --checkout=${{ github.event.pull_request.head.ref }}
+ cm run script --quiet --tags=get,sys-utils-cm
+ - name: Test MLPerf Inference RNNT
+ run: |
+ cm run script --tags=run,mlperf,inference,generate-run-cmds,_performance-only --submitter="cTuning" --model=rnnt --backend=${{ matrix.backend }} --device=cpu --scenario=Offline --test_query_count=5 --precision=${{ matrix.precision }} --target_qps=5 -v --quiet
diff --git a/.github/workflows/test-mlperf-inference-tvm.yml b/.github/workflows/test-mlperf-inference-tvm.yml
new file mode 100644
index 0000000000..04c624513b
--- /dev/null
+++ b/.github/workflows/test-mlperf-inference-tvm.yml
@@ -0,0 +1,38 @@
+# This workflow will install Python dependencies, run tests and lint with a variety of Python versions
+# For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
+
+# We are doing similar test on our tvm tutorial test. So, this test is not necessary
+name: MLPerf inference resnet50 using TVM.
+
+on:
+ pull_request:
+ branches: [ "tvm-more" ]
+ paths:
+ - '.github/workflows/test-mlperf-inference-tvm.yml'
+ - 'cm-mlops/**'
+ - '!cm-mlops/**.md'
+
+jobs:
+ build:
+
+ runs-on: ubuntu-latest
+ strategy:
+ fail-fast: false
+ matrix:
+ python-version: [ "3.12", "3.10" ]
+ backend: [ "tvm-onnx" ]
+
+ steps:
+ - uses: actions/checkout@v3
+ - name: Set up Python ${{ matrix.python-version }}
+ uses: actions/setup-python@v3
+ with:
+ python-version: ${{ matrix.python-version }}
+ - name: Install dependencies
+ run: |
+ python3 -m pip install cmind
+ cm pull repo --url=${{ github.event.pull_request.head.repo.html_url }} --checkout=${{ github.event.pull_request.head.ref }}
+ cm run script --quiet --tags=get,sys-utils-cm
+ - name: MLPerf Inference ResNet50 using TVM
+ run: |
+ cm run script --tags=run,mlperf,inference,generate-run-cmds --hw_name=default --model=resnet50 --backend=${{ matrix.backend }} --device=cpu --scenario=Offline --test_query_count=5 --target_qps=1 -v --quiet
diff --git a/.github/workflows/test-mlperf-loadgen-onnx-huggingface-bert-fp32-squad.yml b/.github/workflows/test-mlperf-loadgen-onnx-huggingface-bert-fp32-squad.yml
new file mode 100644
index 0000000000..a66e40981c
--- /dev/null
+++ b/.github/workflows/test-mlperf-loadgen-onnx-huggingface-bert-fp32-squad.yml
@@ -0,0 +1,36 @@
+# This workflow will install Python dependencies, run tests and lint with a variety of Python versions
+# For more information see: https://help.github.com/actions/language-and-framework-guides/using-python-with-github-actions
+
+name: MLPerf loadgen with HuggingFace bert onnx fp32 squad model
+
+on:
+ pull_request:
+ branches: [ "master", "dev" ]
+ paths:
+ - '.github/workflows/test-mlperf-loadgen-onnx-huggingface-bert-fp32-squad.yml'
+ - 'cm-mlops/**'
+ - '!cm-mlops/**.md'
+
+jobs:
+ build:
+
+ runs-on: ubuntu-latest
+ strategy:
+ fail-fast: false
+ matrix:
+ python-version: [ "3.12", "3.9" ]
+
+ steps:
+ - uses: actions/checkout@v3
+ - name: Set up Python ${{ matrix.python-version }}
+ uses: actions/setup-python@v3
+ with:
+ python-version: ${{ matrix.python-version }}
+ - name: Install dependencies
+ run: |
+ python3 -m pip install cmind
+ cm pull repo --url=${{ github.event.pull_request.head.repo.html_url }} --checkout=${{ github.event.pull_request.head.ref }}
+ cm run script --quiet --tags=get,sys-utils-cm
+ - name: Test MLPerf loadgen with HuggingFace bert onnx fp32 squad model
+ run: |
+ cmr "python app loadgen-generic _onnxruntime _custom _huggingface _model-stub.ctuning/mlperf-inference-bert-onnx-fp32-squad-v1.1" --adr.hf-downloader.model_filename=model.onnx --quiet
diff --git a/.github/workflows/test-qaic-compute-sdk-build.yml b/.github/workflows/test-qaic-compute-sdk-build.yml
new file mode 100644
index 0000000000..b2e774a440
--- /dev/null
+++ b/.github/workflows/test-qaic-compute-sdk-build.yml
@@ -0,0 +1,35 @@
+name: Test Compilation of QAIC Compute SDK (build LLVM from src)
+
+on:
+ schedule:
+ - cron: "1 1 * * 2"
+
+jobs:
+ build:
+ runs-on: ubuntu-20.04
+ strategy:
+ fail-fast: false
+ matrix:
+ llvm-version: [ "12.0.1", "13.0.1", "14.0.0", "15.0.6", "16.0.4", "17.0.6" ]
+ exclude:
+ - llvm-version: "13.0.1"
+ - llvm-version: "14.0.0"
+ - llvm-version: "15.0.6"
+ - llvm-version: "16.0.4"
+ - llvm-version: "17.0.6"
+
+ steps:
+ - uses: actions/checkout@v3
+ - name: Set up Python ${{ matrix.python-version }}
+ uses: actions/setup-python@v3
+ with:
+ python-version: ${{ matrix.python-version }}
+ - name: Install dependencies
+ run: |
+ python3 -m pip install cmind
+ cm pull repo mlcommons@ck
+ cm run script --tags=get,sys-utils-cm --quiet
+
+ - name: Test QAIC Compute SDK for compilation
+ run: |
+ cm run script --tags=get,qaic,compute,sdk --adr.llvm.version=${{ matrix.llvm-version }} --quiet
diff --git a/.github/workflows/test-qaic-software-kit.yml b/.github/workflows/test-qaic-software-kit.yml
new file mode 100644
index 0000000000..e3a186daae
--- /dev/null
+++ b/.github/workflows/test-qaic-software-kit.yml
@@ -0,0 +1,41 @@
+name: Test QAIC Software kit Compilation
+
+on:
+ schedule:
+ - cron: "1 1 * * 1"
+
+jobs:
+ build_ubuntu_20_04:
+ runs-on: ubuntu-20.04
+ strategy:
+ fail-fast: false
+ matrix:
+ compiler: [ "gcc", "llvm" ]
+ llvm-version: [ "12.0.1", "13.0.1", "14.0.0", "15.0.6" ]
+ exclude:
+ - llvm-version: "12.0.1"
+ - llvm-version: "13.0.1"
+ - llvm-version: "14.0.0"
+ compiler: "gcc"
+ - llvm-version: "15.0.6"
+ compiler: "gcc"
+ include:
+ - llvm-version: " "
+ compiler: "gcc"
+
+ steps:
+ - uses: actions/checkout@v3
+ - name: Set up Python ${{ matrix.python-version }}
+ uses: actions/setup-python@v3
+ with:
+ python-version: ${{ matrix.python-version }}
+ - name: Install dependencies
+ run: |
+ python3 -m pip install cmind
+ cm pull repo mlcommons@ck
+ cm run script --tags=get,sys-utils-cm --quiet
+
+ - name: Test Software Kit for compilation on Ubuntu 20.04
+ run: |
+ cm run script --tags=get,qaic,software,kit --adr.compiler.tags=${{ matrix.compiler }} --adr.compiler.version=${{ matrix.llvm-version }} --quiet
+ cm run script --tags=get,qaic,software,kit --adr.compiler.tags=${{ matrix.compiler }} --adr.compiler.version=${{ matrix.llvm-version }} --quiet
diff --git a/.github/workflows/update-script-dockerfiles.yml b/.github/workflows/update-script-dockerfiles.yml
new file mode 100644
index 0000000000..4c626b137e
--- /dev/null
+++ b/.github/workflows/update-script-dockerfiles.yml
@@ -0,0 +1,41 @@
+# This workflow will add/update the default dockerfile for any updated CM scripts
+name: Dockerfile update for CM scripts
+
+on:
+ push:
+ branches: [ "master", "dev" ]
+ paths:
+ - 'cm-mlops/script/**_cm.json'
+
+jobs:
+ dockerfile:
+ if: github.repository == 'mlcommons/ck'
+ runs-on: ubuntu-latest
+ steps:
+ - name: 'Checkout'
+ uses: actions/checkout@v3
+ with:
+ fetch-depth: 0
+ - name: Get changed files
+ id: getfile
+ run: |
+ echo "files=$(git diff --name-only ${{ github.event.before }} | xargs)" >> $GITHUB_OUTPUT
+ - name: Update dockerfile
+ run: |
+ for file in ${{ steps.getfile.outputs.files }}; do
+ echo $file
+ done
+ python3 -m pip install cmind
+ cm pull repo --url=https://github.com/${{ github.repository }} --checkout=${{ github.ref_name }}
+ python3 tests/script/process_dockerfile.py ${{ steps.getfile.outputs.files }}
+
+ FOLDER=`cm find repo mlcommons@ck | cut -d' ' -f3`
+
+ USER=ctuning-admin
+ EMAIL=admin@ctuning.org
+
+ git config --global user.name "$USER"
+ git config --global user.email "$EMAIL"
+ git remote set-url origin https://x-access-token:${{ secrets.ACCESS_TOKEN }}@github.com/${{ github.repository }}
+ git add *.Dockerfile
+ git diff-index --quiet HEAD || (git commit -am "Updated dockerfile" && git push)
diff --git a/.github/workflows/update-script-readme.yml b/.github/workflows/update-script-readme.yml
new file mode 100644
index 0000000000..8e795e4bb2
--- /dev/null
+++ b/.github/workflows/update-script-readme.yml
@@ -0,0 +1,46 @@
+# This workflow will add/update the README.md files for any updated CM scripts
+name: Readme update for CM scripts
+
+on:
+ push:
+ branches: [ "master", "dev" ]
+ paths:
+ - 'cm-mlops/script/**_cm.json'
+
+jobs:
+ doreadme:
+ runs-on: ubuntu-latest
+ if: github.repository == 'mlcommons/ck'
+ steps:
+ - name: 'Checkout'
+ uses: actions/checkout@v3
+ with:
+ fetch-depth: 0
+ - name: Get changed files
+ id: getfile
+ run: |
+ echo "files=$(git diff --name-only ${{ github.event.before }} | xargs)" >> $GITHUB_OUTPUT
+ - name: Update readme
+ run: |
+ echo ${{ steps.getfile.outputs.files }}
+ for file in ${{ steps.getfile.outputs.files }}; do
+ echo $file
+ done
+ python3 -m pip install cmind
+ cm pull repo --url=https://github.com/${{ github.repository }} --checkout=${{ github.ref_name }}
+ python3 tests/script/process_readme.py ${{ steps.getfile.outputs.files }}
+ #REPO=${{ github.repository }}
+ #CM_REPO=${REPO/\//@}
+ #FOLDER=`cm find repo ${CM_REPO} | cut -d' ' -f3`
+ FOLDER=`cm find repo mlcommons@ck | cut -d' ' -f3`
+ cd $FOLDER
+ echo "Changed to $FOLDER"
+
+ USER=ctuning-admin
+ EMAIL=admin@ctuning.org
+
+ git config --global user.name "$USER"
+ git config --global user.email "$EMAIL"
+ git remote set-url origin https://x-access-token:${{ secrets.ACCESS_TOKEN }}@github.com/${{ github.repository }}
+ git add *.md
+ git diff-index --quiet HEAD || (git commit -am "Updated docs" && git push && echo "Changes pushed")
diff --git a/CHANGES.md b/CHANGES.md
new file mode 100644
index 0000000000..a24a477b5e
--- /dev/null
+++ b/CHANGES.md
@@ -0,0 +1,213 @@
+Since March 2023, all updates to CM automations are submitted via PRs.
+You can follow our PRs at
+* https://github.com/ctuning/mlcommons-ck/commits/master
+* https://github.com/mlcommons/ck/pulls?q=is%3Apr+is%3Aclosed .
+
+---
+
+### 20230214
+ * experiment and graph gui are working now
+
+### 20230206:
+ * started prototyping cm run experiment
+
+### 20230123:
+ * added simple GUI to CM scripts
+
+### 20221206:
+ * added "script_name" to the CM "script" meta to specify any native script name
+ * added "--script_name" to "cm add script {alias} --script_name=my-native-script.sh"
+
+### 20221206:
+ * added CM_SCRIPT_EXTRA_CMD to force some flags to all scripts
+
+### 20221202:
+ * major updates for Windows (CL, CUDA, etc)
+
+### 20221111:
+ * various fixes for Student Cluster Competition at SuperComputing'22
+
+### 20221110:
+ * added support to push MLPerf results to W&B dashboard
+
+### 20221103:
+ * added "cm json2yaml utils" and "cm yaml2json utils"
+
+### 20221024:
+ * added --verbose and --time to "cm run script"
+
+### 20221017:
+ * removed the need for echo-off script
+
+### 20221010:
+ * added cm run script --debug-script-tags to run cmd/bash before native script
+ * added cm run script --shell to set env and run shell after script execution
+
+* 20221007:
+ * added script template (used when adding new scripts)
+ * major clean up of all scripts
+
+### 20220916:
+ * treat alias as tags if spaces:
+ cm run script "get compiler" is converted to cm run script --tags=get,compiler
+ * improved gcc detection
+ * refactored "cm run script" to skip deps in cache if needed
+
+### 20220906
+ * added --print_env flag to "cm run script" to print aggregated env
+ before running native scripts
+ * various fixes to support MLPerf automation
+
+### 20220823
+ * various fixes for universal MLPerf inference submission automation
+
+### 20220803
+ * various fixes for TVM and image classification
+
+### 20220802
+ * added "run_script_after_post_deps" to script meta to run script after post deps
+ (useful to activate python virtual env)
+ * added "activate-python-venv" script to make it easier to debug Python deps installation
+
+### 20220722
+ * added --accept-license and --skip-system-deps
+ (converted to env CM_ACCEPT_LICENSE ("True") and CM_SKIP_SYSTEM_DEPS ("True"))
+
+### 20220719
+ * moved relatively stable MLOps automation scripts here
+
+### 20220718
+ * fixed local_env_keys in get-python3
+ * added new_env_only_keys to meta to specify which env to keep
+ * fixed problem with adding tags from the selected script during caching
+ * added --skip-compile and --skip-run to script (converted to env CM_SKIP_COMPILE and CM_SKIP_RUN)
+ * fixed local_env_keys in get-python3
+ * added new_env_only_keys to get-python3
+
+### 20220713
+ * added local_env_keys to meta
+ * added "env" dict to os_info
+
+### 20220712
+ * major script refactoring to support cache tags update from deps
+ * fixed version min/max propagations in deps
+ * improvements to support tags from deps
+ * added tags from deps (python, llvm)
+
+### 20220708
+ * various fixes to handle versions (min/max/default)
+ * various fixes to avoid contamination of ENV from other scripts
+ * various fixes to handle versions (min/max/default)
+
+### 20220705
+ * fixes for remembered selections
+ * added --skip-remembered-selections to "cm run script"
+
+### 20220704
+ * fixed a bug with searching for scripts with variations
+ * added the possibility to update deps from pre/post processing
+ * added --extra-cache-tags and --name for "cm run script"
+ * added prototype of selection caching
+ * fixed get-python-venv
+
+### 20220701
+ * added dummy "cm test script"
+ * added "--env" to "cm show cache" to show env and state
+ * added "cm show cache"
+
+### 20220629
+ * added "detect_version_using_script" in script used to detect python packages
+ * major fix to properly support multiple scripts with the same tags, caching, selection, etc
+ * fixed a bug in version comparison (converting string to int)
+ * added recording of "version" to cache meta
+
+### 20220628
+ * fixed local_env with deps
+
+### 20220623
+ * important update of versions logic
+
+### 20220621
+ * added support for --quiet
+ * changed CM_NEED_VERSION to CM_VERSION
+ * added CM_VERSION_MIN, CM_VERSION_MAX
+ * added cm compare_versions utils --version1=... --version2=...
+ * added support to detect min/max/correct versions
+
+### 20220617
+ * fixed logic to handle variations (-_): https://github.com/mlcommons/ck/issues/243
+
+### 20220616
+ * changed "cached" to "cache" automation
+
+### 20220615
+ * major update of script (remove parallel env/new_env and state/new_state).
+ keep global env & state and detect changes automatically
+ * major simplification of "script"
+ * removed "installed" to be more understandable
+ * added "cached" to be more understandable
+
+### 20220609
+ * added "versions" key to the CM script meta
+ it works similar to "variations" and is forced by --version
+ * changed "ic" to "script" in "experiment" automation
+
+### 20220608
+ * updated "variations" logic in "script"!
+ meta['default_variation'] (str): only one of many
+ meta['default_variations'] (list): multiple choices
+ * deprecated "ic" automation. Use "script" instead!
+
+### 20220607
+ * added strip_folders to utils/unzip_file
+ * fixed minor bugs in CM script
+
+### 20220606
+ * added "name" key to deps (list of names and UIDs)
+ * added "add_deps_tags" in variations and in CMD ({"name":"tag(s)"})
+ * added "deps" to variations to be merged with the list of current deps
+ * added --input and --output for cm run script converted to env CM_INPUT and CM_OUTPUT
+ useful to create interactive CM scripts to process files
+ * Added prototype-test-deps-variations-tags to play with deps, variations, tags
+
+### 20220605
+ * clean tmp files in "script" automation by default and keep them using --dirty flag
+
+### 20220603
+ * added "skip" and "deps" to postprocess to call other scripts.
+ For example call install LLVM if detect LLVM fails...
+ * added "script" automation to substitute less intuitive "ic"
+ * Improved LLVM detection and installation
+ * Added example of image corner detection
+ * Added updated script entries
+
+### 20220601
+ * added version, path, skip_install and post_deps to IC
+ * added --new to IC to detect new components
+ * Updating mechanisms to install and/or detect LLVM
+ * added support to install prebuilt LLVM for Linux, MacOs, Windows
+
+### 20220530
+ * updated ic automation to read tmp-run-state.json
+ and merge it with the "new_state" dict
+
+### 20220524
+ * changed directory ck2-repo-mlops to cm-devops
+
+### 20220517
+ * Changed CM_PATH_LIST to +PATH
+ * Added general support for +ENV that is expanded to ENV=val1;val2;...:${ENV}
+
+### 20220511
+ * Better handle exceptions in utils.download_file
+ * Added support for variations in intelligent components (ic)
+ * Fixed bugs in IC
+ * Added "_" prefix in tags to specify variation of IC
+ * Record env.sh in "installed artifacts even if bat file is not executed
+ * Fixed experiment directory naming on Windows
+ * Added "cm version ic" (#233)
+ * Added prototype of ic::prototype-get-ml-model-resnet50-onnx with variations
+ * Added prototype of ic::prototype-get-imagenet-val with variations
+ * Added prototype of ic::prototype-get-imagenet-aux with variations
+ * Added prototype of ic::prototype-get-llvm
+ * Added prototype of ic::prototype-get-tvm
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 6e05ae89d7..5219a7fc94 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -1,3 +1,5 @@
+# Collective Mind project aka CM
+
## Contributing
The best way to contribute to the MLCommons is to get involved with one of our many project communities. You find more information about getting involved with MLCommons [here](https://mlcommons.org/en/get-involved/#getting-started).
@@ -6,4 +8,70 @@ Generally we encourage people to become a MLCommons member if they wish to contr
Regardless of if you are a member, your organization needs to sign the MLCommons CLA. Please fill out this [CLA sign up form](https://forms.gle/Ew1KkBVpyeJDuRw67) form to get started.
-MLCommons project work is tracked with issue trackers and pull requests. Modify the project in your own fork and issue a pull request once you want other developers to take a look at what you have done and discuss the proposed changes. Ensure that cla-bot and other checks pass for your Pull requests.
\ No newline at end of file
+MLCommons project work is tracked with issue trackers and pull requests. Modify the project in your own fork and issue a pull request once you want other developers to take a look at what you have done and discuss the proposed changes. Ensure that cla-bot and other checks pass for your Pull requests.
+
+## CM project coordinator
+
+* [Grigori Fursin](https://cKnowledge.org/gfursin)
+
+## CM authors
+
+* [Grigori Fursin](https://cKnowledge.org/gfursin) (CM core and CM scripts for MLOps)
+* [Arjun Suresh](https://www.linkedin.com/in/arjunsuresh) (CM scripts for MLPerf and MLOps)
+
+## CM contributors in alphabetical order (suggestions and/or scripts)
+
+* Resmi Arjun
+* Alice Cheng (Nvidia)
+* Jiahao Chen (MIT)
+* Ramesh N Chukka (Intel)
+* Ray DeMoss (One Stop Systems)
+* Ryan T DeRue (Purdue University)
+* Himanshu Dutta (Indian Institute of Technology)
+* Justin Faust (One Stop Systems)
+* Diane Feddema (Red Hat)
+* Leonid Fursin (United Silicon Carbide)
+* Anirban Ghosh (Nvidia)
+* Michael Goin (Neural Magic)
+* Jose Armando Hernandez (Paris Saclay University)
+* Mehrdad Hessar (OctoML)
+* Miro Hodak (AMD)
+* Sachin Idgunji (Nvidia)
+* Tom Jablin (Google)
+* Nino Jacob
+* David Kanter (MLCommons)
+* Jason Knight (OctoML)
+* Ilya Kozulin (Deelvin)
+* @makaveli10 (Collabora)
+* Steve Leak(NERSC)
+* Amija Maji (Purdue University)
+* Peter Mattson (Google, MLCommons)
+* Kasper Mecklenburg (Arm)
+* Pablo Gonzalez Mesa
+* Thierry Moreau (OctoML)
+* Sachin Mudaliyar
+* Stanley Mwangi (Microsoft)
+* Ashwin Nanjappa (Nvidia)
+* Hai Ah Nam (NERSC)
+* Nandeeka Nayak (UIUC)
+* Datta Nimmaturi (Nutanix)
+* Lakshman Patel
+* Arun Tejusve Raghunath Rajan (Cruise)
+* Vijay Janapa Reddi (Harvard University)
+* Andrew Reusch (OctoML)
+* Anandhu S (Kerala Technical University)
+* Sergey Serebryakov (HPE)
+* Warren Schultz (Principled Technologies)
+* Amrutha Sheleenderan (Kerala Technical University)
+* Byoungjun Seo (TTA)
+* Aditya Kumar Shaw (Indian Institute of Science)
+* Ilya Slavutin (Deelvin)
+* Jinho Suh (Nvidia)
+* Badhri Narayanan Suresh (Intel)
+* David Tafur (MLCommons)
+* Chloe Tessier
+* Gaurav Verma (Stony Brook University)
+* Scott Wasson (MLCommons)
+* Haoyang Zhang (UIUC)
+* Bojian Zheng (University of Toronto)
+* Thomas Zhu (Oxford University)
diff --git a/LICENSE.third-party.md b/LICENSE.third-party.md
new file mode 100644
index 0000000000..faa0084585
--- /dev/null
+++ b/LICENSE.third-party.md
@@ -0,0 +1 @@
+This CM repository may contain CM scripts with third-party files licensed under Apache2, BSD or MIT license.
diff --git a/README.md b/README.md
new file mode 100644
index 0000000000..cde1576187
--- /dev/null
+++ b/README.md
@@ -0,0 +1,29 @@
+# CM repository with cross-platform scripts for DevOps, MLOps, AIOps and MLPerf
+
+[](LICENSE.md)
+[](https://github.com/mlcommons/ck).
+
+This repository contains reusable and cross-platform automation recipes to run DevOps, MLOps, AIOps and MLPerf
+via a simple and human-readable [Collective Mind interface (CM)](https://github.com/mlcommons/ck)
+while adapting to different opearting systems, software and hardware.
+
+All СM scripts have a simple Python API, extensible JSON/YAML meta description
+and unifed input/output to make them reusable in different projects either individually
+or by chaining them together into portable automation workflows, applications
+and web services adaptable to continuously changing models, data sets, software and hardware.
+
+These automation recipes are being developed and maintained
+by the [MLCommons Task Force on Automation and Reproducibility](https://github.com/mlcommons/ck/blob/master/docs/taskforce.md)
+with [great contributions](CONTRIBUTING.md) from the community.
+
+### Catalog
+
+See the automatically generated catalog [online](https://access.cknowledge.org/playground/?action=scripts).
+
+### License
+
+[Apache 2.0](LICENSE.md)
+
+### Copyright
+
+2022-2024 [MLCommons](https://mlcommons.org)
diff --git a/automation/cache/README-extra.md b/automation/cache/README-extra.md
new file mode 100644
index 0000000000..84d2741794
--- /dev/null
+++ b/automation/cache/README-extra.md
@@ -0,0 +1,71 @@
+[ [Back to index](../../../docs/README.md) ]
+
+# CM "cache" automation
+
+*We suggest you to check [CM introduction](https://github.com/mlcommons/ck/blob/master/docs/introduction-cm.md)
+ and [CM CLI/API](https://github.com/mlcommons/ck/blob/master/docs/interface.md) to understand CM motivation and concepts.*
+
+## CM script CLI
+
+Whenever a [given CM script]() caches the output, you can find it
+
+Whenever a [CM script](https://access.cknowledge.org/playground/?action=scripts)
+caches its output (such as downloaded model or pre-processed data set or built code),
+you can find it using the CM "cache" automation as follows:
+
+```bash
+cm show cache
+```
+
+You can prune cache entries by tags and variations:
+```bash
+cm show cache --tags=ml-model
+cm show cache --tags=python
+```
+
+You can find a path to a given cache artifact as follows:
+```bash
+cm find cache --tags=ml-model,bert
+```
+
+You can delete one or more cache artifacts as follows:
+```bash
+cm rm cache --tags=ml-model
+```
+
+You can skip user prompt by adding `-f` flag as follows:
+```bash
+cm rm cache --tags=ml-model -f
+```
+
+You can clean the whole cache as follows:
+```bash
+cm rm cache -f
+```
+
+## CM python API
+
+You can access the same functionality via CM Python API as follows:
+
+```python
+
+import cmind
+
+output = cmind.access({'action':'show',
+ 'automation':'cache,541d6f712a6b464e'})
+
+if output['return']>0:
+ cmind.error(output)
+
+artifacts = output['list']
+
+for artifact in artifacts:
+ print ('')
+ print (artifact.path)
+ print (artifact.meta)
+
+```
+
+## Related
+
+* [CM "script" automation](../script/README-extra.md)
diff --git a/automation/cache/README.md b/automation/cache/README.md
new file mode 100644
index 0000000000..0a3114d3b5
--- /dev/null
+++ b/automation/cache/README.md
@@ -0,0 +1,87 @@
+*This README is automatically generated - don't edit! See [extra README](README-extra.md) for extra notes!*
+
+### Automation actions
+
+#### test
+
+ * CM CLI: ```cm test cache``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/cache/module.py#L15))
+ * CM CLI with UID: ```cm test cache,541d6f712a6b464e``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/cache/module.py#L15))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'test'
+ 'automation':'cache,541d6f712a6b464e'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/cache/module.py#L15)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### show
+
+ * CM CLI: ```cm show cache``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/cache/module.py#L54))
+ * CM CLI with UID: ```cm show cache,541d6f712a6b464e``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/cache/module.py#L54))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'show'
+ 'automation':'cache,541d6f712a6b464e'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/cache/module.py#L54)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### search
+
+ * CM CLI: ```cm search cache``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/cache/module.py#L153))
+ * CM CLI with UID: ```cm search cache,541d6f712a6b464e``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/cache/module.py#L153))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'search'
+ 'automation':'cache,541d6f712a6b464e'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/cache/module.py#L153)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### copy_to_remote
+
+ * CM CLI: ```cm copy_to_remote cache``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/cache/module.py#L186))
+ * CM CLI with UID: ```cm copy_to_remote cache,541d6f712a6b464e``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/cache/module.py#L186))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'copy_to_remote'
+ 'automation':'cache,541d6f712a6b464e'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/cache/module.py#L186)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+### Maintainers
+
+* [Open MLCommons taskforce on automation and reproducibility](https://cKnowledge.org/mlcommons-taskforce)
\ No newline at end of file
diff --git a/automation/cache/_cm.json b/automation/cache/_cm.json
new file mode 100644
index 0000000000..ac383f937c
--- /dev/null
+++ b/automation/cache/_cm.json
@@ -0,0 +1,12 @@
+{
+ "alias": "cache",
+ "automation_alias": "automation",
+ "automation_uid": "bbeb15d8f0a944a4",
+ "desc": "Caching cross-platform CM scripts",
+ "developers": "[Arjun Suresh](https://www.linkedin.com/in/arjunsuresh), [Grigori Fursin](https://cKnowledge.org/gfursin)",
+ "sort": 900,
+ "tags": [
+ "automation"
+ ],
+ "uid": "541d6f712a6b464e"
+}
diff --git a/automation/cache/module.py b/automation/cache/module.py
new file mode 100644
index 0000000000..e162d85a75
--- /dev/null
+++ b/automation/cache/module.py
@@ -0,0 +1,212 @@
+import os
+
+from cmind.automation import Automation
+from cmind import utils
+
+class CAutomation(Automation):
+ """
+ Automation actions
+ """
+
+ ############################################################
+ def __init__(self, cmind, automation_file):
+ super().__init__(cmind, __file__)
+
+ ############################################################
+ def test(self, i):
+ """
+ Test automation
+
+ Args:
+ (CM input dict):
+
+ (out) (str): if 'con', output to console
+
+ automation (str): automation as CM string object
+
+ parsed_automation (list): prepared in CM CLI or CM access function
+ [ (automation alias, automation UID) ] or
+ [ (automation alias, automation UID), (automation repo alias, automation repo UID) ]
+
+ (artifact) (str): artifact as CM string object
+
+ (parsed_artifact) (list): prepared in CM CLI or CM access function
+ [ (artifact alias, artifact UID) ] or
+ [ (artifact alias, artifact UID), (artifact repo alias, artifact repo UID) ]
+
+ ...
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ * Output from this automation action
+
+ """
+
+ import json
+ print (json.dumps(i, indent=2))
+
+ return {'return':0}
+
+ ############################################################
+ def show(self, i):
+ """
+ Show cache
+
+ Args:
+ (CM input dict):
+
+ (out) (str): if 'con', output to console
+
+ (env) (bool): if True, show env from cm-cached-state.json
+ ...
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ * Output from this automation action
+
+ """
+ import json
+
+ # Check parsed automation
+ if 'parsed_automation' not in i:
+ return {'return':1, 'error':'automation is not specified'}
+
+ console = i.get('out') == 'con'
+
+ show_env = i.get('env', False)
+
+# Moved to search function
+# # Check simplified CMD: cm show cache "get python"
+# # If artifact has spaces, treat them as tags!
+# artifact = i.get('artifact','')
+# tags = i.get('tags','').strip()
+# if ' ' in artifact or ',' in artifact:
+# del(i['artifact'])
+# if 'parsed_artifact' in i: del(i['parsed_artifact'])
+#
+# new_tags = artifact.replace(' ',',')
+# tags = new_tags if tags=='' else new_tags+','+tags
+#
+# i['tags'] = tags
+
+ # Find CM artifact(s)
+ i['out'] = None
+ r = self.search(i)
+
+ if r['return']>0: return r
+
+ lst = r['list']
+ for artifact in sorted(lst, key = lambda x: sorted(x.meta['tags'])):
+# for artifact in lst:
+ path = artifact.path
+ meta = artifact.meta
+ original_meta = artifact.original_meta
+
+ alias = meta.get('alias','')
+ uid = meta.get('uid','')
+
+ tags = meta.get('tags',[])
+ tags1 = sorted([x for x in tags if not x.startswith('_')])
+ tags2 = sorted([x for x in tags if x.startswith('_')])
+ tags = tags1 + tags2
+
+ version = meta.get('version','')
+
+ if console:
+ print ('')
+# print ('* UID: {}'.format(uid))
+ print ('* Tags: {}'.format(','.join(tags)))
+ print (' Path: {}'.format(path))
+ if version!='':
+ print (' Version: {}'.format(version))
+
+ if show_env and console:
+ path_to_cached_state_file = os.path.join(path, 'cm-cached-state.json')
+
+ if os.path.isfile(path_to_cached_state_file):
+ r = utils.load_json(file_name = path_to_cached_state_file)
+ if r['return']>0: return r
+
+ # Update env and state from cache!
+ cached_state = r['meta']
+
+ new_env = cached_state.get('new_env', {})
+ if len(new_env)>0:
+ print (' New env:')
+ print (json.dumps(new_env, indent=6, sort_keys=True).replace('{','').replace('}',''))
+
+ new_state = cached_state.get('new_state', {})
+ if len(new_state)>0:
+ print (' New state:')
+ print (json.dumps(new_env, indent=6, sort_keys=True))
+
+ return {'return':0, 'list': lst}
+
+ ############################################################
+ def search(self, i):
+ """
+ Overriding the automation search function to add support for a simplified CMD with tags with spaces
+
+ TBD: add input/output description
+ """
+
+ # Check simplified CMD: cm show cache "get python"
+ # If artifact has spaces, treat them as tags!
+ artifact = i.get('artifact','')
+ tags = i.get('tags','')
+ # Tags may be a list (if comes internally from CM scripts) or string if comes from CMD
+ if type(tags)!=list:
+ tags = tags.strip()
+ if ' ' in artifact:# or ',' in artifact:
+ del(i['artifact'])
+ if 'parsed_artifact' in i: del(i['parsed_artifact'])
+
+ new_tags = artifact.replace(' ',',')
+ tags = new_tags if tags=='' else new_tags+','+tags
+
+ i['tags'] = tags
+
+ # Force automation when reruning access with processed input
+ i['automation']='cache,541d6f712a6b464e'
+ i['action']='search'
+ i['common'] = True # Avoid recursion - use internal CM add function to add the script artifact
+
+ # Find CM artifact(s)
+ return self.cmind.access(i)
+
+
+ ############################################################
+ def copy_to_remote(self, i):
+ """
+ Add CM automation.
+
+ Args:
+ (CM input dict):
+
+ (out) (str): if 'con', output to console
+
+ parsed_artifact (list): prepared in CM CLI or CM access function
+ [ (artifact alias, artifact UID) ] or
+ [ (artifact alias, artifact UID), (artifact repo alias, artifact repo UID) ]
+
+ (repos) (str): list of repositories to search for automations (internal & mlcommons@ck by default)
+
+ (output_dir) (str): output directory (./ by default)
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ """
+
+ return utils.call_internal_module(self, __file__, 'module_misc', 'copy_to_remote', i)
diff --git a/automation/cache/module_misc.py b/automation/cache/module_misc.py
new file mode 100644
index 0000000000..cc4a6ac31b
--- /dev/null
+++ b/automation/cache/module_misc.py
@@ -0,0 +1,98 @@
+import os
+from cmind import utils
+
+
+############################################################
+def copy_to_remote(i):
+ """
+ Add CM automation.
+
+ Args:
+ (CM input dict):
+
+ (out) (str): if 'con', output to console
+
+ parsed_artifact (list): prepared in CM CLI or CM access function
+ [ (artifact alias, artifact UID) ] or
+ [ (artifact alias, artifact UID), (artifact repo alias, artifact repo UID) ]
+
+ (repos) (str): list of repositories to search for automations (internal & mlcommons@ck by default)
+
+ (output_dir) (str): output directory (./ by default)
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ """
+
+ self_module = i['self_module']
+
+ remote_host = i.get('remote_host')
+ if not remote_host:
+ return {'return':1, 'error': 'Please input remote host_name/IP via --remote_host'}
+ remote_cm_repos_location = i.get('remote_cm_repos_location', os.path.join("/home", os.getlogin(), "CM", "repos"))
+ remote_cm_cache_location = os.path.join(remote_cm_repos_location, "local", "cache")
+
+ remote_port = i.get('remote_port', '22')
+ remote_user = i.get('remote_user', os.getlogin())
+
+ tag_string = i['tags']
+ tag_string += ",-tmp"
+
+ cm_input = {'action': 'show',
+ 'automation': 'cache',
+ 'tags': f'{tag_string}',
+ 'quiet': True
+ }
+ r = self_module.cmind.access(cm_input)
+ if r['return'] > 0:
+ return r
+
+ if len(r['list']) == 0:
+ pass #fixme
+ elif len(r['list']) > 1:
+ print("Multiple cache entries found: ")
+ for k in sorted(r['list'], key = lambda x: x.meta.get('alias','')):
+ print(k.path)
+ x = input("Would you like to copy them all? Y/n: ")
+ if x.lower() == 'n':
+ return {'return': 0}
+
+ import json
+
+ for k in sorted(r['list'], key = lambda x: x.meta.get('alias','')):
+ path = k.path
+ cacheid = os.path.basename(path)
+
+ copy_cmd = f"rsync -avz --exclude cm-cached-state.json -e 'ssh -p {remote_port}' {path} {remote_user}@{remote_host}:{remote_cm_cache_location}"
+ print(copy_cmd)
+ os.system(copy_cmd)
+
+ cm_cached_state_json_file = os.path.join(path, "cm-cached-state.json")
+ if not os.path.exists(cm_cached_state_json_file):
+ return {'return':1, 'error': f'cm-cached-state.json file missing in {path}'}
+
+ with open(cm_cached_state_json_file, "r") as f:
+ cm_cached_state = json.load(f)
+
+ new_env = cm_cached_state['new_env']
+ new_state = cm_cached_state['new_state'] # Todo fix new state
+ cm_repos_path = os.environ.get('CM_REPOS', os.path.join(os.path.expanduser("~"), "CM", "repos"))
+ cm_cache_path = os.path.realpath(os.path.join(cm_repos_path, "local", "cache"))
+
+ for key,val in new_env.items():
+ if type(val) == str and cm_cache_path in val:
+ new_env[key] = val.replace(cm_cache_path, remote_cm_cache_location)
+
+ with open("tmp_remote_cached_state.json", "w") as f:
+ json.dump(cm_cached_state, f, indent=2)
+
+ remote_cached_state_file_location = os.path.join(remote_cm_cache_location, cacheid, "cm-cached-state.json")
+ copy_cmd = f"rsync -avz -e 'ssh -p {remote_port}' tmp_remote_cached_state.json {remote_user}@{remote_host}:{remote_cached_state_file_location}"
+ print(copy_cmd)
+ os.system(copy_cmd)
+
+ return {'return':0}
diff --git a/automation/cfg/README.md b/automation/cfg/README.md
new file mode 100644
index 0000000000..3c82852c8d
--- /dev/null
+++ b/automation/cfg/README.md
@@ -0,0 +1,27 @@
+*This README is automatically generated - don't edit! Use `README-extra.md` for extra notes!*
+
+### Automation actions
+
+#### test
+
+ * CM CLI: ```cm test cfg``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/cfg/module.py#L15))
+ * CM CLI with UID: ```cm test cfg,88dce9c160324c5d``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/cfg/module.py#L15))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'test'
+ 'automation':'cfg,88dce9c160324c5d'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/cfg/module.py#L15)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+### Maintainers
+
+* [Open MLCommons taskforce on automation and reproducibility](https://cKnowledge.org/mlcommons-taskforce)
\ No newline at end of file
diff --git a/automation/cfg/_cm.json b/automation/cfg/_cm.json
new file mode 100644
index 0000000000..27f80fbd40
--- /dev/null
+++ b/automation/cfg/_cm.json
@@ -0,0 +1,9 @@
+{
+ "alias": "cfg",
+ "automation_alias": "automation",
+ "automation_uid": "bbeb15d8f0a944a4",
+ "tags": [
+ "automation"
+ ],
+ "uid": "88dce9c160324c5d"
+}
diff --git a/automation/cfg/module.py b/automation/cfg/module.py
new file mode 100644
index 0000000000..be8d6e7b1d
--- /dev/null
+++ b/automation/cfg/module.py
@@ -0,0 +1,52 @@
+import os
+
+from cmind.automation import Automation
+from cmind import utils
+
+class CAutomation(Automation):
+ """
+ Automation actions
+ """
+
+ ############################################################
+ def __init__(self, cmind, automation_file):
+ super().__init__(cmind, __file__)
+
+ ############################################################
+ def test(self, i):
+ """
+ Test automation
+
+ Args:
+ (CM input dict):
+
+ (out) (str): if 'con', output to console
+
+ automation (str): automation as CM string object
+
+ parsed_automation (list): prepared in CM CLI or CM access function
+ [ (automation alias, automation UID) ] or
+ [ (automation alias, automation UID), (automation repo alias, automation repo UID) ]
+
+ (artifact) (str): artifact as CM string object
+
+ (parsed_artifact) (list): prepared in CM CLI or CM access function
+ [ (artifact alias, artifact UID) ] or
+ [ (artifact alias, artifact UID), (artifact repo alias, artifact repo UID) ]
+
+ ...
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ * Output from this automation action
+
+ """
+
+ import json
+ print (json.dumps(i, indent=2))
+
+ return {'return':0}
diff --git a/automation/challenge/README.md b/automation/challenge/README.md
new file mode 100644
index 0000000000..2db03e8b16
--- /dev/null
+++ b/automation/challenge/README.md
@@ -0,0 +1,27 @@
+*This README is automatically generated - don't edit! Use `README-extra.md` for extra notes!*
+
+### Automation actions
+
+#### test
+
+ * CM CLI: ```cm test challenge``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/challenge/module.py#L15))
+ * CM CLI with UID: ```cm test challenge,3d84abd768f34e08``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/challenge/module.py#L15))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'test'
+ 'automation':'challenge,3d84abd768f34e08'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/challenge/module.py#L15)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+### Maintainers
+
+* [Open MLCommons taskforce on automation and reproducibility](https://cKnowledge.org/mlcommons-taskforce)
\ No newline at end of file
diff --git a/automation/challenge/_cm.json b/automation/challenge/_cm.json
new file mode 100644
index 0000000000..a4f4164527
--- /dev/null
+++ b/automation/challenge/_cm.json
@@ -0,0 +1,9 @@
+{
+ "alias": "challenge",
+ "automation_alias": "automation",
+ "automation_uid": "bbeb15d8f0a944a4",
+ "tags": [
+ "automation"
+ ],
+ "uid": "3d84abd768f34e08"
+}
diff --git a/automation/challenge/module.py b/automation/challenge/module.py
new file mode 100644
index 0000000000..be8d6e7b1d
--- /dev/null
+++ b/automation/challenge/module.py
@@ -0,0 +1,52 @@
+import os
+
+from cmind.automation import Automation
+from cmind import utils
+
+class CAutomation(Automation):
+ """
+ Automation actions
+ """
+
+ ############################################################
+ def __init__(self, cmind, automation_file):
+ super().__init__(cmind, __file__)
+
+ ############################################################
+ def test(self, i):
+ """
+ Test automation
+
+ Args:
+ (CM input dict):
+
+ (out) (str): if 'con', output to console
+
+ automation (str): automation as CM string object
+
+ parsed_automation (list): prepared in CM CLI or CM access function
+ [ (automation alias, automation UID) ] or
+ [ (automation alias, automation UID), (automation repo alias, automation repo UID) ]
+
+ (artifact) (str): artifact as CM string object
+
+ (parsed_artifact) (list): prepared in CM CLI or CM access function
+ [ (artifact alias, artifact UID) ] or
+ [ (artifact alias, artifact UID), (artifact repo alias, artifact repo UID) ]
+
+ ...
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ * Output from this automation action
+
+ """
+
+ import json
+ print (json.dumps(i, indent=2))
+
+ return {'return':0}
diff --git a/automation/contributor/README.md b/automation/contributor/README.md
new file mode 100644
index 0000000000..df1f4e3d6f
--- /dev/null
+++ b/automation/contributor/README.md
@@ -0,0 +1,47 @@
+*This README is automatically generated - don't edit! Use `README-extra.md` for extra notes!*
+
+### Automation actions
+
+#### test
+
+ * CM CLI: ```cm test contributor``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/contributor/module.py#L15))
+ * CM CLI with UID: ```cm test contributor,68eae17b590d4f8f``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/contributor/module.py#L15))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'test'
+ 'automation':'contributor,68eae17b590d4f8f'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/contributor/module.py#L15)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### add
+
+ * CM CLI: ```cm add contributor``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/contributor/module.py#L54))
+ * CM CLI with UID: ```cm add contributor,68eae17b590d4f8f``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/contributor/module.py#L54))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'add'
+ 'automation':'contributor,68eae17b590d4f8f'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/contributor/module.py#L54)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+### Maintainers
+
+* [Open MLCommons taskforce on automation and reproducibility](https://cKnowledge.org/mlcommons-taskforce)
\ No newline at end of file
diff --git a/automation/contributor/_cm.json b/automation/contributor/_cm.json
new file mode 100644
index 0000000000..008f7d54c9
--- /dev/null
+++ b/automation/contributor/_cm.json
@@ -0,0 +1,9 @@
+{
+ "alias": "contributor",
+ "automation_alias": "automation",
+ "automation_uid": "bbeb15d8f0a944a4",
+ "tags": [
+ "automation"
+ ],
+ "uid": "68eae17b590d4f8f"
+}
diff --git a/automation/contributor/module.py b/automation/contributor/module.py
new file mode 100644
index 0000000000..82807638f8
--- /dev/null
+++ b/automation/contributor/module.py
@@ -0,0 +1,153 @@
+import os
+
+from cmind.automation import Automation
+from cmind import utils
+
+class CAutomation(Automation):
+ """
+ Automation actions
+ """
+
+ ############################################################
+ def __init__(self, cmind, automation_file):
+ super().__init__(cmind, __file__)
+
+ ############################################################
+ def test(self, i):
+ """
+ Test automation
+
+ Args:
+ (CM input dict):
+
+ (out) (str): if 'con', output to console
+
+ automation (str): automation as CM string object
+
+ parsed_automation (list): prepared in CM CLI or CM access function
+ [ (automation alias, automation UID) ] or
+ [ (automation alias, automation UID), (automation repo alias, automation repo UID) ]
+
+ (artifact) (str): artifact as CM string object
+
+ (parsed_artifact) (list): prepared in CM CLI or CM access function
+ [ (artifact alias, artifact UID) ] or
+ [ (artifact alias, artifact UID), (artifact repo alias, artifact repo UID) ]
+
+ ...
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ * Output from this automation action
+
+ """
+
+ import json
+ print (json.dumps(i, indent=2))
+
+ return {'return':0}
+
+ ############################################################
+ def add(self, i):
+ """
+ Add CM script
+
+ Args:
+ (CM input dict):
+
+ (out) (str): if 'con', output to console
+
+ ...
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ """
+
+ self_automation = self.meta['alias']+','+self.meta['uid']
+
+ console = i.get('out') == 'con'
+
+ artifact = i.get('artifact','')
+ if ':' not in artifact:
+ artifact = 'mlcommons@ck:'+artifact
+
+ j = artifact.find(':')
+ name = artifact[j+1:]
+
+ # Check info
+ if name == '':
+ name = input('Enter your name: ').strip()
+ if name == '':
+ return {'return':1, 'error':'name can\'t be empty'}
+
+ artifact += name
+
+ # Check if doesn't exist
+ r = self.cmind.access({'action':'find',
+ 'automation':self_automation,
+ 'artifact':artifact})
+ if r['return']>0: return r
+ elif r['return']==0 and len(r['list'])>0:
+ return {'return':1, 'error':'CM artifact with name {} already exists in {}'.format(name, r['list'][0].path)}
+
+ meta = i.get('meta',{})
+
+ # Prepare meta
+ org = meta.get('organization','')
+ if org=='':
+ org = input('Enter your organization (optional): ').strip()
+
+ url = input('Enter your webpage (optional): ').strip()
+
+ tags = input('Enter tags of your challenges separate by comma (you can add them later): ').strip()
+
+ if meta.get('name','')=='':
+ meta = {'name':name}
+
+ if org!='':
+ meta['organization'] = org
+
+ if url!='':
+ meta['urls'] = [url]
+
+ if tags!='':
+ meta['ongoing'] = tags.split(',')
+
+ # Add placeholder (use common action)
+ i['out'] = 'con'
+ i['common'] = True # Avoid recursion - use internal CM add function to add the script artifact
+
+ i['action'] = 'add'
+ i['automation'] = self_automation
+ i['artifact'] = artifact
+
+ i['meta'] = meta
+
+ print ('')
+
+ r = self.cmind.access(i)
+ if r['return']>0: return r
+
+ path = r['path']
+
+ path2 = os.path.dirname(path)
+
+ print ('')
+ print ('Please go to {}, add your directory to Git, commit and create PR:'.format(path2))
+ print ('')
+ print ('cd {}'.format(path2))
+ print ('git add "{}"'.format(name))
+ print ('git commit "{}"'.format(name))
+ print ('')
+ print ('Please join https://discord.gg/JjWNWXKxwT to discuss challenges!')
+ print ('Looking forward to your contributions!')
+
+ return r
diff --git a/automation/data/_cm.json b/automation/data/_cm.json
new file mode 100644
index 0000000000..7dd9a139f3
--- /dev/null
+++ b/automation/data/_cm.json
@@ -0,0 +1,9 @@
+{
+ "alias": "data",
+ "automation_alias": "automation",
+ "automation_uid": "bbeb15d8f0a944a4",
+ "tags": [
+ "automation"
+ ],
+ "uid": "84d8ef6914bf4d78"
+}
diff --git a/automation/data/module.py b/automation/data/module.py
new file mode 100644
index 0000000000..be8d6e7b1d
--- /dev/null
+++ b/automation/data/module.py
@@ -0,0 +1,52 @@
+import os
+
+from cmind.automation import Automation
+from cmind import utils
+
+class CAutomation(Automation):
+ """
+ Automation actions
+ """
+
+ ############################################################
+ def __init__(self, cmind, automation_file):
+ super().__init__(cmind, __file__)
+
+ ############################################################
+ def test(self, i):
+ """
+ Test automation
+
+ Args:
+ (CM input dict):
+
+ (out) (str): if 'con', output to console
+
+ automation (str): automation as CM string object
+
+ parsed_automation (list): prepared in CM CLI or CM access function
+ [ (automation alias, automation UID) ] or
+ [ (automation alias, automation UID), (automation repo alias, automation repo UID) ]
+
+ (artifact) (str): artifact as CM string object
+
+ (parsed_artifact) (list): prepared in CM CLI or CM access function
+ [ (artifact alias, artifact UID) ] or
+ [ (artifact alias, artifact UID), (artifact repo alias, artifact repo UID) ]
+
+ ...
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ * Output from this automation action
+
+ """
+
+ import json
+ print (json.dumps(i, indent=2))
+
+ return {'return':0}
diff --git a/automation/docker/README.md b/automation/docker/README.md
new file mode 100644
index 0000000000..c6ef9a3842
--- /dev/null
+++ b/automation/docker/README.md
@@ -0,0 +1,27 @@
+*This README is automatically generated - don't edit! Use `README-extra.md` for extra notes!*
+
+### Automation actions
+
+#### test
+
+ * CM CLI: ```cm test docker``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/docker/module.py#L15))
+ * CM CLI with UID: ```cm test docker,2d90be7cab6e4d9f``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/docker/module.py#L15))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'test'
+ 'automation':'docker,2d90be7cab6e4d9f'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/docker/module.py#L15)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+### Maintainers
+
+* [Open MLCommons taskforce on automation and reproducibility](https://cKnowledge.org/mlcommons-taskforce)
\ No newline at end of file
diff --git a/automation/docker/_cm.json b/automation/docker/_cm.json
new file mode 100644
index 0000000000..11a5085d0e
--- /dev/null
+++ b/automation/docker/_cm.json
@@ -0,0 +1,11 @@
+{
+ "alias": "docker",
+ "automation_alias": "automation",
+ "automation_uid": "bbeb15d8f0a944a4",
+ "desc": "Managing modular docker containers (under development)",
+ "developers": "[Arjun Suresh](https://www.linkedin.com/in/arjunsuresh), [Grigori Fursin](https://cKnowledge.org/gfursin)",
+ "tags": [
+ "automation"
+ ],
+ "uid": "2d90be7cab6e4d9f"
+}
diff --git a/automation/docker/module.py b/automation/docker/module.py
new file mode 100644
index 0000000000..aaf0f7802c
--- /dev/null
+++ b/automation/docker/module.py
@@ -0,0 +1,51 @@
+import os
+
+from cmind.automation import Automation
+from cmind import utils
+
+class CAutomation(Automation):
+ """
+ CM "docker" automation actions
+ """
+
+ ############################################################
+ def __init__(self, cmind, automation_file):
+ super().__init__(cmind, __file__)
+
+ ############################################################
+ def test(self, i):
+ """
+ Test automation
+
+ Args:
+ (CM input dict):
+
+ (out) (str): if 'con', output to console
+
+ automation (str): automation as CM string object
+
+ (artifact) (str): artifact as CM string object
+
+ parsed_automation (list): prepared in CM CLI or CM access function
+ [ (automation alias, automation UID) ] or
+ [ (automation alias, automation UID), (automation repo alias, automation repo UID) ]
+
+ (parsed_artifact) (list): prepared in CM CLI or CM access function
+ [ (artifact alias, artifact UID) ] or
+ [ (artifact alias, artifact UID), (artifact repo alias, artifact repo UID) ]
+
+ ...
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ * Output from this automation action
+ """
+
+ import json
+ print (json.dumps(i, indent=2))
+
+ return {'return':0}
diff --git a/automation/docs/_cm.json b/automation/docs/_cm.json
new file mode 100644
index 0000000000..6945baccaf
--- /dev/null
+++ b/automation/docs/_cm.json
@@ -0,0 +1,9 @@
+{
+ "alias": "docs",
+ "automation_alias": "automation",
+ "automation_uid": "bbeb15d8f0a944a4",
+ "tags": [
+ "automation"
+ ],
+ "uid": "9558c9e6ca124065"
+}
diff --git a/automation/docs/module.py b/automation/docs/module.py
new file mode 100644
index 0000000000..be8d6e7b1d
--- /dev/null
+++ b/automation/docs/module.py
@@ -0,0 +1,52 @@
+import os
+
+from cmind.automation import Automation
+from cmind import utils
+
+class CAutomation(Automation):
+ """
+ Automation actions
+ """
+
+ ############################################################
+ def __init__(self, cmind, automation_file):
+ super().__init__(cmind, __file__)
+
+ ############################################################
+ def test(self, i):
+ """
+ Test automation
+
+ Args:
+ (CM input dict):
+
+ (out) (str): if 'con', output to console
+
+ automation (str): automation as CM string object
+
+ parsed_automation (list): prepared in CM CLI or CM access function
+ [ (automation alias, automation UID) ] or
+ [ (automation alias, automation UID), (automation repo alias, automation repo UID) ]
+
+ (artifact) (str): artifact as CM string object
+
+ (parsed_artifact) (list): prepared in CM CLI or CM access function
+ [ (artifact alias, artifact UID) ] or
+ [ (artifact alias, artifact UID), (artifact repo alias, artifact repo UID) ]
+
+ ...
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ * Output from this automation action
+
+ """
+
+ import json
+ print (json.dumps(i, indent=2))
+
+ return {'return':0}
diff --git a/automation/experiment/README-extra.md b/automation/experiment/README-extra.md
new file mode 100644
index 0000000000..c098acc14e
--- /dev/null
+++ b/automation/experiment/README-extra.md
@@ -0,0 +1,315 @@
+[ [Back to index](../../../docs/README.md) ]
+
+
+Click here to see the table of contents.
+
+* [CM "experiment" automation](#cm-"experiment"-automation)
+ * [Introducing CM experiment automation](#introducing-cm-experiment-automation)
+ * [Installing CM with ResearchOps/DevOps/MLOps automations](#installing-cm-with-researchops/devops/mlops-automations)
+ * [Understanding CM experiments](#understanding-cm-experiments)
+ * [Exploring combinations of parameters (autotuning, design space exploration)](#exploring-combinations-of-parameters-autotuning-design-space-exploration)
+ * [Aggregating and unifying results](#aggregating-and-unifying-results)
+ * [Visualizing results](#visualizing-results)
+ * [Sharing experiments with the community](#sharing-experiments-with-the-community)
+ * [Running CM experiments with CM scripts](#running-cm-experiments-with-cm-scripts)
+ * [Further community developments](#further-community-developments)
+
+
+
+# CM "experiment" automation
+
+*We suggest you to check [CM introduction](https://github.com/mlcommons/ck/blob/master/docs/introduction-cm.md),
+ [CM CLI/API](https://github.com/mlcommons/ck/blob/master/docs/interface.md)
+ and [CM scripts](../script/README-extra.md) to understand CM motivation and concepts.
+ You can also try [CM tutorials](https://github.com/mlcommons/ck/blob/master/docs/tutorials/README.md)
+ to run some applications and benchmarks on your platform using CM scripts.*
+
+## Introducing CM experiment automation
+
+
+Researchers, engineers and students spend considerable amount of their time experimenting with
+many different settings of applications, tools, compilers, software and hardware
+to find the optimal combination suitable for their use cases.
+
+Based on their feedback, our [MLCommons taskforce on automation and reproducibility](https://github.com/mlcommons/ck/blob/master/docs/taskforce.md)
+started developing a CM automation called "experiment".
+The goal is to provide a common interface to run, record, share, visualize and reproduce experiments
+on any platform with any software, hardware and data.
+
+The community helped us test a prototype of our "experiment" automation to record results in a unified CM format
+from [several MLPerf benchmarks](https://github.com/mlcommons/cm4mlperf-results)
+including [MLPerf inference](https://github.com/mlcommons/inference) and [MLPerf Tiny](https://github.com/mlcommons/tiny),
+visualize them at the [MLCommons CM platform](https://access.cknowledge.org/playground/?action=experiments&tags=all),
+and improve them by the community via [public benchmarking, optimization and reproducibility challenges](https://access.cknowledge.org/playground/?action=challenges).
+
+
+
+## Installing CM with ResearchOps/DevOps/MLOps automations
+
+This CM automation is available in the most commonly used `mlcommons@ck` repository.
+
+First, install CM automation language as described [here](https://github.com/mlcommons/ck/blob/master/docs/installation.md).
+Then, install or update this repository as follows:
+```bash
+cm pull repo mlcommons@ck
+```
+
+You can now test that CM experiment automation is available as follows:
+```bash
+cm run experiment --help
+```
+or using `cme` shortcut in CM V1.4.1+
+```bash
+cme --help
+```
+
+
+
+## Understanding CM experiments
+
+CM experiment simply wraps any user command line, creates an associated CM `experiment` artifact with a random ID (16 low case HEX characters)
+and some user tags in `_cm.json`, creates extra `{date}{time}` subdirectory with `cm-input.json` file with CM input,
+and executes the user command line inside an extra subdirectory with another random ID as shown below.
+
+The following command will print "Hello World!" while recording all the provenance in CM format in the local CM repository:
+
+```bash
+cme --tags=my,experiment,hello-world -- echo "Hello World!"
+```
+or
+```bash
+cm run experiment --tags=my,experiment,hello-world -- echo "Hello World!"
+```
+
+You should see the output similar to the following:
+```bash
+
+Path to CM experiment artifact: C:\Users\gfursin\CM\repos\local\experiment\b83a1fb24dbf4945
+Path to experiment: C:\Users\gfursin\CM\repos\local\experiment\b83a1fb24dbf4945\2023-06-09.09-58-02.863466
+================================================================
+Experiment step: 1 out of 1
+
+Path to experiment step: C:\Users\gfursin\CM\repos\local\experiment\b83a1fb24dbf4945\2023-06-09.09-58-02.863466\7ed0ea0edd6b4dd7
+
+"Hello World!"
+```
+
+You can find and explore the newly created CM artifact as follows:
+```bash
+cm find experiment --tags=my,experiment,hello-world
+```
+or using UID
+```bash
+cm find experiment b83a1fb24dbf4945
+```
+
+When running the same experiment again, CM will find existing artifact by tags and create new {date}{time} directory there:
+```bash
+cme --tags=my,experiment,hello-world -- echo "Hello World!"
+
+Path to CM experiment artifact: C:\Users\gfursin\CM\repos\local\experiment\b83a1fb24dbf4945
+Path to experiment: C:\Users\gfursin\CM\repos\local\experiment\b83a1fb24dbf4945\2023-06-09.10-02-08.911210
+================================================================
+Experiment step: 1 out of 1
+
+Path to experiment step: C:\Users\gfursin\CM\repos\local\experiment\b83a1fb24dbf4945\2023-06-09.10-02-08.911210\7ed0ea0edd6b4dd7
+
+"Hello World!"
+```
+
+You can now replay this experiment as follows:
+```bash
+cm replay experiment --tags=my,experiment,hello-world
+```
+
+Note that you can obtain current directory where you called CM
+(rather than the CM experiment artifact directory) via {{CD}} variable as follows:
+```bash
+cme --tags=my,experiment,hello-world -- echo {{CD}}
+```
+
+You can also record experiments in another CM repository instead of the `local` one as follows:
+```bash
+cm list repo
+cme {CM repository from above list}: --tags=my,experiment,hello-world -- echo {{CD}}
+```
+
+Finally, you can force a specific artifact name instead of some random ID as follows:
+```bash
+cme {my experiment artifact name} --tags=my,experiment,hello-world -- echo {{CD}}
+```
+or with given repository
+```bash
+cme {CM repository from above list}:{my experiment artifact name} --tags=my,experiment,hello-world -- echo {{CD}}
+```
+
+## Exploring combinations of parameters (autotuning, design space exploration)
+
+One of the most common tasks is computer engineering (and other sciences)
+is to explore various combinations of parameters of some applications
+and systems to select the optimal ones to trade off performance, accuracy,
+power consumption, memory usage and other characteristics.
+
+As a starting point, we have implemented a very simple explorer as a Cartesian product
+of any number of specified variables that are passed to a user command line via double curly braces `{{VAR}}` similar to GitHub.
+
+You just need to create a simple JSON file `cm-input.json` to describe sets/ranges for each variable as follows:
+```json
+{
+ "explore": {
+ "VAR1": [
+ 1,
+ 2,
+ 3
+ ],
+ "VAR2": [
+ "a",
+ "b"
+ ],
+ "VAR3": "[2**i for i in range(0,6)]"
+ }
+}
+```
+
+or YAML `cm-input.yaml`:
+
+```yaml
+explore:
+ VAR1: [1,2,3]
+ VAR2: ["a","b"]
+ VAR3: "[2**i for i in range(0,6)]"
+```
+
+You can then run the following example to see all iterations:
+```bash
+cm run experiment --tags=my,experiment,hello-world @test_input.yaml \
+ -- echo %VAR1% --batch_size={{VAR1}} {{VAR2}} {{VAR4{['xx','yy','zz']}}}-%%VAR3%%
+```
+
+Note that you can also define a Python list of range for other variables
+directly in the command line as demonstrated in above example for `VAR4` - `{{VAR4{['xx','yy','zz']}}}`.
+
+CM will create or reuse experiment artifact with tags `my,experiment,hello-world`
+and will then iterate in a Cartesian product of all detected variables.
+
+For each iteration, CM will create a `{date}{time}` subdirectory in a given experiment artifact
+and will then run a user command line with substituted variables there.
+
+You can then replay any of the exploration experiment as follows:
+```bash
+cm replay experiment --tags={tags} --dir={sub directory}
+```
+
+
+
+## Aggregating and unifying results
+
+Users can expose any information such as measured characteristics of their applications and/or systems (performance,
+hardware or OS state, accuracy, internal parameters, etc) to CM for further analysis and visualization
+by generating a JSON `cm-result.json` file with any dictionary.
+
+If this file exists after executing a user command, CM will load it after each experiment or exploration step,
+and merge it with a list in a common `cm-result.json` in `{date}{time}` directory for this experiment.
+
+
+
+## Visualizing results
+
+Users can now visualize multiple experiments using the CM GUI script as follows:
+```bash
+cm run script "gui _graph" --exp_tags=my,experiment,hello-world
+```
+
+This script will search for all CM experiment entries with these tags, read all `cm-result.json` files,
+detect all keys used in result dictionaries, let users select these keys for X and Y axes
+to prepare a 2D graph using a popular [StreamLit library](https://streamlit.io), add derived metrics and set constraints
+as shown in the following example for one of the official [Tiny MLPerf submissions](https://github.com/mlcommons/tiny):
+
+
+
+
+
+
+
+
+## Sharing experiments with the community
+
+It is possible to share experiments with a common automation interface
+in your own GitHub/GitLab repository, container and zip/tar file
+in a non-intrusive way.
+
+You need to go to a root directory of your project and initialize CM repository there
+with a unique name "my-cool-project" as follows:
+
+```bash
+cm init repo my-cool-project --path=. --prefix=cmr
+```
+
+This command will create a `cmr.yaml` file with a description and unique ID of this repository,
+and will register it in the CM. Note that all CM automations and artifacts will be located
+in the `cmr` sub-directory to avoid contaminating your project. They can be deleted
+or moved to another project at any time.
+
+You can now record new experiments in this repository by adding `my-cool-project:` to the cm experiment command line as follows:
+```bash
+cm run experiment my-cool-project: --tags=my,experiment,hello-world -- echo "Hello World!"
+```
+
+You can also move a set of existing experiments from the `local` CM repository to the new one as follows:
+```bash
+cm move experiment my-cool-project: --tags=my,experiment,hello-world
+```
+
+You can continue replaying these experiments in the way no matter what CM repository they are in:
+```bash
+cm replay experiment --tags=my,experiment,hello-world
+```
+
+or you can enforce a specific repository as follows:
+```bash
+cm replay experiment my-cool-project: --tags=my,experiment,hello-world
+```
+
+
+
+
+
+## Running CM experiments with CM scripts
+
+User scripts and tools may contain some hardwired local paths that may prevent replaying them on another platform.
+In such case, we suggest you to use [CM scripts](/../script/README-extra.md).
+
+CM scripts solve this problem by wrapping existing user scripts and tools and detecting/resolving paths
+to specific tools and artifacts on a given user platform.
+
+You can find example of using CM scripts with CM experiments in [this directory](tests) - see `test3.bat` or `test3.sh`:
+```bash
+cm run experiment --tags=test @test3_input.yaml -- cm run script "print hello-world native" --env.CM_ENV_TEST1={{VAR1}} --const.CM_ENV_TEST2={{VAR2}}
+```
+
+You can use the following environment variables to pass the current path,
+different paths to experiment entries and the number of experiment to your CM script:
+* {{CD}}
+* {{CM_EXPERIMENT_STEP}}
+* {{CM_EXPERIMENT_PATH}}
+* {{CM_EXPERIMENT_PATH2}}
+* {{CM_EXPERIMENT_PATH3}}
+
+
+Feel free to check [this tutorial](../../../docs/tutorials/common-interface-to-reproduce-research-projects.md)
+to add CM scripts for your own applications, tools and native scripts.
+
+We are currently extending CM experiments and CM scripts for MLPerf benchmarks
+to automate benchmarking, optimization and design space exploration of ML/AI systems
+on any software and hardware - please stay tuned via our [Discord server](https://discord.gg/JjWNWXKxwT).
+
+
+
+## Further community developments
+
+We are developing this experiment automation in CM to help the community share, reproduce and reuse experiments
+using a common, simple, human readable, and portable [automation language](../../../docs/README.md).
+
+Join our [Discord server](https://discord.gg/JjWNWXKxwT) from the [MLCommons task force on automation and reproducibility](../taskforce.md)
+to participate in the unification and extension of this interface and CM scripts for diverse research projects and tools.
+
diff --git a/automation/experiment/README.md b/automation/experiment/README.md
new file mode 100644
index 0000000000..13ea6ec1a5
--- /dev/null
+++ b/automation/experiment/README.md
@@ -0,0 +1,87 @@
+*This README is automatically generated - don't edit! See [extra README](README-extra.md) for extra notes!*
+
+### Automation actions
+
+#### test
+
+ * CM CLI: ```cm test experiment``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/experiment/module.py#L22))
+ * CM CLI with UID: ```cm test experiment,a0a2d123ef064bcb``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/experiment/module.py#L22))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'test'
+ 'automation':'experiment,a0a2d123ef064bcb'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/experiment/module.py#L22)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### run
+
+ * CM CLI: ```cm run experiment``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/experiment/module.py#L64))
+ * CM CLI with UID: ```cm run experiment,a0a2d123ef064bcb``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/experiment/module.py#L64))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'run'
+ 'automation':'experiment,a0a2d123ef064bcb'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/experiment/module.py#L64)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### rerun
+
+ * CM CLI: ```cm rerun experiment``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/experiment/module.py#L428))
+ * CM CLI with UID: ```cm rerun experiment,a0a2d123ef064bcb``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/experiment/module.py#L428))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'rerun'
+ 'automation':'experiment,a0a2d123ef064bcb'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/experiment/module.py#L428)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### replay
+
+ * CM CLI: ```cm replay experiment``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/experiment/module.py#L451))
+ * CM CLI with UID: ```cm replay experiment,a0a2d123ef064bcb``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/experiment/module.py#L451))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'replay'
+ 'automation':'experiment,a0a2d123ef064bcb'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/experiment/module.py#L451)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+### Maintainers
+
+* [Open MLCommons taskforce on automation and reproducibility](https://cKnowledge.org/mlcommons-taskforce)
\ No newline at end of file
diff --git a/automation/experiment/_cm.json b/automation/experiment/_cm.json
new file mode 100644
index 0000000000..49bb0e6166
--- /dev/null
+++ b/automation/experiment/_cm.json
@@ -0,0 +1,11 @@
+{
+ "alias": "experiment",
+ "automation_alias": "automation",
+ "automation_uid": "bbeb15d8f0a944a4",
+ "desc": "Managing and reproducing experiments (under development)",
+ "developers": "[Grigori Fursin](https://cKnowledge.org/gfursin)",
+ "tags": [
+ "automation"
+ ],
+ "uid": "a0a2d123ef064bcb"
+}
diff --git a/automation/experiment/module.py b/automation/experiment/module.py
new file mode 100644
index 0000000000..3c6490d0d6
--- /dev/null
+++ b/automation/experiment/module.py
@@ -0,0 +1,804 @@
+import os
+import itertools
+import copy
+import json
+
+from cmind.automation import Automation
+from cmind import utils
+
+class CAutomation(Automation):
+ """
+ CM "experiment" automation actions
+ """
+
+ CM_RESULT_FILE = 'cm-result.json'
+ CM_INPUT_FILE = 'cm-input.json'
+ CM_OUTPUT_FILE = 'cm-output.json'
+
+ ############################################################
+ def __init__(self, cmind, automation_file):
+ super().__init__(cmind, __file__)
+
+ ############################################################
+ def test(self, i):
+ """
+ Test automation
+
+ Args:
+ (CM input dict):
+
+ (out) (str): if 'con', output to console
+
+ automation (str): automation as CM string object
+
+ parsed_automation (list): prepared in CM CLI or CM access function
+ [ (automation alias, automation UID) ] or
+ [ (automation alias, automation UID), (automation repo alias, automation repo UID) ]
+
+ (artifact) (str): artifact as CM string object
+
+ (parsed_artifact) (list): prepared in CM CLI or CM access function
+ [ (artifact alias, artifact UID) ] or
+ [ (artifact alias, artifact UID), (artifact repo alias, artifact repo UID) ]
+
+ ...
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ * Output from this automation action
+ """
+
+ import json
+ print (json.dumps(i, indent=2))
+
+ return {'return':0}
+
+
+
+
+
+ ############################################################
+ def run(self, i):
+ """
+ Run experiment
+
+ Args:
+ (CM input dict):
+
+ (out) (str): if 'con', output to console
+
+ (artifact) (str): experiment artifact name (can include repository separated by :)
+ (tags) (str): experiment tags separated by comma
+
+ (dir) (str): force recording into a specific directory
+
+
+ (script) (str): find and run CM script by name
+ (s)
+
+ (script_tags) (str): find and run CM script by tags
+ (stags)
+
+ (rerun) (bool): if True, rerun experiment in a given entry/directory instead of creating a new one...
+
+ (explore) (dict): exploration dictionary
+
+ ...
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ * Output from this automation action
+ """
+
+ # Copy of original input
+ ii_copy = copy.deepcopy(i)
+ cur_dir = os.getcwd()
+
+ # Find or add artifact based on repo/alias/tags
+ r = self._find_or_add_artifact(i)
+ if r['return']>0: return r
+
+ experiment = r['experiment']
+
+ console = i.get('out','')=='con'
+
+ # Print experiment folder
+ experiment_path = experiment.path
+
+ if console:
+ print ('')
+ print ('Path to CM experiment artifact: {}'.format(experiment_path))
+
+
+ # Get directory with datetime
+ datetime = i.get('dir','')
+
+ if datetime == '' and i.get('rerun', False):
+ # Check if already some dir exist
+
+ directories = os.listdir(experiment_path)
+
+ datetimes = sorted([f for f in directories if os.path.isfile(os.path.join(experiment_path, f, self.CM_RESULT_FILE))], reverse=True)
+
+ if len(datetimes)==1:
+ datetime = datetimes[0]
+ elif len(datetimes)>1:
+ print ('')
+ print ('Select experiment:')
+
+ datetimes = sorted(datetimes)
+
+ num = 0
+ print ('')
+ for d in datetimes:
+ print ('{}) {}'.format(num, d.replace('.',' ')))
+ num += 1
+
+ if not console:
+ return {'return':1, 'error':'more than 1 experiment found.\nPlease use "cm rerun experiment --dir={date and time}"'}
+
+ print ('')
+ x=input('Make your selection or press Enter for 0: ')
+
+ x=x.strip()
+ if x=='': x='0'
+
+ selection = int(x)
+
+ if selection < 0 or selection >= num:
+ selection = 0
+
+ datetime = datetimes[selection]
+
+
+ if datetime!='':
+ experiment_path2 = os.path.join(experiment_path, datetime)
+ else:
+ num = 0
+ found = False
+
+ while not found:
+ r = utils.get_current_date_time({})
+ if r['return']>0: return r
+
+ datetime = r['iso_datetime'].replace(':','-').replace('T','.')
+
+ if num>0:
+ datetime+='.'+str(num)
+
+ experiment_path2 = os.path.join(experiment_path, datetime)
+
+ if not os.path.isdir(experiment_path2):
+ found = True
+ break
+
+ num+=1
+
+ # Check/create directory with date_time
+ if not os.path.isdir(experiment_path2):
+ os.makedirs(experiment_path2)
+
+ # Change current path
+ print ('Path to experiment: {}'.format(experiment_path2))
+
+ os.chdir(experiment_path2)
+
+ # Record experiment input with possible exploration
+ experiment_input_file = os.path.join(experiment_path2, self.CM_INPUT_FILE)
+ experiment_result_file = os.path.join(experiment_path2, self.CM_RESULT_FILE)
+
+ # Clean original input
+ for k in ['parsed_artifact', 'parsed_automation', 'cmd']:
+ if k in ii_copy:
+ del(ii_copy[k])
+
+ r = utils.save_json(file_name=experiment_input_file, meta=ii_copy)
+ if r['return']>0: return r
+
+ # Prepare run command
+ cmd = ''
+
+ unparsed = i.get('unparsed_cmd', [])
+ if len(unparsed)>0:
+ for u in unparsed:
+ if ' ' in u: u='"'+u+'"'
+ cmd+=' '+u
+
+ cmd=cmd.strip()
+
+ # Prepare script run
+ env = i.get('env', {})
+
+ ii = {'action':'native-run',
+ 'automation':'script,5b4e0237da074764',
+ 'env':env}
+
+ # Prepare exploration
+ # Note that from Python 3.7, dictionaries are ordered so we can define order for exploration in json/yaml
+ # ${{XYZ}} ${{ABC(range(1,2,3))}}
+
+ # Extract exploration expressions from {{VAR{expression}}}
+ explore = i.get('explore', {})
+
+ j = 1
+ k = 0
+ while j>=0:
+ j = cmd.find('}}}', k)
+ if j>=0:
+ k = j+1
+
+ l = cmd.rfind('{{',0, j)
+
+ if l>=0:
+ l2 = cmd.find('{', l+2, j)
+ if l2>=0:
+ k = l2+1
+
+ var = cmd[l+2:l2]
+ expr = cmd[l2+1:j]
+
+ explore[var] = expr
+
+ cmd = cmd[:l2]+ cmd[j+1:]
+
+
+ # Separate Design Space Exploration into var and range
+ explore_keys=[]
+ explore_dimensions=[]
+
+ for k in explore:
+ v=explore[k]
+
+ explore_keys.append(k)
+
+ if type(v)!=list:
+ v=eval(v)
+
+ explore_dimensions.append(v)
+
+ # Next command will run all iterations so we need to redo above command once again
+ step = 0
+
+ steps = itertools.product(*explore_dimensions)
+
+ num_steps = len(list(steps))
+
+ steps = itertools.product(*explore_dimensions)
+
+ ii_copy = copy.deepcopy(ii)
+
+ for dimensions in steps:
+
+ step += 1
+
+ print ('================================================================')
+ print ('Experiment step: {} out of {}'.format(step, num_steps))
+
+ print ('')
+
+ ii = copy.deepcopy(ii_copy)
+
+ env = ii.get('env', {})
+
+ l_dimensions=len(dimensions)
+ if l_dimensions>0:
+ print (' Updating ENV variables during exploration:')
+
+ print ('')
+ for j in range(l_dimensions):
+ v = dimensions[j]
+ k = explore_keys[j]
+ print (' - Dimension {}: "{}" = {}'.format(j, k, v))
+
+ env[k] = str(v)
+
+ print ('')
+
+ # Generate UID and prepare extra directory:
+ r = utils.gen_uid()
+ if r['return']>0: return r
+
+ uid = r['uid']
+
+ experiment_path3 = os.path.join(experiment_path2, uid)
+ if not os.path.isdir(experiment_path3):
+ os.makedirs(experiment_path3)
+
+ # Get date time of experiment
+ r = utils.get_current_date_time({})
+ if r['return']>0: return r
+
+ current_datetime = r['iso_datetime']
+
+ # Change current path
+ print ('Path to experiment step: {}'.format(experiment_path3))
+ print ('')
+ os.chdir(experiment_path3)
+
+ # Prepare and run experiment in a given placeholder directory
+ os.chdir(experiment_path3)
+
+ ii['env'] = env
+
+ # Change only in CMD
+ env_local={'CD':cur_dir,
+ 'CM_EXPERIMENT_STEP':str(step),
+ 'CM_EXPERIMENT_PATH':experiment_path,
+ 'CM_EXPERIMENT_PATH2':experiment_path2,
+ 'CM_EXPERIMENT_PATH3':experiment_path3}
+
+
+ # Update {{}} in CMD
+ cmd_step = cmd
+
+ j = 1
+ k = 0
+ while j>=0:
+ j = cmd_step.find('{{', k)
+ if j>=0:
+ k = j
+ l = cmd_step.find('}}',j+2)
+ if l>=0:
+ var = cmd_step[j+2:l]
+
+ # Such vars must be in env
+ if var not in env and var not in env_local:
+ return {'return':1, 'error':'key "{}" is not in env during exploration'.format(var)}
+
+ if var in env:
+ value = env[var]
+ else:
+ value = env_local[var]
+
+ cmd_step = cmd_step[:j] + str(value) + cmd_step[l+2:]
+
+ ii['command'] = cmd_step
+
+ print ('Generated CMD:')
+ print ('')
+ print (cmd_step)
+ print ('')
+
+ # Prepare experiment step input
+ experiment_step_input_file = os.path.join(experiment_path3, self.CM_INPUT_FILE)
+
+ r = utils.save_json(file_name=experiment_step_input_file, meta=ii)
+ if r['return']>0: return r
+
+ experiment_step_output_file = os.path.join(experiment_path3, self.CM_OUTPUT_FILE)
+ if os.path.isfile(experiment_step_output_file):
+ os.delete(experiment_step_output_file)
+
+ # Run CMD
+ rr=self.cmind.access(ii)
+ if rr['return']>0: return rr
+
+ # Record output
+ result = {}
+
+ if os.path.isfile(experiment_step_output_file):
+ r = utils.load_json(file_name=experiment_step_output_file)
+ if r['return']>0: return r
+
+ result = r['meta']
+
+ #Try to flatten
+ try:
+ flatten_result = flatten_dict(result)
+ result = flatten_result
+ except:
+ pass
+
+ # Add extra info
+ result['uid'] = uid
+ result['iso_datetime'] = current_datetime
+
+ # Attempt to append to the main file ...
+ all_results = []
+
+ if os.path.isfile(experiment_result_file):
+ r = utils.load_json(file_name=experiment_result_file)
+ if r['return']>0: return r
+
+ all_results = r['meta']
+
+ all_results.append(result)
+
+ r = utils.save_json(file_name=experiment_result_file, meta = all_results)
+ if r['return']>0: return r
+
+
+ rr = {'return':0,
+ 'experiment_path':experiment_path,
+ 'experiment_path2':experiment_path2}
+
+ return rr
+
+
+
+
+ ############################################################
+ def rerun(self, i):
+ """
+ Rerun experiment
+
+ cm run experiment --rerun=True ...
+ """
+
+ i['rerun']=True
+
+ return self.run(i)
+
+
+
+
+
+
+
+
+
+
+
+
+ ############################################################
+ def replay(self, i):
+ """
+ Replay experiment
+
+ Args:
+ (CM input dict):
+
+ (out) (str): if 'con', output to console
+
+ (artifact) (str): experiment artifact
+
+ (tags) (str): experiment tags separated by comma
+
+ (dir) (str): experiment directory (often date time)
+ (uid) (str): unique ID of an experiment
+
+ ...
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ * Output from this automation action
+ """
+
+ # Find or add artifact based on repo/alias/tags
+ i['fail_if_not_found']=True
+ r = self._find_or_add_artifact(i)
+ if r['return']>0: return r
+
+ experiment = r['experiment']
+
+ console = i.get('out','')=='con'
+
+ # Print experiment folder
+ experiment_path = experiment.path
+
+ if console:
+ print ('')
+ print ('Path to CM experiment artifact: {}'.format(experiment_path))
+
+ # Check date and time folder
+ uid = i.get('uid', '')
+ datetime = i.get('dir', '')
+
+ if datetime!='':
+ datetimes = [datetime]
+ else:
+ directories = os.listdir(experiment_path)
+
+ datetimes = sorted([f for f in directories if os.path.isfile(os.path.join(experiment_path, f, self.CM_RESULT_FILE))], reverse=True)
+
+ if len(datetimes)==0:
+ return {'return':1, 'error':'experiment(s) not found in {}'.format(experiment_path)}
+
+ # Check datetime directory
+ found_result = {}
+
+ if uid!='':
+ for d in datetimes:
+ r = self._find_uid({'path':experiment_path, 'datetime':d, 'uid':uid})
+ if r['return']>0: return r
+
+ if len(r.get('result',{}))>0:
+ found_result = r['result']
+ datetime = d
+ experiment_path2 = os.path.join(experiment_path, datetime)
+ break
+
+ if len(found_result)==0:
+ return {'return':1, 'error':'couldn\'t find result with UID {} in {}'.format(uid, experiment_path)}
+
+ else:
+ if len(datetimes)==1:
+ datetime = datetimes[0]
+ else:
+ print ('')
+ print ('Available experiments:')
+
+ datetimes = sorted(datetimes)
+
+ num = 0
+ print ('')
+ for d in datetimes:
+ print ('{}) {}'.format(num, d.replace('.',' ')))
+ num += 1
+
+ if not console:
+ return {'return':1, 'error':'more than 1 experiment found.\nPlease use "cm run experiment --dir={date and time}"'}
+
+ print ('')
+ x=input('Make your selection or press Enter for 0: ')
+
+ x=x.strip()
+ if x=='': x='0'
+
+ selection = int(x)
+
+ if selection < 0 or selection >= num:
+ selection = 0
+
+ datetime = datetimes[selection]
+
+ # Final path to experiment
+ experiment_path2 = os.path.join(experiment_path, datetime)
+
+ if not os.path.isdir(experiment_path2):
+ return {'return':1, 'error':'experiment path not found {}'.format(experiment_path2)}
+
+ r = self._find_uid({'path':experiment_path, 'datetime':datetime})
+ if r['return']>0: return r
+
+ results = r['meta']
+
+ if len(results)==0:
+ return {'return':1, 'error':'results not found in {}'.format(experiment_path2)}
+
+ elif len(results)==1:
+ selection = 0
+
+ else:
+ print ('')
+ print ('Available Unique IDs of results:')
+
+ results = sorted(results, key=lambda x: x.get('uid',''))
+
+ num = 0
+ print ('')
+ for r in results:
+ print ('{}) {}'.format(num, r.get('uid','')))
+ num += 1
+
+ if not console:
+ return {'return':1, 'error':'more than 1 result found.\nPlease use "cm run experiment --uid={result UID}"'}
+
+ print ('')
+ x=input('Make your selection or press Enter for 0: ')
+
+ x=x.strip()
+ if x=='': x='0'
+
+ selection = int(x)
+
+ if selection < 0 or selection >= num:
+ selection = 0
+
+ found_result = results[selection]
+ uid = found_result['uid']
+
+ # Final info
+ if console:
+ print ('')
+ print ('Path to experiment: {}'.format(experiment_path2))
+
+ print ('')
+ print ('Result UID: {}'.format(uid))
+
+ # Attempt to load cm-input.json
+ experiment_input_file = os.path.join(experiment_path2, self.CM_INPUT_FILE)
+
+ if not os.path.isfile(experiment_input_file):
+ return {'return':1, 'error':'{} not found - can\'t replay'.format(self.CM_INPUT_FILE)}
+
+ r = utils.load_json(experiment_input_file)
+ if r['return']>0: return r
+
+ cm_input = r['meta']
+
+ tags = cm_input.get('tags','').strip()
+ if 'replay' not in tags:
+ if tags!='': tags+=','
+ tags+='replay'
+ cm_input['tags'] = tags
+
+ if console:
+ print ('')
+ print ('Experiment input:')
+ print ('')
+ print (json.dumps(cm_input, indent=2))
+ print ('')
+
+ # Run experiment again
+ r = self.cmind.access(cm_input)
+ if r['return']>0: return r
+
+ # TBA - validate experiment, etc ...
+
+
+ return {'return':0}
+
+
+ ############################################################
+ def _find_or_add_artifact(self, i):
+ """
+ Find or add experiment artifact (reused in run and reply)
+
+ Args:
+ (CM input dict):
+
+ (fail_if_not_found) (bool) - if True, fail if experiment is not found
+
+ ...
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ experiment (CM artifact class): Experiment artifact
+
+ """
+
+ console = i.get('out','')=='con'
+
+ # Try to find experiment artifact by alias and/or tags
+ ii = utils.sub_input(i, self.cmind.cfg['artifact_keys'] + ['tags'])
+ ii['action']='find'
+
+ ii_copy = copy.deepcopy(ii)
+
+ # If artifact is specified, remove tags
+ artifact = ii.get('artifact','').strip()
+ if artifact!='' and not artifact.endswith(':') \
+ and '*' not in artifact and '?' not in artifact:
+ if 'tags' in ii: del(ii['tags'])
+
+ r = self.cmind.access(ii)
+ if r['return']>0: return r
+
+ lst = r['list']
+
+ if len(lst)>1:
+ print ('More than 1 experiment artifact found:')
+
+ lst = sorted(lst, key=lambda x: x.path)
+
+ num = 0
+ print ('')
+ for e in lst:
+ print ('{}) {}'.format(num, e.path))
+ print (' Tags: {}'.format(','.join(e.meta.get('tags',[]))))
+ num += 1
+
+ if not console:
+ return {'return':1, 'error':'more than 1 experiment artifact found.\nPlease use "cm run experiment {name}" or "cm run experiment --tags={tags separated by comma}"'}
+
+ print ('')
+ x=input('Make your selection or press Enter for 0: ')
+
+ x=x.strip()
+ if x=='': x='0'
+
+ selection = int(x)
+
+ if selection < 0 or selection >= num:
+ selection = 0
+
+ experiment = lst[selection]
+
+ elif len(lst)==1:
+ experiment = lst[0]
+ else:
+ # Create new entry
+ if i.get('fail_if_not_found',False):
+ return {'return':1, 'error':'experiment not found'}
+
+ ii = copy.deepcopy(ii_copy)
+ ii['action']='add'
+ r = self.cmind.access(ii)
+ if r['return']>0: return r
+
+ experiment_uid = r['meta']['uid']
+
+ r = self.cmind.access({'action':'find',
+ 'automation':'experiment,a0a2d123ef064bcb',
+ 'artifact':experiment_uid})
+ if r['return']>0: return r
+
+ lst = r['list']
+ if len(lst)==0 or len(lst)>1:
+ return {'return':1, 'error':'created experiment artifact with UID {} but can\'t find it - weird'.format(experiment_uid)}
+
+ experiment = lst[0]
+
+ return {'return':0, 'experiment':experiment}
+
+ ############################################################
+ def _find_uid(self, i):
+ """
+ Find experiment result with a given UID
+
+ Args:
+ (CM input dict):
+
+ path (str): path to experiment artifact
+ datetime (str): sub-path to experiment
+ (uid) (str): experiment UID
+
+ ...
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ path_to_file (str): path to experiment result file
+ meta (dict): complete list of all results
+ result (dict): result dictionary with a given UID
+
+ """
+
+ path = i['path']
+ datetime = i['datetime']
+ uid = i.get('uid', '').strip()
+
+ path_to_experiment_result_file = os.path.join(path, datetime, self.CM_RESULT_FILE)
+
+ rr={'return':0, 'path_to_file':path_to_experiment_result_file}
+
+ if os.path.isfile(path_to_experiment_result_file):
+ r = utils.load_json(file_name=path_to_experiment_result_file)
+ if r['return']>0: return r
+
+ meta = r['meta']
+
+ rr['meta'] = meta
+
+ # Searching for UID
+ if uid!='':
+ for result in meta:
+ ruid = result.get('uid', '').strip()
+ if ruid!='' and ruid==uid:
+ rr['result']=result
+ break
+
+ return rr
+
+############################################################################
+def flatten_dict(d, flat_dict = {}, prefix = ''):
+
+ for k in d:
+ v = d[k]
+
+ if type(v) is dict:
+ flatten_dict(v, flat_dict, prefix+k+'.')
+ else:
+ flat_dict[prefix+k] = v
+
+ return flat_dict
diff --git a/automation/experiment/tests/test2.bat b/automation/experiment/tests/test2.bat
new file mode 100644
index 0000000000..5ecb3a0d8d
--- /dev/null
+++ b/automation/experiment/tests/test2.bat
@@ -0,0 +1 @@
+cm run experiment --tags=test @test_input.yaml -- echo %VAR1% --batch_size={{VAR1}} {{VAR2}} {{VAR4{['xx','yy','zz']}}}-%%VAR3%%
diff --git a/automation/experiment/tests/test2.sh b/automation/experiment/tests/test2.sh
new file mode 100644
index 0000000000..40d60a25a3
--- /dev/null
+++ b/automation/experiment/tests/test2.sh
@@ -0,0 +1 @@
+cm run experiment --tags=test @test_input.yaml -- echo "\${VAR1} --batch_size={{VAR1}} {{VAR2}} {{VAR4{['xx','yy','zz']}}}-\${VAR3}"
\ No newline at end of file
diff --git a/automation/experiment/tests/test3.bat b/automation/experiment/tests/test3.bat
new file mode 100644
index 0000000000..800e36076d
--- /dev/null
+++ b/automation/experiment/tests/test3.bat
@@ -0,0 +1 @@
+cm run experiment --tags=test @test3_input.yaml -- cm run script "print hello-world native" --env.CM_ENV_TEST1={{VAR1}} --const.CM_ENV_TEST2={{VAR2}}
diff --git a/automation/experiment/tests/test3.sh b/automation/experiment/tests/test3.sh
new file mode 100644
index 0000000000..148e564337
--- /dev/null
+++ b/automation/experiment/tests/test3.sh
@@ -0,0 +1 @@
+cm run experiment --tags=test @test3_input.yaml -- cm run script "print hello-world native" --env.CM_ENV_TEST1={{VAR1}} --const.CM_ENV_TEST2={{VAR2}}
diff --git a/automation/experiment/tests/test3_input.yaml b/automation/experiment/tests/test3_input.yaml
new file mode 100644
index 0000000000..1c789f52a5
--- /dev/null
+++ b/automation/experiment/tests/test3_input.yaml
@@ -0,0 +1,4 @@
+explore:
+ VAR1: [1,2,3]
+ VAR2: ["a","b"]
+ CM_ENV_TEST3: "[2**i for i in range(0,6)]"
diff --git a/automation/experiment/tests/test__json.bat b/automation/experiment/tests/test__json.bat
new file mode 100644
index 0000000000..16eb9184b8
--- /dev/null
+++ b/automation/experiment/tests/test__json.bat
@@ -0,0 +1 @@
+cm run experiment --tags=test @test_input.json -- {{CD}}\test_run.bat
diff --git a/automation/experiment/tests/test__json.sh b/automation/experiment/tests/test__json.sh
new file mode 100644
index 0000000000..a46cb98f5a
--- /dev/null
+++ b/automation/experiment/tests/test__json.sh
@@ -0,0 +1 @@
+cm run experiment --tags=test @test_input.json -- {{CD}}/test_run.sh
diff --git a/automation/experiment/tests/test__yaml.bat b/automation/experiment/tests/test__yaml.bat
new file mode 100644
index 0000000000..e583f209bf
--- /dev/null
+++ b/automation/experiment/tests/test__yaml.bat
@@ -0,0 +1 @@
+cm run experiment --tags=test @test_input.yaml -- {{CD}}\test_run.bat
diff --git a/automation/experiment/tests/test__yaml.sh b/automation/experiment/tests/test__yaml.sh
new file mode 100644
index 0000000000..60c2f7a80c
--- /dev/null
+++ b/automation/experiment/tests/test__yaml.sh
@@ -0,0 +1 @@
+cm run experiment --tags=test @test_input.yaml -- {{CD}}/test_run.sh
diff --git a/automation/experiment/tests/test_input.json b/automation/experiment/tests/test_input.json
new file mode 100644
index 0000000000..f682f5a344
--- /dev/null
+++ b/automation/experiment/tests/test_input.json
@@ -0,0 +1,14 @@
+{
+ "explore": {
+ "VAR1": [
+ 1,
+ 2,
+ 3
+ ],
+ "VAR2": [
+ "a",
+ "b"
+ ],
+ "VAR3": "[2**i for i in range(0,6)]"
+ }
+}
diff --git a/automation/experiment/tests/test_input.yaml b/automation/experiment/tests/test_input.yaml
new file mode 100644
index 0000000000..a621c5ef95
--- /dev/null
+++ b/automation/experiment/tests/test_input.yaml
@@ -0,0 +1,4 @@
+explore:
+ VAR1: [1,2,3]
+ VAR2: ["a","b"]
+ VAR3: "[2**i for i in range(0,6)]"
diff --git a/automation/experiment/tests/test_run.bat b/automation/experiment/tests/test_run.bat
new file mode 100644
index 0000000000..b3aa91028e
--- /dev/null
+++ b/automation/experiment/tests/test_run.bat
@@ -0,0 +1,3 @@
+echo %VAR1% --batch_size=%VAR3% %VAR2%
+
+echo {"x":%VAR1%, "y":"%VAR2%", "z":%VAR3%} > cm-output.json
diff --git a/automation/experiment/tests/test_run.sh b/automation/experiment/tests/test_run.sh
new file mode 100644
index 0000000000..7ed1b472ed
--- /dev/null
+++ b/automation/experiment/tests/test_run.sh
@@ -0,0 +1 @@
+echo $VAR1 --batch_size=$VAR3 $VAR2
diff --git a/automation/project/README.md b/automation/project/README.md
new file mode 100644
index 0000000000..e684ac7ade
--- /dev/null
+++ b/automation/project/README.md
@@ -0,0 +1,27 @@
+*This README is automatically generated - don't edit! Use `README-extra.md` for extra notes!*
+
+### Automation actions
+
+#### test
+
+ * CM CLI: ```cm test project``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/project/module.py#L15))
+ * CM CLI with UID: ```cm test project,6882553224164c56``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/project/module.py#L15))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'test'
+ 'automation':'project,6882553224164c56'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/project/module.py#L15)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+### Maintainers
+
+* [Open MLCommons taskforce on automation and reproducibility](https://cKnowledge.org/mlcommons-taskforce)
\ No newline at end of file
diff --git a/automation/project/_cm.json b/automation/project/_cm.json
new file mode 100644
index 0000000000..68042c4319
--- /dev/null
+++ b/automation/project/_cm.json
@@ -0,0 +1,10 @@
+{
+ "alias": "project",
+ "automation_alias": "automation",
+ "automation_uid": "bbeb15d8f0a944a4",
+ "developers": "[Grigori Fursin](https://cKnowledge.org/gfursin)",
+ "tags": [
+ "automation"
+ ],
+ "uid": "6882553224164c56"
+}
diff --git a/automation/project/module.py b/automation/project/module.py
new file mode 100644
index 0000000000..be8d6e7b1d
--- /dev/null
+++ b/automation/project/module.py
@@ -0,0 +1,52 @@
+import os
+
+from cmind.automation import Automation
+from cmind import utils
+
+class CAutomation(Automation):
+ """
+ Automation actions
+ """
+
+ ############################################################
+ def __init__(self, cmind, automation_file):
+ super().__init__(cmind, __file__)
+
+ ############################################################
+ def test(self, i):
+ """
+ Test automation
+
+ Args:
+ (CM input dict):
+
+ (out) (str): if 'con', output to console
+
+ automation (str): automation as CM string object
+
+ parsed_automation (list): prepared in CM CLI or CM access function
+ [ (automation alias, automation UID) ] or
+ [ (automation alias, automation UID), (automation repo alias, automation repo UID) ]
+
+ (artifact) (str): artifact as CM string object
+
+ (parsed_artifact) (list): prepared in CM CLI or CM access function
+ [ (artifact alias, artifact UID) ] or
+ [ (artifact alias, artifact UID), (artifact repo alias, artifact repo UID) ]
+
+ ...
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ * Output from this automation action
+
+ """
+
+ import json
+ print (json.dumps(i, indent=2))
+
+ return {'return':0}
diff --git a/automation/report/README.md b/automation/report/README.md
new file mode 100644
index 0000000000..6f2f966963
--- /dev/null
+++ b/automation/report/README.md
@@ -0,0 +1,27 @@
+*This README is automatically generated - don't edit! Use `README-extra.md` for extra notes!*
+
+### Automation actions
+
+#### test
+
+ * CM CLI: ```cm test report``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/report/module.py#L15))
+ * CM CLI with UID: ```cm test report,6462ecdba2054467``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/report/module.py#L15))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'test'
+ 'automation':'report,6462ecdba2054467'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/report/module.py#L15)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+### Maintainers
+
+* [Open MLCommons taskforce on automation and reproducibility](https://cKnowledge.org/mlcommons-taskforce)
\ No newline at end of file
diff --git a/automation/report/_cm.json b/automation/report/_cm.json
new file mode 100644
index 0000000000..8808957575
--- /dev/null
+++ b/automation/report/_cm.json
@@ -0,0 +1,9 @@
+{
+ "alias": "report",
+ "automation_alias": "automation",
+ "automation_uid": "bbeb15d8f0a944a4",
+ "tags": [
+ "automation"
+ ],
+ "uid": "6462ecdba2054467"
+}
diff --git a/automation/report/module.py b/automation/report/module.py
new file mode 100644
index 0000000000..be8d6e7b1d
--- /dev/null
+++ b/automation/report/module.py
@@ -0,0 +1,52 @@
+import os
+
+from cmind.automation import Automation
+from cmind import utils
+
+class CAutomation(Automation):
+ """
+ Automation actions
+ """
+
+ ############################################################
+ def __init__(self, cmind, automation_file):
+ super().__init__(cmind, __file__)
+
+ ############################################################
+ def test(self, i):
+ """
+ Test automation
+
+ Args:
+ (CM input dict):
+
+ (out) (str): if 'con', output to console
+
+ automation (str): automation as CM string object
+
+ parsed_automation (list): prepared in CM CLI or CM access function
+ [ (automation alias, automation UID) ] or
+ [ (automation alias, automation UID), (automation repo alias, automation repo UID) ]
+
+ (artifact) (str): artifact as CM string object
+
+ (parsed_artifact) (list): prepared in CM CLI or CM access function
+ [ (artifact alias, artifact UID) ] or
+ [ (artifact alias, artifact UID), (artifact repo alias, artifact repo UID) ]
+
+ ...
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ * Output from this automation action
+
+ """
+
+ import json
+ print (json.dumps(i, indent=2))
+
+ return {'return':0}
diff --git a/automation/script/README-extra.md b/automation/script/README-extra.md
new file mode 100644
index 0000000000..c5e2607bbc
--- /dev/null
+++ b/automation/script/README-extra.md
@@ -0,0 +1,1023 @@
+[ [Back to index](../../../docs/README.md) ]
+
+# CM "script" automation
+
+
+Click here to see the table of contents.
+
+ * [Motivation](#motivation)
+ * [Obtaining shared CM scripts](#obtaining-shared-cm-scripts)
+ * [Getting started with CM scripts](#getting-started-with-cm-scripts)
+ * [Understanding CM scripts](#understanding-cm-scripts)
+ * [Wrapping native scripts](#wrapping-native-scripts)
+ * [Modifying environment variables](#modifying-environment-variables)
+ * [Understanding unified output dictionary](#understanding-unified-output-dictionary)
+ * [Modifying state dictionary](#modifying-state-dictionary)
+ * [Running CM scripts via CM Python API](#running-cm-scripts-via-cm-python-api)
+ * [Assembling pipelines (workflows) of CM scripts](#assembling-pipelines-workflows-of-cm-scripts)
+ * [Customizing CM script execution flow](#customizing-cm-script-execution-flow)
+ * [Caching output of CM scripts](#caching-output-of-cm-scripts)
+ * [Assembling pipeline to compile and run image corner detection](#assembling-pipeline-to-compile-and-run-image-corner-detection)
+ * [Customizing sub-dependencies in a pipeline](#customizing-sub-dependencies-in-a-pipeline)
+ * [Using Python virtual environments](#using-python-virtual-environments)
+ * [Assembling pipelines with other artifacts included](#assembling-pipelines-with-other-artifacts-included)
+ * [Unifying host OS and CPU detection](#unifying-host-os-and-cpu-detection)
+ * [Detecting, installing and caching system dependencies](#detecting-installing-and-caching-system-dependencies)
+ * [Using variations](#using-variations)
+ * [Running CM scripts inside containers](#running-cm-scripts-inside-containers)
+ * [Getting help about other script automation flags](#getting-help-about-other-script-automation-flags)
+ * [Further reading](#further-reading)
+
+
+
+*We suggest you to check [CM introduction](https://github.com/mlcommons/ck/blob/master/docs/introduction-cm.md)
+ and [CM CLI/API](https://github.com/mlcommons/ck/blob/master/docs/interface.md) to understand CM motivation and concepts.
+ You can also try [CM tutorials](https://github.com/mlcommons/ck/blob/master/docs/tutorials/README.md)
+ to run some applications and benchmarks on your platform using CM scripts.*
+
+## Motivation
+
+While helping the community reproduce [150+ research papers](https://learning.acm.org/techtalks/reproducibility),
+we have noticed that researchers always create their own ad-hoc scripts, environment variable and files
+to perform *exactly the same steps (actions) across all papers* to prepare, run and reproduce their experiments
+across different software, hardware, models and data.
+
+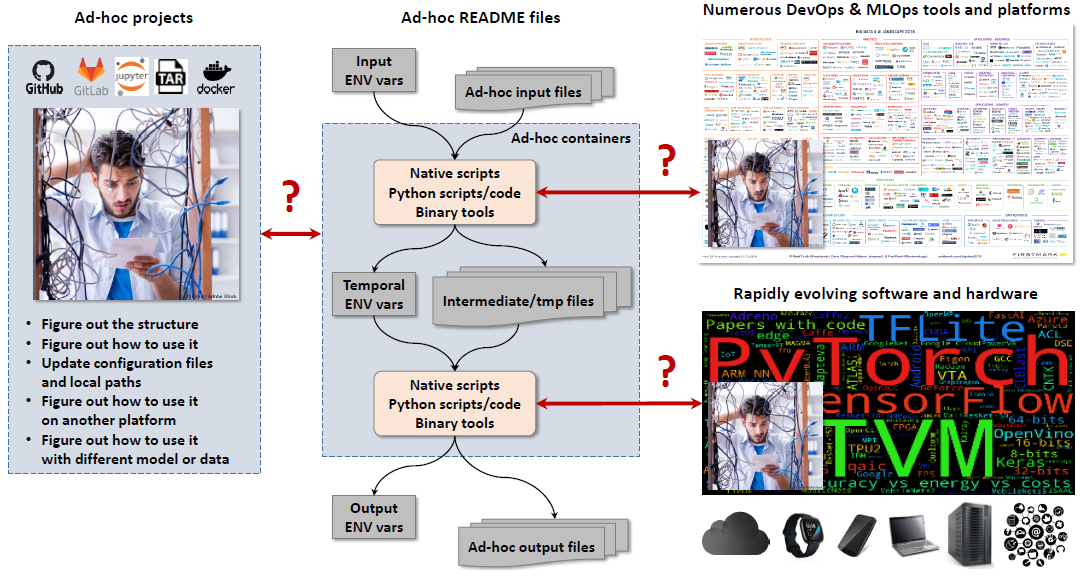
+
+This experience motivated us to create a CM automation called "script" to warp native scripts
+from research and industrial projects with a common, simple and unified CM Command Line Interface and Python API.
+
+Such non-intrusive wrapping helps to make numerous native scripts and tools more reusable, interoperable, portable, findable
+and deterministic across different projects with different artifacts based on [FAIR principles](https://www.go-fair.org/fair-principles).
+
+CM scripts can be embedded into existing projects with minimal or no modifications at all, and they can be connected
+into powerful and portable pipelines and workflows using simple JSON or YAML files
+to prepare, run and reproduce experiments across continuously changing technology.
+
+Importantly, CM scripts can be executed in the same way in a native user environment,
+Python virtual environments (to avoid messing up native environment) and containers
+while automatically adapting to a given environment!
+
+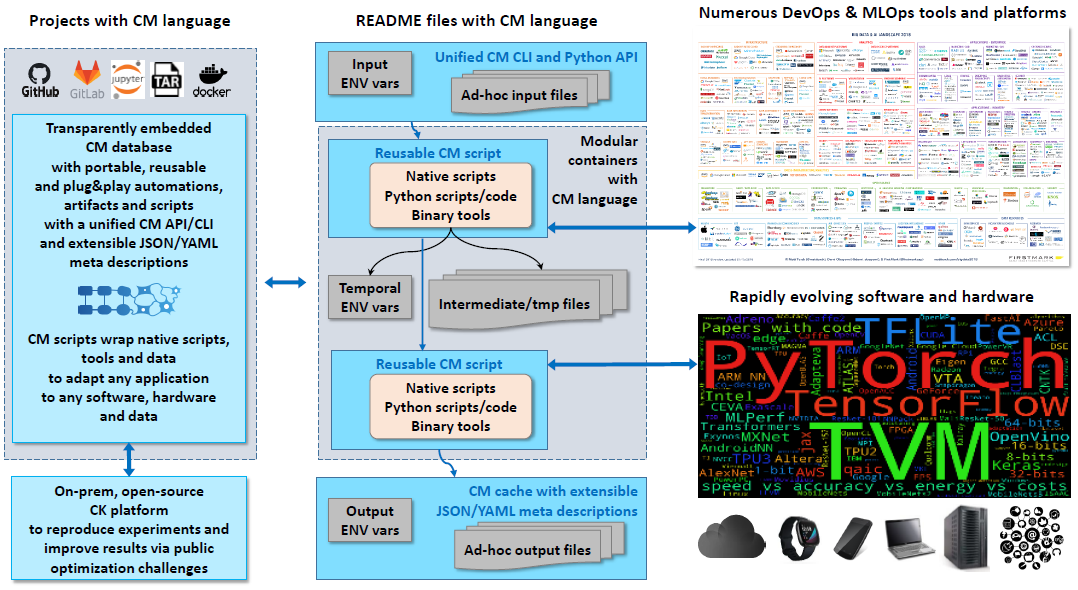
+
+
+
+
+
+## Obtaining shared CM scripts
+
+In order to reuse some CM scripts embedded into shared projects,
+you need to install these projects via the CM interface.
+
+For example, to use automation scripts developed by the [MLCommons task force on automation and reproducibility](https://github.com/mlcommons/ck/blob/master/docs/list_of_scripts.md)
+and shared via GitHub, you just need to pull this repository via CM:
+
+```bash
+cm pull repo --url=https://github.com/mlcommons/ck
+```
+
+or
+
+```bash
+cm pull repo mlcommons@ck
+```
+
+You can now see all available CM scripts in your system as follows:
+
+```bash
+cm find script
+cm find script install* | sort
+
+```
+
+
+## Getting started with CM scripts
+
+You can run any of the above CM script on any platform as follows:
+```bash
+cm run script "tags separated by space" --keys=values --env.KEY=VALUE
+cm run script --tags="tags separated by comma" --keys=values --env.KEY=VALUE
+```
+or using a shortcut `cmr` available in CM V1.4.0+:
+```bash
+cmr "tags separated by space" --keys=values --env.KEY=VALUE
+```
+
+You can also use `-j` flag to print JSON output at the end of the script execution
+and `-v` flag to show extra debug information during script execution.
+
+For example, you can download a RESNET-50 model in ONNX format from Zenodo using the following script:
+```bash
+cmr "download file" --url=https://zenodo.org/record/4735647/files/resnet50_v1.onnx
+```
+
+You can also obtain info about your OS (Linux, Windows, MacOS) in a unified way and print JSON output
+as well as CM debug info as follows:
+```bash
+cmr "detect os" -j -v
+```
+
+## Understanding CM scripts
+
+CM scripts are treated as standard CM artifacts with the associated CM automation ["script"](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script),
+CM action ["run"](https://github.com/mlcommons/ck/blob/master/cm-mlops/automation/script/module.py#L73),
+and JSON and/or YAML meta descriptions.
+
+CM scripts can be invoked by using their alias, unique ID and human-readable tags (preferred method).
+
+For example, the [CM "Print Hello World" script](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/print-hello-world)
+simply wraps 2 native `run.sh` and `run.bat` scripts to print "Hello World" on Linux, MacOs or Windows
+together with a few environment variables:
+
+```bash
+ls `cm find script print-hello-world`
+
+README.md _cm.json run.bat run.sh
+```
+
+It is described by this [_cm.json meta description file](https://github.com/mlcommons/ck/blob/master/cm-mlops/script/print-hello-world/_cm.json)
+with the following alias, UID and tags:
+
+```json
+{
+ "automation_alias": "script",
+ "automation_uid": "5b4e0237da074764",
+
+ "alias": "print-hello-world",
+ "uid": "b9f0acba4aca4baa",
+
+ "default_env": {
+ "CM_ENV_TEST1": "TEST1"
+ },
+
+ "env": {
+ "CM_ENV_TEST2": "TEST2"
+ },
+
+ "input_mapping": {
+ "test1": "CM_ENV_TEST1"
+ },
+
+ "new_env_keys": [
+ "CM_ENV_TEST*"
+ ],
+
+ "new_state_keys": [
+ "hello_test*"
+ ],
+
+ "tags": [
+ "print",
+ "hello-world",
+ "hello world",
+ "hello",
+ "world",
+ "native-script",
+ "native",
+ "script"
+ ]
+}
+```
+
+The `automation_alias` and `automation_uid` tells CM that this artifact can be used with the CM "script" automation.
+
+Therefore, this script can be executed from the command line in any of the following ways:
+
+```bash
+cm run script print-hello-world
+cm run script b9f0acba4aca4baa
+cm run script --tags=print,native-script,hello-world
+cm run script "print native-script hello-world"
+```
+
+The same script can be also executed using CM Python API as follows:
+```python
+import cmind
+
+output = cmind.access({'action':'run', 'automation':'script', 'tags':'print,native-script,hello-world'})
+if output['return']>0:
+ cmind.error(output)
+
+import json
+print (json.dumps(output, indent=2))
+```
+
+Normally you should see the following output along with some debug information (that will be removed soon):
+
+```bash
+
+...
+
+CM_ENV_TEST1 = TEST1
+CM_ENV_TEST2 = TEST2
+
+HELLO WORLD!
+...
+```
+
+### Wrapping native scripts
+
+*run.bat* and *run.sh* are native scripts that will be executed by this CM script in a unified way on Linux, MacOS and Windows:
+
+```bash
+echo ""
+echo "CM_ENV_TEST1 = ${CM_ENV_TEST1}"
+echo "CM_ENV_TEST2 = ${CM_ENV_TEST2}"
+
+echo ""
+echo "HELLO WORLD!"
+```
+
+The idea to use native scripts is to make it easier for researchers and engineers to reuse their existing automation scripts
+while providing a common CM wrapper with a unified CLI, Python API and extensible meta descriptions.
+
+
+
+
+### Modifying environment variables
+
+CM script automation CLI uses a flag `--env.VAR=VALUE` to set some environment variable and pass it to a native script
+as shown in this example:
+
+```bash
+cm run script "print native-script hello-world" \
+ --env.CM_ENV_TEST1=ABC1 --env.CM_ENV_TEST2=ABC2
+
+...
+
+CM_ENV_TEST1 = ABC1
+CM_ENV_TEST2 = TEST2
+
+HELLO WORLD!
+```
+
+Note, that *CM_ENV_TEST2* did not change. This happened because dictionary `env` in the *_cm.json* forces *CM_ENV_TEST2* to *TEST2*,
+while `default_env` dictionary allows environment variables to be updated externally.
+
+You can still force an environment variable to a given value externally using a `--const` flag as follows:
+
+```bash
+cm run script "print native-script hello-world" \
+ --env.CM_ENV_TEST1=ABC1 --const.CM_ENV_TEST2=ABC2
+
+...
+
+CM_ENV_TEST1 = ABC1
+CM_ENV_TEST2 = ABC2
+
+HELLO WORLD!
+
+```
+
+You can also use a JSON file instead of flags. Create *input.json* (or any other filename):
+```json
+{
+ "tags":"print,native-script,hello-world",
+ "env":{
+ "CM_ENV_TEST1":"ABC1"
+ }
+}
+```
+
+and run the CM script with this input file as follows:
+```
+cm run script @input.json
+```
+
+
+You can use YAML file instead of CLI. Create *input.yaml* (or any other filename):
+```yaml
+tags: "print,hello-world,script"
+env:
+ CM_ENV_TEST1: "ABC1"
+```
+
+and run the CM script with this input file as follows:
+```
+cm run script @input.yaml
+```
+
+Finally, you can map any other flag from the script CLI to an environment variable
+using the key `input_mapping` in the `_cm.json` meta description of this script:
+
+```bash
+cm run script "print native-script hello-world" --test1=ABC1
+
+...
+
+CM_ENV_TEST1 = ABC1
+CM_ENV_TEST2 = TEST2
+
+HELLO WORLD!
+
+```
+
+
+### Understanding unified output dictionary
+
+You can see the output of a given CM script in the JSON format by adding `--out=json` flag as follows:
+
+```bash
+cm run script --tags=print,hello-world,script --env.CM_ENV_TEST1=ABC1 --out=json
+
+...
+
+CM_ENV_TEST1 = ABC1
+CM_ENV_TEST2 = ABC2
+
+HELLO WORLD!
+
+{
+ "deps": [],
+ "env": {
+ "CM_ENV_TEST1": "ABC1",
+ "CM_ENV_TEST2": "TEST2"
+ },
+ "new_env": {
+ "CM_ENV_TEST1": "ABC1",
+ "CM_ENV_TEST2": "TEST2"
+ },
+ "new_state": {},
+ "return": 0,
+ "state": {}
+}
+```
+
+Note that `new_env`shows new environment variables produced and explicitly exposed by this script
+via a `new_env_keys` key in the `_cm.json` meta description of this script.
+
+This is needed to assemble automation pipelines and workflows while avoiding their contamination
+with temporal environments. CM script must explicitly expose environment variables that will
+go to the next stage of a pipeline.
+
+In the following example, `CM_ENV_TEST3` will be added to the `new_env` while `CM_XYZ` will not
+since it is not included in `"new_env_keys":["CM_ENV_TEST*"]`:
+
+```bash
+cm run script --tags=print,hello-world,script --env.CM_ENV_TEST1=ABC1 --out=json --env.CM_ENV_TEST3=ABC3 --env.CM_XYZ=XYZ
+```
+
+### Modifying state dictionary
+
+Sometimes, it is needed to use more complex structures than environment variables in scripts and workflows.
+We use a dictionary `state` that can be updated and exposed by a given script via `new_state_keys` key
+in the `_cm.json` meta description of this script.
+
+In the following example, `hello_world` key will be updated in the `new_state` dictionary,
+while `hello` key will not be updated because it is not included in the wild card `"new_state_key":["hello_world*"]`:
+
+```bash
+cm run script --tags=print,hello-world,script --out=json \
+ --state.hello=xyz1 --state.hello_world=xyz2
+
+...
+
+{
+ "deps": [],
+ "env": {
+ "CM_ENV_TEST1": "TEST1",
+ "CM_ENV_TEST2": "TEST2"
+ },
+ "new_env": {
+ "CM_ENV_TEST1": "TEST1",
+ "CM_ENV_TEST2": "TEST2"
+ },
+ "new_state": {
+ "hello_world": "xyz2"
+ },
+ "return": 0,
+ "state": {
+ "hello": "xyz1",
+ "hello_world": "xyz2"
+ }
+}
+```
+
+### Running CM scripts via CM Python API
+
+You can run a given CM script from python or Jupyter notebooks as follows:
+
+```python
+
+import cmind
+
+r = cmind.access({'action':'run',
+ 'automation':'script',
+ 'tags':'print,hello-world,script',
+ 'const':{
+ 'CM_ENV_TEST1':'ABC1',
+ },
+ 'env':{
+ 'CM_ENV_TEST2':'ABC2'
+ },
+ 'state': {
+ 'hello':'xyz1',
+ 'hello_world':'xyz2'
+ }
+ })
+
+print (r)
+
+```
+
+```bash
+...
+
+CM_ENV_TEST1 = ABC1
+CM_ENV_TEST2 = ABC2
+
+HELLO WORLD!
+
+{'return': 0,
+ 'env': {'CM_ENV_TEST2': 'TEST2', 'CM_ENV_TEST1': 'ABC1'},
+ 'new_env': {'CM_ENV_TEST2': 'TEST2', 'CM_ENV_TEST1': 'ABC1'},
+ 'state': {'hello': 'xyz1', 'hello_world': 'xyz2'},
+ 'new_state': {'hello_world': 'xyz2'},
+ 'deps': []}
+
+```
+
+
+
+### Assembling pipelines (workflows) of CM scripts
+
+We've added a simple mechanism to chain reusable CM scripts into complex pipelines
+without the need for specialized workflow frameworks.
+
+Simply add the following dictionary "deps" to the `_cm.json` or `_cm.yaml` of your script as follows:
+
+```json
+
+{
+ "deps": [
+ {
+ "tags": "a string of tags separated by comma to find and execute the 1st CM script"
+ },
+ {
+ "tags": "a string of tags separated by comma to find and execute the 1st CM script"
+ },
+ ...
+ ]
+}
+
+```
+
+This CM script will run all dependent scripts in above sequence, aggregate environment variable and `state` dictionary,
+and will then run native scripts.
+
+You can also turn on specific dependencies based on some values in specific environment variables or min/max version (if supported)
+in this pipeline as follows:
+
+```json
+
+{
+ "deps": [
+ {
+ "tags": "a string of tags separated by comma to find and execute the 1st CM script",
+ "enable_if_env": { "USE_CUDA" : ["yes", "YES", "true"] }
+ },
+ {
+ "tags": "a string of tags separated by comma to find and execute the 1st CM script"
+ "enable_if_env": { "USE_CPU" : ["yes", "YES", "true"] },
+ "version_min": "3.10"
+ },
+ ...
+ ]
+}
+
+```
+
+You can also specify dependencies to be invoked after executing native scripts
+using a dictionary `"post_deps"` with the same format `"deps"`.
+
+
+You can see an example of such dependencies in the [_cm.json](https://github.com/mlcommons/ck/blob/master/cm-mlops/script/print-hello-world-py/_cm.json)
+of the ["print-hello-world-py" CM script](https://github.com/mlcommons/ck/blob/master/cm-mlops/script/print-hello-world-py)
+that detects and unifies OS parameters using the ["detect-os" CM script](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/detect-os),
+detects or builds Python using the ["get-python3" CM script](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-python3)
+and then runs `code.py` with "Hello World" from `run.sh` or `run.bat`:
+
+```bash
+cm run script "print python hello-world"
+```
+
+
+
+
+
+
+### Customizing CM script execution flow
+
+If a developer adds `customize.py` file inside a given CM script,
+it can be used to programmatically update environment variables, prepare input scripts
+and even invoke other scripts programmatically using Python.
+
+If a function `preprocess` exists in this file, CM script will call it before
+invoking a native script.
+
+If this function returns `{"skip":True}` in the output,
+further execution of this script will be skipped.
+
+After executing the preprocess function, the CM script automation will record the global state dictionary
+into *tmp-state.json* and the local state dictionary from this CM script into *tmp-state-new.json*.
+
+The CM script automation will then run a native script (run.sh on Linux/MacOS or run.bat on Windows)
+with all merged environment variables from previous scripts.
+
+Note that native scripts can also create 2 files that will be automatically picked up and processed by the CM script automation:
+* *tmp-run-env.out* - list of environment variables to update the "new_env" of a given CM script
+* *tmp-run-state.json* - the state dictionary to update the "new_state" of a given CM script
+
+If `postprocess` function exists in the *customize.py* file, the CM script will call it
+to finalize the postprocessing of files, environment variables, and the state dictionary.
+
+You can see an [example of such `customize.py` module](https://github.com/mlcommons/ck/blob/master/cm-mlops/script/get-python3/customize.py) in the CM script
+to [detect or install/build Python interpreter](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-python3) in a unified way on any machine.
+
+This script exposes a number of environment variables for a detected Python
+in the [`postprocess` function](https://github.com/mlcommons/ck/blob/master/cm-mlops/script/get-python3/customize.py#L60):
+
+* `CM_PYTHON_BIN` - python3.10 or python.exe or any other name of a Python interpreter on a given system
+* `CM_PYTHON_BIN_PATH` - path to a detected or installed python
+* `CM_PYTHON_BIN_WITH_PATH` - full path to a detected or installed python
+* `LD_LIBRARY_PATH` - updated LD_LIBRARY_PATH to python
+* `PATH` - updated PATH to python
+
+These environment variables can be reused by other CM scripts or external tools
+while decoupling them from specific python versions and paths, and even allowing
+multiple versions of tools and artifacts to co-exist on the same system
+and plugged into CM scripts:
+
+```bash
+cm run script "get python3" --out=json
+```
+
+
+
+### Caching output of CM scripts
+
+By default, CM scripts run wrapped scripts and tools, update environment variables and produce new files in the current directory.
+
+In many cases, we want to cache the output and environment variables when we run the same CM script with the same input again
+to avoid potentially lengthy detections, downloads, builds and data pre/post processing.
+
+That's why we have developed another CM automation called ["cache"](../cache/README-extra.md)
+to cache the output of scripts in the "cache" artifacts in the "local" CM repository
+that can be found by tags or unique IDs like any other CM artifact.
+
+Our convention is to use names *get-{tool or artifact}* for CM scripts that detect already installed artifacts,
+prepare their environment and cache them in the *local* CM repository using the "cache" automation.
+
+If installed artifact doesn't exist, we either enhance above scripts to include download, installation and even building
+for a given artifact (if it's a tool) or we create extra CM scripts *install-{tool or artifact}*
+that download and prepare tools and artifacts (install, build, preprocess, etc).
+
+For example, the CM script [*get-python3*](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-python3)
+has *customize.py* with *preprocess* function that implements the search for python3 on Linux
+or python.exe on Windows, 2 native scripts *run.sh* and *run.bat* to obtain the version of the detected python installation,
+and *postprocess* function to prepare environment variables *CM_PYTHON_BIN* and *CM_PYTHON_BIN_WITH_PATH*
+that can be used by other CM scripts:
+
+```bash
+cm run script "get python" --out=json
+```
+
+If you run it for the first time and CM script detects multiple versions of python co-existing on your system,
+it will ask you to select one. CM will then cache the output in the *cache* artifact of the CM repository.
+You can see all *cache* CM entries for other tools and artifacts as follows:
+
+```bash
+cm show cache
+```
+or
+```bash
+cm show cache --tags=get,python
+```
+
+You can see the cached files as follows:
+```bash
+ls `cm find cache --tags=get,python`
+```
+
+* _cm.json - CM meta description of this "cache" artifact with its unique ID, tags and other meta information
+* cm-cached-state.json - dictionary with the new environment variables and the new state dictionary
+* tmp-env-all.sh - all environment variables used during CM script execution
+* tmp-env.sh - only new environment variables produced after CM script execution (it can be used directly by external tools)
+* tmp-run.sh - all environment variables and a call to the native script (useful for reproducibility)
+* tmp-state.json - the state before running native script - it can be loaded and used by native scripts and tools instead of using environment variables
+* tmp-ver.out - the output of the --version command parsed by `postprocess` and `detect_version` functions in `customize.py`
+
+
+If you (or other CM script) run this CM script to get the python tool for the second time, CM script will reuse the cached output:
+```bash
+cm run script "get python" --out=json
+```
+
+This also allows us to install multiple tool versions into different CM cache entries (python virtual environments,
+LLVM compiler, etc) and use them separately without the need to change higher-level CM scripts - these tools
+will be automatically plugged in:
+
+```bash
+cm run script "install prebuilt llvm" --version=14.0.0
+cm run script "install prebuilt llvm" --version=16.0.0
+cm run script "install src llvm"
+```
+
+
+Such approach allows us to "probe" the user environment, detect different tools and artifacts, unify them
+and adapt complex applications to a user environment in an automatic, transparent and non-intrusive way
+as shown in the next example.
+
+
+
+
+
+
+## Assembling pipeline to compile and run image corner detection
+
+We can use automatically detected compiler from CM script to create simple and technology-neutral compilation and execution pipelines
+in CM scripts.
+
+For example, we have implemented a simple [image corner detection CM script]( https://github.com/mlcommons/ck/tree/master/cm-mlops/script/app-image-corner-detection )
+with [this meta description](https://github.com/mlcommons/ck/blob/master/cm-mlops/script/app-image-corner-detection/_cm.json).
+
+It uses two other reusable CM scripts to compile a given program using a detected/installed and cached compiler via CM (such as LLVM),
+and then run it with some input image.
+
+First, let's detect installed LLVM it via CM:
+
+```bash
+cm run script "get llvm"
+```
+or install a prebuilt version on Linux, MacOs or Windows:
+```bash
+cm run script "install prebuilt llvm" --version=14.0.0
+```
+
+We can then run this CM script to compile and run image corner detection as follows:
+```bash
+cm run script "app image corner-detection" --input=`cm find script --tags=app,image,corner-detection`/computer_mouse.pgm
+```
+
+This CM script will preset environment variables for a detected/installed compiler,
+compile our C program, run it via `run.sh` (Linux/MacOS) or `run.bat` (Windows)
+and generate an output image *output_image_with_corners.pgm* in the `output` directory of this script:
+
+```bash
+ls `cm find script --tags=app,image,corner-detection`/output
+
+image-corner output_image_with_corners.pgm
+
+```
+
+Note that this directory also contains the compiled tool "image-corner" that can now be used independently from CM if necessary.
+
+
+
+
+### Customizing sub-dependencies in a pipeline
+
+When running a CM script with many sub-dependencies similar to above example,
+we may want to specify some version constraints on sub-dependencies such as LLVM.
+
+One can use the key `"names"` in the "deps" list of any CM script meta description
+to specify multiple names for a given dependency.
+
+For example, a dependency to "get compiler" in CM script "compile-program"
+has `"names":["compiler"]` as shown [here](https://github.com/mlcommons/ck/blob/master/cm-mlops/script/compile-program/_cm.json#L15).
+
+We can now use a CM script flag `--add_deps_recursive.{some name}.{some key}={some value}` or
+`--adr.{above name}.{some key}={some value}` to update a dictionary of all sub-dependencies
+that has `some name`.
+
+For example, we can now specify to use LLVM 16.0.0 for image corner detection as follows:
+```bash
+cm run script "app image corner-detection" --adr.compiler.tags=llvm --adr.compiler.version=16.0.0
+```
+
+If this compiler was not yet detected or installed by CM, it will find related scripts
+to install either a prebuilt version of LLVM or build it from sources.
+
+
+## Using Python virtual environments
+
+By default, CM scripts will install python dependencies into user space.
+This can influence other existing projects and may not be desirable.
+CM can be used inside virtual Python environments without any changes,
+but a user still need to do some manual steps to set up such environment.
+That's why we've developed a [CM script](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/install-python-venv)
+to automate creation of multiple Python virtual environments with different names:
+
+```bash
+cm run script "install python-venv" --name={some name}
+```
+
+CM will create a virtual environment using default Python and save it in CM cache.
+It is possible to create a python virtual environment with a minimal required version
+or a specific one on Linux and MacOS as follows:
+
+```bash
+cm run script "install python-venv" --version_min=3.8 --name=mlperf
+cm run script "install python-venv" --version=3.10.8 --name=mlperf2
+```
+
+In this case, CM will attempt to detect Python 3.10.8 on a system.
+If CM can't detect it, CM will then automatically download and build it
+using [this script](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/install-python-src).
+
+Now, when user runs pipelines that install Python dependencies, CM will detect
+virtual environment in the CM cache as well as native Python and will ask a user
+which one to use.
+
+It is possible to avoid such questions by using the flag `--adr.python.name=mlperf`.
+In such case, CM will propagate the name of a virtual environment to all sub-dependencies
+as shown in the next example.
+
+Instead of adding this flag to all scripts, you can specify it
+using `CM_SCRIPT_EXTRA_CMD` environment variable as follows:
+```bash
+export CM_SCRIPT_EXTRA_CMD="--adr.python.name=mlperf"
+```
+
+You can even specify min Python version required as follows:
+```bash
+export CM_SCRIPT_EXTRA_CMD="--adr.python.name=mlperf --adr.python.version_min=3.9"
+```
+
+## Assembling pipelines with other artifacts included
+
+We can now use existing CM scripts as "LEGO" blocks to assemble more complex automation pipelines and workflows
+while automatically downloading and plugging in
+and pre-/post-processing all necessary artifacts (models, data sets, frameworks, compilers, etc)
+on any supported platform (Linux, MacOS, Windows).
+
+For example, we have implemented a simple image classification application automated by the following CM script:
+[*app-image-classification-onnx-py*]( https://github.com/mlcommons/ck/tree/master/cm-mlops/script/app-image-classification-onnx-py ).
+
+It is described by the following [`_cm.yaml`](https://github.com/mlcommons/ck/blob/master/cm-mlops/script/app-image-classification-onnx-py/_cm.yaml) meta description:
+
+```yaml
+alias: app-image-classification-onnx-py
+uid: 3d5e908e472b417e
+
+automation_alias: script
+automation_uid: 5b4e0237da074764
+
+category: "Modular ML/AI applications"
+
+tags:
+- app
+- image-classification
+- onnx
+- python
+
+default_env:
+ CM_BATCH_COUNT: '1'
+ CM_BATCH_SIZE: '1'
+
+deps:
+- tags: detect,os
+- tags: get,sys-utils-cm
+- names:
+ - python
+ - python3
+ tags: get,python3
+- tags: get,cuda
+ names:
+ - cuda
+ enable_if_env:
+ USE_CUDA:
+ - yes
+- tags: get,dataset,imagenet,image-classification,original
+- tags: get,dataset-aux,imagenet-aux,image-classification
+- tags: get,ml-model,resnet50,_onnx,image-classification
+
+- tags: get,generic-python-lib,_onnxruntime
+ skip_if_env:
+ USE_CUDA:
+ - yes
+- tags: get,generic-python-lib,_onnxruntime_gpu
+ enable_if_env:
+ USE_CUDA:
+ - yes
+
+variations:
+ cuda:
+ env:
+ USE_CUDA: yes
+```
+
+
+Its `deps` pipeline runs other CM scripts to detect OS parameters, detect or install Python,
+install the latest ONNX run-time, download ResNet-50 model and the minimal ImageNet dataset (500).
+
+It also contains [`run.sh`](https://github.com/mlcommons/ck/blob/master/cm-mlops/script/app-image-classification-onnx-py/run.sh)
+and [`run.bat`](https://github.com/mlcommons/ck/blob/master/cm-mlops/script/app-image-classification-onnx-py/run.bat)
+to install extra Python requirements (not yet unified by CM scripts)
+and run a Python script that classifies an image from ImageNet
+or an image provided by user.
+
+Before running it, let us install Python virtual environment via CM to avoid altering
+native Python installation:
+```bash
+cm run script "install python-venv" --name=my-test
+cm show cache --tags=python
+```
+
+You can run it on any system as follows:
+
+```bash
+cm run script "python app image-classification onnx"
+
+```
+
+
+To avoid CM asking which python to use, you can force the use of Python virtual environment
+as follows:
+
+```bash
+cm run script "python app image-classification onnx" --adr.python.name=my-test
+```
+
+
+
+If you run this CM script for the first time, it may take some minutes because it will detect, download, build and cache all dependencies.
+
+When you run it again, it will plug in all cached dependencies:
+
+```bash
+cm run script "python app image-classification onnx" --adr.python.name.my-test
+
+```
+
+You can then run it with your own image as follows:
+```bash
+cm run script --tags=app,image-classification,onnx,python \
+ --adr.python.name.my-test --input={path to my JPEG image}
+```
+
+
+
+## Unifying host OS and CPU detection
+
+In order to make experiments more portable and interoperable, we need to unify
+the information about host OS and CPU across different systems.
+We are gradually improving the following two CM scripts:
+
+* [`detect-os`](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/detect-os)
+* [`detect-cpu`](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/detect-cpu)
+
+These two CM script have *customize.py* with preprocess and postprocess functions
+and a native run script to detect OS info and update environment variables
+and the state dictionary needed by all other CM scripts.
+
+You can run them on your platform as follows:
+
+```bash
+cm run script "detect os" --out=json
+
+...
+
+cm run script "detect cpu" --out=json
+```
+
+If some information is missing or not consistent across different platforms,
+you can improve it in a backwards compatible way. You can then submit a PR [here](https://github.com/mlcommons/ck/pulls)
+to let the community reuse your knowledge and collaboratively enhance common automation scripts, pipelines and workflows -
+that's why we called our project "Collective Knowledge".
+
+
+## Detecting, installing and caching system dependencies
+
+Many projects require installation of some system dependencies. Unfortunately, the procedure
+is different across different systems.
+
+That's why we have developed two other CM script to unify and automate this process on any system.
+
+* [`get-sys-utils-cm`]( https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-sys-utils-cm )
+* [`get-sys-utils-min`]( https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-sys-utils-min )
+
+They will install (minimal) system dependencies based on the OS and CPU info detected by CM scripts mentioned above.
+
+The last script is particularly useful to make applications compatible with Windows
+where many typical tools like "wget", "patch", etc are missing - they will be automatically
+download by that script.
+
+You can use them as follows:
+```bash
+cm run script "get sys-utils-min" --out=json
+cm run script "get sys-utils-cm"
+```
+
+
+
+
+## Using variations
+
+In some cases, we want the same CM script to download some artifact in a different format.
+
+For example, we may want to download and cache ResNet50 model in ONNX or PyTorch or TensorFlow or TFLite format.
+
+In such case, we use so-called `variations` in the meta description of a given CM script.
+
+For example, the CM script [`get-ml-model-resnet50`] has many variations and combinations separated by comma
+to download this model in multiple formats:
+
+* `onnx`
+* `onnx,opset-11`
+* `onnx,opset-8`
+* `pytorch`
+* `pytorch,fp32`
+* `pytorch,int8`
+* `tflite`
+* `tflite,argmax`
+* `tflite,no-argmax`
+* `tensorflow`
+* `batch_size.1`
+* `batch_size.#`
+
+These variations simply update environment variables and add more dependencies on other CM scripts
+before running `customize.py` and native scripts as described in [_cm.json]( https://github.com/mlcommons/ck/blob/master/cm-mlops/script/get-ml-model-resnet50/_cm.json#L30 ).
+
+It is possible to specify a required variation or multiple variations when running a given CM script by adding extra tags with "_" prefix.
+
+For example, you can install quantized ResNet-50 model in PyTorch int8 format as follows:
+
+```bash
+cm run script "get ml-model resnet50 _pytorch _int8" --out=json
+```
+
+You can install another FP32 variation of this model at the same time:
+```bash
+cm run script "get ml-model resnet50 _pytorch _fp32" --out=json
+```
+
+You can now find them in cache by tags and variations as follows:
+```bash
+cm show cache --tags=get,ml-model,resnet50
+cm show cache --tags=get,ml-model,resnet50,_pytorch
+cm show cache --tags=get,ml-model,resnet50,_pytorch,_fp32
+```
+
+
+
+
+
+
+
+
+
+
+
+## Running CM scripts inside containers
+
+One of the important ideas behind using a common automation language
+is to use it inside and outside containers thus avoiding the need to create
+ad-hoc manual containers and README files.
+
+We can just use base containers and let the CM automation language
+detect installed tools and connect external data with the automation pipelines and workflows.
+
+See examples of modular containers with CM language to automate the MLPerf inference benchmark from MLCommons
+[here](https://github.com/mlcommons/ck/tree/master/docker).
+
+Note that we continue working on a CM functionality to automatically generate
+Docker containers and README files when executing CM scripts
+(a prototype was successfully validated in the MLPerf inference v3.0 submission):
+
+* https://github.com/mlcommons/ck/tree/master/cm-mlops/script/build-dockerfile
+* https://github.com/mlcommons/ck/tree/master/cm-mlops/script/build-docker-image
+
+
+
+
+## Getting help about other script automation flags
+
+You can get help about all flags used to customize execution
+of a given CM script from the command line as follows:
+
+```bash
+cm run script --help
+```
+
+Some flags are useful to make it easier to debug scripts and save output in files.
+
+You can find more info about CM script execution flow in this [document](README-specs.md).
+
+
+
+
+
+
+
+
+
+
+
+
+## Further reading
+
+* [CM "script" automation specification](README-specs.md)
+* [MLCommons CM script sources](https://github.com/mlcommons/ck/tree/master/cm-mlops/script)
+* [List of portable and reusable CM scripts from MLCommons](https://github.com/mlcommons/ck/blob/master/docs/list_of_scripts.md)
+* [CM "cache" automation](../cache/README-extra.md)
diff --git a/automation/script/README-specs.md b/automation/script/README-specs.md
new file mode 100644
index 0000000000..58526d1687
--- /dev/null
+++ b/automation/script/README-specs.md
@@ -0,0 +1,81 @@
+# CM "script" automation specification
+
+Please check the [CM documentation](https://github.com/mlcommons/ck/tree/master/docs#collective-mind-language-cm)
+for more details about the CM automation language.
+
+See the CM script introduction [here](README-extra.md).
+
+See the [automatically generated catalog](https://github.com/mlcommons/ck/blob/master/docs/list_of_scripts.md) of all CM scripts from MLCommons.
+
+## Getting started with CM scripts
+
+* A CM script is identified by a set of tags and by unique ID.
+* Further each CM script can have multiple variations and they are identified by variation tags which are treated in the same way as tags and identified by a `_` prefix.
+
+### CM script execution flow
+* When a CM script is invoked (either by tags or by unique ID), its `_cm.json` is processed first which will check for any `deps` script and if there are, then they are executed in order.
+* Once all the `deps` scripts are executed, `customize.py` file is checked and if existing `preprocess` function inside it is executed if present.
+* Then any `prehook_deps` CM scripts mentioned in `_cm.json` are executed similar to `deps`
+* After this, keys in `env` dictionary is exported as `ENV` variables and `run` file if exists is executed.
+* Once run file execution is done, any `posthook_deps` CM scripts mentioned in `_cm.json` are executed similar to `deps`
+* Then `postprocess` function inside customize.py is executed if present.
+* After this stage any `post_deps` CM scripts mentioned in `_cm.json` is executed.
+
+** If a script is already cached, then the `preprocess`, `run file` and `postprocess` executions won't happen and only the dependencies marked as `dynamic` will be executed from `deps`, `prehook_deps`, `posthook_deps` and `postdeps`.
+
+### Input flags
+When we run a CM script we can also pass inputs to it and any input added in `input_mapping` dictionary inside `_cm.json` gets converted to the corresponding `ENV` variable.
+
+### Conditional execution of any `deps`, `post_deps`
+We can use `skip_if_env` dictionary inside any `deps`, `prehook_deps`, `posthook_deps` or `post_deps` to make its executional conditional
+
+### Versions
+We can specify any specific version of a script using `version`. `version_max` and `version_min` are also possible options.
+* When `version_min` is given, any version above this if present in the cache or detected in the system can be chosen. If nothing is detected `default_version` if present and if above `version_min` will be used for installation. Otherwise `version_min` will be used as `version`.
+* When `version_max` is given, any version below this if present in the cache or detected in the system can be chosen. If nothing is detected `default_version` if present and if below `version_max` will be used for installation. Otherwise `version_max_usable` (additional needed input for `version_max`) will be used as `version`.
+
+### Variations
+* Variations are used to customize CM script and each unique combination of variations uses a unique cache entry. Each variation can turn on `env` keys also any other meta including dependencies specific to it. Variations are turned on like tags but with a `_` prefix. For example, if a script is having tags `"get,myscript"`, to call the variation `"test"` inside it, we have to use tags `"get,myscript,_test"`.
+
+#### Variation groups
+`group` is a key to map variations into a group and at any time only one variation from a group can be used in the variation tags. For example, both `cpu` and `cuda` can be two variations under the `device` group, but user can at any time use either `cpu` or `cuda` as variation tags but not both.
+
+#### Dynamic variations
+Sometimes it is difficult to add all variations needed for a script like say `batch_size` which can take many different values. To handle this case, we support dynamic variations using '#' where '#' can be dynamically replaced by any string. For example, `"_batch_size.8"` can be used as a tag to turn on the dynamic variation `"_batch_size.#"`.
+
+### ENV flow during CM script execution
+* [TBD] Issue added [here](https://github.com/mlcommons/ck/issues/382)
+* During a given script execution incoming `env` dictionary is saved `(saved_env)` and all the updates happens on a copy of it.
+* Once a script execution is over (which includes all the dependent script executions as well), newly created keys and any updated keys are merged with the `saved_env` provided the keys are mentioned in `new_env_keys`
+* Same behaviour applies to `state` dictionary.
+
+#### Special env keys
+* Any env key with a prefix `CM_TMP_*` and `CM_GIT_*` are not passed by default to any dependency. These can be force passed by adding the key(s) to the `force_env_keys` list of the concerned dependency.
+* Similarly we can avoid any env key from being passed to a given dependency by adding the prefix of the key in the `clean_env_keys` list of the concerned dependency.
+* `--input` is automatically converted to `CM_INPUT` env key
+* `version` is converted to `CM_VERSION`, ``version_min` to `CM_VERSION_MIN` and `version_max` to `CM_VERSION_MAX`
+* If `env['CM_GH_TOKEN']=TOKEN_VALUE` is set then git URLs (specified by `CM_GIT_URL`) are changed to add this token.
+* If `env['CM_GIT_SSH']=yes`, then git URLs are changed to SSH from HTTPS.
+
+### Script Meta
+#### Special keys in script meta
+* TBD: `reuse_version`, `inherit_variation_tags`, `update_env_tags_from_env`
+
+### How cache works?
+* If `cache=true` is set in a script meta, the result of the script execution is cached for further use.
+* For a cached script, `env` and `state` updates are done using `new_env` and `new_state` dictionaries which are stored in the `cm-cached.json` file inside the cached folder.
+* By using `--new` input, a new cache entry can be forced even when an old one exist.
+* By default no depndencies are run for a cached entry unless `dynamic` key is set for it.
+
+### Updating ENV from inside the run script
+* [TBD]
+
+
+### Script workflow (env, deps, native scripts)
+
+
+
+
+
+
+© 2022-23 [MLCommons](https://mlcommons.org)
diff --git a/automation/script/README.md b/automation/script/README.md
new file mode 100644
index 0000000000..da54b2a5db
--- /dev/null
+++ b/automation/script/README.md
@@ -0,0 +1,427 @@
+*This README is automatically generated - don't edit! See [extra README](README-extra.md) for extra notes!*
+
+### Automation actions
+
+#### run
+
+ * CM CLI: ```cm run script``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L77))
+ * CM CLI with UID: ```cm run script,5b4e0237da074764``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L77))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'run'
+ 'automation':'script,5b4e0237da074764'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L77)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### version
+
+ * CM CLI: ```cm version script``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L2041))
+ * CM CLI with UID: ```cm version script,5b4e0237da074764``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L2041))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'version'
+ 'automation':'script,5b4e0237da074764'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L2041)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### search
+
+ * CM CLI: ```cm search script``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L2069))
+ * CM CLI with UID: ```cm search script,5b4e0237da074764``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L2069))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'search'
+ 'automation':'script,5b4e0237da074764'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L2069)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### test
+
+ * CM CLI: ```cm test script``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L2188))
+ * CM CLI with UID: ```cm test script,5b4e0237da074764``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L2188))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'test'
+ 'automation':'script,5b4e0237da074764'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L2188)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### native_run
+
+ * CM CLI: ```cm native_run script``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L2254))
+ * CM CLI with UID: ```cm native_run script,5b4e0237da074764``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L2254))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'native_run'
+ 'automation':'script,5b4e0237da074764'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L2254)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### add
+
+ * CM CLI: ```cm add script``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L2327))
+ * CM CLI with UID: ```cm add script,5b4e0237da074764``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L2327))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'add'
+ 'automation':'script,5b4e0237da074764'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L2327)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### run_native_script
+
+ * CM CLI: ```cm run_native_script script``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L2955))
+ * CM CLI with UID: ```cm run_native_script script,5b4e0237da074764``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L2955))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'run_native_script'
+ 'automation':'script,5b4e0237da074764'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L2955)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### find_file_in_paths
+
+ * CM CLI: ```cm find_file_in_paths script``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L2996))
+ * CM CLI with UID: ```cm find_file_in_paths script,5b4e0237da074764``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L2996))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'find_file_in_paths'
+ 'automation':'script,5b4e0237da074764'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L2996)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### detect_version_using_script
+
+ * CM CLI: ```cm detect_version_using_script script``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3215))
+ * CM CLI with UID: ```cm detect_version_using_script script,5b4e0237da074764``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3215))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'detect_version_using_script'
+ 'automation':'script,5b4e0237da074764'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3215)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### find_artifact
+
+ * CM CLI: ```cm find_artifact script``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3288))
+ * CM CLI with UID: ```cm find_artifact script,5b4e0237da074764``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3288))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'find_artifact'
+ 'automation':'script,5b4e0237da074764'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3288)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### find_file_deep
+
+ * CM CLI: ```cm find_file_deep script``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3446))
+ * CM CLI with UID: ```cm find_file_deep script,5b4e0237da074764``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3446))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'find_file_deep'
+ 'automation':'script,5b4e0237da074764'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3446)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### find_file_back
+
+ * CM CLI: ```cm find_file_back script``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3504))
+ * CM CLI with UID: ```cm find_file_back script,5b4e0237da074764``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3504))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'find_file_back'
+ 'automation':'script,5b4e0237da074764'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3504)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### parse_version
+
+ * CM CLI: ```cm parse_version script``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3545))
+ * CM CLI with UID: ```cm parse_version script,5b4e0237da074764``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3545))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'parse_version'
+ 'automation':'script,5b4e0237da074764'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3545)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### update_deps
+
+ * CM CLI: ```cm update_deps script``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3599))
+ * CM CLI with UID: ```cm update_deps script,5b4e0237da074764``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3599))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'update_deps'
+ 'automation':'script,5b4e0237da074764'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3599)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### get_default_path_list
+
+ * CM CLI: ```cm get_default_path_list script``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3619))
+ * CM CLI with UID: ```cm get_default_path_list script,5b4e0237da074764``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3619))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'get_default_path_list'
+ 'automation':'script,5b4e0237da074764'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3619)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### doc
+
+ * CM CLI: ```cm doc script``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3630))
+ * CM CLI with UID: ```cm doc script,5b4e0237da074764``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3630))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'doc'
+ 'automation':'script,5b4e0237da074764'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3630)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### gui
+
+ * CM CLI: ```cm gui script``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3658))
+ * CM CLI with UID: ```cm gui script,5b4e0237da074764``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3658))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'gui'
+ 'automation':'script,5b4e0237da074764'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3658)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### dockerfile
+
+ * CM CLI: ```cm dockerfile script``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3695))
+ * CM CLI with UID: ```cm dockerfile script,5b4e0237da074764``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3695))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'dockerfile'
+ 'automation':'script,5b4e0237da074764'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3695)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### docker
+
+ * CM CLI: ```cm docker script``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3723))
+ * CM CLI with UID: ```cm docker script,5b4e0237da074764``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3723))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'docker'
+ 'automation':'script,5b4e0237da074764'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3723)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### prepare
+
+ * CM CLI: ```cm prepare script``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3777))
+ * CM CLI with UID: ```cm prepare script,5b4e0237da074764``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3777))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'prepare'
+ 'automation':'script,5b4e0237da074764'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3777)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### clean_some_tmp_files
+
+ * CM CLI: ```cm clean_some_tmp_files script``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3788))
+ * CM CLI with UID: ```cm clean_some_tmp_files script,5b4e0237da074764``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3788))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'clean_some_tmp_files'
+ 'automation':'script,5b4e0237da074764'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/script/module.py#L3788)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+### Maintainers
+
+* [Open MLCommons taskforce on automation and reproducibility](https://cKnowledge.org/mlcommons-taskforce)
\ No newline at end of file
diff --git a/automation/script/_cm.json b/automation/script/_cm.json
new file mode 100644
index 0000000000..140662bfa1
--- /dev/null
+++ b/automation/script/_cm.json
@@ -0,0 +1,16 @@
+{
+ "alias": "script",
+ "automation_alias": "automation",
+ "automation_uid": "bbeb15d8f0a944a4",
+ "deps": {
+ "cache": "cache,541d6f712a6b464e"
+ },
+ "desc": "Making native scripts more portable, interoperable and deterministic",
+ "developers": "[Arjun Suresh](https://www.linkedin.com/in/arjunsuresh), [Grigori Fursin](https://cKnowledge.org/gfursin)",
+ "actions_with_help":["run", "docker"],
+ "sort": 1000,
+ "tags": [
+ "automation"
+ ],
+ "uid": "5b4e0237da074764"
+}
diff --git a/automation/script/assets/scripts-workflow.png b/automation/script/assets/scripts-workflow.png
new file mode 100644
index 0000000000..60d0ef7157
Binary files /dev/null and b/automation/script/assets/scripts-workflow.png differ
diff --git a/automation/script/module.py b/automation/script/module.py
new file mode 100644
index 0000000000..22ff9c5da3
--- /dev/null
+++ b/automation/script/module.py
@@ -0,0 +1,5062 @@
+# CM "script" automation that wraps native scripts with a unified CLI, Python API
+# and JSON/YAML meta descriptions.
+#
+# It is a stable prototype being developed by Grigori Fursin and Arjun Suresh.
+#
+# We think to develop a simpler version of this automation at some point
+# while keeping full backwards compatibility.
+#
+# Join the MLCommons taskforce on automation and reproducibility
+# to discuss further developments:
+# https://github.com/mlcommons/ck/blob/master/docs/taskforce.md
+
+import os
+
+from cmind.automation import Automation
+from cmind import utils
+
+class CAutomation(Automation):
+ """
+ CM "script" automation actions
+ (making native scripts more portable, deterministic, reusable and reproducible)
+ """
+
+ ############################################################
+ def __init__(self, cmind, automation_file):
+ super().__init__(cmind, __file__)
+
+ self.os_info = {}
+ self.run_state = {}
+ self.run_state['deps'] = []
+ self.run_state['fake_deps'] = False
+ self.run_state['parent'] = None
+ self.run_state['version_info'] = []
+
+ self.file_with_cached_state = 'cm-cached-state.json'
+
+ self.tmp_file_env = 'tmp-env'
+ self.tmp_file_env_all = 'tmp-env-all'
+ self.tmp_file_run = 'tmp-run'
+ self.tmp_file_state = 'tmp-state.json'
+
+ self.tmp_file_run_state = 'tmp-run-state.json'
+ self.tmp_file_run_env = 'tmp-run-env.out'
+ self.tmp_file_ver = 'tmp-ver.out'
+
+ self.__version__ = "1.2.1"
+
+ self.local_env_keys = ['CM_VERSION',
+ 'CM_VERSION_MIN',
+ 'CM_VERSION_MAX',
+ 'CM_VERSION_MAX_USABLE',
+ 'CM_DETECTED_VERSION',
+ 'CM_INPUT',
+ 'CM_OUTPUT',
+ 'CM_NAME',
+ 'CM_EXTRA_CACHE_TAGS',
+ 'CM_TMP_*',
+ 'CM_GIT_*',
+ 'CM_RENEW_CACHE_ENTRY']
+
+ self.input_flags_converted_to_tmp_env = ['path']
+
+ self.input_flags_converted_to_env = ['input',
+ 'output',
+ 'name',
+ 'extra_cache_tags',
+ 'skip_compile',
+ 'skip_run',
+ 'accept_license',
+ 'skip_system_deps',
+ 'git_ssh',
+ 'gh_token']
+
+
+
+
+ ############################################################
+ def run(self, i):
+ """
+ Run CM script
+
+ Args:
+ (CM input dict):
+
+ (out) (str): if 'con', output to console
+
+ (artifact) (str): specify CM script (CM artifact) explicitly
+
+ (tags) (str): tags to find an CM script (CM artifact)
+
+ (env) (dict): global environment variables (can/will be updated by a given script and dependencies)
+ (const) (dict): constant environment variable (will be preserved and persistent for a given script and dependencies)
+
+ (state) (dict): global state dictionary (can/will be updated by a given script and dependencies)
+ (const_state) (dict): constant state (will be preserved and persistent for a given script and dependencies)
+
+ (add_deps) (dict): {"name": {"tag": "tag(s)"}, "name": {"version": "version_no"}, ...}
+ (add_deps_recursive) (dict): same as add_deps but is passed recursively onto dependencies as well
+
+ (version) (str): version to be added to env.CM_VERSION to specialize this flow
+ (version_min) (str): min version to be added to env.CM_VERSION_MIN to specialize this flow
+ (version_max) (str): max version to be added to env.CM_VERSION_MAX to specialize this flow
+ (version_max_usable) (str): max USABLE version to be added to env.CM_VERSION_MAX_USABLE
+
+ (path) (str): list of paths to be added to env.CM_TMP_PATH to specialize this flow
+
+ (input) (str): converted to env.CM_INPUT (local env)
+ (output) (str): converted to env.CM_OUTPUT (local env)
+
+ (extra_cache_tags) (str): converted to env.CM_EXTRA_CACHE_TAGS and used to add to caching (local env)
+
+ (name) (str): taken from env.CM_NAME and/or converted to env.CM_NAME (local env)
+ Added to extra_cache_tags with "name-" prefix .
+ Useful for python virtual env (to create multiple entries)
+
+ (quiet) (bool): if True, set env.CM_QUIET to "yes" and attempt to skip questions
+ (the developers have to support it in pre/post processing and scripts)
+
+ (skip_cache) (bool): if True, skip caching and run in current directory
+ (force_cache) (bool): if True, force caching if can_force_cache=true in script meta
+
+ (skip_remembered_selections) (bool): if True, skip remembered selections
+ (uses or sets env.CM_TMP_SKIP_REMEMBERED_SELECTIONS to "yes")
+
+ (new) (bool): if True, skip search for cached and run again
+ (renew) (bool): if True, rewrite cache entry if exists
+
+ (dirty) (bool): if True, do not clean files
+
+ (save_env) (bool): if True, save env and state to tmp-env.sh/bat and tmp-state.json
+ (shell) (bool): if True, save env with cmd/bash and run it
+
+ (recursion) (bool): True if recursive call.
+ Useful when preparing the global bat file or Docker container
+ to save/run it in the end.
+
+ (recursion_spaces) (str, internal): adding ' ' during recursion for debugging
+
+ (remembered_selections) (list): remember selections of cached outputs
+
+ (print_env) (bool): if True, print aggregated env before each run of a native script
+
+ (fake_run) (bool): if True, will run the dependent scripts but will skip the main run script
+ (prepare) (bool): the same as fake_run
+ (fake_deps) (bool): if True, will fake run the dependent scripts
+ (print_deps) (bool): if True, will print the CM run commands of the direct dependent scripts
+ (run_state) (dict): Internal run state
+
+ (debug_script_tags) (str): if !='', run cmd/bash before executing a native command
+ inside a script specified by these tags
+
+ (debug_script) (bool): if True, debug current script (set debug_script_tags to the tags of a current script)
+ (detected_versions) (dict): All the used scripts and their detected_versions
+
+ (verbose) (bool): if True, prints all tech. info about script execution (False by default)
+ (v) (bool): the same as verbose
+
+ (time) (bool): if True, print script execution time (or if verbose == True)
+ (space) (bool): if True, print used disk space for this script (or if verbose == True)
+
+ (ignore_script_error) (bool): if True, ignore error code in native tools and scripts
+ and finish a given CM script. Useful to test/debug partial installations
+
+ (json) (bool): if True, print output as JSON
+ (j) (bool): if True, print output as JSON
+
+ (pause) (bool): if True, pause at the end of the main script (Press Enter to continue)
+
+ (repro) (bool): if True, dump cm-run-script-input.json, cm-run_script_output.json,
+ cm-run-script-state.json, cm-run-script-info.json
+ to improve the reproducibility of results
+
+ (repro_prefix) (str): if !='', use it to record above files {repro-prefix)-input.json ...
+ (repro_dir) (str): if !='', use this directory to dump info
+
+ (script_call_prefix) (str): how to call script in logs and READMEs (cm run script)
+ ...
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ * (skipped) (bool): if true, this script was skipped
+
+ * new_env (dict): new environment (delta from a collective script)
+ * new_state (dict): new state (delta from a collective script)
+
+ * env (dict): global env (updated by this script - includes new_env)
+ * state (dict): global state (updated by this script - includes new_state)
+
+ """
+
+ r = self._run(i)
+
+ return r
+
+
+ ############################################################
+ def _run(self, i):
+
+ from cmind import utils
+ import copy
+ import time
+ import shutil
+
+ # Check if save input/output to file
+ repro = i.get('repro', False)
+ repro_prefix = ''
+
+ if repro:
+ repro_prefix = i.get('repro_prefix', '')
+ if repro_prefix == '': repro_prefix = 'cm-run-script'
+
+ repro_dir = i.get('repro_dir', '')
+ if repro_dir == '': repro_dir = os.getcwd()
+
+ repro_prefix = os.path.join (repro_dir, repro_prefix)
+
+ if repro_prefix!='':
+ dump_repro_start(repro_prefix, i)
+
+
+ recursion = i.get('recursion', False)
+
+ # If first script run, check if can write to current directory
+ if not recursion and not i.get('skip_write_test', False):
+ if not can_write_to_current_directory():
+ return {'return':1, 'error':'Current directory "{}" is not writable - please change it'.format(os.getcwd())}
+
+ recursion_int = int(i.get('recursion_int',0))+1
+
+ start_time = time.time()
+
+ # Check extra input from environment variable CM_SCRIPT_EXTRA_CMD
+ # Useful to set up default flags such as the name of virtual enviroment
+ extra_cli = os.environ.get('CM_SCRIPT_EXTRA_CMD', '').strip()
+ if extra_cli != '':
+ from cmind import cli
+ r = cli.parse(extra_cli)
+ if r['return']>0: return r
+
+ cm_input = r['cm_input']
+
+ utils.merge_dicts({'dict1':i, 'dict2':cm_input, 'append_lists':True, 'append_unique':True})
+
+ # Check simplified CMD: cm run script "get compiler"
+ # If artifact has spaces, treat them as tags!
+ artifact = i.get('artifact','')
+ if ' ' in artifact: # or ',' in artifact:
+ del(i['artifact'])
+ if 'parsed_artifact' in i: del(i['parsed_artifact'])
+ # Force substitute tags
+ i['tags']=artifact.replace(' ',',')
+
+ # Check if has extra tags as a second artifact
+ # Example: cmr . "_python _tiny"
+
+ parsed_artifacts = i.get('parsed_artifacts',[])
+ if len(parsed_artifacts)>0:
+ extra_tags = parsed_artifacts[0][0][0]
+ if ' ' in extra_tags or ',' in extra_tags:
+ # Add tags
+ x=i.get('tags','')
+ if x!='': x+=','
+ i['tags']=x+extra_tags.replace(' ',',')
+
+ # Recursion spaces needed to format log and print
+ recursion_spaces = i.get('recursion_spaces', '')
+ # Caching selections to avoid asking users again
+ remembered_selections = i.get('remembered_selections', [])
+
+ # Get current env and state before running this script and sub-scripts
+ env = i.get('env',{})
+ state = i.get('state',{})
+ const = i.get('const',{})
+ const_state = i.get('const_state',{})
+
+ # Save current env and state to detect new env and state after running a given script
+ saved_env = copy.deepcopy(env)
+ saved_state = copy.deepcopy(state)
+
+ for key in [ "env", "state", "const", "const_state" ]:
+ if i.get("local_"+key):
+ if not i.get(key, {}):
+ i[key] = {}
+ utils.merge_dicts({'dict1':i[key], 'dict2':i['local_'+key], 'append_lists':True, 'append_unique':True})
+
+ add_deps = i.get('ad',{})
+ if not add_deps:
+ add_deps = i.get('add_deps',{})
+ else:
+ utils.merge_dicts({'dict1':add_deps, 'dict2':i.get('add_deps', {}), 'append_lists':True, 'append_unique':True})
+
+ add_deps_recursive = i.get('adr', {})
+ if not add_deps_recursive:
+ add_deps_recursive = i.get('add_deps_recursive', {})
+ else:
+ utils.merge_dicts({'dict1':add_deps_recursive, 'dict2':i.get('add_deps_recursive', {}), 'append_lists':True, 'append_unique':True})
+
+ save_env = i.get('save_env', False)
+
+ print_env = i.get('print_env', False)
+
+ verbose = False
+
+ if 'verbose' in i: verbose=i['verbose']
+ elif 'v' in i: verbose=i['v']
+
+ if verbose:
+ env['CM_VERBOSE']='yes'
+
+ show_time = i.get('time', False)
+ show_space = i.get('space', False)
+
+ if not recursion and show_space:
+ start_disk_stats = shutil.disk_usage("/")
+
+ extra_recursion_spaces = ' '# if verbose else ''
+
+ skip_cache = i.get('skip_cache', False)
+ force_cache = i.get('force_cache', False)
+
+ fake_run = i.get('fake_run', False)
+ fake_run = i.get('fake_run', False) if 'fake_run' in i else i.get('prepare', False)
+ if fake_run: env['CM_TMP_FAKE_RUN']='yes'
+
+ fake_deps = i.get('fake_deps', False)
+ if fake_deps: env['CM_TMP_FAKE_DEPS']='yes'
+
+ run_state = i.get('run_state', self.run_state)
+ if not run_state.get('version_info', []):
+ run_state['version_info'] = []
+ if run_state.get('parent', '') == '':
+ run_state['parent'] = None
+ if fake_deps:
+ run_state['fake_deps'] = True
+
+ print_deps = i.get('print_deps', False)
+ print_readme = i.get('print_readme', False)
+
+ new_cache_entry = i.get('new', False)
+ renew = i.get('renew', False)
+
+ cmd = i.get('cmd', '')
+ # Capturing the input command if it is coming from an access function
+ if not cmd and 'cmd' in i.get('input',''):
+ i['cmd'] = i['input']['cmd']
+ cmd = i['cmd']
+
+ debug_script_tags = i.get('debug_script_tags', '')
+
+ detected_versions = i.get('detected_versions', {})
+
+ ignore_script_error = i.get('ignore_script_error', False)
+
+ # Get constant env and state
+ const = i.get('const',{})
+ const_state = i.get('const_state',{})
+
+ # Detect current path and record in env for further use in native scripts
+ current_path = os.path.abspath(os.getcwd())
+ env['CM_TMP_CURRENT_PATH'] = current_path
+
+ # Check if quiet mode
+ quiet = i.get('quiet', False) if 'quiet' in i else (env.get('CM_QUIET','').lower() == 'yes')
+ if quiet: env['CM_QUIET'] = 'yes'
+
+ skip_remembered_selections = i.get('skip_remembered_selections', False) if 'skip_remembered_selections' in i \
+ else (env.get('CM_SKIP_REMEMBERED_SELECTIONS','').lower() == 'yes')
+ if skip_remembered_selections: env['CM_SKIP_REMEMBERED_SELECTIONS'] = 'yes'
+
+ # Prepare debug info
+ parsed_script = i.get('parsed_artifact')
+ parsed_script_alias = parsed_script[0][0] if parsed_script is not None else ''
+
+
+
+
+
+ # Get and cache minimal host OS info to be able to run scripts and manage OS environment
+ if len(self.os_info) == 0:
+ r = self.cmind.access({'action':'get_host_os_info',
+ 'automation':'utils,dc2743f8450541e3'})
+ if r['return']>0: return r
+
+ self.os_info = r['info']
+
+ os_info = self.os_info
+
+ # Bat extension for this host OS
+ bat_ext = os_info['bat_ext']
+
+ # Add permanent env from OS (such as CM_WINDOWS:"yes" on Windows)
+ env_from_os_info = os_info.get('env',{})
+ if len(env_from_os_info)>0:
+ env.update(env_from_os_info)
+
+ #take some env from the user environment
+ keys = [ "GH_TOKEN", "ftp_proxy", "FTP_PROXY", "http_proxy", "HTTP_PROXY", "https_proxy", "HTTPS_PROXY", "no_proxy", "NO_PROXY", "socks_proxy", "SOCKS_PROXY" ]
+ for key in keys:
+ if os.environ.get(key, '') != '' and env.get(key, '') == '':
+ env[key] = os.environ[key]
+
+ # Check path/input/output in input and pass to env
+ for key in self.input_flags_converted_to_tmp_env:
+ value = i.get(key, '').strip()
+ if value != '':
+ env['CM_TMP_' + key.upper()] = value
+
+ for key in self.input_flags_converted_to_env:
+ value = i.get(key, '')
+ if type(value)==str: value=value.strip()
+ if value != '':
+ env['CM_' + key.upper()] = value
+
+
+ ############################################################################################################
+ # Check if we want to skip cache (either by skip_cache or by fake_run)
+ force_skip_cache = True if skip_cache else False
+ force_skip_cache = True if fake_run else force_skip_cache
+
+
+ ############################################################################################################
+ # Find CM script(s) based on their tags and variations to get their meta and customize this workflow.
+ # We will need to decide how to select if more than 1 (such as "get compiler")
+ #
+ # Note: this local search function will separate tags and variations
+ #
+ # STEP 100 Input: Search sripts by i['tags'] (includes variations starting from _) and/or i['parsed_artifact']
+ # tags_string = i['tags']
+
+ tags_string = i.get('tags','').strip()
+
+ ii = utils.sub_input(i, self.cmind.cfg['artifact_keys'])
+
+ ii['tags'] = tags_string
+ ii['out'] = None
+
+
+ # if cm run script without tags/artifact and with --help
+ if len(ii.get('parsed_artifact',[]))==0 and ii.get('tags','')=='' and i.get('help',False):
+ return utils.call_internal_module(self, __file__, 'module_help', 'print_help', {'meta':{}, 'path':''})
+
+ r = self.search(ii)
+ if r['return']>0: return r
+
+ # Search function will return
+
+ list_of_found_scripts = r['list']
+
+ script_tags = r['script_tags']
+ script_tags_string = ','.join(script_tags)
+
+ variation_tags = r['variation_tags']
+
+# # Print what was searched!
+# cm_script_info = 'CM script'
+#
+# x = 'with'
+# if parsed_script_alias !='' :
+# cm_script_info += ' '+x+' alias "{}"'.format(parsed_script_alias)
+# x = 'and'
+#
+# if len(script_tags)>0:
+# cm_script_info += ' '+x+' tags "{}"'.format(script_tags_string.replace(',',' '))
+# x = 'and'
+#
+# if len(variation_tags)>0:
+# x_variation_tags = ['_'+v for v in variation_tags]
+# cm_script_info += ' '+x+' variations "{}"'.format(" ".join(x_variation_tags))
+#
+# if verbose:
+# print ('')
+# print (recursion_spaces + '* Searching for ' + cm_script_info)
+# else:
+# print (recursion_spaces + '* Running ' + cm_script_info)
+
+
+ cm_script_info = i.get('script_call_prefix', '').strip()
+ if cm_script_info == '': cm_script_info = 'cm run script'
+ if not cm_script_info.endswith(' '): cm_script_info+=' '
+
+ x = '"'
+ y = ' '
+ if parsed_script_alias !='' :
+ cm_script_info += parsed_script_alias
+ x = ' --tags="'
+ y = ','
+
+ if len(script_tags)>0 or len(variation_tags)>0:
+ cm_script_info += x
+
+ if len(script_tags)>0:
+ cm_script_info += script_tags_string.replace(',',y)
+
+ if len(variation_tags)>0:
+ if len(script_tags)>0: cm_script_info+=' '
+
+ x_variation_tags = ['_'+v for v in variation_tags]
+ cm_script_info += y.join(x_variation_tags)
+
+ cm_script_info += '"'
+
+# if verbose:
+# print ('')
+
+ print ('')
+ print (recursion_spaces + '* ' + cm_script_info)
+
+
+ #############################################################################
+ # Report if scripts were not found or there is an ambiguity with UIDs
+ if not r['found_scripts']:
+ return {'return':1, 'error': 'no scripts were found with above tags (when variations ignored)'}
+
+ if len(list_of_found_scripts) == 0:
+ return {'return':16, 'error':'no scripts were found with above tags and variations\n'+r.get('warning', '')}
+
+ # Sometimes there is an ambiguity when someone adds a script
+ # while duplicating a UID. In such case, we will return >1 script
+ # and will start searching in the cache ...
+ # We are detecing such cases here:
+ if len(list_of_found_scripts)>1 and script_tags_string=='' and parsed_script_alias!='' and '?' not in parsed_script_alias and '*' not in parsed_script_alias:
+ x='Ambiguity in the following scripts have the same UID - please change that in _cm.json or _cm.yaml:\n'
+ for y in list_of_found_scripts:
+ x+=' * '+y.path+'\n'
+
+ return {'return':1, 'error':x}
+
+ # STEP 100 Output: list_of_found_scripts based on tags (with variations) and/or parsed_artifact
+ # script_tags [] - contains tags without variations (starting from _ such as _cuda)
+ # variation_tags [] - contains only variations tags (without _)
+ # string_tags_string [str] (joined script_tags)
+
+
+
+
+
+
+
+
+ #############################################################################
+ # Sort scripts for better determinism
+ list_of_found_scripts = sorted(list_of_found_scripts, key = lambda a: (a.meta.get('sort',0),
+ a.path))
+ if verbose:
+ print (recursion_spaces + ' - Number of scripts found: {}'.format(len(list_of_found_scripts)))
+
+ # Check if script selection is remembered
+ if not skip_remembered_selections and len(list_of_found_scripts) > 1:
+ for selection in remembered_selections:
+ if selection['type'] == 'script' and set(selection['tags'].split(',')) == set(script_tags_string.split(',')):
+ # Leave 1 entry in the found list
+ list_of_found_scripts = [selection['cached_script']]
+ if verbose:
+ print (recursion_spaces + ' - Found remembered selection with tags: {}'.format(script_tags_string))
+ break
+
+
+ # STEP 200 Output: potentially pruned list_of_found_scripts if selection of multple scripts was remembered
+
+
+
+
+
+
+ # STEP 300: If more than one CM script found (example: "get compiler"),
+ # first, check if selection was already remembered!
+ # second, check in cache to prune scripts
+
+ # STEP 300 input: lit_of_found_scripts
+
+ select_script = 0
+
+ # If 1 script found and script_tags == '', pick them from the meta
+ if script_tags_string == '' and len(list_of_found_scripts) == 1:
+ script_tags_string = ','.join(list_of_found_scripts[0].meta.get('tags',[]))
+
+ # Found 1 or more scripts. Scans cache tags to find at least 1 with cache==True
+ preload_cached_scripts = False
+ for script in list_of_found_scripts:
+ if script.meta.get('cache', False) == True or (script.meta.get('can_force_cache', False) and force_cache):
+ preload_cached_scripts = True
+ break
+
+ # STEP 300 Output: preload_cached_scripts = True if at least one of the list_of_found_scripts must be cached
+
+
+
+
+
+
+ # STEP 400: If not force_skip_cache and at least one script can be cached, find (preload) related cache entries for found scripts
+ # STEP 400 input: script_tags and -tmp (to avoid unfinished scripts particularly when installation fails)
+
+ cache_list = []
+
+ if not force_skip_cache and preload_cached_scripts:
+ cache_tags_without_tmp_string = '-tmp'
+ if script_tags_string !='':
+ cache_tags_without_tmp_string += ',' + script_tags_string
+ if variation_tags:
+ cache_tags_without_tmp_string += ',_' + ",_".join(variation_tags)
+ # variation_tags are prefixed with "_" but the CM search function knows only tags and so we need to change "_-" to "-_" for excluding any variations
+ # This change can later be moved to a search function specific to cache
+ cache_tags_without_tmp_string = cache_tags_without_tmp_string.replace(",_-", ",-_")
+
+ if verbose:
+ print (recursion_spaces + ' - Searching for cached script outputs with the following tags: {}'.format(cache_tags_without_tmp_string))
+
+ search_cache = {'action':'find',
+ 'automation':self.meta['deps']['cache'],
+ 'tags':cache_tags_without_tmp_string}
+ rc = self.cmind.access(search_cache)
+ if rc['return']>0: return rc
+
+ cache_list = rc['list']
+
+ if verbose:
+ print (recursion_spaces + ' - Number of cached script outputs found: {}'.format(len(cache_list)))
+
+ # STEP 400 output: cache_list
+
+
+
+
+
+
+ # STEP 500: At this stage with have cache_list related to either 1 or more scripts (in case of get,compiler)
+ # If more than 1: Check if in cache and reuse it or ask user to select
+ # STEP 500 input: list_of_found_scripts
+
+ if len(list_of_found_scripts) > 0:
+ # If only tags are used, check if there are no cached scripts with tags - then we will reuse them
+ # The use case: cm run script --tags=get,compiler
+ # CM script will always ask to select gcc,llvm,etc even if any of them will be already cached
+ if len(cache_list) > 0:
+ new_list_of_found_scripts = []
+
+ for cache_entry in cache_list:
+ # Find associated script and add to the list_of_found_scripts
+ associated_script_artifact = cache_entry.meta['associated_script_artifact']
+
+ x = associated_script_artifact.find(',')
+ if x<0:
+ return {'return':1, 'error':'CM artifact format is wrong "{}" - no comma found'.format(associated_script_artifact)}
+
+ associated_script_artifact_uid = associated_script_artifact[x+1:]
+
+ cache_entry.meta['associated_script_artifact_uid'] = associated_script_artifact_uid
+
+ for script in list_of_found_scripts:
+ script_uid = script.meta['uid']
+
+ if associated_script_artifact_uid == script_uid:
+ if script not in new_list_of_found_scripts:
+ new_list_of_found_scripts.append(script)
+
+ # Avoid case when all scripts are pruned due to just 1 variation used
+ if len(new_list_of_found_scripts)>0:
+ list_of_found_scripts = new_list_of_found_scripts
+
+ # Select scripts
+ if len(list_of_found_scripts) > 1:
+ select_script = select_script_artifact(list_of_found_scripts, 'script', recursion_spaces, False, script_tags_string, quiet, verbose)
+
+ # Remember selection
+ if not skip_remembered_selections:
+ remembered_selections.append({'type': 'script',
+ 'tags':script_tags_string,
+ 'cached_script':list_of_found_scripts[select_script]})
+ else:
+ select_script = 0
+
+ # Prune cache list with the selected script
+ if len(list_of_found_scripts) > 0:
+ script_artifact_uid = list_of_found_scripts[select_script].meta['uid']
+
+ new_cache_list = []
+ for cache_entry in cache_list:
+ if cache_entry.meta['associated_script_artifact_uid'] == script_artifact_uid:
+ new_cache_list.append(cache_entry)
+
+ cache_list = new_cache_list
+
+ # Here a specific script is found and meta obtained
+ # Set some useful local variables
+ script_artifact = list_of_found_scripts[select_script]
+
+ meta = script_artifact.meta
+ path = script_artifact.path
+
+ # Check path to repo
+ script_repo_path = script_artifact.repo_path
+
+ script_repo_path_with_prefix = script_artifact.repo_path
+ if script_artifact.repo_meta.get('prefix', '') != '':
+ script_repo_path_with_prefix = os.path.join(script_repo_path, script_artifact.repo_meta['prefix'])
+
+ env['CM_TMP_CURRENT_SCRIPT_REPO_PATH'] = script_repo_path
+ env['CM_TMP_CURRENT_SCRIPT_REPO_PATH_WITH_PREFIX'] = script_repo_path_with_prefix
+
+ # Check if has --help
+ if i.get('help',False):
+ return utils.call_internal_module(self, __file__, 'module_help', 'print_help', {'meta':meta, 'path':path})
+
+ run_state['script_id'] = meta['alias'] + "," + meta['uid']
+ run_state['script_variation_tags'] = variation_tags
+
+ deps = meta.get('deps',[])
+ post_deps = meta.get('post_deps',[])
+ prehook_deps = meta.get('prehook_deps',[])
+ posthook_deps = meta.get('posthook_deps',[])
+ input_mapping = meta.get('input_mapping', {})
+ docker_settings = meta.get('docker')
+ docker_input_mapping = {}
+ if docker_settings:
+ docker_input_mapping = docker_settings.get('docker_input_mapping', {})
+ new_env_keys_from_meta = meta.get('new_env_keys', [])
+ new_state_keys_from_meta = meta.get('new_state_keys', [])
+
+ found_script_artifact = utils.assemble_cm_object(meta['alias'], meta['uid'])
+
+ found_script_tags = meta.get('tags',[])
+
+ if i.get('debug_script', False):
+ debug_script_tags=','.join(found_script_tags)
+
+ if verbose:
+ print (recursion_spaces+' - Found script::{} in {}'.format(found_script_artifact, path))
+
+
+ # STEP 500 output: script_artifact - unique selected script artifact
+ # (cache_list) pruned for the unique script if cache is used
+ # meta - script meta
+ # path - script path
+ # found_script_tags [] - all tags of the found script
+
+
+
+
+
+
+
+
+
+
+
+
+
+ # HERE WE HAVE ORIGINAL ENV
+
+ # STEP 600: Continue updating env
+ # Add default env from meta to new env if not empty
+ # (env NO OVERWRITE)
+ script_artifact_default_env = meta.get('default_env',{})
+ for key in script_artifact_default_env:
+ env.setdefault(key, script_artifact_default_env[key])
+
+
+ # Force env from meta['env'] as a CONST
+ # (env OVERWRITE)
+ script_artifact_env = meta.get('env',{})
+ env.update(script_artifact_env)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ # STEP 700: Overwrite env with keys from the script input (to allow user friendly CLI)
+ # IT HAS THE PRIORITY OVER meta['default_env'] and meta['env']
+ # (env OVERWRITE - user enforces it from CLI)
+ # (it becomes const)
+ if input_mapping:
+ update_env_from_input_mapping(env, i, input_mapping)
+ update_env_from_input_mapping(const, i, input_mapping)
+
+ # This mapping is done in module_misc
+ #if docker_input_mapping:
+ # update_env_from_input_mapping(env, i, docker_input_mapping)
+ # update_env_from_input_mapping(const, i, docker_input_mapping)
+
+
+
+
+
+
+ # STEP 800: Process variations and update env (overwrite from env and update form default_env)
+ # VARIATIONS HAS THE PRIORITY OVER
+ # MULTIPLE VARIATIONS (THAT CAN BE TURNED ON AT THE SAME TIME) SHOULD NOT HAVE CONFLICTING ENV
+
+ # VARIATIONS OVERWRITE current ENV but not input keys (they become const)
+
+
+
+
+ variations = script_artifact.meta.get('variations', {})
+ state['docker'] = meta.get('docker', {})
+
+ r = self._update_state_from_variations(i, meta, variation_tags, variations, env, state, deps, post_deps, prehook_deps, posthook_deps, new_env_keys_from_meta, new_state_keys_from_meta, add_deps_recursive, run_state, recursion_spaces, verbose)
+ if r['return'] > 0:
+ return r
+
+ warnings = meta.get('warnings', [])
+ if len(r.get('warnings', [])) >0:
+ warnings += r['warnings']
+
+ variation_tags_string = r['variation_tags_string']
+ explicit_variation_tags = r['explicit_variation_tags']
+
+ # USE CASE:
+ # HERE we may have versions in script input and env['CM_VERSION_*']
+
+ # STEP 900: Get version, min, max, usable from env (priority if passed from another script to force version),
+ # then script input, then script meta
+
+ # VERSIONS SHOULD NOT BE USED INSIDE VARIATIONS (in meta)!
+
+ # First, take version from input
+ version = i.get('version', '').strip()
+ version_min = i.get('version_min', '').strip()
+ version_max = i.get('version_max', '').strip()
+ version_max_usable = i.get('version_max_usable', '').strip()
+
+ # Second, take from env
+ if version == '': version = env.get('CM_VERSION','')
+ if version_min == '': version_min = env.get('CM_VERSION_MIN','')
+ if version_max == '': version_max = env.get('CM_VERSION_MAX','')
+ if version_max_usable == '': version_max_usable = env.get('CM_VERSION_MAX_USABLE','')
+
+
+ # Third, take from meta
+ if version == '': version = meta.get('version', '')
+ if version_min == '': version_min = meta.get('version_min', '')
+ if version_max == '': version_max = meta.get('version_max', '')
+ if version_max_usable == '': version_max_usable = meta.get('version_max_usable', '')
+
+ # Update env with resolved versions
+ notes = []
+ for version_index in [(version, 'CM_VERSION', ' == {}'),
+ (version_min, 'CM_VERSION_MIN', ' >= {}'),
+ (version_max, 'CM_VERSION_MAX', ' <= {}'),
+ (version_max_usable, 'CM_VERSION_MAX_USABLE', '({})')]:
+ version_value = version_index[0]
+ key = version_index[1]
+ note = version_index[2]
+
+ if version_value !='':
+ env[key] = version_value
+
+ notes.append(note.format(version_value))
+# elif key in env:
+# # If version_X is "", remove related key from ENV ...
+# del(env[key])
+
+ if len(notes)>0:
+ if verbose:
+ print (recursion_spaces+' - Requested version: ' + ' '.join(notes))
+
+ # STEP 900 output: version* set
+ # env['CM_VERSION*] set
+
+
+
+ # STEP 1000: Update version only if in "versions" (not obligatory)
+ # can be useful when handling complex Git revisions
+ versions = script_artifact.meta.get('versions', {})
+
+ if version!='' and version in versions:
+ versions_meta = versions[version]
+ r = update_state_from_meta(versions_meta, env, state, deps, post_deps, prehook_deps, posthook_deps, new_env_keys_from_meta, new_state_keys_from_meta, i)
+ if r['return']>0: return r
+ adr=get_adr(versions_meta)
+ if adr:
+ self._merge_dicts_with_tags(add_deps_recursive, adr)
+ #Processing them again using updated deps for add_deps_recursive
+ r = update_adr_from_meta(deps, post_deps, prehook_deps, posthook_deps, add_deps_recursive)
+
+
+ # STEP 1100: Update deps from input
+ r = update_deps_from_input(deps, post_deps, prehook_deps, posthook_deps, i)
+ if r['return']>0: return r
+
+
+ r = update_env_with_values(env)
+ if r['return']>0: return r
+
+ if str(env.get('CM_RUN_STATE_DOCKER', False)).lower() in ['true', '1', 'yes']:
+ if state.get('docker'):
+ if str(state['docker'].get('run', True)).lower() in ['false', '0', 'no']:
+ print (recursion_spaces+' - Skipping script::{} run as we are inside docker'.format(found_script_artifact))
+ return {'return': 0}
+ elif str(state['docker'].get('docker_real_run', True)).lower() in ['false', '0', 'no']:
+ print (recursion_spaces+' - Doing fake run for script::{} as we are inside docker'.format(found_script_artifact))
+ fake_run = True
+ env['CM_TMP_FAKE_RUN']='yes'
+
+
+
+ ############################################################################################################
+ # Check extra cache tags
+ x = env.get('CM_EXTRA_CACHE_TAGS','').strip()
+ extra_cache_tags = [] if x=='' else x.split(',')
+
+ if i.get('extra_cache_tags','')!='':
+ for x in i['extra_cache_tags'].strip().split(','):
+ if x!='':
+ if '<<<' in x:
+ import re
+ tmp_values = re.findall(r'<<<(.*?)>>>', str(x))
+ for tmp_value in tmp_values:
+ xx = str(env.get(tmp_value,''))
+ x = x.replace("<<<"+tmp_value+">>>", xx)
+ if x not in extra_cache_tags:
+ extra_cache_tags.append(x)
+
+ if env.get('CM_NAME','')!='':
+ extra_cache_tags.append('name-'+env['CM_NAME'].strip().lower())
+
+
+
+ ############################################################################################################
+ # Check if need to clean output files
+ clean_output_files = meta.get('clean_output_files', [])
+
+ if len(clean_output_files)>0:
+ clean_tmp_files(clean_output_files, recursion_spaces)
+
+
+
+
+
+
+ ############################################################################################################
+ # Check if the output of a selected script should be cached
+ cache = False if i.get('skip_cache', False) else meta.get('cache', False)
+ cache = False if fake_run else cache
+ cache = cache or (i.get('force_cache', False) and meta.get('can_force_cache', False))
+
+ cached_uid = ''
+ cached_tags = []
+ cached_meta = {}
+
+ remove_tmp_tag = False
+ reuse_cached = False
+
+ found_cached = False
+ cached_path = ''
+
+ local_env_keys_from_meta = meta.get('local_env_keys', [])
+
+
+
+
+
+ ############################################################################################################
+ # Check if script is cached if we need to skip deps from cached entries
+ this_script_cached = False
+
+ ############################################################################################################
+ # Check if the output of a selected script should be cached
+ if cache:
+ # TBD - need to reuse and prune cache_list instead of a new CM search inside find_cached_script
+
+ r = find_cached_script({'self':self,
+ 'recursion_spaces':recursion_spaces,
+ 'script_tags':script_tags,
+ 'found_script_tags':found_script_tags,
+ 'variation_tags':variation_tags,
+ 'explicit_variation_tags':explicit_variation_tags,
+ 'version':version,
+ 'version_min':version_min,
+ 'version_max':version_max,
+ 'extra_cache_tags':extra_cache_tags,
+ 'new_cache_entry':new_cache_entry,
+ 'meta':meta,
+ 'env':env,
+ 'skip_remembered_selections':skip_remembered_selections,
+ 'remembered_selections':remembered_selections,
+ 'quiet':quiet,
+ 'verbose':verbose
+ })
+ if r['return'] >0: return r
+
+ # Sort by tags to ensure determinism in order (and later add versions)
+ found_cached_scripts = sorted(r['found_cached_scripts'], key = lambda x: sorted(x.meta['tags']))
+
+ cached_tags = r['cached_tags']
+ search_tags = r['search_tags']
+
+ num_found_cached_scripts = len(found_cached_scripts)
+
+ if num_found_cached_scripts > 0:
+ selection = 0
+
+ # Check if quiet mode
+ if num_found_cached_scripts > 1:
+ if quiet:
+ num_found_cached_scripts = 1
+
+ if num_found_cached_scripts > 1:
+ selection = select_script_artifact(found_cached_scripts, 'cached script output', recursion_spaces, True, script_tags_string, quiet, verbose)
+
+ if selection >= 0:
+ if not skip_remembered_selections:
+ # Remember selection
+ remembered_selections.append({'type': 'cache',
+ 'tags':search_tags,
+ 'cached_script':found_cached_scripts[selection]})
+ else:
+ num_found_cached_scripts = 0
+
+
+ elif num_found_cached_scripts == 1:
+ if verbose:
+ print (recursion_spaces+' - Found cached script output: {}'.format(found_cached_scripts[0].path))
+
+
+ if num_found_cached_scripts > 0:
+ found_cached = True
+
+ # Check chain of dynamic dependencies on other CM scripts
+ if len(deps)>0:
+ if verbose:
+ print (recursion_spaces + ' - Checking dynamic dependencies on other CM scripts:')
+
+ r = self._call_run_deps(deps, self.local_env_keys, local_env_keys_from_meta, env, state, const, const_state, add_deps_recursive,
+ recursion_spaces + extra_recursion_spaces,
+ remembered_selections, variation_tags_string, True, debug_script_tags, verbose, show_time, extra_recursion_spaces, run_state)
+ if r['return']>0: return r
+
+ if verbose:
+ print (recursion_spaces + ' - Processing env after dependencies ...')
+
+ r = update_env_with_values(env)
+ if r['return']>0: return r
+
+
+ # Check chain of prehook dependencies on other CM scripts. (No execution of customize.py for cached scripts)
+ if verbose:
+ print (recursion_spaces + ' - Checking prehook dependencies on other CM scripts:')
+
+ r = self._call_run_deps(prehook_deps, self.local_env_keys, local_env_keys_from_meta, env, state, const, const_state, add_deps_recursive,
+ recursion_spaces + extra_recursion_spaces,
+ remembered_selections, variation_tags_string, found_cached, debug_script_tags, verbose, show_time, extra_recursion_spaces, run_state)
+ if r['return']>0: return r
+
+ # Continue with the selected cached script
+ cached_script = found_cached_scripts[selection]
+
+ if verbose:
+ print (recursion_spaces+' - Loading state from cached entry ...')
+
+ path_to_cached_state_file = os.path.join(cached_script.path,
+ self.file_with_cached_state)
+
+ r = utils.load_json(file_name = path_to_cached_state_file)
+ if r['return']>0: return r
+ version = r['meta'].get('version')
+
+ print (recursion_spaces + ' ! load {}'.format(path_to_cached_state_file))
+
+
+ ################################################################################################
+ # IF REUSE FROM CACHE - update env and state from cache!
+ cached_state = r['meta']
+
+ new_env = cached_state['new_env']
+ utils.merge_dicts({'dict1':env, 'dict2':new_env, 'append_lists':True, 'append_unique':True})
+
+ new_state = cached_state['new_state']
+ utils.merge_dicts({'dict1':state, 'dict2':new_state, 'append_lists':True, 'append_unique':True})
+
+ utils.merge_dicts({'dict1':new_env, 'dict2':const, 'append_lists':True, 'append_unique':True})
+ utils.merge_dicts({'dict1':new_state, 'dict2':const_state, 'append_lists':True, 'append_unique':True})
+
+
+
+
+
+
+ # Check chain of posthook dependencies on other CM scripts. We consider them same as postdeps when
+ # script is in cache
+ if verbose:
+ print (recursion_spaces + ' - Checking posthook dependencies on other CM scripts:')
+
+ clean_env_keys_post_deps = meta.get('clean_env_keys_post_deps',[])
+
+ r = self._call_run_deps(posthook_deps, self.local_env_keys, clean_env_keys_post_deps, env, state, const, const_state, add_deps_recursive,
+ recursion_spaces + extra_recursion_spaces,
+ remembered_selections, variation_tags_string, found_cached, debug_script_tags, verbose, show_time, extra_recursion_spaces, run_state)
+ if r['return']>0: return r
+
+ if verbose:
+ print (recursion_spaces + ' - Checking post dependencies on other CM scripts:')
+
+ # Check chain of post dependencies on other CM scripts
+ r = self._call_run_deps(post_deps, self.local_env_keys, clean_env_keys_post_deps, env, state, const, const_state, add_deps_recursive,
+ recursion_spaces + extra_recursion_spaces,
+ remembered_selections, variation_tags_string, found_cached, debug_script_tags, verbose, show_time, extra_recursion_spaces, run_state)
+ if r['return']>0: return r
+
+
+
+
+
+ if renew or (not found_cached and num_found_cached_scripts == 0):
+ # Add more tags to cached tags
+ # based on meta information of the found script
+ x = 'script-artifact-' + meta['uid']
+ if x not in cached_tags:
+ cached_tags.append(x)
+
+ # Add all tags from the original CM script
+ for x in meta.get('tags', []):
+ if x not in cached_tags:
+ cached_tags.append(x)
+
+
+ if not found_cached and num_found_cached_scripts == 0:
+
+ # If not cached, create cached script artifact and mark as tmp (remove if cache successful)
+ tmp_tags = ['tmp']
+
+ # Finalize tmp tags
+ tmp_tags += [ t for t in cached_tags if not t.startswith("-") ]
+
+ # Check if some variations are missing
+ # though it should not happen!
+ for t in variation_tags:
+ if t.startswith("-"):
+ continue
+ x = '_' + t
+ if x not in tmp_tags:
+ tmp_tags.append(x)
+
+ # Use update to update the tmp one if already exists
+ if verbose:
+ print (recursion_spaces+' - Creating new "cache" script artifact in the CM local repository ...')
+ print (recursion_spaces+' - Tags: {}'.format(','.join(tmp_tags)))
+
+ if version != '':
+ cached_meta['version'] = version
+
+ ii = {'action':'update',
+ 'automation': self.meta['deps']['cache'],
+ 'search_tags':tmp_tags,
+ 'tags':','.join(tmp_tags),
+ 'meta':cached_meta,
+ 'force':True}
+
+ r = self.cmind.access(ii)
+ if r['return'] > 0: return r
+
+ remove_tmp_tag = True
+
+ cached_script = r['list'][0]
+
+ cached_path = cached_script.path
+ cached_meta = cached_script.meta
+
+ cached_uid = cached_meta['uid']
+
+ # Changing path to CM script artifact for cached output
+ # to record data and files there
+ if verbose:
+ print (recursion_spaces+' - Changing to {}'.format(cached_path))
+
+ os.chdir(cached_path)
+
+
+
+ # If found cached and we want to renew it
+ if found_cached and renew:
+ cached_path = cached_script.path
+ cached_meta = cached_script.meta
+
+ cached_uid = cached_meta['uid']
+
+ # Changing path to CM script artifact for cached output
+ # to record data and files there
+ if verbose:
+ print (recursion_spaces+' - Changing to {}'.format(cached_path))
+
+ os.chdir(cached_path)
+
+ # Force to finalize script inside cached entry
+ found_cached = False
+ remove_tmp_tag = True
+
+ env['CM_RENEW_CACHE_ENTRY']='yes'
+
+ # Prepare files to be cleaned
+ clean_files = [self.tmp_file_run_state,
+ self.tmp_file_run_env,
+ self.tmp_file_ver,
+ self.tmp_file_env + bat_ext,
+ self.tmp_file_env_all + bat_ext,
+ self.tmp_file_state,
+ self.tmp_file_run + bat_ext]
+
+ if not found_cached and len(meta.get('clean_files', [])) >0:
+ clean_files = meta['clean_files'] + clean_files
+
+ ################################
+ if not found_cached:
+ if len(warnings)>0:
+ print ('=================================================')
+ print ('WARNINGS:')
+ print ('')
+ for w in warnings:
+ print (' '+w)
+ print ('=================================================')
+
+ # Update default version meta if version is not set
+ if version == '':
+ default_version = meta.get('default_version', '')
+ if default_version != '':
+ version = default_version
+
+ if version_min != '':
+ ry = self.cmind.access({'action':'compare_versions',
+ 'automation':'utils,dc2743f8450541e3',
+ 'version1':version,
+ 'version2':version_min})
+ if ry['return']>0: return ry
+
+ if ry['comparison'] < 0:
+ version = version_min
+
+ if version_max != '':
+ ry = self.cmind.access({'action':'compare_versions',
+ 'automation':'utils,dc2743f8450541e3',
+ 'version1':version,
+ 'version2':version_max})
+ if ry['return']>0: return ry
+
+ if ry['comparison'] > 0:
+ if version_max_usable!='':
+ version = version_max_usable
+ else:
+ version = version_max
+
+ if verbose:
+ print (recursion_spaces+' - Version is not specified - use either default_version from meta or min/max/usable: {}'.format(version))
+
+ env['CM_VERSION'] = version
+
+ if 'version-'+version not in cached_tags: cached_tags.append('version-'+version)
+
+ if default_version in versions:
+ versions_meta = versions[default_version]
+ r = update_state_from_meta(versions_meta, env, state, deps, post_deps, prehook_deps, posthook_deps, new_env_keys_from_meta, new_state_keys_from_meta, i)
+ if r['return']>0: return r
+
+ if "add_deps_recursive" in versions_meta:
+ self._merge_dicts_with_tags(add_deps_recursive, versions_meta['add_deps_recursive'])
+
+ # Run chain of docker dependencies if current run cmd is from inside a docker container
+ docker_deps = []
+ if i.get('docker_run_deps'):
+ docker_meta = meta.get('docker')
+ if docker_meta:
+ docker_deps = docker_meta.get('deps', [])
+ if docker_deps:
+ docker_deps = [ dep for dep in docker_deps if not dep.get('skip_inside_docker', False) ]
+
+ if len(docker_deps)>0:
+
+ if verbose:
+ print (recursion_spaces + ' - Checking docker run dependencies on other CM scripts:')
+
+ r = self._call_run_deps(docker_deps, self.local_env_keys, local_env_keys_from_meta, env, state, const, const_state, add_deps_recursive,
+ recursion_spaces + extra_recursion_spaces,
+ remembered_selections, variation_tags_string, False, debug_script_tags, verbose, show_time, extra_recursion_spaces, run_state)
+ if r['return']>0: return r
+
+ if verbose:
+ print (recursion_spaces + ' - Processing env after docker run dependencies ...')
+
+ r = update_env_with_values(env)
+ if r['return']>0: return r
+
+ # Check chain of dependencies on other CM scripts
+ if len(deps)>0:
+ if verbose:
+ print (recursion_spaces + ' - Checking dependencies on other CM scripts:')
+
+ r = self._call_run_deps(deps, self.local_env_keys, local_env_keys_from_meta, env, state, const, const_state, add_deps_recursive,
+ recursion_spaces + extra_recursion_spaces,
+ remembered_selections, variation_tags_string, False, debug_script_tags, verbose, show_time, extra_recursion_spaces, run_state)
+ if r['return']>0: return r
+
+ if verbose:
+ print (recursion_spaces + ' - Processing env after dependencies ...')
+
+ r = update_env_with_values(env)
+ if r['return']>0: return r
+
+ # Clean some output files
+ clean_tmp_files(clean_files, recursion_spaces)
+
+ # Check if has customize.py
+ path_to_customize_py = os.path.join(path, 'customize.py')
+ customize_code = None
+
+ # Prepare common input to prepare and run script
+ run_script_input = {
+ 'path': path,
+ 'bat_ext': bat_ext,
+ 'os_info': os_info,
+ 'const': const,
+ 'state': state,
+ 'const_state': const_state,
+ 'reuse_cached': reuse_cached,
+ 'recursion': recursion,
+ 'recursion_spaces': recursion_spaces,
+ 'remembered_selections': remembered_selections,
+ 'tmp_file_run_state': self.tmp_file_run_state,
+ 'tmp_file_run_env': self.tmp_file_run_env,
+ 'tmp_file_state': self.tmp_file_state,
+ 'tmp_file_run': self.tmp_file_run,
+ 'local_env_keys': self.local_env_keys,
+ 'local_env_keys_from_meta': local_env_keys_from_meta,
+ 'posthook_deps': posthook_deps,
+ 'add_deps_recursive': add_deps_recursive,
+ 'remembered_selections': remembered_selections,
+ 'found_script_tags': found_script_tags,
+ 'variation_tags_string': variation_tags_string,
+ 'found_cached': False,
+ 'debug_script_tags': debug_script_tags,
+ 'verbose': verbose,
+ 'meta':meta,
+ 'self': self
+ }
+
+ if repro_prefix != '': run_script_input['repro_prefix'] = repro_prefix
+ if ignore_script_error: run_script_input['ignore_script_error'] = True
+
+ if os.path.isfile(path_to_customize_py):
+ r=utils.load_python_module({'path':path, 'name':'customize'})
+ if r['return']>0: return r
+
+ customize_code = r['code']
+
+ customize_common_input = {
+ 'input':i,
+ 'automation':self,
+ 'artifact':script_artifact,
+ 'customize':script_artifact.meta.get('customize',{}),
+ 'os_info':os_info,
+ 'recursion_spaces':recursion_spaces,
+ 'script_tags':script_tags,
+ 'variation_tags':variation_tags
+ }
+
+ run_script_input['customize_code'] = customize_code
+ run_script_input['customize_common_input'] = customize_common_input
+
+ # Assemble PIP versions
+ pip_version_string = ''
+
+ pip_version = env.get('CM_VERSION', '')
+ pip_version_min = env.get('CM_VERSION_MIN', '')
+ pip_version_max = env.get('CM_VERSION_MAX', '')
+
+ if pip_version != '':
+ pip_version_string = '=='+pip_version
+ elif pip_version_min != '' and pip_version_max != '':
+ pip_version_string = '>='+pip_version_min+',<='+pip_version_max
+ elif pip_version_min != '':
+ pip_version_string = '>='+pip_version_min
+ elif pip_version_max != '':
+ pip_version_string = '<='+pip_version_max
+
+ env['CM_TMP_PIP_VERSION_STRING'] = pip_version_string
+ if pip_version_string != '':
+ if verbose:
+ print (recursion_spaces+' # potential PIP version string (if needed): '+pip_version_string)
+
+ # Check if pre-process and detect
+ if 'preprocess' in dir(customize_code) and not fake_run:
+
+ if verbose:
+ print (recursion_spaces+' - Running preprocess ...')
+
+ # Update env and state with const
+ utils.merge_dicts({'dict1':env, 'dict2':const, 'append_lists':True, 'append_unique':True})
+ utils.merge_dicts({'dict1':state, 'dict2':const_state, 'append_lists':True, 'append_unique':True})
+
+ run_script_input['run_state'] = run_state
+
+ ii = copy.deepcopy(customize_common_input)
+ ii['env'] = env
+ ii['state'] = state
+ ii['meta'] = meta
+ ii['run_script_input'] = run_script_input # may need to detect versions in multiple paths
+
+ r = customize_code.preprocess(ii)
+ if r['return']>0: return r
+
+ # Check if preprocess says to skip this component
+ skip = r.get('skip', False)
+
+ if skip:
+ if verbose:
+ print (recursion_spaces+' - this script is skipped!')
+
+ # Check if script asks to run other dependencies instead of the skipped one
+ another_script = r.get('script', {})
+
+ if len(another_script) == 0:
+ return {'return':0, 'skipped': True}
+
+ if verbose:
+ print (recursion_spaces+' - another script is executed instead!')
+
+ ii = {
+ 'action':'run',
+ 'automation':utils.assemble_cm_object(self.meta['alias'], self.meta['uid']),
+ 'recursion_spaces':recursion_spaces + extra_recursion_spaces,
+ 'recursion':True,
+ 'remembered_selections': remembered_selections,
+ 'env':env,
+ 'state':state,
+ 'const':const,
+ 'const_state':const_state,
+ 'save_env':save_env,
+ 'add_deps_recursive':add_deps_recursive
+ }
+
+ ii.update(another_script)
+
+ # Return to current path
+ os.chdir(current_path)
+
+ ############################################################################################################
+ return self.cmind.access(ii)
+
+ # If return version
+ if cache:
+ if r.get('version','') != '':
+ cached_tags = [x for x in cached_tags if not x.startswith('version-')]
+ cached_tags.append('version-' + r['version'])
+
+ if len(r.get('add_extra_cache_tags',[]))>0:
+ for t in r['add_extra_cache_tags']:
+ if t not in cached_tags:
+ cached_tags.append(t)
+
+
+ if print_env:
+ import json
+ if verbose:
+ print (json.dumps(env, indent=2, sort_keys=True))
+
+ # Check chain of pre hook dependencies on other CM scripts
+ if len(prehook_deps)>0:
+ if verbose:
+ print (recursion_spaces + ' - Checking prehook dependencies on other CM scripts:')
+
+ r = self._call_run_deps(prehook_deps, self.local_env_keys, local_env_keys_from_meta, env, state, const, const_state, add_deps_recursive,
+ recursion_spaces + extra_recursion_spaces,
+ remembered_selections, variation_tags_string, found_cached, debug_script_tags, verbose, show_time, extra_recursion_spaces, run_state)
+ if r['return']>0: return r
+
+ if not fake_run:
+ env_key_mappings = meta.get("env_key_mappings", {})
+ if env_key_mappings:
+ update_env_keys(env, env_key_mappings)
+
+ run_script_input['meta'] = meta
+ run_script_input['env'] = env
+ run_script_input['run_state'] = run_state
+ run_script_input['recursion'] = recursion
+
+ r = prepare_and_run_script_with_postprocessing(run_script_input)
+ if r['return']>0: return r
+
+ # If return version
+ if r.get('version','') != '':
+ version = r.get('version')
+ if cache:
+ cached_tags = [x for x in cached_tags if not x.startswith('version-')]
+ cached_tags.append('version-' + r['version'])
+
+ if len(r.get('add_extra_cache_tags',[]))>0 and cache:
+ for t in r['add_extra_cache_tags']:
+ if t not in cached_tags:
+ cached_tags.append(t)
+
+ # Check chain of post dependencies on other CM scripts
+ clean_env_keys_post_deps = meta.get('clean_env_keys_post_deps',[])
+
+ r = self._run_deps(post_deps, clean_env_keys_post_deps, env, state, const, const_state, add_deps_recursive, recursion_spaces,
+ remembered_selections, variation_tags_string, found_cached, debug_script_tags, verbose, show_time, extra_recursion_spaces, run_state)
+ if r['return']>0: return r
+
+ # Add extra tags from env updated by deps (such as python version and compiler version, etc)
+ extra_cache_tags_from_env = meta.get('extra_cache_tags_from_env',[])
+ for extra_cache_tags in extra_cache_tags_from_env:
+ key = extra_cache_tags['env']
+ prefix = extra_cache_tags.get('prefix','')
+
+ v = env.get(key,'').strip()
+ if v!='':
+ for t in v.split(','):
+ x = 'deps-' + prefix + t
+ if x not in cached_tags:
+ cached_tags.append(x)
+
+
+ detected_version = env.get('CM_DETECTED_VERSION', env.get('CM_VERSION',''))
+ dependent_cached_path = env.get('CM_GET_DEPENDENT_CACHED_PATH','')
+
+ ############################################################################################################
+ ##################################### Finalize script
+
+ # Force consts in the final new env and state
+ utils.merge_dicts({'dict1':env, 'dict2':const, 'append_lists':True, 'append_unique':True})
+ utils.merge_dicts({'dict1':state, 'dict2':const_state, 'append_lists':True, 'append_unique':True})
+
+ if i.get('force_new_env_keys', []):
+ new_env_keys = i['force_new_env_keys']
+ else:
+ new_env_keys = new_env_keys_from_meta
+
+ if i.get('force_new_state_keys', []):
+ new_state_keys = i['force_new_state_keys']
+ else:
+ new_state_keys = new_state_keys_from_meta
+
+ r = detect_state_diff(env, saved_env, new_env_keys, new_state_keys, state, saved_state)
+ if r['return']>0: return r
+
+ new_env = r['new_env']
+ new_state = r['new_state']
+
+ utils.merge_dicts({'dict1':saved_env, 'dict2':new_env, 'append_lists':True, 'append_unique':True})
+ utils.merge_dicts({'dict1':saved_state, 'dict2':new_state, 'append_lists':True, 'append_unique':True})
+
+
+
+ # Restore original env/state and merge env/state
+ # This is needed since we want to keep original env/state outside this script
+ # If we delete env and create a new dict, the original one outside this script will be detached
+ # That's why we just clean all keys in original env/state (used oustide)
+ # And then copy saved_env (with new_env merged) and saved_state (with new_state merged)
+ # while getting rid of all temporal updates in env and state inside this script
+
+ for k in list(env.keys()):
+ del(env[k])
+ for k in list(state.keys()):
+ del(state[k])
+
+ env.update(saved_env)
+ state.update(saved_state)
+
+
+
+ # Prepare env script content (to be saved in cache and in the current path if needed)
+ env_script = convert_env_to_script(new_env, os_info, start_script = os_info['start_script'])
+
+ # If using cached script artifact, return to default path and then update the cache script artifact
+ if cache and cached_path!='':
+ # Check if need to remove tag
+ if remove_tmp_tag:
+ # Save state, env and deps for reuse
+ r = utils.save_json(file_name = os.path.join(cached_path, self.file_with_cached_state),
+ meta={'new_state':new_state, 'new_env':new_env, 'deps':deps, 'version': version})
+ if r['return']>0: return r
+
+ # Save all env
+ env_all_script = convert_env_to_script(env, os_info, start_script = os_info['start_script'])
+
+ r = record_script(os.path.join(cached_path, self.tmp_file_env_all + bat_ext),
+ env_all_script, os_info)
+ if r['return']>0: return r
+
+ # Save env
+ r = record_script(os.path.join(cached_path, self.tmp_file_env + bat_ext),
+ env_script, os_info)
+ if r['return']>0: return r
+
+ # Remove tmp tag from the "cached" arifact to finalize caching
+ if verbose:
+ print (recursion_spaces+' - Removing tmp tag in the script cached output {} ...'.format(cached_uid))
+
+ # Check if version was detected and record in meta)
+ if detected_version != '':
+ cached_meta['version'] = detected_version
+
+ if found_script_artifact != '':
+ cached_meta['associated_script_artifact'] = found_script_artifact
+
+ x = found_script_artifact.find(',')
+ if x<0:
+ return {'return':1, 'error':'CM artifact format is wrong "{}" - no comma found'.format(found_script_artifact)}
+
+ cached_meta['associated_script_artifact_uid'] = found_script_artifact[x+1:]
+
+
+ # Check if the cached entry is dependent on any other cached entry
+ if dependent_cached_path != '':
+ if os.path.isdir(cached_path) and os.path.isdir(dependent_cached_path):
+ if not os.path.samefile(cached_path, dependent_cached_path):
+ cached_meta['dependent_cached_path'] = dependent_cached_path
+
+ ii = {'action': 'update',
+ 'automation': self.meta['deps']['cache'],
+ 'artifact': cached_uid,
+ 'meta':cached_meta,
+ 'replace_lists': True, # To replace tags
+ 'tags':','.join(cached_tags)}
+
+ r = self.cmind.access(ii)
+ if r['return']>0: return r
+
+ # Clean tmp files only in current path (do not touch cache - we keep all info there)
+ script_path = os.getcwd()
+ os.chdir(current_path)
+
+ shell = i.get('shell', False)
+# if not shell:
+# shell = i.get('debug', False)
+
+ if not shell and not i.get('dirty', False) and not cache:
+ clean_tmp_files(clean_files, recursion_spaces)
+
+ # Record new env and new state in the current dir if needed
+ if save_env or shell:
+ # Check if script_prefix in the state from other components
+ where_to_add = len(os_info['start_script'])
+
+ script_prefix = state.get('script_prefix',[])
+ if len(script_prefix)>0:
+ env_script.insert(where_to_add, '\n')
+ for x in reversed(script_prefix):
+ env_script.insert(where_to_add, x)
+
+ if shell:
+ x=['cmd', '.', '','.bat',''] if os_info['platform'] == 'windows' else ['bash', ' ""', '"','.sh','. ./']
+
+ env_script.append('\n')
+ env_script.append('echo{}\n'.format(x[1]))
+ env_script.append('echo {}Working path: {}{}'.format(x[2], script_path, x[2]))
+ xtmp_run_file = ''
+ tmp_run_file = 'tmp-run{}'.format(x[3])
+ if os.path.isfile(tmp_run_file):
+ xtmp_run_file = 'Change and run "{}". '.format(tmp_run_file)
+
+ env_script.append('echo {}Running debug shell. {}Type exit to quit ...{}\n'.format(x[2], xtmp_run_file, x[2]))
+ env_script.append('echo{}\n'.format(x[1]))
+ env_script.append('\n')
+ env_script.append(x[0])
+
+ env_file = self.tmp_file_env + bat_ext
+
+ r = record_script(env_file, env_script, os_info)
+ if r['return']>0: return r
+
+ if shell:
+ x = env_file if os_info['platform'] == 'windows' else '. ./'+env_file
+ os.system(x)
+
+ if not version and detected_version:
+ version = detected_version
+
+ if version:
+ script_uid = script_artifact.meta.get('uid')
+ script_alias = script_artifact.meta.get('alias')
+ script_tags = script_artifact.meta.get('tags')
+ version_info = {}
+ version_info_tags = ",".join(script_tags + variation_tags)
+ version_info[version_info_tags] = {}
+ version_info[version_info_tags]['script_uid'] = script_uid
+ version_info[version_info_tags]['script_alias'] = script_alias
+ version_info[version_info_tags]['version'] = version
+ version_info[version_info_tags]['parent'] = run_state['parent']
+ run_state['version_info'].append(version_info)
+ script_versions = detected_versions.get(meta['uid'], [])
+ if not script_versions:
+ detected_versions[meta['uid']] = [ version ]
+ else:
+ script_versions.append(version)
+ else:
+ pass # these scripts don't have versions. Should we use cm mlops version here?
+
+ ############################# RETURN
+ elapsed_time = time.time() - start_time
+
+ if verbose and cached_uid!='':
+ print (recursion_spaces+' - cache UID: {}'.format(cached_uid))
+
+ if print_deps:
+ print_deps_data = self._print_deps(run_state['deps'])
+ new_state['print_deps'] = print_deps_data
+
+ if print_readme:
+ readme = self._get_readme(i.get('cmd', ''), run_state['deps'])
+ with open('readme.md', 'w') as f:
+ f.write(readme)
+
+ if i.get('dump_version_info'):
+ r = self._dump_version_info_for_script()
+ if r['return'] > 0:
+ return r
+
+ rr = {'return':0, 'env':env, 'new_env':new_env, 'state':state, 'new_state':new_state, 'deps': run_state['deps']}
+
+ # Print output as json to console
+ if i.get('json', False) or i.get('j', False):
+ import json
+
+ print ('')
+ print (json.dumps(rr, indent=2))
+
+
+
+ # Check if save json to file
+ if repro_prefix !='':
+ dump_repro(repro_prefix, rr, run_state)
+
+ if verbose or show_time:
+ print (recursion_spaces+' - running time of script "{}": {:.2f} sec.'.format(','.join(found_script_tags), elapsed_time))
+
+
+ if not recursion and show_space:
+ stop_disk_stats = shutil.disk_usage("/")
+
+ used_disk_space_in_mb = int((start_disk_stats.free - stop_disk_stats.free) / (1024*1024))
+
+ if used_disk_space_in_mb > 0:
+ print (recursion_spaces+' - used disk space: {} MB'.format(used_disk_space_in_mb))
+
+
+ # Check if pause (useful if running a given script in a new terminal that may close automatically)
+ if i.get('pause', False):
+ print ('')
+ input ('Press Enter to continue ...')
+
+ # Check if need to print some final info such as path to model, etc
+ print_env_at_the_end = meta.get('print_env_at_the_end',{})
+ if len(print_env_at_the_end)>0:
+ print ('')
+
+ for p in sorted(print_env_at_the_end):
+ t = print_env_at_the_end[p]
+ if t == '': t = 'ENV[{}]'.format(p)
+
+ v = new_env.get(p, None)
+
+ print ('{}: {}'.format(t, str(v)))
+
+ print ('')
+
+ return rr
+
+ ######################################################################################
+ def _dump_version_info_for_script(self, output_dir = os.getcwd()):
+ import json
+ with open(os.path.join(output_dir, 'version_info.json'), 'w') as f:
+ f.write(json.dumps(self.run_state['version_info'], indent=2))
+ return {'return': 0}
+
+ ######################################################################################
+ def _update_state_from_variations(self, i, meta, variation_tags, variations, env, state, deps, post_deps, prehook_deps, posthook_deps, new_env_keys_from_meta, new_state_keys_from_meta, add_deps_recursive, run_state, recursion_spaces, verbose):
+
+ # Save current explicit variations
+ import copy
+ explicit_variation_tags=copy.deepcopy(variation_tags)
+
+ # Calculate space
+ required_disk_space = {}
+
+ # Check if warning
+ warnings = []
+
+ # variation_tags get appended by any aliases
+ r = self._get_variations_with_aliases(variation_tags, variations)
+ if r['return'] > 0:
+ return r
+ variation_tags = r['variation_tags']
+ excluded_variation_tags = r['excluded_variation_tags']
+
+ # Get a dictionary of variation groups
+ r = self._get_variation_groups(variations)
+ if r['return'] > 0:
+ return r
+
+ variation_groups = r['variation_groups']
+
+ run_state['variation_groups'] = variation_groups
+
+ # Add variation(s) if specified in the "tags" input prefixed by _
+ # If there is only 1 default variation, then just use it or substitute from CMD
+
+ default_variation = meta.get('default_variation', '')
+
+ if default_variation and default_variation not in variations:
+ return {'return': 1, 'error': 'Default variation "{}" is not in the list of variations: "{}" '.format(default_variation, variations.keys())}
+
+ if len(variation_tags) == 0:
+ if default_variation != '' and default_variation not in excluded_variation_tags:
+ variation_tags = [default_variation]
+
+ r = self._update_variation_tags_from_variations(variation_tags, variations, variation_groups, excluded_variation_tags)
+ if r['return'] > 0:
+ return r
+
+ # variation_tags get appended by any default on variation in groups
+ r = self._process_variation_tags_in_groups(variation_tags, variation_groups, excluded_variation_tags, variations)
+ if r['return'] > 0:
+ return r
+ if variation_tags != r['variation_tags']:
+ variation_tags = r['variation_tags']
+
+ # we need to again process variation tags if any new default variation is added
+ r = self._update_variation_tags_from_variations(variation_tags, variations, variation_groups, excluded_variation_tags)
+ if r['return'] > 0:
+ return r
+
+
+ valid_variation_combinations = meta.get('valid_variation_combinations', [])
+ if valid_variation_combinations:
+ if not any ( all(t in variation_tags for t in s) for s in valid_variation_combinations):
+ return {'return': 1, 'error': 'Invalid variation combination "{}" prepared. Valid combinations: "{}" '.format(variation_tags, valid_variation_combinations)}
+
+ invalid_variation_combinations = meta.get('invalid_variation_combinations', [])
+ if invalid_variation_combinations:
+ if any ( all(t in variation_tags for t in s) for s in invalid_variation_combinations):
+ return {'return': 1, 'error': 'Invalid variation combination "{}" prepared. Invalid combinations: "{}" '.format(variation_tags, invalid_variation_combinations)}
+
+ variation_tags_string = ''
+ if len(variation_tags)>0:
+ for t in variation_tags:
+ if variation_tags_string != '':
+ variation_tags_string += ','
+
+ x = '_' + t
+ variation_tags_string += x
+
+ if verbose:
+ print (recursion_spaces+' Prepared variations: {}'.format(variation_tags_string))
+
+ # Update env and other keys if variations
+ if len(variation_tags)>0:
+ for variation_tag in variation_tags:
+ if variation_tag.startswith('~'):
+ # ignore such tag (needed for caching only to differentiate variations)
+ continue
+
+ if variation_tag.startswith('-'):
+ # ignore such tag (needed for caching only to eliminate variations)
+ continue
+
+ variation_tag_dynamic_suffix = None
+ if variation_tag not in variations:
+ if '.' in variation_tag and variation_tag[-1] != '.':
+ variation_tag_dynamic_suffix = variation_tag[variation_tag.index(".")+1:]
+ if not variation_tag_dynamic_suffix:
+ return {'return':1, 'error':'tag {} is not in variations {}'.format(variation_tag, variations.keys())}
+ variation_tag = self._get_name_for_dynamic_variation_tag(variation_tag)
+ if variation_tag not in variations:
+ return {'return':1, 'error':'tag {} is not in variations {}'.format(variation_tag, variations.keys())}
+
+ variation_meta = variations[variation_tag]
+ if variation_tag_dynamic_suffix:
+ self._update_variation_meta_with_dynamic_suffix(variation_meta, variation_tag_dynamic_suffix)
+
+ r = update_state_from_meta(variation_meta, env, state, deps, post_deps, prehook_deps, posthook_deps, new_env_keys_from_meta, new_state_keys_from_meta, i)
+ if r['return']>0: return r
+
+ if variation_meta.get('script_name', '')!='':
+ meta['script_name'] = variation_meta['script_name']
+
+ if variation_meta.get('required_disk_space', 0) > 0 and variation_tag not in required_disk_space:
+ required_disk_space[variation_tag] = variation_meta['required_disk_space']
+
+ if variation_meta.get('warning', '') != '':
+ x = variation_meta['warning']
+ if x not in warnings: warnings.append()
+
+ adr=get_adr(variation_meta)
+ if adr:
+ self._merge_dicts_with_tags(add_deps_recursive, adr)
+
+ combined_variations = [ t for t in variations if ',' in t ]
+
+ combined_variations.sort(key=lambda x: x.count(','))
+ ''' By sorting based on the number of variations users can safely override
+ env and state in a larger combined variation
+ '''
+
+ for combined_variation in combined_variations:
+ v = combined_variation.split(",")
+ all_present = set(v).issubset(set(variation_tags))
+ if all_present:
+
+ combined_variation_meta = variations[combined_variation]
+
+ r = update_state_from_meta(combined_variation_meta, env, state, deps, post_deps, prehook_deps, posthook_deps, new_env_keys_from_meta, new_state_keys_from_meta, i)
+ if r['return']>0: return r
+
+ adr=get_adr(combined_variation_meta)
+ if adr:
+ self._merge_dicts_with_tags(add_deps_recursive, adr)
+
+ if combined_variation_meta.get('script_name', '')!='':
+ meta['script_name'] = combined_variation_meta['script_name']
+
+ if combined_variation_meta.get('required_disk_space', 0) > 0 and combined_variation not in required_disk_space:
+ required_disk_space[combined_variation] = combined_variation_meta['required_disk_space']
+
+ if combined_variation_meta.get('warning', '') != '':
+ x = combined_variation_meta['warning']
+ if x not in warnings: warnings.append(x)
+
+ #Processing them again using updated deps for add_deps_recursive
+ r = update_adr_from_meta(deps, post_deps, prehook_deps, posthook_deps, add_deps_recursive)
+ if r['return']>0: return r
+
+ if len(required_disk_space)>0:
+ required_disk_space_sum_mb = sum(list(required_disk_space.values()))
+
+ warnings.append('Required disk space: {} MB'.format(required_disk_space_sum_mb))
+
+ return {'return': 0, 'variation_tags_string': variation_tags_string, 'explicit_variation_tags': explicit_variation_tags, 'warnings':warnings}
+
+ ######################################################################################
+ def _update_variation_tags_from_variations(self, variation_tags, variations, variation_groups, excluded_variation_tags):
+
+ import copy
+ tmp_variation_tags_static = copy.deepcopy(variation_tags)
+ for v_i in range(len(tmp_variation_tags_static)):
+ v = tmp_variation_tags_static[v_i]
+
+ if v not in variations:
+ v_static = self._get_name_for_dynamic_variation_tag(v)
+ tmp_variation_tags_static[v_i] = v_static
+
+ combined_variations = [ t for t in variations if ',' in t ]
+ # We support default_variations in the meta of cmbined_variations
+ combined_variations.sort(key=lambda x: x.count(','))
+ ''' By sorting based on the number of variations users can safely override
+ env and state in a larger combined variation
+ '''
+ tmp_combined_variations = {k: False for k in combined_variations}
+
+ # Recursively add any base variations specified
+ if len(variation_tags) > 0:
+ tmp_variations = {k: False for k in variation_tags}
+ while True:
+ for variation_name in variation_tags:
+ tag_to_append = None
+
+ #ignore the excluded variations
+ if variation_name.startswith("~") or variation_name.startswith("-"):
+ tmp_variations[variation_name] = True
+ continue
+
+ if variation_name not in variations:
+ variation_name = self._get_name_for_dynamic_variation_tag(variation_name)
+
+ # base variations are automatically turned on. Only variations outside of any variation group can be added as a base_variation
+ if "base" in variations[variation_name]:
+ base_variations = variations[variation_name]["base"]
+ for base_variation in base_variations:
+ dynamic_base_variation = False
+ dynamic_base_variation_already_added = False
+ if base_variation not in variations:
+ base_variation_dynamic = self._get_name_for_dynamic_variation_tag(base_variation)
+ if not base_variation_dynamic or base_variation_dynamic not in variations:
+ return {'return': 1, 'error': 'Variation "{}" specified as base variation of "{}" is not existing'.format(base_variation, variation_name)}
+ else:
+ dynamic_base_variation = True
+ base_prefix = base_variation_dynamic.split(".")[0]+"."
+ for x in variation_tags:
+ if x.startswith(base_prefix):
+ dynamic_base_variation_already_added = True
+
+ if base_variation not in variation_tags and not dynamic_base_variation_already_added:
+ tag_to_append = base_variation
+
+ if tag_to_append:
+ if tag_to_append in excluded_variation_tags:
+ return {'return': 1, 'error': 'Variation "{}" specified as base variation for the variation is in the excluded list "{}" '.format(tag_to_append, variation_name)}
+ variation_tags.append(tag_to_append)
+ tmp_variations[tag_to_append] = False
+
+ tag_to_append = None
+
+ # default_variations dictionary specifies the default_variation for each variation group. A default variation in a group is turned on if no other variation from that group is turned on and it is not excluded using the '-' prefix
+ r = self._get_variation_tags_from_default_variations(variations[variation_name], variations, variation_groups, tmp_variation_tags_static, excluded_variation_tags)
+ if r['return'] > 0:
+ return r
+
+ variations_to_add = r['variations_to_add']
+ for t in variations_to_add:
+ tmp_variations[t] = False
+ variation_tags.append(t)
+
+ tmp_variations[variation_name] = True
+
+ for combined_variation in combined_variations:
+ if tmp_combined_variations[combined_variation]:
+ continue
+ v = combined_variation.split(",")
+ all_present = set(v).issubset(set(variation_tags))
+ if all_present:
+ combined_variation_meta = variations[combined_variation]
+ tmp_combined_variations[combined_variation] = True
+
+ r = self._get_variation_tags_from_default_variations(combined_variation_meta, variations, variation_groups, tmp_variation_tags_static, excluded_variation_tags)
+ if r['return'] > 0:
+ return r
+
+ variations_to_add = r['variations_to_add']
+ for t in variations_to_add:
+ tmp_variations[t] = False
+ variation_tags.append(t)
+
+ all_base_processed = True
+ for variation_name in variation_tags:
+ if variation_name.startswith("-"):
+ continue
+ if variation_name not in variations:
+ variation_name = self._get_name_for_dynamic_variation_tag(variation_name)
+ if tmp_variations[variation_name] == False:
+ all_base_processed = False
+ break
+ if all_base_processed:
+ break
+ return {'return': 0}
+
+ ######################################################################################
+ def _get_variation_tags_from_default_variations(self, variation_meta, variations, variation_groups, tmp_variation_tags_static, excluded_variation_tags):
+ # default_variations dictionary specifies the default_variation for each variation group. A default variation in a group is turned on if no other variation from that group is turned on and it is not excluded using the '-' prefix
+
+ tmp_variation_tags = []
+ if "default_variations" in variation_meta:
+ default_base_variations = variation_meta["default_variations"]
+ for default_base_variation in default_base_variations:
+ tag_to_append = None
+
+ if default_base_variation not in variation_groups:
+ return {'return': 1, 'error': 'Default variation "{}" is not a valid group. Valid groups are "{}" '.format(default_base_variation, variation_groups)}
+
+ unique_allowed_variations = variation_groups[default_base_variation]['variations']
+ # add the default only if none of the variations from the current group is selected and it is not being excluded with - prefix
+ if len(set(unique_allowed_variations) & set(tmp_variation_tags_static)) == 0 and default_base_variations[default_base_variation] not in excluded_variation_tags and default_base_variations[default_base_variation] not in tmp_variation_tags_static:
+ tag_to_append = default_base_variations[default_base_variation]
+
+ if tag_to_append:
+ if tag_to_append not in variations:
+ variation_tag_static = self._get_name_for_dynamic_variation_tag(tag_to_append)
+ if not variation_tag_static or variation_tag_static not in variations:
+ return {'return': 1, 'error': 'Invalid variation "{}" specified in default variations for the variation "{}" '.format(tag_to_append, variation_meta)}
+ tmp_variation_tags.append(tag_to_append)
+
+ return {'return': 0, 'variations_to_add': tmp_variation_tags}
+
+ ############################################################
+ def version(self, i):
+ """
+ Print version
+
+ Args:
+ (CM input dict):
+
+ (out) (str): if 'con', output to console
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ """
+
+ console = i.get('out') == 'con'
+
+ version = self.__version__
+
+ if console:
+ print (version)
+
+ return {'return':0, 'version':version}
+
+
+ ############################################################
+ def search(self, i):
+ """
+ Overriding the automation search function to filter out scripts not matching the given variation tags
+
+ TBD: add input/output description
+ """
+
+ console = i.get('out') == 'con'
+
+ # Check simplified CMD: cm run script "get compiler"
+ # If artifact has spaces, treat them as tags!
+ artifact = i.get('artifact','')
+ if ' ' in artifact: # or ',' in artifact:
+ del(i['artifact'])
+ if 'parsed_artifact' in i: del(i['parsed_artifact'])
+ # Force substitute tags
+ i['tags']=artifact.replace(' ',',')
+
+ ############################################################################################################
+ # Process tags to find script(s) and separate variations
+ # (not needed to find scripts)
+ tags_string = i.get('tags','').strip()
+
+ tags = [] if tags_string == '' else tags_string.split(',')
+
+ script_tags = []
+ variation_tags = []
+
+ for t in tags:
+ t = t.strip()
+ if t != '':
+ if t.startswith('_'):
+ tx = t[1:]
+ if tx not in variation_tags:
+ variation_tags.append(tx)
+ elif t.startswith('-_'):
+ tx = '-' + t[2:]
+ if tx not in variation_tags:
+ variation_tags.append(tx)
+ else:
+ script_tags.append(t)
+
+ excluded_tags = [ v[1:] for v in script_tags if v.startswith("-") ]
+ common = set(script_tags).intersection(set(excluded_tags))
+ if common:
+ return {'return':1, 'error': 'There is common tags {} in the included and excluded lists'.format(common)}
+
+ excluded_variation_tags = [ v[1:] for v in variation_tags if v.startswith("-") ]
+ common = set(variation_tags).intersection(set(excluded_variation_tags))
+ if common:
+ return {'return':1, 'error': 'There is common variation tags {} in the included and excluded lists'.format(common)}
+
+ ############################################################################################################
+ # Find CM script(s) based on thier tags to get their meta (can be more than 1)
+ # Then check if variations exists inside meta
+
+ i['tags'] = ','.join(script_tags)
+
+ i['out'] = None
+ i['common'] = True
+
+ r = super(CAutomation,self).search(i)
+ if r['return']>0: return r
+
+ lst = r['list']
+
+ r['unfiltered_list'] = lst
+
+ found_scripts = False if len(lst) == 0 else True
+
+ if found_scripts and len(variation_tags)>0:
+ filtered = []
+
+ for script_artifact in lst:
+ meta = script_artifact.meta
+ variations = meta.get('variations', {})
+
+ matched = True
+ for t in variation_tags:
+ if t.startswith('-'):
+ t = t[1:]
+ if t in variations:
+ continue
+ matched = False
+ for s in variations:
+ if s.endswith('.#'):
+ if t.startswith(s[:-1]) and t[-1] != '.':
+ matched = True
+ break
+ if not matched:
+ break
+ if not matched:
+ continue
+
+ filtered.append(script_artifact)
+
+ if len(lst) > 0 and not filtered:
+ warning = [""]
+ for script in lst:
+ meta = script.meta
+ variations = meta.get('variations', {})
+ warning.append('variation tags {} are not matching for the found script {} with variations {}\n'.format(variation_tags, meta.get('alias'), variations.keys()))
+ r['warning'] = "\n".join(warning)
+
+ r['list'] = filtered
+
+ # Print filtered paths if console
+ if console:
+ for script in r['list']:
+ print (script.path)
+
+ # Finalize output
+ r['script_tags'] = script_tags
+ r['variation_tags'] = variation_tags
+ r['found_scripts'] = found_scripts
+
+ return r
+
+ ############################################################
+ def test(self, i):
+ """
+ Test automation (TBD)
+
+ Args:
+ (CM input dict):
+
+ (out) (str): if 'con', output to console
+
+ automation (str): automation as CM string object
+
+ parsed_automation (list): prepared in CM CLI or CM access function
+ [ (automation alias, automation UID) ] or
+ [ (automation alias, automation UID), (automation repo alias, automation repo UID) ]
+
+ (artifact) (str): artifact as CM string object
+
+ (parsed_artifact) (list): prepared in CM CLI or CM access function
+ [ (artifact alias, artifact UID) ] or
+ [ (artifact alias, artifact UID), (artifact repo alias, artifact repo UID) ]
+
+ ...
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ * Output from this automation action
+
+ """
+
+ import json
+
+ # Check parsed automation
+ if 'parsed_automation' not in i:
+ return {'return':1, 'error':'automation is not specified'}
+
+ console = i.get('out') == 'con'
+
+ # Find CM artifact(s)
+ i['out'] = None
+ r = self.search(i)
+
+ if r['return']>0: return r
+
+ lst = r['list']
+ for script_artifact in lst:
+ path = script_artifact.path
+ meta = script_artifact.meta
+ original_meta = script_artifact.original_meta
+
+ alias = meta.get('alias','')
+ uid = meta.get('uid','')
+
+ if console:
+ print ('')
+ print (path)
+ print (' Test: TBD')
+
+
+ return {'return':0, 'list': lst}
+
+
+ ############################################################
+ def native_run(self, i):
+ """
+ Add CM script
+
+ Args:
+ (CM input dict):
+
+ env (dict): environment
+ command (str): string
+ ...
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ """
+
+ env = i.get('env', {})
+ cmd = i.get('command', '')
+
+ script = i.get('script',[])
+
+ # Create temporary script name
+ script_name = i.get('script_name','')
+ if script_name=='':
+ script_name='tmp-native-run.'
+
+ if os.name == 'nt':
+ script_name+='bat'
+ else:
+ script_name+='sh'
+
+ if os.name == 'nt':
+ xcmd = 'call '+script_name
+
+ if len(script)==0:
+ script.append('@echo off')
+ script.append('')
+ else:
+ xcmd = 'chmod 755 '+script_name+' ; ./'+script_name
+
+ if len(script)==0:
+ script.append('#!/bin/bash')
+ script.append('')
+
+ # Assemble env
+ if len(env)>0:
+ for k in env:
+ v=env[k]
+
+ if os.name == 'nt':
+ script.append('set '+k+'='+v)
+ else:
+ if ' ' in v: v='"'+v+'"'
+ script.append('export '+k+'='+v)
+
+ script.append('')
+
+ # Add CMD
+ script.append(cmd)
+
+ # Record script
+ r = utils.save_txt(file_name=script_name, string='\n'.join(script))
+ if r['return']>0: return r
+
+ # Run script
+ rc = os.system(xcmd)
+
+ return {'return':0, 'return_code':rc}
+
+ ############################################################
+ def add(self, i):
+ """
+ Add CM script
+
+ Args:
+ (CM input dict):
+
+ (out) (str): if 'con', output to console
+
+ parsed_artifact (list): prepared in CM CLI or CM access function
+ [ (artifact alias, artifact UID) ] or
+ [ (artifact alias, artifact UID), (artifact repo alias, artifact repo UID) ]
+
+ (tags) (str): tags to find an CM script (CM artifact)
+
+ (script_name) (str): name of script (it will be copied to the new entry and added to the meta)
+
+ (tags) (string or list): tags to be added to meta
+
+ (new_tags) (string or list): new tags to be added to meta (the same as tags)
+
+ (json) (bool): if True, record JSON meta instead of YAML
+
+ (meta) (dict): preloaded meta
+
+ (template) (string): template to use (python)
+ (python) (bool): template=python
+ (pytorch) (bool): template=pytorch
+ ...
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ """
+
+ import shutil
+
+ console = i.get('out') == 'con'
+
+ # Try to find script artifact by alias and/or tags
+ ii = utils.sub_input(i, self.cmind.cfg['artifact_keys'])
+
+ parsed_artifact = i.get('parsed_artifact',[])
+
+ artifact_obj = parsed_artifact[0] if len(parsed_artifact)>0 else None
+ artifact_repo = parsed_artifact[1] if len(parsed_artifact)>1 else None
+
+ script_name = ''
+ if 'script_name' in i:
+ script_name = i.get('script_name','').strip()
+ del(i['script_name'])
+
+ if script_name != '' and not os.path.isfile(script_name):
+ return {'return':1, 'error':'file {} not found'.format(script_name)}
+
+ # Move tags from input to meta of the newly created script artifact
+ tags_list = utils.convert_tags_to_list(i)
+ if 'tags' in i: del(i['tags'])
+
+ if len(tags_list)==0:
+ if console:
+ x=input('Please specify a combination of unique tags separated by comma for this script: ')
+ x = x.strip()
+ if x!='':
+ tags_list = x.split(',')
+
+ if len(tags_list)==0:
+ return {'return':1, 'error':'you must specify a combination of unique tags separate by comman using "--new_tags"'}
+
+ # Add placeholder (use common action)
+ ii['out']='con'
+ ii['common']=True # Avoid recursion - use internal CM add function to add the script artifact
+
+ # Check template path
+ template_dir = 'template'
+
+ template = i.get('template','')
+
+ if template == '':
+ if i.get('python', False):
+ template = 'python'
+ elif i.get('pytorch', False):
+ template = 'pytorch'
+
+ if template!='':
+ template_dir += '-'+template
+
+ template_path = os.path.join(self.path, template_dir)
+
+ if not os.path.isdir(template_path):
+ return {'return':1, 'error':'template path {} not found'.format(template_path)}
+
+ # Check if preloaded meta exists
+ meta = {
+ 'cache':False
+# 20240127: Grigori commented that because newly created script meta looks ugly
+# 'new_env_keys':[],
+# 'new_state_keys':[],
+# 'input_mapping':{},
+# 'docker_input_mapping':{},
+# 'deps':[],
+# 'prehook_deps':[],
+# 'posthook_deps':[],
+# 'post_deps':[],
+# 'versions':{},
+# 'variations':{},
+# 'input_description':{}
+ }
+
+ fmeta = os.path.join(template_path, self.cmind.cfg['file_cmeta'])
+
+ r = utils.load_yaml_and_json(fmeta)
+ if r['return']==0:
+ utils.merge_dicts({'dict1':meta, 'dict2':r['meta'], 'append_lists':True, 'append_unique':True})
+
+ # Check meta from CMD
+ xmeta = i.get('meta',{})
+
+ if len(xmeta)>0:
+ utils.merge_dicts({'dict1':meta, 'dict2':xmeta, 'append_lists':True, 'append_unique':True})
+
+ meta['automation_alias']=self.meta['alias']
+ meta['automation_uid']=self.meta['uid']
+ meta['tags']=tags_list
+
+ script_name_base = script_name
+ script_name_ext = ''
+ if script_name!='':
+ # separate name and extension
+ j=script_name.rfind('.')
+ if j>=0:
+ script_name_base = script_name[:j]
+ script_name_ext = script_name[j:]
+
+ meta['script_name'] = script_name_base
+
+ ii['meta']=meta
+ ii['action']='add'
+
+ use_yaml = True if not i.get('json',False) else False
+
+ if use_yaml:
+ ii['yaml']=True
+
+ ii['automation']='script,5b4e0237da074764'
+
+ for k in ['parsed_automation', 'parsed_artifact']:
+ if k in ii: del ii[k]
+
+ if artifact_repo != None:
+ artifact = ii.get('artifact','')
+ ii['artifact'] = utils.assemble_cm_object2(artifact_repo) + ':' + artifact
+
+ r_obj=self.cmind.access(ii)
+ if r_obj['return']>0: return r_obj
+
+ new_script_path = r_obj['path']
+
+ if console:
+ print ('Created script in {}'.format(new_script_path))
+
+ # Copy files from template (only if exist)
+ files = [
+ (template_path, 'README-extra.md', ''),
+ (template_path, 'customize.py', ''),
+ (template_path, 'main.py', ''),
+ (template_path, 'requirements.txt', ''),
+ (template_path, 'install_deps.bat', ''),
+ (template_path, 'install_deps.sh', ''),
+ (template_path, 'plot.bat', ''),
+ (template_path, 'plot.sh', ''),
+ (template_path, 'analyze.bat', ''),
+ (template_path, 'analyze.sh', ''),
+ (template_path, 'validate.bat', ''),
+ (template_path, 'validate.sh', '')
+ ]
+
+ if script_name == '':
+ files += [(template_path, 'run.bat', ''),
+ (template_path, 'run.sh', '')]
+ else:
+ if script_name_ext == '.bat':
+ files += [(template_path, 'run.sh', script_name_base+'.sh')]
+ files += [('', script_name, script_name)]
+
+ else:
+ files += [(template_path, 'run.bat', script_name_base+'.bat')]
+ files += [('', script_name, script_name_base+'.sh')]
+
+
+ for x in files:
+ path = x[0]
+ f1 = x[1]
+ f2 = x[2]
+
+ if f2 == '':
+ f2 = f1
+
+ if path!='':
+ f1 = os.path.join(path, f1)
+
+ if os.path.isfile(f1):
+ f2 = os.path.join(new_script_path, f2)
+
+ if console:
+ print (' * Copying {} to {}'.format(f1, f2))
+
+ shutil.copyfile(f1,f2)
+
+ return r_obj
+
+ ##############################################################################
+ def _get_name_for_dynamic_variation_tag(script, variation_tag):
+ '''
+ Returns the variation name in meta for the dynamic_variation_tag
+ '''
+ if "." not in variation_tag or variation_tag[-1] == ".":
+ return None
+ return variation_tag[:variation_tag.index(".")+1]+"#"
+
+
+ ##############################################################################
+ def _update_variation_meta_with_dynamic_suffix(script, variation_meta, variation_tag_dynamic_suffix):
+ '''
+ Updates the variation meta with dynamic suffix
+ '''
+ for key in variation_meta:
+ value = variation_meta[key]
+
+ if type(value) is list: #deps,pre_deps...
+ for item in value:
+ if type(item) is dict:
+ for item_key in item:
+ item_value = item[item_key]
+ if type(item_value) is dict: #env,default_env inside deps
+ for item_key2 in item_value:
+ item_value[item_key2] = item_value[item_key2].replace("#", variation_tag_dynamic_suffix)
+ elif type(item_value) is list: #names for example
+ for i,l_item in enumerate(item_value):
+ if type(l_item) is str:
+ item_value[i] = l_item.replace("#", variation_tag_dynamic_suffix)
+ else:
+ item[item_key] = item[item_key].replace("#", variation_tag_dynamic_suffix)
+
+ elif type(value) is dict: #add_deps, env, ..
+ for item in value:
+ item_value = value[item]
+ if type(item_value) is dict: #deps
+ for item_key in item_value:
+ item_value2 = item_value[item_key]
+ if type(item_value2) is dict: #env,default_env inside deps
+ for item_key2 in item_value2:
+ item_value2[item_key2] = item_value2[item_key2].replace("#", variation_tag_dynamic_suffix)
+ else:
+ item_value[item_key] = item_value[item_key].replace("#", variation_tag_dynamic_suffix)
+ else:
+ if type(item_value) is list: # lists inside env...
+ for i,l_item in enumerate(item_value):
+ if type(l_item) is str:
+ item_value[i] = l_item.replace("#", variation_tag_dynamic_suffix)
+ else:
+ value[item] = value[item].replace("#", variation_tag_dynamic_suffix)
+
+ else: #scalar value
+ pass #no dynamic update for now
+
+
+ ##############################################################################
+ def _get_variations_with_aliases(script, variation_tags, variations):
+ '''
+ Automatically turn on variation tags which are aliased by any given tag
+ '''
+ import copy
+ tmp_variation_tags=copy.deepcopy(variation_tags)
+
+ excluded_variations = [ k[1:] for k in variation_tags if k.startswith("-") ]
+ for i,e in enumerate(excluded_variations):
+ if e not in variations:
+ dynamic_tag = script._get_name_for_dynamic_variation_tag(e)
+ if dynamic_tag and dynamic_tag in variations:
+ excluded_variations[i] = dynamic_tag
+
+ for k in variation_tags:
+ if k.startswith("-"):
+ continue
+ if k in variations:
+ variation = variations[k]
+ else:
+ variation = variations[script._get_name_for_dynamic_variation_tag(k)]
+ if 'alias' in variation:
+
+ if variation['alias'] in excluded_variations:
+ return {'return': 1, 'error': 'Alias "{}" specified for the variation "{}" is conflicting with the excluded variation "-{}" '.format(variation['alias'], k, variation['alias'])}
+
+ if variation['alias'] not in variations:
+ return {'return': 1, 'error': 'Alias "{}" specified for the variation "{}" is not existing '.format(variation['alias'], k)}
+
+ if 'group' in variation:
+ return {'return': 1, 'error': 'Incompatible combinations: (alias, group) specified for the variation "{}" '.format(k)}
+
+ if 'default' in variation:
+ return {'return': 1, 'error': 'Incompatible combinations: (default, group) specified for the variation "{}" '.format(k)}
+
+ if variation['alias'] not in tmp_variation_tags:
+ tmp_variation_tags.append(variation['alias'])
+
+ return {'return':0, 'variation_tags': tmp_variation_tags, 'excluded_variation_tags': excluded_variations}
+
+
+
+ ##############################################################################
+ def _get_variation_groups(script, variations):
+
+ groups = {}
+
+ for k in variations:
+ variation = variations[k]
+ if not variation:
+ continue
+ if 'group' in variation:
+ if variation['group'] not in groups:
+ groups[variation['group']] = {}
+ groups[variation['group']]['variations'] = []
+ groups[variation['group']]['variations'].append(k)
+ if 'default' in variation:
+ if 'default' in groups[variation['group']]:
+ return {'return': 1, 'error': 'Multiple defaults specied for the variation group "{}": "{},{}" '.format(variation['group'], k, groups[variation['group']]['default'])}
+ groups[variation['group']]['default'] = k
+
+ return {'return': 0, 'variation_groups': groups}
+
+
+ ##############################################################################
+ def _process_variation_tags_in_groups(script, variation_tags, groups, excluded_variations, variations):
+ import copy
+ tmp_variation_tags = copy.deepcopy(variation_tags)
+ tmp_variation_tags_static = copy.deepcopy(variation_tags)
+
+ for v_i in range(len(tmp_variation_tags_static)):
+ v = tmp_variation_tags_static[v_i]
+
+ if v not in variations:
+ v_static = script._get_name_for_dynamic_variation_tag(v)
+ tmp_variation_tags_static[v_i] = v_static
+
+ for k in groups:
+ group = groups[k]
+ unique_allowed_variations = group['variations']
+
+ if len(set(unique_allowed_variations) & set(tmp_variation_tags_static)) > 1:
+ return {'return': 1, 'error': 'Multiple variation tags selected for the variation group "{}": {} '.format(k, str(set(unique_allowed_variations) & set(tmp_variation_tags_static)))}
+ if len(set(unique_allowed_variations) & set(tmp_variation_tags_static)) == 0:
+ if 'default' in group and group['default'] not in excluded_variations:
+ tmp_variation_tags.append(group['default'])
+
+ return {'return':0, 'variation_tags': tmp_variation_tags}
+
+
+
+
+
+
+ ##############################################################################
+ def _call_run_deps(script, deps, local_env_keys, local_env_keys_from_meta, env, state, const, const_state,
+ add_deps_recursive, recursion_spaces, remembered_selections, variation_tags_string, found_cached, debug_script_tags='',
+ verbose=False, show_time=False, extra_recursion_spaces=' ', run_state={'deps':[], 'fake_deps':[], 'parent': None}):
+ if len(deps) == 0:
+ return {'return': 0}
+
+ # Check chain of post hook dependencies on other CM scripts
+ import copy
+
+ # Get local env keys
+ local_env_keys = copy.deepcopy(local_env_keys)
+
+ if len(local_env_keys_from_meta)>0:
+ local_env_keys += local_env_keys_from_meta
+
+ r = script._run_deps(deps, local_env_keys, env, state, const, const_state, add_deps_recursive, recursion_spaces,
+ remembered_selections, variation_tags_string, found_cached, debug_script_tags,
+ verbose, show_time, extra_recursion_spaces, run_state)
+ if r['return']>0: return r
+
+ return {'return': 0}
+
+ ##############################################################################
+ def _run_deps(self, deps, clean_env_keys_deps, env, state, const, const_state, add_deps_recursive, recursion_spaces,
+ remembered_selections, variation_tags_string='', from_cache=False, debug_script_tags='',
+ verbose=False, show_time=False, extra_recursion_spaces=' ', run_state={'deps':[], 'fake_deps':[], 'parent': None}):
+ """
+ Runs all the enabled dependencies and pass them env minus local env
+ """
+
+ if len(deps)>0:
+ # Preserve local env
+ tmp_env = {}
+
+ variation_groups = run_state.get('variation_groups')
+
+ for d in deps:
+
+ if not d.get('tags'):
+ continue
+
+ if d.get('skip_if_fake_run', False) and env.get('CM_TMP_FAKE_RUN','')=='yes':
+ continue
+
+ if "enable_if_env" in d:
+ if not enable_or_skip_script(d["enable_if_env"], env):
+ continue
+
+ if "skip_if_env" in d:
+ if enable_or_skip_script(d["skip_if_env"], env):
+ continue
+
+ if from_cache and not d.get("dynamic", None):
+ continue
+
+ update_tags_from_env_with_prefix = d.get("update_tags_from_env_with_prefix", {})
+ for t in update_tags_from_env_with_prefix:
+ for key in update_tags_from_env_with_prefix[t]:
+ if str(env.get(key, '')).strip() != '':
+ d['tags']+=","+t+str(env[key])
+
+ for key in clean_env_keys_deps:
+ if '?' in key or '*' in key:
+ import fnmatch
+ for kk in list(env.keys()):
+ if fnmatch.fnmatch(kk, key):
+ tmp_env[kk] = env[kk]
+ del(env[kk])
+ elif key in env:
+ tmp_env[key] = env[key]
+ del(env[key])
+
+ import re
+ for key in list(env.keys()):
+ value = env[key]
+ tmp_values = re.findall(r'<<<(.*?)>>>', str(value))
+ if tmp_values == []: continue
+ tmp_env[key] = env[key]
+ del(env[key])
+
+ force_env_keys_deps = d.get("force_env_keys", [])
+ for key in force_env_keys_deps:
+ if '?' in key or '*' in key:
+ import fnmatch
+ for kk in list(tmp_env.keys()):
+ if fnmatch.fnmatch(kk, key):
+ env[kk] = tmp_env[kk]
+ elif key in tmp_env:
+ env[key] = tmp_env[key]
+
+ if d.get("reuse_version", False):
+ for k in tmp_env:
+ if k.startswith('CM_VERSION'):
+ env[k] = tmp_env[k]
+
+ update_tags_from_env = d.get("update_tags_from_env", [])
+ for t in update_tags_from_env:
+ if env.get(t, '').strip() != '':
+ d['tags']+=","+env[t]
+
+ inherit_variation_tags = d.get("inherit_variation_tags", False)
+ skip_inherit_variation_groups = d.get("skip_inherit_variation_groups", [])
+ variation_tags_to_be_skipped = []
+ if inherit_variation_tags:
+ if skip_inherit_variation_groups: #skips inheriting variations belonging to given groups
+ for group in variation_groups:
+ if group in skip_inherit_variation_groups:
+ variation_tags_to_be_skipped += variation_groups[group]['variations']
+
+ variation_tags = variation_tags_string.split(",")
+ variation_tags = [ x for x in variation_tags if not x.startswith("_") or x[1:] not in set(variation_tags_to_be_skipped) ]
+
+ # handle group in case of dynamic variations
+ for t_variation in variation_tags_to_be_skipped:
+ if t_variation.endswith(".#"):
+ beg = t_variation[:-1]
+ for m_tag in variation_tags:
+ if m_tag.startswith("_"+beg):
+ variation_tags.remove(m_tag)
+
+ deps_tags = d['tags'].split(",")
+ for tag in deps_tags:
+ if tag.startswith("-_") or tag.startswith("_-"):
+ variation_tag = "_" + tag[2:]
+ if variation_tag in variation_tags:
+ variation_tags.remove(variation_tag)
+ new_variation_tags_string = ",".join(variation_tags)
+ d['tags']+=","+new_variation_tags_string #deps should have non-empty tags
+
+ run_state['deps'].append(d['tags'])
+
+ if not run_state['fake_deps']:
+ import copy
+ tmp_run_state_deps = copy.deepcopy(run_state['deps'])
+ run_state['deps'] = []
+ tmp_parent = run_state['parent']
+ run_state['parent'] = run_state['script_id']+":"+",".join(run_state['script_variation_tags'])
+ tmp_script_id = run_state['script_id']
+ tmp_script_variation_tags = run_state['script_variation_tags']
+
+ # Run collective script via CM API:
+ # Not very efficient but allows logging - can be optimized later
+ ii = {
+ 'action':'run',
+ 'automation':utils.assemble_cm_object(self.meta['alias'], self.meta['uid']),
+ 'recursion_spaces':recursion_spaces, # + extra_recursion_spaces,
+ 'recursion':True,
+ 'remembered_selections': remembered_selections,
+ 'env':env,
+ 'state':state,
+ 'const':const,
+ 'const_state':const_state,
+ 'add_deps_recursive':add_deps_recursive,
+ 'debug_script_tags':debug_script_tags,
+ 'verbose':verbose,
+ 'time':show_time,
+ 'run_state':run_state
+
+ }
+
+ for key in [ "env", "state", "const", "const_state" ]:
+ ii['local_'+key] = d.get(key, {})
+ if d.get(key):
+ d[key] = {}
+
+ utils.merge_dicts({'dict1':ii, 'dict2':d, 'append_lists':True, 'append_unique':True})
+
+ r = update_env_with_values(ii['env']) #to update env local to a dependency
+ if r['return']>0: return r
+
+ r = self.cmind.access(ii)
+ if r['return']>0: return r
+
+ run_state['deps'] = tmp_run_state_deps
+ run_state['parent'] = tmp_parent
+ run_state['script_id'] = tmp_script_id
+ run_state['script_variation_tags'] = tmp_script_variation_tags
+
+ # Restore local env
+ env.update(tmp_env)
+ r = update_env_with_values(env)
+ if r['return']>0: return r
+
+ return {'return': 0}
+
+ ##############################################################################
+ def _merge_dicts_with_tags(self, dict1, dict2):
+ """
+ Merges two dictionaries and append any tag strings in them
+ """
+ if dict1 == dict2:
+ return {'return': 0}
+ for dep in dict1:
+ if 'tags' in dict1[dep]:
+ dict1[dep]['tags_list'] = utils.convert_tags_to_list(dict1[dep])
+ for dep in dict2:
+ if 'tags' in dict2[dep]:
+ dict2[dep]['tags_list'] = utils.convert_tags_to_list(dict2[dep])
+ utils.merge_dicts({'dict1':dict1, 'dict2':dict2, 'append_lists':True, 'append_unique':True})
+ for dep in dict1:
+ if 'tags_list' in dict1[dep]:
+ dict1[dep]['tags'] = ",".join(dict1[dep]['tags_list'])
+ del(dict1[dep]['tags_list'])
+ for dep in dict2:
+ if 'tags_list' in dict2[dep]:
+ del(dict2[dep]['tags_list'])
+
+ ##############################################################################
+ def _get_readme(self, cmd_parts, deps):
+ """
+ Outputs a Markdown README file listing the CM run commands for the dependencies
+ """
+ pre = ''
+ content = pre
+ heading2 = "## Command to Run\n"
+ content += heading2
+ cmd="cm run script "
+ for cmd_part in cmd_parts:
+ cmd = cmd+ " "+cmd_part
+ content += "\n"
+ cmd = self._markdown_cmd(cmd)
+ content = content + cmd + "\n\n"
+ deps_heading = "## Dependent CM scripts\n"
+ deps_ = ""
+ run_cmds = self._get_deps_run_cmds(deps)
+ i = 1
+ for cmd in run_cmds:
+ deps_ = deps_+ str(i) + ". " + self._markdown_cmd(cmd)+"\n"
+ i = i+1
+ if deps_:
+ content += deps_heading
+ content += deps_
+ return content
+
+ ##############################################################################
+ def _markdown_cmd(self, cmd):
+ """
+ Returns a CM command in markdown format
+ """
+ return '```bash\n '+cmd+' \n ```'
+
+
+ ##############################################################################
+ def _print_deps(self, deps):
+ """
+ Prints the CM run commands for the list of CM script dependencies
+ """
+ print_deps_data = []
+ run_cmds = self._get_deps_run_cmds(deps)
+ for cmd in run_cmds:
+ print_deps_data.append(cmd)
+ print(cmd)
+ return print_deps_data
+
+
+ ##############################################################################
+ def _get_deps_run_cmds(self, deps):
+ """
+ Returns the CM run commands for the list of CM script dependencies
+ """
+ run_cmds = []
+ for dep_tags in deps:
+ run_cmds.append("cm run script --tags="+dep_tags)
+ return run_cmds
+
+
+
+
+
+ ##############################################################################
+ def run_native_script(self, i):
+ """
+ Run native script in a CM script entry
+ (wrapper around "prepare_and_run_script_with_postprocessing" function)
+
+ Args:
+ (dict):
+
+ run_script_input (dict): saved input for "prepare_and_run_script_with_postprocessing" function
+ env (dict): the latest environment for the script
+ script_name (str): native script name
+
+ Returns:
+ (dict): Output from "prepare_and_run_script_with_postprocessing" function
+
+
+ """
+
+ import copy
+
+ run_script_input = i['run_script_input']
+ script_name = i['script_name']
+ env = i.get('env','')
+
+ # Create and work on a copy to avoid contamination
+ env_copy = copy.deepcopy(run_script_input.get('env',{}))
+ run_script_input_state_copy = copy.deepcopy(run_script_input.get('state',{}))
+ script_name_copy = run_script_input.get('script_name','')
+
+ run_script_input['script_name'] = script_name
+ run_script_input['env'] = env
+
+ r = prepare_and_run_script_with_postprocessing(run_script_input, postprocess="")
+
+ env_tmp = copy.deepcopy(run_script_input['env'])
+ r['env_tmp'] = env_tmp
+
+ run_script_input['state'] = run_script_input_state_copy
+ run_script_input['env'] = env_copy
+ run_script_input['script_name'] = script_name_copy
+
+ return r
+
+ ##############################################################################
+ def find_file_in_paths(self, i):
+ """
+ Find file name in a list of paths
+
+ Args:
+ (CM input dict):
+
+ paths (list): list of paths
+ file_name (str): filename pattern to find
+ (select) (bool): if True and more than 1 path found, select
+ (select_default) (bool): if True, select the default one
+ (recursion_spaces) (str): add space to print
+ (run_script_input) (dict): prepared dict to run script and detect version
+
+ (detect_version) (bool): if True, attempt to detect version
+ (env_path) (str): env key to pass path to the script to detect version
+ (run_script_input) (dict): use this input to run script to detect version
+ (env) (dict): env to check/force version
+
+ (hook) (func): call this func to skip some artifacts
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ (found_files) (list): paths to files when found
+
+ """
+ import copy
+
+ paths = i['paths']
+ select = i.get('select',False)
+ select_default = i.get('select_default', False)
+ recursion_spaces = i.get('recursion_spaces','')
+
+ hook = i.get('hook', None)
+
+ verbose = i.get('verbose', False)
+ if not verbose: verbose = i.get('v', False)
+
+ file_name = i.get('file_name', '')
+ file_name_re = i.get('file_name_re', '')
+ file_is_re = False
+
+ if file_name_re != '':
+ file_name = file_name_re
+ file_is_re = True
+
+ if file_name == '':
+ raise Exception('file_name or file_name_re not specified in find_artifact')
+
+ found_files = []
+
+ import glob
+ import re
+
+ for path in paths:
+ # May happen that path is in variable but it doesn't exist anymore
+ if os.path.isdir(path):
+ if file_is_re:
+ file_list = [os.path.join(path,f) for f in os.listdir(path) if re.match(file_name, f)]
+
+ for f in file_list:
+ duplicate = False
+ for existing in found_files:
+ if os.path.samefile(existing, f):
+ duplicate = True
+ break
+ if not duplicate:
+ skip = False
+ if hook!=None:
+ r=hook({'file':f})
+ if r['return']>0: return r
+ skip = r['skip']
+ if not skip:
+ found_files.append(f)
+
+ else:
+ path_to_file = os.path.join(path, file_name)
+
+ file_pattern_suffixes = [
+ "",
+ ".[0-9]",
+ ".[0-9][0-9]",
+ "-[0-9]",
+ "-[0-9][0-9]",
+ "[0-9]",
+ "[0-9][0-9]",
+ "[0-9].[0-9]",
+ "[0-9][0-9].[0-9]",
+ "[0-9][0-9].[0-9][0-9]"
+ ]
+
+ for suff in file_pattern_suffixes:
+ file_list = glob.glob(path_to_file + suff)
+ for f in file_list:
+ duplicate = False
+
+ for existing in found_files:
+ try:
+ if os.path.samefile(existing, f):
+ duplicate = True
+ break
+ except Exception as e:
+ # This function fails on Windows sometimes
+ # because some files can't be accessed
+ pass
+
+ if not duplicate:
+ skip = False
+ if hook!=None:
+ r=hook({'file':f})
+ if r['return']>0: return r
+ skip = r['skip']
+ if not skip:
+ found_files.append(f)
+
+
+ if select:
+ # Check and prune versions
+ if i.get('detect_version', False):
+ found_paths_with_good_version = []
+ found_files_with_good_version = []
+
+ env = i.get('env', {})
+
+ run_script_input = i['run_script_input']
+ env_path_key = i['env_path_key']
+
+ version = env.get('CM_VERSION', '')
+ version_min = env.get('CM_VERSION_MIN', '')
+ version_max = env.get('CM_VERSION_MAX', '')
+
+ x = ''
+
+ if version != '': x += ' == {}'.format(version)
+ if version_min != '': x += ' >= {}'.format(version_min)
+ if version_max != '': x += ' <= {}'.format(version_max)
+
+ if x!='':
+ print (recursion_spaces + ' - Searching for versions: {}'.format(x))
+
+ new_recursion_spaces = recursion_spaces + ' '
+
+
+ for path_to_file in found_files:
+
+ print ('')
+ print (recursion_spaces + ' * ' + path_to_file)
+
+ run_script_input['env'] = env
+ run_script_input['env'][env_path_key] = path_to_file
+ run_script_input['recursion_spaces'] = new_recursion_spaces
+
+ rx = prepare_and_run_script_with_postprocessing(run_script_input, postprocess="detect_version")
+
+ run_script_input['recursion_spaces'] = recursion_spaces
+
+ if rx['return']>0:
+ if rx['return'] != 2:
+ return rx
+ else:
+ # Version was detected
+ detected_version = rx.get('version','')
+
+ if detected_version != '':
+ if detected_version == -1:
+ print (recursion_spaces + ' SKIPPED due to incompatibility ...')
+ else:
+ ry = check_version_constraints({'detected_version': detected_version,
+ 'version': version,
+ 'version_min': version_min,
+ 'version_max': version_max,
+ 'cmind':self.cmind})
+ if ry['return']>0: return ry
+
+ if not ry['skip']:
+ found_files_with_good_version.append(path_to_file)
+ else:
+ print (recursion_spaces + ' SKIPPED due to version constraints ...')
+
+ found_files = found_files_with_good_version
+
+ # Continue with selection
+ if len(found_files)>1:
+ if len(found_files) == 1 or select_default:
+ selection = 0
+ else:
+ # Select 1 and proceed
+ print (recursion_spaces+' - More than 1 path found:')
+
+ print ('')
+ num = 0
+
+ for file in found_files:
+ print (recursion_spaces+' {}) {}'.format(num, file))
+ num += 1
+
+ print ('')
+ x=input(recursion_spaces+' Make your selection or press Enter for 0: ')
+
+ x=x.strip()
+ if x=='': x='0'
+
+ selection = int(x)
+
+ if selection < 0 or selection >= num:
+ selection = 0
+
+ print ('')
+ print (recursion_spaces+' Selected {}: {}'.format(selection, found_files[selection]))
+
+ found_files = [found_files[selection]]
+
+ return {'return':0, 'found_files':found_files}
+
+ ##############################################################################
+ def detect_version_using_script(self, i):
+ """
+ Detect version using script
+
+ Args:
+ (CM input dict):
+
+ (recursion_spaces) (str): add space to print
+
+ run_script_input (dict): use this input to run script to detect version
+ (env) (dict): env to check/force version
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ 16 if not detected
+ * (error) (str): error string if return>0
+
+ (detected_version) (str): detected version
+
+ """
+ recursion_spaces = i.get('recursion_spaces','')
+
+ import copy
+
+ detected = False
+
+ env = i.get('env', {})
+
+ run_script_input = i['run_script_input']
+
+ version = env.get('CM_VERSION', '')
+ version_min = env.get('CM_VERSION_MIN', '')
+ version_max = env.get('CM_VERSION_MAX', '')
+
+ x = ''
+
+ if version != '': x += ' == {}'.format(version)
+ if version_min != '': x += ' >= {}'.format(version_min)
+ if version_max != '': x += ' <= {}'.format(version_max)
+
+ if x!='':
+ print (recursion_spaces + ' - Searching for versions: {}'.format(x))
+
+ new_recursion_spaces = recursion_spaces + ' '
+
+ run_script_input['recursion_spaces'] = new_recursion_spaces
+ run_script_input['env'] = env
+
+ # Prepare run script
+ rx = prepare_and_run_script_with_postprocessing(run_script_input, postprocess="detect_version")
+
+ run_script_input['recursion_spaces'] = recursion_spaces
+
+ if rx['return'] == 0:
+ # Version was detected
+ detected_version = rx.get('version','')
+
+ if detected_version != '':
+ ry = check_version_constraints({'detected_version': detected_version,
+ 'version': version,
+ 'version_min': version_min,
+ 'version_max': version_max,
+ 'cmind':self.cmind})
+ if ry['return']>0: return ry
+
+ if not ry['skip']:
+ return {'return':0, 'detected_version':detected_version}
+
+ return {'return':16, 'error':'version was not detected'}
+
+ ##############################################################################
+ def find_artifact(self, i):
+ """
+ Find some artifact (file) by name
+
+ Args:
+ (CM input dict):
+
+ file_name (str): filename to find
+
+ env (dict): global env
+ os_info (dict): OS info
+
+ (detect_version) (bool): if True, attempt to detect version
+ (env_path) (str): env key to pass path to the script to detect version
+ (run_script_input) (dict): use this input to run script to detect version
+
+ (default_path_env_key) (str): check in default paths from global env
+ (PATH, PYTHONPATH, LD_LIBRARY_PATH ...)
+
+ (recursion_spaces) (str): add space to print
+
+ (hook) (func): call this func to skip some artifacts
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+ error = 16 if artifact not found but no problem
+
+ found_path (list): found path to an artifact
+ full_path (str): full path to a found artifact
+ default_path_list (list): list of default paths
+
+ """
+
+ import copy
+
+ file_name = i['file_name']
+
+ os_info = i['os_info']
+
+ env = i['env']
+
+ env_path_key = i.get('env_path_key', '')
+
+ run_script_input = i.get('run_script_input', {})
+ extra_paths = i.get('extra_paths', {})
+
+ # Create and work on a copy to avoid contamination
+ env_copy = copy.deepcopy(env)
+ run_script_input_state_copy = copy.deepcopy(run_script_input.get('state',{}))
+
+ default_path_env_key = i.get('default_path_env_key', '')
+ recursion_spaces = i.get('recursion_spaces', '')
+
+ hook = i.get('hook', None)
+
+ # Check if forced to search in a specific path or multiple paths
+ # separated by OS var separator (usually : or ;)
+ path = env.get('CM_TMP_PATH','')
+
+ if path!='' and env.get('CM_TMP_PATH_IGNORE_NON_EXISTANT','')!='yes':
+ # Can be a list of paths
+ path_list_tmp = path.split(os_info['env_separator'])
+ for path_tmp in path_list_tmp:
+ if path_tmp.strip()!='' and not os.path.isdir(path_tmp):
+ return {'return':1, 'error':'path {} doesn\'t exist'.format(path_tmp)}
+
+ # Check if forced path and file name from --input (CM_INPUT - local env - will not be visible for higher-level script)
+ forced_file = env.get('CM_INPUT','').strip()
+ if forced_file != '':
+ if not os.path.isfile(forced_file):
+ return {'return':1, 'error':'file {} doesn\'t exist'.format(forced_file)}
+
+ file_name = os.path.basename(forced_file)
+ path = os.path.dirname(forced_file)
+
+ default_path_list = self.get_default_path_list(i)
+ #[] if default_path_env_key == '' else \
+ # os.environ.get(default_path_env_key,'').split(os_info['env_separator'])
+
+
+ if path == '':
+ path_list_tmp = default_path_list
+ else:
+ print (recursion_spaces + ' # Requested paths: {}'.format(path))
+ path_list_tmp = path.split(os_info['env_separator'])
+
+ # Check soft links
+ path_list_tmp2 = []
+ for path_tmp in path_list_tmp:
+# path_tmp_abs = os.path.realpath(os.path.join(path_tmp, file_name))
+# GF: I remarked above code because it doesn't work correcly
+# for virtual python - it unsoftlinks virtual python and picks up
+# native one from /usr/bin thus making workflows work incorrectly ...
+ path_tmp_abs = os.path.join(path_tmp, file_name)
+
+ if not path_tmp_abs in path_list_tmp2:
+ path_list_tmp2.append(path_tmp_abs)
+
+ path_list = []
+ for path_tmp in path_list_tmp2:
+ path_list.append(os.path.dirname(path_tmp))
+
+ # Check if quiet
+ select_default = True if env.get('CM_QUIET','') == 'yes' else False
+
+ # Prepare paths to search
+ r = self.find_file_in_paths({'paths': path_list,
+ 'file_name': file_name,
+ 'select': True,
+ 'select_default': select_default,
+ 'detect_version': i.get('detect_version', False),
+ 'env_path_key': env_path_key,
+ 'env':env_copy,
+ 'hook':hook,
+ 'run_script_input': run_script_input,
+ 'recursion_spaces': recursion_spaces})
+
+ run_script_input['state'] = run_script_input_state_copy
+
+ if r['return']>0: return r
+
+ found_files = r['found_files']
+
+ if len(found_files)==0:
+ return {'return':16, 'error':'{} not found'.format(file_name)}
+
+ # Finalize output
+ file_path = found_files[0]
+ found_path = os.path.dirname(file_path)
+
+ if found_path not in default_path_list:
+ env_key = '+'+default_path_env_key
+
+ paths = env.get(env_key, [])
+ if found_path not in paths:
+ paths.insert(0, found_path)
+ env[env_key] = paths
+ for extra_path in extra_paths:
+ epath = os.path.normpath(os.path.join(found_path, "..", extra_path))
+ if os.path.exists(epath):
+ if extra_paths[extra_path] not in env:
+ env[extra_paths[extra_path]] = []
+ env[extra_paths[extra_path]].append(epath)
+ print ()
+ print (recursion_spaces + ' # Found artifact in {}'.format(file_path))
+
+ if env_path_key != '':
+ env[env_path_key] = file_path
+
+ return {'return':0, 'found_path':found_path,
+ 'found_file_path':file_path,
+ 'found_file_name':os.path.basename(file_path),
+ 'default_path_list': default_path_list}
+
+ ##############################################################################
+ def find_file_deep(self, i):
+ """
+ Find file name in a list of paths
+
+ Args:
+ (CM input dict):
+
+ paths (list): list of paths
+ file_name (str): filename pattern to find
+ (restrict_paths) (list): restrict found paths to these combinations
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ (found_paths) (list): paths to files when found
+
+ """
+
+ paths = i['paths']
+ file_name = i['file_name']
+
+ restrict_paths = i.get('restrict_paths',[])
+
+ found_paths = []
+
+ for p in paths:
+ if os.path.isdir(p):
+ p1 = os.listdir(p)
+ for f in p1:
+ p2 = os.path.join(p, f)
+
+ if os.path.isdir(p2):
+ r = self.find_file_deep({'paths':[p2], 'file_name': file_name, 'restrict_paths':restrict_paths})
+ if r['return']>0: return r
+
+ found_paths += r['found_paths']
+ else:
+ if f == file_name:
+ found_paths.append(p)
+ break
+
+ if len(found_paths) > 0 and len(restrict_paths) > 0:
+ filtered_found_paths = []
+
+ for p in found_paths:
+ for f in restrict_paths:
+ if f in p:
+ filtered_found_paths.append(p)
+ break
+
+ found_paths = filtered_found_paths
+
+ return {'return':0, 'found_paths':found_paths}
+
+ ##############################################################################
+ def find_file_back(self, i):
+ """
+ Find file name backwards
+
+ Args:
+ (CM input dict):
+
+ path (str): path to start with
+ file_name (str): filename or directory to find
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ (found_path) (str): path if found or empty
+
+ """
+
+ path = i['path']
+ file_name = i['file_name']
+
+ found_path = ''
+
+ while path != '':
+ path_to_file = os.path.join(path, file_name)
+ if os.path.isfile(path_to_file):
+ break
+
+ path2 = os.path.dirname(path)
+
+ if path2 == path:
+ path = ''
+ break
+ else:
+ path = path2
+
+ return {'return':0, 'found_path':path}
+
+ ##############################################################################
+ def parse_version(self, i):
+ """
+ Parse version (used in post processing functions)
+
+ Args:
+ (CM input dict):
+
+ (file_name) (str): filename to get version from (tmp-ver.out by default)
+ match_text (str): RE match text string
+ group_number (int): RE group number to get version from
+ env_key (str): which env key to update
+ which_env (dict): which env to update
+ (debug) (boolean): if True, print some debug info
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ version (str): detected version
+ string (str): full file string
+
+ """
+
+ file_name = i.get('file_name','')
+ if file_name == '': file_name = self.tmp_file_ver
+
+ match_text = i['match_text']
+ group_number = i['group_number']
+ env_key = i['env_key']
+ which_env = i['which_env']
+ debug = i.get('debug', False)
+
+ r = utils.load_txt(file_name = file_name,
+ check_if_exists = True,
+ split = True,
+ match_text = match_text,
+ fail_if_no_match = 'version was not detected')
+ if r['return']>0:
+ if r.get('string','')!='':
+ r['error'] += ' ({})'.format(r['string'])
+ return r
+
+ string = r['string']
+
+ version = r['match'].group(group_number)
+
+ which_env[env_key] = version
+ which_env['CM_DETECTED_VERSION'] = version # to be recorded in the cache meta
+
+ return {'return':0, 'version':version, 'string':string}
+
+ ##############################################################################
+ def update_deps(self, i):
+ """
+ Update deps from pre/post processing
+ Args:
+ (CM input dict):
+ deps (dict): deps dict
+ update_deps (dict): key matches "names" in deps
+ Returns:
+ (CM return dict):
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+ """
+
+ deps = i['deps']
+ add_deps = i['update_deps']
+ update_deps(deps, add_deps, False)
+
+ return {'return':0}
+
+ ##############################################################################
+ def get_default_path_list(self, i):
+ default_path_env_key = i.get('default_path_env_key', '')
+ os_info = i['os_info']
+ default_path_list = [] if default_path_env_key == '' else \
+ os.environ.get(default_path_env_key,'').split(os_info['env_separator'])
+
+ return default_path_list
+
+
+
+ ############################################################
+ def doc(self, i):
+ """
+ Document CM script.
+
+ Args:
+ (CM input dict):
+
+ (out) (str): if 'con', output to console
+
+ parsed_artifact (list): prepared in CM CLI or CM access function
+ [ (artifact alias, artifact UID) ] or
+ [ (artifact alias, artifact UID), (artifact repo alias, artifact repo UID) ]
+
+ (repos) (str): list of repositories to search for automations (internal & mlcommons@ck by default)
+
+ (output_dir) (str): output directory (../docs by default)
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ """
+
+ return utils.call_internal_module(self, __file__, 'module_misc', 'doc', i)
+
+ ############################################################
+ def gui(self, i):
+ """
+ Run GUI for CM script.
+
+ Args:
+ (CM input dict):
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ """
+
+ artifact = i.get('artifact', '')
+ tags = ''
+ if artifact != '':
+ if ' ' in artifact:
+ tags = artifact.replace(' ',',')
+
+ if tags=='':
+ tags = i.get('tags','')
+
+ if 'tags' in i:
+ del(i['tags'])
+
+ i['action']='run'
+ i['artifact']='gui'
+ i['parsed_artifact']=[('gui','605cac42514a4c69')]
+ i['script']=tags.replace(',',' ')
+
+ return self.cmind.access(i)
+
+
+
+ ############################################################
+ def dockerfile(self, i):
+ """
+ Generate Dockerfile for CM script.
+
+ Args:
+ (CM input dict):
+
+ (out) (str): if 'con', output to console
+
+ parsed_artifact (list): prepared in CM CLI or CM access function
+ [ (artifact alias, artifact UID) ] or
+ [ (artifact alias, artifact UID), (artifact repo alias, artifact repo UID) ]
+
+ (repos) (str): list of repositories to search for automations (internal & mlcommons@ck by default)
+
+ (output_dir) (str): output directory (./ by default)
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ """
+
+ return utils.call_internal_module(self, __file__, 'module_misc', 'dockerfile', i)
+
+ ############################################################
+ def docker(self, i):
+ """
+ Run CM script in an automatically-generated container.
+
+ Args:
+ (CM input dict):
+
+ (out) (str): if 'con', output to console
+
+ parsed_artifact (list): prepared in CM CLI or CM access function
+ [ (artifact alias, artifact UID) ] or
+ [ (artifact alias, artifact UID), (artifact repo alias, artifact repo UID) ]
+
+ (repos) (str): list of repositories to search for automations (internal & mlcommons@ck by default)
+
+ (output_dir) (str): output directory (./ by default)
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ """
+
+ return utils.call_internal_module(self, __file__, 'module_misc', 'docker', i)
+
+
+ ##############################################################################
+ def _available_variations(self, i):
+ """
+ return error with available variations
+
+ Args:
+ (CM input dict):
+
+ meta (dict): meta of the script
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ 16 if not detected
+ * (error) (str): error string if return>0
+
+ """
+
+ meta = i['meta']
+
+ list_of_variations = sorted(['_'+v for v in list(meta.get('variations',{}.keys()))])
+
+ return {'return':1, 'error':'python package variation is not defined in "{}". Available: {}'.format(meta['alias'],' '.join(list_of_variations))}
+
+ ############################################################
+ def prepare(self, i):
+ """
+ Run CM script with --fake_run only to resolve deps
+ """
+
+ i['fake_run']=True
+
+ return self.run(i)
+
+ ############################################################
+ # Reusable blocks for some scripts
+ def clean_some_tmp_files(self, i):
+ """
+ Clean tmp files
+ """
+
+ env = i.get('env',{})
+
+ cur_work_dir = env.get('CM_TMP_CURRENT_SCRIPT_WORK_PATH','')
+ if cur_work_dir !='' and os.path.isdir(cur_work_dir):
+ for x in ['tmp-run.bat', 'tmp-state.json']:
+ xx = os.path.join(cur_work_dir, x)
+ if os.path.isfile(xx):
+ os.remove(xx)
+
+ return {'return':0}
+
+
+
+##############################################################################
+def find_cached_script(i):
+ """
+ Internal automation function: find cached script
+
+ Args:
+ (CM input dict):
+
+ deps (dict): deps dict
+ update_deps (dict): key matches "names" in deps
+
+ Returns:
+ (CM return dict):
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+ """
+
+ import copy
+
+ recursion_spaces = i['recursion_spaces']
+ script_tags = i['script_tags']
+ cached_tags = []
+ found_script_tags = i['found_script_tags']
+ variation_tags = i['variation_tags']
+ explicit_variation_tags = i['explicit_variation_tags']
+ version = i['version']
+ version_min = i['version_min']
+ version_max = i['version_max']
+ extra_cache_tags = i['extra_cache_tags']
+ new_cache_entry = i['new_cache_entry']
+ meta = i['meta']
+ env = i['env']
+ self_obj = i['self']
+ skip_remembered_selections = i['skip_remembered_selections']
+ remembered_selections = i['remembered_selections']
+ quiet = i['quiet']
+ search_tags = ''
+
+ verbose = i.get('verbose', False)
+ if not verbose: verbose = i.get('v', False)
+
+ found_cached_scripts = []
+
+ if verbose:
+ print (recursion_spaces + ' - Checking if script execution is already cached ...')
+
+ # Create a search query to find that we already ran this script with the same or similar input
+ # It will be gradually enhanced with more "knowledge" ...
+ if len(script_tags)>0:
+ for x in script_tags:
+ if x not in cached_tags:
+ cached_tags.append(x)
+
+ if len(found_script_tags)>0:
+ for x in found_script_tags:
+ if x not in cached_tags:
+ cached_tags.append(x)
+
+ explicit_cached_tags=copy.deepcopy(cached_tags)
+
+ if len(explicit_variation_tags)>0:
+ explicit_variation_tags_string = ''
+
+ for t in explicit_variation_tags:
+ if explicit_variation_tags_string != '':
+ explicit_variation_tags_string += ','
+ if t.startswith("-"):
+ x = "-_" + t[1:]
+ else:
+ x = '_' + t
+ explicit_variation_tags_string += x
+
+ if x not in explicit_cached_tags:
+ explicit_cached_tags.append(x)
+
+ if verbose:
+ print (recursion_spaces+' - Prepared explicit variations: {}'.format(explicit_variation_tags_string))
+
+ if len(variation_tags)>0:
+ variation_tags_string = ''
+
+ for t in variation_tags:
+ if variation_tags_string != '':
+ variation_tags_string += ','
+ if t.startswith("-"):
+ x = "-_" + t[1:]
+ else:
+ x = '_' + t
+ variation_tags_string += x
+
+ if x not in cached_tags:
+ cached_tags.append(x)
+
+ if verbose:
+ print (recursion_spaces+' - Prepared variations: {}'.format(variation_tags_string))
+
+ # Add version
+ if version !='':
+ if 'version-'+version not in cached_tags:
+ cached_tags.append('version-'+version)
+ explicit_cached_tags.append('version-'+version)
+
+ # Add extra cache tags (such as "virtual" for python)
+ if len(extra_cache_tags)>0:
+ for t in extra_cache_tags:
+ if t not in cached_tags:
+ cached_tags.append(t)
+ explicit_cached_tags.append(t)
+
+ # Add tags from deps (will be also duplicated when creating new cache entry)
+ extra_cache_tags_from_env = meta.get('extra_cache_tags_from_env',[])
+ for extra_cache_tags in extra_cache_tags_from_env:
+ key = extra_cache_tags['env']
+ prefix = extra_cache_tags.get('prefix','')
+
+ v = env.get(key,'').strip()
+ if v!='':
+ for t in v.split(','):
+ x = 'deps-' + prefix + t
+ if x not in cached_tags:
+ cached_tags.append(x)
+ explicit_cached_tags.append(x)
+
+ # Check if already cached
+ if not new_cache_entry:
+ search_tags = '-tmp'
+ if len(cached_tags) >0 :
+ search_tags += ',' + ','.join(explicit_cached_tags)
+
+ if verbose:
+ print (recursion_spaces+' - Searching for cached script outputs with the following tags: {}'.format(search_tags))
+
+ r = self_obj.cmind.access({'action':'find',
+ 'automation':self_obj.meta['deps']['cache'],
+ 'tags':search_tags})
+ if r['return']>0: return r
+
+ found_cached_scripts = r['list']
+
+ # Check if selection is remembered
+ if not skip_remembered_selections and len(found_cached_scripts) > 1:
+ # Need to add extra cached tags here (since recorded later)
+ for selection in remembered_selections:
+ if selection['type'] == 'cache' and set(selection['tags'].split(',')) == set(search_tags.split(',')):
+ tmp_version_in_cached_script = selection['cached_script'].meta.get('version','')
+
+ skip_cached_script = check_versions(self_obj.cmind, tmp_version_in_cached_script, version_min, version_max)
+
+ if skip_cached_script:
+ return {'return':2, 'error':'The version of the previously remembered selection for a given script ({}) mismatches the newly requested one'.format(tmp_version_in_cached_script)}
+ else:
+ found_cached_scripts = [selection['cached_script']]
+ if verbose:
+ print (recursion_spaces + ' - Found remembered selection with tags "{}"!'.format(search_tags))
+ break
+
+
+ if len(found_cached_scripts) > 0:
+ selection = 0
+
+ # Check version ranges ...
+ new_found_cached_scripts = []
+
+ for cached_script in found_cached_scripts:
+ skip_cached_script = False
+ dependent_cached_path = cached_script.meta.get('dependent_cached_path', '')
+ if dependent_cached_path:
+ if not os.path.exists(dependent_cached_path):
+ #Need to rm this cache entry
+ skip_cached_script = True
+ continue
+
+ if not skip_cached_script:
+ cached_script_version = cached_script.meta.get('version', '')
+
+ skip_cached_script = check_versions(self_obj.cmind, cached_script_version, version_min, version_max)
+
+ if not skip_cached_script:
+ new_found_cached_scripts.append(cached_script)
+
+ found_cached_scripts = new_found_cached_scripts
+
+ return {'return':0, 'cached_tags':cached_tags, 'search_tags':search_tags, 'found_cached_scripts':found_cached_scripts}
+
+
+##############################################################################
+def enable_or_skip_script(meta, env):
+ """
+ Internal: enable a dependency based on enable_if_env and skip_if_env meta information
+ """
+ for key in meta:
+ if key in env:
+ value = str(env[key]).lower()
+
+ meta_key = [str(v).lower() for v in meta[key]]
+
+ if set(meta_key) & set(["yes", "on", "true", "1"]):
+ if value not in ["no", "off", "false", "0"]:
+ continue
+ elif set(meta_key) & set(["no", "off", "false", "0"]):
+ if value in ["no", "off", "false", "0"]:
+ continue
+ elif value in meta_key:
+ continue
+ return False
+ return True
+
+############################################################################################################
+def update_env_with_values(env, fail_on_not_found=False):
+ """
+ Update any env key used as part of values in meta
+ """
+ import re
+ for key in env:
+ if key.startswith("+") and type(env[key]) != list:
+ return {'return': 1, 'error': 'List value expected for {} in env'.format(key)}
+
+ value = env[key]
+
+ # Check cases such as --env.CM_SKIP_COMPILE
+ if type(value)==bool:
+ env[key] = str(value)
+ continue
+
+ tmp_values = re.findall(r'<<<(.*?)>>>', str(value))
+
+ if not tmp_values:
+ if key == 'CM_GIT_URL' and env.get('CM_GIT_AUTH', "no") == "yes":
+ if 'CM_GH_TOKEN' in env and '@' not in env['CM_GIT_URL']:
+ params = {}
+ params["token"] = env['CM_GH_TOKEN']
+ value = get_git_url("token", value, params)
+ elif 'CM_GIT_SSH' in env:
+ value = get_git_url("ssh", value)
+ env[key] = value
+
+ continue
+
+ for tmp_value in tmp_values:
+ if tmp_value not in env and fail_on_not_found:
+ return {'return':1, 'error':'variable {} is not in env'.format(tmp_value)}
+ if tmp_value in env:
+ value = value.replace("<<<"+tmp_value+">>>", str(env[tmp_value]))
+
+ env[key] = value
+
+ return {'return': 0}
+
+
+##############################################################################
+def check_version_constraints(i):
+ """
+ Internal: check version constaints and skip script artifact if constraints are not met
+ """
+
+ detected_version = i['detected_version']
+
+ version = i.get('version', '')
+ version_min = i.get('version_min', '')
+ version_max = i.get('version_max', '')
+
+ cmind = i['cmind']
+
+ skip = False
+
+ if version != '' and version != detected_version:
+ skip = True
+
+ if not skip and detected_version != '' and version_min != '':
+ ry = cmind.access({'action':'compare_versions',
+ 'automation':'utils,dc2743f8450541e3',
+ 'version1':detected_version,
+ 'version2':version_min})
+ if ry['return']>0: return ry
+
+ if ry['comparison'] < 0:
+ skip = True
+
+ if not skip and detected_version != '' and version_max != '':
+ ry = cmind.access({'action':'compare_versions',
+ 'automation':'utils,dc2743f8450541e3',
+ 'version1':detected_version,
+ 'version2':version_max})
+ if ry['return']>0: return ry
+
+ if ry['comparison'] > 0:
+ skip = True
+
+ return {'return':0, 'skip':skip}
+
+
+##############################################################################
+def prepare_and_run_script_with_postprocessing(i, postprocess="postprocess"):
+ """
+ Internal: prepare and run script with postprocessing that can be reused for version check
+ """
+
+ path = i['path']
+ bat_ext = i['bat_ext']
+ os_info = i['os_info']
+ customize_code = i.get('customize_code', None)
+ customize_common_input = i.get('customize_common_input',{})
+
+ env = i.get('env', {})
+ const = i.get('const', {})
+ state = i.get('state', {})
+ const_state = i.get('const_state', {})
+ run_state = i.get('run_state', {})
+ verbose = i.get('verbose', False)
+ if not verbose: verbose = i.get('v', False)
+
+ show_time = i.get('time', False)
+
+ recursion = i.get('recursion', False)
+ found_script_tags = i.get('found_script_tags', [])
+ debug_script_tags = i.get('debug_script_tags', '')
+
+ meta = i.get('meta',{})
+
+ reuse_cached = i.get('reused_cached', False)
+ recursion_spaces = i.get('recursion_spaces', '')
+
+ tmp_file_run_state = i.get('tmp_file_run_state', '')
+ tmp_file_run_env = i.get('tmp_file_run_env', '')
+ tmp_file_state = i.get('tmp_file_state', '')
+ tmp_file_run = i['tmp_file_run']
+ local_env_keys = i.get('local_env_keys', [])
+ local_env_keys_from_meta = i.get('local_env_keys_from_meta', [])
+ posthook_deps = i.get('posthook_deps', [])
+ add_deps_recursive = i.get('add_deps_recursive', {})
+ recursion_spaces = i['recursion_spaces']
+ remembered_selections = i.get('remembered_selections', {})
+ variation_tags_string = i.get('variation_tags_string', '')
+ found_cached = i.get('found_cached', False)
+ script_automation = i['self']
+
+ repro_prefix = i.get('repro_prefix', '')
+
+ # Prepare script name
+ check_if_run_script_exists = False
+ script_name = i.get('script_name','').strip()
+ if script_name == '':
+ script_name = meta.get('script_name','').strip()
+ if script_name !='':
+ # Script name was added by user - we need to check that it really exists (on Linux or Windows)
+ check_if_run_script_exists = True
+ if script_name == '':
+ # Here is the default script name - if it doesn't exist, we skip it.
+ # However, if it's explicitly specified, we check it and report
+ # if it's missing ...
+ script_name = 'run'
+
+ if bat_ext == '.sh':
+ run_script = get_script_name(env, path, script_name)
+ else:
+ run_script = script_name + bat_ext
+
+ path_to_run_script = os.path.join(path, run_script)
+
+ if check_if_run_script_exists and not os.path.isfile(path_to_run_script):
+ return {'return':16, 'error':'script {} not found - please add one'.format(path_to_run_script)}
+
+ # Update env and state with const
+ utils.merge_dicts({'dict1':env, 'dict2':const, 'append_lists':True, 'append_unique':True})
+ utils.merge_dicts({'dict1':state, 'dict2':const_state, 'append_lists':True, 'append_unique':True})
+
+ # Update env with the current path
+ if os_info['platform'] == 'windows' and ' ' in path:
+ path = '"' + path + '"'
+
+ cur_dir = os.getcwd()
+
+ env['CM_TMP_CURRENT_SCRIPT_PATH'] = path
+ env['CM_TMP_CURRENT_SCRIPT_WORK_PATH'] = cur_dir
+
+ # Record state
+ if tmp_file_state != '':
+ r = utils.save_json(file_name = tmp_file_state, meta = state)
+ if r['return']>0: return r
+
+ rr = {'return':0}
+
+ # If batch file exists, run it with current env and state
+ if os.path.isfile(path_to_run_script) and not reuse_cached:
+ if tmp_file_run_state != '' and os.path.isfile(tmp_file_run_state):
+ os.remove(tmp_file_run_state)
+ if tmp_file_run_env != '' and os.path.isfile(tmp_file_run_env):
+ os.remove(tmp_file_run_env)
+
+ run_script = tmp_file_run + bat_ext
+
+ if verbose:
+ print ('')
+ print (recursion_spaces + ' - Running native script "{}" from temporal script "{}" in "{}" ...'.format(path_to_run_script, run_script, cur_dir))
+ print ('')
+
+ print (recursion_spaces + ' ! cd {}'.format(cur_dir))
+ print (recursion_spaces + ' ! call {} from {}'.format(path_to_run_script, run_script))
+
+
+ # Prepare env variables
+ import copy
+ script = copy.deepcopy(os_info['start_script'])
+
+ # Check if script_prefix in the state from other components
+ script_prefix = state.get('script_prefix',[])
+ if len(script_prefix)>0:
+# script = script_prefix + ['\n'] + script
+ script += script_prefix + ['\n']
+
+ script += convert_env_to_script(env, os_info)
+
+ # Check if run bash/cmd before running the command (for debugging)
+ if debug_script_tags !='' and all(item in found_script_tags for item in debug_script_tags.split(',')):
+ x=['cmd', '.', '','.bat'] if os_info['platform'] == 'windows' else ['bash', ' ""', '"','.sh']
+
+ script.append('\n')
+ script.append('echo{}\n'.format(x[1]))
+ script.append('echo {}Running debug shell. Type exit to resume script execution ...{}\n'.format(x[2],x[3],x[2]))
+ script.append('echo{}\n'.format(x[1]))
+ script.append('\n')
+ script.append(x[0])
+
+ # Append batch file to the tmp script
+ script.append('\n')
+ script.append(os_info['run_bat'].replace('${bat_file}', '"'+path_to_run_script+'"') + '\n')
+
+ # Prepare and run script
+ r = record_script(run_script, script, os_info)
+ if r['return']>0: return r
+
+ # Run final command
+ cmd = os_info['run_local_bat_from_python'].replace('${bat_file}', run_script)
+
+ rc = os.system(cmd)
+
+ if rc>0 and not i.get('ignore_script_error', False):
+ # Check if print files when error
+ print_files = meta.get('print_files_if_script_error', [])
+ if len(print_files)>0:
+ for pr in print_files:
+ if os.path.isfile(pr):
+ r = utils.load_txt(file_name = pr)
+ if r['return'] == 0:
+ print ("========================================================")
+ print ("Print file {}:".format(pr))
+ print ("")
+ print (r['string'])
+ print ("")
+
+ note = '''
+^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
+Note that it may be a portability issue of a third-party tool or a native script
+wrapped and unified by this automation recipe (CM script). In such case,
+please report this issue with a full log at "https://github.com/mlcommons/ck".
+The CM concept is to collaboratively fix such issues inside portable CM scripts
+to make existing tools and native scripts more portable, interoperable
+and deterministic. Thank you'''
+
+ rr = {'return':2, 'error':'Portable CM script failed (name = {}, return code = {})\n\n{}'.format(meta['alias'], rc, note)}
+
+ if repro_prefix != '':
+ dump_repro(repro_prefix, rr, run_state)
+
+ return rr
+
+ # Load updated state if exists
+ if tmp_file_run_state != '' and os.path.isfile(tmp_file_run_state):
+ r = utils.load_json(file_name = tmp_file_run_state)
+ if r['return']>0: return r
+
+ updated_state = r['meta']
+
+ utils.merge_dicts({'dict1':state, 'dict2':updated_state, 'append_lists':True, 'append_unique':True})
+
+ # Load updated env if exists
+ if tmp_file_run_env != '' and os.path.isfile(tmp_file_run_env):
+ r = utils.load_txt(file_name = tmp_file_run_env)
+ if r['return']>0: return r
+
+ r = utils.convert_env_to_dict(r['string'])
+ if r['return']>0: return r
+
+ updated_env = r['dict']
+
+ utils.merge_dicts({'dict1':env, 'dict2':updated_env, 'append_lists':True, 'append_unique':True})
+
+
+ if postprocess != '' and customize_code is not None:
+ print (recursion_spaces+' ! call "{}" from {}'.format(postprocess, customize_code.__file__))
+
+ if len(posthook_deps)>0 and (postprocess == "postprocess"):
+ r = script_automation._call_run_deps(posthook_deps, local_env_keys, local_env_keys_from_meta, env, state, const, const_state,
+ add_deps_recursive, recursion_spaces, remembered_selections, variation_tags_string, found_cached, debug_script_tags, verbose, show_time, ' ', run_state)
+ if r['return']>0: return r
+
+ if (postprocess == "postprocess") and customize_code is not None and 'postprocess' in dir(customize_code):
+ rr = run_postprocess(customize_code, customize_common_input, recursion_spaces, env, state, const,
+ const_state, meta, verbose, i) # i as run_script_input
+ elif (postprocess == "detect_version") and customize_code is not None and 'detect_version' in dir(customize_code):
+ rr = run_detect_version(customize_code, customize_common_input, recursion_spaces, env, state, const,
+ const_state, meta, verbose)
+
+ return rr
+
+##############################################################################
+def run_detect_version(customize_code, customize_common_input, recursion_spaces, env, state, const, const_state, meta, verbose=False):
+
+ if customize_code is not None and 'detect_version' in dir(customize_code):
+ import copy
+
+ if verbose:
+ print (recursion_spaces+' - Running detect_version ...')
+
+ # Update env and state with const
+ utils.merge_dicts({'dict1':env, 'dict2':const, 'append_lists':True, 'append_unique':True})
+ utils.merge_dicts({'dict1':state, 'dict2':const_state, 'append_lists':True, 'append_unique':True})
+
+ ii = copy.deepcopy(customize_common_input)
+ ii['env'] = env
+ ii['state'] = state
+ ii['meta'] = meta
+
+ r = customize_code.detect_version(ii)
+ return r
+
+ return {'return': 0}
+
+##############################################################################
+def run_postprocess(customize_code, customize_common_input, recursion_spaces, env, state, const, const_state, meta, verbose=False, run_script_input=None):
+
+ if customize_code is not None and 'postprocess' in dir(customize_code):
+ import copy
+
+ if verbose:
+ print (recursion_spaces+' - Running postprocess ...')
+
+ # Update env and state with const
+ utils.merge_dicts({'dict1':env, 'dict2':const, 'append_lists':True, 'append_unique':True})
+ utils.merge_dicts({'dict1':state, 'dict2':const_state, 'append_lists':True, 'append_unique':True})
+
+ ii = copy.deepcopy(customize_common_input)
+ ii['env'] = env
+ ii['state'] = state
+ ii['meta'] = meta
+
+ if run_script_input != None:
+ ii['run_script_input'] = run_script_input
+
+ r = customize_code.postprocess(ii)
+ return r
+
+ return {'return': 0}
+
+##############################################################################
+def get_script_name(env, path, script_name = 'run'):
+ """
+ Internal: find the most appropriate run script name for the detected OS
+ """
+
+ from os.path import exists
+
+ tmp_suff1 = env.get('CM_HOST_OS_FLAVOR', '')
+ tmp_suff2 = env.get('CM_HOST_OS_VERSION', '')
+ tmp_suff3 = env.get('CM_HOST_PLATFORM_FLAVOR', '')
+
+ if exists(os.path.join(path, script_name+'-' + tmp_suff1 + '-'+ tmp_suff2 + '-' + tmp_suff3 + '.sh')):
+ return script_name+'-' + tmp_suff1 + '-' + tmp_suff2 + '-' + tmp_suff3 + '.sh'
+ elif exists(os.path.join(path, script_name+'-' + tmp_suff1 + '-' + tmp_suff3 + '.sh')):
+ return script_name+'-' + tmp_suff1 + '-' + tmp_suff3 + '.sh'
+ elif exists(os.path.join(path, script_name+'-' + tmp_suff1 + '-' + tmp_suff2 + '.sh')):
+ return script_name+'-' + tmp_suff1 + '-' + tmp_suff2 + '.sh'
+ elif exists(os.path.join(path, script_name+'-' + tmp_suff1 + '.sh')):
+ return script_name+'-' + tmp_suff1 + '.sh'
+ elif exists(os.path.join(path, script_name+'-' + tmp_suff3 + '.sh')):
+ return script_name+'-' + tmp_suff3 + '.sh'
+ else:
+ return script_name+'.sh';
+
+##############################################################################
+def update_env_keys(env, env_key_mappings):
+ """
+ Internal: convert env keys as per the given mapping
+ """
+
+ for key_prefix in env_key_mappings:
+ for key in list(env):
+ if key.startswith(key_prefix):
+ new_key = key.replace(key_prefix, env_key_mappings[key_prefix])
+ env[new_key] = env[key]
+ #del(env[key])
+
+##############################################################################
+def convert_env_to_script(env, os_info, start_script = []):
+ """
+ Internal: convert env to script for a given platform
+ """
+
+ import copy
+ script = copy.deepcopy(start_script)
+
+ windows = True if os_info['platform'] == 'windows' else False
+
+ for k in sorted(env):
+ env_value = env[k]
+
+ if windows:
+ x = env_value
+ if type(env_value)!=list:
+ x = [x]
+
+ xx = []
+ for v in x:
+ # If " is already in env value, it means that there was some custom processing to consider special characters
+
+ y=str(v)
+
+ if '"' not in y:
+ for z in ['|', '&', '>', '<']:
+ if z in y:
+ y = '"'+y+'"'
+ break
+ xx.append(y)
+
+ env_value = xx if type(env_value)==list else xx[0]
+
+ # Process special env
+ key = k
+
+ if k.startswith('+'):
+ # List and append the same key at the end (+PATH, +LD_LIBRARY_PATH, +PYTHONPATH)
+ key=k[1:]
+ first = key[0]
+ env_separator = os_info['env_separator']
+ # If key starts with a symbol use it as the list separator (+ CFLAG will use ' ' the
+ # list separator while +;TEMP will use ';' as the separator)
+ if not first.isalnum():
+ env_separator = first
+ key=key[1:]
+
+ env_value = env_separator.join(env_value) + \
+ env_separator + \
+ os_info['env_var'].replace('env_var', key)
+
+ v = os_info['set_env'].replace('${key}', key).replace('${value}', str(env_value))
+
+ script.append(v)
+
+ return script
+
+##############################################################################
+def record_script(run_script, script, os_info):
+ """
+ Internal: record script and chmod 755 on Linux
+ """
+
+ final_script = '\n'.join(script)
+
+ if not final_script.endswith('\n'):
+ final_script += '\n'
+
+ r = utils.save_txt(file_name=run_script, string=final_script)
+ if r['return']>0: return r
+
+ if os_info.get('set_exec_file','')!='':
+ cmd = os_info['set_exec_file'].replace('${file_name}', run_script)
+ rc = os.system(cmd)
+
+ return {'return':0}
+
+##############################################################################
+def clean_tmp_files(clean_files, recursion_spaces):
+ """
+ Internal: clean tmp files
+ """
+
+# print ('')
+# print (recursion_spaces+' - cleaning files {} ...'.format(clean_files))
+
+ for tmp_file in clean_files:
+ if os.path.isfile(tmp_file):
+ os.remove(tmp_file)
+
+ return {'return':0}
+
+##############################################################################
+def update_dep_info(dep, new_info):
+ """
+ Internal: add additional info to a dependency
+ """
+ for info in new_info:
+ if info == "tags":
+ tags = dep.get('tags', '')
+ tags_list = tags.split(",")
+ new_tags_list = new_info["tags"].split(",")
+ combined_tags = tags_list + list(set(new_tags_list) - set(tags_list))
+ dep['tags'] = ",".join(combined_tags)
+ else:
+ dep[info] = new_info[info]
+
+##############################################################################
+def update_deps(deps, add_deps, fail_error=False):
+ """
+ Internal: add deps tags, version etc. by name
+ """
+ #deps_info_to_add = [ "version", "version_min", "version_max", "version_max_usable", "path" ]
+ new_deps_info = {}
+ for new_deps_name in add_deps:
+ dep_found = False
+ for dep in deps:
+ names = dep.get('names',[])
+ if new_deps_name in names:
+ update_dep_info(dep, add_deps[new_deps_name])
+ dep_found = True
+ if not dep_found and fail_error:
+ return {'return':1, 'error':new_deps_name + ' is not one of the dependency'}
+
+ return {'return':0}
+
+
+##############################################################################
+def append_deps(deps, new_deps):
+ """
+ Internal: add deps from meta
+ """
+
+ for new_dep in new_deps:
+ existing = False
+ new_dep_names = new_dep.get('names',[])
+ if len(new_dep_names)>0:
+ for i in range(len(deps)):
+ dep = deps[i]
+ dep_names = dep.get('names',[])
+ if len(dep_names)>0:
+ if set(new_dep_names) == set(dep_names):
+ deps[i] = new_dep
+ existing = True
+ break
+ else: #when no name, check for tags
+ new_dep_tags = new_dep.get('tags')
+ new_dep_tags_list = new_dep_tags.split(",")
+ for i in range(len(deps)):
+ dep = deps[i]
+ dep_tags_list = dep.get('tags').split(",")
+ if set(new_dep_tags_list) == set (dep_tags_list):
+ deps[i] = new_dep
+ existing = True
+ break
+
+ if not existing:
+ deps.append(new_dep)
+
+ return {'return':0}
+
+##############################################################################
+def update_deps_from_input(deps, post_deps, prehook_deps, posthook_deps, i):
+ """
+ Internal: update deps from meta
+ """
+ add_deps_info_from_input = i.get('ad',{})
+ if not add_deps_info_from_input:
+ add_deps_info_from_input = i.get('add_deps',{})
+ else:
+ utils.merge_dicts({'dict1':add_deps_info_from_input, 'dict2':i.get('add_deps', {}), 'append_lists':True, 'append_unique':True})
+
+ add_deps_recursive_info_from_input = i.get('adr', {})
+ if not add_deps_recursive_info_from_input:
+ add_deps_recursive_info_from_input = i.get('add_deps_recursive', {})
+ else:
+ utils.merge_dicts({'dict1':add_deps_recursive_info_from_input, 'dict2':i.get('add_deps_recursive', {}), 'append_lists':True, 'append_unique':True})
+
+ if add_deps_info_from_input:
+ r1 = update_deps(deps, add_deps_info_from_input, True)
+ r2 = update_deps(post_deps, add_deps_info_from_input, True)
+ r3 = update_deps(prehook_deps, add_deps_info_from_input, True)
+ r4 = update_deps(posthook_deps, add_deps_info_from_input, True)
+ if r1['return']>0 and r2['return']>0 and r3['return']>0 and r4['return']>0: return r1
+ if add_deps_recursive_info_from_input:
+ update_deps(deps, add_deps_recursive_info_from_input)
+ update_deps(post_deps, add_deps_recursive_info_from_input)
+ update_deps(prehook_deps, add_deps_recursive_info_from_input)
+ update_deps(posthook_deps, add_deps_recursive_info_from_input)
+
+ return {'return':0}
+
+
+##############################################################################
+def update_env_from_input_mapping(env, inp, input_mapping):
+ """
+ Internal: update env from input and input_mapping
+ """
+ for key in input_mapping:
+ if key in inp:
+ env[input_mapping[key]] = inp[key]
+
+##############################################################################
+def update_state_from_meta(meta, env, state, deps, post_deps, prehook_deps, posthook_deps, new_env_keys, new_state_keys, i):
+ """
+ Internal: update env and state from meta
+ """
+
+ default_env = meta.get('default_env',{})
+ for key in default_env:
+ env.setdefault(key, default_env[key])
+ update_env = meta.get('env', {})
+ env.update(update_env)
+
+ update_state = meta.get('state', {})
+ utils.merge_dicts({'dict1':state, 'dict2':update_state, 'append_lists':True, 'append_unique':True})
+
+ new_deps = meta.get('deps', [])
+ if len(new_deps)>0:
+ append_deps(deps, new_deps)
+
+ new_post_deps = meta.get("post_deps", [])
+ if len(new_post_deps) > 0:
+ append_deps(post_deps, new_post_deps)
+
+ new_prehook_deps = meta.get("prehook_deps", [])
+ if len(new_prehook_deps) > 0:
+ append_deps(prehook_deps, new_prehook_deps)
+
+ new_posthook_deps = meta.get("posthook_deps", [])
+ if len(new_posthook_deps) > 0:
+ append_deps(posthook_deps, new_posthook_deps)
+
+ add_deps_info = meta.get('ad', {})
+ if not add_deps_info:
+ add_deps_info = meta.get('add_deps',{})
+ else:
+ utils.merge_dicts({'dict1':add_deps_info, 'dict2':meta.get('add_deps', {}), 'append_lists':True, 'append_unique':True})
+ if add_deps_info:
+ r1 = update_deps(deps, add_deps_info, True)
+ r2 = update_deps(post_deps, add_deps_info, True)
+ r3 = update_deps(prehook_deps, add_deps_info, True)
+ r4 = update_deps(posthook_deps, add_deps_info, True)
+ if r1['return']>0 and r2['return']>0 and r3['return'] > 0 and r4['return'] > 0: return r1
+
+ input_mapping = meta.get('input_mapping', {})
+ if input_mapping:
+ update_env_from_input_mapping(env, i['input'], input_mapping)
+
+ # Possibly restrict this to within docker environment
+ new_docker_settings = meta.get('docker')
+ if new_docker_settings:
+ docker_settings = state.get('docker', {})
+ #docker_input_mapping = docker_settings.get('docker_input_mapping', {})
+ #new_docker_input_mapping = new_docker_settings.get('docker_input_mapping', {})
+ #if new_docker_input_mapping:
+ # # update_env_from_input_mapping(env, i['input'], docker_input_mapping)
+ # utils.merge_dicts({'dict1':docker_input_mapping, 'dict2':new_docker_input_mapping, 'append_lists':True, 'append_unique':True})
+ utils.merge_dicts({'dict1':docker_settings, 'dict2':new_docker_settings, 'append_lists':True, 'append_unique':True})
+ state['docker'] = docker_settings
+
+ new_env_keys_from_meta = meta.get('new_env_keys', [])
+ if new_env_keys_from_meta:
+ new_env_keys += new_env_keys_from_meta
+
+ new_state_keys_from_meta = meta.get('new_state_keys', [])
+ if new_state_keys_from_meta:
+ new_state_keys += new_state_keys_from_meta
+
+ return {'return':0}
+
+##############################################################################
+def update_adr_from_meta(deps, post_deps, prehook_deps, posthook_deps, add_deps_recursive_info):
+ """
+ Internal: update add_deps_recursive from meta
+ """
+ if add_deps_recursive_info:
+ update_deps(deps, add_deps_recursive_info)
+ update_deps(post_deps, add_deps_recursive_info)
+ update_deps(prehook_deps, add_deps_recursive_info)
+ update_deps(posthook_deps, add_deps_recursive_info)
+
+ return {'return':0}
+
+##############################################################################
+def get_adr(meta):
+ add_deps_recursive_info = meta.get('adr', {})
+ if not add_deps_recursive_info:
+ add_deps_recursive_info = meta.get('add_deps_recursive',{})
+ else:
+ utils.merge_dicts({'dict1':add_deps_recursive_info, 'dict2':meta.get('add_deps_recursive', {}), 'append_lists':True, 'append_unique':True})
+ return add_deps_recursive_info
+
+##############################################################################
+def detect_state_diff(env, saved_env, new_env_keys, new_state_keys, state, saved_state):
+ """
+ Internal: detect diff in env and state
+ """
+
+ new_env = {}
+ new_state = {}
+
+ # Check if leave only specific keys or detect diff automatically
+ for k in new_env_keys:
+ if '?' in k or '*' in k:
+ import fnmatch
+ for kk in env:
+ if fnmatch.fnmatch(kk, k):
+ new_env[kk] = env[kk]
+ elif k in env:
+ new_env[k] = env[k]
+ elif "<<<" in k:
+ import re
+ tmp_values = re.findall(r'<<<(.*?)>>>', k)
+ for tmp_value in tmp_values:
+ if tmp_value in env:
+ value = env[tmp_value]
+ if value in env:
+ new_env[value] = env[value]
+
+ for k in new_state_keys:
+ if '?' in k or '*' in k:
+ import fnmatch
+ for kk in state:
+ if fnmatch.fnmatch(kk, k):
+ new_state[kk] = state[kk]
+ elif k in state:
+ new_state[k] = state[k]
+ elif "<<<" in k:
+ import re
+ tmp_values = re.findall(r'<<<(.*?)>>>', k)
+ for tmp_value in tmp_values:
+ if tmp_value in state:
+ value = state[tmp_value]
+ if value in state:
+ new_state[value] = state[value]
+
+ return {'return':0, 'env':env, 'new_env':new_env, 'state':state, 'new_state':new_state}
+
+##############################################################################
+def select_script_artifact(lst, text, recursion_spaces, can_skip, script_tags_string, quiet, verbose):
+ """
+ Internal: select script
+ """
+
+ string1 = recursion_spaces+' - More than 1 {} found for "{}":'.format(text,script_tags_string)
+
+ # If quiet, select 0 (can be sorted for determinism)
+ if quiet:
+ if verbose:
+ print (string1)
+ print ('')
+ print ('Selected default due to "quiet" mode')
+
+ return 0
+
+ # Select 1 and proceed
+ print (string1)
+
+ print ('')
+ num = 0
+
+ for a in lst:
+ meta = a.meta
+
+ name = meta.get('name', '')
+
+ s = a.path
+ if name !='': s = '"'+name+'" '+s
+
+ x = recursion_spaces+' {}) {} ({})'.format(num, s, ','.join(meta['tags']))
+
+ version = meta.get('version','')
+ if version!='':
+ x+=' (Version {})'.format(version)
+
+ print (x)
+ num+=1
+
+ print ('')
+
+ s = 'Make your selection or press Enter for 0'
+ if can_skip:
+ s += ' or use -1 to skip'
+
+ x = input(recursion_spaces+' '+s+': ')
+ x = x.strip()
+ if x == '': x = '0'
+
+ selection = int(x)
+
+ if selection <0 and not can_skip:
+ selection = 0
+
+ if selection <0:
+
+ print ('')
+ print (recursion_spaces+' Skipped')
+ else:
+ if selection >= num:
+ selection = 0
+
+ print ('')
+ print (recursion_spaces+' Selected {}: {}'.format(selection, lst[selection].path))
+
+ return selection
+
+##############################################################################
+def check_versions(cmind, cached_script_version, version_min, version_max):
+ """
+ Internal: check versions of the cached script
+ """
+ skip_cached_script = False
+
+ if cached_script_version != '':
+ if version_min != '':
+ ry = cmind.access({'action':'compare_versions',
+ 'automation':'utils,dc2743f8450541e3',
+ 'version1':cached_script_version,
+ 'version2':version_min})
+ if ry['return']>0: return ry
+
+ if ry['comparison'] < 0:
+ skip_cached_script = True
+
+ if not skip_cached_script and version_max != '':
+ ry = cmind.access({'action':'compare_versions',
+ 'automation':'utils,dc2743f8450541e3',
+ 'version1':cached_script_version,
+ 'version2':version_max})
+ if ry['return']>0: return ry
+
+ if ry['comparison'] > 0:
+ skip_cached_script = True
+
+ return skip_cached_script
+
+##############################################################################
+def get_git_url(get_type, url, params = {}):
+ from giturlparse import parse
+ p = parse(url)
+ if get_type == "ssh":
+ return p.url2ssh
+ elif get_type == "token":
+ token = params['token']
+ return "https://git:" + token + "@" + p.host + "/" + p.owner + "/" + p.repo
+ return url
+
+##############################################################################
+def can_write_to_current_directory():
+
+ import tempfile
+
+ cur_dir = os.getcwd()
+
+# try:
+# tmp_file = tempfile.NamedTemporaryFile(dir = cur_dir)
+# except Exception as e:
+# return False
+
+ tmp_file_name = next(tempfile._get_candidate_names())+'.tmp'
+
+ tmp_path = os.path.join(cur_dir, tmp_file_name)
+
+ try:
+ tmp_file = open(tmp_file_name, 'w')
+ except Exception as e:
+ return False
+
+ tmp_file.close()
+
+ os.remove(tmp_file_name)
+
+ return True
+
+######################################################################################
+def dump_repro_start(repro_prefix, ii):
+ import json
+
+ # Clean reproducibility and experiment files
+ for f in ['cm-output.json', 'version_info.json', '-input.json', '-info.json', '-output.json', '-run-state.json']:
+ ff = repro_prefix+f if f.startswith('-') else f
+ if os.path.isfile(ff):
+ try:
+ os.remove(ff)
+ except:
+ pass
+
+ try:
+ with open(repro_prefix+'-input.json', 'w', encoding='utf-8') as f:
+ json.dump(ii, f, ensure_ascii=False, indent=2)
+ except:
+ pass
+
+ # Get some info
+ info = {}
+
+ try:
+ import platform
+ import sys
+
+ info['host_os_name'] = os.name
+ info['host_system'] = platform.system()
+ info['host_os_release'] = platform.release()
+ info['host_machine'] = platform.machine()
+ info['host_architecture'] = platform.architecture()
+ info['host_python_version'] = platform.python_version()
+ info['host_sys_version'] = sys.version
+
+ r = utils.gen_uid()
+ if r['return']==0:
+ info['run_uid'] = r['uid']
+
+ r = utils.get_current_date_time({})
+ if r['return']==0:
+ info['run_iso_datetime'] = r['iso_datetime']
+
+ with open(repro_prefix+'-info.json', 'w', encoding='utf-8') as f:
+ json.dump(info, f, ensure_ascii=False, indent=2)
+ except:
+ pass
+
+
+ # For experiment
+ cm_output = {}
+
+ cm_output['tmp_test_value']=10.0
+
+ cm_output['info']=info
+ cm_output['input']=ii
+
+ try:
+ with open('cm-output.json', 'w', encoding='utf-8') as f:
+ json.dump(cm_output, f, ensure_ascii=False, indent=2)
+ except:
+ pass
+
+ return {'return': 0}
+
+######################################################################################
+def dump_repro(repro_prefix, rr, run_state):
+ import json
+ import copy
+
+ try:
+ with open(repro_prefix+'-output.json', 'w', encoding='utf-8') as f:
+ json.dump(rr, f, ensure_ascii=False, indent=2)
+ except:
+ pass
+
+ try:
+ with open(repro_prefix+'-run-state.json', 'w', encoding='utf-8') as f:
+ json.dump(run_state, f, ensure_ascii=False, indent=2)
+ except:
+ pass
+
+ # For experiment
+ cm_output = {}
+
+ # Attempt to read
+ try:
+ r = utils.load_json('cm-output.json')
+ if r['return']==0:
+ cm_output = r['meta']
+ except:
+ pass
+
+ cm_output['output'] = rr
+ cm_output['state'] = copy.deepcopy(run_state)
+
+ # Try to load version_info.json
+ version_info = {}
+
+ version_info_orig = {}
+
+ if 'version_info' in cm_output['state']:
+ version_info_orig = cm_output['state']['version_info']
+ del(cm_output['state']['version_info'])
+
+ try:
+ r = utils.load_json('version_info.json')
+ if r['return']==0:
+ version_info_orig += r['meta']
+
+ for v in version_info_orig:
+ for key in v:
+ dep = v[key]
+ version_info[key] = dep
+
+ except:
+ pass
+
+ if len(version_info)>0:
+ cm_output['version_info'] = version_info
+
+ if rr['return'] == 0:
+ cm_output['acm_ctuning_repro_badge_available'] = True
+ cm_output['acm_ctuning_repro_badge_functional'] = True
+
+ try:
+ with open('cm-output.json', 'w', encoding='utf-8') as f:
+ json.dump(cm_output, f, ensure_ascii=False, indent=2, sort_keys=True)
+ except:
+ pass
+
+
+ return {'return': 0}
+
+
+##############################################################################
+# Demo to show how to use CM components independently if needed
+if __name__ == "__main__":
+ import cmind
+ auto = CAutomation(cmind, __file__)
+
+ r=auto.test({'x':'y'})
+
+ print (r)
diff --git a/automation/script/module_help.py b/automation/script/module_help.py
new file mode 100644
index 0000000000..e27d756877
--- /dev/null
+++ b/automation/script/module_help.py
@@ -0,0 +1,100 @@
+import os
+from cmind import utils
+
+# Pring help about script
+def print_help(i):
+
+ meta = i.get('meta', '')
+ path = i.get('path', '')
+
+ if len(meta)==0 and path=='':
+ return {'return':0}
+
+ print ('')
+ print ('Help for this CM script ({},{}):'.format(meta.get('alias',''), meta.get('uid','')))
+
+ print ('')
+ print ('Path to this automation recipe: {}'.format(path))
+
+ variations = meta.get('variations',{})
+ if len(variations)>0:
+ print ('')
+ print ('Available variations:')
+ print ('')
+ for v in sorted(variations):
+ print (' _'+v)
+
+ input_mapping = meta.get('input_mapping', {})
+ if len(input_mapping)>0:
+ print ('')
+ print ('Available flags mapped to environment variables:')
+ print ('')
+ for k in sorted(input_mapping):
+ v = input_mapping[k]
+
+ print (' --{} -> --env.{}'.format(k,v))
+
+ input_description = meta.get('input_description', {})
+ if len(input_description)>0:
+ # Check if has important ones (sort)
+ sorted_keys = []
+ all_keys = sorted(list(input_description.keys()))
+
+ for k in sorted(all_keys, key = lambda x: input_description[x].get('sort',0)):
+ v = input_description[k]
+ if v.get('sort',0)>0:
+ sorted_keys.append(k)
+
+
+ print ('')
+ print ('Available flags (Python API dict keys):')
+ print ('')
+ for k in all_keys:
+ v = input_description[k]
+ n = v.get('desc','')
+
+ x = ' --'+k
+ if n!='': x+=' ({})'.format(n)
+
+ print (x)
+
+ if len(sorted_keys)>0:
+ print ('')
+ print ('Main flags:')
+ print ('')
+ for k in sorted_keys:
+ v = input_description[k]
+ n = v.get('desc','')
+
+ x = ' --'+k
+
+ d = None
+ if 'default' in v:
+ d = v.get('default','')
+
+ if d!=None:
+ x+='='+d
+
+ c = v.get('choices',[])
+ if len(c)>0:
+ x+=' {'+','.join(c)+'}'
+
+ if n!='': x+=' ({})'.format(n)
+
+ print (x)
+
+
+
+ print ('')
+ x = input ('Would you like to see a Python API with a list of common keys/flags for all scripts including this one (y/N)? ')
+
+ x = x.strip().lower()
+
+ skip_delayed_help = False if x in ['y','yes'] else True
+
+ r = {'return':0}
+
+ if skip_delayed_help:
+ r['skip_delayed_help'] = True
+
+ return r
diff --git a/automation/script/module_misc.py b/automation/script/module_misc.py
new file mode 100644
index 0000000000..91b7873ae9
--- /dev/null
+++ b/automation/script/module_misc.py
@@ -0,0 +1,1990 @@
+import os
+from cmind import utils
+
+# Meta deps
+def process_deps(self_module, meta, meta_url, md_script_readme, key, extra_space='', skip_from_meta=False, skip_if_empty=False):
+
+ x = ''
+ y = []
+ if len(meta.get(key,{}))>0:
+ x = '***'
+
+ for d in meta[key]:
+ d_tags = d.get('tags', '')
+
+ z = extra_space+' * '+d_tags
+
+ names = d.get('names', [])
+ enable_if_env = d.get('enable_if_env', {})
+ skip_if_env = d.get('skip_if_env', {})
+
+ q = ''
+
+ q1 = ''
+ for e in enable_if_env:
+ if q1!='': q1 += ' AND '
+ q1 += e+' '
+ v = enable_if_env[e]
+ q1 += ' == '+str(v[0]) if len(v)==1 else 'in '+str(v)
+ if q1!='': q1 = '('+q1+')'
+
+ q2 = ''
+ for e in skip_if_env:
+ if q2!='': q2 += ' OR '
+ q2 += e+' '
+ v = skip_if_env[e]
+ q2 += ' != '+str(v[0]) if len(v)==1 else 'not in '+str(v)
+
+ if q2!='': q2 = '('+q2+')'
+
+ if q1!='' or q2!='':
+ q = 'if '
+
+ if q1!='': q+=q1
+ if q2!='':
+ if q1!='': q+=' AND '
+ q+=q2
+
+ y.append(z)
+
+ if q!='':
+ y.append(extra_space+' * `'+q+'`')
+
+ if len(names)>0:
+ y.append(extra_space+' * CM names: `--adr.'+str(names)+'...`')
+
+
+ # Attempt to find related CM scripts
+ r = self_module.cmind.access({'action':'find',
+ 'automation':'script',
+ 'tags':d_tags})
+ if r['return']==0:
+ lst = r['list']
+
+ if len(lst)==0:
+ y.append(extra_space+' - *Warning: no scripts found*')
+ else:
+ for s in lst:
+ s_repo_meta = s.repo_meta
+
+ s_repo_alias = s_repo_meta.get('alias','')
+ s_repo_uid = s_repo_meta.get('uid','')
+
+ # Check URL
+ s_url = ''
+ s_url_repo = ''
+ if s_repo_alias == 'internal':
+ s_url_repo = 'https://github.com/mlcommons/ck/tree/master/cm/cmind/repo'
+ s_url = s_url_repo+'/script/'
+ elif '@' in s_repo_alias:
+ s_url_repo = 'https://github.com/'+s_repo_alias.replace('@','/')+'/tree/master'
+ if s_repo_meta.get('prefix','')!='': s_url_repo+='/'+s_repo_meta['prefix']
+ s_url = s_url_repo+ '/script/'
+
+ s_alias = s.meta['alias']
+ y.append(extra_space+' - CM script: [{}]({})'.format(s_alias, s_url+s_alias))
+
+ z = ''
+ if not skip_from_meta:
+ z = ' from [meta]({})'.format(meta_url)
+
+ if not skip_if_empty or len(y)>0:
+ md_script_readme.append((extra_space+' 1. '+x+'Read "{}" on other CM scripts'+z+x).format(key))
+ md_script_readme += y
+
+############################################################
+def doc(i):
+ """
+ Add CM automation.
+
+ Args:
+ (CM input dict):
+
+ (out) (str): if 'con', output to console
+
+ parsed_artifact (list): prepared in CM CLI or CM access function
+ [ (artifact alias, artifact UID) ] or
+ [ (artifact alias, artifact UID), (artifact repo alias, artifact repo UID) ]
+
+ (repos) (str): list of repositories to search for automations (internal & mlcommons@ck by default)
+
+ (output_dir) (str): output directory (../docs by default)
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ """
+
+ self_module = i['self_module']
+
+ cur_dir = os.getcwd()
+
+ template_file = 'template_list_of_scripts.md'
+ list_file = 'list_of_scripts.md'
+
+ public_taskforce = '[Public MLCommons Task Force on Automation and Reproducibility](https://github.com/mlcommons/ck/blob/master/docs/taskforce.md)'
+
+ console = i.get('out') == 'con'
+
+ repos = i.get('repos','')
+ if repos == '': repos='internal,a4705959af8e447a'
+
+ parsed_artifact = i.get('parsed_artifact',[])
+
+ if len(parsed_artifact)<1:
+ parsed_artifact = [('',''), ('','')]
+ elif len(parsed_artifact)<2:
+ parsed_artifact.append(('',''))
+ else:
+ repos = parsed_artifact[1][0]
+
+ list_of_repos = repos.split(',') if ',' in repos else [repos]
+
+ ii = utils.sub_input(i, self_module.cmind.cfg['artifact_keys'] + ['tags'])
+
+ ii['out'] = None
+
+ # Search for automations in repos
+ lst = []
+ for repo in list_of_repos:
+ parsed_artifact[1] = ('',repo) if utils.is_cm_uid(repo) else (repo,'')
+ ii['parsed_artifact'] = parsed_artifact
+ r = self_module.search(ii)
+ if r['return']>0: return r
+ lst += r['list']
+
+ md = []
+
+ toc = []
+
+ toc_category = {}
+ toc_category_sort = {}
+ script_meta = {}
+ urls = {}
+
+ for artifact in sorted(lst, key = lambda x: x.meta.get('alias','')):
+
+ toc_readme = []
+
+ # Common index for all scripts
+ md_script = []
+
+ path = artifact.path
+ meta = artifact.meta
+ original_meta = artifact.original_meta
+
+ print ('Documenting {}'.format(path))
+
+ alias = meta.get('alias','')
+ uid = meta.get('uid','')
+
+ script_meta[alias] = meta
+
+ name = meta.get('name','')
+ developers = meta.get('developers','')
+
+ # Check if has tags help otherwise all tags
+ tags = meta.get('tags_help','').strip()
+ if tags=='':
+ tags = meta.get('tags',[])
+ else:
+ tags = tags.split(' ')
+
+ variations = meta.get('variations',{})
+
+ variation_keys = sorted(list(variations.keys()))
+ version_keys = sorted(list(meta.get('versions',{}).keys()))
+
+ default_variation = meta.get('default_variation','')
+ default_version = meta.get('default_version','')
+
+ input_mapping = meta.get('input_mapping', {})
+ input_description = meta.get('input_description', {})
+
+ category = meta.get('category', '').strip()
+ category_sort = meta.get('category_sort', 0)
+ if category != '':
+ if category not in toc_category:
+ toc_category[category]=[]
+
+ if category not in toc_category_sort or category_sort>0:
+ toc_category_sort[category]=category_sort
+
+ if alias not in toc_category[category]:
+ toc_category[category].append(alias)
+
+ repo_path = artifact.repo_path
+ repo_meta = artifact.repo_meta
+
+ repo_alias = repo_meta.get('alias','')
+ repo_uid = repo_meta.get('uid','')
+
+
+ # Check URL
+ url = ''
+ url_repo = ''
+ if repo_alias == 'internal':
+ url_repo = 'https://github.com/mlcommons/ck/tree/dev/cm/cmind/repo'
+ url = url_repo+'/script/'
+ elif '@' in repo_alias:
+ url_repo = 'https://github.com/'+repo_alias.replace('@','/')+'/tree/dev'
+ if repo_meta.get('prefix','')!='': url_repo+='/'+repo_meta['prefix']
+ url = url_repo+ '/script/'
+
+ if url!='':
+ url+=alias
+
+ urls[alias]=url
+
+ # Check if there is about doc
+ path_readme = os.path.join(path, 'README.md')
+ path_readme_extra = os.path.join(path, 'README-extra.md')
+ path_readme_about = os.path.join(path, 'README-about.md')
+
+ readme_about = ''
+ if os.path.isfile(path_readme_about):
+ r = utils.load_txt(path_readme_about, split = True)
+ if r['return']>0: return
+
+ s = r['string']
+ readme_about = r['list']
+
+
+ #######################################################################
+ # Start automatically generated README
+ md_script_readme = [
+# '',
+# 'Click here to see the table of contents.
',
+# '{{CM_README_TOC}}',
+# ' ',
+# '',
+ 'Automatically generated README for this automation recipe: **{}**'.format(meta['alias']),
+ ]
+
+
+ md_script.append('## '+alias)
+ md_script.append('')
+
+# x = 'About'
+# md_script_readme.append('___')
+# md_script_readme.append('### '+x)
+# md_script_readme.append('')
+# toc_readme.append(x)
+
+# x = 'About'
+# md_script_readme.append('#### '+x)
+# md_script_readme.append('')
+# toc_readme.append(' '+x)
+
+ if name!='':
+ name += '.'
+ md_script.append('*'+name+'*')
+ md_script.append('')
+
+# md_script_readme.append('*'+name+'*')
+# md_script_readme.append('')
+
+
+
+ if os.path.isfile(path_readme):
+ r = utils.load_txt(path_readme, split = True)
+ if r['return']>0: return
+
+ s = r['string']
+ readme = r['list']
+
+ if not 'automatically generated' in s.lower():
+ found_path_readme_extra = True
+
+ # Attempt to rename to README-extra.md
+ if os.path.isfile(path_readme_extra):
+ return {'return':1, 'error':'README.md is not auto-generated and README-extra.md already exists - can\'t rename'}
+
+ os.rename(path_readme, path_readme_extra)
+
+ # Add to Git (if in git)
+ os.chdir(path)
+ os.system('git add README-extra.md')
+ os.chdir(cur_dir)
+
+
+
+ if category!='':
+ md_script_readme.append('')
+ md_script_readme.append('Category: **{}**'.format(category))
+
+ md_script_readme.append('')
+ md_script_readme.append('License: **Apache 2.0**')
+
+
+ md_script_readme.append('')
+
+ if developers == '':
+ md_script_readme.append('Maintainers: ' + public_taskforce)
+ else:
+ md_script_readme.append('Developers: ' + developers)
+
+ x = '* [{}]({})'.format(alias, url)
+ if name !='': x+=' *('+name+')*'
+ toc.append(x)
+
+
+
+ cm_readme_extra = '[ [Online info and GUI to run this CM script](https://access.cknowledge.org/playground/?action=scripts&name={},{}) ] '.format(alias, uid)
+
+ if os.path.isfile(path_readme_extra):
+ readme_extra_url = url+'/README-extra.md'
+
+ x = '* Notes from the authors, contributors and users: [*GitHub*]({})'.format(readme_extra_url)
+ md_script.append(x)
+
+ cm_readme_extra += '[ [Notes from the authors, contributors and users](README-extra.md) ] '
+
+ md_script_readme.append('')
+ md_script_readme.append('---')
+ md_script_readme.append('*'+cm_readme_extra.strip()+'*')
+
+
+ if readme_about!='':
+ md_script_readme += ['', '---', ''] + readme_about
+
+
+
+ x = 'Summary'
+ md_script_readme.append('')
+ md_script_readme.append('---')
+ md_script_readme += [
+# '',
+# 'Click to see the summary
',
+ '#### Summary',
+ ''
+ ]
+ toc_readme.append(x)
+
+
+# if category != '':
+# x = 'Category'
+# md_script_readme.append('___')
+# md_script_readme.append('#### '+x)
+# md_script_readme.append(' ')
+# md_script_readme.append(category+'.')
+# toc_readme.append(x)
+
+# x = '* Category: *{}*'.format(category + '.')
+# md_script_readme.append(x)
+
+
+# x = 'Origin'
+# md_script_readme.append('___')
+# md_script_readme.append('#### '+x)
+# md_script_readme.append('')
+# toc_readme.append(x)
+
+ x = '* CM GitHub repository: *[{}]({})*'.format(repo_alias, url_repo)
+ md_script.append(x)
+ md_script_readme.append(x)
+
+
+ x = '* GitHub directory for this script: *[GitHub]({})*'.format(url)
+ md_script.append(x)
+ md_script_readme.append(x)
+
+
+
+ # Check meta
+ meta_file = self_module.cmind.cfg['file_cmeta']
+ meta_path = os.path.join(path, meta_file)
+
+ meta_file += '.yaml' if os.path.isfile(meta_path+'.yaml') else '.json'
+
+ meta_url = url+'/'+meta_file
+
+ x = '* CM meta description of this script: *[GitHub]({})*'.format(meta_url)
+ md_script.append(x)
+
+# x = '* CM automation "script": *[Docs]({})*'.format('https://github.com/octoml/ck/blob/master/docs/list_of_automations.md#script')
+# md_script.append(x)
+# md_script_readme.append(x)
+
+ if len(variation_keys)>0:
+ variation_pointer="[,variations]"
+ variation_pointer2="[variations]"
+ else:
+ variation_pointer=''
+ variation_pointer2=''
+
+ if len(input_mapping)>0:
+ input_mapping_pointer="[--input_flags]"
+ else:
+ input_mapping_pointer=''
+
+ cli_all_tags = '`cm run script --tags={}`'.format(','.join(tags))
+ cli_all_tags3 = '`cm run script --tags={}{} {}`'.format(','.join(tags), variation_pointer, input_mapping_pointer)
+ x = '* CM CLI with all tags: {}*'.format(cli_all_tags)
+ md_script.append(x)
+
+ cli_help_tags_alternative = '`cmr "{}" --help`'.format(' '.join(tags))
+
+ cli_all_tags_alternative = '`cmr "{}"`'.format(' '.join(tags))
+ cli_all_tags_alternative3 = '`cmr "{} {}" {}`'.format(' '.join(tags), variation_pointer2, input_mapping_pointer)
+ cli_all_tags_alternative_j = '`cmr "{} {}" {} -j`'.format(' '.join(tags), variation_pointer, input_mapping_pointer)
+ x = '* CM CLI alternative: {}*'.format(cli_all_tags_alternative)
+ md_script.append(x)
+
+ cli_all_tags_alternative_docker = '`cm docker script "{}{}" {}`'.format(' '.join(tags), variation_pointer2, input_mapping_pointer)
+
+
+# cli_uid = '`cm run script {} {}`'.format(meta['uid'], input_mapping_pointer)
+# x = '* CM CLI with alias and UID: {}*'.format(cli_uid)
+# md_script.append(x)
+
+ if len(variation_keys)>0:
+ x=''
+ for variation in variation_keys:
+ if x!='': x+='; '
+ x+='_'+variation
+ md_script.append('* Variations: *{}*'.format(x))
+
+ if default_variation!='':
+ md_script.append('* Default variation: *{}*'.format(default_variation))
+
+ if len(version_keys)>0:
+ md_script.append('* Versions: *{}*'.format('; '.join(version_keys)))
+
+ if default_version!='':
+ md_script.append('* Default version: *{}*'.format(default_version))
+
+
+
+
+
+
+
+ md_script.append('')
+# md_script_readme.append('')
+
+ # Add extra to README
+ x = 'Meta description'
+# md_script_readme.append('___')
+# md_script_readme.append('### '+x)
+ md_script_readme.append('* CM meta description for this script: *[{}]({})*'.format(meta_file, meta_file))
+# md_script_readme.append('')
+# toc_readme.append(x)
+
+ x = 'Tags'
+# md_script_readme.append('___')
+# md_script_readme.append('### '+x)
+ md_script_readme.append('* All CM tags to find and reuse this script (see in above meta description): *{}*'.format(','.join(tags)))
+# md_script_readme.append('')
+# toc_readme.append(x)
+
+
+ cache = meta.get('cache', False)
+ md_script_readme.append('* Output cached? *{}*'.format(str(cache)))
+
+ md_script_readme.append('* See [pipeline of dependencies]({}) on other CM scripts'.format('#dependencies-on-other-cm-scripts'))
+
+ md_script_readme += ['',
+# ' '
+ ]
+
+
+
+ # Add usage
+ x1 = 'Reuse this script in your project'
+ x1a = 'Install MLCommons CM automation meta-framework'
+ x1aa = 'Pull CM repository with this automation recipe (CM script)'
+ x1b = 'Print CM help from the command line'
+ x2 = 'Customize and run this script from the command line with different variations and flags'
+ x3 = 'Run this script from Python'
+ x3a = 'Run this script via GUI'
+ x4 = 'Run this script via Docker (beta)'
+ md_script_readme += [
+ '',
+ '---',
+ '### '+x1,
+ '',
+ '#### '+x1a,
+ '',
+ '* [Install CM](https://access.cknowledge.org/playground/?action=install)',
+ '* [CM Getting Started Guide](https://github.com/mlcommons/ck/blob/master/docs/getting-started.md)',
+ '',
+ '#### '+x1aa,
+ '',
+ '```cm pull repo {}```'.format(repo_alias),
+ '',
+ '#### '+x1b,
+ '',
+ '```{}```'.format(cli_help_tags_alternative),
+ '',
+ '#### '+x2,
+ '',
+ '{}'.format(cli_all_tags),
+ '',
+ '{}'.format(cli_all_tags3),
+ '',
+ '*or*',
+ '',
+ '{}'.format(cli_all_tags_alternative),
+ '',
+ '{}'.format(cli_all_tags_alternative3),
+ '',
+# '3. {}'.format(cli_uid),
+ '']
+
+
+ x = ' and check the [Gettings Started Guide](https://github.com/mlcommons/ck/blob/dev/docs/getting-started.md) for more details.'
+ if len(variation_keys)>0:
+ md_script_readme += ['* *See the list of `variations` [here](#variations)'+x+'*',
+ ''
+ ]
+
+ if input_description and len(input_description)>0:
+ x = 'Input Flags'
+ md_script_readme.append('')
+ md_script_readme.append('#### '+x)
+ toc_readme.append(' '+x)
+
+ md_script_readme.append('')
+ key0 = ''
+ for key in input_description:
+ if key0=='': key0=key
+
+ value = input_description[key]
+ desc = value
+
+ if type(value) == dict:
+ desc = value['desc']
+
+ choices = value.get('choices', [])
+ if len(choices) > 0:
+ desc+=' {'+','.join(choices)+'}'
+
+ default = value.get('default','')
+ if default!='':
+ desc+=' (*'+str(default)+'*)'
+
+ md_script_readme.append('* --**{}**={}'.format(key,desc))
+
+ md_script_readme.append('')
+ md_script_readme.append('**Above CLI flags can be used in the Python CM API as follows:**')
+ md_script_readme.append('')
+
+ x = '```python\nr=cm.access({... , "'+key0+'":...}\n```'
+ md_script_readme.append(x)
+
+
+
+
+
+ md_script_readme += ['#### '+x3,
+ '',
+ '',
+ 'Click here to expand this section.
',
+ '',
+ '```python',
+ '',
+ 'import cmind',
+ '',
+ "r = cmind.access({'action':'run'",
+ " 'automation':'script',",
+ " 'tags':'{}'".format(','.join(tags)),
+ " 'out':'con',",
+ " ...",
+ " (other input keys for this script)",
+ " ...",
+ " })",
+ "",
+ "if r['return']>0:",
+ " print (r['error'])",
+ '',
+ '```',
+ '',
+ ' ',
+ '',
+
+ '',
+ '#### '+x3a,
+ '',
+ '```cmr "cm gui" --script="'+','.join(tags)+'"```',
+ '',
+ 'Use this [online GUI](https://cKnowledge.org/cm-gui/?tags={}) to generate CM CMD.'.format(','.join(tags)),
+ '',
+ '#### '+x4,
+ '',
+ '{}'.format(cli_all_tags_alternative_docker),
+ ''
+ ]
+ toc_readme.append(x1)
+ toc_readme.append(' '+x1a)
+ toc_readme.append(' '+x1b)
+ toc_readme.append(' '+x2)
+ toc_readme.append(' '+x3)
+ toc_readme.append(' '+x3a)
+ toc_readme.append(' '+x4)
+
+ x = 'Customization'
+ md_script_readme.append('___')
+ md_script_readme.append('### '+x)
+ md_script_readme.append('')
+ toc_readme.append(x)
+
+
+
+
+ if len(variation_keys)>0:
+# x = 'Variation groups'
+# md_script_readme.append('___')
+# md_script_readme.append('### '+x)
+# toc_readme.append(x)
+
+ variation_groups = {}
+ default_variations = []
+ variation_md = {}
+ variation_alias = {}
+
+ # Normally should not use anymore. Should use default:true inside individual variations.
+ default_variation = meta.get('default_variation','')
+
+ for variation_key in sorted(variation_keys):
+ variation = variations[variation_key]
+
+ alias = variation.get('alias','').strip()
+
+ if alias!='':
+ aliases = variation_alias.get(alias, [])
+ if variation_key not in aliases:
+ aliases.append(variation_key)
+ variation_alias[alias]=aliases
+
+ # Do not continue this loop if alias
+ continue
+
+ default = variation.get('default', False)
+
+ if not default:
+ # Check outdated
+ if default_variation == variation_key:
+ default = True
+
+ extra1 = ''
+ extra2 = ''
+ if default:
+ extra1 = '**'
+ extra2 = '** (default)'
+
+ default_variations.append(variation_key)
+
+
+ md_var = []
+
+ md_var.append('* {}`_{}`{}'.format(extra1, variation_key, extra2))
+
+ variation_md[variation_key] = md_var
+
+# md_script_readme+=md_var
+
+ group = variation.get('group','')
+
+ if variation_key.endswith('_'):
+ group = '*Internal group (variations should not be selected manually)*'
+ elif group == '':
+ group = '*No group (any variation can be selected)*'
+
+ if group not in variation_groups:
+ variation_groups[group]=[]
+
+ variation_groups[group].append(variation_key)
+
+
+ x = 'Variations'
+ md_script_readme.append('')
+ md_script_readme.append('#### '+x)
+ toc_readme.append(' '+x)
+
+ variation_groups_order = meta.get('variation_groups_order',[])
+ for variation in sorted(variation_groups):
+ if variation not in variation_groups_order:
+ variation_groups_order.append(variation)
+
+ for group_key in variation_groups_order:
+ md_script_readme.append('')
+
+ if not group_key.startswith('*'):
+ md_script_readme.append(' * Group "**{}**"'.format(group_key))
+ else:
+ md_script_readme.append(' * {}'.format(group_key))
+
+
+ md_script_readme += [
+ ' ',
+ ' Click here to expand this section.
',
+ ''
+ ]
+
+ for variation_key in sorted(variation_groups[group_key]):
+ variation = variations[variation_key]
+
+ xmd = variation_md[variation_key]
+
+ aliases = variation_alias.get(variation_key,[])
+ aliases2 = ['_'+v for v in aliases]
+
+ if len(aliases)>0:
+ xmd.append(' - Aliases: `{}`'.format(','.join(aliases2)))
+
+ if len(variation.get('env',{}))>0:
+ xmd.append(' - Environment variables:')
+ for key in variation['env']:
+ xmd.append(' - *{}*: `{}`'.format(key, variation['env'][key]))
+
+ xmd.append(' - Workflow:')
+
+ for dep in ['deps', 'prehook_deps', 'posthook_deps', 'post_deps']:
+ process_deps(self_module, variation, meta_url, xmd, dep, ' ', True, True)
+
+ for x in xmd:
+ md_script_readme.append(' '+x)
+
+ md_script_readme.append('')
+ md_script_readme.append(' ')
+ md_script_readme.append('')
+
+ # Check if has invalid_variation_combinations
+ vvc = meta.get('invalid_variation_combinations', [])
+ if len(vvc)>0:
+ x = 'Unsupported or invalid variation combinations'
+ md_script_readme.append('')
+ md_script_readme.append('#### '+x)
+ md_script_readme.append('')
+ md_script_readme.append('')
+ md_script_readme.append('')
+ toc_readme.append(' '+x)
+
+ for v in vvc:
+ vv = ['_'+x for x in v]
+ md_script_readme.append('* `'+','.join(vv)+'`')
+
+
+ if len(default_variations)>0:
+ md_script_readme.append('')
+ md_script_readme.append('#### Default variations')
+ md_script_readme.append('')
+
+ dv = ['_'+x for x in sorted(default_variations)]
+
+ md_script_readme.append('`{}`'.format(','.join(dv)))
+
+
+ # Check if has valid_variation_combinations
+ vvc = meta.get('valid_variation_combinations', [])
+ if len(vvc)>0:
+ x = 'Valid variation combinations checked by the community'
+ md_script_readme.append('')
+ md_script_readme.append('#### '+x)
+ md_script_readme.append('')
+ md_script_readme.append('')
+ md_script_readme.append('')
+ toc_readme.append(' '+x)
+
+ for v in vvc:
+ vv = ['_'+x for x in v]
+ md_script_readme.append('* `'+','.join(vv)+'`')
+
+
+
+
+
+ # Check input flags
+ if input_mapping and len(input_mapping)>0:
+ x = 'Script flags mapped to environment'
+ md_script_readme.append('')
+ md_script_readme.append('#### '+x)
+ toc_readme.append(' '+x)
+
+ md_script_readme.append('')
+ md_script_readme.append('Click here to expand this section.
')
+
+ md_script_readme.append('')
+ key0 = ''
+ for key in sorted(input_mapping):
+ if key0=='': key0=key
+ value = input_mapping[key]
+ md_script_readme.append('* `--{}=value` → `{}=value`'.format(key,value))
+
+ md_script_readme.append('')
+ md_script_readme.append('**Above CLI flags can be used in the Python CM API as follows:**')
+ md_script_readme.append('')
+
+ x = '```python\nr=cm.access({... , "'+key0+'":...}\n```'
+ md_script_readme.append(x)
+
+ md_script_readme.append('')
+ md_script_readme.append(' ')
+ md_script_readme.append('')
+
+
+ # Default environment
+ default_env = meta.get('default_env',{})
+
+ x = 'Default environment'
+# md_script_readme.append('___')
+ md_script_readme.append('#### '+x)
+ toc_readme.append(' '+x)
+
+ md_script_readme.append('')
+ md_script_readme.append('')
+ md_script_readme.append('Click here to expand this section.
')
+ md_script_readme.append('')
+ md_script_readme.append('These keys can be updated via `--env.KEY=VALUE` or `env` dictionary in `@input.json` or using script flags.')
+ md_script_readme.append('')
+
+ for key in default_env:
+ value = default_env[key]
+ md_script_readme.append('* {}: `{}`'.format(key,value))
+
+ md_script_readme.append('')
+ md_script_readme.append(' ')
+ md_script_readme.append('')
+
+
+
+
+
+
+
+ if len(version_keys)>0 or default_version!='':
+ x = 'Versions'
+# md_script_readme.append('___')
+ md_script_readme.append('#### '+x)
+ toc_readme.append(x)
+
+ if default_version!='':
+ md_script_readme.append('Default version: `{}`'.format(default_version))
+ md_script_readme.append('')
+
+ if len(version_keys)>0:
+ for version in version_keys:
+ md_script_readme.append('* `{}`'.format(version))
+
+
+
+ # Add workflow
+ x = 'Dependencies on other CM scripts'
+ md_script_readme += ['___',
+ '### '+x,
+ '']
+ toc_readme.append(x)
+
+# md_script_readme.append('')
+# md_script_readme.append('Click here to expand this section.
')
+
+ md_script_readme.append('')
+
+ # Check customize.py file
+ path_customize = os.path.join(path, 'customize.py')
+ found_customize = False
+ found_customize_preprocess = False
+ found_customize_postprocess = False
+ found_output_env = []
+
+ if os.path.isfile(path_customize):
+ found_customize = True
+
+ r = utils.load_txt(path_customize, split=True)
+ if r['return']>0: return r
+
+ customize = r['string']
+ customize_l = r['list']
+
+ if 'def preprocess(' in customize:
+ found_customize_preprocess = True
+
+ if 'def postprocess(' in customize:
+ found_customize_postprocess = True
+
+ # Ugly attempt to get output env
+ found_postprocess = False
+ for l in customize_l:
+# if not found_postprocess:
+# if 'def postprocess' in l:
+# found_postprocess = True
+# else:
+ j = l.find(' env[')
+ if j>=0:
+ j1 = l.find(']', j+4)
+ if j1>=0:
+ j2 = l.find('=',j1+1)
+ if j2>=0:
+ key2 = l[j+5:j1].strip()
+ key=key2[1:-1]
+
+ if key.startswith('CM_') and 'TMP' not in key and key not in found_output_env:
+ found_output_env.append(key)
+
+ process_deps(self_module, meta, meta_url, md_script_readme, 'deps')
+
+ x = ''
+ y = 'customize.py'
+ if found_customize_preprocess:
+ x = '***'
+ y = '['+y+']('+url+'/'+y+')'
+ md_script_readme.append((' 1. '+x+'Run "preprocess" function from {}'+x).format(y))
+
+ process_deps(self_module, meta, meta_url, md_script_readme, 'prehook_deps')
+
+ # Check scripts
+ files = os.listdir(path)
+ x = ''
+ y = []
+ for f in sorted(files):
+ x = '***'
+ if f.startswith('run') and (f.endswith('.sh') or f.endswith('.bat')):
+ f_url = url+'/'+f
+ y.append(' * [{}]({})'.format(f, f_url))
+
+ md_script_readme.append((' 1. '+x+'Run native script if exists'+x).format(y))
+ md_script_readme += y
+
+ process_deps(self_module, meta, meta_url, md_script_readme, 'posthook_deps')
+
+ x = ''
+ y = 'customize.py'
+ if found_customize_postprocess:
+ x = '***'
+ y = '['+y+']('+url+'/'+y+')'
+ md_script_readme.append((' 1. '+x+'Run "postrocess" function from {}'+x).format(y))
+
+ process_deps(self_module, meta, meta_url, md_script_readme, 'post_deps')
+ # md_script_readme.append(' ')
+ md_script_readme.append('')
+
+ # New environment
+ new_env_keys = meta.get('new_env_keys',[])
+
+ x = 'Script output'
+ md_script_readme.append('___')
+ md_script_readme.append('### '+x)
+ toc_readme.append(x)
+
+ md_script_readme.append(cli_all_tags_alternative_j)
+
+ x = 'New environment keys (filter)'
+ md_script_readme.append('#### '+x)
+ toc_readme.append(x)
+
+ md_script_readme.append('')
+ for key in sorted(new_env_keys):
+ md_script_readme.append('* `{}`'.format(key))
+
+ # Pass found_output_env through above filter
+ found_output_env_filtered = []
+
+ import fnmatch
+
+ for key in found_output_env:
+ add = False
+
+ for f in new_env_keys:
+ if fnmatch.fnmatch(key, f):
+ add = True
+ break
+
+ if add:
+ found_output_env_filtered.append(key)
+
+ x = 'New environment keys auto-detected from customize'
+ md_script_readme.append('#### '+x)
+ toc_readme.append(x)
+
+ md_script_readme.append('')
+ for key in sorted(found_output_env_filtered):
+ md_script_readme.append('* `{}`'.format(key))
+
+
+
+ # Add maintainers
+# x = 'Maintainers'
+# md_script_readme.append('___')
+# md_script_readme.append('### '+x)
+# md_script_readme.append('')
+# md_script_readme.append('* ' + public_taskforce)
+# toc_readme.append(x)
+
+ # Process TOC
+ toc_readme_string = '\n'
+ for x in toc_readme:
+ x2 = x
+ prefix = ''
+
+ if x.startswith(' '):
+ prefix = ' '
+ x2 = x[1:]
+
+ x2 = x2.lower().replace(' ','-').replace(',','')
+ toc_readme_string += prefix + '* [{}](#{})\n'.format(x, x2)
+
+ # Add to the total list
+ md += md_script
+
+ s = '\n'.join(md_script_readme)
+
+ s = s.replace('{{CM_README_EXTRA}}', cm_readme_extra)
+# s = s.replace('{{CM_SEE_README_EXTRA}}', cm_see_readme_extra)
+ s = s.replace('{{CM_README_TOC}}', toc_readme_string)
+
+ r = utils.save_txt(path_readme, s)
+ if r['return']>0: return r
+
+ # Add to Git (if in git)
+ os.chdir(path)
+ os.system('git add README.md')
+ os.chdir(cur_dir)
+
+
+ # Recreate TOC with categories
+ toc2 = []
+
+ for category in sorted(toc_category):#, key = lambda x: -toc_category_sort[x]):
+ toc2.append('### '+category)
+ toc2.append('')
+
+ for script in sorted(toc_category[category]):
+
+ meta = script_meta[script]
+
+ name = meta.get('name','')
+
+ url = urls[script]
+
+ x = '* [{}]({})'.format(script, url)
+ if name !='': x+=' *('+name+')*'
+
+ toc2.append(x)
+
+ toc2.append('')
+
+ toc_category_string = ''
+ for category in sorted(toc_category):
+ category_link = category.lower().replace(' ','-').replace('/','')
+ toc_category_string += '* [{}](#{})\n'.format(category, category_link)
+
+
+ # Load template
+ r = utils.load_txt(os.path.join(self_module.path, template_file))
+ if r['return']>0: return r
+
+ s = r['string']
+
+ s = s.replace('{{CM_TOC2}}', '\n'.join(toc2))
+ s = s.replace('{{CM_TOC}}', '\n'.join(toc))
+# s = s.replace('{{CM_MAIN}}', '\n'.join(md))
+ s = s.replace('{{CM_MAIN}}', '')
+ s = s.replace('{{CM_TOC_CATEGORIES}}', toc_category_string)
+
+ # Output
+ output_dir = i.get('output_dir','')
+
+ if output_dir == '': output_dir = '..'
+
+ output_file = os.path.join(output_dir, list_file)
+
+ r = utils.save_txt(output_file, s)
+ if r['return']>0: return r
+
+ return {'return':0}
+
+
+
+# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+def update_path_for_docker(path, mounts, force_path_target=''):
+
+ path_orig = ''
+ path_target = ''
+
+ if path!='': # and (os.path.isfile(path) or os.path.isdir(path)):
+ path = os.path.abspath(path)
+
+ path_target = path
+ path_orig = path
+
+ if os.name == 'nt':
+ from pathlib import PureWindowsPath, PurePosixPath
+
+ x = PureWindowsPath(path_orig)
+ path_target = str(PurePosixPath('/', *x.parts[1:]))
+
+ if not path_target.startswith('/'): path_target='/'+path_target
+
+ path_target='/cm-mount'+path_target if force_path_target=='' else force_path_target
+
+ # If file, mount directory
+ if os.path.isfile(path) or not os.path.isdir(path):
+ x = os.path.dirname(path_orig) + ':' + os.path.dirname(path_target)
+ else:
+ x = path_orig + ':' + path_target
+
+ # CHeck if no duplicates
+ to_add = True
+ for y in mounts:
+ if y.lower()==x.lower():
+ to_add = False
+ break
+
+ if to_add:
+ mounts.append(x)
+
+
+ return (path_orig, path_target)
+
+############################################################
+def process_inputs(i):
+
+ import copy
+
+ i_run_cmd_arc = i['run_cmd_arc']
+ docker_settings = i['docker_settings']
+ mounts = i['mounts']
+
+ # Check if need to update/map/mount inputs and env
+ i_run_cmd = copy.deepcopy(i_run_cmd_arc)
+
+
+ def get_value_using_key_with_dots(d, k):
+ v = None
+ j = k.find('.')
+ if j>=0:
+ k1 = k[:j]
+ k2 = k[j+1:]
+
+ if k1 in d:
+ v = d[k1]
+
+ if '.' in k2:
+ v, d, k = get_value_using_key_with_dots(v, k2)
+ else:
+ d = v
+ k = k2
+ if type(v)==dict:
+ v = v.get(k2)
+ else:
+ v = None
+ else:
+ if k == '':
+ v = d
+ else:
+ v = d.get(k)
+
+ return v, d, k
+
+ docker_input_paths = docker_settings.get('input_paths',[])
+ if len(i_run_cmd)>0:
+ for k in docker_input_paths:
+ v2, i_run_cmd2, k2 = get_value_using_key_with_dots(i_run_cmd, k)
+
+ if v2!=None:
+ v=i_run_cmd2[k2]
+
+ path_orig, path_target = update_path_for_docker(v, mounts)
+
+ if path_target!='':
+ i_run_cmd2[k2] = path_target
+
+ return {'return':0, 'run_cmd':i_run_cmd}
+
+
+############################################################
+def regenerate_script_cmd(i):
+
+ script_uid = i['script_uid']
+ script_alias = i['script_alias']
+ tags = i['tags']
+ docker_settings = i['docker_settings']
+ fake_run = i.get('fake_run', False)
+
+ i_run_cmd = i['run_cmd']
+
+ docker_run_cmd_prefix = i['docker_run_cmd_prefix']
+
+ # Regenerate command from dictionary input
+ run_cmd = 'cm run script'
+
+ x = ''
+
+ # Check if there are some tags without variation
+ requested_tags = i_run_cmd.get('tags', [])
+
+ tags_without_variation = False
+ for t in requested_tags:
+ if not t.startswith('_'):
+ tags_without_variation = True
+ break
+
+ if not tags_without_variation:
+ # If no tags without variation, add script alias and UID explicitly
+ if script_uid!='': x=script_uid
+ if script_alias!='':
+ if x!='': x=','+x
+ x = script_alias+x
+
+ if x!='':
+ run_cmd += ' ' + x + ' '
+
+
+ skip_input_for_fake_run = docker_settings.get('skip_input_for_fake_run', [])
+ add_quotes_to_keys = docker_settings.get('add_quotes_to_keys', [])
+
+
+ def rebuild_flags(i_run_cmd, fake_run, skip_input_for_fake_run, add_quotes_to_keys, key_prefix):
+
+ run_cmd = ''
+
+ keys = list(i_run_cmd.keys())
+
+ if 'tags' in keys:
+ # Move tags first
+ tags_position = keys.index('tags')
+ del(keys[tags_position])
+ keys = ['tags']+keys
+
+ for k in keys:
+ # Assemble long key if dictionary
+ long_key = key_prefix
+ if long_key!='': long_key+='.'
+ long_key+=k
+
+ if fake_run and long_key in skip_input_for_fake_run:
+ continue
+
+ v = i_run_cmd[k]
+
+ q = '\\"' if long_key in add_quotes_to_keys else ''
+
+ if type(v)==dict:
+ run_cmd += rebuild_flags(v, fake_run, skip_input_for_fake_run, add_quotes_to_keys, long_key)
+ elif type(v)==list:
+ x = ''
+ for vv in v:
+ if x != '': x+=','
+ x+=q+str(vv)+q
+ run_cmd+=' --'+long_key+',=' + x
+ else:
+ run_cmd+=' --'+long_key+'='+q+str(v)+q
+
+ return run_cmd
+
+ run_cmd += rebuild_flags(i_run_cmd, fake_run, skip_input_for_fake_run, add_quotes_to_keys, '')
+
+ run_cmd = docker_run_cmd_prefix + ' && ' + run_cmd if docker_run_cmd_prefix!='' else run_cmd
+
+ return {'return':0, 'run_cmd_string':run_cmd}
+
+
+
+############################################################
+def aux_search(i):
+
+ self_module = i['self_module']
+
+ inp = i['input']
+
+ repos = inp.get('repos','')
+# Grigori Fursin remarked on 20240412 because this line prevents
+# from searching for scripts in other public or private repositories.
+# Not sure why we enforce just 2 repositories
+#
+# if repos == '': repos='internal,a4705959af8e447a'
+
+ parsed_artifact = inp.get('parsed_artifact',[])
+
+ if len(parsed_artifact)<1:
+ parsed_artifact = [('',''), ('','')]
+ elif len(parsed_artifact)<2:
+ parsed_artifact.append(('',''))
+ else:
+ repos = parsed_artifact[1][0]
+
+ list_of_repos = repos.split(',') if ',' in repos else [repos]
+
+ ii = utils.sub_input(inp, self_module.cmind.cfg['artifact_keys'] + ['tags'])
+
+ ii['out'] = None
+
+ # Search for automations in repos
+ lst = []
+ for repo in list_of_repos:
+ parsed_artifact[1] = ('',repo) if utils.is_cm_uid(repo) else (repo,'')
+ ii['parsed_artifact'] = parsed_artifact
+ r = self_module.search(ii)
+ if r['return']>0: return r
+ lst += r['list']
+
+ return {'return':0, 'list':lst}
+
+
+############################################################
+def dockerfile(i):
+ """
+ Add CM automation.
+
+ Args:
+ (CM input dict):
+
+ (out) (str): if 'con', output to console
+
+ parsed_artifact (list): prepared in CM CLI or CM access function
+ [ (artifact alias, artifact UID) ] or
+ [ (artifact alias, artifact UID), (artifact repo alias, artifact repo UID) ]
+
+ (repos) (str): list of repositories to search for automations (internal & mlcommons@ck by default)
+
+ (output_dir) (str): output directory (./ by default)
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ """
+
+ import copy
+
+ # Check simplified CMD: cm docker script "python app image-classification onnx"
+ # If artifact has spaces, treat them as tags!
+ self_module = i['self_module']
+ self_module.cmind.access({'action':'detect_tags_in_artifact', 'automation':'utils', 'input':i})
+
+ # Prepare "clean" input to replicate command
+ r = self_module.cmind.access({'action':'prune_input', 'automation':'utils', 'input':i, 'extra_keys_starts_with':['docker_']})
+ i_run_cmd_arc = r['new_input']
+
+ cur_dir = os.getcwd()
+
+ quiet = i.get('quiet', False)
+
+ console = i.get('out') == 'con'
+
+ cm_repo = i.get('docker_cm_repo', 'mlcommons@ck')
+ cm_repo_flags = i.get('docker_cm_repo_flags', '')
+
+ # Search for script(s)
+ r = aux_search({'self_module': self_module, 'input': i})
+ if r['return']>0: return r
+
+ lst = r['list']
+
+ if len(lst)==0:
+ return {'return':1, 'error':'no scripts were found'}
+
+
+
+
+# if i.get('cmd'):
+# run_cmd = "cm run script " + " ".join( a for a in i['cmd'] if not a.startswith('--docker_') )
+# elif i.get('artifact'):
+# run_cmd = "cm run script "+i['artifact']
+# elif i.get('tags'):
+# run_cmd = "cm run script \""+" "+" ".join(i['tags']) + "\""
+# else:
+# run_cmd = ""
+#
+# run_cmd = i.get('docker_run_cmd_prefix') + ' && ' + run_cmd if i.get('docker_run_cmd_prefix') else run_cmd
+
+
+
+
+
+ env=i.get('env', {})
+ state = i.get('state', {})
+ script_automation = i['self_module']
+
+ dockerfile_env=i.get('dockerfile_env', {})
+ dockerfile_env['CM_RUN_STATE_DOCKER'] = True
+
+ tags_split = i.get('tags', '').split(",")
+ variation_tags = [ t[1:] for t in tags_split if t.startswith("_") ]
+
+ for artifact in sorted(lst, key = lambda x: x.meta.get('alias','')):
+
+ meta = artifact.meta
+
+ script_path = artifact.path
+
+ tags = meta.get("tags", [])
+ tag_string=",".join(tags)
+
+ script_alias = meta.get('alias', '')
+ script_uid = meta.get('uid', '')
+
+
+ variations = meta.get('variations', {})
+ docker_settings = meta.get('docker', {})
+ state['docker'] = docker_settings
+
+ r = script_automation._update_state_from_variations(i, meta, variation_tags, variations, env, state, deps = [], post_deps = [], prehook_deps = [], posthook_deps = [], new_env_keys_from_meta = [], new_state_keys_from_meta = [], add_deps_recursive = {}, run_state = {}, recursion_spaces='', verbose = False)
+ if r['return'] > 0:
+ return r
+
+ docker_settings = state['docker']
+
+ if not docker_settings.get('run', True):
+ print("docker.run set to False in _cm.json")
+ continue
+ '''run_config_path = os.path.join(script_path,'run_config.yml')
+ if not os.path.exists(run_config_path):
+ print("No run_config.yml file present in {}".format(script_path))
+ continue
+ import yaml
+ with open(run_config_path, 'r') as run_config_file:
+ run_config = yaml.safe_load(run_config_file)
+ docker_settings = run_config.get('docker')
+ if not docker_settings or not docker_settings.get('build') or not run_config.get('run_with_default_inputs'):
+ print("Run config is not configured for docker run in {}".format(run_config_path))
+ continue
+ '''
+
+ # Check if need to update/map/mount inputs and env
+ r = process_inputs({'run_cmd_arc': i_run_cmd_arc,
+ 'docker_settings': docker_settings,
+ 'mounts':[]})
+ if r['return']>0: return r
+
+ i_run_cmd = r['run_cmd']
+
+ docker_run_cmd_prefix = i.get('docker_run_cmd_prefix', docker_settings.get('run_cmd_prefix', ''))
+
+ r = regenerate_script_cmd({'script_uid':script_uid,
+ 'script_alias':script_alias,
+ 'run_cmd':i_run_cmd,
+ 'tags':tags,
+ 'fake_run':True,
+ 'docker_settings':docker_settings,
+ 'docker_run_cmd_prefix':docker_run_cmd_prefix})
+ if r['return']>0: return r
+
+ run_cmd = r['run_cmd_string']
+
+
+ docker_base_image = i.get('docker_base_image', docker_settings.get('base_image'))
+ docker_os = i.get('docker_os', docker_settings.get('docker_os', 'ubuntu'))
+ docker_os_version = i.get('docker_os_version', docker_settings.get('docker_os_version', '22.04'))
+
+ docker_cm_repos = i.get('docker_cm_repos', docker_settings.get('cm_repos', ''))
+
+ docker_extra_sys_deps = i.get('docker_extra_sys_deps', '')
+
+ if not docker_base_image:
+ dockerfilename_suffix = docker_os +'_'+docker_os_version
+ else:
+ if os.name == 'nt':
+ dockerfilename_suffix = docker_base_image.replace('/', '-').replace(':','-')
+ else:
+ dockerfilename_suffix = docker_base_image.split("/")
+ dockerfilename_suffix = dockerfilename_suffix[len(dockerfilename_suffix) - 1]
+
+ fake_run_deps = i.get('fake_run_deps', docker_settings.get('fake_run_deps', False))
+ docker_run_final_cmds = docker_settings.get('docker_run_final_cmds', [])
+
+ r = check_gh_token(i, docker_settings, quiet)
+ if r['return'] >0 : return r
+ gh_token = r['gh_token']
+ i['docker_gh_token'] = gh_token # To pass to docker function if needed
+
+ if i.get('docker_real_run', docker_settings.get('docker_real_run',False)):
+ fake_run_option = " "
+ fake_run_deps = False
+ else:
+ fake_run_option = " --fake_run"
+
+ docker_copy_files = i.get('docker_copy_files', docker_settings.get('copy_files', []))
+
+ env['CM_DOCKER_PRE_RUN_COMMANDS'] = docker_run_final_cmds
+
+ docker_path = i.get('docker_path', '').strip()
+ if docker_path == '':
+ docker_path = script_path
+
+ dockerfile_path = os.path.join(docker_path, 'dockerfiles', dockerfilename_suffix +'.Dockerfile')
+
+ if i.get('print_deps'):
+ cm_input = {'action': 'run',
+ 'automation': 'script',
+ 'tags': f'{tag_string}',
+ 'print_deps': True,
+ 'quiet': True,
+ 'silent': True,
+ 'fake_run': True,
+ 'fake_deps': True
+ }
+ r = self_module.cmind.access(cm_input)
+ if r['return'] > 0:
+ return r
+ print_deps = r['new_state']['print_deps']
+ comments = [ "#RUN " + dep for dep in print_deps ]
+ comments.append("")
+ comments.append("# Run CM workflow")
+ else:
+ comments = []
+
+ cm_docker_input = {'action': 'run',
+ 'automation': 'script',
+ 'tags': 'build,dockerfile',
+ 'cm_repo': cm_repo,
+ 'cm_repo_flags': cm_repo_flags,
+ 'docker_base_image': docker_base_image,
+ 'docker_os': docker_os,
+ 'docker_os_version': docker_os_version,
+ 'file_path': dockerfile_path,
+ 'fake_run_option': fake_run_option,
+ 'comments': comments,
+ 'run_cmd': f'{run_cmd} --quiet',
+ 'script_tags': f'{tag_string}',
+ 'copy_files': docker_copy_files,
+ 'quiet': True,
+ 'env': env,
+ 'dockerfile_env': dockerfile_env,
+ 'v': i.get('v', False),
+ 'fake_docker_deps': fake_run_deps,
+ 'print_deps': True,
+ 'real_run': True
+ }
+
+ if docker_cm_repos != '':
+ cm_docker_input['cm_repos'] = docker_cm_repos
+
+ if gh_token != '':
+ cm_docker_input['gh_token'] = gh_token
+
+ if docker_extra_sys_deps != '':
+ cm_docker_input['extra_sys_deps'] = docker_extra_sys_deps
+
+ r = self_module.cmind.access(cm_docker_input)
+ if r['return'] > 0:
+ return r
+
+ print ('')
+ print ("Dockerfile generated at " + dockerfile_path)
+
+ return {'return':0}
+
+def get_container_path(value):
+ path_split = value.split(os.sep)
+ if len(path_split) == 1:
+ return value
+
+ new_value = ''
+ if "cache" in path_split and "local" in path_split:
+ new_path_split = [ "", "home", "cmuser" ]
+ repo_entry_index = path_split.index("local")
+ new_path_split += path_split[repo_entry_index:]
+ return "/".join(new_path_split)
+
+ return value
+
+
+############################################################
+def docker(i):
+ """
+ CM automation to run CM scripts via Docker
+
+ Args:
+ (CM input dict):
+
+ (out) (str): if 'con', output to console
+
+ (docker_path) (str): where to create or find Dockerfile
+ (docker_gh_token) (str): GitHub token for private repositories
+ (docker_save_script) (str): if !='' name of script to save docker command
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ """
+
+ import copy
+ import re
+
+ quiet = i.get('quiet', False)
+
+ detached = i.get('docker_detached', '')
+ if detached=='':
+ detached = i.get('docker_dt', '')
+ if detached=='':
+ detached='no'
+
+ interactive = i.get('docker_interactive', '')
+ if interactive == '':
+ interactive = i.get('docker_it', '')
+
+ verbose = i.get('v', False)
+ show_time = i.get('show_time', False)
+
+ # Check simplified CMD: cm docker script "python app image-classification onnx"
+ # If artifact has spaces, treat them as tags!
+ self_module = i['self_module']
+ self_module.cmind.access({'action':'detect_tags_in_artifact', 'automation':'utils', 'input':i})
+
+ # Prepare "clean" input to replicate command
+ r = self_module.cmind.access({'action':'prune_input', 'automation':'utils', 'input':i, 'extra_keys_starts_with':['docker_']})
+ i_run_cmd_arc = r['new_input']
+
+ noregenerate_docker_file = i.get('docker_noregenerate', False)
+
+ if not noregenerate_docker_file:
+ r = utils.call_internal_module(self_module, __file__, 'module_misc', 'dockerfile', i)
+ if r['return']>0: return r
+
+ cur_dir = os.getcwd()
+
+ console = i.get('out') == 'con'
+
+ # Search for script(s)
+ r = aux_search({'self_module': self_module, 'input': i})
+ if r['return']>0: return r
+
+ lst = r['list']
+
+ if len(lst)==0:
+ return {'return':1, 'error':'no scripts were found'}
+
+ env=i.get('env', {})
+ env['CM_RUN_STATE_DOCKER'] = False
+ script_automation = i['self_module']
+ state = i.get('state', {})
+
+ tags_split = i.get('tags', '').split(",")
+ variation_tags = [ t[1:] for t in tags_split if t.startswith("_") ]
+
+ docker_cache = i.get('docker_cache', "yes")
+ if docker_cache in ["no", False, "False" ]:
+ if 'CM_DOCKER_CACHE' not in env:
+ env['CM_DOCKER_CACHE'] = docker_cache
+
+ image_repo = i.get('docker_image_repo','')
+ if image_repo == '':
+ image_repo = 'cknowledge'
+
+ for artifact in sorted(lst, key = lambda x: x.meta.get('alias','')):
+
+ meta = artifact.meta
+
+ if i.get('help',False):
+ return utils.call_internal_module(self_module, __file__, 'module_help', 'print_help', {'meta':meta, 'path':artifact.path})
+
+ script_path = artifact.path
+
+ tags = meta.get("tags", [])
+ tag_string=",".join(tags)
+
+ script_alias = meta.get('alias', '')
+ script_uid = meta.get('uid', '')
+
+
+ mounts = copy.deepcopy(i.get('docker_mounts', []))
+
+ '''run_config_path = os.path.join(script_path,'run_config.yml')
+ if not os.path.exists(run_config_path):
+ print("No run_config.yml file present in {}".format(script_path))
+ continue
+ import yaml
+ with open(run_config_path, 'r') as run_config_file:
+ run_config = yaml.safe_load(run_config_file)
+ '''
+
+ variations = meta.get('variations', {})
+ docker_settings = meta.get('docker', {})
+ state['docker'] = docker_settings
+
+ r = script_automation._update_state_from_variations(i, meta, variation_tags, variations, env, state, deps = [], post_deps = [], prehook_deps = [], posthook_deps = [], new_env_keys_from_meta = [], new_state_keys_from_meta = [], add_deps_recursive = {}, run_state = {}, recursion_spaces='', verbose = False)
+ if r['return'] > 0:
+ return r
+
+ docker_settings = state['docker']
+
+ if not docker_settings.get('run', True):
+ print("docker.run set to False in _cm.json")
+ continue
+ '''
+ if not docker_settings or not docker_settings.get('build') or not run_config.get('run_with_default_inputs'):
+ print("Run config is not configured for docker run in {}".format(run_config_path))
+ continue
+ '''
+
+ # Check if need to update/map/mount inputs and env
+ r = process_inputs({'run_cmd_arc': i_run_cmd_arc,
+ 'docker_settings': docker_settings,
+ 'mounts':mounts})
+ if r['return']>0: return r
+
+ i_run_cmd = r['run_cmd']
+
+ # Check if need to mount home directory
+ current_path_target = '/cm-mount/current'
+ if docker_settings.get('mount_current_dir','')=='yes':
+ update_path_for_docker('.', mounts, force_path_target=current_path_target)
+
+
+ _os = i.get('docker_os', docker_settings.get('docker_os', 'ubuntu'))
+ version = i.get('docker_os_version', docker_settings.get('docker_os_version', '22.04'))
+
+ deps = docker_settings.get('deps', [])
+ if deps:
+ # Todo: Support state, const and add_deps_recursive
+ run_state = {'deps':[], 'fake_deps':[], 'parent': None}
+ run_state['script_id'] = script_alias + "," + script_uid
+ run_state['script_variation_tags'] = variation_tags
+ r = script_automation._run_deps(deps, [], env, {}, {}, {}, {}, '', {}, '', False, '', verbose, show_time, ' ', run_state)
+ if r['return'] > 0:
+ return r
+
+ for key in docker_settings.get('mounts', []):
+ mounts.append(key)
+
+ # Updating environment variables from CM input based on input_mapping from meta
+ input_mapping = meta.get('input_mapping', {})
+
+ for c_input in input_mapping:
+ if c_input in i:
+ env[input_mapping[c_input]] = i[c_input]
+
+ # Updating environment variables from CM input based on docker_input_mapping from meta
+
+ docker_input_mapping = docker_settings.get('docker_input_mapping', {})
+
+ for c_input in docker_input_mapping:
+ if c_input in i:
+ env[docker_input_mapping[c_input]] = i[c_input]
+
+ container_env_string = '' # env keys corresponding to container mounts are explicitly passed to the container run cmd
+ for index in range(len(mounts)):
+ mount = mounts[index]
+
+ # Since windows may have 2 :, we search from the right
+ j = mount.rfind(':')
+ if j>0:
+ mount_parts = [mount[:j], mount[j+1:]]
+ else:
+ return {'return':1, 'error': 'Can\'t find separator : in a mount string: {}'.format(mount)}
+
+# mount_parts = mount.split(":")
+# if len(mount_parts) != 2:
+# return {'return': 1, 'error': f'Invalid mount specified in docker settings'}
+
+ host_mount = mount_parts[0]
+ new_host_mount = host_mount
+ container_mount = mount_parts[1]
+ new_container_mount = container_mount
+
+ tmp_values = re.findall(r'\${{ (.*?) }}', str(host_mount))
+ skip = False
+ if tmp_values:
+ for tmp_value in tmp_values:
+ if tmp_value in env:
+ new_host_mount = env[tmp_value]
+ else:# we skip those mounts
+ mounts[index] = None
+ skip = True
+ break
+
+ tmp_values = re.findall(r'\${{ (.*?) }}', str(container_mount))
+ if tmp_values:
+ for tmp_value in tmp_values:
+ if tmp_value in env:
+ new_container_mount = get_container_path(env[tmp_value])
+ container_env_string += " --env.{}={} ".format(tmp_value, new_container_mount)
+ else:# we skip those mounts
+ mounts[index] = None
+ skip = True
+ break
+
+ if skip:
+ continue
+ mounts[index] = new_host_mount+":"+new_container_mount
+
+ mounts = list(filter(lambda item: item is not None, mounts))
+
+ mount_string = "" if len(mounts)==0 else ",".join(mounts)
+
+ #check for proxy settings and pass onto the docker
+ proxy_keys = [ "ftp_proxy", "FTP_PROXY", "http_proxy", "HTTP_PROXY", "https_proxy", "HTTPS_PROXY", "no_proxy", "NO_PROXY", "socks_proxy", "SOCKS_PROXY", "GH_TOKEN" ]
+
+ if env.get('+ CM_DOCKER_BUILD_ARGS', []) == []:
+ env['+ CM_DOCKER_BUILD_ARGS'] = []
+
+ for key in proxy_keys:
+ if os.environ.get(key, '') != '':
+ value = os.environ[key]
+ container_env_string += " --env.{}={} ".format(key, value)
+ env['+ CM_DOCKER_BUILD_ARGS'].append("{}={}".format(key, value))
+
+ docker_use_host_group_id = i.get('docker_use_host_group_id', docker_settings.get('use_host_group_id'))
+ if docker_use_host_group_id and os.name != 'nt':
+ env['+ CM_DOCKER_BUILD_ARGS'].append("{}={}".format('CM_ADD_DOCKER_GROUP_ID', '\\"-g $(id -g $USER) -o\\"'))
+
+ docker_base_image = i.get('docker_base_image', docker_settings.get('base_image'))
+ docker_os = i.get('docker_os', docker_settings.get('docker_os', 'ubuntu'))
+ docker_os_version = i.get('docker_os_version', docker_settings.get('docker_os_version', '22.04'))
+
+ if not docker_base_image:
+ dockerfilename_suffix = docker_os +'_'+docker_os_version
+ else:
+ if os.name == 'nt':
+ dockerfilename_suffix = docker_base_image.replace('/', '-').replace(':','-')
+ else:
+ dockerfilename_suffix = docker_base_image.split("/")
+ dockerfilename_suffix = dockerfilename_suffix[len(dockerfilename_suffix) - 1]
+
+
+ cm_repo=i.get('docker_cm_repo', 'mlcommons@ck')
+
+ docker_path = i.get('docker_path', '').strip()
+ if docker_path == '':
+ docker_path = script_path
+
+ dockerfile_path = os.path.join(docker_path, 'dockerfiles', dockerfilename_suffix +'.Dockerfile')
+
+ docker_skip_run_cmd = i.get('docker_skip_run_cmd', docker_settings.get('skip_run_cmd', False)) #skips docker run cmd and gives an interactive shell to the user
+
+ docker_pre_run_cmds = i.get('docker_pre_run_cmds', []) + docker_settings.get('pre_run_cmds', [])
+
+ docker_run_cmd_prefix = i.get('docker_run_cmd_prefix', docker_settings.get('run_cmd_prefix', ''))
+
+ all_gpus = i.get('docker_all_gpus', docker_settings.get('all_gpus'))
+
+ device = i.get('docker_device', docker_settings.get('device'))
+
+ r = check_gh_token(i, docker_settings, quiet)
+ if r['return'] >0 : return r
+ gh_token = r['gh_token']
+
+
+ port_maps = i.get('docker_port_maps', docker_settings.get('port_maps', []))
+
+ shm_size = i.get('docker_shm_size', docker_settings.get('shm_size', ''))
+
+ extra_run_args = i.get('docker_extra_run_args', docker_settings.get('extra_run_args', ''))
+
+ if detached == '':
+ detached = docker_settings.get('detached', '')
+
+ if interactive == '':
+ interactive = docker_settings.get('interactive', '')
+
+# # Regenerate run_cmd
+# if i.get('cmd'):
+# run_cmd = "cm run script " + " ".join( a for a in i['cmd'] if not a.startswith('--docker_') )
+# elif i.get('artifact'):
+# run_cmd = "cm run script "+i['artifact']
+# elif i.get('tags'):
+# run_cmd = "cm run script \""+" "+" ".join(i['tags']) + "\""
+# else:
+# run_cmd = ""
+
+
+
+ r = regenerate_script_cmd({'script_uid':script_uid,
+ 'script_alias':script_alias,
+ 'tags':tags,
+ 'run_cmd':i_run_cmd,
+ 'docker_settings':docker_settings,
+ 'docker_run_cmd_prefix':i.get('docker_run_cmd_prefix','')})
+ if r['return']>0: return r
+
+ run_cmd = r['run_cmd_string'] + ' ' + container_env_string + ' --docker_run_deps '
+
+ env['CM_RUN_STATE_DOCKER'] = True
+
+ if docker_settings.get('mount_current_dir','')=='yes':
+ run_cmd = 'cd '+current_path_target+' && '+run_cmd
+
+ final_run_cmd = run_cmd if docker_skip_run_cmd not in [ 'yes', True, 'True' ] else 'cm version'
+
+ print ('')
+ print ('CM command line regenerated to be used inside Docker:')
+ print ('')
+ print (final_run_cmd)
+ print ('')
+
+
+ cm_docker_input = {'action': 'run',
+ 'automation': 'script',
+ 'tags': 'run,docker,container',
+ 'recreate': 'yes',
+ 'docker_base_image': docker_base_image,
+ 'docker_os': docker_os,
+ 'docker_os_version': docker_os_version,
+ 'cm_repo': cm_repo,
+ 'env': env,
+ 'image_repo': image_repo,
+ 'interactive': interactive,
+ 'mounts': mounts,
+ 'image_name': 'cm-script-'+script_alias,
+# 'image_tag': script_alias,
+ 'detached': detached,
+ 'script_tags': f'{tag_string}',
+ 'run_cmd': final_run_cmd,
+ 'v': i.get('v', False),
+ 'quiet': True,
+ 'pre_run_cmds': docker_pre_run_cmds,
+ 'real_run': True,
+ 'add_deps_recursive': {
+ 'build-docker-image': {
+ 'dockerfile': dockerfile_path
+ }
+ }
+ }
+
+ if all_gpus:
+ cm_docker_input['all_gpus'] = True
+
+ if device:
+ cm_docker_input['device'] = device
+
+ if gh_token != '':
+ cm_docker_input['gh_token'] = gh_token
+
+ if port_maps:
+ cm_docker_input['port_maps'] = port_maps
+
+ if shm_size != '':
+ cm_docker_input['shm_size'] = shm_size
+
+ if extra_run_args != '':
+ cm_docker_input['extra_run_args'] = extra_run_args
+
+ if i.get('docker_save_script', ''):
+ cm_docker_input['save_script'] = i['docker_save_script']
+
+ print ('')
+
+ r = self_module.cmind.access(cm_docker_input)
+ if r['return'] > 0:
+ return r
+
+
+ return {'return':0}
+
+############################################################
+def check_gh_token(i, docker_settings, quiet):
+ gh_token = i.get('docker_gh_token', '')
+
+ if docker_settings.get('gh_token_required', False) and gh_token == '':
+ rx = {'return':1, 'error':'GH token is required but not provided. Use --docker_gh_token to set it'}
+
+ if quiet:
+ return rx
+
+ print ('')
+ gh_token = input ('Enter GitHub token to access private CM repositories required for this CM script: ')
+
+ if gh_token == '':
+ return rx
+
+ return {'return':0, 'gh_token': gh_token}
diff --git a/automation/script/template-ae-python/README-extra.md b/automation/script/template-ae-python/README-extra.md
new file mode 100644
index 0000000000..05e53dc1a0
--- /dev/null
+++ b/automation/script/template-ae-python/README-extra.md
@@ -0,0 +1,2 @@
+# CM script to run and reproduce experiments
+
diff --git a/automation/script/template-ae-python/_cm.yaml b/automation/script/template-ae-python/_cm.yaml
new file mode 100644
index 0000000000..8019b3647e
--- /dev/null
+++ b/automation/script/template-ae-python/_cm.yaml
@@ -0,0 +1,38 @@
+cache: false
+
+deps:
+ # Detect host OS features
+ - tags: detect,os
+
+ # Detect/install python
+ - tags: get,python
+ names:
+ - python
+ - python3
+
+script_name: run
+
+input_mapping:
+ experiment: CM_EXPERIMENT
+
+default_env:
+ CM_EXPERIMENT: '1'
+
+variations:
+ install_deps:
+ script_name: install_deps
+
+ run:
+ script_name: run
+
+ reproduce:
+ script_name: reproduce
+
+ plot:
+ script_name: plot
+
+ analyze:
+ script_name: analyze
+
+ validate:
+ script_name: validate
diff --git a/automation/script/template-ae-python/analyze.bat b/automation/script/template-ae-python/analyze.bat
new file mode 100644
index 0000000000..7e786771ae
--- /dev/null
+++ b/automation/script/template-ae-python/analyze.bat
@@ -0,0 +1,12 @@
+@echo off
+
+set CUR_DIR=%cd%
+
+echo.
+echo Current execution path: %CUR_DIR%
+echo Path to script: %CM_TMP_CURRENT_SCRIPT_PATH%
+echo ENV CM_EXPERIMENT: %CM_EXPERIMENT%
+
+rem echo.
+rem %CM_PYTHON_BIN_WITH_PATH% %CM_TMP_CURRENT_SCRIPT_PATH%\main.py
+rem IF %ERRORLEVEL% NEQ 0 EXIT %ERRORLEVEL%
diff --git a/automation/script/template-ae-python/analyze.sh b/automation/script/template-ae-python/analyze.sh
new file mode 100644
index 0000000000..630c3db3dd
--- /dev/null
+++ b/automation/script/template-ae-python/analyze.sh
@@ -0,0 +1,12 @@
+#!/bin/bash
+
+CUR_DIR=${PWD}
+
+echo ""
+echo "Current execution path: ${CUR_DIR}"
+echo "Path to script: ${CM_TMP_CURRENT_SCRIPT_PATH}"
+echo "ENV CM_EXPERIMENT: ${CM_EXPERIMENT}"
+
+#echo ""
+#${CM_PYTHON_BIN_WITH_PATH} ${CM_TMP_CURRENT_SCRIPT_PATH}/main.py
+#test $? -eq 0 || exit 1
diff --git a/automation/script/template-ae-python/customize.py b/automation/script/template-ae-python/customize.py
new file mode 100644
index 0000000000..d12f9b3e1d
--- /dev/null
+++ b/automation/script/template-ae-python/customize.py
@@ -0,0 +1,22 @@
+from cmind import utils
+import os
+
+def preprocess(i):
+
+ os_info = i['os_info']
+
+ env = i['env']
+
+ meta = i['meta']
+
+ automation = i['automation']
+
+ quiet = (env.get('CM_QUIET', False) == 'yes')
+
+ return {'return':0}
+
+def postprocess(i):
+
+ env = i['env']
+
+ return {'return':0}
diff --git a/automation/script/template-ae-python/install_deps.bat b/automation/script/template-ae-python/install_deps.bat
new file mode 100644
index 0000000000..47f7e7ce26
--- /dev/null
+++ b/automation/script/template-ae-python/install_deps.bat
@@ -0,0 +1,18 @@
+@echo off
+
+set CUR_DIR=%cd%
+
+echo.
+echo Current execution path: %CUR_DIR%
+echo Path to script: %CM_TMP_CURRENT_SCRIPT_PATH%
+echo ENV CM_EXPERIMENT: %CM_EXPERIMENT%
+
+if exist "%CM_TMP_CURRENT_SCRIPT_PATH%\requirements.txt" (
+
+ echo.
+ echo Installing requirements.txt ...
+ echo.
+
+ %CM_PYTHON_BIN_WITH_PATH% -m pip install -r %CM_TMP_CURRENT_SCRIPT_PATH%\requirements.txt
+ IF %ERRORLEVEL% NEQ 0 EXIT %ERRORLEVEL%
+)
diff --git a/automation/script/template-ae-python/install_deps.sh b/automation/script/template-ae-python/install_deps.sh
new file mode 100644
index 0000000000..cb7c44c2bc
--- /dev/null
+++ b/automation/script/template-ae-python/install_deps.sh
@@ -0,0 +1,17 @@
+#!/bin/bash
+
+CUR_DIR=${PWD}
+
+echo ""
+echo "Current execution path: ${CUR_DIR}"
+echo "Path to script: ${CM_TMP_CURRENT_SCRIPT_PATH}"
+echo "ENV CM_EXPERIMENT: ${CM_EXPERIMENT}"
+
+if test -f "${CM_TMP_CURRENT_SCRIPT_PATH}/requirements.txt"; then
+ echo ""
+ echo "Installing requirements.txt ..."
+ echo ""
+
+ ${CM_PYTHON_BIN_WITH_PATH} -m pip install -r ${CM_TMP_CURRENT_SCRIPT_PATH}/requirements.txt
+ test $? -eq 0 || exit 1
+fi
diff --git a/automation/script/template-ae-python/main.py b/automation/script/template-ae-python/main.py
new file mode 100644
index 0000000000..d851f1450f
--- /dev/null
+++ b/automation/script/template-ae-python/main.py
@@ -0,0 +1,10 @@
+import os
+
+if __name__ == "__main__":
+
+ print ('')
+ print ('Main script:')
+ print ('Experiment: {}'.format(os.environ.get('CM_EXPERIMENT','')))
+ print ('')
+
+ exit(0)
diff --git a/automation/script/template-ae-python/plot.bat b/automation/script/template-ae-python/plot.bat
new file mode 100644
index 0000000000..7e786771ae
--- /dev/null
+++ b/automation/script/template-ae-python/plot.bat
@@ -0,0 +1,12 @@
+@echo off
+
+set CUR_DIR=%cd%
+
+echo.
+echo Current execution path: %CUR_DIR%
+echo Path to script: %CM_TMP_CURRENT_SCRIPT_PATH%
+echo ENV CM_EXPERIMENT: %CM_EXPERIMENT%
+
+rem echo.
+rem %CM_PYTHON_BIN_WITH_PATH% %CM_TMP_CURRENT_SCRIPT_PATH%\main.py
+rem IF %ERRORLEVEL% NEQ 0 EXIT %ERRORLEVEL%
diff --git a/automation/script/template-ae-python/plot.sh b/automation/script/template-ae-python/plot.sh
new file mode 100644
index 0000000000..630c3db3dd
--- /dev/null
+++ b/automation/script/template-ae-python/plot.sh
@@ -0,0 +1,12 @@
+#!/bin/bash
+
+CUR_DIR=${PWD}
+
+echo ""
+echo "Current execution path: ${CUR_DIR}"
+echo "Path to script: ${CM_TMP_CURRENT_SCRIPT_PATH}"
+echo "ENV CM_EXPERIMENT: ${CM_EXPERIMENT}"
+
+#echo ""
+#${CM_PYTHON_BIN_WITH_PATH} ${CM_TMP_CURRENT_SCRIPT_PATH}/main.py
+#test $? -eq 0 || exit 1
diff --git a/automation/script/template-ae-python/reproduce.bat b/automation/script/template-ae-python/reproduce.bat
new file mode 100644
index 0000000000..7e786771ae
--- /dev/null
+++ b/automation/script/template-ae-python/reproduce.bat
@@ -0,0 +1,12 @@
+@echo off
+
+set CUR_DIR=%cd%
+
+echo.
+echo Current execution path: %CUR_DIR%
+echo Path to script: %CM_TMP_CURRENT_SCRIPT_PATH%
+echo ENV CM_EXPERIMENT: %CM_EXPERIMENT%
+
+rem echo.
+rem %CM_PYTHON_BIN_WITH_PATH% %CM_TMP_CURRENT_SCRIPT_PATH%\main.py
+rem IF %ERRORLEVEL% NEQ 0 EXIT %ERRORLEVEL%
diff --git a/automation/script/template-ae-python/reproduce.sh b/automation/script/template-ae-python/reproduce.sh
new file mode 100644
index 0000000000..630c3db3dd
--- /dev/null
+++ b/automation/script/template-ae-python/reproduce.sh
@@ -0,0 +1,12 @@
+#!/bin/bash
+
+CUR_DIR=${PWD}
+
+echo ""
+echo "Current execution path: ${CUR_DIR}"
+echo "Path to script: ${CM_TMP_CURRENT_SCRIPT_PATH}"
+echo "ENV CM_EXPERIMENT: ${CM_EXPERIMENT}"
+
+#echo ""
+#${CM_PYTHON_BIN_WITH_PATH} ${CM_TMP_CURRENT_SCRIPT_PATH}/main.py
+#test $? -eq 0 || exit 1
diff --git a/automation/script/template-ae-python/run.bat b/automation/script/template-ae-python/run.bat
new file mode 100644
index 0000000000..6c1274ce64
--- /dev/null
+++ b/automation/script/template-ae-python/run.bat
@@ -0,0 +1,12 @@
+@echo off
+
+set CUR_DIR=%cd%
+
+echo.
+echo Current execution path: %CUR_DIR%
+echo Path to script: %CM_TMP_CURRENT_SCRIPT_PATH%
+echo ENV CM_EXPERIMENT: %CM_EXPERIMENT%
+
+echo.
+%CM_PYTHON_BIN_WITH_PATH% %CM_TMP_CURRENT_SCRIPT_PATH%\main.py
+IF %ERRORLEVEL% NEQ 0 EXIT %ERRORLEVEL%
diff --git a/automation/script/template-ae-python/run.sh b/automation/script/template-ae-python/run.sh
new file mode 100644
index 0000000000..2150b45dcd
--- /dev/null
+++ b/automation/script/template-ae-python/run.sh
@@ -0,0 +1,12 @@
+#!/bin/bash
+
+CUR_DIR=${PWD}
+
+echo ""
+echo "Current execution path: ${CUR_DIR}"
+echo "Path to script: ${CM_TMP_CURRENT_SCRIPT_PATH}"
+echo "ENV CM_EXPERIMENT: ${CM_EXPERIMENT}"
+
+echo ""
+${CM_PYTHON_BIN_WITH_PATH} ${CM_TMP_CURRENT_SCRIPT_PATH}/main.py
+test $? -eq 0 || exit 1
diff --git a/automation/script/template-ae-python/validate.bat b/automation/script/template-ae-python/validate.bat
new file mode 100644
index 0000000000..7e786771ae
--- /dev/null
+++ b/automation/script/template-ae-python/validate.bat
@@ -0,0 +1,12 @@
+@echo off
+
+set CUR_DIR=%cd%
+
+echo.
+echo Current execution path: %CUR_DIR%
+echo Path to script: %CM_TMP_CURRENT_SCRIPT_PATH%
+echo ENV CM_EXPERIMENT: %CM_EXPERIMENT%
+
+rem echo.
+rem %CM_PYTHON_BIN_WITH_PATH% %CM_TMP_CURRENT_SCRIPT_PATH%\main.py
+rem IF %ERRORLEVEL% NEQ 0 EXIT %ERRORLEVEL%
diff --git a/automation/script/template-ae-python/validate.sh b/automation/script/template-ae-python/validate.sh
new file mode 100644
index 0000000000..630c3db3dd
--- /dev/null
+++ b/automation/script/template-ae-python/validate.sh
@@ -0,0 +1,12 @@
+#!/bin/bash
+
+CUR_DIR=${PWD}
+
+echo ""
+echo "Current execution path: ${CUR_DIR}"
+echo "Path to script: ${CM_TMP_CURRENT_SCRIPT_PATH}"
+echo "ENV CM_EXPERIMENT: ${CM_EXPERIMENT}"
+
+#echo ""
+#${CM_PYTHON_BIN_WITH_PATH} ${CM_TMP_CURRENT_SCRIPT_PATH}/main.py
+#test $? -eq 0 || exit 1
diff --git a/automation/script/template-python/README-extra.md b/automation/script/template-python/README-extra.md
new file mode 100644
index 0000000000..582991f6d2
--- /dev/null
+++ b/automation/script/template-python/README-extra.md
@@ -0,0 +1 @@
+# CM script
diff --git a/automation/script/template-python/_cm.yaml b/automation/script/template-python/_cm.yaml
new file mode 100644
index 0000000000..adbb8d4e7c
--- /dev/null
+++ b/automation/script/template-python/_cm.yaml
@@ -0,0 +1,23 @@
+cache: false
+
+deps:
+ # Detect host OS features
+ - tags: detect,os
+
+ # Detect/install python
+ - tags: get,python
+ names:
+ - python
+ - python3
+
+input_mapping:
+ var1: CM_VAR1
+ req: PIP_REQUIREMENTS
+
+default_env:
+ CM_VAR1: 'something'
+
+variations:
+ req:
+ env:
+ PIP_REQUIREMENTS: True
diff --git a/automation/script/template-python/customize.py b/automation/script/template-python/customize.py
new file mode 100644
index 0000000000..10214b87df
--- /dev/null
+++ b/automation/script/template-python/customize.py
@@ -0,0 +1,30 @@
+from cmind import utils
+import os
+
+def preprocess(i):
+
+ print ('')
+ print ('Preprocessing ...')
+
+ os_info = i['os_info']
+
+ env = i['env']
+
+ meta = i['meta']
+
+ automation = i['automation']
+
+ quiet = (env.get('CM_QUIET', False) == 'yes')
+
+ print (' ENV CM_VAR1: {}'.format(env.get('CM_VAR1','')))
+
+ return {'return':0}
+
+def postprocess(i):
+
+ print ('')
+ print ('Postprocessing ...')
+
+ env = i['env']
+
+ return {'return':0}
diff --git a/automation/script/template-python/main.py b/automation/script/template-python/main.py
new file mode 100644
index 0000000000..9ba7bb751d
--- /dev/null
+++ b/automation/script/template-python/main.py
@@ -0,0 +1,10 @@
+import os
+
+if __name__ == "__main__":
+
+ print ('')
+ print ('Main script:')
+ print ('ENV CM_VAR1: {}'.format(os.environ.get('CM_VAR1','')))
+ print ('')
+
+ exit(0)
diff --git a/automation/script/template-python/requirements.txt b/automation/script/template-python/requirements.txt
new file mode 100644
index 0000000000..e69de29bb2
diff --git a/automation/script/template-python/run.bat b/automation/script/template-python/run.bat
new file mode 100644
index 0000000000..f9e1264bc8
--- /dev/null
+++ b/automation/script/template-python/run.bat
@@ -0,0 +1,25 @@
+@echo off
+
+set CUR_DIR=%cd%
+
+echo.
+echo Current execution path: %CUR_DIR%
+echo Path to script: %CM_TMP_CURRENT_SCRIPT_PATH%
+echo ENV PIP_REQUIREMENTS: %PIP_REQUIREMENTS%
+echo ENV CM_VAR1: %CM_VAR1%
+
+if "%PIP_REQUIREMENTS%" == "True" (
+ if exist "%CM_TMP_CURRENT_SCRIPT_PATH%\requirements.txt" (
+
+ echo.
+ echo Installing requirements.txt ...
+ echo.
+
+ %CM_PYTHON_BIN_WITH_PATH% -m pip install -r %CM_TMP_CURRENT_SCRIPT_PATH%\requirements.txt
+ IF %ERRORLEVEL% NEQ 0 EXIT %ERRORLEVEL%
+ )
+)
+
+echo.
+%CM_PYTHON_BIN_WITH_PATH% %CM_TMP_CURRENT_SCRIPT_PATH%\main.py
+IF %ERRORLEVEL% NEQ 0 EXIT %ERRORLEVEL%
diff --git a/automation/script/template-python/run.sh b/automation/script/template-python/run.sh
new file mode 100644
index 0000000000..a1a6aec2e2
--- /dev/null
+++ b/automation/script/template-python/run.sh
@@ -0,0 +1,24 @@
+#!/bin/bash
+
+CUR_DIR=${PWD}
+
+echo ""
+echo "Current execution path: ${CUR_DIR}"
+echo "Path to script: ${CM_TMP_CURRENT_SCRIPT_PATH}"
+echo "ENV PIP_REQUIREMENTS: ${PIP_REQUIREMENTS}"
+echo "ENV CM_VAR1: ${CM_VAR1}"
+
+if [ "${PIP_REQUIREMENTS}" == "True" ]; then
+ if test -f "${CM_TMP_CURRENT_SCRIPT_PATH}/requirements.txt"; then
+ echo ""
+ echo "Installing requirements.txt ..."
+ echo ""
+
+ ${CM_PYTHON_BIN_WITH_PATH} -m pip install -r ${CM_TMP_CURRENT_SCRIPT_PATH}/requirements.txt
+ test $? -eq 0 || exit 1
+ fi
+fi
+
+echo ""
+${CM_PYTHON_BIN_WITH_PATH} ${CM_TMP_CURRENT_SCRIPT_PATH}/main.py
+test $? -eq 0 || exit 1
diff --git a/automation/script/template-pytorch/README-extra.md b/automation/script/template-pytorch/README-extra.md
new file mode 100644
index 0000000000..582991f6d2
--- /dev/null
+++ b/automation/script/template-pytorch/README-extra.md
@@ -0,0 +1 @@
+# CM script
diff --git a/automation/script/template-pytorch/_cm.yaml b/automation/script/template-pytorch/_cm.yaml
new file mode 100644
index 0000000000..eaff95e47d
--- /dev/null
+++ b/automation/script/template-pytorch/_cm.yaml
@@ -0,0 +1,42 @@
+cache: false
+
+deps:
+ # Detect host OS features
+ - tags: detect,os
+
+ # Detect/install python
+ - tags: get,python
+ names:
+ - python
+ - python3
+
+ - tags: get,generic-python-lib,_torch
+ skip_if_env:
+ USE_CUDA:
+ - yes
+
+ - tags: get,generic-python-lib,_torch_cuda
+ enable_if_env:
+ USE_CUDA:
+ - yes
+
+ - tags: get,generic-python-lib,_package.numpy
+
+
+input_mapping:
+ var1: CM_VAR1
+ req: PIP_REQUIREMENTS
+
+default_env:
+ CM_VAR1: 'something'
+
+variations:
+ req:
+ env:
+ PIP_REQUIREMENTS: True
+
+ cuda:
+ env:
+ USE_CUDA: yes
+ deps:
+ - tags: get,cuda
diff --git a/automation/script/template-pytorch/customize.py b/automation/script/template-pytorch/customize.py
new file mode 100644
index 0000000000..10214b87df
--- /dev/null
+++ b/automation/script/template-pytorch/customize.py
@@ -0,0 +1,30 @@
+from cmind import utils
+import os
+
+def preprocess(i):
+
+ print ('')
+ print ('Preprocessing ...')
+
+ os_info = i['os_info']
+
+ env = i['env']
+
+ meta = i['meta']
+
+ automation = i['automation']
+
+ quiet = (env.get('CM_QUIET', False) == 'yes')
+
+ print (' ENV CM_VAR1: {}'.format(env.get('CM_VAR1','')))
+
+ return {'return':0}
+
+def postprocess(i):
+
+ print ('')
+ print ('Postprocessing ...')
+
+ env = i['env']
+
+ return {'return':0}
diff --git a/automation/script/template-pytorch/main.py b/automation/script/template-pytorch/main.py
new file mode 100644
index 0000000000..3e49da450f
--- /dev/null
+++ b/automation/script/template-pytorch/main.py
@@ -0,0 +1,15 @@
+import os
+
+import torch
+
+if __name__ == "__main__":
+
+ print ('')
+ print ('Main script:')
+ print ('ENV CM_VAR1: {}'.format(os.environ.get('CM_VAR1','')))
+ print ('ENV USE_CUDA: {}'.format(os.environ.get('USE_CUDA','')))
+ print ('')
+ print ('PyTorch version: {}'.format(torch.__version__))
+ print ('')
+
+ exit(0)
diff --git a/automation/script/template-pytorch/requirements.txt b/automation/script/template-pytorch/requirements.txt
new file mode 100644
index 0000000000..e69de29bb2
diff --git a/automation/script/template-pytorch/run.bat b/automation/script/template-pytorch/run.bat
new file mode 100644
index 0000000000..f9e1264bc8
--- /dev/null
+++ b/automation/script/template-pytorch/run.bat
@@ -0,0 +1,25 @@
+@echo off
+
+set CUR_DIR=%cd%
+
+echo.
+echo Current execution path: %CUR_DIR%
+echo Path to script: %CM_TMP_CURRENT_SCRIPT_PATH%
+echo ENV PIP_REQUIREMENTS: %PIP_REQUIREMENTS%
+echo ENV CM_VAR1: %CM_VAR1%
+
+if "%PIP_REQUIREMENTS%" == "True" (
+ if exist "%CM_TMP_CURRENT_SCRIPT_PATH%\requirements.txt" (
+
+ echo.
+ echo Installing requirements.txt ...
+ echo.
+
+ %CM_PYTHON_BIN_WITH_PATH% -m pip install -r %CM_TMP_CURRENT_SCRIPT_PATH%\requirements.txt
+ IF %ERRORLEVEL% NEQ 0 EXIT %ERRORLEVEL%
+ )
+)
+
+echo.
+%CM_PYTHON_BIN_WITH_PATH% %CM_TMP_CURRENT_SCRIPT_PATH%\main.py
+IF %ERRORLEVEL% NEQ 0 EXIT %ERRORLEVEL%
diff --git a/automation/script/template-pytorch/run.sh b/automation/script/template-pytorch/run.sh
new file mode 100644
index 0000000000..a1a6aec2e2
--- /dev/null
+++ b/automation/script/template-pytorch/run.sh
@@ -0,0 +1,24 @@
+#!/bin/bash
+
+CUR_DIR=${PWD}
+
+echo ""
+echo "Current execution path: ${CUR_DIR}"
+echo "Path to script: ${CM_TMP_CURRENT_SCRIPT_PATH}"
+echo "ENV PIP_REQUIREMENTS: ${PIP_REQUIREMENTS}"
+echo "ENV CM_VAR1: ${CM_VAR1}"
+
+if [ "${PIP_REQUIREMENTS}" == "True" ]; then
+ if test -f "${CM_TMP_CURRENT_SCRIPT_PATH}/requirements.txt"; then
+ echo ""
+ echo "Installing requirements.txt ..."
+ echo ""
+
+ ${CM_PYTHON_BIN_WITH_PATH} -m pip install -r ${CM_TMP_CURRENT_SCRIPT_PATH}/requirements.txt
+ test $? -eq 0 || exit 1
+ fi
+fi
+
+echo ""
+${CM_PYTHON_BIN_WITH_PATH} ${CM_TMP_CURRENT_SCRIPT_PATH}/main.py
+test $? -eq 0 || exit 1
diff --git a/automation/script/template/README-extra.md b/automation/script/template/README-extra.md
new file mode 100644
index 0000000000..582991f6d2
--- /dev/null
+++ b/automation/script/template/README-extra.md
@@ -0,0 +1 @@
+# CM script
diff --git a/automation/script/template/customize.py b/automation/script/template/customize.py
new file mode 100644
index 0000000000..d12f9b3e1d
--- /dev/null
+++ b/automation/script/template/customize.py
@@ -0,0 +1,22 @@
+from cmind import utils
+import os
+
+def preprocess(i):
+
+ os_info = i['os_info']
+
+ env = i['env']
+
+ meta = i['meta']
+
+ automation = i['automation']
+
+ quiet = (env.get('CM_QUIET', False) == 'yes')
+
+ return {'return':0}
+
+def postprocess(i):
+
+ env = i['env']
+
+ return {'return':0}
diff --git a/automation/script/template/run.bat b/automation/script/template/run.bat
new file mode 100644
index 0000000000..648302ca71
--- /dev/null
+++ b/automation/script/template/run.bat
@@ -0,0 +1 @@
+rem native script
diff --git a/automation/script/template/run.sh b/automation/script/template/run.sh
new file mode 100644
index 0000000000..3a584c10cf
--- /dev/null
+++ b/automation/script/template/run.sh
@@ -0,0 +1,27 @@
+#!/bin/bash
+
+#CM Script location: ${CM_TMP_CURRENT_SCRIPT_PATH}
+
+#To export any variable
+#echo "VARIABLE_NAME=VARIABLE_VALUE" >>tmp-run-env.out
+
+#${CM_PYTHON_BIN_WITH_PATH} contains the path to python binary if "get,python" is added as a dependency
+
+
+
+function exit_if_error() {
+ test $? -eq 0 || exit $?
+}
+
+function run() {
+ echo "Running: "
+ echo "$1"
+ echo ""
+ if [[ ${CM_FAKE_RUN} != 'yes' ]]; then
+ eval "$1"
+ exit_if_error
+ fi
+}
+
+#Add your run commands here...
+# run "$CM_RUN_CMD"
diff --git a/automation/script/template_list_of_scripts.md b/automation/script/template_list_of_scripts.md
new file mode 100644
index 0000000000..9158bc8e16
--- /dev/null
+++ b/automation/script/template_list_of_scripts.md
@@ -0,0 +1,52 @@
+[ [Back to index](README.md) ]
+
+
+
+This is an automatically generated list of portable and reusable automation recipes (CM scripts)
+with a [human-friendly interface (CM)](https://github.com/mlcommons/ck)
+to run a growing number of ad-hoc MLPerf, MLOps, and DevOps scripts
+from [MLCommons projects](https://github.com/mlcommons/ck/tree/master/cm-mlops/script)
+and [research papers](https://www.youtube.com/watch?v=7zpeIVwICa4)
+in a unified way on any operating system with any software and hardware
+natively or inside containers.
+
+Click on any automation recipe below to learn how to run and reuse it
+via CM command line, Python API or GUI.
+
+CM scripts can easily chained together into automation workflows using `deps` and `tags` keys
+while automatically updating all environment variables and paths
+for a given task and platform [using simple JSON or YAML](https://github.com/mlcommons/ck/blob/master/cm-mlops/script/app-image-classification-onnx-py/_cm.yaml).
+
+
+*Note that CM is a community project being developed and extended by [MLCommons members and individual contributors](../CONTRIBUTING.md) -
+ you can find source code of CM scripts maintained by MLCommons [here](../cm-mlops/script).
+ Please join [Discord server](https://discord.gg/JjWNWXKxwT) to participate in collaborative developments or provide your feedback.*
+
+
+# License
+
+[Apache 2.0](LICENSE.md)
+
+
+# Copyright
+
+2022-2024 [MLCommons](https://mlcommons.org)
+
+
+
+
+
+# List of CM scripts by categories
+
+{{CM_TOC_CATEGORIES}}
+
+{{CM_TOC2}}
+
+# List of all sorted CM scripts
+
+{{CM_TOC}}
+
+
+{{CM_MAIN}}
diff --git a/automation/utils/README.md b/automation/utils/README.md
new file mode 100644
index 0000000000..9a844c6566
--- /dev/null
+++ b/automation/utils/README.md
@@ -0,0 +1,387 @@
+*This README is automatically generated - don't edit! Use `README-extra.md` for extra notes!*
+
+### Automation actions
+
+#### test
+
+ * CM CLI: ```cm test utils``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L15))
+ * CM CLI with UID: ```cm test utils,dc2743f8450541e3``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L15))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'test'
+ 'automation':'utils,dc2743f8450541e3'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L15)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### get_host_os_info
+
+ * CM CLI: ```cm get_host_os_info utils``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L54))
+ * CM CLI with UID: ```cm get_host_os_info utils,dc2743f8450541e3``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L54))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'get_host_os_info'
+ 'automation':'utils,dc2743f8450541e3'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L54)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### download_file
+
+ * CM CLI: ```cm download_file utils``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L156))
+ * CM CLI with UID: ```cm download_file utils,dc2743f8450541e3``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L156))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'download_file'
+ 'automation':'utils,dc2743f8450541e3'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L156)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### unzip_file
+
+ * CM CLI: ```cm unzip_file utils``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L265))
+ * CM CLI with UID: ```cm unzip_file utils,dc2743f8450541e3``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L265))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'unzip_file'
+ 'automation':'utils,dc2743f8450541e3'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L265)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### compare_versions
+
+ * CM CLI: ```cm compare_versions utils``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L343))
+ * CM CLI with UID: ```cm compare_versions utils,dc2743f8450541e3``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L343))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'compare_versions'
+ 'automation':'utils,dc2743f8450541e3'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L343)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### json2yaml
+
+ * CM CLI: ```cm json2yaml utils``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L391))
+ * CM CLI with UID: ```cm json2yaml utils,dc2743f8450541e3``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L391))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'json2yaml'
+ 'automation':'utils,dc2743f8450541e3'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L391)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### yaml2json
+
+ * CM CLI: ```cm yaml2json utils``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L429))
+ * CM CLI with UID: ```cm yaml2json utils,dc2743f8450541e3``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L429))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'yaml2json'
+ 'automation':'utils,dc2743f8450541e3'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L429)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### sort_json
+
+ * CM CLI: ```cm sort_json utils``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L467))
+ * CM CLI with UID: ```cm sort_json utils,dc2743f8450541e3``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L467))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'sort_json'
+ 'automation':'utils,dc2743f8450541e3'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L467)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### dos2unix
+
+ * CM CLI: ```cm dos2unix utils``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L504))
+ * CM CLI with UID: ```cm dos2unix utils,dc2743f8450541e3``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L504))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'dos2unix'
+ 'automation':'utils,dc2743f8450541e3'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L504)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### replace_string_in_file
+
+ * CM CLI: ```cm replace_string_in_file utils``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L541))
+ * CM CLI with UID: ```cm replace_string_in_file utils,dc2743f8450541e3``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L541))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'replace_string_in_file'
+ 'automation':'utils,dc2743f8450541e3'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L541)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### create_toc_from_md
+
+ * CM CLI: ```cm create_toc_from_md utils``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L591))
+ * CM CLI with UID: ```cm create_toc_from_md utils,dc2743f8450541e3``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L591))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'create_toc_from_md'
+ 'automation':'utils,dc2743f8450541e3'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L591)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### copy_to_clipboard
+
+ * CM CLI: ```cm copy_to_clipboard utils``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L659))
+ * CM CLI with UID: ```cm copy_to_clipboard utils,dc2743f8450541e3``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L659))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'copy_to_clipboard'
+ 'automation':'utils,dc2743f8450541e3'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L659)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### list_files_recursively
+
+ * CM CLI: ```cm list_files_recursively utils``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L737))
+ * CM CLI with UID: ```cm list_files_recursively utils,dc2743f8450541e3``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L737))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'list_files_recursively'
+ 'automation':'utils,dc2743f8450541e3'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L737)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### generate_secret
+
+ * CM CLI: ```cm generate_secret utils``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L770))
+ * CM CLI with UID: ```cm generate_secret utils,dc2743f8450541e3``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L770))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'generate_secret'
+ 'automation':'utils,dc2743f8450541e3'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L770)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### detect_tags_in_artifact
+
+ * CM CLI: ```cm detect_tags_in_artifact utils``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L793))
+ * CM CLI with UID: ```cm detect_tags_in_artifact utils,dc2743f8450541e3``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L793))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'detect_tags_in_artifact'
+ 'automation':'utils,dc2743f8450541e3'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L793)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### prune_input
+
+ * CM CLI: ```cm prune_input utils``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L822))
+ * CM CLI with UID: ```cm prune_input utils,dc2743f8450541e3``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L822))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'prune_input'
+ 'automation':'utils,dc2743f8450541e3'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L822)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### uid
+
+ * CM CLI: ```cm uid utils``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L864))
+ * CM CLI with UID: ```cm uid utils,dc2743f8450541e3``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L864))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'uid'
+ 'automation':'utils,dc2743f8450541e3'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L864)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### system
+
+ * CM CLI: ```cm system utils``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L891))
+ * CM CLI with UID: ```cm system utils,dc2743f8450541e3``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L891))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'system'
+ 'automation':'utils,dc2743f8450541e3'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L891)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+#### load_cfg
+
+ * CM CLI: ```cm load_cfg utils``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L969))
+ * CM CLI with UID: ```cm load_cfg utils,dc2743f8450541e3``` ([add flags (dict keys) from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L969))
+ * CM Python API:
+ ```python
+ import cmind
+
+ r=cm.access({
+ 'action':'load_cfg'
+ 'automation':'utils,dc2743f8450541e3'
+ 'out':'con'
+ ```
+ [add keys from this API](https://github.com/mlcommons/ck/tree/master/cm-mlops/automation/utils/module.py#L969)
+ ```python
+ })
+ if r['return']>0:
+ print(r['error'])
+ ```
+
+### Maintainers
+
+* [Open MLCommons taskforce on automation and reproducibility](https://cKnowledge.org/mlcommons-taskforce)
\ No newline at end of file
diff --git a/automation/utils/_cm.json b/automation/utils/_cm.json
new file mode 100644
index 0000000000..f2dc9c5b66
--- /dev/null
+++ b/automation/utils/_cm.json
@@ -0,0 +1,12 @@
+{
+ "alias": "utils",
+ "automation_alias": "automation",
+ "automation_uid": "bbeb15d8f0a944a4",
+ "desc": "Accessing various CM utils",
+ "developers": "[Grigori Fursin](https://cKnowledge.org/gfursin)",
+ "sort": 800,
+ "tags": [
+ "automation"
+ ],
+ "uid": "dc2743f8450541e3"
+}
diff --git a/automation/utils/module.py b/automation/utils/module.py
new file mode 100644
index 0000000000..084431a39b
--- /dev/null
+++ b/automation/utils/module.py
@@ -0,0 +1,986 @@
+import os
+
+from cmind.automation import Automation
+from cmind import utils
+
+class CAutomation(Automation):
+ """
+ Automation actions
+ """
+
+ ############################################################
+ def __init__(self, cmind, automation_file):
+ super().__init__(cmind, __file__)
+
+ ############################################################
+ def test(self, i):
+ """
+ Test automation
+
+ Args:
+ (CM input dict):
+
+ (out) (str): if 'con', output to console
+
+ automation (str): automation as CM string object
+
+ parsed_automation (list): prepared in CM CLI or CM access function
+ [ (automation alias, automation UID) ] or
+ [ (automation alias, automation UID), (automation repo alias, automation repo UID) ]
+
+ (artifact) (str): artifact as CM string object
+
+ (parsed_artifact) (list): prepared in CM CLI or CM access function
+ [ (artifact alias, artifact UID) ] or
+ [ (artifact alias, artifact UID), (artifact repo alias, artifact repo UID) ]
+
+ ...
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ * Output from this automation action
+
+ """
+
+ import json
+ print (json.dumps(i, indent=2))
+
+ return {'return':0}
+
+ ##############################################################################
+ def get_host_os_info(self, i):
+ """
+ Get some host platform name (currently windows or linux) and OS bits
+
+ Args:
+ (CM input dict):
+
+ (bits) (str): force host platform bits
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ * info (dict):
+ * platform (str): "windows", "linux" or "darwin"
+ * bat_ext (str): ".bat" or ".sh"
+ * bits (str): 32 or 64 bits
+ * python_bits 9str): python bits
+
+ """
+
+ import os
+ import platform
+ import struct
+
+ info = {}
+
+ pbits = str(8 * struct.calcsize("P"))
+
+ if platform.system().lower().startswith('win'):
+ platform = 'windows'
+ info['bat_ext']='.bat'
+ info['set_env']='set ${key}=${value}'
+ info['env_separator']=';'
+ info['env_var']='%env_var%'
+ info['bat_rem']='rem ${rem}'
+ info['run_local_bat']='call ${bat_file}'
+ info['run_local_bat_from_python']='call ${bat_file}'
+ info['run_bat']='call ${bat_file}'
+ info['start_script']=['@echo off', '']
+ info['env']={
+ "CM_WINDOWS":"yes"
+ }
+ else:
+ if platform.system().lower().startswith('darwin'):
+ platform = 'darwin'
+ else:
+ platform = 'linux'
+
+ info['bat_ext']='.sh'
+ info['set_env']='export ${key}="${value}"'
+ info['env_separator']=':'
+ info['env_var']='${env_var}'
+ info['set_exec_file']='chmod 755 "${file_name}"'
+ info['bat_rem']='# ${rem}'
+ info['run_local_bat']='. ./${bat_file}'
+ info['run_local_bat_from_python']='bash -c ". ./${bat_file}"'
+ info['run_bat']='. ${bat_file}'
+ info['start_script']=['#!/bin/bash', '']
+ info['env']={}
+
+ info['platform'] = platform
+
+ obits = i.get('bits', '')
+ if obits == '':
+ obits = '32'
+ if platform == 'windows':
+ # Trying to get fast way to detect bits
+ if os.environ.get('ProgramW6432', '') != '' or os.environ.get('ProgramFiles(x86)', '') != '': # pragma: no cover
+ obits = '64'
+ else:
+ # On Linux use first getconf LONG_BIT and if doesn't work use python bits
+
+ obits = pbits
+
+ r = utils.gen_tmp_file({})
+ if r['return'] > 0:
+ return r
+
+ fn = r['file_name']
+
+ cmd = 'getconf LONG_BIT > '+fn
+ rx = os.system(cmd)
+
+ if rx == 0:
+ r = utils.load_txt(file_name = fn, remove_after_read = True)
+
+ if r['return'] == 0:
+ s = r['string'].strip()
+ if len(s) > 0 and len(s) < 4:
+ obits = s
+ else:
+ if os.path.isfile(fn): os.remove(fn)
+
+ info['bits'] = obits
+ info['python_bits'] = pbits
+
+ return {'return': 0, 'info': info}
+
+ ##############################################################################
+ def download_file(self, i):
+ """
+ Download file using requests
+
+ Args:
+ (CM input dict):
+
+ url (str): URL with file
+ (filename) (str): explicit file name
+ (path) (str): path to record file (or current if empty)
+ (chunk_size) (int): chunck size in bytes (65536 by default)
+ (text) (str): print text before downloaded status ("Downloaded: " by default)
+ (verify) (bool): verify SSL certificate if True (True by default)
+ can be switched by global env CM_UTILS_DOWNLOAD_VERIFY_SSL = no
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ * filename (str): file name
+ * path (str): path to file
+ * size (int): file size
+
+ """
+
+ import requests
+ import time
+ import sys
+ from urllib import parse
+
+ # Get URL
+ url = i['url']
+
+ # Check file name
+ file_name = i.get('filename','')
+ if file_name == '':
+ parsed_url = parse.urlparse(url)
+ file_name = os.path.basename(parsed_url.path)
+
+ # Check path
+ path = i.get('path','')
+ if path is None or path=='':
+ path = os.getcwd()
+
+ # Output file
+ path_to_file = os.path.join(path, file_name)
+
+ if os.path.isfile(path_to_file):
+ os.remove(path_to_file)
+
+ print ('Downloading to {}'.format(path_to_file))
+ print ('')
+
+ # Download
+ size = -1
+ downloaded = 0
+ chunk_size = i.get('chunk_size', 65536)
+
+ text = i.get('text','Downloaded: ')
+
+ if 'CM_UTILS_DOWNLOAD_VERIFY_SSL' in os.environ:
+ verify = os.environ['CM_UTILS_DOWNLOAD_VERIFY_SSL'] == 'yes'
+ else:
+ verify = i.get('verify', True)
+
+ try:
+ with requests.get(url, stream=True, allow_redirects=True, verify=verify) as download:
+ download.raise_for_status()
+
+ size_string = download.headers.get('Content-Length')
+
+ if size_string is None:
+ transfer_encoding = download.headers.get('Transfer-Encoding', '')
+ if transfer_encoding != 'chunked':
+ return {'return':1, 'error':'did not receive file'}
+ else:
+ size_string = "0"
+
+ size = int(size_string)
+
+ with open(path_to_file, 'wb') as output:
+ for chunk in download.iter_content(chunk_size = chunk_size):
+
+ if chunk:
+ output.write(chunk)
+ if size == 0:
+ continue
+ downloaded+=1
+ percent = downloaded * chunk_size * 100 / size
+
+ sys.stdout.write("\r{}{:3.0f}%".format(text, percent))
+ sys.stdout.flush()
+
+ sys.stdout.write("\r{}{:3.0f}%".format(text, 100))
+ sys.stdout.flush()
+
+ except Exception as e:
+ return {'return':1, 'error':format(e)}
+
+ print ('')
+ if size == 0:
+ file_stats=os.stat(path_to_file)
+ size = file_stats.st_size
+
+ return {'return': 0, 'filename':file_name, 'path': path_to_file, 'size':size}
+
+ ##############################################################################
+ def unzip_file(self, i):
+ """
+ Unzip file
+
+ Args:
+ (CM input dict):
+
+ filename (str): explicit file name
+ (path) (str): path where to unzip file (current path otherwise)
+ (strip_folders) (int): strip first folders
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ """
+
+ import zipfile
+
+ # Check file name
+ file_name = i['filename']
+
+ if not os.path.isfile(file_name):
+ return {'return':1, 'error':'file {} not found'.format(file_name)}
+
+ console = i.get('out') == 'con'
+
+ # Attempt to read cmr.json
+ file_name_handle = open(file_name, 'rb')
+ file_name_zip = zipfile.ZipFile(file_name_handle)
+
+ info_files=file_name_zip.infolist()
+
+ path=i.get('path','')
+ if path is None or path=='':
+ path=os.getcwd()
+
+ strip_folders = i.get('strip_folders',0)
+
+ # Unpacking zip
+ for info in info_files:
+ f = info.filename
+ permissions = info.external_attr
+
+ if not f.startswith('..') and not f.startswith('/') and not f.startswith('\\'):
+ f_zip = f
+
+ if strip_folders>0:
+ fsplit = f.split('/') # Zip standard on all OS
+ f = '/'.join(fsplit[strip_folders:])
+
+ file_path = os.path.join(path, f)
+
+ if f.endswith('/'):
+ # create directory
+ if not os.path.exists(file_path):
+ os.makedirs(file_path)
+ else:
+ dir_name = os.path.dirname(file_path)
+ if not os.path.exists(dir_name):
+ os.makedirs(dir_name)
+
+ # extract file
+ file_out = open(file_path, 'wb')
+ file_out.write(file_name_zip.read(f_zip))
+ file_out.close()
+
+ if permissions > 0xffff:
+ os.chmod(file_path, permissions >> 16)
+
+ file_name_zip.close()
+ file_name_handle.close()
+
+ return {'return':0}
+
+ ##############################################################################
+ def compare_versions(self, i):
+ """
+ Compare versions
+
+ Args:
+
+ version1 (str): version 1
+ version2 (str): version 2
+
+ Returns:
+ (CM return dict):
+
+ * comparison (int): 1 - version 1 > version 2
+ 0 - version 1 == version 2
+ -1 - version 1 < version 2
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+ """
+
+ version1 = i['version1']
+ version2 = i['version2']
+
+ l_version1 = version1.split('.')
+ l_version2 = version2.split('.')
+
+ # 3.9.6 vs 3.9
+ # 3.9 vs 3.9.6
+
+ i_version1 = [int(v) if v.isdigit() else v for v in l_version1]
+ i_version2 = [int(v) if v.isdigit() else v for v in l_version2]
+
+ comparison = 0
+
+ for index in range(max(len(i_version1), len(i_version2))):
+ v1 = i_version1[index] if index < len(i_version1) else 0
+ v2 = i_version2[index] if index < len(i_version2) else 0
+
+ if v1 > v2:
+ comparison = 1
+ break
+ elif v1 < v2:
+ comparison = -1
+ break
+
+ return {'return':0, 'comparison': comparison}
+
+ ##############################################################################
+ def json2yaml(self, i):
+ """
+ Convert JSON file to YAML
+
+ Args:
+
+ input (str): input file (.json)
+ (output) (str): output file (.yaml)
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+ """
+
+ input_file = i.get('input','')
+
+ if input_file == '':
+ return {'return':1, 'error':'please specify --input={json file}'}
+
+ output_file = i.get('output','')
+
+ r = utils.load_json(input_file, check_if_exists = True)
+ if r['return']>0: return r
+
+ meta = r['meta']
+
+ if output_file=='':
+ output_file = input_file[:-5] if input_file.endswith('.json') else input_file
+ output_file+='.yaml'
+
+ r = utils.save_yaml(output_file, meta)
+ if r['return']>0: return r
+
+ return {'return':0}
+
+ ##############################################################################
+ def yaml2json(self, i):
+ """
+ Convert YAML file to JSON
+
+ Args:
+
+ input (str): input file (.yaml)
+ (output) (str): output file (.json)
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+ """
+
+ input_file = i.get('input','')
+
+ if input_file == '':
+ return {'return':1, 'error':'please specify --input={yaml file}'}
+
+ output_file = i.get('output','')
+
+ r = utils.load_yaml(input_file, check_if_exists = True)
+ if r['return']>0: return r
+
+ meta = r['meta']
+
+ if output_file=='':
+ output_file = input_file[:-5] if input_file.endswith('.yaml') else input_file
+ output_file+='.json'
+
+ r = utils.save_json(output_file, meta)
+ if r['return']>0: return r
+
+ return {'return':0}
+
+ ##############################################################################
+ def sort_json(self, i):
+ """
+ Sort JSON file
+
+ Args:
+
+ input (str): input file (.json)
+ (output) (str): output file
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+ """
+
+ input_file = i.get('input','')
+
+ if input_file == '':
+ return {'return':1, 'error':'please specify --input={json file}'}
+
+ r = utils.load_json(input_file, check_if_exists = True)
+ if r['return']>0: return r
+
+ meta = r['meta']
+
+ output_file = i.get('output','')
+
+ if output_file=='':
+ output_file = input_file
+
+ r = utils.save_json(output_file, meta, sort_keys=True)
+ if r['return']>0: return r
+
+ return {'return':0}
+
+ ##############################################################################
+ def dos2unix(self, i):
+ """
+ Convert DOS file to UNIX (remove \r)
+
+ Args:
+
+ input (str): input file (.txt)
+ (output) (str): output file
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+ """
+
+ input_file = i.get('input','')
+
+ if input_file == '':
+ return {'return':1, 'error':'please specify --input={txt file}'}
+
+ r = utils.load_txt(input_file, check_if_exists = True)
+ if r['return']>0: return r
+
+ s = r['string'].replace('\r','')
+
+ output_file = i.get('output','')
+
+ if output_file=='':
+ output_file = input_file
+
+ r = utils.save_txt(output_file, s)
+ if r['return']>0: return r
+
+ return {'return':0}
+
+ ##############################################################################
+ def replace_string_in_file(self, i):
+ """
+ Convert DOS file to UNIX (remove \r)
+
+ Args:
+
+ input (str): input file (.txt)
+ (output) (str): output file
+ string (str): string to replace
+ replacement (str): replacement string
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ (update) (bool): True if file was upated
+ """
+
+ input_file = i.get('input', '')
+ if input_file == '':
+ return {'return':1, 'error':'please specify --input={txt file}'}
+
+ string = i.get('string', '')
+ if string == '':
+ return {'return':1, 'error':'please specify --string={string to replace}'}
+
+ replacement = i.get('replacement', '')
+ if replacement == '':
+ return {'return':1, 'error':'please specify --replacement={string to replace}'}
+
+ output_file = i.get('output','')
+
+ if output_file=='':
+ output_file = input_file
+
+ r = utils.load_txt(input_file, check_if_exists = True)
+ if r['return']>0: return r
+
+ s = r['string'].replace('\r','')
+
+ s = s.replace(string, replacement)
+
+ r = utils.save_txt(output_file, s)
+ if r['return']>0: return r
+
+ return {'return':0}
+
+ ##############################################################################
+ def create_toc_from_md(self, i):
+ """
+ Convert DOS file to UNIX (remove \r)
+
+ Args:
+
+ input (str): input file (.md)
+ (output) (str): output file (input+'.toc)
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+ """
+
+ input_file = i.get('input', '')
+ if input_file == '':
+ return {'return':1, 'error':'please specify --input={txt file}'}
+
+ output_file = i.get('output','')
+
+ if output_file=='':
+ output_file = input_file + '.toc'
+
+ r = utils.load_txt(input_file, check_if_exists = True)
+ if r['return']>0: return r
+
+ lines = r['string'].split('\n')
+
+ toc = []
+
+ toc.append('')
+ toc.append('Click here to see the table of contents.
')
+ toc.append('')
+
+ for line in lines:
+ line = line.strip()
+
+ if line.startswith('#'):
+ j = line.find(' ')
+ if j>=0:
+ title = line[j:].strip()
+
+ x = title.lower().replace(' ','-')
+
+ for k in range(0,2):
+ if x.startswith('*'):
+ x=x[1:]
+ if x.endswith('*'):
+ x=x[:-1]
+
+ for z in [':', '+', '.', '(', ')', ',']:
+ x = x.replace(z, '')
+
+ y = ' '*(2*(j-1)) + '* ['+title+'](#'+x+')'
+
+ toc.append(y)
+
+ toc.append('')
+ toc.append(' ')
+
+ r = utils.save_txt(output_file, '\n'.join(toc)+'\n')
+ if r['return']>0: return r
+
+ return {'return':0}
+
+ ##############################################################################
+ def copy_to_clipboard(self, i):
+ """
+ Copy string to a clipboard
+
+ Args:
+
+ string (str): string to copy to a clipboard
+ (add_quotes) (bool): add quotes to the string in a clipboard
+ (skip_fail) (bool): if True, do not fail
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+ """
+
+ s = i.get('string','')
+
+ if i.get('add_quotes',False): s='"'+s+'"'
+
+ failed = False
+ warning = ''
+
+ # Try to load pyperclip (seems to work fine on Windows)
+ try:
+ import pyperclip
+ except Exception as e:
+ warning = format(e)
+ failed = True
+ pass
+
+ if not failed:
+ pyperclip.copy(s)
+ else:
+ failed = False
+
+ # Try to load Tkinter
+ try:
+ from Tkinter import Tk
+ except ImportError as e:
+ warning = format(e)
+ failed = True
+ pass
+
+ if failed:
+ failed = False
+ try:
+ from tkinter import Tk
+ except ImportError as e:
+ warning = format(e)
+ failed = True
+ pass
+
+ if not failed:
+ # Copy to clipboard
+ try:
+ r = Tk()
+ r.withdraw()
+ r.clipboard_clear()
+ r.clipboard_append(s)
+ r.update()
+ r.destroy()
+ except Exception as e:
+ failed = True
+ warning = format(e)
+
+ rr = {'return':0}
+
+ if failed:
+ if not i.get('skip_fail',False):
+ return {'return':1, 'error':warning}
+
+ rr['warning']=warning
+
+ return rr
+
+ ##############################################################################
+ def list_files_recursively(self, i):
+ """
+ List files and concatenate into string separate by comma
+
+ Args:
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+ """
+
+ files = os.walk('.')
+
+ s = ''
+
+ for (dir_path, dir_names, file_names) in files:
+ for f in file_names:
+ if s!='': s+=','
+
+ if dir_path=='.':
+ dir_path2=''
+ else:
+ dir_path2=dir_path[2:].replace('\\','/')+'/'
+
+ s+=dir_path2+f
+
+ print (s)
+
+ return {'return':0}
+
+ ##############################################################################
+ def generate_secret(self, i):
+ """
+ Generate secret for web apps
+
+ Args:
+
+ Returns:
+ (CM return dict):
+
+ secret (str): secret
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+ """
+
+ import secrets
+ s = secrets.token_urlsafe(16)
+
+ print (s)
+
+ return {'return':0, 'secret': s}
+
+ ##############################################################################
+ def detect_tags_in_artifact(self, i):
+ """
+ Detect if there are tags in an artifact name (spaces) and update input
+
+ Args:
+
+ input (dict) : original input
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+ """
+
+ inp = i['input']
+
+ artifact = inp.get('artifact','')
+ if artifact == '.':
+ del(inp['artifact'])
+ elif ' ' in artifact: # or ',' in artifact:
+ del(inp['artifact'])
+ if 'parsed_artifact' in inp: del(inp['parsed_artifact'])
+ # Force substitute tags
+ inp['tags']=artifact.replace(' ',',')
+
+ return {'return':0}
+
+ ##############################################################################
+ def prune_input(self, i):
+ """
+ Leave only input keys and remove the rest (to regenerate CM commands)
+
+ Args:
+
+ input (dict) : original input
+ (extra_keys_starts_with) (list): remove keys that starts
+ with the ones from this list
+
+ Returns:
+ (CM return dict):
+
+ new_input (dict): pruned input
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+ """
+
+ import copy
+
+ inp = i['input']
+ extra_keys = i.get('extra_keys_starts_with',[])
+
+ i_run_cmd_arc = copy.deepcopy(inp)
+ for k in inp:
+ remove = False
+ if k in ['action', 'automation', 'cmd', 'out', 'parsed_automation', 'parsed_artifact', 'self_module']:
+ remove = True
+ if not remove:
+ for ek in extra_keys:
+ if k.startswith(ek):
+ remove = True
+ break
+
+ if remove:
+ del(i_run_cmd_arc[k])
+
+ return {'return':0, 'new_input':i_run_cmd_arc}
+
+
+ ##############################################################################
+ def uid(self, i):
+ """
+ Generate CM UID.
+
+ Args:
+ (CM input dict): empty dict
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ * uid (str): CM UID
+ """
+
+ console = i.get('out') == 'con'
+
+ r = utils.gen_uid()
+
+ if console:
+ print (r['uid'])
+
+ return r
+
+
+ ##############################################################################
+ def system(self, i):
+ """
+ Run system command and redirect output to string.
+
+ Args:
+ (CM input dict):
+
+ * cmd (str): command line
+ * (path) (str): go to this directory and return back to current
+ * (stdout) (str): stdout file
+ * (stderr) (str): stderr file
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ * ret (int): return code
+ * std (str): stdout + stderr
+ * stdout (str): stdout
+ * stderr (str): stderr
+ """
+
+ cmd = i['cmd']
+
+ if cmd == '':
+ return {'return':1, 'error': 'cmd is empty'}
+
+ path = i.get('path','')
+ if path!='' and os.path.isdir(path):
+ cur_dir = os.getcwd()
+ os.chdir(path)
+
+ if i.get('stdout','')!='':
+ fn1=i['stdout']
+ fn1_delete = False
+ else:
+ r = utils.gen_tmp_file({})
+ if r['return'] > 0: return r
+ fn1 = r['file_name']
+ fn1_delete = True
+
+ if i.get('stderr','')!='':
+ fn2=i['stderr']
+ fn2_delete = False
+ else:
+ r = utils.gen_tmp_file({})
+ if r['return'] > 0: return r
+ fn2 = r['file_name']
+ fn2_delete = True
+
+ cmd += ' > '+fn1 + ' 2> '+fn2
+ rx = os.system(cmd)
+
+ std = ''
+ stdout = ''
+ stderr = ''
+
+ if os.path.isfile(fn1):
+ r = utils.load_txt(file_name = fn1, remove_after_read = fn1_delete)
+ if r['return'] == 0: stdout = r['string'].strip()
+
+ if os.path.isfile(fn2):
+ r = utils.load_txt(file_name = fn2, remove_after_read = fn2_delete)
+ if r['return'] == 0: stderr = r['string'].strip()
+
+ std = stdout
+ if stderr!='':
+ if std!='': std+='\n'
+ std+=stderr
+
+ if path!='' and os.path.isdir(path):
+ os.chdir(cur_dir)
+
+ return {'return':0, 'ret':rx, 'stdout':stdout, 'stderr':stderr, 'std':std}
+
+ ############################################################
+ def load_cfg(self, i):
+ """
+ Load configuration artifacts and files
+
+ Args:
+ (CM input dict):
+
+
+ Returns:
+ (CM return dict):
+
+ * return (int): return code == 0 if no error and >0 if error
+ * (error) (str): error string if return>0
+
+ """
+
+ return utils.call_internal_module(self, __file__, 'module_cfg', 'load_cfg', i)
diff --git a/automation/utils/module_cfg.py b/automation/utils/module_cfg.py
new file mode 100644
index 0000000000..b70f2145cf
--- /dev/null
+++ b/automation/utils/module_cfg.py
@@ -0,0 +1,225 @@
+import os
+import cmind
+import copy
+
+base_path={}
+base_path_meta={}
+
+##################################################################################
+def load_cfg(i):
+
+ tags = i.get('tags','')
+ artifact = i.get('artifact','')
+
+ key = i.get('key', '')
+ key_end = i.get('key_end', [])
+
+ ii={'action':'find',
+ 'automation':'cfg'}
+ if artifact!='':
+ ii['artifact']=artifact
+ elif tags!='':
+ ii['tags']=tags
+
+ r=cmind.access(ii)
+ if r['return']>0: return r
+
+ lst = r['list']
+
+ prune = i.get('prune',{})
+ prune_key = prune.get('key', '')
+ prune_key_uid = prune.get('key_uid', '')
+ prune_meta_key = prune.get('meta_key', '')
+ prune_meta_key_uid = prune.get('meta_key_uid', '')
+ prune_uid = prune.get('uid', '')
+ prune_list = prune.get('list',[])
+
+ # Checking individual files inside CM entry
+ selection = []
+
+ if i.get('skip_files', False):
+ for l in lst:
+ meta = l.meta
+ full_path = l.path
+
+ meta['full_path']=full_path
+
+ add = True
+
+ if prune_key!='' and prune_key_uid!='':
+ if prune_key_uid not in meta.get(prune_key, []):
+ add = False
+
+ if add:
+ selection.append(meta)
+ else:
+ for l in lst:
+ path = l.path
+
+ main_meta = l.meta
+
+ skip = False
+
+ if prune_meta_key!='' and prune_meta_key_uid!='':
+ if prune_meta_key_uid not in main_meta.get(prune_meta_key, []):
+ skip = True
+
+ if skip:
+ continue
+
+ all_tags = main_meta.get('tags',[])
+
+ files = os.listdir(path)
+
+ for f in files:
+ if key!='' and not f.startswith(key):
+ continue
+
+ if f.startswith('_') or (not f.endswith('.json') and not f.endswith('.yaml')):
+ continue
+
+ if len(key_end)>0:
+ skip = True
+ for ke in key_end:
+ if f.endswith(ke):
+ skip = False
+ break
+ if skip:
+ continue
+
+ full_path = os.path.join(path, f)
+
+ full_path_without_ext = full_path[:-5]
+
+ r = cmind.utils.load_yaml_and_json(full_path_without_ext)
+ if r['return']>0:
+ print ('Warning: problem loading file {}'.format(full_path))
+ else:
+ meta = r['meta']
+
+ # Check base
+ r = process_base(meta, full_path)
+ if r['return']>0: return r
+ meta = r['meta']
+
+ uid = meta['uid']
+
+ # Check pruning
+ add = True
+
+ if len(prune)>0:
+ if prune_uid!='' and uid != prune_uid:
+ add = False
+
+ if add and len(prune_list)>0 and uid not in prune_list:
+ add = False
+
+ if add and prune_key!='' and prune_key_uid!='' and prune_key_uid != meta.get(prune_key, None):
+ add = False
+
+ if add:
+ meta['full_path']=full_path
+
+ add_all_tags = copy.deepcopy(all_tags)
+
+ name = meta.get('name','')
+ if name=='':
+ name = ' '.join(meta.get('tags',[]))
+ name = name.strip()
+ meta['name'] = name
+
+ file_tags = meta.get('tags', '').strip()
+ if file_tags=='':
+ if name!='':
+ add_all_tags += [v.lower() for v in name.split(' ')]
+ else:
+ add_all_tags += file_tags.split(',')
+
+ meta['all_tags']=add_all_tags
+
+ meta['main_meta']=main_meta
+
+ selection.append(meta)
+
+ return {'return':0, 'lst':lst, 'selection':selection}
+
+##################################################################################
+def process_base(meta, full_path):
+
+ global base_path, base_path_meta
+
+ _base = meta.get('_base', '')
+ if _base != '':
+ name = ''
+
+ filename = _base
+ full_path_base = os.path.dirname(full_path)
+
+ if not filename.endswith('.yaml') and not filename.endswith('.json'):
+ return {'return':1, 'error':'_base file {} in {} must be .yaml or .json'.format(filename, full_path)}
+
+ if ':' in _base:
+ x = _base.split(':')
+ name = x[0]
+
+ full_path_base = base_path.get(name, '')
+ if full_path_base == '':
+
+ # Find artifact
+ r = cmind.access({'action':'find',
+ 'automation':'cfg',
+ 'artifact':name})
+ if r['return']>0: return r
+
+ lst = r['list']
+
+ if len(lst)==0:
+ if not os.path.isfile(path):
+ return {'return':1, 'error':'_base artifact {} not found in {}'.format(name, full_path)}
+
+ full_path_base = lst[0].path
+
+ base_path[name] = full_path_base
+
+ filename = x[1]
+
+ # Load base
+ path = os.path.join(full_path_base, filename)
+
+ if not os.path.isfile(path):
+ return {'return':1, 'error':'_base file {} not found in {}'.format(filename, full_path)}
+
+ if path in base_path_meta:
+ base = copy.deepcopy(base_path_meta[path])
+ else:
+ path_without_ext = path[:-5]
+
+ r = cmind.utils.load_yaml_and_json(path_without_ext)
+ if r['return']>0: return r
+
+ base = r['meta']
+
+ base_path_meta[path]=copy.deepcopy(base)
+
+ for k in meta:
+ v = meta[k]
+
+ if k not in base:
+ base[k]=v
+ else:
+ if isinstance(v, str):
+ # Only merge a few special keys and overwrite the rest
+ if k in ['tags','name']:
+ base[k] += meta[k]
+ else:
+ base[k] = meta[k]
+
+ elif type(v) == list:
+ for vv in v:
+ base[k].append(vv)
+ elif type(v) == dict:
+ base[k].merge(v)
+
+ meta = base
+
+ return {'return':0, 'meta':meta}
diff --git a/cfg/benchmark-hardware-compute/_cm.json b/cfg/benchmark-hardware-compute/_cm.json
new file mode 100644
index 0000000000..6877b34a7e
--- /dev/null
+++ b/cfg/benchmark-hardware-compute/_cm.json
@@ -0,0 +1,10 @@
+{
+ "alias": "benchmark-hardware-compute",
+ "automation_alias": "cfg",
+ "automation_uid": "88dce9c160324c5d",
+ "tags": [
+ "benchmark",
+ "compute"
+ ],
+ "uid": "ca67f372e7294afd"
+}
diff --git a/cfg/benchmark-hardware-compute/amd-cpu-x64.json b/cfg/benchmark-hardware-compute/amd-cpu-x64.json
new file mode 100644
index 0000000000..53f295d729
--- /dev/null
+++ b/cfg/benchmark-hardware-compute/amd-cpu-x64.json
@@ -0,0 +1,6 @@
+{
+ "uid": "cdfd424c32734e38",
+ "name": "AMD - x64",
+ "tags": "cpu,x64,generic,amd",
+ "mlperf_inference_device": "cpu"
+}
diff --git a/cfg/benchmark-hardware-compute/amd-gpu.json b/cfg/benchmark-hardware-compute/amd-gpu.json
new file mode 100644
index 0000000000..d70e1d1554
--- /dev/null
+++ b/cfg/benchmark-hardware-compute/amd-gpu.json
@@ -0,0 +1,6 @@
+{
+ "uid": "d8f06040f7294319",
+ "name": "AMD - GPU",
+ "tags": "gpu,amd",
+ "mlperf_inference_device": "rocm"
+}
diff --git a/cfg/benchmark-hardware-compute/generic-cpu-arm64.json b/cfg/benchmark-hardware-compute/generic-cpu-arm64.json
new file mode 100644
index 0000000000..7af318b27b
--- /dev/null
+++ b/cfg/benchmark-hardware-compute/generic-cpu-arm64.json
@@ -0,0 +1,6 @@
+{
+ "uid":"357a972e79614903",
+ "name": "Arm - AArch64",
+ "tags": "cpu,arm64,aarch64,generic",
+ "mlperf_inference_device": "cpu"
+}
diff --git a/cfg/benchmark-hardware-compute/google-tpu.json b/cfg/benchmark-hardware-compute/google-tpu.json
new file mode 100644
index 0000000000..2bb4d22cf5
--- /dev/null
+++ b/cfg/benchmark-hardware-compute/google-tpu.json
@@ -0,0 +1,6 @@
+{
+ "uid": "b3be7ac9ef954f5a",
+ "name": "Google - TPU",
+ "tags": "tpu,google",
+ "mlperf_inference_device": "tpu"
+}
diff --git a/cfg/benchmark-hardware-compute/habana-gaudi.json b/cfg/benchmark-hardware-compute/habana-gaudi.json
new file mode 100644
index 0000000000..b6caa96554
--- /dev/null
+++ b/cfg/benchmark-hardware-compute/habana-gaudi.json
@@ -0,0 +1,6 @@
+{
+ "uid": "a42388a2a8cd412c",
+ "name": "Intel/Habana - Gauidi 2",
+ "tags": "gaudi,habana",
+ "mlperf_inference_device": "gaudi"
+}
diff --git a/cfg/benchmark-hardware-compute/intel-cpu-x64.json b/cfg/benchmark-hardware-compute/intel-cpu-x64.json
new file mode 100644
index 0000000000..2e8ab51c4a
--- /dev/null
+++ b/cfg/benchmark-hardware-compute/intel-cpu-x64.json
@@ -0,0 +1,6 @@
+{
+ "uid": "ee8c568e0ac44f2b",
+ "name": "Intel - x64",
+ "tags": "cpu,x64,generic,intel",
+ "mlperf_inference_device": "cpu"
+}
diff --git a/cfg/benchmark-hardware-compute/nvidia-gpu-jetson-orin.yaml b/cfg/benchmark-hardware-compute/nvidia-gpu-jetson-orin.yaml
new file mode 100644
index 0000000000..d8b9787c65
--- /dev/null
+++ b/cfg/benchmark-hardware-compute/nvidia-gpu-jetson-orin.yaml
@@ -0,0 +1,7 @@
+uid: fe379ecd1e054a00
+
+tags: gpu,nvidia,jetson,orin
+
+name: "Nvidia - GPU - Jetson Orin"
+
+mlperf_inference_device: cuda
diff --git a/cfg/benchmark-hardware-compute/nvidia-gpu.json b/cfg/benchmark-hardware-compute/nvidia-gpu.json
new file mode 100644
index 0000000000..5bc7582532
--- /dev/null
+++ b/cfg/benchmark-hardware-compute/nvidia-gpu.json
@@ -0,0 +1,6 @@
+{
+ "uid": "fe379ecd1e054a00",
+ "name": "Nvidia - GPU",
+ "tags": "gpu,nvidia",
+ "mlperf_inference_device": "cuda"
+}
diff --git a/cfg/benchmark-hardware-compute/qualcomm-ai100.json b/cfg/benchmark-hardware-compute/qualcomm-ai100.json
new file mode 100644
index 0000000000..aa84e57351
--- /dev/null
+++ b/cfg/benchmark-hardware-compute/qualcomm-ai100.json
@@ -0,0 +1,6 @@
+{
+ "uid": "d2ae645066664463",
+ "name": "Qualcomm - AI 100",
+ "tags": "accelerator,acc,qualcomm,ai,100,ai-100",
+ "mlperf_inference_device": "qaic"
+}
diff --git a/cfg/benchmark-hardware-compute/stm-32L4R5ZIT6U-NUCLEO-L4R5ZI.yaml b/cfg/benchmark-hardware-compute/stm-32L4R5ZIT6U-NUCLEO-L4R5ZI.yaml
new file mode 100644
index 0000000000..c6d06e9b43
--- /dev/null
+++ b/cfg/benchmark-hardware-compute/stm-32L4R5ZIT6U-NUCLEO-L4R5ZI.yaml
@@ -0,0 +1,5 @@
+uid: 2cd26d4f92ca4b85
+
+tags: stm,stm32,stm32l4r5zit6u,nucleo,l4r5zi
+
+name: "STM32L4R5ZIT6U - NUCLEO-L4R5ZI"
diff --git a/cfg/benchmark-list/_cm.json b/cfg/benchmark-list/_cm.json
new file mode 100644
index 0000000000..533c86271a
--- /dev/null
+++ b/cfg/benchmark-list/_cm.json
@@ -0,0 +1,10 @@
+{
+ "alias": "benchmark-list",
+ "automation_alias": "cfg",
+ "automation_uid": "88dce9c160324c5d",
+ "tags": [
+ "benchmark",
+ "list"
+ ],
+ "uid": "15291dfc4f904146"
+}
diff --git a/cfg/benchmark-list/loadgen-cpp.yaml b/cfg/benchmark-list/loadgen-cpp.yaml
new file mode 100644
index 0000000000..5a3f75a85a
--- /dev/null
+++ b/cfg/benchmark-list/loadgen-cpp.yaml
@@ -0,0 +1,19 @@
+uid: f594dc94b2714713
+
+tags: benchmark,run,loadgen,cpp
+
+name: "ML models with LoadGen (C++; Linux/MacOS/Windows) - dev"
+
+urls:
+- name: "GitHub dev page"
+ url: "https://github.com/mlcommons/ck/tree/master/cm-mlops/script/app-mlperf-inference-cpp"
+
+supported_compute:
+- cpu,x64
+- gpu,nvidia
+
+script_name: run-mlperf-inference-app,4a5d5b13fd7e4ac8
+
+bench_input:
+ mlperf_inference_implementation: mil
+
\ No newline at end of file
diff --git a/cfg/benchmark-list/loadgen-python.yaml b/cfg/benchmark-list/loadgen-python.yaml
new file mode 100644
index 0000000000..0ac5805022
--- /dev/null
+++ b/cfg/benchmark-list/loadgen-python.yaml
@@ -0,0 +1,16 @@
+uid: 0d6b54eb27d1454e
+
+tags: benchmark,run,loadgen,python
+
+name: "ML models with LoadGen (Python; Linux/MacOS/Windows) - dev"
+
+urls:
+- name: "GitHub dev page"
+ url: "https://github.com/mlcommons/ck/tree/master/cm-mlops/script/app-loadgen-generic-python"
+
+supported_compute:
+- cpu,x64
+- cpu,arm64
+- gpu,nvidia
+
+script_name: app-loadgen-generic-python,d3d949cc361747a6
diff --git a/cfg/benchmark-list/mlperf-abtf.yaml b/cfg/benchmark-list/mlperf-abtf.yaml
new file mode 100644
index 0000000000..a01edcbde1
--- /dev/null
+++ b/cfg/benchmark-list/mlperf-abtf.yaml
@@ -0,0 +1,18 @@
+uid: 94f0faaa0c61445d
+
+tags: benchmark,run,mlperf,abtf,mlperf-abtf
+
+name: "MLPerf ABTF - dev"
+
+urls:
+- name: "Announcement"
+ url: "https://mlcommons.org/2023/05/avcc-and-mlcommons-join-forces-to-develop-an-automotive-industry-standard/"
+- name: "MLCommons CM automation (under development)"
+ url: "https://access.cknowledge.org/playground/?action=scripts"
+
+supported_compute:
+- cpu,x64
+- cpu,arm64
+- gpu,nvidia
+
+script_name: test-abtf-ssd-pytorch,91bfc4333b054c21
diff --git a/cfg/benchmark-list/mlperf-inference.yaml b/cfg/benchmark-list/mlperf-inference.yaml
new file mode 100644
index 0000000000..e57764a486
--- /dev/null
+++ b/cfg/benchmark-list/mlperf-inference.yaml
@@ -0,0 +1,28 @@
+uid: 39877bb63fb54725
+
+tags: benchmark,run,mlperf,inference,mlperf-inference
+
+name: "MLPerf inference"
+
+urls:
+- name: "Official page"
+ url: "https://mlcommons.org/benchmarks/inference"
+- name: "GitHub dev page"
+ url: "https://github.com/mlcommons/inference"
+- name: "ArXiv paper"
+ url: "https://arxiv.org/abs/1911.02549"
+- name: "MLCommons CM automation for MLPerf inference"
+ url: "https://github.com/mlcommons/ck/tree/master/docs/mlperf/inference"
+
+script_name: run-mlperf-inference-app,4a5d5b13fd7e4ac8
+
+skip_extra_urls: true
+
+supported_compute:
+- cpu,x64
+- cpu,arm64
+- gpu,nvidia
+- gpu,amd
+- accelerator,acc,qualcomm,ai,100,ai-100
+- tpu,google
+- gaudi,habana
diff --git a/cfg/benchmark-list/mlperf-mobile.yaml b/cfg/benchmark-list/mlperf-mobile.yaml
new file mode 100644
index 0000000000..85771a44d9
--- /dev/null
+++ b/cfg/benchmark-list/mlperf-mobile.yaml
@@ -0,0 +1,14 @@
+uid: 8b2ed0897bd74267
+
+tags: benchmark,run,mlperf,mobile,mlperf-mobile
+
+name: "MLPerf mobile"
+
+urls:
+- name: "Official page"
+ url: "https://mlcommons.org/benchmarks/inference-mobile/"
+- name: "GitHub page for mobile app"
+ url: "https://github.com/mlcommons/mobile_app_open"
+
+supported_compute:
+- cpu,arm64
diff --git a/cfg/benchmark-list/mlperf-tiny.yaml b/cfg/benchmark-list/mlperf-tiny.yaml
new file mode 100644
index 0000000000..d6aeccabc5
--- /dev/null
+++ b/cfg/benchmark-list/mlperf-tiny.yaml
@@ -0,0 +1,16 @@
+uid: 28870394c19c4c37
+
+tags: benchmark,run,mlperf,tiny,mlperf-tiny
+
+name: "MLPerf tiny"
+
+urls:
+- name: "Official page"
+ url: "https://mlcommons.org/benchmarks/inference-tiny"
+- name: "GitHub dev page"
+ url: "https://github.com/mlcommons/tiny"
+- name: "MLCommons CM automation (under development)"
+ url: "https://github.com/mlcommons/ck/blob/master/docs/tutorials/reproduce-mlperf-tiny.md"
+
+supported_compute:
+- stm32
diff --git a/cfg/benchmark-list/mlperf-training.yaml b/cfg/benchmark-list/mlperf-training.yaml
new file mode 100644
index 0000000000..8b95de4f73
--- /dev/null
+++ b/cfg/benchmark-list/mlperf-training.yaml
@@ -0,0 +1,18 @@
+uid: 59311e6098c14b22
+
+tags: benchmark,run,mlperf,training,mlperf-training
+
+name: "MLPerf training"
+
+urls:
+- name: "Official page"
+ url: "https://mlcommons.org/benchmarks/training"
+- name: "GitHub dev page"
+ url: "https://github.com/mlcommons/training"
+- name: "MLCommons CM automation (under development)"
+ url: "https://github.com/mlcommons/ck/blob/master/docs/tutorials/reproduce-mlperf-training.md"
+
+supported_compute:
+- cpu,x64
+- gpu,nvidia
+- tpu,google
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/_cm.yaml b/cfg/benchmark-run-mlperf-inference-v3.1/_cm.yaml
new file mode 100644
index 0000000000..334bd4d94c
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/_cm.yaml
@@ -0,0 +1,45 @@
+alias: benchmark-run-mlperf-inference-v3.1
+uid: 8eb42e27ec984185
+
+automation_alias: cfg
+automation_uid: 88dce9c160324c5d
+
+tags:
+- benchmark
+- run
+- mlperf
+- inference
+- v3.1
+
+name: "MLPerf inference - v3.1"
+
+supported_compute:
+- ee8c568e0ac44f2b
+- fe379ecd1e054a00
+
+bench_uid: 39877bb63fb54725
+
+view_dimensions:
+- - input.device
+ - "MLPerf device"
+- - input.implementation
+ - "MLPerf implementation"
+- - input.backend
+ - "MLPerf backend"
+- - input.model
+ - "MLPerf model"
+- - input.precision
+ - "Model precision"
+- - input.scenario
+ - "MLPerf scenario"
+- - input.host_os
+ - "Host OS"
+- - output.state.cm-mlperf-inference-results-last.performance
+ - "Got performance"
+ - "tick"
+- - output.state.cm-mlperf-inference-results-last.accuracy
+ - "Got accuracy"
+ - "tick"
+- - output.state.cm-mlperf-inference-results-last.power
+ - "Got energy"
+ - "tick"
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-005147815bf840b8-input.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-005147815bf840b8-input.json
new file mode 100644
index 0000000000..d1f187f498
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-005147815bf840b8-input.json
@@ -0,0 +1,54 @@
+{
+ "action": "run",
+ "automation": "script",
+ "tags": "run-mlperf-inference,_r4.0,_performance-only,_short",
+ "division": "open",
+ "category": "datacenter",
+ "device": "qaic",
+ "model": "bert-99.9",
+ "precision": "float16",
+ "implementation": "qualcomm",
+ "backend": "glow",
+ "scenario": "Offline",
+ "execution_mode": "test",
+ "power": "no",
+ "adr": {
+ "python": {
+ "version_min": "3.8"
+ }
+ },
+ "clean": true,
+ "compliance": "no",
+ "j": true,
+ "jf": "run-0eeb9799b12b488f",
+ "quiet": true,
+ "time": true,
+ "host_os": "linux",
+ "cmd": [
+ "--tags=run-mlperf-inference,_r4.0,_performance-only,_short",
+ "--division=open",
+ "--category=datacenter",
+ "--device=qaic",
+ "--model=bert-99.9",
+ "--precision=float16",
+ "--implementation=qualcomm",
+ "--backend=glow",
+ "--scenario=Offline",
+ "--execution_mode=test",
+ "--power=no",
+ "--adr.python.version_min=3.8",
+ "--clean",
+ "--compliance=no",
+ "--j",
+ "--quiet",
+ "--time",
+ "--host_os=linux"
+ ],
+ "out": "con",
+ "parsed_automation": [
+ [
+ "script",
+ "5b4e0237da074764"
+ ]
+ ]
+}
\ No newline at end of file
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-005147815bf840b8-meta.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-005147815bf840b8-meta.json
new file mode 100644
index 0000000000..a9243fe3ce
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-005147815bf840b8-meta.json
@@ -0,0 +1,9 @@
+{
+ "uid": "800fe1b33ca443da",
+ "compute_uid": "d2ae645066664463",
+ "bench_uid": "39877bb63fb54725",
+ "date_time": "2024-02-20T15:25:03.786139",
+ "functional": true,
+ "reproduced": true,
+ "support_docker": true
+}
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-005147815bf840b8-output.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-005147815bf840b8-output.json
new file mode 100644
index 0000000000..a07a992e76
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-005147815bf840b8-output.json
@@ -0,0 +1,11 @@
+{
+ "return": 0,
+ "env": {},
+ "new_env": {},
+ "state": {
+ "cm-mlperf-inference-results-last": {
+ "performance": "tested-will-be-added-in-v4.0",
+ "performance_valid": true
+ }
+ }
+}
\ No newline at end of file
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-0eeb9799b12b488f-input.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-0eeb9799b12b488f-input.json
new file mode 100644
index 0000000000..1fe11d6d51
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-0eeb9799b12b488f-input.json
@@ -0,0 +1,55 @@
+{
+ "action": "run",
+ "automation": "script",
+ "tags": "run-mlperf-inference,_r4.0,_performance-only,_short",
+ "division": "open",
+ "category": "edge",
+ "device": "cpu",
+ "model": "bert-99",
+ "precision": "int8",
+ "implementation": "reference",
+ "backend": "deepsparse",
+ "scenario": "Offline",
+ "execution_mode": "test",
+ "power": "no",
+ "adr": {
+ "python": {
+ "version_min": "3.8"
+ }
+ },
+ "clean": true,
+ "compliance": "no",
+ "j": true,
+ "jf": "run-0eeb9799b12b488f",
+ "quiet": true,
+ "time": true,
+ "host_os": "linux",
+ "cmd": [
+ "--tags=run-mlperf-inference,_r4.0,_performance-only,_short",
+ "--division=open",
+ "--category=edge",
+ "--device=cpu",
+ "--model=bert-99",
+ "--precision=int8",
+ "--implementation=reference",
+ "--backend=deepsparse",
+ "--scenario=Offline",
+ "--execution_mode=test",
+ "--power=no",
+ "--adr.python.version_min=3.8",
+ "--clean",
+ "--compliance=no",
+ "--j",
+ "--jf=run-0eeb9799b12b488f",
+ "--quiet",
+ "--time",
+ "--host_os=linux"
+ ],
+ "out": "con",
+ "parsed_automation": [
+ [
+ "script",
+ "5b4e0237da074764"
+ ]
+ ]
+}
\ No newline at end of file
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-0eeb9799b12b488f-meta.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-0eeb9799b12b488f-meta.json
new file mode 100644
index 0000000000..dbd58de078
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-0eeb9799b12b488f-meta.json
@@ -0,0 +1,9 @@
+{
+ "uid": "12242042335e4bc8",
+ "compute_uid": "ee8c568e0ac44f2b",
+ "bench_uid": "39877bb63fb54725",
+ "date_time": "2024-02-20T15:15:53.984671",
+ "functional": true,
+ "reproduced": true,
+ "support_docker": true
+}
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-0eeb9799b12b488f-output.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-0eeb9799b12b488f-output.json
new file mode 100644
index 0000000000..519ddf3a3b
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-0eeb9799b12b488f-output.json
@@ -0,0 +1,137 @@
+{
+ "return": 0,
+ "env": {},
+ "new_env": {},
+ "state": {
+ "app_mlperf_inference_log_summary": {
+ "sut name": "PySUT",
+ "scenario": "Offline",
+ "mode": "PerformanceOnly",
+ "samples per second": "12.4548",
+ "result is": "VALID",
+ "min duration satisfied": "Yes",
+ "min queries satisfied": "Yes",
+ "early stopping satisfied": "Yes",
+ "min latency (ns)": "64039368",
+ "max latency (ns)": "802905050",
+ "mean latency (ns)": "372956875",
+ "50.00 percentile latency (ns)": "378435867",
+ "90.00 percentile latency (ns)": "802905050",
+ "95.00 percentile latency (ns)": "802905050",
+ "97.00 percentile latency (ns)": "802905050",
+ "99.00 percentile latency (ns)": "802905050",
+ "99.90 percentile latency (ns)": "802905050",
+ "samples_per_query": "10",
+ "target_qps": "1",
+ "target_latency (ns)": "0",
+ "max_async_queries": "1",
+ "min_duration (ms)": "0",
+ "max_duration (ms)": "0",
+ "min_query_count": "1",
+ "max_query_count": "10",
+ "qsl_rng_seed": "13281865557512327830",
+ "sample_index_rng_seed": "198141574272810017",
+ "schedule_rng_seed": "7575108116881280410",
+ "accuracy_log_rng_seed": "0",
+ "accuracy_log_probability": "0",
+ "accuracy_log_sampling_target": "0",
+ "print_timestamps": "0",
+ "performance_issue_unique": "0",
+ "performance_issue_same": "0",
+ "performance_issue_same_index": "0",
+ "performance_sample_count": "10833"
+ },
+ "app_mlperf_inference_measurements": {
+ "starting_weights_filename": "https://github.com/mlcommons/inference_results_v2.1/raw/master/open/NeuralMagic/code/bert/deepsparse/models/oBERT-Large_95sparse_block4_qat.onnx.tar.xz",
+ "retraining": "no",
+ "input_data_types": "fp32",
+ "weight_data_types": "fp32",
+ "weight_transformations": "none"
+ },
+ "cm-mlperf-inference-results": {
+ "ip_172_31_89_56-reference-cpu-deepsparse-vdefault-default_config": {
+ "bert-99": {
+ "Offline": {
+ "performance": "12.455",
+ "performance_valid": true
+ }
+ }
+ }
+ },
+ "cm-mlperf-inference-results-last": {
+ "performance": "12.455",
+ "performance_valid": true
+ }
+ },
+ "new_state": {
+ "app_mlperf_inference_log_summary": {
+ "sut name": "PySUT",
+ "scenario": "Offline",
+ "mode": "PerformanceOnly",
+ "samples per second": "12.4548",
+ "result is": "VALID",
+ "min duration satisfied": "Yes",
+ "min queries satisfied": "Yes",
+ "early stopping satisfied": "Yes",
+ "min latency (ns)": "64039368",
+ "max latency (ns)": "802905050",
+ "mean latency (ns)": "372956875",
+ "50.00 percentile latency (ns)": "378435867",
+ "90.00 percentile latency (ns)": "802905050",
+ "95.00 percentile latency (ns)": "802905050",
+ "97.00 percentile latency (ns)": "802905050",
+ "99.00 percentile latency (ns)": "802905050",
+ "99.90 percentile latency (ns)": "802905050",
+ "samples_per_query": "10",
+ "target_qps": "1",
+ "target_latency (ns)": "0",
+ "max_async_queries": "1",
+ "min_duration (ms)": "0",
+ "max_duration (ms)": "0",
+ "min_query_count": "1",
+ "max_query_count": "10",
+ "qsl_rng_seed": "13281865557512327830",
+ "sample_index_rng_seed": "198141574272810017",
+ "schedule_rng_seed": "7575108116881280410",
+ "accuracy_log_rng_seed": "0",
+ "accuracy_log_probability": "0",
+ "accuracy_log_sampling_target": "0",
+ "print_timestamps": "0",
+ "performance_issue_unique": "0",
+ "performance_issue_same": "0",
+ "performance_issue_same_index": "0",
+ "performance_sample_count": "10833"
+ },
+ "app_mlperf_inference_measurements": {
+ "starting_weights_filename": "https://github.com/mlcommons/inference_results_v2.1/raw/master/open/NeuralMagic/code/bert/deepsparse/models/oBERT-Large_95sparse_block4_qat.onnx.tar.xz",
+ "retraining": "no",
+ "input_data_types": "fp32",
+ "weight_data_types": "fp32",
+ "weight_transformations": "none"
+ },
+ "cm-mlperf-inference-results": {
+ "ip_172_31_89_56-reference-cpu-deepsparse-vdefault-default_config": {
+ "bert-99": {
+ "Offline": {
+ "performance": "12.455",
+ "performance_valid": true
+ }
+ }
+ }
+ },
+ "cm-mlperf-inference-results-last": {
+ "performance": "12.455",
+ "performance_valid": true
+ }
+ },
+ "deps": [
+ "detect,os",
+ "detect,cpu",
+ "get,python3",
+ "get,mlcommons,inference,src",
+ "get,sut,description",
+ "get,mlperf,inference,results,dir",
+ "install,pip-package,for-cmind-python,_package.tabulate",
+ "get,mlperf,inference,utils"
+ ]
+}
\ No newline at end of file
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-52c1d43172664ed0-input.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-52c1d43172664ed0-input.json
new file mode 100644
index 0000000000..b02bb76950
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-52c1d43172664ed0-input.json
@@ -0,0 +1,55 @@
+{
+ "action": "run",
+ "automation": "script",
+ "tags": "run-mlperf-inference,_r4.0,_performance-only,_short",
+ "division": "open",
+ "category": "edge",
+ "device": "cpu",
+ "model": "bert-99.9",
+ "precision": "float32",
+ "implementation": "reference",
+ "backend": "onnxruntime",
+ "scenario": "Offline",
+ "execution_mode": "test",
+ "power": "no",
+ "adr": {
+ "python": {
+ "version_min": "3.8"
+ }
+ },
+ "clean": true,
+ "compliance": "no",
+ "j": true,
+ "jf": "run-52c1d43172664ed0",
+ "quiet": true,
+ "time": true,
+ "host_os": "linux",
+ "cmd": [
+ "--tags=run-mlperf-inference,_r4.0,_performance-only,_short",
+ "--division=open",
+ "--category=edge",
+ "--device=cpu",
+ "--model=bert-99.9",
+ "--precision=float32",
+ "--implementation=reference",
+ "--backend=onnxruntime",
+ "--scenario=Offline",
+ "--execution_mode=test",
+ "--power=no",
+ "--adr.python.version_min=3.8",
+ "--clean",
+ "--compliance=no",
+ "--j",
+ "--jf=run-52c1d43172664ed0",
+ "--quiet",
+ "--time",
+ "--host_os=linux"
+ ],
+ "out": "con",
+ "parsed_automation": [
+ [
+ "script",
+ "5b4e0237da074764"
+ ]
+ ]
+}
\ No newline at end of file
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-52c1d43172664ed0-meta.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-52c1d43172664ed0-meta.json
new file mode 100644
index 0000000000..7b7b419f34
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-52c1d43172664ed0-meta.json
@@ -0,0 +1,9 @@
+{
+ "uid": "52c1d43172664ed0",
+ "compute_uid": "ee8c568e0ac44f2b",
+ "bench_uid": "39877bb63fb54725",
+ "date_time": "2024-02-20T15:04:13.424211",
+ "functional": true,
+ "reproduced": true,
+ "support_docker": true
+}
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-52c1d43172664ed0-output.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-52c1d43172664ed0-output.json
new file mode 100644
index 0000000000..c250f0c626
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-52c1d43172664ed0-output.json
@@ -0,0 +1,137 @@
+{
+ "return": 0,
+ "env": {},
+ "new_env": {},
+ "state": {
+ "app_mlperf_inference_log_summary": {
+ "sut name": "PySUT",
+ "scenario": "Offline",
+ "mode": "PerformanceOnly",
+ "samples per second": "0.615377",
+ "result is": "VALID",
+ "min duration satisfied": "Yes",
+ "min queries satisfied": "Yes",
+ "early stopping satisfied": "Yes",
+ "min latency (ns)": "4705323615",
+ "max latency (ns)": "16250190121",
+ "mean latency (ns)": "10456508889",
+ "50.00 percentile latency (ns)": "10133038152",
+ "90.00 percentile latency (ns)": "16250190121",
+ "95.00 percentile latency (ns)": "16250190121",
+ "97.00 percentile latency (ns)": "16250190121",
+ "99.00 percentile latency (ns)": "16250190121",
+ "99.90 percentile latency (ns)": "16250190121",
+ "samples_per_query": "10",
+ "target_qps": "1",
+ "target_latency (ns)": "0",
+ "max_async_queries": "1",
+ "min_duration (ms)": "0",
+ "max_duration (ms)": "0",
+ "min_query_count": "1",
+ "max_query_count": "10",
+ "qsl_rng_seed": "13281865557512327830",
+ "sample_index_rng_seed": "198141574272810017",
+ "schedule_rng_seed": "7575108116881280410",
+ "accuracy_log_rng_seed": "0",
+ "accuracy_log_probability": "0",
+ "accuracy_log_sampling_target": "0",
+ "print_timestamps": "0",
+ "performance_issue_unique": "0",
+ "performance_issue_same": "0",
+ "performance_issue_same_index": "0",
+ "performance_sample_count": "10833"
+ },
+ "app_mlperf_inference_measurements": {
+ "starting_weights_filename": "https://armi.in/files/model.onnx",
+ "retraining": "no",
+ "input_data_types": "fp32",
+ "weight_data_types": "fp32",
+ "weight_transformations": "none"
+ },
+ "cm-mlperf-inference-results": {
+ "ip_172_31_89_56-reference-cpu-onnxruntime-v1.17.0-default_config": {
+ "bert-99.9": {
+ "Offline": {
+ "performance": "0.615",
+ "performance_valid": true
+ }
+ }
+ }
+ },
+ "cm-mlperf-inference-results-last": {
+ "performance": "0.615",
+ "performance_valid": true
+ }
+ },
+ "new_state": {
+ "app_mlperf_inference_log_summary": {
+ "sut name": "PySUT",
+ "scenario": "Offline",
+ "mode": "PerformanceOnly",
+ "samples per second": "0.615377",
+ "result is": "VALID",
+ "min duration satisfied": "Yes",
+ "min queries satisfied": "Yes",
+ "early stopping satisfied": "Yes",
+ "min latency (ns)": "4705323615",
+ "max latency (ns)": "16250190121",
+ "mean latency (ns)": "10456508889",
+ "50.00 percentile latency (ns)": "10133038152",
+ "90.00 percentile latency (ns)": "16250190121",
+ "95.00 percentile latency (ns)": "16250190121",
+ "97.00 percentile latency (ns)": "16250190121",
+ "99.00 percentile latency (ns)": "16250190121",
+ "99.90 percentile latency (ns)": "16250190121",
+ "samples_per_query": "10",
+ "target_qps": "1",
+ "target_latency (ns)": "0",
+ "max_async_queries": "1",
+ "min_duration (ms)": "0",
+ "max_duration (ms)": "0",
+ "min_query_count": "1",
+ "max_query_count": "10",
+ "qsl_rng_seed": "13281865557512327830",
+ "sample_index_rng_seed": "198141574272810017",
+ "schedule_rng_seed": "7575108116881280410",
+ "accuracy_log_rng_seed": "0",
+ "accuracy_log_probability": "0",
+ "accuracy_log_sampling_target": "0",
+ "print_timestamps": "0",
+ "performance_issue_unique": "0",
+ "performance_issue_same": "0",
+ "performance_issue_same_index": "0",
+ "performance_sample_count": "10833"
+ },
+ "app_mlperf_inference_measurements": {
+ "starting_weights_filename": "https://armi.in/files/model.onnx",
+ "retraining": "no",
+ "input_data_types": "fp32",
+ "weight_data_types": "fp32",
+ "weight_transformations": "none"
+ },
+ "cm-mlperf-inference-results": {
+ "ip_172_31_89_56-reference-cpu-onnxruntime-v1.17.0-default_config": {
+ "bert-99.9": {
+ "Offline": {
+ "performance": "0.615",
+ "performance_valid": true
+ }
+ }
+ }
+ },
+ "cm-mlperf-inference-results-last": {
+ "performance": "0.615",
+ "performance_valid": true
+ }
+ },
+ "deps": [
+ "detect,os",
+ "detect,cpu",
+ "get,python3",
+ "get,mlcommons,inference,src",
+ "get,sut,description",
+ "get,mlperf,inference,results,dir",
+ "install,pip-package,for-cmind-python,_package.tabulate",
+ "get,mlperf,inference,utils"
+ ]
+}
\ No newline at end of file
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-66cce585ff0242bc-input.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-66cce585ff0242bc-input.json
new file mode 100644
index 0000000000..2addebee94
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-66cce585ff0242bc-input.json
@@ -0,0 +1,56 @@
+{
+ "action": "run",
+ "automation": "script",
+ "tags": "run-mlperf-inference,_r4.0,_submission,_short",
+ "division": "open",
+ "category": "edge",
+ "device": "cuda",
+ "model": "bert-99",
+ "host_os": "linux",
+ "precision": "float32",
+ "implementation": "nvidia-original",
+ "backend": "tensorrt",
+ "scenario": "Offline",
+ "execution_mode": "test",
+ "submitter": "CTuning",
+ "power": "no",
+ "adr": {
+ "python": {
+ "version_min": "3.8"
+ }
+ },
+ "compliance": "no",
+ "j": true,
+ "time": true,
+ "clean": true,
+ "quiet": true,
+ "jf": "mlperf-inference-results",
+ "cmd": [
+ "--tags=run-mlperf-inference,_r4.0,_submission,_short",
+ "--division=open",
+ "--category=edge",
+ "--device=cuda",
+ "--model=bert-99",
+ "--precision=float32",
+ "--implementation=nvidia-original",
+ "--backend=tensorrt",
+ "--scenario=Offline",
+ "--execution_mode=test",
+ "--submitter=CTuning",
+ "--power=no",
+ "--adr.python.version_min=3.8",
+ "--compliance=no",
+ "--j",
+ "--time",
+ "--clean",
+ "--quiet",
+ "--jf=mlperf-inference-results"
+ ],
+ "out": "con",
+ "parsed_automation": [
+ [
+ "script",
+ "5b4e0237da074764"
+ ]
+ ]
+}
\ No newline at end of file
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-66cce585ff0242bc-meta.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-66cce585ff0242bc-meta.json
new file mode 100644
index 0000000000..0e5dcba611
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-66cce585ff0242bc-meta.json
@@ -0,0 +1,9 @@
+{
+ "uid": "66cce585ff0242bc",
+ "compute_uid": "fe379ecd1e054a00",
+ "bench_uid": "39877bb63fb54725",
+ "date_time": "2024-02-20T16:23:59.000629",
+ "functional": true,
+ "reproduced": true,
+ "support_docker": true
+}
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-6a07cf881dee462a-input.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-6a07cf881dee462a-input.json
new file mode 100644
index 0000000000..82a0cc826b
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-6a07cf881dee462a-input.json
@@ -0,0 +1,56 @@
+{
+ "action": "run",
+ "automation": "script",
+ "tags": "run-mlperf-inference,_r4.0,_submission,_short",
+ "division": "open",
+ "category": "edge",
+ "device": "cpu",
+ "model": "bert-99",
+ "host_os": "linux",
+ "precision": "float32",
+ "implementation": "reference",
+ "backend": "tf",
+ "scenario": "Offline",
+ "execution_mode": "test",
+ "submitter": "CTuning",
+ "power": "no",
+ "adr": {
+ "python": {
+ "version_min": "3.8"
+ }
+ },
+ "compliance": "no",
+ "j": true,
+ "time": true,
+ "clean": true,
+ "quiet": true,
+ "jf": "mlperf-inference-results",
+ "cmd": [
+ "--tags=run-mlperf-inference,_r4.0,_submission,_short",
+ "--division=open",
+ "--category=edge",
+ "--device=cpu",
+ "--model=bert-99",
+ "--precision=float32",
+ "--implementation=reference",
+ "--backend=tf",
+ "--scenario=Offline",
+ "--execution_mode=test",
+ "--submitter=CTuning",
+ "--power=no",
+ "--adr.python.version_min=3.8",
+ "--compliance=no",
+ "--j",
+ "--time",
+ "--clean",
+ "--quiet",
+ "--jf=mlperf-inference-results"
+ ],
+ "out": "con",
+ "parsed_automation": [
+ [
+ "script",
+ "5b4e0237da074764"
+ ]
+ ]
+}
\ No newline at end of file
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-6a07cf881dee462a-meta.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-6a07cf881dee462a-meta.json
new file mode 100644
index 0000000000..3bde194aba
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-6a07cf881dee462a-meta.json
@@ -0,0 +1,9 @@
+{
+ "uid": "6a07cf881dee462a",
+ "compute_uid": "ee8c568e0ac44f2b",
+ "bench_uid": "39877bb63fb54725",
+ "date_time": "2024-02-20T15:33:11.932584",
+ "functional": false,
+ "reproduced": false,
+ "support_docker": false
+}
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-7d80f464b2274742-input.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-7d80f464b2274742-input.json
new file mode 100644
index 0000000000..de6e2b2c93
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-7d80f464b2274742-input.json
@@ -0,0 +1,55 @@
+{
+ "action": "run",
+ "automation": "script",
+ "tags": "run-mlperf-inference,_r4.0,_performance-only,_short",
+ "division": "open",
+ "category": "edge",
+ "device": "cuda",
+ "model": "bert-99",
+ "precision": "float32",
+ "implementation": "reference",
+ "backend": "onnxruntime",
+ "scenario": "Offline",
+ "execution_mode": "test",
+ "power": "no",
+ "adr": {
+ "python": {
+ "version_min": "3.8"
+ }
+ },
+ "clean": true,
+ "compliance": "no",
+ "j": true,
+ "jf": "run-7d80f464b2274742",
+ "quiet": true,
+ "time": true,
+ "host_os": "linux",
+ "cmd": [
+ "--tags=run-mlperf-inference,_r4.0,_performance-only,_short",
+ "--division=open",
+ "--category=edge",
+ "--device=cuda",
+ "--model=bert-99",
+ "--precision=float32",
+ "--implementation=reference",
+ "--backend=onnxruntime",
+ "--scenario=Offline",
+ "--execution_mode=test",
+ "--power=no",
+ "--adr.python.version_min=3.8",
+ "--clean",
+ "--compliance=no",
+ "--j",
+ "--jf=run-7d80f464b2274742",
+ "--quiet",
+ "--time",
+ "--host_os=linux"
+ ],
+ "out": "con",
+ "parsed_automation": [
+ [
+ "script",
+ "5b4e0237da074764"
+ ]
+ ]
+}
\ No newline at end of file
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-7d80f464b2274742-meta.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-7d80f464b2274742-meta.json
new file mode 100644
index 0000000000..eadf7f2014
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-7d80f464b2274742-meta.json
@@ -0,0 +1,10 @@
+{
+ "uid": "7d80f464b2274742",
+ "compute_uid": "fe379ecd1e054a00",
+ "bench_uid": "39877bb63fb54725",
+ "date_time": "2024-02-20T16:04:27.903539",
+ "notes":"ONNX 1.15.0 worked; ONNX 1.17.0 did not work",
+ "functional": true,
+ "reproduced": true,
+ "support_docker": false
+}
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-7d80f464b2274742-output.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-7d80f464b2274742-output.json
new file mode 100644
index 0000000000..5d8f74da15
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-7d80f464b2274742-output.json
@@ -0,0 +1,137 @@
+{
+ "return": 0,
+ "env": {},
+ "new_env": {},
+ "state": {
+ "app_mlperf_inference_log_summary": {
+ "sut name": "PySUT",
+ "scenario": "Offline",
+ "mode": "PerformanceOnly",
+ "samples per second": "13.1969",
+ "result is": "VALID",
+ "min duration satisfied": "Yes",
+ "min queries satisfied": "Yes",
+ "early stopping satisfied": "Yes",
+ "min latency (ns)": "295840204",
+ "max latency (ns)": "757755274",
+ "mean latency (ns)": "521501098",
+ "50.00 percentile latency (ns)": "497153427",
+ "90.00 percentile latency (ns)": "757755274",
+ "95.00 percentile latency (ns)": "757755274",
+ "97.00 percentile latency (ns)": "757755274",
+ "99.00 percentile latency (ns)": "757755274",
+ "99.90 percentile latency (ns)": "757755274",
+ "samples_per_query": "10",
+ "target_qps": "1",
+ "target_latency (ns)": "0",
+ "max_async_queries": "1",
+ "min_duration (ms)": "0",
+ "max_duration (ms)": "0",
+ "min_query_count": "1",
+ "max_query_count": "10",
+ "qsl_rng_seed": "13281865557512327830",
+ "sample_index_rng_seed": "198141574272810017",
+ "schedule_rng_seed": "7575108116881280410",
+ "accuracy_log_rng_seed": "0",
+ "accuracy_log_probability": "0",
+ "accuracy_log_sampling_target": "0",
+ "print_timestamps": "0",
+ "performance_issue_unique": "0",
+ "performance_issue_same": "0",
+ "performance_issue_same_index": "0",
+ "performance_sample_count": "10833"
+ },
+ "app_mlperf_inference_measurements": {
+ "starting_weights_filename": "https://armi.in/files/model.onnx",
+ "retraining": "no",
+ "input_data_types": "fp32",
+ "weight_data_types": "fp32",
+ "weight_transformations": "none"
+ },
+ "cm-mlperf-inference-results": {
+ "ip_172_31_89_56-reference-gpu-onnxruntime-v1.15.0-default_config": {
+ "bert-99": {
+ "Offline": {
+ "performance": "13.197",
+ "performance_valid": true
+ }
+ }
+ }
+ },
+ "cm-mlperf-inference-results-last": {
+ "performance": "13.197",
+ "performance_valid": true
+ }
+ },
+ "new_state": {
+ "app_mlperf_inference_log_summary": {
+ "sut name": "PySUT",
+ "scenario": "Offline",
+ "mode": "PerformanceOnly",
+ "samples per second": "13.1969",
+ "result is": "VALID",
+ "min duration satisfied": "Yes",
+ "min queries satisfied": "Yes",
+ "early stopping satisfied": "Yes",
+ "min latency (ns)": "295840204",
+ "max latency (ns)": "757755274",
+ "mean latency (ns)": "521501098",
+ "50.00 percentile latency (ns)": "497153427",
+ "90.00 percentile latency (ns)": "757755274",
+ "95.00 percentile latency (ns)": "757755274",
+ "97.00 percentile latency (ns)": "757755274",
+ "99.00 percentile latency (ns)": "757755274",
+ "99.90 percentile latency (ns)": "757755274",
+ "samples_per_query": "10",
+ "target_qps": "1",
+ "target_latency (ns)": "0",
+ "max_async_queries": "1",
+ "min_duration (ms)": "0",
+ "max_duration (ms)": "0",
+ "min_query_count": "1",
+ "max_query_count": "10",
+ "qsl_rng_seed": "13281865557512327830",
+ "sample_index_rng_seed": "198141574272810017",
+ "schedule_rng_seed": "7575108116881280410",
+ "accuracy_log_rng_seed": "0",
+ "accuracy_log_probability": "0",
+ "accuracy_log_sampling_target": "0",
+ "print_timestamps": "0",
+ "performance_issue_unique": "0",
+ "performance_issue_same": "0",
+ "performance_issue_same_index": "0",
+ "performance_sample_count": "10833"
+ },
+ "app_mlperf_inference_measurements": {
+ "starting_weights_filename": "https://armi.in/files/model.onnx",
+ "retraining": "no",
+ "input_data_types": "fp32",
+ "weight_data_types": "fp32",
+ "weight_transformations": "none"
+ },
+ "cm-mlperf-inference-results": {
+ "ip_172_31_89_56-reference-gpu-onnxruntime-v1.15.0-default_config": {
+ "bert-99": {
+ "Offline": {
+ "performance": "13.197",
+ "performance_valid": true
+ }
+ }
+ }
+ },
+ "cm-mlperf-inference-results-last": {
+ "performance": "13.197",
+ "performance_valid": true
+ }
+ },
+ "deps": [
+ "detect,os",
+ "detect,cpu",
+ "get,python3",
+ "get,mlcommons,inference,src",
+ "get,sut,description",
+ "get,mlperf,inference,results,dir",
+ "install,pip-package,for-cmind-python,_package.tabulate",
+ "get,mlperf,inference,utils"
+ ]
+}
\ No newline at end of file
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-7f094c244ebb4985-input.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-7f094c244ebb4985-input.json
new file mode 100644
index 0000000000..c72a9f6a27
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-7f094c244ebb4985-input.json
@@ -0,0 +1,56 @@
+{
+ "action": "run",
+ "automation": "script",
+ "tags": "run-mlperf-inference,_r4.0,_submission,_short",
+ "division": "open",
+ "category": "edge",
+ "host_os": "linux",
+ "device": "cpu",
+ "model": "retinanet",
+ "precision": "float32",
+ "implementation": "reference",
+ "backend": "onnxruntime",
+ "scenario": "Offline",
+ "execution_mode": "test",
+ "submitter": "CTuning",
+ "power": "no",
+ "adr": {
+ "python": {
+ "version_min": "3.8"
+ }
+ },
+ "compliance": "no",
+ "j": true,
+ "time": true,
+ "clean": true,
+ "quiet": true,
+ "jf": "mlperf-inference-results",
+ "cmd": [
+ "--tags=run-mlperf-inference,_r4.0,_submission,_short",
+ "--division=open",
+ "--category=edge",
+ "--device=cpu",
+ "--model=retinanet",
+ "--precision=float32",
+ "--implementation=reference",
+ "--backend=onnxruntime",
+ "--scenario=Offline",
+ "--execution_mode=test",
+ "--submitter=CTuning",
+ "--power=no",
+ "--adr.python.version_min=3.8",
+ "--compliance=no",
+ "--j",
+ "--time",
+ "--clean",
+ "--quiet",
+ "--jf=mlperf-inference-results"
+ ],
+ "out": "con",
+ "parsed_automation": [
+ [
+ "script",
+ "5b4e0237da074764"
+ ]
+ ]
+}
\ No newline at end of file
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-7f094c244ebb4985-meta.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-7f094c244ebb4985-meta.json
new file mode 100644
index 0000000000..2b86368970
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-7f094c244ebb4985-meta.json
@@ -0,0 +1,9 @@
+{
+ "uid": "7f094c244ebb4985",
+ "compute_uid": "ee8c568e0ac44f2b",
+ "bench_uid": "39877bb63fb54725",
+ "date_time": "2024-02-18",
+ "functional": true,
+ "reproduced": true,
+ "support_docker": true
+}
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-7f094c244ebb4985-output.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-7f094c244ebb4985-output.json
new file mode 100644
index 0000000000..cae36b057d
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-7f094c244ebb4985-output.json
@@ -0,0 +1,146 @@
+{
+ "return": 0,
+ "env": {},
+ "new_env": {},
+ "state": {
+ "app_mlperf_inference_log_summary": {
+ "sut name": "PySUT",
+ "scenario": "Offline",
+ "mode": "PerformanceOnly",
+ "samples per second": "0.808629",
+ "result is": "VALID",
+ "min duration satisfied": "Yes",
+ "min queries satisfied": "Yes",
+ "early stopping satisfied": "Yes",
+ "min latency (ns)": "963485100",
+ "max latency (ns)": "12366604800",
+ "mean latency (ns)": "5961694610",
+ "50.00 percentile latency (ns)": "6164791100",
+ "90.00 percentile latency (ns)": "12366604800",
+ "95.00 percentile latency (ns)": "12366604800",
+ "97.00 percentile latency (ns)": "12366604800",
+ "99.00 percentile latency (ns)": "12366604800",
+ "99.90 percentile latency (ns)": "12366604800",
+ "samples_per_query": "10",
+ "target_qps": "1",
+ "target_latency (ns)": "0",
+ "max_async_queries": "1",
+ "min_duration (ms)": "0",
+ "max_duration (ms)": "0",
+ "min_query_count": "1",
+ "max_query_count": "10",
+ "qsl_rng_seed": "13281865557512327830",
+ "sample_index_rng_seed": "198141574272810017",
+ "schedule_rng_seed": "7575108116881280410",
+ "accuracy_log_rng_seed": "0",
+ "accuracy_log_probability": "0",
+ "accuracy_log_sampling_target": "0",
+ "print_timestamps": "0",
+ "performance_issue_unique": "0",
+ "performance_issue_same": "0",
+ "performance_issue_same_index": "0",
+ "performance_sample_count": "64"
+ },
+ "app_mlperf_inference_measurements": {
+ "starting_weights_filename": "resnext50_32x4d_fpn.onnx",
+ "retraining": "no",
+ "input_data_types": "fp32",
+ "weight_data_types": "fp32",
+ "weight_transformations": "no"
+ },
+ "cm-mlperf-inference-results": {
+ "FGG_LENOVO_P14S-reference-cpu-onnxruntime-v1.16.0-default_config": {
+ "retinanet": {
+ "Offline": {
+ "performance": "0.809",
+ "performance_valid": true,
+ "accuracy": "49.593",
+ "accuracy_valid": true
+ }
+ }
+ }
+ },
+ "cm-mlperf-inference-results-last": {
+ "performance": "0.809",
+ "performance_valid": true,
+ "accuracy": "49.593",
+ "accuracy_valid": true
+ }
+ },
+ "new_state": {
+ "app_mlperf_inference_log_summary": {
+ "sut name": "PySUT",
+ "scenario": "Offline",
+ "mode": "PerformanceOnly",
+ "samples per second": "0.808629",
+ "result is": "VALID",
+ "min duration satisfied": "Yes",
+ "min queries satisfied": "Yes",
+ "early stopping satisfied": "Yes",
+ "min latency (ns)": "963485100",
+ "max latency (ns)": "12366604800",
+ "mean latency (ns)": "5961694610",
+ "50.00 percentile latency (ns)": "6164791100",
+ "90.00 percentile latency (ns)": "12366604800",
+ "95.00 percentile latency (ns)": "12366604800",
+ "97.00 percentile latency (ns)": "12366604800",
+ "99.00 percentile latency (ns)": "12366604800",
+ "99.90 percentile latency (ns)": "12366604800",
+ "samples_per_query": "10",
+ "target_qps": "1",
+ "target_latency (ns)": "0",
+ "max_async_queries": "1",
+ "min_duration (ms)": "0",
+ "max_duration (ms)": "0",
+ "min_query_count": "1",
+ "max_query_count": "10",
+ "qsl_rng_seed": "13281865557512327830",
+ "sample_index_rng_seed": "198141574272810017",
+ "schedule_rng_seed": "7575108116881280410",
+ "accuracy_log_rng_seed": "0",
+ "accuracy_log_probability": "0",
+ "accuracy_log_sampling_target": "0",
+ "print_timestamps": "0",
+ "performance_issue_unique": "0",
+ "performance_issue_same": "0",
+ "performance_issue_same_index": "0",
+ "performance_sample_count": "64"
+ },
+ "app_mlperf_inference_measurements": {
+ "starting_weights_filename": "resnext50_32x4d_fpn.onnx",
+ "retraining": "no",
+ "input_data_types": "fp32",
+ "weight_data_types": "fp32",
+ "weight_transformations": "no"
+ },
+ "cm-mlperf-inference-results": {
+ "FGG_LENOVO_P14S-reference-cpu-onnxruntime-v1.16.0-default_config": {
+ "retinanet": {
+ "Offline": {
+ "performance": "0.809",
+ "performance_valid": true,
+ "accuracy": "49.593",
+ "accuracy_valid": true
+ }
+ }
+ }
+ },
+ "cm-mlperf-inference-results-last": {
+ "performance": "0.809",
+ "performance_valid": true,
+ "accuracy": "49.593",
+ "accuracy_valid": true
+ }
+ },
+ "deps": [
+ "detect,os",
+ "detect,cpu",
+ "get,python3",
+ "get,mlcommons,inference,src",
+ "get,sut,description",
+ "get,mlperf,inference,results,dir",
+ "install,pip-package,for-cmind-python,_package.tabulate",
+ "get,mlperf,inference,utils",
+ "generate,mlperf,inference,submission"
+ ]
+}
\ No newline at end of file
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-7f094c244ebb4985.md b/cfg/benchmark-run-mlperf-inference-v3.1/run-7f094c244ebb4985.md
new file mode 100644
index 0000000000..6b58ae634a
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-7f094c244ebb4985.md
@@ -0,0 +1 @@
+TBD1
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-d5b6b5af6d794045-input.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-d5b6b5af6d794045-input.json
new file mode 100644
index 0000000000..fb7e74af53
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-d5b6b5af6d794045-input.json
@@ -0,0 +1,53 @@
+{
+ "action": "run",
+ "automation": "script",
+ "tags": "run-mlperf-inference,_r4.0,_performance-only,_short",
+ "division": "open",
+ "category": "edge",
+ "device": "cpu",
+ "model": "bert-99",
+ "precision": "uint8",
+ "implementation": "intel-original",
+ "backend": "pytorch",
+ "scenario": "Offline",
+ "execution_mode": "test",
+ "power": "no",
+ "adr": {
+ "python": {
+ "version_min": "3.8"
+ }
+ },
+ "clean": true,
+ "compliance": "no",
+ "j": true,
+ "jf": "run-d8c0f02f52bf49ae",
+ "time": true,
+ "host_os": "linux",
+ "cmd": [
+ "--tags=run-mlperf-inference,_r4.0,_performance-only,_short",
+ "--division=open",
+ "--category=edge",
+ "--device=cpu",
+ "--model=bert-99",
+ "--precision=uint8",
+ "--implementation=intel-original",
+ "--backend=pytorch",
+ "--scenario=Offline",
+ "--execution_mode=test",
+ "--power=no",
+ "--adr.python.version_min=3.8",
+ "--clean",
+ "--compliance=no",
+ "--j",
+ "--jf=run-d8c0f02f52bf49ae",
+ "--time",
+ "--host_os=linux"
+ ],
+ "out": "con",
+ "parsed_automation": [
+ [
+ "script",
+ "5b4e0237da074764"
+ ]
+ ]
+}
\ No newline at end of file
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-d5b6b5af6d794045-meta.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-d5b6b5af6d794045-meta.json
new file mode 100644
index 0000000000..adf9c9f9f1
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-d5b6b5af6d794045-meta.json
@@ -0,0 +1,9 @@
+{
+ "uid": "d5b6b5af6d794045",
+ "compute_uid": "ee8c568e0ac44f2b",
+ "bench_uid": "39877bb63fb54725",
+ "date_time": "2024-02-20T16:18:34.632335",
+ "functional": true,
+ "reproduced": true,
+ "support_docker": true
+}
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-d8c0f02f52bf49ae-input.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-d8c0f02f52bf49ae-input.json
new file mode 100644
index 0000000000..d23c116653
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-d8c0f02f52bf49ae-input.json
@@ -0,0 +1,53 @@
+{
+ "action": "run",
+ "automation": "script",
+ "tags": "run-mlperf-inference,_r4.0,_performance-only,_short",
+ "division": "open",
+ "category": "edge",
+ "device": "cpu",
+ "model": "retinanet",
+ "precision": "float32",
+ "implementation": "mil",
+ "backend": "onnxruntime",
+ "scenario": "Offline",
+ "execution_mode": "test",
+ "power": "no",
+ "adr": {
+ "python": {
+ "version_min": "3.8"
+ }
+ },
+ "clean": true,
+ "compliance": "no",
+ "j": true,
+ "jf": "run-d8c0f02f52bf49ae",
+ "time": true,
+ "host_os": "linux",
+ "cmd": [
+ "--tags=run-mlperf-inference,_r4.0,_performance-only,_short",
+ "--division=open",
+ "--category=edge",
+ "--device=cpu",
+ "--model=retinanet",
+ "--precision=float32",
+ "--implementation=mil",
+ "--backend=onnxruntime",
+ "--scenario=Offline",
+ "--execution_mode=test",
+ "--power=no",
+ "--adr.python.version_min=3.8",
+ "--clean",
+ "--compliance=no",
+ "--j",
+ "--jf=run-d8c0f02f52bf49ae",
+ "--time",
+ "--host_os=linux"
+ ],
+ "out": "con",
+ "parsed_automation": [
+ [
+ "script",
+ "5b4e0237da074764"
+ ]
+ ]
+}
\ No newline at end of file
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-d8c0f02f52bf49ae-meta.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-d8c0f02f52bf49ae-meta.json
new file mode 100644
index 0000000000..b0269fa051
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-d8c0f02f52bf49ae-meta.json
@@ -0,0 +1,10 @@
+{
+ "uid": "d8c0f02f52bf49ae",
+ "compute_uid": "ee8c568e0ac44f2b",
+ "bench_uid": "39877bb63fb54725",
+ "date_time": "2024-02-20T15:39:15.255021",
+ "notes":"Used clang 14 installed via apt; LLVM 16.0.4 couldn't find llvmgold plugin - need to check ...",
+ "functional": false,
+ "reproduced": false,
+ "support_docker": false
+}
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-d8c0f02f52bf49ae-output.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-d8c0f02f52bf49ae-output.json
new file mode 100644
index 0000000000..784796ecc2
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-d8c0f02f52bf49ae-output.json
@@ -0,0 +1,137 @@
+{
+ "return": 0,
+ "env": {},
+ "new_env": {},
+ "state": {
+ "app_mlperf_inference_log_summary": {
+ "sut name": "QueueSUT",
+ "scenario": "Offline",
+ "mode": "PerformanceOnly",
+ "samples per second": "0.452945",
+ "result is": "VALID",
+ "min duration satisfied": "Yes",
+ "min queries satisfied": "Yes",
+ "early stopping satisfied": "Yes",
+ "min latency (ns)": "2550773320",
+ "max latency (ns)": "22077722147",
+ "mean latency (ns)": "12323786694",
+ "50.00 percentile latency (ns)": "13414914364",
+ "90.00 percentile latency (ns)": "22077722147",
+ "95.00 percentile latency (ns)": "22077722147",
+ "97.00 percentile latency (ns)": "22077722147",
+ "99.00 percentile latency (ns)": "22077722147",
+ "99.90 percentile latency (ns)": "22077722147",
+ "samples_per_query": "10",
+ "target_qps": "1",
+ "target_latency (ns)": "0",
+ "max_async_queries": "1",
+ "min_duration (ms)": "0",
+ "max_duration (ms)": "0",
+ "min_query_count": "1",
+ "max_query_count": "10",
+ "qsl_rng_seed": "13281865557512327830",
+ "sample_index_rng_seed": "198141574272810017",
+ "schedule_rng_seed": "7575108116881280410",
+ "accuracy_log_rng_seed": "0",
+ "accuracy_log_probability": "0",
+ "accuracy_log_sampling_target": "0",
+ "print_timestamps": "0",
+ "performance_issue_unique": "0",
+ "performance_issue_same": "0",
+ "performance_issue_same_index": "0",
+ "performance_sample_count": "64"
+ },
+ "app_mlperf_inference_measurements": {
+ "starting_weights_filename": "resnext50_32x4d_fpn.onnx",
+ "retraining": "no",
+ "input_data_types": "fp32",
+ "weight_data_types": "fp32",
+ "weight_transformations": "no"
+ },
+ "cm-mlperf-inference-results": {
+ "ip_172_31_89_56-cpp-cpu-onnxruntime-vdefault-default_config": {
+ "retinanet": {
+ "Offline": {
+ "performance": "0.453",
+ "performance_valid": true
+ }
+ }
+ }
+ },
+ "cm-mlperf-inference-results-last": {
+ "performance": "0.453",
+ "performance_valid": true
+ }
+ },
+ "new_state": {
+ "app_mlperf_inference_log_summary": {
+ "sut name": "QueueSUT",
+ "scenario": "Offline",
+ "mode": "PerformanceOnly",
+ "samples per second": "0.452945",
+ "result is": "VALID",
+ "min duration satisfied": "Yes",
+ "min queries satisfied": "Yes",
+ "early stopping satisfied": "Yes",
+ "min latency (ns)": "2550773320",
+ "max latency (ns)": "22077722147",
+ "mean latency (ns)": "12323786694",
+ "50.00 percentile latency (ns)": "13414914364",
+ "90.00 percentile latency (ns)": "22077722147",
+ "95.00 percentile latency (ns)": "22077722147",
+ "97.00 percentile latency (ns)": "22077722147",
+ "99.00 percentile latency (ns)": "22077722147",
+ "99.90 percentile latency (ns)": "22077722147",
+ "samples_per_query": "10",
+ "target_qps": "1",
+ "target_latency (ns)": "0",
+ "max_async_queries": "1",
+ "min_duration (ms)": "0",
+ "max_duration (ms)": "0",
+ "min_query_count": "1",
+ "max_query_count": "10",
+ "qsl_rng_seed": "13281865557512327830",
+ "sample_index_rng_seed": "198141574272810017",
+ "schedule_rng_seed": "7575108116881280410",
+ "accuracy_log_rng_seed": "0",
+ "accuracy_log_probability": "0",
+ "accuracy_log_sampling_target": "0",
+ "print_timestamps": "0",
+ "performance_issue_unique": "0",
+ "performance_issue_same": "0",
+ "performance_issue_same_index": "0",
+ "performance_sample_count": "64"
+ },
+ "app_mlperf_inference_measurements": {
+ "starting_weights_filename": "resnext50_32x4d_fpn.onnx",
+ "retraining": "no",
+ "input_data_types": "fp32",
+ "weight_data_types": "fp32",
+ "weight_transformations": "no"
+ },
+ "cm-mlperf-inference-results": {
+ "ip_172_31_89_56-cpp-cpu-onnxruntime-vdefault-default_config": {
+ "retinanet": {
+ "Offline": {
+ "performance": "0.453",
+ "performance_valid": true
+ }
+ }
+ }
+ },
+ "cm-mlperf-inference-results-last": {
+ "performance": "0.453",
+ "performance_valid": true
+ }
+ },
+ "deps": [
+ "detect,os",
+ "detect,cpu",
+ "get,python3",
+ "get,mlcommons,inference,src",
+ "get,sut,description",
+ "get,mlperf,inference,results,dir",
+ "install,pip-package,for-cmind-python,_package.tabulate",
+ "get,mlperf,inference,utils"
+ ]
+}
\ No newline at end of file
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-df843c22cbf54aaf-input.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-df843c22cbf54aaf-input.json
new file mode 100644
index 0000000000..9eabe5cb60
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-df843c22cbf54aaf-input.json
@@ -0,0 +1,56 @@
+{
+ "action": "run",
+ "automation": "script",
+ "tags": "run-mlperf-inference,_r4.0,_submission,_short",
+ "division": "open",
+ "category": "edge",
+ "device": "cpu",
+ "model": "resnet50",
+ "host_os": "windows",
+ "precision": "float32",
+ "implementation": "reference",
+ "backend": "onnxruntime",
+ "scenario": "Offline",
+ "execution_mode": "test",
+ "submitter": "CTuning",
+ "power": "no",
+ "adr": {
+ "python": {
+ "version_min": "3.8"
+ }
+ },
+ "compliance": "no",
+ "j": true,
+ "time": true,
+ "clean": true,
+ "quiet": true,
+ "jf": "mlperf-inference-results",
+ "cmd": [
+ "--tags=run-mlperf-inference,_r4.0,_submission,_short",
+ "--division=open",
+ "--category=edge",
+ "--device=cpu",
+ "--model=retinanet",
+ "--precision=float32",
+ "--implementation=reference",
+ "--backend=onnxruntime",
+ "--scenario=Offline",
+ "--execution_mode=test",
+ "--submitter=CTuning",
+ "--power=no",
+ "--adr.python.version_min=3.8",
+ "--compliance=no",
+ "--j",
+ "--time",
+ "--clean",
+ "--quiet",
+ "--jf=mlperf-inference-results"
+ ],
+ "out": "con",
+ "parsed_automation": [
+ [
+ "script",
+ "5b4e0237da074764"
+ ]
+ ]
+}
\ No newline at end of file
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-df843c22cbf54aaf-meta.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-df843c22cbf54aaf-meta.json
new file mode 100644
index 0000000000..45eb699b96
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-df843c22cbf54aaf-meta.json
@@ -0,0 +1,9 @@
+{
+ "uid": "df843c22cbf54aaf",
+ "compute_uid": "fe379ecd1e054a00",
+ "bench_uid": "39877bb63fb54725",
+ "date_time": "2024-02-18",
+ "functional": true,
+ "reproduced": true,
+ "support_docker": true
+}
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-df843c22cbf54aaf-output.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-df843c22cbf54aaf-output.json
new file mode 100644
index 0000000000..cae36b057d
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-df843c22cbf54aaf-output.json
@@ -0,0 +1,146 @@
+{
+ "return": 0,
+ "env": {},
+ "new_env": {},
+ "state": {
+ "app_mlperf_inference_log_summary": {
+ "sut name": "PySUT",
+ "scenario": "Offline",
+ "mode": "PerformanceOnly",
+ "samples per second": "0.808629",
+ "result is": "VALID",
+ "min duration satisfied": "Yes",
+ "min queries satisfied": "Yes",
+ "early stopping satisfied": "Yes",
+ "min latency (ns)": "963485100",
+ "max latency (ns)": "12366604800",
+ "mean latency (ns)": "5961694610",
+ "50.00 percentile latency (ns)": "6164791100",
+ "90.00 percentile latency (ns)": "12366604800",
+ "95.00 percentile latency (ns)": "12366604800",
+ "97.00 percentile latency (ns)": "12366604800",
+ "99.00 percentile latency (ns)": "12366604800",
+ "99.90 percentile latency (ns)": "12366604800",
+ "samples_per_query": "10",
+ "target_qps": "1",
+ "target_latency (ns)": "0",
+ "max_async_queries": "1",
+ "min_duration (ms)": "0",
+ "max_duration (ms)": "0",
+ "min_query_count": "1",
+ "max_query_count": "10",
+ "qsl_rng_seed": "13281865557512327830",
+ "sample_index_rng_seed": "198141574272810017",
+ "schedule_rng_seed": "7575108116881280410",
+ "accuracy_log_rng_seed": "0",
+ "accuracy_log_probability": "0",
+ "accuracy_log_sampling_target": "0",
+ "print_timestamps": "0",
+ "performance_issue_unique": "0",
+ "performance_issue_same": "0",
+ "performance_issue_same_index": "0",
+ "performance_sample_count": "64"
+ },
+ "app_mlperf_inference_measurements": {
+ "starting_weights_filename": "resnext50_32x4d_fpn.onnx",
+ "retraining": "no",
+ "input_data_types": "fp32",
+ "weight_data_types": "fp32",
+ "weight_transformations": "no"
+ },
+ "cm-mlperf-inference-results": {
+ "FGG_LENOVO_P14S-reference-cpu-onnxruntime-v1.16.0-default_config": {
+ "retinanet": {
+ "Offline": {
+ "performance": "0.809",
+ "performance_valid": true,
+ "accuracy": "49.593",
+ "accuracy_valid": true
+ }
+ }
+ }
+ },
+ "cm-mlperf-inference-results-last": {
+ "performance": "0.809",
+ "performance_valid": true,
+ "accuracy": "49.593",
+ "accuracy_valid": true
+ }
+ },
+ "new_state": {
+ "app_mlperf_inference_log_summary": {
+ "sut name": "PySUT",
+ "scenario": "Offline",
+ "mode": "PerformanceOnly",
+ "samples per second": "0.808629",
+ "result is": "VALID",
+ "min duration satisfied": "Yes",
+ "min queries satisfied": "Yes",
+ "early stopping satisfied": "Yes",
+ "min latency (ns)": "963485100",
+ "max latency (ns)": "12366604800",
+ "mean latency (ns)": "5961694610",
+ "50.00 percentile latency (ns)": "6164791100",
+ "90.00 percentile latency (ns)": "12366604800",
+ "95.00 percentile latency (ns)": "12366604800",
+ "97.00 percentile latency (ns)": "12366604800",
+ "99.00 percentile latency (ns)": "12366604800",
+ "99.90 percentile latency (ns)": "12366604800",
+ "samples_per_query": "10",
+ "target_qps": "1",
+ "target_latency (ns)": "0",
+ "max_async_queries": "1",
+ "min_duration (ms)": "0",
+ "max_duration (ms)": "0",
+ "min_query_count": "1",
+ "max_query_count": "10",
+ "qsl_rng_seed": "13281865557512327830",
+ "sample_index_rng_seed": "198141574272810017",
+ "schedule_rng_seed": "7575108116881280410",
+ "accuracy_log_rng_seed": "0",
+ "accuracy_log_probability": "0",
+ "accuracy_log_sampling_target": "0",
+ "print_timestamps": "0",
+ "performance_issue_unique": "0",
+ "performance_issue_same": "0",
+ "performance_issue_same_index": "0",
+ "performance_sample_count": "64"
+ },
+ "app_mlperf_inference_measurements": {
+ "starting_weights_filename": "resnext50_32x4d_fpn.onnx",
+ "retraining": "no",
+ "input_data_types": "fp32",
+ "weight_data_types": "fp32",
+ "weight_transformations": "no"
+ },
+ "cm-mlperf-inference-results": {
+ "FGG_LENOVO_P14S-reference-cpu-onnxruntime-v1.16.0-default_config": {
+ "retinanet": {
+ "Offline": {
+ "performance": "0.809",
+ "performance_valid": true,
+ "accuracy": "49.593",
+ "accuracy_valid": true
+ }
+ }
+ }
+ },
+ "cm-mlperf-inference-results-last": {
+ "performance": "0.809",
+ "performance_valid": true,
+ "accuracy": "49.593",
+ "accuracy_valid": true
+ }
+ },
+ "deps": [
+ "detect,os",
+ "detect,cpu",
+ "get,python3",
+ "get,mlcommons,inference,src",
+ "get,sut,description",
+ "get,mlperf,inference,results,dir",
+ "install,pip-package,for-cmind-python,_package.tabulate",
+ "get,mlperf,inference,utils",
+ "generate,mlperf,inference,submission"
+ ]
+}
\ No newline at end of file
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-df843c22cbf54aaf.md b/cfg/benchmark-run-mlperf-inference-v3.1/run-df843c22cbf54aaf.md
new file mode 100644
index 0000000000..97635650c3
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-df843c22cbf54aaf.md
@@ -0,0 +1 @@
+TBD2
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-f05147815bf840b8-input.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-f05147815bf840b8-input.json
new file mode 100644
index 0000000000..68cf51d221
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-f05147815bf840b8-input.json
@@ -0,0 +1,55 @@
+{
+ "action": "run",
+ "automation": "script",
+ "tags": "run-mlperf-inference,_r4.0,_performance-only,_short",
+ "division": "open",
+ "category": "edge",
+ "device": "cpu",
+ "model": "bert-99",
+ "precision": "float32",
+ "implementation": "reference",
+ "backend": "pytorch",
+ "scenario": "Offline",
+ "execution_mode": "test",
+ "power": "no",
+ "adr": {
+ "python": {
+ "version_min": "3.8"
+ }
+ },
+ "clean": true,
+ "compliance": "no",
+ "j": true,
+ "jf": "run-f05147815bf840b8",
+ "quiet": true,
+ "time": true,
+ "host_os": "linux",
+ "cmd": [
+ "--tags=run-mlperf-inference,_r4.0,_performance-only,_short",
+ "--division=open",
+ "--category=edge",
+ "--device=cpu",
+ "--model=bert-99",
+ "--precision=float32",
+ "--implementation=reference",
+ "--backend=pytorch",
+ "--scenario=Offline",
+ "--execution_mode=test",
+ "--power=no",
+ "--adr.python.version_min=3.8",
+ "--clean",
+ "--compliance=no",
+ "--j",
+ "--jf=run-f05147815bf840b8",
+ "--quiet",
+ "--time",
+ "--host_os=linux"
+ ],
+ "out": "con",
+ "parsed_automation": [
+ [
+ "script",
+ "5b4e0237da074764"
+ ]
+ ]
+}
\ No newline at end of file
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-f05147815bf840b8-meta.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-f05147815bf840b8-meta.json
new file mode 100644
index 0000000000..45eb699b96
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-f05147815bf840b8-meta.json
@@ -0,0 +1,9 @@
+{
+ "uid": "df843c22cbf54aaf",
+ "compute_uid": "fe379ecd1e054a00",
+ "bench_uid": "39877bb63fb54725",
+ "date_time": "2024-02-18",
+ "functional": true,
+ "reproduced": true,
+ "support_docker": true
+}
diff --git a/cfg/benchmark-run-mlperf-inference-v3.1/run-f05147815bf840b8-output.json b/cfg/benchmark-run-mlperf-inference-v3.1/run-f05147815bf840b8-output.json
new file mode 100644
index 0000000000..627e18889a
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v3.1/run-f05147815bf840b8-output.json
@@ -0,0 +1,137 @@
+{
+ "return": 0,
+ "env": {},
+ "new_env": {},
+ "state": {
+ "app_mlperf_inference_log_summary": {
+ "sut name": "PySUT",
+ "scenario": "Offline",
+ "mode": "PerformanceOnly",
+ "samples per second": "0.771384",
+ "result is": "VALID",
+ "min duration satisfied": "Yes",
+ "min queries satisfied": "Yes",
+ "early stopping satisfied": "Yes",
+ "min latency (ns)": "1409122219",
+ "max latency (ns)": "12963712908",
+ "mean latency (ns)": "7203424157",
+ "50.00 percentile latency (ns)": "7862607410",
+ "90.00 percentile latency (ns)": "12963712908",
+ "95.00 percentile latency (ns)": "12963712908",
+ "97.00 percentile latency (ns)": "12963712908",
+ "99.00 percentile latency (ns)": "12963712908",
+ "99.90 percentile latency (ns)": "12963712908",
+ "samples_per_query": "10",
+ "target_qps": "1",
+ "target_latency (ns)": "0",
+ "max_async_queries": "1",
+ "min_duration (ms)": "0",
+ "max_duration (ms)": "0",
+ "min_query_count": "1",
+ "max_query_count": "10",
+ "qsl_rng_seed": "13281865557512327830",
+ "sample_index_rng_seed": "198141574272810017",
+ "schedule_rng_seed": "7575108116881280410",
+ "accuracy_log_rng_seed": "0",
+ "accuracy_log_probability": "0",
+ "accuracy_log_sampling_target": "0",
+ "print_timestamps": "0",
+ "performance_issue_unique": "0",
+ "performance_issue_same": "0",
+ "performance_issue_same_index": "0",
+ "performance_sample_count": "10833"
+ },
+ "app_mlperf_inference_measurements": {
+ "starting_weights_filename": "https://zenodo.org/record/3733896/files/model.pytorch",
+ "retraining": "no",
+ "input_data_types": "fp32",
+ "weight_data_types": "fp32",
+ "weight_transformations": "none"
+ },
+ "cm-mlperf-inference-results": {
+ "ip_172_31_89_56-reference-cpu-pytorch-v2.1.0-default_config": {
+ "bert-99": {
+ "Offline": {
+ "performance": "0.771",
+ "performance_valid": true
+ }
+ }
+ }
+ },
+ "cm-mlperf-inference-results-last": {
+ "performance": "0.771",
+ "performance_valid": true
+ }
+ },
+ "new_state": {
+ "app_mlperf_inference_log_summary": {
+ "sut name": "PySUT",
+ "scenario": "Offline",
+ "mode": "PerformanceOnly",
+ "samples per second": "0.771384",
+ "result is": "VALID",
+ "min duration satisfied": "Yes",
+ "min queries satisfied": "Yes",
+ "early stopping satisfied": "Yes",
+ "min latency (ns)": "1409122219",
+ "max latency (ns)": "12963712908",
+ "mean latency (ns)": "7203424157",
+ "50.00 percentile latency (ns)": "7862607410",
+ "90.00 percentile latency (ns)": "12963712908",
+ "95.00 percentile latency (ns)": "12963712908",
+ "97.00 percentile latency (ns)": "12963712908",
+ "99.00 percentile latency (ns)": "12963712908",
+ "99.90 percentile latency (ns)": "12963712908",
+ "samples_per_query": "10",
+ "target_qps": "1",
+ "target_latency (ns)": "0",
+ "max_async_queries": "1",
+ "min_duration (ms)": "0",
+ "max_duration (ms)": "0",
+ "min_query_count": "1",
+ "max_query_count": "10",
+ "qsl_rng_seed": "13281865557512327830",
+ "sample_index_rng_seed": "198141574272810017",
+ "schedule_rng_seed": "7575108116881280410",
+ "accuracy_log_rng_seed": "0",
+ "accuracy_log_probability": "0",
+ "accuracy_log_sampling_target": "0",
+ "print_timestamps": "0",
+ "performance_issue_unique": "0",
+ "performance_issue_same": "0",
+ "performance_issue_same_index": "0",
+ "performance_sample_count": "10833"
+ },
+ "app_mlperf_inference_measurements": {
+ "starting_weights_filename": "https://zenodo.org/record/3733896/files/model.pytorch",
+ "retraining": "no",
+ "input_data_types": "fp32",
+ "weight_data_types": "fp32",
+ "weight_transformations": "none"
+ },
+ "cm-mlperf-inference-results": {
+ "ip_172_31_89_56-reference-cpu-pytorch-v2.1.0-default_config": {
+ "bert-99": {
+ "Offline": {
+ "performance": "0.771",
+ "performance_valid": true
+ }
+ }
+ }
+ },
+ "cm-mlperf-inference-results-last": {
+ "performance": "0.771",
+ "performance_valid": true
+ }
+ },
+ "deps": [
+ "detect,os",
+ "detect,cpu",
+ "get,python3",
+ "get,mlcommons,inference,src",
+ "get,sut,description",
+ "get,mlperf,inference,results,dir",
+ "install,pip-package,for-cmind-python,_package.tabulate",
+ "get,mlperf,inference,utils"
+ ]
+}
\ No newline at end of file
diff --git a/cfg/benchmark-run-mlperf-inference-v4.0/_cm.yaml b/cfg/benchmark-run-mlperf-inference-v4.0/_cm.yaml
new file mode 100644
index 0000000000..50086d0862
--- /dev/null
+++ b/cfg/benchmark-run-mlperf-inference-v4.0/_cm.yaml
@@ -0,0 +1,38 @@
+alias: benchmark-run-mlperf-inference-v4.0
+uid: b4ee9b6c820e493a
+
+automation_alias: cfg
+automation_uid: 88dce9c160324c5d
+
+tags:
+- benchmark
+- run
+- mlperf
+- inference
+- v4.0
+
+name: "MLPerf inference - v4.0"
+
+supported_compute:
+- ee8c568e0ac44f2b
+- fe379ecd1e054a00
+
+bench_uid: 39877bb63fb54725
+
+view_dimensions:
+- - input.device
+ - "MLPerf device"
+- - input.implementation
+ - "MLPerf implementation"
+- - input.backend
+ - "MLPerf backend"
+- - input.model
+ - "MLPerf model"
+- - input.scenario
+ - "MLPerf scenario"
+- - input.host_os
+ - "Host OS"
+- - output.state.cm-mlperf-inference-results-last.performance
+ - "Got performance"
+- - output.state.cm-mlperf-inference-results-last.accuracy
+ - "Got accuracy"
diff --git a/cmr.yaml b/cmr.yaml
new file mode 100644
index 0000000000..0a6633e9cf
--- /dev/null
+++ b/cmr.yaml
@@ -0,0 +1,4 @@
+alias: mlcommons@cm4mlops
+uid: 9e97bb72b0474657
+
+git: true
diff --git a/script/README.md b/script/README.md
new file mode 100644
index 0000000000..a9e5e41450
--- /dev/null
+++ b/script/README.md
@@ -0,0 +1,13 @@
+### About
+
+This is a source code of portable and reusable automation recipes
+from MLCommons projects with a [human-friendly CM interface](https://github.com/mlcommons/ck) -
+you can find a human-readable catalog of these automation recipes [here](../../docs/list_of_scripts.md).
+
+### License
+
+[Apache 2.0](../../LICENSE.md)
+
+### Copyright
+
+2022-2024 [MLCommons](https://mlcommons.org)
diff --git a/script/activate-python-venv/README-extra.md b/script/activate-python-venv/README-extra.md
new file mode 100644
index 0000000000..2b61d193cd
--- /dev/null
+++ b/script/activate-python-venv/README-extra.md
@@ -0,0 +1,7 @@
+# About
+
+Activate python virtual environment installed via CM:
+
+```bash
+cm run script "activate python-ven" (--version={python version}) (--name={user friendly name of the virtual environment))
+```
diff --git a/script/activate-python-venv/README.md b/script/activate-python-venv/README.md
new file mode 100644
index 0000000000..9a804da0fd
--- /dev/null
+++ b/script/activate-python-venv/README.md
@@ -0,0 +1,123 @@
+Automatically generated README for this automation recipe: **activate-python-venv**
+
+Category: **Python automation**
+
+License: **Apache 2.0**
+
+Developers: [Grigori Fursin](https://cKnowledge.org/gfursin)
+
+---
+*[ [Online info and GUI to run this CM script](https://access.cknowledge.org/playground/?action=scripts&name=activate-python-venv,fcbbb84946f34c55) ] [ [Notes from the authors, contributors and users](README-extra.md) ]*
+
+---
+#### Summary
+
+* CM GitHub repository: *[mlcommons@ck](https://github.com/mlcommons/ck/tree/dev/cm-mlops)*
+* GitHub directory for this script: *[GitHub](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/activate-python-venv)*
+* CM meta description for this script: *[_cm.json](_cm.json)*
+* All CM tags to find and reuse this script (see in above meta description): *activate,python-venv*
+* Output cached? *False*
+* See [pipeline of dependencies](#dependencies-on-other-cm-scripts) on other CM scripts
+
+
+---
+### Reuse this script in your project
+
+#### Install MLCommons CM automation meta-framework
+
+* [Install CM](https://access.cknowledge.org/playground/?action=install)
+* [CM Getting Started Guide](https://github.com/mlcommons/ck/blob/master/docs/getting-started.md)
+
+#### Pull CM repository with this automation recipe (CM script)
+
+```cm pull repo mlcommons@ck```
+
+#### Print CM help from the command line
+
+````cmr "activate python-venv" --help````
+
+#### Customize and run this script from the command line with different variations and flags
+
+`cm run script --tags=activate,python-venv`
+
+`cm run script --tags=activate,python-venv `
+
+*or*
+
+`cmr "activate python-venv"`
+
+`cmr "activate python-venv " `
+
+
+#### Run this script from Python
+
+
+Click here to expand this section.
+
+```python
+
+import cmind
+
+r = cmind.access({'action':'run'
+ 'automation':'script',
+ 'tags':'activate,python-venv'
+ 'out':'con',
+ ...
+ (other input keys for this script)
+ ...
+ })
+
+if r['return']>0:
+ print (r['error'])
+
+```
+
+
+
+
+#### Run this script via GUI
+
+```cmr "cm gui" --script="activate,python-venv"```
+
+Use this [online GUI](https://cKnowledge.org/cm-gui/?tags=activate,python-venv) to generate CM CMD.
+
+#### Run this script via Docker (beta)
+
+`cm docker script "activate python-venv" `
+
+___
+### Customization
+
+#### Default environment
+
+
+Click here to expand this section.
+
+These keys can be updated via `--env.KEY=VALUE` or `env` dictionary in `@input.json` or using script flags.
+
+
+
+
+___
+### Dependencies on other CM scripts
+
+
+ 1. Read "deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/activate-python-venv/_cm.json)
+ 1. ***Run "preprocess" function from [customize.py](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/activate-python-venv/customize.py)***
+ 1. ***Read "prehook_deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/activate-python-venv/_cm.json)***
+ * install,python-venv
+ * CM names: `--adr.['python-venv']...`
+ - CM script: [install-python-venv](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/install-python-venv)
+ 1. ***Run native script if exists***
+ * [run.bat](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/activate-python-venv/run.bat)
+ * [run.sh](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/activate-python-venv/run.sh)
+ 1. Read "posthook_deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/activate-python-venv/_cm.json)
+ 1. Run "postrocess" function from customize.py
+ 1. Read "post_deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/activate-python-venv/_cm.json)
+
+___
+### Script output
+`cmr "activate python-venv " -j`
+#### New environment keys (filter)
+
+#### New environment keys auto-detected from customize
diff --git a/script/activate-python-venv/_cm.json b/script/activate-python-venv/_cm.json
new file mode 100644
index 0000000000..90997ca293
--- /dev/null
+++ b/script/activate-python-venv/_cm.json
@@ -0,0 +1,25 @@
+{
+ "alias": "activate-python-venv",
+ "automation_alias": "script",
+ "automation_uid": "5b4e0237da074764",
+ "category": "Python automation",
+ "developers": "[Grigori Fursin](https://cKnowledge.org/gfursin)",
+ "name": "Activate virtual Python environment",
+ "prehook_deps": [
+ {
+ "names": [
+ "python-venv"
+ ],
+ "reuse_version": true,
+ "tags": "install,python-venv"
+ }
+ ],
+ "tags": [
+ "activate",
+ "python",
+ "activate-python-venv",
+ "python-venv"
+ ],
+ "tags_help":"activate python-venv",
+ "uid": "fcbbb84946f34c55"
+}
diff --git a/script/activate-python-venv/customize.py b/script/activate-python-venv/customize.py
new file mode 100644
index 0000000000..938a016a05
--- /dev/null
+++ b/script/activate-python-venv/customize.py
@@ -0,0 +1,29 @@
+from cmind import utils
+import os
+
+def preprocess(i):
+
+ os_info = i['os_info']
+
+ env = i['env']
+
+ meta = i['meta']
+
+ automation = i['automation']
+
+ quiet = (env.get('CM_QUIET', False) == 'yes')
+
+ name = env.get('CM_NAME','')
+ if name != '':
+ name = name.strip().lower()
+
+ r = automation.update_deps({'deps':meta['prehook_deps'],
+ 'update_deps':{
+ 'python-venv':{
+ 'name':name
+ }
+ }
+ })
+ if r['return']>0: return r
+
+ return {'return':0}
diff --git a/script/activate-python-venv/run.bat b/script/activate-python-venv/run.bat
new file mode 100644
index 0000000000..5ca2ac0edd
--- /dev/null
+++ b/script/activate-python-venv/run.bat
@@ -0,0 +1,7 @@
+echo.
+echo call "%CM_VIRTUAL_ENV_SCRIPTS_PATH%\activate.bat && cmd"
+echo.
+echo Enter exit to exit virtual env.
+echo.
+
+call %CM_VIRTUAL_ENV_SCRIPTS_PATH%\activate.bat && cmd
diff --git a/script/activate-python-venv/run.sh b/script/activate-python-venv/run.sh
new file mode 100644
index 0000000000..6569b07e55
--- /dev/null
+++ b/script/activate-python-venv/run.sh
@@ -0,0 +1,9 @@
+#!/bin/bash
+
+echo ""
+echo " bash --init-file ${CM_VIRTUAL_ENV_SCRIPTS_PATH}/activate"
+echo ""
+echo " Enter exit to exit virtual env."
+echo ""
+
+bash --init-file ${CM_VIRTUAL_ENV_SCRIPTS_PATH}/activate
diff --git a/script/add-custom-nvidia-system/README-extra.md b/script/add-custom-nvidia-system/README-extra.md
new file mode 100644
index 0000000000..baa487880e
--- /dev/null
+++ b/script/add-custom-nvidia-system/README-extra.md
@@ -0,0 +1,2 @@
+# About
+This CM script detects the system details using Nvidia script
diff --git a/script/add-custom-nvidia-system/README.md b/script/add-custom-nvidia-system/README.md
new file mode 100644
index 0000000000..51b160909b
--- /dev/null
+++ b/script/add-custom-nvidia-system/README.md
@@ -0,0 +1,177 @@
+Automatically generated README for this automation recipe: **add-custom-nvidia-system**
+
+Category: **MLPerf benchmark support**
+
+License: **Apache 2.0**
+
+Maintainers: [Public MLCommons Task Force on Automation and Reproducibility](https://github.com/mlcommons/ck/blob/master/docs/taskforce.md)
+
+---
+*[ [Online info and GUI to run this CM script](https://access.cknowledge.org/playground/?action=scripts&name=add-custom-nvidia-system,b2e6c46c6e8745a3) ] [ [Notes from the authors, contributors and users](README-extra.md) ]*
+
+---
+#### Summary
+
+* CM GitHub repository: *[mlcommons@ck](https://github.com/mlcommons/ck/tree/dev/cm-mlops)*
+* GitHub directory for this script: *[GitHub](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/add-custom-nvidia-system)*
+* CM meta description for this script: *[_cm.yaml](_cm.yaml)*
+* All CM tags to find and reuse this script (see in above meta description): *add,custom,system,nvidia*
+* Output cached? *True*
+* See [pipeline of dependencies](#dependencies-on-other-cm-scripts) on other CM scripts
+
+
+---
+### Reuse this script in your project
+
+#### Install MLCommons CM automation meta-framework
+
+* [Install CM](https://access.cknowledge.org/playground/?action=install)
+* [CM Getting Started Guide](https://github.com/mlcommons/ck/blob/master/docs/getting-started.md)
+
+#### Pull CM repository with this automation recipe (CM script)
+
+```cm pull repo mlcommons@ck```
+
+#### Print CM help from the command line
+
+````cmr "add custom system nvidia" --help````
+
+#### Customize and run this script from the command line with different variations and flags
+
+`cm run script --tags=add,custom,system,nvidia`
+
+`cm run script --tags=add,custom,system,nvidia[,variations] `
+
+*or*
+
+`cmr "add custom system nvidia"`
+
+`cmr "add custom system nvidia [variations]" `
+
+
+* *See the list of `variations` [here](#variations) and check the [Gettings Started Guide](https://github.com/mlcommons/ck/blob/dev/docs/getting-started.md) for more details.*
+
+#### Run this script from Python
+
+
+Click here to expand this section.
+
+```python
+
+import cmind
+
+r = cmind.access({'action':'run'
+ 'automation':'script',
+ 'tags':'add,custom,system,nvidia'
+ 'out':'con',
+ ...
+ (other input keys for this script)
+ ...
+ })
+
+if r['return']>0:
+ print (r['error'])
+
+```
+
+
+
+
+#### Run this script via GUI
+
+```cmr "cm gui" --script="add,custom,system,nvidia"```
+
+Use this [online GUI](https://cKnowledge.org/cm-gui/?tags=add,custom,system,nvidia) to generate CM CMD.
+
+#### Run this script via Docker (beta)
+
+`cm docker script "add custom system nvidia[variations]" `
+
+___
+### Customization
+
+
+#### Variations
+
+ * Group "**code**"
+
+ Click here to expand this section.
+
+ * `_ctuning`
+ - Workflow:
+ * `_custom`
+ - Workflow:
+ * `_mlcommons`
+ - Workflow:
+ * `_nvidia-only`
+ - Workflow:
+
+
+
+#### Default environment
+
+
+Click here to expand this section.
+
+These keys can be updated via `--env.KEY=VALUE` or `env` dictionary in `@input.json` or using script flags.
+
+
+
+
+#### Versions
+* `r2.1`
+* `r3.0`
+* `r3.1`
+___
+### Dependencies on other CM scripts
+
+
+ 1. ***Read "deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/add-custom-nvidia-system/_cm.yaml)***
+ * detect,os
+ - CM script: [detect-os](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/detect-os)
+ * detect,cpu
+ - CM script: [detect-cpu](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/detect-cpu)
+ * get,sys-utils-cm
+ - CM script: [get-sys-utils-cm](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-sys-utils-cm)
+ * get,python3
+ * CM names: `--adr.['python', 'python3']...`
+ - CM script: [get-python3](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-python3)
+ * get,cuda,_cudnn
+ - CM script: [get-cuda](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-cuda)
+ * get,tensorrt
+ - CM script: [get-tensorrt](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-tensorrt)
+ * get,cmake
+ - CM script: [get-cmake](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-cmake)
+ * get,generic-python-lib,_requests
+ - CM script: [get-generic-python-lib](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-generic-python-lib)
+ * get,generic,sys-util,_glog-dev
+ - CM script: [get-generic-sys-util](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-generic-sys-util)
+ * get,generic,sys-util,_gflags-dev
+ - CM script: [get-generic-sys-util](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-generic-sys-util)
+ * get,generic,sys-util,_libre2-dev
+ - CM script: [get-generic-sys-util](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-generic-sys-util)
+ * get,generic,sys-util,_libnuma-dev
+ - CM script: [get-generic-sys-util](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-generic-sys-util)
+ * get,generic,sys-util,_libboost-all-dev
+ - CM script: [get-generic-sys-util](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-generic-sys-util)
+ * get,generic,sys-util,_rapidjson-dev
+ - CM script: [get-generic-sys-util](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-generic-sys-util)
+ * get,nvidia,mlperf,inference,common-code
+ * CM names: `--adr.['nvidia-inference-common-code']...`
+ - CM script: [get-mlperf-inference-nvidia-common-code](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-mlperf-inference-nvidia-common-code)
+ * get,generic-python-lib,_pycuda
+ - CM script: [get-generic-python-lib](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-generic-python-lib)
+ 1. ***Run "preprocess" function from [customize.py](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/add-custom-nvidia-system/customize.py)***
+ 1. Read "prehook_deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/add-custom-nvidia-system/_cm.yaml)
+ 1. ***Run native script if exists***
+ * [run.sh](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/add-custom-nvidia-system/run.sh)
+ 1. Read "posthook_deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/add-custom-nvidia-system/_cm.yaml)
+ 1. ***Run "postrocess" function from [customize.py](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/add-custom-nvidia-system/customize.py)***
+ 1. Read "post_deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/add-custom-nvidia-system/_cm.yaml)
+
+___
+### Script output
+`cmr "add custom system nvidia [,variations]" -j`
+#### New environment keys (filter)
+
+#### New environment keys auto-detected from customize
diff --git a/script/add-custom-nvidia-system/_cm.yaml b/script/add-custom-nvidia-system/_cm.yaml
new file mode 100644
index 0000000000..6705c3cdc8
--- /dev/null
+++ b/script/add-custom-nvidia-system/_cm.yaml
@@ -0,0 +1,113 @@
+# Identification of this CM script
+alias: add-custom-nvidia-system
+uid: b2e6c46c6e8745a3
+cache: true
+automation_alias: script
+automation_uid: 5b4e0237da074764
+
+category: "MLPerf benchmark support"
+
+
+# User-friendly tags to find this CM script
+tags:
+ - add
+ - custom
+ - system
+ - nvidia
+
+
+# Dependencies on other CM scripts
+
+deps:
+
+ # Detect host OS features
+ - tags: detect,os
+
+ # Detect host CPU features
+ - tags: detect,cpu
+
+ # Install system dependencies on a given host
+ - tags: get,sys-utils-cm
+
+ # Detect python3
+ - tags: get,python3
+ names:
+ - python
+ - python3
+
+ # Detect CUDA
+ - tags: get,cuda,_cudnn
+
+ # Detect Tensorrt
+ - tags: get,tensorrt
+
+ # Detect CMake
+ - tags: get,cmake
+
+ # Detect requests
+ - tags: get,generic-python-lib,_requests
+
+ # Detect Google Logger
+ - tags: get,generic,sys-util,_glog-dev
+
+ # Detect GFlags
+ - tags: get,generic,sys-util,_gflags-dev
+
+ # Detect libre2-dev
+ - tags: get,generic,sys-util,_libre2-dev
+
+ # Detect libnuma-dev
+ - tags: get,generic,sys-util,_libnuma-dev
+
+ # Detect libboost-all-dev
+ - tags: get,generic,sys-util,_libboost-all-dev
+
+ # Detect rapidjson-dev
+ - tags: get,generic,sys-util,_rapidjson-dev
+
+ # Download Nvidia Submission Code
+ - tags: get,nvidia,mlperf,inference,common-code
+ names:
+ - nvidia-inference-common-code
+
+ # Detect pycuda
+ - tags: get,generic-python-lib,_pycuda
+
+variations:
+ nvidia-only:
+ group: code
+ add_deps_recursive:
+ nvidia-inference-common-code:
+ tags: _nvidia-only
+ custom:
+ group: code
+ add_deps_recursive:
+ nvidia-inference-common-code:
+ tags: _custom
+ mlcommons:
+ group: code
+ add_deps_recursive:
+ nvidia-inference-common-code:
+ tags: _mlcommons
+ ctuning:
+ group: code
+ add_deps_recursive:
+ nvidia-inference-common-code:
+ tags: _ctuning
+
+
+versions:
+ r2.1:
+ add_deps_recursive:
+ nvidia-inference-common-code:
+ version: r2.1
+
+ r3.0:
+ add_deps_recursive:
+ nvidia-inference-common-code:
+ version: r3.0
+
+ r3.1:
+ add_deps_recursive:
+ nvidia-inference-common-code:
+ version: r3.1
diff --git a/script/add-custom-nvidia-system/customize.py b/script/add-custom-nvidia-system/customize.py
new file mode 100644
index 0000000000..e9573338b1
--- /dev/null
+++ b/script/add-custom-nvidia-system/customize.py
@@ -0,0 +1,22 @@
+from cmind import utils
+import os
+import shutil
+
+def preprocess(i):
+
+ os_info = i['os_info']
+
+ if os_info['platform'] == 'windows':
+ return {'return':1, 'error': 'Windows is not supported in this script yet'}
+
+ env = i['env']
+
+ return {'return':0}
+
+def postprocess(i):
+
+ env = i['env']
+
+ env['CM_GET_DEPENDENT_CACHED_PATH'] = env['CM_MLPERF_INFERENCE_NVIDIA_CODE_PATH']
+
+ return {'return':0}
diff --git a/script/add-custom-nvidia-system/run.sh b/script/add-custom-nvidia-system/run.sh
new file mode 100644
index 0000000000..b89617f7f2
--- /dev/null
+++ b/script/add-custom-nvidia-system/run.sh
@@ -0,0 +1,5 @@
+#!/bin/bash
+CUR=$PWD
+cd ${CM_MLPERF_INFERENCE_NVIDIA_CODE_PATH}
+${CM_PYTHON_BIN_WITH_PATH} scripts/custom_systems/add_custom_system.py
+test $? -eq 0 || exit $?
diff --git a/script/app-image-classification-onnx-py/README-extra.md b/script/app-image-classification-onnx-py/README-extra.md
new file mode 100644
index 0000000000..e379e2544e
--- /dev/null
+++ b/script/app-image-classification-onnx-py/README-extra.md
@@ -0,0 +1,17 @@
+# About
+
+See [this tutorial](https://github.com/mlcommons/ck/blob/master/docs/tutorials/modular-image-classification.md).
+
+# Collaborative testing
+
+## Windows 11
+
+* CUDA 11.8; cuDNN 8.7.0; ONNX GPU 1.16.1
+
+## Windows 10
+
+* CUDA 11.6; cuDNN 8.6.0.96; ONNX GPU 1.13.1
+
+## Ubuntu 22.04
+
+* CUDA 11.3; ONNX 1.12.0
diff --git a/script/app-image-classification-onnx-py/README.md b/script/app-image-classification-onnx-py/README.md
new file mode 100644
index 0000000000..e74a1be740
--- /dev/null
+++ b/script/app-image-classification-onnx-py/README.md
@@ -0,0 +1,211 @@
+Automatically generated README for this automation recipe: **app-image-classification-onnx-py**
+
+Category: **Modular AI/ML application pipeline**
+
+License: **Apache 2.0**
+
+Maintainers: [Public MLCommons Task Force on Automation and Reproducibility](https://github.com/mlcommons/ck/blob/master/docs/taskforce.md)
+
+---
+*[ [Online info and GUI to run this CM script](https://access.cknowledge.org/playground/?action=scripts&name=app-image-classification-onnx-py,3d5e908e472b417e) ] [ [Notes from the authors, contributors and users](README-extra.md) ]*
+
+---
+#### Summary
+
+* CM GitHub repository: *[mlcommons@ck](https://github.com/mlcommons/ck/tree/dev/cm-mlops)*
+* GitHub directory for this script: *[GitHub](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-onnx-py)*
+* CM meta description for this script: *[_cm.yaml](_cm.yaml)*
+* All CM tags to find and reuse this script (see in above meta description): *modular,python,app,image-classification,onnx*
+* Output cached? *False*
+* See [pipeline of dependencies](#dependencies-on-other-cm-scripts) on other CM scripts
+
+
+---
+### Reuse this script in your project
+
+#### Install MLCommons CM automation meta-framework
+
+* [Install CM](https://access.cknowledge.org/playground/?action=install)
+* [CM Getting Started Guide](https://github.com/mlcommons/ck/blob/master/docs/getting-started.md)
+
+#### Pull CM repository with this automation recipe (CM script)
+
+```cm pull repo mlcommons@ck```
+
+#### Print CM help from the command line
+
+````cmr "modular python app image-classification onnx" --help````
+
+#### Customize and run this script from the command line with different variations and flags
+
+`cm run script --tags=modular,python,app,image-classification,onnx`
+
+`cm run script --tags=modular,python,app,image-classification,onnx[,variations] [--input_flags]`
+
+*or*
+
+`cmr "modular python app image-classification onnx"`
+
+`cmr "modular python app image-classification onnx [variations]" [--input_flags]`
+
+
+* *See the list of `variations` [here](#variations) and check the [Gettings Started Guide](https://github.com/mlcommons/ck/blob/dev/docs/getting-started.md) for more details.*
+
+
+#### Input Flags
+
+* --**input**=Path to JPEG image to classify
+* --**output**=Output directory (optional)
+* --**j**=Print JSON output
+
+**Above CLI flags can be used in the Python CM API as follows:**
+
+```python
+r=cm.access({... , "input":...}
+```
+#### Run this script from Python
+
+
+Click here to expand this section.
+
+```python
+
+import cmind
+
+r = cmind.access({'action':'run'
+ 'automation':'script',
+ 'tags':'modular,python,app,image-classification,onnx'
+ 'out':'con',
+ ...
+ (other input keys for this script)
+ ...
+ })
+
+if r['return']>0:
+ print (r['error'])
+
+```
+
+
+
+
+#### Run this script via GUI
+
+```cmr "cm gui" --script="modular,python,app,image-classification,onnx"```
+
+Use this [online GUI](https://cKnowledge.org/cm-gui/?tags=modular,python,app,image-classification,onnx) to generate CM CMD.
+
+#### Run this script via Docker (beta)
+
+`cm docker script "modular python app image-classification onnx[variations]" [--input_flags]`
+
+___
+### Customization
+
+
+#### Variations
+
+ * Group "**target**"
+
+ Click here to expand this section.
+
+ * **`_cpu`** (default)
+ - Environment variables:
+ - *USE_CPU*: `True`
+ - Workflow:
+ * `_cuda`
+ - Environment variables:
+ - *USE_CUDA*: `True`
+ - Workflow:
+
+
+
+
+#### Default variations
+
+`_cpu`
+
+#### Script flags mapped to environment
+
+Click here to expand this section.
+
+* `--input=value` → `CM_IMAGE=value`
+* `--output=value` → `CM_APP_IMAGE_CLASSIFICATION_ONNX_PY_OUTPUT=value`
+
+**Above CLI flags can be used in the Python CM API as follows:**
+
+```python
+r=cm.access({... , "input":...}
+```
+
+
+
+#### Default environment
+
+
+Click here to expand this section.
+
+These keys can be updated via `--env.KEY=VALUE` or `env` dictionary in `@input.json` or using script flags.
+
+* CM_BATCH_COUNT: `1`
+* CM_BATCH_SIZE: `1`
+
+
+
+___
+### Dependencies on other CM scripts
+
+
+ 1. ***Read "deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-onnx-py/_cm.yaml)***
+ * detect,os
+ - CM script: [detect-os](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/detect-os)
+ * get,sys-utils-cm
+ - CM script: [get-sys-utils-cm](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-sys-utils-cm)
+ * get,python3
+ * CM names: `--adr.['python', 'python3']...`
+ - CM script: [get-python3](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-python3)
+ * get,cuda
+ * `if (USE_CUDA == True)`
+ * CM names: `--adr.['cuda']...`
+ - CM script: [get-cuda](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-cuda)
+ * get,cudnn
+ * `if (USE_CUDA == True)`
+ * CM names: `--adr.['cudnn']...`
+ - CM script: [get-cudnn](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-cudnn)
+ * get,dataset,imagenet,image-classification,original
+ - CM script: [get-dataset-imagenet-val](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-dataset-imagenet-val)
+ * get,dataset-aux,imagenet-aux,image-classification
+ - CM script: [get-dataset-imagenet-aux](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-dataset-imagenet-aux)
+ * get,ml-model,resnet50,_onnx,image-classification
+ * CM names: `--adr.['ml-model']...`
+ - CM script: [get-ml-model-resnet50](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-ml-model-resnet50)
+ * get,generic-python-lib,_package.Pillow
+ - CM script: [get-generic-python-lib](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-generic-python-lib)
+ * get,generic-python-lib,_package.numpy
+ - CM script: [get-generic-python-lib](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-generic-python-lib)
+ * get,generic-python-lib,_package.opencv-python
+ - CM script: [get-generic-python-lib](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-generic-python-lib)
+ * get,generic-python-lib,_onnxruntime
+ * `if (USE_CUDA != True)`
+ * CM names: `--adr.['onnxruntime']...`
+ - CM script: [get-generic-python-lib](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-generic-python-lib)
+ * get,generic-python-lib,_onnxruntime_gpu
+ * `if (USE_CUDA == True)`
+ * CM names: `--adr.['onnxruntime']...`
+ - CM script: [get-generic-python-lib](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-generic-python-lib)
+ 1. ***Run "preprocess" function from [customize.py](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-onnx-py/customize.py)***
+ 1. Read "prehook_deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-onnx-py/_cm.yaml)
+ 1. ***Run native script if exists***
+ * [run.bat](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-onnx-py/run.bat)
+ * [run.sh](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-onnx-py/run.sh)
+ 1. Read "posthook_deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-onnx-py/_cm.yaml)
+ 1. ***Run "postrocess" function from [customize.py](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-onnx-py/customize.py)***
+ 1. Read "post_deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-onnx-py/_cm.yaml)
+
+___
+### Script output
+`cmr "modular python app image-classification onnx [,variations]" [--input_flags] -j`
+#### New environment keys (filter)
+
+* `CM_APP_IMAGE_CLASSIFICATION_ONNX_PY*`
+#### New environment keys auto-detected from customize
diff --git a/script/app-image-classification-onnx-py/_cm.yaml b/script/app-image-classification-onnx-py/_cm.yaml
new file mode 100644
index 0000000000..a2cd1994be
--- /dev/null
+++ b/script/app-image-classification-onnx-py/_cm.yaml
@@ -0,0 +1,116 @@
+alias: app-image-classification-onnx-py
+uid: 3d5e908e472b417e
+
+automation_alias: script
+automation_uid: 5b4e0237da074764
+
+category: "Modular AI/ML application pipeline"
+
+tags:
+- app
+- modular
+- image-classification
+- onnx
+- python
+
+tags_help: "modular python app image-classification onnx"
+
+default_env:
+ CM_BATCH_COUNT: '1'
+ CM_BATCH_SIZE: '1'
+
+
+deps:
+- tags: detect,os
+- tags: get,sys-utils-cm
+- names:
+ - python
+ - python3
+ tags: get,python3
+
+- tags: get,cuda
+ names:
+ - cuda
+ enable_if_env:
+ USE_CUDA:
+ - yes
+- tags: get,cudnn
+ names:
+ - cudnn
+ enable_if_env:
+ USE_CUDA:
+ - yes
+
+- tags: get,dataset,imagenet,image-classification,original
+- tags: get,dataset-aux,imagenet-aux,image-classification
+- tags: get,ml-model,resnet50,_onnx,image-classification
+ names:
+ - ml-model
+
+- tags: get,generic-python-lib,_package.Pillow
+- tags: get,generic-python-lib,_package.numpy
+- tags: get,generic-python-lib,_package.opencv-python
+
+
+- tags: get,generic-python-lib,_onnxruntime
+ names:
+ - onnxruntime
+ skip_if_env:
+ USE_CUDA:
+ - yes
+- tags: get,generic-python-lib,_onnxruntime_gpu
+ names:
+ - onnxruntime
+ enable_if_env:
+ USE_CUDA:
+ - yes
+
+variations:
+ cuda:
+ docker:
+ all_gpus: 'yes'
+ group: target
+ env:
+ USE_CUDA: yes
+
+ cpu:
+ group: target
+ default: yes
+ env:
+ USE_CPU: yes
+
+input_mapping:
+ input: CM_IMAGE
+ output: CM_APP_IMAGE_CLASSIFICATION_ONNX_PY_OUTPUT
+
+
+new_env_keys:
+ - CM_APP_IMAGE_CLASSIFICATION_ONNX_PY*
+
+
+new_state_keys:
+ - cm_app_image_classification_onnx_py
+
+
+input_description:
+ input:
+ desc: "Path to JPEG image to classify"
+ output:
+ desc: "Output directory (optional)"
+ j:
+ desc: "Print JSON output"
+ boolean: true
+
+docker:
+ skip_run_cmd: 'no'
+ input_paths:
+ - input
+ - env.CM_IMAGE
+ - output
+ skip_input_for_fake_run:
+ - input
+ - env.CM_IMAGE
+ - output
+ - j
+ pre_run_cmds:
+ - echo \"CM pre run commands\"
diff --git a/script/app-image-classification-onnx-py/customize.py b/script/app-image-classification-onnx-py/customize.py
new file mode 100644
index 0000000000..43098c71f7
--- /dev/null
+++ b/script/app-image-classification-onnx-py/customize.py
@@ -0,0 +1,64 @@
+from cmind import utils
+import os
+import shutil
+
+def preprocess(i):
+
+ os_info = i['os_info']
+ env = i['env']
+
+ print ('')
+ print ('Running preprocess function in customize.py ...')
+
+ return {'return':0}
+
+def postprocess(i):
+
+ os_info = i['os_info']
+ env = i['env']
+ state = i['state']
+
+
+# print ('')
+# print ('Running postprocess function in customize.py ...')
+
+ # Saving predictions to JSON file to current directory
+ # Should work with "cm docker script" ?
+
+ data = state.get('cm_app_image_classification_onnx_py',{})
+
+ fjson = 'cm-image-classification-onnx-py.json'
+ fyaml = 'cm-image-classification-onnx-py.yaml'
+
+ output=env.get('CM_APP_IMAGE_CLASSIFICATION_ONNX_PY_OUTPUT','')
+ if output!='':
+ if not os.path.exists(output):
+ os.makedirs(output)
+
+ fjson=os.path.join(output, fjson)
+ fyaml=os.path.join(output, fyaml)
+
+ try:
+ import json
+ with open(fjson, 'w', encoding='utf-8') as f:
+ json.dump(data, f, ensure_ascii=False, indent=4)
+ except Exception as e:
+ print ('CM warning: {}'.format(e))
+
+
+ try:
+ import yaml
+ with open(fyaml, 'w', encoding='utf-8') as f:
+ yaml.dump(data, f)
+ except Exception as e:
+ print ('CM warning: {}'.format(e))
+
+ top_classification = data.get('top_classification','')
+
+ if top_classification!='':
+ print ('')
+ x = 'Top classification: {}'.format(top_classification)
+ print ('='*len(x))
+ print (x)
+
+ return {'return':0}
diff --git a/script/app-image-classification-onnx-py/img/computer_mouse.jpg b/script/app-image-classification-onnx-py/img/computer_mouse.jpg
new file mode 100644
index 0000000000..e7f8abb6fe
Binary files /dev/null and b/script/app-image-classification-onnx-py/img/computer_mouse.jpg differ
diff --git a/script/app-image-classification-onnx-py/requirements.txt b/script/app-image-classification-onnx-py/requirements.txt
new file mode 100644
index 0000000000..e69de29bb2
diff --git a/script/app-image-classification-onnx-py/run.bat b/script/app-image-classification-onnx-py/run.bat
new file mode 100644
index 0000000000..ee7db98674
--- /dev/null
+++ b/script/app-image-classification-onnx-py/run.bat
@@ -0,0 +1,29 @@
+rem echo %CM_PYTHON_BIN%
+rem echo %CM_DATASET_PATH%
+rem echo %CM_DATASET_AUX_PATH%
+rem echo %CM_ML_MODEL_FILE_WITH_PATH%
+
+rem connect CM intelligent components with CK env
+set CK_ENV_ONNX_MODEL_ONNX_FILEPATH=%CM_ML_MODEL_FILE_WITH_PATH%
+set CK_ENV_ONNX_MODEL_INPUT_LAYER_NAME=input_tensor:0
+set CK_ENV_ONNX_MODEL_OUTPUT_LAYER_NAME=softmax_tensor:0
+set CK_ENV_DATASET_IMAGENET_VAL=%CM_DATASET_PATH%
+set CK_CAFFE_IMAGENET_SYNSET_WORDS_TXT=%CM_DATASET_AUX_PATH%\synset_words.txt
+set ML_MODEL_DATA_LAYOUT=NCHW
+set CK_BATCH_SIZE=%CM_BATCH_SIZE%
+set CK_BATCH_COUNT=%CM_BATCH_COUNT%
+
+IF NOT DEFINED CM_TMP_CURRENT_SCRIPT_PATH SET CM_TMP_CURRENT_SCRIPT_PATH=%CD%
+
+IF DEFINED CM_INPUT SET CM_IMAGE=%CM_INPUT%
+
+echo.
+%CM_PYTHON_BIN_WITH_PATH% -m pip install -r %CM_TMP_CURRENT_SCRIPT_PATH%\requirements.txt
+IF %ERRORLEVEL% NEQ 0 EXIT %ERRORLEVEL%
+
+echo.
+%CM_PYTHON_BIN_WITH_PATH% %CM_TMP_CURRENT_SCRIPT_PATH%\src\onnx_classify.py
+IF %ERRORLEVEL% NEQ 0 EXIT %ERRORLEVEL%
+
+rem Just a demo to pass environment variables from native scripts back to CM workflows
+echo CM_APP_IMAGE_CLASSIFICATION_ONNX_PY=sucess > tmp-run-env.out
diff --git a/script/app-image-classification-onnx-py/run.sh b/script/app-image-classification-onnx-py/run.sh
new file mode 100644
index 0000000000..62b07e1f10
--- /dev/null
+++ b/script/app-image-classification-onnx-py/run.sh
@@ -0,0 +1,37 @@
+#!/bin/bash
+
+if [[ ${CM_RUN_DOCKER_CONTAINER} == "yes" ]]; then
+ exit 0
+fi
+
+#echo ${CM_PYTHON_BIN}
+#echo ${CM_DATASET_PATH}
+#echo ${CM_DATASET_AUX_PATH}
+#echo ${CM_ML_MODEL_FILE_WITH_PATH}
+CM_PYTHON_BIN=${CM_PYTHON_BIN_WITH_PATH:-python3}
+CM_TMP_CURRENT_SCRIPT_PATH=${CM_TMP_CURRENT_SCRIPT_PATH:-$PWD}
+
+# connect CM intelligent components with CK env
+export CK_ENV_ONNX_MODEL_ONNX_FILEPATH=${CM_ML_MODEL_FILE_WITH_PATH}
+export CK_ENV_ONNX_MODEL_INPUT_LAYER_NAME="input_tensor:0"
+export CK_ENV_ONNX_MODEL_OUTPUT_LAYER_NAME="softmax_tensor:0"
+export CK_ENV_DATASET_IMAGENET_VAL=${CM_DATASET_PATH}
+export CK_CAFFE_IMAGENET_SYNSET_WORDS_TXT=${CM_DATASET_AUX_PATH}/synset_words.txt
+export ML_MODEL_DATA_LAYOUT="NCHW"
+export CK_BATCH_SIZE=${CM_BATCH_SIZE}
+export CK_BATCH_COUNT=${CM_BATCH_COUNT}
+
+if [[ "${CM_INPUT}" != "" ]]; then export CM_IMAGE=${CM_INPUT}; fi
+
+PIP_EXTRA=`${CM_PYTHON_BIN} -c "import importlib.metadata; print(' --break-system-packages ' if int(importlib.metadata.version('pip').split('.')[0]) >= 23 else '')"`
+
+echo ""
+${CM_PYTHON_BIN} -m pip install -r ${CM_TMP_CURRENT_SCRIPT_PATH}/requirements.txt ${PIP_EXTRA}
+test $? -eq 0 || exit 1
+
+echo ""
+${CM_PYTHON_BIN} ${CM_TMP_CURRENT_SCRIPT_PATH}/src/onnx_classify.py
+test $? -eq 0 || exit 1
+
+# Just a demo to pass environment variables from native scripts back to CM workflows
+echo "CM_APP_IMAGE_CLASSIFICATION_ONNX_PY=sucess" > tmp-run-env.out
diff --git a/script/app-image-classification-onnx-py/src/onnx_classify.py b/script/app-image-classification-onnx-py/src/onnx_classify.py
new file mode 100644
index 0000000000..00baaab149
--- /dev/null
+++ b/script/app-image-classification-onnx-py/src/onnx_classify.py
@@ -0,0 +1,172 @@
+#!/usr/bin/env python3
+
+# Extended by Grigori Fursin to support MLCommons CM workflow automation language
+
+import os
+import onnxruntime as rt
+import numpy as np
+import time
+import json
+
+from PIL import Image
+
+model_path = os.environ['CK_ENV_ONNX_MODEL_ONNX_FILEPATH']
+input_layer_name = os.environ['CK_ENV_ONNX_MODEL_INPUT_LAYER_NAME']
+output_layer_name = os.environ['CK_ENV_ONNX_MODEL_OUTPUT_LAYER_NAME']
+normalize_data_bool = os.getenv('CK_ENV_ONNX_MODEL_NORMALIZE_DATA', '0') in ('YES', 'yes', 'ON', 'on', '1')
+subtract_mean_bool = os.getenv('CK_ENV_ONNX_MODEL_SUBTRACT_MEAN', '0') in ('YES', 'yes', 'ON', 'on', '1')
+given_channel_means = os.getenv('ML_MODEL_GIVEN_CHANNEL_MEANS','')
+if given_channel_means:
+ given_channel_means = np.array(given_channel_means.split(' '), dtype=np.float32)
+
+imagenet_path = os.environ['CK_ENV_DATASET_IMAGENET_VAL']
+labels_path = os.environ['CK_CAFFE_IMAGENET_SYNSET_WORDS_TXT']
+data_layout = os.environ['ML_MODEL_DATA_LAYOUT']
+batch_size = int( os.environ['CK_BATCH_SIZE'] )
+batch_count = int( os.environ['CK_BATCH_COUNT'] )
+CPU_THREADS = int(os.getenv('CK_HOST_CPU_NUMBER_OF_PROCESSORS',0))
+
+
+def load_labels(labels_filepath):
+ my_labels = []
+ input_file = open(labels_filepath, 'r')
+ for l in input_file:
+ my_labels.append(l.strip())
+ return my_labels
+
+
+def load_and_resize_image(image_filepath, height, width):
+ pillow_img = Image.open(image_filepath).resize((width, height)) # sic! The order of dimensions in resize is (W,H)
+
+ # Grigori fixed below
+ #input_data = np.float32(pillow_img)
+ input_data=np.asarray(pillow_img)
+ input_data=np.asarray(input_data, np.float32)
+
+ # Normalize
+ if normalize_data_bool:
+ input_data = input_data/127.5 - 1.0
+
+ # Subtract mean value
+ if subtract_mean_bool:
+ if len(given_channel_means):
+ input_data -= given_channel_means
+ else:
+ input_data -= np.mean(input_data)
+
+# print(np.array(pillow_img).shape)
+ nhwc_data = np.expand_dims(input_data, axis=0)
+
+ if data_layout == 'NHWC':
+ # print(nhwc_data.shape)
+ return nhwc_data
+ else:
+ nchw_data = nhwc_data.transpose(0,3,1,2)
+ # print(nchw_data.shape)
+ return nchw_data
+
+
+def load_a_batch(batch_filenames):
+ unconcatenated_batch_data = []
+ for image_filename in batch_filenames:
+ image_filepath = image_filename
+ nchw_data = load_and_resize_image( image_filepath, height, width )
+ unconcatenated_batch_data.append( nchw_data )
+ batch_data = np.concatenate(unconcatenated_batch_data, axis=0)
+
+ return batch_data
+
+
+
+#print("Device: " + rt.get_device())
+
+sess_options = rt.SessionOptions()
+
+if CPU_THREADS > 0:
+ sess_options.enable_sequential_execution = False
+ sess_options.session_thread_pool_size = CPU_THREADS
+
+if len(rt.get_all_providers()) > 1 and os.environ.get("USE_CUDA", "yes").lower() not in [ "0", "false", "off", "no" ]:
+ #Currently considering only CUDAExecutionProvider
+ sess = rt.InferenceSession(model_path, sess_options, providers=['CUDAExecutionProvider'])
+else:
+ sess = rt.InferenceSession(model_path, sess_options, providers=["CPUExecutionProvider"])
+
+input_layer_names = [ x.name for x in sess.get_inputs() ] # FIXME: check that input_layer_name belongs to this list
+input_layer_name = input_layer_name or input_layer_names[0]
+
+output_layer_names = [ x.name for x in sess.get_outputs() ] # FIXME: check that output_layer_name belongs to this list
+output_layer_name = output_layer_name or output_layer_names[0]
+
+model_input_shape = sess.get_inputs()[0].shape
+model_classes = sess.get_outputs()[1].shape[1]
+labels = load_labels(labels_path)
+bg_class_offset = model_classes-len(labels) # 1 means the labels represent classes 1..1000 and the background class 0 has to be skipped
+
+if data_layout == 'NHWC':
+ (samples, height, width, channels) = model_input_shape
+else:
+ (samples, channels, height, width) = model_input_shape
+
+print("")
+print("Data layout: {}".format(data_layout) )
+print("Input layers: {}".format([ str(x) for x in sess.get_inputs()]))
+print("Output layers: {}".format([ str(x) for x in sess.get_outputs()]))
+print("Input layer name: " + input_layer_name)
+print("Expected input shape: {}".format(model_input_shape))
+print("Output layer name: " + output_layer_name)
+print("Data normalization: {}".format(normalize_data_bool))
+print("Subtract mean: {}".format(subtract_mean_bool))
+print('Per-channel means to subtract: {}'.format(given_channel_means))
+print("Background/unlabelled classes to skip: {}".format(bg_class_offset))
+print("")
+
+starting_index = 1
+
+start_time = time.time()
+
+for batch_idx in range(batch_count):
+ print ('')
+ print ("Batch {}/{}:".format(batch_idx+1, batch_count))
+
+ batch_filenames = [ imagenet_path + '/' + "ILSVRC2012_val_00000{:03d}.JPEG".format(starting_index + batch_idx*batch_size + i) for i in range(batch_size) ]
+
+ # Grigori: trick to test models:
+ if os.environ.get('CM_IMAGE','')!='':
+ batch_filenames=[os.environ['CM_IMAGE']]
+
+ batch_data = load_a_batch( batch_filenames )
+ #print(batch_data.shape)
+
+ batch_predictions = sess.run([output_layer_name], {input_layer_name: batch_data})[0]
+
+ cm_status = {'classifications':[]}
+
+ print ('')
+ top_classification = ''
+ for in_batch_idx in range(batch_size):
+ softmax_vector = batch_predictions[in_batch_idx][bg_class_offset:] # skipping the background class on the left (if present)
+ top5_indices = list(reversed(softmax_vector.argsort()))[:5]
+
+ print(' * ' + batch_filenames[in_batch_idx] + ' :')
+
+ for class_idx in top5_indices:
+ if top_classification == '':
+ top_classification = labels[class_idx]
+
+ print("\t{}\t{}\t{}".format(class_idx, softmax_vector[class_idx], labels[class_idx]))
+
+ cm_status['classifications'].append({'class_idx':int(class_idx),
+ 'softmax': float(softmax_vector[class_idx]),
+ 'label':labels[class_idx]})
+
+ print ('')
+ print ('Top classification: {}'.format(top_classification))
+ cm_status['top_classification'] = top_classification
+
+avg_time = (time.time() - start_time) / batch_count
+cm_status['avg_time'] = avg_time
+
+# Record cm_status to embedded it into CM workflows
+with open('tmp-run-state.json', 'w') as cm_file:
+ cm_file.write(json.dumps({'cm_app_image_classification_onnx_py':cm_status}, sort_keys=True, indent=2))
diff --git a/script/app-image-classification-onnx-py/tests/README.md b/script/app-image-classification-onnx-py/tests/README.md
new file mode 100644
index 0000000000..899509cb7f
--- /dev/null
+++ b/script/app-image-classification-onnx-py/tests/README.md
@@ -0,0 +1,14 @@
+```bash
+docker system prune -a -f
+
+cmr "download file _wget" --url=https://cKnowledge.org/ai/data/computer_mouse.jpg --verify=no --env.CM_DOWNLOAD_CHECKSUM=45ae5c940233892c2f860efdf0b66e7e
+
+cm docker script "python app image-classification onnx" --docker_cm_repo=ctuning@mlcommons-ck --env.CM_IMAGE=computer_mouse.jpg
+cm docker script "python app image-classification onnx" --docker_cm_repo=ctuning@mlcommons-ck --input=computer_mouse.jpg
+
+cmrd "python app image-classification onnx" --docker_cm_repo=ctuning@mlcommons-ck --input=computer_mouse.jpg -j --docker_it
+
+cmrd "python app image-classification onnx" --docker_cm_repo=ctuning@mlcommons-ck --input=computer_mouse.jpg --output=.
+
+
+```
diff --git a/script/app-image-classification-tf-onnx-cpp/README-extra.md b/script/app-image-classification-tf-onnx-cpp/README-extra.md
new file mode 100644
index 0000000000..5e59c8fede
--- /dev/null
+++ b/script/app-image-classification-tf-onnx-cpp/README-extra.md
@@ -0,0 +1,3 @@
+# Image Classification App in C++ for ResNet50 model
+
+* In development stage, not complete
diff --git a/script/app-image-classification-tf-onnx-cpp/README.md b/script/app-image-classification-tf-onnx-cpp/README.md
new file mode 100644
index 0000000000..11f9495bd4
--- /dev/null
+++ b/script/app-image-classification-tf-onnx-cpp/README.md
@@ -0,0 +1,135 @@
+Automatically generated README for this automation recipe: **app-image-classification-tf-onnx-cpp**
+
+Category: **Modular AI/ML application pipeline**
+
+License: **Apache 2.0**
+
+Maintainers: [Public MLCommons Task Force on Automation and Reproducibility](https://github.com/mlcommons/ck/blob/master/docs/taskforce.md)
+
+---
+*[ [Online info and GUI to run this CM script](https://access.cknowledge.org/playground/?action=scripts&name=app-image-classification-tf-onnx-cpp,879ed32e47074033) ] [ [Notes from the authors, contributors and users](README-extra.md) ]*
+
+---
+#### Summary
+
+* CM GitHub repository: *[mlcommons@ck](https://github.com/mlcommons/ck/tree/dev/cm-mlops)*
+* GitHub directory for this script: *[GitHub](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-tf-onnx-cpp)*
+* CM meta description for this script: *[_cm.json](_cm.json)*
+* All CM tags to find and reuse this script (see in above meta description): *app,image-classification,cpp,tensorflow,onnx*
+* Output cached? *False*
+* See [pipeline of dependencies](#dependencies-on-other-cm-scripts) on other CM scripts
+
+
+---
+### Reuse this script in your project
+
+#### Install MLCommons CM automation meta-framework
+
+* [Install CM](https://access.cknowledge.org/playground/?action=install)
+* [CM Getting Started Guide](https://github.com/mlcommons/ck/blob/master/docs/getting-started.md)
+
+#### Pull CM repository with this automation recipe (CM script)
+
+```cm pull repo mlcommons@ck```
+
+#### Print CM help from the command line
+
+````cmr "app image-classification cpp tensorflow onnx" --help````
+
+#### Customize and run this script from the command line with different variations and flags
+
+`cm run script --tags=app,image-classification,cpp,tensorflow,onnx`
+
+`cm run script --tags=app,image-classification,cpp,tensorflow,onnx `
+
+*or*
+
+`cmr "app image-classification cpp tensorflow onnx"`
+
+`cmr "app image-classification cpp tensorflow onnx " `
+
+
+#### Run this script from Python
+
+
+Click here to expand this section.
+
+```python
+
+import cmind
+
+r = cmind.access({'action':'run'
+ 'automation':'script',
+ 'tags':'app,image-classification,cpp,tensorflow,onnx'
+ 'out':'con',
+ ...
+ (other input keys for this script)
+ ...
+ })
+
+if r['return']>0:
+ print (r['error'])
+
+```
+
+
+
+
+#### Run this script via GUI
+
+```cmr "cm gui" --script="app,image-classification,cpp,tensorflow,onnx"```
+
+Use this [online GUI](https://cKnowledge.org/cm-gui/?tags=app,image-classification,cpp,tensorflow,onnx) to generate CM CMD.
+
+#### Run this script via Docker (beta)
+
+`cm docker script "app image-classification cpp tensorflow onnx" `
+
+___
+### Customization
+
+#### Default environment
+
+
+Click here to expand this section.
+
+These keys can be updated via `--env.KEY=VALUE` or `env` dictionary in `@input.json` or using script flags.
+
+* CM_BATCH_COUNT: `1`
+* CM_BATCH_SIZE: `1`
+
+
+
+___
+### Dependencies on other CM scripts
+
+
+ 1. ***Read "deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-tf-onnx-cpp/_cm.json)***
+ * detect,os
+ - CM script: [detect-os](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/detect-os)
+ * get,sys-utils-cm
+ - CM script: [get-sys-utils-cm](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-sys-utils-cm)
+ * get,gcc
+ - CM script: [get-gcc](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-gcc)
+ * get,dataset,image-classification,original
+ - CM script: [get-dataset-imagenet-val](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-dataset-imagenet-val)
+ * get,dataset-aux,image-classification
+ - CM script: [get-dataset-imagenet-aux](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-dataset-imagenet-aux)
+ * get,ml-model,raw,image-classification,resnet50,_onnx,_opset-11
+ - CM script: [get-ml-model-resnet50](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-ml-model-resnet50)
+ * tensorflow,from-src
+ - CM script: [install-tensorflow-from-src](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/install-tensorflow-from-src)
+ 1. Run "preprocess" function from customize.py
+ 1. Read "prehook_deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-tf-onnx-cpp/_cm.json)
+ 1. ***Run native script if exists***
+ * [run.sh](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-tf-onnx-cpp/run.sh)
+ 1. Read "posthook_deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-tf-onnx-cpp/_cm.json)
+ 1. Run "postrocess" function from customize.py
+ 1. Read "post_deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-tf-onnx-cpp/_cm.json)
+
+___
+### Script output
+`cmr "app image-classification cpp tensorflow onnx " -j`
+#### New environment keys (filter)
+
+#### New environment keys auto-detected from customize
diff --git a/script/app-image-classification-tf-onnx-cpp/_cm.json b/script/app-image-classification-tf-onnx-cpp/_cm.json
new file mode 100644
index 0000000000..0baccd0cb1
--- /dev/null
+++ b/script/app-image-classification-tf-onnx-cpp/_cm.json
@@ -0,0 +1,46 @@
+{
+ "alias": "app-image-classification-tf-onnx-cpp",
+ "automation_alias": "script",
+ "automation_uid": "5b4e0237da074764",
+ "category": "Modular AI/ML application pipeline",
+ "default_env": {
+ "CM_BATCH_COUNT": "1",
+ "CM_BATCH_SIZE": "1"
+ },
+ "deps": [
+ {
+ "tags": "detect,os"
+ },
+ {
+ "tags": "get,sys-utils-cm"
+ },
+ {
+ "tags": "get,gcc"
+ },
+ {
+ "tags": "get,dataset,image-classification,original"
+ },
+ {
+ "tags": "get,dataset-aux,image-classification"
+ },
+ {
+ "tags": "get,ml-model,raw,image-classification,resnet50,_onnx,_opset-11"
+ },
+ {
+ "tags": "tensorflow,from-src",
+ "version": "v2.0.0"
+ }
+ ],
+ "tags": [
+ "app",
+ "image-classification",
+ "tf",
+ "tensorflow",
+ "tf-onnx",
+ "tensorflow-onnx",
+ "onnx",
+ "cpp"
+ ],
+ "tags_help":"app image-classification cpp tensorflow onnx",
+ "uid": "879ed32e47074033"
+}
diff --git a/script/app-image-classification-tf-onnx-cpp/include/benchmark.h b/script/app-image-classification-tf-onnx-cpp/include/benchmark.h
new file mode 100644
index 0000000000..42b0418fce
--- /dev/null
+++ b/script/app-image-classification-tf-onnx-cpp/include/benchmark.h
@@ -0,0 +1,511 @@
+/*
+ * Copyright (c) 2018 cTuning foundation.
+ * See CK COPYRIGHT.txt for copyright details.
+ *
+ * See CK LICENSE for licensing details.
+ * See CK COPYRIGHT for copyright details.
+ */
+
+#pragma once
+
+#include
+#include
+
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+
+//#include
+
+#define DEBUG(msg) std::cout << "DEBUG: " << msg << std::endl;
+
+namespace CK {
+
+enum _TIMERS {
+ X_TIMER_SETUP,
+ X_TIMER_TEST,
+
+ X_TIMER_COUNT
+};
+
+enum _VARS {
+ X_VAR_TIME_SETUP,
+ X_VAR_TIME_TEST,
+ X_VAR_TIME_IMG_LOAD_TOTAL,
+ X_VAR_TIME_IMG_LOAD_AVG,
+ X_VAR_TIME_CLASSIFY_TOTAL,
+ X_VAR_TIME_CLASSIFY_AVG,
+
+ X_VAR_COUNT
+};
+
+enum MODEL_TYPE {
+ LITE,
+ TF_FROZEN
+};
+
+/// Store named value into xopenme variable.
+inline void store_value_f(int index, const char* name, float value) {
+ char* json_name = new char[strlen(name) + 6];
+ sprintf(json_name, "\"%s\":%%f", name);
+ //xopenme_add_var_f(index, json_name, value);
+ delete[] json_name;
+}
+
+/// Load mandatory string value from the environment.
+inline std::string getenv_s(const std::string& name) {
+ const char *value = getenv(name.c_str());
+ if (!value)
+ throw "Required environment variable " + name + " is not set";
+ return std::string(value);
+}
+
+/// Load mandatory integer value from the environment.
+inline int getenv_i(const std::string& name) {
+ const char *value = getenv(name.c_str());
+ if (!value)
+ throw "Required environment variable " + name + " is not set";
+ return atoi(value);
+}
+
+/// Load mandatory float value from the environment.
+inline float getenv_f(const std::string& name) {
+ const char *value = getenv(name.c_str());
+ if (!value)
+ throw "Required environment variable " + name + " is not set";
+ return atof(value);
+}
+
+/// Dummy `sprintf` like formatting function using std::string.
+/// It uses buffer of fixed length so can't be used in any cases,
+/// generally use it for short messages with numeric arguments.
+template
+inline std::string format(const char* str, Args ...args) {
+ char buf[1024];
+ sprintf(buf, str, args...);
+ return std::string(buf);
+}
+
+//----------------------------------------------------------------------
+
+class Accumulator {
+public:
+ void reset() { _total = 0, _count = 0; }
+ void add(float value) { _total += value, _count++; }
+ float total() const { return _total; }
+ float avg() const { return _total / static_cast(_count); }
+private:
+ float _total = 0;
+ int _count = 0;
+};
+
+//----------------------------------------------------------------------
+
+class BenchmarkSettings {
+public:
+ const std::string images_dir = getenv_s("CK_ENV_DATASET_IMAGENET_PREPROCESSED_DIR");
+ const std::string images_file = getenv_s("CK_ENV_DATASET_IMAGENET_PREPROCESSED_SUBSET_FOF");
+ const bool skip_internal_preprocessing = getenv("CK_ENV_DATASET_IMAGENET_PREPROCESSED_DATA_TYPE")
+ && ( getenv_s("CK_ENV_DATASET_IMAGENET_PREPROCESSED_DATA_TYPE") == "float32" );
+
+ const std::string result_dir = getenv_s("CK_RESULTS_DIR");
+ const std::string input_layer_name = getenv_s("CK_ENV_TENSORFLOW_MODEL_INPUT_LAYER_NAME");
+ const std::string output_layer_name = getenv_s("CK_ENV_TENSORFLOW_MODEL_OUTPUT_LAYER_NAME");
+ const int batch_count = getenv_i("CK_BATCH_COUNT");
+ const int batch_size = getenv_i("CK_BATCH_SIZE");
+ const int image_size = getenv_i("CK_ENV_DATASET_IMAGENET_PREPROCESSED_INPUT_SQUARE_SIDE");
+ const int num_channels = 3;
+ const int num_classes = 1000;
+ const bool normalize_img = getenv_s("CK_ENV_TENSORFLOW_MODEL_NORMALIZE_DATA") == "YES";
+ const bool subtract_mean = getenv_s("CK_ENV_TENSORFLOW_MODEL_SUBTRACT_MEAN") == "YES";
+ const char *given_channel_means_str = getenv("CM_ML_MODEL_GIVEN_CHANNEL_MEANS");
+
+ const bool full_report = getenv_i("CK_SILENT_MODE") == 0;
+
+ BenchmarkSettings(enum MODEL_TYPE mode = MODEL_TYPE::LITE) {
+
+ if(given_channel_means_str) {
+ std::stringstream ss(given_channel_means_str);
+ for(int i=0;i<3;i++){
+ ss >> given_channel_means[i];
+ }
+ }
+
+ switch (mode)
+ {
+ case MODEL_TYPE::LITE:
+ _graph_file = getenv_s("CK_ENV_TENSORFLOW_MODEL_TFLITE_FILEPATH");
+ break;
+
+ case MODEL_TYPE::TF_FROZEN:
+ _graph_file = getenv_s("CK_ENV_TENSORFLOW_MODEL_TF_FROZEN_FILEPATH");
+ break;
+
+ default:
+ std::cout << "Unsupported MODEL_TYPE" << std::endl;
+ exit(1);
+ break;
+ };
+ _number_of_threads = std::thread::hardware_concurrency();
+ _number_of_threads = _number_of_threads < 1 ? 1 : _number_of_threads;
+ _number_of_threads = !getenv("CK_HOST_CPU_NUMBER_OF_PROCESSORS")
+ ? _number_of_threads
+ : getenv_i("CK_HOST_CPU_NUMBER_OF_PROCESSORS");
+
+ // Print settings
+ std::cout << "Graph file: " << _graph_file << std::endl;
+ std::cout << "Image dir: " << images_dir << std::endl;
+ std::cout << "Image list: " << images_file << std::endl;
+ std::cout << "Image size: " << image_size << std::endl;
+ std::cout << "Image channels: " << num_channels << std::endl;
+ std::cout << "Prediction classes: " << num_classes << std::endl;
+ std::cout << "Result dir: " << result_dir << std::endl;
+ std::cout << "Batch count: " << batch_count << std::endl;
+ std::cout << "Batch size: " << batch_size << std::endl;
+ std::cout << "Normalize: " << normalize_img << std::endl;
+ std::cout << "Subtract mean: " << subtract_mean << std::endl;
+ if(subtract_mean && given_channel_means_str)
+ std::cout << "Per-channel means to subtract: " << given_channel_means[0]
+ << ", " << given_channel_means[1]
+ << ", " << given_channel_means[2] << std::endl;
+
+ // Create results dir if none
+ auto dir = opendir(result_dir.c_str());
+ if (dir)
+ closedir(dir);
+ else
+ system(("mkdir " + result_dir).c_str());
+
+ // Load list of images to be processed
+ std::ifstream file(images_file);
+ if (!file)
+ throw "Unable to open image list file " + images_file;
+ for (std::string s; !getline(file, s).fail();)
+ _image_list.emplace_back(s);
+ std::cout << "Image count in file: " << _image_list.size() << std::endl;
+ }
+
+ const std::vector& image_list() const { return _image_list; }
+
+ std::vector _image_list;
+
+ int number_of_threads() { return _number_of_threads; }
+
+ std::string graph_file() { return _graph_file; }
+
+ float given_channel_means[3];
+private:
+ int _number_of_threads;
+ std::string _graph_file;
+};
+
+//----------------------------------------------------------------------
+
+class BenchmarkSession {
+public:
+ BenchmarkSession(const BenchmarkSettings* settings): _settings(settings) {
+ }
+
+ virtual ~BenchmarkSession() {}
+
+ float total_load_images_time() const { return _loading_time.total(); }
+ float total_prediction_time() const { return _total_prediction_time; }
+ float avg_load_images_time() const { return _loading_time.avg(); }
+ float avg_prediction_time() const { return _prediction_time.avg(); }
+
+ bool get_next_batch() {
+ if (_batch_index+1 == _settings->batch_count)
+ return false;
+ _batch_index++;
+ int batch_number = _batch_index+1;
+ if (_settings->full_report || batch_number%10 == 0)
+ std::cout << "\nBatch " << batch_number << " of " << _settings->batch_count << std::endl;
+ int begin = _batch_index * _settings->batch_size;
+ int end = (_batch_index + 1) * _settings->batch_size;
+ int images_count = _settings->image_list().size();
+ if (begin >= images_count || end > images_count)
+ throw format("Not enough images to populate batch %d", _batch_index);
+ _batch_files.clear();
+ for (int i = begin; i < end; i++)
+ _batch_files.emplace_back(_settings->image_list()[i]);
+ return true;
+ }
+
+ /// Begin measuring of new benchmark stage.
+ /// Only one stage can be measured at a time.
+ void measure_begin() {
+ _start_time = std::chrono::high_resolution_clock::now();
+ }
+
+ /// Finish measuring of batch loading stage
+ float measure_end_load_images() {
+ float duration = measure_end();
+ if (_settings->full_report)
+ std::cout << "Batch loaded in " << duration << " s" << std::endl;
+ _loading_time.add(duration);
+ return duration;
+ }
+
+ /// Finish measuring of batch prediction stage
+ float measure_end_prediction() {
+ float duration = measure_end();
+ _total_prediction_time += duration;
+ if (_settings->full_report)
+ std::cout << "Batch classified in " << duration << " s" << std::endl;
+ // Skip first batch in order to account warming-up the system
+ if (_batch_index > 0 || _settings->batch_count == 1)
+ _prediction_time.add(duration);
+ return duration;
+ }
+
+ int batch_index() const { return _batch_index; }
+ const std::vector& batch_files() const { return _batch_files; }
+
+private:
+ int _batch_index = -1;
+ Accumulator _loading_time;
+ Accumulator _prediction_time;
+ const BenchmarkSettings* _settings;
+ float _total_prediction_time = 0;
+ std::vector _batch_files;
+ std::chrono::time_point _start_time;
+
+ float measure_end() const {
+ auto finish_time = std::chrono::high_resolution_clock::now();
+ std::chrono::duration elapsed = finish_time - _start_time;
+ return static_cast(elapsed.count());
+ }
+};
+
+//----------------------------------------------------------------------
+
+inline void init_benchmark() {
+ //xopenme_init(X_TIMER_COUNT, X_VAR_COUNT);
+}
+
+inline void finish_benchmark(const BenchmarkSession& s) {
+ // Store metrics
+ /* store_value_f(X_VAR_TIME_SETUP, "setup_time_s", xopenme_get_timer(X_TIMER_SETUP));
+ store_value_f(X_VAR_TIME_TEST, "test_time_s", xopenme_get_timer(X_TIMER_TEST));
+ store_value_f(X_VAR_TIME_IMG_LOAD_TOTAL, "images_load_time_total_s", s.total_load_images_time());
+ store_value_f(X_VAR_TIME_IMG_LOAD_AVG, "images_load_time_avg_s", s.avg_load_images_time());
+ store_value_f(X_VAR_TIME_CLASSIFY_TOTAL, "prediction_time_total_s", s.total_prediction_time());
+ store_value_f(X_VAR_TIME_CLASSIFY_AVG, "prediction_time_avg_s", s.avg_prediction_time());
+
+ // Finish xopenmp
+ xopenme_dump_state();
+ xopenme_finish();*/
+}
+
+template
+void measure_setup(L &&lambda_function) {
+ //xopenme_clock_start(X_TIMER_SETUP);
+ lambda_function();
+ //xopenme_clock_end(X_TIMER_SETUP);
+}
+
+template
+void measure_prediction(L &&lambda_function) {
+ //xopenme_clock_start(X_TIMER_TEST);
+ lambda_function();
+ //xopenme_clock_end(X_TIMER_TEST);
+}
+
+//----------------------------------------------------------------------
+
+template
+class StaticBuffer {
+public:
+ StaticBuffer(int size, const std::string& dir): _size(size), _dir(dir) {
+ _buffer = new TData[size];
+ }
+
+ virtual ~StaticBuffer() {
+ delete[] _buffer;
+ }
+
+ TData* data() const { return _buffer; }
+ int size() const { return _size; }
+
+protected:
+ const int _size;
+ const std::string _dir;
+ TData* _buffer;
+};
+
+//----------------------------------------------------------------------
+
+class ImageData : public StaticBuffer {
+public:
+ ImageData(const BenchmarkSettings* s): StaticBuffer(
+ s->image_size * s->image_size * s->num_channels * (s->skip_internal_preprocessing ? sizeof(float) : sizeof(uint8_t)),
+ s->images_dir) {}
+
+ void load(const std::string& filename) {
+ auto path = _dir + '/' + filename;
+ std::ifstream file(path, std::ios::in | std::ios::binary);
+ if (!file) throw "Failed to open image data " + path;
+ file.read(reinterpret_cast(_buffer), _size);
+ }
+};
+
+//----------------------------------------------------------------------
+
+class ResultData : public StaticBuffer {
+public:
+ ResultData(const BenchmarkSettings* s): StaticBuffer(
+ s->num_classes, s->result_dir) {}
+
+ void save(const std::string& filename) {
+ auto path = _dir + '/' + filename + ".txt";
+ std::ofstream file(path);
+ if (!file) throw "Unable to create result file " + path;
+ for (int i = 0; i < _size; i++)
+ file << _buffer[i] << std::endl;
+ }
+};
+
+//----------------------------------------------------------------------
+
+class IBenchmark {
+public:
+ bool has_background_class = false;
+
+ virtual ~IBenchmark() {}
+ virtual void load_images(const std::vector& batch_images) = 0;
+ virtual void save_results(const std::vector& batch_images) = 0;
+};
+
+
+template
+class Benchmark : public IBenchmark {
+public:
+ Benchmark(const BenchmarkSettings* settings, TData *in_ptr, TData *out_ptr) {
+ _in_ptr = in_ptr;
+ _out_ptr = out_ptr;
+ _in_data.reset(new ImageData(settings));
+ _out_data.reset(new ResultData(settings));
+ _in_converter.reset(new TInConverter(settings));
+ _out_converter.reset(new TOutConverter(settings));
+ }
+
+ void load_images(const std::vector& batch_images) override {
+ int image_offset = 0;
+ for (auto image_file : batch_images) {
+ _in_data->load(image_file);
+ _in_converter->convert(_in_data.get(), _in_ptr + image_offset);
+ image_offset += _in_data->size();
+ }
+ }
+
+ void save_results(const std::vector& batch_images) override {
+ int image_offset = 0;
+ int probe_offset = has_background_class ? 1 : 0;
+ for (auto image_file : batch_images) {
+ _out_converter->convert(_out_ptr + image_offset + probe_offset, _out_data.get());
+ _out_data->save(image_file);
+ image_offset += _out_data->size() + probe_offset;
+ }
+ }
+
+private:
+ TData* _in_ptr;
+ TData* _out_ptr;
+ std::unique_ptr _in_data;
+ std::unique_ptr _out_data;
+ std::unique_ptr _in_converter;
+ std::unique_ptr _out_converter;
+};
+
+//----------------------------------------------------------------------
+
+class IinputConverter {
+public:
+ virtual ~IinputConverter() {}
+ virtual void convert(const ImageData* source, void* target) = 0;
+};
+
+//----------------------------------------------------------------------
+
+class InCopy : public IinputConverter {
+public:
+ InCopy(const BenchmarkSettings* s) {}
+
+ void convert(const ImageData* source, void* target) {
+ uint8_t *uint8_target = static_cast(target);
+ std::copy(source->data(), source->data() + source->size(), uint8_target);
+ }
+};
+
+//----------------------------------------------------------------------
+
+class InNormalize : public IinputConverter {
+public:
+ InNormalize(const BenchmarkSettings* s):
+ _normalize_img(s->normalize_img),
+ _subtract_mean(s->subtract_mean),
+ _given_channel_means(s->given_channel_means),
+ _num_channels(s->num_channels) {
+ }
+
+ void convert(const ImageData* source, void* target) {
+ // Copy image data to target
+ float *float_target = static_cast(target);
+ float sum = 0;
+ for (int i = 0; i < source->size(); i++) {
+ float px = source->data()[i];
+ if (_normalize_img)
+ px = (px / 255.0 - 0.5) * 2.0;
+ sum += px;
+ float_target[i] = px;
+ }
+ // Subtract mean value if required
+ if (_subtract_mean) {
+ if(_given_channel_means) {
+ for (int i = 0; i < source->size(); i++)
+ float_target[i] -= _given_channel_means[i % _num_channels]; // assuming NHWC order!
+ } else {
+ float mean = sum / static_cast(source->size());
+ for (int i = 0; i < source->size(); i++)
+ float_target[i] -= mean;
+ }
+ }
+ }
+
+private:
+ const bool _normalize_img;
+ const bool _subtract_mean;
+ const float *_given_channel_means;
+ const int _num_channels;
+};
+
+//----------------------------------------------------------------------
+
+class OutCopy {
+public:
+ OutCopy(const BenchmarkSettings* s) {}
+
+ void convert(const float* source, ResultData* target) const {
+ std::copy(source, source + target->size(), target->data());
+ }
+};
+
+//----------------------------------------------------------------------
+
+class OutDequantize {
+public:
+ OutDequantize(const BenchmarkSettings* s) {}
+
+ void convert(const uint8_t* source, ResultData* target) const {
+ for (int i = 0; i < target->size(); i++)
+ target->data()[i] = source[i] / 255.0;
+ }
+};
+
+} // namespace CK
diff --git a/script/app-image-classification-tf-onnx-cpp/run.sh b/script/app-image-classification-tf-onnx-cpp/run.sh
new file mode 100644
index 0000000000..b4a46853bc
--- /dev/null
+++ b/script/app-image-classification-tf-onnx-cpp/run.sh
@@ -0,0 +1,6 @@
+#!/bin/bash
+
+CM_TMP_CURRENT_SCRIPT_PATH=${CM_TMP_CURRENT_SCRIPT_PATH:-$PWD}
+${CM_CXX_COMPILER_WITH_PATH} -O3 ${CM_TMP_CURRENT_SCRIPT_PATH}/src/classification.cpp -o classification.exe -ltensorflow
+
+test $? -eq 0 || exit 1
diff --git a/script/app-image-classification-tf-onnx-cpp/src/classification.cpp b/script/app-image-classification-tf-onnx-cpp/src/classification.cpp
new file mode 100644
index 0000000000..a9ee5ee50e
--- /dev/null
+++ b/script/app-image-classification-tf-onnx-cpp/src/classification.cpp
@@ -0,0 +1,107 @@
+/*
+ * Copyright (c) 2018 cTuning foundation.
+ * See CK COPYRIGHT.txt for copyright details.
+ *
+ * See CK LICENSE for licensing details.
+ * See CK COPYRIGHT for copyright details.
+ */
+
+// TODO: this header should be moved to a common location (where?)
+#include "../include/benchmark.h"
+
+#include "tensorflow/core/public/session.h"
+#include "tensorflow/cc/framework/scope.h"
+
+using namespace std;
+using namespace CK;
+using namespace tensorflow;
+
+int main(int argc, char* argv[]) {
+ try {
+ init_benchmark();
+
+ BenchmarkSettings settings(MODEL_TYPE::TF_FROZEN);
+ BenchmarkSession session(&settings);
+ ImageData input_data(&settings);
+ ResultData result_data(&settings);
+ unique_ptr input_converter;
+ OutCopy result_converter(&settings);
+ unique_ptr tf_session;
+ GraphDef graph_def;
+
+ if (settings.skip_internal_preprocessing)
+ input_converter.reset(new InCopy(&settings));
+ else
+ input_converter.reset(new InNormalize(&settings));
+
+ // TODO: this option is for TF mobilenets, but generally should be evaluated
+ // from weights package somehow (supported number or classes in meta?)
+ // TODO: this problem is related to the absence of a knowledge about
+ // required image size for particular image recognition network package.
+ // TODO: We have to provide common set of parameters for all image-recognition packages.
+ const bool has_background_class = true;
+
+ cout << "\nLoading graph..." << endl;
+ measure_setup([&]{
+ Status status = ReadBinaryProto(Env::Default(), settings.graph_file(), &graph_def);
+ if (!status.ok())
+ throw "Failed to load graph: " + status.ToString();
+
+ tf_session.reset(NewSession(SessionOptions()));
+
+ status = tf_session->Create(graph_def);
+ if (!status.ok())
+ throw "Failed to create new session: " + status.ToString();
+ });
+
+ cout << "\nProcessing batches..." << endl;
+ measure_prediction([&]{
+ Tensor input(DT_FLOAT, TensorShape({settings.batch_size,
+ settings.image_size,
+ settings.image_size,
+ settings.num_channels}));
+ float* input_ptr = input.flat().data();
+ vector outputs;
+
+ while (session.get_next_batch()) {
+ // Load batch
+ session.measure_begin();
+ int image_offset = 0;
+ for (auto image_file : session.batch_files()) {
+ input_data.load(image_file);
+ input_converter->convert(&input_data, input_ptr + image_offset);
+ image_offset += input_data.size();
+ }
+ session.measure_end_load_images();
+
+ // Classify current batch
+ session.measure_begin();
+ Status status = tf_session->Run(
+ {{settings.input_layer_name, input}}, {settings.output_layer_name}, {}, &outputs);
+ if (!status.ok())
+ throw "Running model failed: " + status.ToString();
+ session.measure_end_prediction();
+
+ // Process output tensor
+ auto output_flat = outputs[0].flat();
+ if (output_flat.size() != settings.batch_size * (settings.num_classes + 1))
+ throw format("Output tensor has size of %d, but expected size is %d",
+ output_flat.size(), settings.batch_size * (settings.num_classes + 1));
+ image_offset = 0;
+ int probe_offset = has_background_class ? 1 : 0;
+ for (auto image_file : session.batch_files()) {
+ result_converter.convert(output_flat.data() + image_offset + probe_offset, &result_data);
+ result_data.save(image_file);
+ image_offset += result_data.size() + probe_offset;
+ }
+ }
+ });
+
+ finish_benchmark(session);
+ }
+ catch (const string& error_message) {
+ cerr << "ERROR: " << error_message << endl;
+ return -1;
+ }
+ return 0;
+}
diff --git a/script/app-image-classification-torch-py/README-extra.md b/script/app-image-classification-torch-py/README-extra.md
new file mode 100644
index 0000000000..6628885061
--- /dev/null
+++ b/script/app-image-classification-torch-py/README-extra.md
@@ -0,0 +1,16 @@
+# CPU
+
+## 20240129; Windows 11
+
+```bash
+cmr "get generic-python-lib _package.torch" --version=2.1.1
+cmr "get generic-python-lib _package.torchvision" --version=0.16.2
+```
+
+# CUDA
+
+```bash
+cm run script "install python-venv" --name=test
+cm run script "python app image-classification pytorch _cuda" --adr.python.name=test
+cm run script "python app image-classification pytorch _cuda" --adr.python.name=test --input=src/computer_mouse.jpg
+```
diff --git a/script/app-image-classification-torch-py/README.md b/script/app-image-classification-torch-py/README.md
new file mode 100644
index 0000000000..107a6a860c
--- /dev/null
+++ b/script/app-image-classification-torch-py/README.md
@@ -0,0 +1,168 @@
+Automatically generated README for this automation recipe: **app-image-classification-torch-py**
+
+Category: **Modular AI/ML application pipeline**
+
+License: **Apache 2.0**
+
+Maintainers: [Public MLCommons Task Force on Automation and Reproducibility](https://github.com/mlcommons/ck/blob/master/docs/taskforce.md)
+
+---
+*[ [Online info and GUI to run this CM script](https://access.cknowledge.org/playground/?action=scripts&name=app-image-classification-torch-py,e3986ae887b84ca8) ] [ [Notes from the authors, contributors and users](README-extra.md) ]*
+
+---
+#### Summary
+
+* CM GitHub repository: *[mlcommons@ck](https://github.com/mlcommons/ck/tree/dev/cm-mlops)*
+* GitHub directory for this script: *[GitHub](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-torch-py)*
+* CM meta description for this script: *[_cm.json](_cm.json)*
+* All CM tags to find and reuse this script (see in above meta description): *app,image-classification,python,torch*
+* Output cached? *False*
+* See [pipeline of dependencies](#dependencies-on-other-cm-scripts) on other CM scripts
+
+
+---
+### Reuse this script in your project
+
+#### Install MLCommons CM automation meta-framework
+
+* [Install CM](https://access.cknowledge.org/playground/?action=install)
+* [CM Getting Started Guide](https://github.com/mlcommons/ck/blob/master/docs/getting-started.md)
+
+#### Pull CM repository with this automation recipe (CM script)
+
+```cm pull repo mlcommons@ck```
+
+#### Print CM help from the command line
+
+````cmr "app image-classification python torch" --help````
+
+#### Customize and run this script from the command line with different variations and flags
+
+`cm run script --tags=app,image-classification,python,torch`
+
+`cm run script --tags=app,image-classification,python,torch[,variations] `
+
+*or*
+
+`cmr "app image-classification python torch"`
+
+`cmr "app image-classification python torch [variations]" `
+
+
+* *See the list of `variations` [here](#variations) and check the [Gettings Started Guide](https://github.com/mlcommons/ck/blob/dev/docs/getting-started.md) for more details.*
+
+#### Run this script from Python
+
+
+Click here to expand this section.
+
+```python
+
+import cmind
+
+r = cmind.access({'action':'run'
+ 'automation':'script',
+ 'tags':'app,image-classification,python,torch'
+ 'out':'con',
+ ...
+ (other input keys for this script)
+ ...
+ })
+
+if r['return']>0:
+ print (r['error'])
+
+```
+
+
+
+
+#### Run this script via GUI
+
+```cmr "cm gui" --script="app,image-classification,python,torch"```
+
+Use this [online GUI](https://cKnowledge.org/cm-gui/?tags=app,image-classification,python,torch) to generate CM CMD.
+
+#### Run this script via Docker (beta)
+
+`cm docker script "app image-classification python torch[variations]" `
+
+___
+### Customization
+
+
+#### Variations
+
+ * *No group (any variation can be selected)*
+
+ Click here to expand this section.
+
+ * `_cuda`
+ - Environment variables:
+ - *USE_CUDA*: `yes`
+ - Workflow:
+ 1. ***Read "deps" on other CM scripts***
+ * get,cuda
+ - CM script: [get-cuda](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-cuda)
+
+
+
+#### Default environment
+
+
+Click here to expand this section.
+
+These keys can be updated via `--env.KEY=VALUE` or `env` dictionary in `@input.json` or using script flags.
+
+* CM_BATCH_COUNT: `1`
+* CM_BATCH_SIZE: `1`
+
+
+
+___
+### Dependencies on other CM scripts
+
+
+ 1. ***Read "deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-torch-py/_cm.json)***
+ * detect,os
+ - CM script: [detect-os](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/detect-os)
+ * get,sys-utils-cm
+ - CM script: [get-sys-utils-cm](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-sys-utils-cm)
+ * get,python3
+ * CM names: `--adr.['python', 'python3']...`
+ - CM script: [get-python3](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-python3)
+ * get,dataset,imagenet,image-classification,preprocessed
+ - CM script: [get-preprocessed-dataset-imagenet](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-preprocessed-dataset-imagenet)
+ * get,dataset-aux,imagenet-aux,image-classification
+ - CM script: [get-dataset-imagenet-aux](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-dataset-imagenet-aux)
+ * get,imagenet-helper
+ - CM script: [get-dataset-imagenet-helper](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-dataset-imagenet-helper)
+ * get,ml-model,image-classification,resnet50,_pytorch,_fp32
+ - CM script: [get-ml-model-resnet50](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-ml-model-resnet50)
+ * get,generic-python-lib,_torch
+ * `if (USE_CUDA != yes)`
+ - CM script: [get-generic-python-lib](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-generic-python-lib)
+ * get,generic-python-lib,_torch_cuda
+ * `if (USE_CUDA == yes)`
+ - CM script: [get-generic-python-lib](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-generic-python-lib)
+ * get,generic-python-lib,_torchvision
+ * `if (USE_CUDA != yes)`
+ - CM script: [get-generic-python-lib](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-generic-python-lib)
+ * get,generic-python-lib,_torchvision_cuda
+ * `if (USE_CUDA == yes)`
+ - CM script: [get-generic-python-lib](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-generic-python-lib)
+ 1. Run "preprocess" function from customize.py
+ 1. Read "prehook_deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-torch-py/_cm.json)
+ 1. ***Run native script if exists***
+ * [run.bat](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-torch-py/run.bat)
+ * [run.sh](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-torch-py/run.sh)
+ 1. Read "posthook_deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-torch-py/_cm.json)
+ 1. Run "postrocess" function from customize.py
+ 1. Read "post_deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-torch-py/_cm.json)
+
+___
+### Script output
+`cmr "app image-classification python torch [,variations]" -j`
+#### New environment keys (filter)
+
+#### New environment keys auto-detected from customize
diff --git a/script/app-image-classification-torch-py/_cm.json b/script/app-image-classification-torch-py/_cm.json
new file mode 100644
index 0000000000..a6a78a6798
--- /dev/null
+++ b/script/app-image-classification-torch-py/_cm.json
@@ -0,0 +1,89 @@
+{
+ "alias": "app-image-classification-torch-py",
+ "automation_alias": "script",
+ "automation_uid": "5b4e0237da074764",
+ "category": "Modular AI/ML application pipeline",
+ "default_env": {
+ "CM_BATCH_COUNT": "1",
+ "CM_BATCH_SIZE": "1"
+ },
+ "deps": [
+ {
+ "tags": "detect,os"
+ },
+ {
+ "tags": "get,sys-utils-cm"
+ },
+ {
+ "names": [
+ "python",
+ "python3"
+ ],
+ "tags": "get,python3"
+ },
+ {
+ "tags": "get,dataset,imagenet,image-classification,preprocessed"
+ },
+ {
+ "tags": "get,dataset-aux,imagenet-aux,image-classification"
+ },
+ {
+ "tags": "get,imagenet-helper"
+ },
+ {
+ "tags": "get,ml-model,image-classification,resnet50,_pytorch,_fp32"
+ },
+ {
+ "tags": "get,generic-python-lib,_torch",
+ "skip_if_env": {
+ "USE_CUDA": [
+ "yes"
+ ]
+ }
+ },
+ {
+ "tags": "get,generic-python-lib,_torch_cuda",
+ "enable_if_env": {
+ "USE_CUDA": [
+ "yes"
+ ]
+ }
+ },
+ {
+ "tags": "get,generic-python-lib,_torchvision",
+ "skip_if_env": {
+ "USE_CUDA": [
+ "yes"
+ ]
+ }
+ },
+ {
+ "tags": "get,generic-python-lib,_torchvision_cuda",
+ "enable_if_env": {
+ "USE_CUDA": [
+ "yes"
+ ]
+ }
+ }
+ ],
+ "tags": [
+ "app",
+ "image-classification",
+ "torch",
+ "python"
+ ],
+ "tags_help":"app image-classification python torch",
+ "variations": {
+ "cuda": {
+ "env": {
+ "USE_CUDA": "yes"
+ },
+ "deps": [
+ {
+ "tags": "get,cuda"
+ }
+ ]
+ }
+ },
+ "uid": "e3986ae887b84ca8"
+}
diff --git a/script/app-image-classification-torch-py/img/computer_mouse.jpg b/script/app-image-classification-torch-py/img/computer_mouse.jpg
new file mode 100644
index 0000000000..e7f8abb6fe
Binary files /dev/null and b/script/app-image-classification-torch-py/img/computer_mouse.jpg differ
diff --git a/script/app-image-classification-torch-py/requirements.txt b/script/app-image-classification-torch-py/requirements.txt
new file mode 100644
index 0000000000..d1c427e4aa
--- /dev/null
+++ b/script/app-image-classification-torch-py/requirements.txt
@@ -0,0 +1,4 @@
+Pillow
+requests
+numpy
+
diff --git a/script/app-image-classification-torch-py/run.bat b/script/app-image-classification-torch-py/run.bat
new file mode 100644
index 0000000000..1415d4265b
--- /dev/null
+++ b/script/app-image-classification-torch-py/run.bat
@@ -0,0 +1,20 @@
+rem connect CM portable scripts with CK env
+
+set CM_ML_TORCH_MODEL_NAME=resnet50
+set CM_ML_MODEL_INPUT_DATA_TYPE=float32
+set CM_ML_MODEL_IMAGE_HEIGHT=224
+set CM_ML_MODEL_IMAGE_WIDTH=224
+
+rem set CM_DATASET_IMAGENET_PREPROCESSED_DIR=%CM_DATASET_PREPROCESSED_PATH%
+
+set CM_DATASET_IMAGENET_PREPROCESSED_DIR=%CM_DATASET_PREPROCESSED_FULL_PATH%
+set CM_CAFFE_IMAGENET_SYNSET_WORDS_TXT=%CM_DATASET_AUX_PATH%\synset_words.txt
+set CM_DATASET_IMAGENET_PREPROCESSED_DATA_TYPE=float32
+set CM_RESULTS_DIR=%CM_TMP_CURRENT_SCRIPT_PATH%\results
+set ML_MODEL_DATA_LAYOUT=NCHW
+
+%CM_PYTHON_BIN_WITH_PATH% -m pip install -r %CM_TMP_CURRENT_SCRIPT_PATH%\requirements.txt
+IF %ERRORLEVEL% NEQ 0 EXIT %ERRORLEVEL%
+
+%CM_PYTHON_BIN_WITH_PATH% %CM_TMP_CURRENT_SCRIPT_PATH%\src\pytorch_classify_preprocessed.py
+IF %ERRORLEVEL% NEQ 0 EXIT %ERRORLEVEL%
diff --git a/script/app-image-classification-torch-py/run.sh b/script/app-image-classification-torch-py/run.sh
new file mode 100644
index 0000000000..b50b79eb40
--- /dev/null
+++ b/script/app-image-classification-torch-py/run.sh
@@ -0,0 +1,20 @@
+#!/bin/bash
+
+CM_TMP_CURRENT_SCRIPT_PATH=${CM_TMP_CURRENT_SCRIPT_PATH:-$PWD}
+
+# connect CM intelligent components with CK env
+export CM_ML_TORCH_MODEL_NAME=resnet50
+export CM_ML_MODEL_INPUT_DATA_TYPE=float32
+export CM_ML_MODEL_IMAGE_HEIGHT=224
+export CM_ML_MODEL_IMAGE_WIDTH=224
+export CM_DATASET_IMAGENET_PREPROCESSED_DIR=${CM_DATASET_PREPROCESSED_FULL_PATH}
+export CM_CAFFE_IMAGENET_SYNSET_WORDS_TXT=${CM_DATASET_AUX_PATH}/synset_words.txt
+export CM_DATASET_IMAGENET_PREPROCESSED_DATA_TYPE=float32
+export CM_RESULTS_DIR=${CM_TMP_CURRENT_SCRIPT_PATH}/results
+export ML_MODEL_DATA_LAYOUT=NCHW
+
+${CM_PYTHON_BIN} -m pip install -r ${CM_TMP_CURRENT_SCRIPT_PATH}/requirements.txt
+test $? -eq 0 || exit 1
+
+${CM_PYTHON_BIN} ${CM_TMP_CURRENT_SCRIPT_PATH}/src/pytorch_classify_preprocessed.py
+test $? -eq 0 || exit 1
diff --git a/script/app-image-classification-torch-py/src/pytorch_classify_preprocessed.py b/script/app-image-classification-torch-py/src/pytorch_classify_preprocessed.py
new file mode 100644
index 0000000000..f3ee0b587d
--- /dev/null
+++ b/script/app-image-classification-torch-py/src/pytorch_classify_preprocessed.py
@@ -0,0 +1,205 @@
+#!/usr/bin/env python3
+
+import json
+import time
+import os
+import shutil
+import numpy as np
+
+
+import torch
+import torchvision.models as models
+
+import imagenet_helper
+from imagenet_helper import (load_preprocessed_batch, image_list, class_labels, BATCH_SIZE)
+
+## Writing the results out:
+#
+RESULTS_DIR = os.getenv('CM_RESULTS_DIR')
+FULL_REPORT = os.getenv('CM_SILENT_MODE', '0') in ('NO', 'no', 'OFF', 'off', '0')
+
+## Processing by batches:
+#
+BATCH_COUNT = int(os.getenv('CM_BATCH_COUNT', 1))
+
+## Enabling GPU if available and not disabled:
+#
+USE_CUDA = (os.getenv('USE_CUDA', '').strip()=='yes')
+
+
+labels_path = os.environ['CM_CAFFE_IMAGENET_SYNSET_WORDS_TXT']
+
+def load_labels(labels_filepath):
+ my_labels = []
+ input_file = open(labels_filepath, 'r')
+ for l in input_file:
+ my_labels.append(l.strip())
+ return my_labels
+
+
+labels = load_labels(labels_path)
+
+
+data_layout = os.environ['ML_MODEL_DATA_LAYOUT']
+
+
+
+def main():
+ global BATCH_SIZE
+ global BATCH_COUNT
+
+ setup_time_begin = time.time()
+
+ bg_class_offset=0
+
+ # Cleanup results directory
+ if os.path.isdir(RESULTS_DIR):
+ shutil.rmtree(RESULTS_DIR)
+ os.mkdir(RESULTS_DIR)
+
+ # Load the [cached] Torch model
+ path_to_model_pth = os.environ['CM_ML_MODEL_FILE_WITH_PATH']
+
+ model=models.resnet50(pretrained=False)
+ model.load_state_dict(torch.load(path_to_model_pth))
+
+ model.eval()
+
+ # move the model to GPU for speed if available
+ if USE_CUDA:
+ model.to('cuda')
+
+ setup_time = time.time() - setup_time_begin
+
+ # Run batched mode
+ test_time_begin = time.time()
+ image_index = 0
+ total_load_time = 0
+ total_classification_time = 0
+ first_classification_time = 0
+ images_loaded = 0
+
+ image_path = os.environ.get('CM_INPUT','')
+ if image_path !='':
+
+ normalize_data_bool=True
+ subtract_mean_bool=False
+
+ from PIL import Image
+
+ def load_and_resize_image(image_filepath, height, width):
+ pillow_img = Image.open(image_filepath).resize((width, height)) # sic! The order of dimensions in resize is (W,H)
+
+ input_data = np.float32(pillow_img)
+
+ # Normalize
+ if normalize_data_bool:
+ input_data = input_data/127.5 - 1.0
+
+ # Subtract mean value
+ if subtract_mean_bool:
+ if len(given_channel_means):
+ input_data -= given_channel_means
+ else:
+ input_data -= np.mean(input_data)
+
+ # print(np.array(pillow_img).shape)
+ nhwc_data = np.expand_dims(input_data, axis=0)
+
+ if data_layout == 'NHWC':
+ # print(nhwc_data.shape)
+ return nhwc_data
+ else:
+ nchw_data = nhwc_data.transpose(0,3,1,2)
+ # print(nchw_data.shape)
+ return nchw_data
+
+ BATCH_COUNT=1
+
+
+ for batch_index in range(BATCH_COUNT):
+ batch_number = batch_index+1
+ if FULL_REPORT or (batch_number % 10 == 0):
+ print("\nBatch {} of {}".format(batch_number, BATCH_COUNT))
+
+ begin_time = time.time()
+
+ if image_path=='':
+ batch_data, image_index = load_preprocessed_batch(image_list, image_index)
+ else:
+ batch_data = load_and_resize_image(image_path, 224, 224)
+ image_index = 1
+
+ torch_batch = torch.from_numpy( batch_data )
+
+ load_time = time.time() - begin_time
+ total_load_time += load_time
+ images_loaded += BATCH_SIZE
+ if FULL_REPORT:
+ print("Batch loaded in %fs" % (load_time))
+
+ # Classify one batch
+ begin_time = time.time()
+
+ # move the input to GPU for speed if available
+ if USE_CUDA:
+ torch_batch = torch_batch.to('cuda')
+
+ with torch.no_grad():
+ batch_results = model( torch_batch )
+
+ classification_time = time.time() - begin_time
+ if FULL_REPORT:
+ print("Batch classified in %fs" % (classification_time))
+
+ total_classification_time += classification_time
+ # Remember first batch prediction time
+ if batch_index == 0:
+ first_classification_time = classification_time
+
+ # Process results
+ for index_in_batch in range(BATCH_SIZE):
+ softmax_vector = batch_results[index_in_batch][bg_class_offset:] # skipping the background class on the left (if present)
+ global_index = batch_index * BATCH_SIZE + index_in_batch
+
+ res_file = os.path.join(RESULTS_DIR, image_list[global_index])
+
+ with open(res_file + '.txt', 'w') as f:
+ for prob in softmax_vector:
+ f.write('{}\n'.format(prob))
+
+ top5_indices = list(reversed(softmax_vector.argsort()))[:5]
+ for class_idx in top5_indices:
+ print("\t{}\t{}\t{}".format(class_idx, softmax_vector[class_idx], labels[class_idx]))
+ print("")
+
+
+ test_time = time.time() - test_time_begin
+
+ if BATCH_COUNT > 1:
+ avg_classification_time = (total_classification_time - first_classification_time) / (images_loaded - BATCH_SIZE)
+ else:
+ avg_classification_time = total_classification_time / images_loaded
+
+ avg_load_time = total_load_time / images_loaded
+
+ # Store benchmarking results:
+ output_dict = {
+ 'setup_time_s': setup_time,
+ 'test_time_s': test_time,
+ 'images_load_time_total_s': total_load_time,
+ 'images_load_time_avg_s': avg_load_time,
+ 'prediction_time_total_s': total_classification_time,
+ 'prediction_time_avg_s': avg_classification_time,
+
+ 'avg_time_ms': avg_classification_time * 1000,
+ 'avg_fps': 1.0 / avg_classification_time,
+ 'batch_time_ms': avg_classification_time * 1000 * BATCH_SIZE,
+ 'batch_size': BATCH_SIZE,
+ }
+ with open('tmp-ck-timer.json', 'w') as out_file:
+ json.dump(output_dict, out_file, indent=4, sort_keys=True)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/script/app-image-classification-tvm-onnx-py/README-extra.md b/script/app-image-classification-tvm-onnx-py/README-extra.md
new file mode 100644
index 0000000000..c24e073a99
--- /dev/null
+++ b/script/app-image-classification-tvm-onnx-py/README-extra.md
@@ -0,0 +1,16 @@
+Example:
+
+```bash
+cm run script "get llvm" --version=14.0.0
+cm run script "get tvm _llvm" --version=0.10.0
+cm run script "python app image-classification tvm-onnx"
+```
+
+Example 2:
+
+```bash
+cm run script "install python-venv" --name=test --version=3.10.7
+cm run script "get generic-python-lib _apache-tvm"
+cm run script "python app image-classification tvm-onnx _tvm-pip-install"
+cm run script "python app image-classification tvm-onnx _tvm-pip-install" --input=`cm find script --tags=python,app,image-classification,tvm-onnx`/img/computer_mouse.jpg
+```
\ No newline at end of file
diff --git a/script/app-image-classification-tvm-onnx-py/README.md b/script/app-image-classification-tvm-onnx-py/README.md
new file mode 100644
index 0000000000..bd1d4c56aa
--- /dev/null
+++ b/script/app-image-classification-tvm-onnx-py/README.md
@@ -0,0 +1,160 @@
+Automatically generated README for this automation recipe: **app-image-classification-tvm-onnx-py**
+
+Category: **Modular AI/ML application pipeline**
+
+License: **Apache 2.0**
+
+Maintainers: [Public MLCommons Task Force on Automation and Reproducibility](https://github.com/mlcommons/ck/blob/master/docs/taskforce.md)
+
+---
+*[ [Online info and GUI to run this CM script](https://access.cknowledge.org/playground/?action=scripts&name=app-image-classification-tvm-onnx-py,63080407db4d4ac4) ] [ [Notes from the authors, contributors and users](README-extra.md) ]*
+
+---
+#### Summary
+
+* CM GitHub repository: *[mlcommons@ck](https://github.com/mlcommons/ck/tree/dev/cm-mlops)*
+* GitHub directory for this script: *[GitHub](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-tvm-onnx-py)*
+* CM meta description for this script: *[_cm.json](_cm.json)*
+* All CM tags to find and reuse this script (see in above meta description): *app,image-classification,python,tvm-onnx*
+* Output cached? *False*
+* See [pipeline of dependencies](#dependencies-on-other-cm-scripts) on other CM scripts
+
+
+---
+### Reuse this script in your project
+
+#### Install MLCommons CM automation meta-framework
+
+* [Install CM](https://access.cknowledge.org/playground/?action=install)
+* [CM Getting Started Guide](https://github.com/mlcommons/ck/blob/master/docs/getting-started.md)
+
+#### Pull CM repository with this automation recipe (CM script)
+
+```cm pull repo mlcommons@ck```
+
+#### Print CM help from the command line
+
+````cmr "app image-classification python tvm-onnx" --help````
+
+#### Customize and run this script from the command line with different variations and flags
+
+`cm run script --tags=app,image-classification,python,tvm-onnx`
+
+`cm run script --tags=app,image-classification,python,tvm-onnx[,variations] `
+
+*or*
+
+`cmr "app image-classification python tvm-onnx"`
+
+`cmr "app image-classification python tvm-onnx [variations]" `
+
+
+* *See the list of `variations` [here](#variations) and check the [Gettings Started Guide](https://github.com/mlcommons/ck/blob/dev/docs/getting-started.md) for more details.*
+
+#### Run this script from Python
+
+
+Click here to expand this section.
+
+```python
+
+import cmind
+
+r = cmind.access({'action':'run'
+ 'automation':'script',
+ 'tags':'app,image-classification,python,tvm-onnx'
+ 'out':'con',
+ ...
+ (other input keys for this script)
+ ...
+ })
+
+if r['return']>0:
+ print (r['error'])
+
+```
+
+
+
+
+#### Run this script via GUI
+
+```cmr "cm gui" --script="app,image-classification,python,tvm-onnx"```
+
+Use this [online GUI](https://cKnowledge.org/cm-gui/?tags=app,image-classification,python,tvm-onnx) to generate CM CMD.
+
+#### Run this script via Docker (beta)
+
+`cm docker script "app image-classification python tvm-onnx[variations]" `
+
+___
+### Customization
+
+
+#### Variations
+
+ * *No group (any variation can be selected)*
+
+ Click here to expand this section.
+
+ * `_cuda`
+ - Environment variables:
+ - *USE_CUDA*: `yes`
+ - Workflow:
+ 1. ***Read "deps" on other CM scripts***
+ * get,cuda
+ - CM script: [get-cuda](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-cuda)
+ * `_llvm`
+ - Workflow:
+
+
+
+#### Default environment
+
+
+Click here to expand this section.
+
+These keys can be updated via `--env.KEY=VALUE` or `env` dictionary in `@input.json` or using script flags.
+
+* CM_BATCH_COUNT: `1`
+* CM_BATCH_SIZE: `1`
+
+
+
+___
+### Dependencies on other CM scripts
+
+
+ 1. ***Read "deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-tvm-onnx-py/_cm.json)***
+ * detect,os
+ - CM script: [detect-os](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/detect-os)
+ * detect,cpu
+ - CM script: [detect-cpu](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/detect-cpu)
+ * get,python3
+ * CM names: `--adr.['python', 'python3']...`
+ - CM script: [get-python3](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-python3)
+ * get,dataset,image-classification,original
+ - CM script: [get-dataset-imagenet-val](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-dataset-imagenet-val)
+ * get,dataset-aux,image-classification
+ - CM script: [get-dataset-imagenet-aux](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-dataset-imagenet-aux)
+ * get,raw,ml-model,image-classification,resnet50,_onnx
+ - CM script: [get-ml-model-resnet50](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-ml-model-resnet50)
+ * get,generic-python-lib,_onnxruntime
+ - CM script: [get-generic-python-lib](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-generic-python-lib)
+ * get,tvm
+ * CM names: `--adr.['tvm']...`
+ - CM script: [get-tvm](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-tvm)
+ 1. Run "preprocess" function from customize.py
+ 1. Read "prehook_deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-tvm-onnx-py/_cm.json)
+ 1. ***Run native script if exists***
+ * [run.sh](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-tvm-onnx-py/run.sh)
+ 1. Read "posthook_deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-tvm-onnx-py/_cm.json)
+ 1. Run "postrocess" function from customize.py
+ 1. Read "post_deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-classification-tvm-onnx-py/_cm.json)
+
+___
+### Script output
+`cmr "app image-classification python tvm-onnx [,variations]" -j`
+#### New environment keys (filter)
+
+#### New environment keys auto-detected from customize
diff --git a/script/app-image-classification-tvm-onnx-py/_cm.json b/script/app-image-classification-tvm-onnx-py/_cm.json
new file mode 100644
index 0000000000..1ae2e5c320
--- /dev/null
+++ b/script/app-image-classification-tvm-onnx-py/_cm.json
@@ -0,0 +1,73 @@
+{
+ "alias": "app-image-classification-tvm-onnx-py",
+ "automation_alias": "script",
+ "automation_uid": "5b4e0237da074764",
+ "category": "Modular AI/ML application pipeline",
+ "default_env": {
+ "CM_BATCH_COUNT": "1",
+ "CM_BATCH_SIZE": "1"
+ },
+ "deps": [
+ {
+ "tags": "detect,os"
+ },
+ {
+ "tags": "detect,cpu"
+ },
+ {
+ "names": [
+ "python",
+ "python3"
+ ],
+ "tags": "get,python3"
+ },
+ {
+ "tags": "get,dataset,image-classification,original"
+ },
+ {
+ "tags": "get,dataset-aux,image-classification"
+ },
+ {
+ "tags": "get,raw,ml-model,image-classification,resnet50,_onnx"
+ },
+ {
+ "tags": "get,generic-python-lib,_onnxruntime"
+ },
+ {
+ "names": [ "tvm" ],
+ "tags": "get,tvm"
+ }
+ ],
+ "tags": [
+ "app",
+ "image-classification",
+ "tvm-onnx",
+ "python"
+ ],
+ "tags_help":"app image-classification python tvm-onnx",
+ "uid": "63080407db4d4ac4",
+ "variations": {
+ "llvm": {
+ "add_deps_recursive": {
+ "tvm": {
+ "tags": "_llvm"
+ }
+ }
+ },
+ "cuda": {
+ "add_deps_recursive": {
+ "tvm": {
+ "tags": "_cuda"
+ }
+ },
+ "env": {
+ "USE_CUDA": "yes"
+ },
+ "deps": [
+ {
+ "tags": "get,cuda"
+ }
+ ]
+ }
+ }
+}
diff --git a/script/app-image-classification-tvm-onnx-py/img/computer_mouse.jpg b/script/app-image-classification-tvm-onnx-py/img/computer_mouse.jpg
new file mode 100644
index 0000000000..e7f8abb6fe
Binary files /dev/null and b/script/app-image-classification-tvm-onnx-py/img/computer_mouse.jpg differ
diff --git a/script/app-image-classification-tvm-onnx-py/requirements.txt b/script/app-image-classification-tvm-onnx-py/requirements.txt
new file mode 100644
index 0000000000..ae4aff7eae
--- /dev/null
+++ b/script/app-image-classification-tvm-onnx-py/requirements.txt
@@ -0,0 +1,7 @@
+matplotlib
+opencv-python
+scipy
+onnx
+decorator
+attrs
+psutil
diff --git a/script/app-image-classification-tvm-onnx-py/run.sh b/script/app-image-classification-tvm-onnx-py/run.sh
new file mode 100644
index 0000000000..8eb0660771
--- /dev/null
+++ b/script/app-image-classification-tvm-onnx-py/run.sh
@@ -0,0 +1,26 @@
+#!/bin/bash
+
+CM_TMP_CURRENT_SCRIPT_PATH=${CM_TMP_CURRENT_SCRIPT_PATH:-$PWD}
+
+#if [[ ${CM_HOST_PLATFORM_FLAVOR} == "arm64" ]]; then
+# ${CM_PYTHON_BIN} -m pip install -i https://test.pypi.org/simple/ onnxruntime==1.9.0.dev174552
+#fi
+
+export USE_TVM=yes
+
+
+wget -nc https://raw.githubusercontent.com/mlcommons/ck-mlops/main/program/ml-task-image-classification-tvm-onnx-cpu/synset.txt
+test $? -eq 0 || exit 1
+
+${CM_PYTHON_BIN} -m pip install -r ${CM_TMP_CURRENT_SCRIPT_PATH}/requirements.txt
+test $? -eq 0 || exit 1
+
+if [[ "${CM_INPUT}" != "" ]]; then
+ export CM_IMAGE=${CM_INPUT}
+else
+ export CM_IMAGE=${CM_DATASET_PATH}/ILSVRC2012_val_00000001.JPEG
+fi
+
+
+${CM_PYTHON_BIN} ${CM_TMP_CURRENT_SCRIPT_PATH}/src/classify.py --image ${CM_IMAGE}
+test $? -eq 0 || exit 1
diff --git a/script/app-image-classification-tvm-onnx-py/src/classify.py b/script/app-image-classification-tvm-onnx-py/src/classify.py
new file mode 100644
index 0000000000..0eb299f2df
--- /dev/null
+++ b/script/app-image-classification-tvm-onnx-py/src/classify.py
@@ -0,0 +1,292 @@
+"""
+Developers:
+ - grigori@octoml.ai
+"""
+
+import time
+import os
+import argparse
+import json
+
+from PIL import Image
+import cv2
+
+import numpy as np
+
+import onnxruntime as rt
+
+
+
+# Image conversion from MLPerf(tm) vision
+def center_crop(img, out_height, out_width):
+ height, width, _ = img.shape
+ left = int((width - out_width) / 2)
+ right = int((width + out_width) / 2)
+ top = int((height - out_height) / 2)
+ bottom = int((height + out_height) / 2)
+ img = img[top:bottom, left:right]
+ return img
+
+
+def resize_with_aspectratio(img, out_height, out_width, scale=87.5, inter_pol=cv2.INTER_LINEAR):
+ height, width, _ = img.shape
+ new_height = int(100. * out_height / scale)
+ new_width = int(100. * out_width / scale)
+ if height > width:
+ w = new_width
+ h = int(new_height * height / width)
+ else:
+ h = new_height
+ w = int(new_width * width / height)
+ img = cv2.resize(img, (w, h), interpolation=inter_pol)
+ return img
+
+
+# returns list of pairs (prob, class_index)
+def get_top5(all_probs):
+ probs_with_classes = []
+
+ for class_index in range(len(all_probs)):
+ prob = all_probs[class_index]
+ probs_with_classes.append((prob, class_index))
+
+ sorted_probs = sorted(probs_with_classes, key = lambda pair: pair[0], reverse=True)
+ return sorted_probs[0:5]
+
+def run_case(dtype, image, target):
+ # Check image
+ import os
+ import json
+ import sys
+
+ STAT_REPEAT=os.environ.get('STAT_REPEAT','')
+ if STAT_REPEAT=='' or STAT_REPEAT==None:
+ STAT_REPEAT=10
+ STAT_REPEAT=int(STAT_REPEAT)
+
+ # FGG: set model files via CM env
+ CATEG_FILE = 'synset.txt'
+ synset = eval(open(os.path.join(CATEG_FILE)).read())
+
+ files=[]
+ val={}
+
+ # FGG: set timers
+ import time
+ timers={}
+
+ img_orig = cv2.imread(image)
+
+ img = cv2.cvtColor(img_orig, cv2.COLOR_BGR2RGB)
+
+ output_height, output_width, _ = 224, 224, 3
+ img = resize_with_aspectratio(img, output_height, output_width, inter_pol=cv2.INTER_AREA)
+ img = center_crop(img, output_height, output_width)
+ img = np.asarray(img, dtype='float32')
+
+ # normalize image
+ means = np.array([123.68, 116.78, 103.94], dtype=np.float32)
+ img -= means
+
+ # transpose if needed
+ img = img.transpose([2, 0, 1])
+
+ import matplotlib.pyplot as plt
+ img1 = img.transpose([1, 2, 0])
+ arr_ = np.squeeze(img1) # you can give axis attribute if you wanna squeeze in specific dimension
+ plt.imshow(arr_)
+# plt.show()
+ plt.savefig('pre-processed-image.png')
+ # Load model
+ model_path=os.environ.get('CM_ML_MODEL_FILE_WITH_PATH','')
+ if model_path=='':
+ print ('Error: environment variable CM_ML_MODEL_FILE_WITH_PATH is not defined')
+ exit(1)
+
+ opt = rt.SessionOptions()
+
+ if len(rt.get_all_providers()) > 1 and os.environ.get("USE_CUDA", "yes").lower() not in [ "0", "false", "off", "no" ]:
+ #Currently considering only CUDAExecutionProvider
+ sess = rt.InferenceSession(model_path, opt, providers=['CUDAExecutionProvider'])
+ else:
+ sess = rt.InferenceSession(model_path, opt, providers=["CPUExecutionProvider"])
+
+ inputs = [meta.name for meta in sess.get_inputs()]
+ outputs = [meta.name for meta in sess.get_outputs()]
+
+ print (inputs)
+ print (outputs)
+
+
+
+
+ if os.environ.get('USE_TVM','')=='yes':
+ import tvm
+ from tvm import relay
+ import onnx
+
+ del sess
+
+ # Load model via ONNX to be used with TVM
+ print ('')
+ print ('ONNX: load model ...')
+ print ('')
+
+ onnx_model = onnx.load(model_path)
+
+ # Init TVM
+ # TBD: add tvm platform selector
+ if os.environ.get('USE_CUDA','')=='yes':
+ # TVM package must be built with CUDA enabled
+ ctx = tvm.cuda(0)
+ else:
+ ctx = tvm.cpu(0)
+ tvm_ctx = ctx
+
+ build_conf = {'relay.backend.use_auto_scheduler': False}
+ opt_lvl = int(os.environ.get('TVM_OPT_LEVEL', 3))
+ host = os.environ.get('CM_HOST_PLATFORM_FLAVOR')
+ if host == 'x86_64' and 'AMD' in os.environ.get('CM_HOST_CPU_VENDOR_ID',''):
+ target = os.environ.get('TVM_TARGET', 'llvm -mcpu=znver2')
+ else:
+ target = os.environ.get('TVM_TARGET', 'llvm')
+
+ target_host=None
+ params={}
+
+ # New target API
+ tvm_target = tvm.target.Target(target, host=target_host)
+
+ input_shape = (1, 3, 224, 224)
+ shape_dict = {inputs[0]: input_shape}
+
+ print ('')
+ print ('TVM: import model ...')
+ print ('')
+ # Extra param: opset=12
+ mod, params = relay.frontend.from_onnx(onnx_model, shape_dict, freeze_params=True)
+
+ print ('')
+ print ('TVM: transform to static ...')
+ print ('')
+ mod = relay.transform.DynamicToStatic()(mod)
+
+ print ('')
+ print ('TVM: apply extra optimizations ...')
+ print ('')
+ # Padding optimization
+ # Adds extra optimizations
+ mod = relay.transform.FoldExplicitPadding()(mod)
+
+
+ print ('')
+ print ('TVM: build model ...')
+ print ('')
+
+ executor=os.environ.get('MLPERF_TVM_EXECUTOR','graph')
+
+ if executor == "graph" or executor == "debug":
+ from tvm.contrib import graph_executor
+
+ # Without history
+ with tvm.transform.PassContext(opt_level=opt_lvl, config=build_conf):
+ graph_module = relay.build(mod,
+ target=tvm_target,
+ params=params)
+ lib = graph_module
+
+ print ('')
+ print ('TVM: init graph engine ...')
+ print ('')
+
+ sess = graph_executor.GraphModule(lib['default'](ctx))
+
+
+ elif executor == "vm":
+ from tvm.runtime.vm import VirtualMachine
+
+ # Without history
+ with tvm.transform.PassContext(opt_level=opt_lvl, config=build_conf):
+ vm_exec = relay.vm.compile(mod, target=tvm_target, params=params)
+
+ r_exec = vm_exec
+
+ print ('')
+ print ('TVM: init VM ...')
+ print ('')
+
+ sess = VirtualMachine(r_exec, ctx)
+
+
+ # For now only graph
+ sess.set_input(inputs[0], tvm.nd.array([img]))
+
+ # Run TVM inference
+ sess.run()
+
+ # Process TVM outputs
+ output = []
+
+ for i in range(sess.get_num_outputs()):
+ # Take only the output of batch size for dynamic batches
+ if len(output)<(i+1):
+ output.append([])
+ output[i].append(sess.get_output(i).asnumpy()[0])
+
+
+
+ else:
+ inp={inputs[0]:np.array([img], dtype=np.float32)}
+ output=sess.run(outputs, inp)
+
+
+
+
+ top1 = np.argmax(output[1])-1 #.asnumpy())
+
+ top5=[]
+ atop5 = get_top5(output[1][0]) #.asnumpy())
+
+ print ('')
+ print('Prediction Top1:', top1, synset[top1])
+
+ print ('')
+ print('Prediction Top5:')
+ for p in atop5:
+ out=p[1]-1
+ name=synset[out]
+ print (' * {} {}'.format(out, name))
+
+ ck_results={
+ 'prediction':synset[top1]
+ }
+
+ with open('tmp-ck-timer.json', 'w') as ck_results_file:
+ json.dump(ck_results, ck_results_file, indent=2, sort_keys=True)
+
+ return
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--image', type=str, help="Path to JPEG image.", default=None, required=True)
+ parser.add_argument('--target', type=str, help="Target", default=None)
+ args = parser.parse_args()
+
+ if args.image.strip().lower()=='':
+ print ('Please specify path to an image using CM_IMAGE environment variable!')
+ exit(1)
+
+ # set parameter
+ batch_size = 1
+ num_classes = 1000
+ image_shape = (3, 224, 224)
+
+ # load model
+ data_shape = (batch_size,) + image_shape
+ out_shape = (batch_size, num_classes)
+
+ dtype='float32'
+ if os.environ.get('CM_TVM_DTYPE','')!='':
+ dtype=os.environ['CM_TVM_DTYPE']
+
+ run_case(dtype, args.image, args.target)
diff --git a/script/app-image-corner-detection/README-extra.md b/script/app-image-corner-detection/README-extra.md
new file mode 100644
index 0000000000..cc22865183
--- /dev/null
+++ b/script/app-image-corner-detection/README-extra.md
@@ -0,0 +1,25 @@
+# Examples
+
+First download images:
+
+```bash
+cmr "download file _wget" --url=https://cKnowledge.org/ai/data/data.pgm --verify=no --env.CM_DOWNLOAD_CHECKSUM=0af279e557a8de252d7ff0751a999379
+cmr "download file _wget" --url=https://cKnowledge.org/ai/data/computer_mouse.jpg --verify=no --env.CM_DOWNLOAD_CHECKSUM=45ae5c940233892c2f860efdf0b66e7e
+cmr "download file _wget" --url=https://cKnowledge.org/ai/data/computer_mouse2.jpg --verify=no --env.CM_DOWNLOAD_CHECKSUM=e7e2050b41e0b85cedca3ca87ab55390
+cmr "download file _wget" --url=https://cKnowledge.org/ai/data/computer_mouse2.pgm --verify=no --env.CM_DOWNLOAD_CHECKSUM=a4e48556d3eb09402bfc98e375b41311
+```
+
+Then run app
+
+```bash
+cm run script "app image corner-detection"
+cm run script "app image corner-detection" -add_deps_recursive.compiler.tags=llvm
+cm run script "app image corner-detection" -add_deps_recursive.compiler.tags=gcc
+cm run script "app image corner-detection" -add_deps_recursive.compiler.tags=llvm --add_deps_recursive.compiler.version_min=11.0.0 --add_deps_recursive.compiler.version_max=13.0.0
+```
+
+## Reproducibility matrix
+
+* Ubuntu 22.04; x64; LLVM 17.06
+* Windows 11; x64; LLVM 17.06
+
diff --git a/script/app-image-corner-detection/README.md b/script/app-image-corner-detection/README.md
new file mode 100644
index 0000000000..dad1c84a9a
--- /dev/null
+++ b/script/app-image-corner-detection/README.md
@@ -0,0 +1,129 @@
+Automatically generated README for this automation recipe: **app-image-corner-detection**
+
+Category: **Modular application pipeline**
+
+License: **Apache 2.0**
+
+Maintainers: [Public MLCommons Task Force on Automation and Reproducibility](https://github.com/mlcommons/ck/blob/master/docs/taskforce.md)
+
+---
+*[ [Online info and GUI to run this CM script](https://access.cknowledge.org/playground/?action=scripts&name=app-image-corner-detection,998ffee0bc534d0a) ] [ [Notes from the authors, contributors and users](README-extra.md) ]*
+
+---
+#### Summary
+
+* CM GitHub repository: *[mlcommons@ck](https://github.com/mlcommons/ck/tree/dev/cm-mlops)*
+* GitHub directory for this script: *[GitHub](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-corner-detection)*
+* CM meta description for this script: *[_cm.json](_cm.json)*
+* All CM tags to find and reuse this script (see in above meta description): *app,image,corner-detection*
+* Output cached? *False*
+* See [pipeline of dependencies](#dependencies-on-other-cm-scripts) on other CM scripts
+
+
+---
+### Reuse this script in your project
+
+#### Install MLCommons CM automation meta-framework
+
+* [Install CM](https://access.cknowledge.org/playground/?action=install)
+* [CM Getting Started Guide](https://github.com/mlcommons/ck/blob/master/docs/getting-started.md)
+
+#### Pull CM repository with this automation recipe (CM script)
+
+```cm pull repo mlcommons@ck```
+
+#### Print CM help from the command line
+
+````cmr "app image corner-detection" --help````
+
+#### Customize and run this script from the command line with different variations and flags
+
+`cm run script --tags=app,image,corner-detection`
+
+`cm run script --tags=app,image,corner-detection `
+
+*or*
+
+`cmr "app image corner-detection"`
+
+`cmr "app image corner-detection " `
+
+
+#### Run this script from Python
+
+
+Click here to expand this section.
+
+```python
+
+import cmind
+
+r = cmind.access({'action':'run'
+ 'automation':'script',
+ 'tags':'app,image,corner-detection'
+ 'out':'con',
+ ...
+ (other input keys for this script)
+ ...
+ })
+
+if r['return']>0:
+ print (r['error'])
+
+```
+
+
+
+
+#### Run this script via GUI
+
+```cmr "cm gui" --script="app,image,corner-detection"```
+
+Use this [online GUI](https://cKnowledge.org/cm-gui/?tags=app,image,corner-detection) to generate CM CMD.
+
+#### Run this script via Docker (beta)
+
+`cm docker script "app image corner-detection" `
+
+___
+### Customization
+
+#### Default environment
+
+
+Click here to expand this section.
+
+These keys can be updated via `--env.KEY=VALUE` or `env` dictionary in `@input.json` or using script flags.
+
+
+
+
+___
+### Dependencies on other CM scripts
+
+
+ 1. ***Read "deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-corner-detection/_cm.json)***
+ * detect,os
+ - CM script: [detect-os](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/detect-os)
+ * detect,cpu
+ - CM script: [detect-cpu](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/detect-cpu)
+ 1. ***Run "preprocess" function from [customize.py](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-corner-detection/customize.py)***
+ 1. Read "prehook_deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-corner-detection/_cm.json)
+ 1. ***Run native script if exists***
+ * [run.sh](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-corner-detection/run.sh)
+ 1. ***Read "posthook_deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-corner-detection/_cm.json)***
+ * compile,cpp-program
+ * `if (CM_SKIP_COMPILE != on)`
+ - CM script: [compile-program](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/compile-program)
+ * benchmark-program
+ * `if (CM_SKIP_RUN != on)`
+ - CM script: [benchmark-program](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/benchmark-program)
+ 1. ***Run "postrocess" function from [customize.py](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-corner-detection/customize.py)***
+ 1. Read "post_deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-image-corner-detection/_cm.json)
+
+___
+### Script output
+`cmr "app image corner-detection " -j`
+#### New environment keys (filter)
+
+#### New environment keys auto-detected from customize
diff --git a/script/app-image-corner-detection/_cm.json b/script/app-image-corner-detection/_cm.json
new file mode 100644
index 0000000000..405654f5ee
--- /dev/null
+++ b/script/app-image-corner-detection/_cm.json
@@ -0,0 +1,34 @@
+{
+ "alias": "app-image-corner-detection",
+ "automation_alias": "script",
+ "automation_uid": "5b4e0237da074764",
+ "category": "Modular application pipeline",
+ "deps": [
+ {"tags":"detect,os"},
+ {"tags":"detect,cpu"}
+ ],
+ "posthook_deps": [
+ {
+ "skip_if_env": {
+ "CM_SKIP_COMPILE": [
+ "on"
+ ]
+ },
+ "tags": "compile,cpp-program"
+ },
+ {
+ "skip_if_env": {
+ "CM_SKIP_RUN": [
+ "on"
+ ]
+ },
+ "tags": "benchmark-program"
+ }
+ ],
+ "tags": [
+ "app",
+ "image",
+ "corner-detection"
+ ],
+ "uid": "998ffee0bc534d0a"
+}
diff --git a/script/app-image-corner-detection/customize.py b/script/app-image-corner-detection/customize.py
new file mode 100644
index 0000000000..19536aee3c
--- /dev/null
+++ b/script/app-image-corner-detection/customize.py
@@ -0,0 +1,34 @@
+from cmind import utils
+import os
+
+def preprocess(i):
+ os_info = i['os_info']
+
+ env = i['env']
+ script_path=i['run_script_input']['path']
+
+ env["CM_SOURCE_FOLDER_PATH"] = script_path
+ env['CM_C_SOURCE_FILES']="susan.c"
+
+ if 'CM_INPUT' not in env:
+ env['CM_INPUT'] = os.path.join(script_path, 'data.pgm')
+ if 'CM_OUTPUT' not in env:
+ env['CM_OUTPUT'] = 'output_image_with_corners.pgm'
+ if 'CM_RUN_DIR' not in env:
+ env['CM_RUN_DIR'] = os.path.join(script_path, "output")
+ env['CM_RUN_SUFFIX']= env['CM_INPUT'] + ' ' + env['CM_OUTPUT'] + ' -c'
+
+ if os_info['platform'] == 'windows':
+ env['CM_BIN_NAME']='image-corner.exe'
+ else:
+ env['CM_BIN_NAME']='image-corner'
+ env['+ LDCFLAGS'] = ["-lm"]
+
+ return {'return':0}
+
+def postprocess(i):
+
+ env = i['env']
+ print(env['CM_OUTPUT'] + " generated in " + env['CM_RUN_DIR'])
+
+ return {'return':0}
diff --git a/script/app-image-corner-detection/run.sh b/script/app-image-corner-detection/run.sh
new file mode 100644
index 0000000000..30cfbdd00e
--- /dev/null
+++ b/script/app-image-corner-detection/run.sh
@@ -0,0 +1,6 @@
+#!/bin/bash
+
+CUR=${CM_TMP_CURRENT_SCRIPT_PATH:-$PWD}
+mkdir -p $CUR"/output"
+
+test $? -eq 0 || exit 1
diff --git a/script/app-image-corner-detection/susan.c b/script/app-image-corner-detection/susan.c
new file mode 100644
index 0000000000..8a41d9a22e
--- /dev/null
+++ b/script/app-image-corner-detection/susan.c
@@ -0,0 +1,2161 @@
+/* {{{ Copyright etc. */
+
+/**********************************************************************\
+
+ SUSAN Version 2l by Stephen Smith
+ Oxford Centre for Functional Magnetic Resonance Imaging of the Brain,
+ Department of Clinical Neurology, Oxford University, Oxford, UK
+ (Previously in Computer Vision and Image Processing Group - now
+ Computer Vision and Electro Optics Group - DERA Chertsey, UK)
+ Email: steve@fmrib.ox.ac.uk
+ WWW: http://www.fmrib.ox.ac.uk/~steve
+
+ (C) Crown Copyright (1995-1999), Defence Evaluation and Research Agency,
+ Farnborough, Hampshire, GU14 6TD, UK
+ DERA WWW site:
+ http://www.dera.gov.uk/
+ DERA Computer Vision and Electro Optics Group WWW site:
+ http://www.dera.gov.uk/imageprocessing/dera/group_home.html
+ DERA Computer Vision and Electro Optics Group point of contact:
+ Dr. John Savage, jtsavage@dera.gov.uk, +44 1344 633203
+
+ A UK patent has been granted: "Method for digitally processing
+ images to determine the position of edges and/or corners therein for
+ guidance of unmanned vehicle", UK Patent 2272285. Proprietor:
+ Secretary of State for Defence, UK. 15 January 1997
+
+ This code is issued for research purposes only and remains the
+ property of the UK Secretary of State for Defence. This code must
+ not be passed on without this header information being kept
+ intact. This code must not be sold.
+
+\**********************************************************************/
+
+/* }}} */
+/* {{{ Readme First */
+
+/**********************************************************************\
+
+ SUSAN Version 2l
+ SUSAN = Smallest Univalue Segment Assimilating Nucleus
+
+ Email: steve@fmrib.ox.ac.uk
+ WWW: http://www.fmrib.ox.ac.uk/~steve
+
+ Related paper:
+ @article{Smith97,
+ author = "Smith, S.M. and Brady, J.M.",
+ title = "{SUSAN} - A New Approach to Low Level Image Processing",
+ journal = "Int. Journal of Computer Vision",
+ pages = "45--78",
+ volume = "23",
+ number = "1",
+ month = "May",
+ year = 1997}
+
+ To be registered for automatic (bug) updates of SUSAN, send an email.
+
+ Compile with:
+ gcc -O4 -o susan susan2l.c -lm
+
+ See following section for different machine information. Please
+ report any bugs (and fixes). There are a few optional changes that
+ can be made in the "defines" section which follows shortly.
+
+ Usage: type "susan" to get usage. Only PGM format files can be input
+ and output. Utilities such as the netpbm package and XV can be used
+ to convert to and from other formats. Any size of image can be
+ processed.
+
+ This code is written using an emacs folding mode, making moving
+ around the different sections very easy. This is why there are
+ various marks within comments and why comments are indented.
+
+
+ SUSAN QUICK:
+
+ This version of the SUSAN corner finder does not do all the
+ false-corner suppression and thus is faster and produced some false
+ positives, particularly on strong edges. However, because there are
+ less stages involving thresholds etc., the corners that are
+ correctly reported are usually more stable than those reported with
+ the full algorithm. Thus I recommend at least TRYING this algorithm
+ for applications where stability is important, e.g., tracking.
+
+ THRESHOLDS:
+
+ There are two thresholds which can be set at run-time. These are the
+ brightness threshold (t) and the distance threshold (d).
+
+ SPATIAL CONTROL: d
+
+ In SUSAN smoothing d controls the size of the Gaussian mask; its
+ default is 4.0. Increasing d gives more smoothing. In edge finding,
+ a fixed flat mask is used, either 37 pixels arranged in a "circle"
+ (default), or a 3 by 3 mask which gives finer detail. In corner
+ finding, only the larger 37 pixel mask is used; d is not
+ variable. In smoothing, the flat 3 by 3 mask can be used instead of
+ a larger Gaussian mask; this gives low smoothing and fast operation.
+
+ BRIGHTNESS CONTROL: t
+
+ In all three algorithms, t can be varied (default=20); this is the
+ main threshold to be varied. It determines the maximum difference in
+ greylevels between two pixels which allows them to be considered
+ part of the same "region" in the image. Thus it can be reduced to
+ give more edges or corners, i.e. to be more sensitive, and vice
+ versa. In smoothing, reducing t gives less smoothing, and vice
+ versa. Set t=10 for the test image available from the SUSAN web
+ page.
+
+ ITERATIONS:
+
+ With SUSAN smoothing, more smoothing can also be obtained by
+ iterating the algorithm several times. This has a different effect
+ from varying d or t.
+
+ FIXED MASKS:
+
+ 37 pixel mask: ooo 3 by 3 mask: ooo
+ ooooo ooo
+ ooooooo ooo
+ ooooooo
+ ooooooo
+ ooooo
+ ooo
+
+ CORNER ATTRIBUTES dx, dy and I
+ (Only read this if you are interested in the C implementation or in
+ using corner attributes, e.g., for corner matching)
+
+ Corners reported in the corner list have attributes associated with
+ them as well as positions. This is useful, for example, when
+ attempting to match corners from one image to another, as these
+ attributes can often be fairly unchanged between images. The
+ attributes are dx, dy and I. I is the value of image brightness at
+ the position of the corner. In the case of susan_corners_quick, dx
+ and dy are the first order derivatives (differentials) of the image
+ brightness in the x and y directions respectively, at the position
+ of the corner. In the case of normal susan corner finding, dx and dy
+ are scaled versions of the position of the centre of gravity of the
+ USAN with respect to the centre pixel (nucleus).
+
+ BRIGHTNESS FUNCTION LUT IMPLEMENTATION:
+ (Only read this if you are interested in the C implementation)
+
+ The SUSAN brightness function is implemented as a LUT
+ (Look-Up-Table) for speed. The resulting pointer-based code is a
+ little hard to follow, so here is a brief explanation. In
+ setup_brightness_lut() the LUT is setup. This mallocs enough space
+ for *bp and then repositions the pointer to the centre of the
+ malloced space. The SUSAN function e^-(x^6) or e^-(x^2) is
+ calculated and converted to a uchar in the range 0-100, for all
+ possible image brightness differences (including negative
+ ones). Thus bp[23] is the output for a brightness difference of 23
+ greylevels. In the SUSAN algorithms this LUT is used as follows:
+
+ p=in + (i-3)*x_size + j - 1;
+ p points to the first image pixel in the circular mask surrounding
+ point (x,y).
+
+ cp=bp + in[i*x_size+j];
+ cp points to a position in the LUT corresponding to the brightness
+ of the centre pixel (x,y).
+
+ now for every pixel within the mask surrounding (x,y),
+ n+=*(cp-*p++);
+ the brightness difference function is found by moving the cp pointer
+ down by an amount equal to the value of the pixel pointed to by p,
+ thus subtracting the two brightness values and performing the
+ exponential function. This value is added to n, the running USAN
+ area.
+
+ in SUSAN smoothing, the variable height mask is implemented by
+ multiplying the above by the moving mask pointer, reset for each new
+ centre pixel.
+ tmp = *dpt++ * *(cp-brightness);
+
+\**********************************************************************/
+
+/* }}} */
+/* {{{ Machine Information */
+
+/**********************************************************************\
+
+ Success has been reported with the following:
+
+ MACHINE OS COMPILER
+
+ Sun 4.1.4 bundled C, gcc
+
+ Next
+
+ SGI IRIX SGI cc
+
+ DEC Unix V3.2+
+
+ IBM RISC AIX gcc
+
+ PC Borland 5.0
+
+ PC Linux gcc-2.6.3
+
+ PC Win32 Visual C++ 4.0 (Console Application)
+
+ PC Win95 Visual C++ 5.0 (Console Application)
+ Thanks to Niu Yongsheng :
+ Use the FOPENB option below
+
+ PC DOS djgpp gnu C
+ Thanks to Mark Pettovello :
+ Use the FOPENB option below
+
+ HP HP-UX bundled cc
+ Thanks to Brian Dixon :
+ in ksh:
+ export CCOPTS="-Aa -D_HPUX_SOURCE | -lM"
+ cc -O3 -o susan susan2l.c
+
+\**********************************************************************/
+
+/* }}} */
+/* {{{ History */
+
+/**********************************************************************\
+
+ SUSAN Version 2l, 12/2/99
+ Changed GNUDOS option to FOPENB.
+ (Thanks to Niu Yongsheng .)
+ Took out redundant "sq=sq/2;".
+
+ SUSAN Version 2k, 19/8/98:
+ In corner finding:
+ Changed if(yyx_size) etc. tests in smoothing.
+ Added a couple of free() calls for cgx and cgy.
+ (Thanks to geoffb@ucs.ed.ac.uk - Geoff Browitt.)
+
+ SUSAN Version 2i, 21/7/97:
+ Added information about corner attributes.
+
+ SUSAN Version 2h, 16/12/96:
+ Added principle (initial enhancement) option.
+
+ SUSAN Version 2g, 2/7/96:
+ Minor superficial changes to code.
+
+ SUSAN Version 2f, 16/1/96:
+ Added GNUDOS option (now called FOPENB; see options below).
+
+ SUSAN Version 2e, 9/1/96:
+ Added -b option.
+ Fixed 1 pixel horizontal offset error for drawing edges.
+
+ SUSAN Version 2d, 27/11/95:
+ Fixed loading of certain PGM files in get_image (again!)
+
+ SUSAN Version 2c, 22/11/95:
+ Fixed loading of certain PGM files in get_image.
+ (Thanks to qu@San-Jose.ate.slb.com - Gongyuan Qu.)
+
+ SUSAN Version 2b, 9/11/95:
+ removed "z==" error in edges routines.
+
+ SUSAN Version 2a, 6/11/95:
+ Removed a few unnecessary variable declarations.
+ Added different machine information.
+ Changed "header" in get_image to char.
+
+ SUSAN Version 2, 1/11/95: first combined version able to take any
+ image sizes.
+
+ SUSAN "Versions 1", circa 1992: the various SUSAN algorithms were
+ developed during my doctorate within different programs and for
+ fixed image sizes. The algorithms themselves are virtually unaltered
+ between "versions 1" and the combined program, version 2.
+
+\**********************************************************************/
+
+/* }}} */
+/* {{{ defines, includes and typedefs */
+
+/* ********** Optional settings */
+
+#ifndef PPC
+typedef int TOTAL_TYPE; /* this is faster for "int" but should be "float" for large d masks */
+#else
+typedef float TOTAL_TYPE; /* for my PowerPC accelerator only */
+#endif
+
+/*#define FOPENB*/ /* uncomment if using djgpp gnu C for DOS or certain Win95 compilers */
+#define SEVEN_SUPP /* size for non-max corner suppression; SEVEN_SUPP or FIVE_SUPP */
+#define MAX_CORNERS 15000 /* max corners per frame */
+
+/* ********** Leave the rest - but you may need to remove one or both of sys/file.h and malloc.h lines */
+
+#include
+#include
+#include
+#include
+#define exit_error(IFB,IFC) { fprintf(stderr,IFB,IFC); exit(0); }
+#define FTOI(a) ( (a) < 0 ? ((int)(a-0.5)) : ((int)(a+0.5)) )
+typedef unsigned char uchar;
+typedef struct {int x,y,info, dx, dy, I;} CORNER_LIST[MAX_CORNERS];
+
+/* }}} */
+/* {{{ usage() */
+
+#ifdef OPENME
+#include
+#endif
+#ifdef XOPENME
+#include
+#endif
+
+void usage(void)
+{
+ printf("Usage: susan [options]\n\n");
+
+ printf("-s : Smoothing mode (default)\n");
+ printf("-e : Edges mode\n");
+ printf("-c : Corners mode\n\n");
+
+ printf("See source code for more information about setting the thresholds\n");
+ printf("-t : Brightness threshold, all modes (default=20)\n");
+ printf("-d : Distance threshold, smoothing mode, (default=4) (use next option instead for flat 3x3 mask)\n");
+ printf("-3 : Use flat 3x3 mask, edges or smoothing mode\n");
+ printf("-n : No post-processing on the binary edge map (runs much faster); edges mode\n");
+ printf("-q : Use faster (and usually stabler) corner mode; edge-like corner suppression not carried out; corners mode\n");
+ printf("-b : Mark corners/edges with single black points instead of black with white border; corners or edges mode\n");
+ printf("-p : Output initial enhancement image only; corners or edges mode (default is edges mode)\n");
+
+ printf("\nSUSAN Version 2l (C) 1995-1997 Stephen Smith, DRA UK. steve@fmrib.ox.ac.uk\n");
+
+ exit(0);
+}
+
+/* }}} */
+/* {{{ get_image(filename,in,x_size,y_size) */
+
+/* {{{ int getint(fp) derived from XV */
+
+int getint(FILE* fd)
+{
+ int c, i;
+ char dummy[10000];
+
+ c = getc(fd);
+ while (1) /* find next integer */
+ {
+ if (c=='#') /* if we're at a comment, read to end of line */
+ fgets(dummy,9000,fd);
+ if (c==EOF)
+ exit_error("Image %s not binary PGM.\n","is");
+ if (c>='0' && c<='9')
+ break; /* found what we were looking for */
+ c = getc(fd);
+ }
+
+ /* we're at the start of a number, continue until we hit a non-number */
+ i = 0;
+ while (1) {
+ i = (i*10) + (c - '0');
+ c = getc(fd);
+ if (c==EOF) return (i);
+ if (c<'0' || c>'9') break;
+ }
+
+ return (i);
+}
+
+/* }}} */
+
+void get_image(char filename[200], unsigned char** in, int* x_size, int* y_size)
+{
+FILE *fd;
+char header [100];
+int tmp;
+
+#ifdef FOPENB
+ if ((fd=fopen(filename,"rb")) == NULL)
+#else
+ if ((fd=fopen(filename,"r")) == NULL)
+#endif
+ exit_error("Can't input image %s.\n",filename);
+
+ /* {{{ read header */
+
+ header[0]=fgetc(fd);
+ header[1]=fgetc(fd);
+ if(!(header[0]=='P' && header[1]=='5'))
+ exit_error("Image %s does not have binary PGM header.\n",filename);
+
+ *x_size = getint(fd);
+ *y_size = getint(fd);
+ tmp = getint(fd);
+
+/* }}} */
+
+ *in = (uchar *) malloc(*x_size * *y_size);
+
+ if (fread(*in,1,*x_size * *y_size,fd) == 0)
+ exit_error("Image %s is wrong size.\n",filename);
+
+ fclose(fd);
+}
+
+/* }}} */
+/* {{{ put_image(filename,in,x_size,y_size) */
+
+void put_image(char filename[100], char* in, int x_size, int y_size)
+{
+FILE *fd;
+
+#ifdef FOPENB
+ if ((fd=fopen(filename,"wb")) == NULL)
+#else
+ if ((fd=fopen(filename,"w")) == NULL)
+#endif
+ exit_error("Can't output image%s.\n",filename);
+
+ fprintf(fd,"P5\n");
+ fprintf(fd,"%d %d\n",x_size,y_size);
+ fprintf(fd,"255\n");
+
+ if (fwrite(in,x_size*y_size,1,fd) != 1)
+ exit_error("Can't write image %s.\n",filename);
+
+ fclose(fd);
+}
+
+/* }}} */
+/* {{{ int_to_uchar(r,in,size) */
+
+void int_to_uchar(int* r, uchar* in, int size)
+{
+int i,
+ max_r=r[0],
+ min_r=r[0];
+
+ for (i=0; i max_r )
+ max_r=r[i];
+ if ( r[i] < min_r )
+ min_r=r[i];
+ }
+
+ /*printf("min=%d max=%d\n",min_r,max_r);*/
+
+ max_r-=min_r;
+
+ for (i=0; ip[l+1])
+ {
+ tmp=p[l]; p[l]=p[l+1]; p[l+1]=tmp;
+ }
+
+ return( (p[3]+p[4]) / 2 );
+}
+
+/* }}} */
+/* {{{ enlarge(in,tmp_image,x_size,y_size,border) */
+
+/* this enlarges "in" so that borders can be dealt with easily */
+
+void enlarge(uchar** in, uchar* tmp_image, int* x_size, int* y_size, int border)
+{
+int i, j;
+
+ for(i=0; i<*y_size; i++) /* copy *in into tmp_image */
+ memcpy(tmp_image+(i+border)*(*x_size+2*border)+border, *in+i* *x_size, *x_size);
+
+ for(i=0; i15) && (total==0) )
+ {
+ printf("Distance_thresh (%f) too big for integer arithmetic.\n",dt);
+ printf("Either reduce it to <=15 or recompile with variable \"total\"\n");
+ printf("as a float: see top \"defines\" section.\n");
+ exit(0);
+ }
+
+ if ( (2*mask_size+1>x_size) || (2*mask_size+1>y_size) )
+ {
+ printf("Mask size (1.5*distance_thresh+1=%d) too big for image (%dx%d).\n",mask_size,x_size,y_size);
+ exit(0);
+ }
+
+ tmp_image = (uchar *) malloc( (x_size+mask_size*2) * (y_size+mask_size*2) );
+ enlarge(&in,tmp_image,&x_size,&y_size,mask_size);
+
+/* }}} */
+
+ if (three_by_three==0)
+ { /* large Gaussian masks */
+ /* {{{ setup distance lut */
+
+ n_max = (mask_size*2) + 1;
+
+ increment = x_size - n_max;
+
+ dp = (unsigned char *)malloc(n_max*n_max);
+ dpt = dp;
+ temp = -(dt*dt);
+
+ for(i=-mask_size; i<=mask_size; i++)
+ for(j=-mask_size; j<=mask_size; j++)
+ {
+ x = (int) (100.0 * exp( ((float)((i*i)+(j*j))) / temp ));
+ *dpt++ = (unsigned char)x;
+ }
+
+/* }}} */
+ /* {{{ main section */
+
+ for (i=mask_size;im) { m=l[y+y+y+x]; a=y; b=x; }
+
+ if (m>0)
+ {
+ if (mid[i*x_size+j]<4)
+ mid[(i+a-1)*x_size+j+b-1] = 4;
+ else
+ mid[(i+a-1)*x_size+j+b-1] = mid[i*x_size+j]+1;
+ if ( (a+a+b) < 3 ) /* need to jump back in image */
+ {
+ i+=a-1;
+ j+=b-2;
+ if (i<4) i=4;
+ if (j<4) j=4;
+ }
+ }
+ }
+
+/* }}} */
+ /* {{{ n==2 */
+
+ if (n==2)
+ {
+ /* put in a bit here to straighten edges */
+ b00 = mid[(i-1)*x_size+j-1]<8; /* corners of 3x3 */
+ b02 = mid[(i-1)*x_size+j+1]<8;
+ b20 = mid[(i+1)*x_size+j-1]<8;
+ b22 = mid[(i+1)*x_size+j+1]<8;
+ if ( ((b00+b02+b20+b22)==2) && ((b00|b22)&(b02|b20)))
+ { /* case: move a point back into line.
+ e.g. X O X CAN become X X X
+ O X O O O O
+ O O O O O O */
+ if (b00)
+ {
+ if (b02) { x=0; y=-1; }
+ else { x=-1; y=0; }
+ }
+ else
+ {
+ if (b02) { x=1; y=0; }
+ else { x=0; y=1; }
+ }
+ if (((float)r[(i+y)*x_size+j+x]/(float)centre) > 0.7)
+ {
+ if ( ( (x==0) && (mid[(i+(2*y))*x_size+j]>7) && (mid[(i+(2*y))*x_size+j-1]>7) && (mid[(i+(2*y))*x_size+j+1]>7) ) ||
+ ( (y==0) && (mid[(i)*x_size+j+(2*x)]>7) && (mid[(i+1)*x_size+j+(2*x)]>7) && (mid[(i-1)*x_size+j+(2*x)]>7) ) )
+ {
+ mid[(i)*x_size+j]=100;
+ mid[(i+y)*x_size+j+x]=3; /* no jumping needed */
+ }
+ }
+ }
+ else
+ {
+ b01 = mid[(i-1)*x_size+j ]<8;
+ b12 = mid[(i )*x_size+j+1]<8;
+ b21 = mid[(i+1)*x_size+j ]<8;
+ b10 = mid[(i )*x_size+j-1]<8;
+ /* {{{ right angle ends - not currently used */
+
+#ifdef IGNORETHIS
+ if ( (b00&b01)|(b00&b10)|(b02&b01)|(b02&b12)|(b20&b10)|(b20&b21)|(b22&b21)|(b22&b12) )
+ { /* case; right angle ends. clean up.
+ e.g.; X X O CAN become X X O
+ O X O O O O
+ O O O O O O */
+ if ( ((b01)&(mid[(i-2)*x_size+j-1]>7)&(mid[(i-2)*x_size+j]>7)&(mid[(i-2)*x_size+j+1]>7)&
+ ((b00&((2*r[(i-1)*x_size+j+1])>centre))|(b02&((2*r[(i-1)*x_size+j-1])>centre)))) |
+ ((b10)&(mid[(i-1)*x_size+j-2]>7)&(mid[(i)*x_size+j-2]>7)&(mid[(i+1)*x_size+j-2]>7)&
+ ((b00&((2*r[(i+1)*x_size+j-1])>centre))|(b20&((2*r[(i-1)*x_size+j-1])>centre)))) |
+ ((b12)&(mid[(i-1)*x_size+j+2]>7)&(mid[(i)*x_size+j+2]>7)&(mid[(i+1)*x_size+j+2]>7)&
+ ((b02&((2*r[(i+1)*x_size+j+1])>centre))|(b22&((2*r[(i-1)*x_size+j+1])>centre)))) |
+ ((b21)&(mid[(i+2)*x_size+j-1]>7)&(mid[(i+2)*x_size+j]>7)&(mid[(i+2)*x_size+j+1]>7)&
+ ((b20&((2*r[(i+1)*x_size+j+1])>centre))|(b22&((2*r[(i+1)*x_size+j-1])>centre)))) )
+ {
+ mid[(i)*x_size+j]=100;
+ if (b10&b20) j-=2;
+ if (b00|b01|b02) { i--; j-=2; }
+ }
+ }
+#endif
+
+/* }}} */
+ if ( ((b01+b12+b21+b10)==2) && ((b10|b12)&(b01|b21)) &&
+ ((b01&((mid[(i-2)*x_size+j-1]<8)|(mid[(i-2)*x_size+j+1]<8)))|(b10&((mid[(i-1)*x_size+j-2]<8)|(mid[(i+1)*x_size+j-2]<8)))|
+ (b12&((mid[(i-1)*x_size+j+2]<8)|(mid[(i+1)*x_size+j+2]<8)))|(b21&((mid[(i+2)*x_size+j-1]<8)|(mid[(i+2)*x_size+j+1]<8)))) )
+ { /* case; clears odd right angles.
+ e.g.; O O O becomes O O O
+ X X O X O O
+ O X O O X O */
+ mid[(i)*x_size+j]=100;
+ i--; /* jump back */
+ j-=2;
+ if (i<4) i=4;
+ if (j<4) j=4;
+ }
+ }
+ }
+
+/* }}} */
+ /* {{{ n>2 the thinning is done here without breaking connectivity */
+
+ if (n>2)
+ {
+ b01 = mid[(i-1)*x_size+j ]<8;
+ b12 = mid[(i )*x_size+j+1]<8;
+ b21 = mid[(i+1)*x_size+j ]<8;
+ b10 = mid[(i )*x_size+j-1]<8;
+ if((b01+b12+b21+b10)>1)
+ {
+ b00 = mid[(i-1)*x_size+j-1]<8;
+ b02 = mid[(i-1)*x_size+j+1]<8;
+ b20 = mid[(i+1)*x_size+j-1]<8;
+ b22 = mid[(i+1)*x_size+j+1]<8;
+ p1 = b00 | b01;
+ p2 = b02 | b12;
+ p3 = b22 | b21;
+ p4 = b20 | b10;
+
+ if( ((p1 + p2 + p3 + p4) - ((b01 & p2)+(b12 & p3)+(b21 & p4)+(b10 & p1))) < 2)
+ {
+ mid[(i)*x_size+j]=100;
+ i--;
+ j-=2;
+ if (i<4) i=4;
+ if (j<4) j=4;
+ }
+ }
+ }
+
+/* }}} */
+ }
+}
+
+/* }}} */
+/* {{{ susan_edges(in,r,sf,max_no,out) */
+
+void susan_edges(uchar* in, int* r, uchar* mid, uchar* bp,
+ int max_no, int x_size, int y_size)
+{
+float z;
+int do_symmetry, i, j, m, n, a, b, x, y, w;
+uchar c,*p,*cp;
+
+ memset (r,0,x_size * y_size * sizeof(int));
+
+ for (i=3;i0)
+ {
+ m=r[i*x_size+j];
+ n=max_no - m;
+ cp=bp + in[i*x_size+j];
+
+ if (n>600)
+ {
+ p=in + (i-3)*x_size + j - 1;
+ x=0;y=0;
+
+ c=*(cp-*p++);x-=c;y-=3*c;
+ c=*(cp-*p++);y-=3*c;
+ c=*(cp-*p);x+=c;y-=3*c;
+ p+=x_size-3;
+
+ c=*(cp-*p++);x-=2*c;y-=2*c;
+ c=*(cp-*p++);x-=c;y-=2*c;
+ c=*(cp-*p++);y-=2*c;
+ c=*(cp-*p++);x+=c;y-=2*c;
+ c=*(cp-*p);x+=2*c;y-=2*c;
+ p+=x_size-5;
+
+ c=*(cp-*p++);x-=3*c;y-=c;
+ c=*(cp-*p++);x-=2*c;y-=c;
+ c=*(cp-*p++);x-=c;y-=c;
+ c=*(cp-*p++);y-=c;
+ c=*(cp-*p++);x+=c;y-=c;
+ c=*(cp-*p++);x+=2*c;y-=c;
+ c=*(cp-*p);x+=3*c;y-=c;
+ p+=x_size-6;
+
+ c=*(cp-*p++);x-=3*c;
+ c=*(cp-*p++);x-=2*c;
+ c=*(cp-*p);x-=c;
+ p+=2;
+ c=*(cp-*p++);x+=c;
+ c=*(cp-*p++);x+=2*c;
+ c=*(cp-*p);x+=3*c;
+ p+=x_size-6;
+
+ c=*(cp-*p++);x-=3*c;y+=c;
+ c=*(cp-*p++);x-=2*c;y+=c;
+ c=*(cp-*p++);x-=c;y+=c;
+ c=*(cp-*p++);y+=c;
+ c=*(cp-*p++);x+=c;y+=c;
+ c=*(cp-*p++);x+=2*c;y+=c;
+ c=*(cp-*p);x+=3*c;y+=c;
+ p+=x_size-5;
+
+ c=*(cp-*p++);x-=2*c;y+=2*c;
+ c=*(cp-*p++);x-=c;y+=2*c;
+ c=*(cp-*p++);y+=2*c;
+ c=*(cp-*p++);x+=c;y+=2*c;
+ c=*(cp-*p);x+=2*c;y+=2*c;
+ p+=x_size-3;
+
+ c=*(cp-*p++);x-=c;y+=3*c;
+ c=*(cp-*p++);y+=3*c;
+ c=*(cp-*p);x+=c;y+=3*c;
+
+ z = sqrt((float)((x*x) + (y*y)));
+ if (z > (0.9*(float)n)) /* 0.5 */
+ {
+ do_symmetry=0;
+ if (x==0)
+ z=1000000.0;
+ else
+ z=((float)y) / ((float)x);
+ if (z < 0) { z=-z; w=-1; }
+ else w=1;
+ if (z < 0.5) { /* vert_edge */ a=0; b=1; }
+ else { if (z > 2.0) { /* hor_edge */ a=1; b=0; }
+ else { /* diag_edge */ if (w>0) { a=1; b=1; }
+ else { a=-1; b=1; }}}
+ if ( (m > r[(i+a)*x_size+j+b]) && (m >= r[(i-a)*x_size+j-b]) &&
+ (m > r[(i+(2*a))*x_size+j+(2*b)]) && (m >= r[(i-(2*a))*x_size+j-(2*b)]) )
+ mid[i*x_size+j] = 1;
+ }
+ else
+ do_symmetry=1;
+ }
+ else
+ do_symmetry=1;
+
+ if (do_symmetry==1)
+ {
+ p=in + (i-3)*x_size + j - 1;
+ x=0; y=0; w=0;
+
+ /* | \
+ y -x- w
+ | \ */
+
+ c=*(cp-*p++);x+=c;y+=9*c;w+=3*c;
+ c=*(cp-*p++);y+=9*c;
+ c=*(cp-*p);x+=c;y+=9*c;w-=3*c;
+ p+=x_size-3;
+
+ c=*(cp-*p++);x+=4*c;y+=4*c;w+=4*c;
+ c=*(cp-*p++);x+=c;y+=4*c;w+=2*c;
+ c=*(cp-*p++);y+=4*c;
+ c=*(cp-*p++);x+=c;y+=4*c;w-=2*c;
+ c=*(cp-*p);x+=4*c;y+=4*c;w-=4*c;
+ p+=x_size-5;
+
+ c=*(cp-*p++);x+=9*c;y+=c;w+=3*c;
+ c=*(cp-*p++);x+=4*c;y+=c;w+=2*c;
+ c=*(cp-*p++);x+=c;y+=c;w+=c;
+ c=*(cp-*p++);y+=c;
+ c=*(cp-*p++);x+=c;y+=c;w-=c;
+ c=*(cp-*p++);x+=4*c;y+=c;w-=2*c;
+ c=*(cp-*p);x+=9*c;y+=c;w-=3*c;
+ p+=x_size-6;
+
+ c=*(cp-*p++);x+=9*c;
+ c=*(cp-*p++);x+=4*c;
+ c=*(cp-*p);x+=c;
+ p+=2;
+ c=*(cp-*p++);x+=c;
+ c=*(cp-*p++);x+=4*c;
+ c=*(cp-*p);x+=9*c;
+ p+=x_size-6;
+
+ c=*(cp-*p++);x+=9*c;y+=c;w-=3*c;
+ c=*(cp-*p++);x+=4*c;y+=c;w-=2*c;
+ c=*(cp-*p++);x+=c;y+=c;w-=c;
+ c=*(cp-*p++);y+=c;
+ c=*(cp-*p++);x+=c;y+=c;w+=c;
+ c=*(cp-*p++);x+=4*c;y+=c;w+=2*c;
+ c=*(cp-*p);x+=9*c;y+=c;w+=3*c;
+ p+=x_size-5;
+
+ c=*(cp-*p++);x+=4*c;y+=4*c;w-=4*c;
+ c=*(cp-*p++);x+=c;y+=4*c;w-=2*c;
+ c=*(cp-*p++);y+=4*c;
+ c=*(cp-*p++);x+=c;y+=4*c;w+=2*c;
+ c=*(cp-*p);x+=4*c;y+=4*c;w+=4*c;
+ p+=x_size-3;
+
+ c=*(cp-*p++);x+=c;y+=9*c;w-=3*c;
+ c=*(cp-*p++);y+=9*c;
+ c=*(cp-*p);x+=c;y+=9*c;w+=3*c;
+
+ if (y==0)
+ z = 1000000.0;
+ else
+ z = ((float)x) / ((float)y);
+ if (z < 0.5) { /* vertical */ a=0; b=1; }
+ else { if (z > 2.0) { /* horizontal */ a=1; b=0; }
+ else { /* diagonal */ if (w>0) { a=-1; b=1; }
+ else { a=1; b=1; }}}
+ if ( (m > r[(i+a)*x_size+j+b]) && (m >= r[(i-a)*x_size+j-b]) &&
+ (m > r[(i+(2*a))*x_size+j+(2*b)]) && (m >= r[(i-(2*a))*x_size+j-(2*b)]) )
+ mid[i*x_size+j] = 2;
+ }
+ }
+ }
+}
+
+/* }}} */
+/* {{{ susan_edges_small(in,r,sf,max_no,out) */
+
+void susan_edges_small(uchar* in, int* r, uchar* mid, uchar* bp,
+ int max_no, int x_size, int y_size)
+{
+float z;
+int do_symmetry, i, j, m, n, a, b, x, y, w;
+uchar c,*p,*cp;
+
+ memset (r,0,x_size * y_size * sizeof(int));
+
+ max_no = 730; /* ho hum ;) */
+
+ for (i=1;i0)
+ {
+ m=r[i*x_size+j];
+ n=max_no - m;
+ cp=bp + in[i*x_size+j];
+
+ if (n>250)
+ {
+ p=in + (i-1)*x_size + j - 1;
+ x=0;y=0;
+
+ c=*(cp-*p++);x-=c;y-=c;
+ c=*(cp-*p++);y-=c;
+ c=*(cp-*p);x+=c;y-=c;
+ p+=x_size-2;
+
+ c=*(cp-*p);x-=c;
+ p+=2;
+ c=*(cp-*p);x+=c;
+ p+=x_size-2;
+
+ c=*(cp-*p++);x-=c;y+=c;
+ c=*(cp-*p++);y+=c;
+ c=*(cp-*p);x+=c;y+=c;
+
+ z = sqrt((float)((x*x) + (y*y)));
+ if (z > (0.4*(float)n)) /* 0.6 */
+ {
+ do_symmetry=0;
+ if (x==0)
+ z=1000000.0;
+ else
+ z=((float)y) / ((float)x);
+ if (z < 0) { z=-z; w=-1; }
+ else w=1;
+ if (z < 0.5) { /* vert_edge */ a=0; b=1; }
+ else { if (z > 2.0) { /* hor_edge */ a=1; b=0; }
+ else { /* diag_edge */ if (w>0) { a=1; b=1; }
+ else { a=-1; b=1; }}}
+ if ( (m > r[(i+a)*x_size+j+b]) && (m >= r[(i-a)*x_size+j-b]) )
+ mid[i*x_size+j] = 1;
+ }
+ else
+ do_symmetry=1;
+ }
+ else
+ do_symmetry=1;
+
+ if (do_symmetry==1)
+ {
+ p=in + (i-1)*x_size + j - 1;
+ x=0; y=0; w=0;
+
+ /* | \
+ y -x- w
+ | \ */
+
+ c=*(cp-*p++);x+=c;y+=c;w+=c;
+ c=*(cp-*p++);y+=c;
+ c=*(cp-*p);x+=c;y+=c;w-=c;
+ p+=x_size-2;
+
+ c=*(cp-*p);x+=c;
+ p+=2;
+ c=*(cp-*p);x+=c;
+ p+=x_size-2;
+
+ c=*(cp-*p++);x+=c;y+=c;w-=c;
+ c=*(cp-*p++);y+=c;
+ c=*(cp-*p);x+=c;y+=c;w+=c;
+
+ if (y==0)
+ z = 1000000.0;
+ else
+ z = ((float)x) / ((float)y);
+ if (z < 0.5) { /* vertical */ a=0; b=1; }
+ else { if (z > 2.0) { /* horizontal */ a=1; b=0; }
+ else { /* diagonal */ if (w>0) { a=-1; b=1; }
+ else { a=1; b=1; }}}
+ if ( (m > r[(i+a)*x_size+j+b]) && (m >= r[(i-a)*x_size+j-b]) )
+ mid[i*x_size+j] = 2;
+ }
+ }
+ }
+}
+
+/* }}} */
+
+/* }}} */
+/* {{{ corners */
+
+/* {{{ corner_draw(in,corner_list,drawing_mode) */
+
+void corner_draw(uchar* in, CORNER_LIST corner_list,
+ int x_size, int drawing_mode)
+{
+uchar *p;
+int n=0;
+
+ while(corner_list[n].info != 7)
+ {
+ if (drawing_mode==0)
+ {
+ p = in + (corner_list[n].y-1)*x_size + corner_list[n].x - 1;
+ *p++=255; *p++=255; *p=255; p+=x_size-2;
+ *p++=255; *p++=0; *p=255; p+=x_size-2;
+ *p++=255; *p++=255; *p=255;
+ n++;
+ }
+ else
+ {
+ p = in + corner_list[n].y*x_size + corner_list[n].x;
+ *p=0;
+ n++;
+ }
+ }
+}
+
+/* }}} */
+/* {{{ susan(in,r,sf,max_no,corner_list) */
+
+void susan_corners(uchar* in, int* r, uchar* bp,
+ int max_no, CORNER_LIST corner_list,
+ int x_size, int y_size)
+{
+int n,x,y,sq,xx,yy,
+ i,j,*cgx,*cgy;
+float divide;
+uchar c,*p,*cp;
+
+ memset (r,0,x_size * y_size * sizeof(int));
+
+ cgx=(int *)malloc(x_size*y_size*sizeof(int));
+ cgy=(int *)malloc(x_size*y_size*sizeof(int));
+
+ for (i=5;i ((n*n)/2) )
+ {
+ if(yy290){
+ r[i*x_size+j] = max_no-n;
+ cgx[i*x_size+j] = (51*x)/n;
+ cgy[i*x_size+j] = (51*y)/n;}
+ }
+ }
+}}}}}}}}}}}}}}}}}}}
+
+ /* to locate the local maxima */
+ n=0;
+ for (i=5;i0) {
+ /* 5x5 mask */
+#ifdef FIVE_SUPP
+ if (
+ (x>r[(i-1)*x_size+j+2]) &&
+ (x>r[(i )*x_size+j+1]) &&
+ (x>r[(i )*x_size+j+2]) &&
+ (x>r[(i+1)*x_size+j-1]) &&
+ (x>r[(i+1)*x_size+j ]) &&
+ (x>r[(i+1)*x_size+j+1]) &&
+ (x>r[(i+1)*x_size+j+2]) &&
+ (x>r[(i+2)*x_size+j-2]) &&
+ (x>r[(i+2)*x_size+j-1]) &&
+ (x>r[(i+2)*x_size+j ]) &&
+ (x>r[(i+2)*x_size+j+1]) &&
+ (x>r[(i+2)*x_size+j+2]) &&
+ (x>=r[(i-2)*x_size+j-2]) &&
+ (x>=r[(i-2)*x_size+j-1]) &&
+ (x>=r[(i-2)*x_size+j ]) &&
+ (x>=r[(i-2)*x_size+j+1]) &&
+ (x>=r[(i-2)*x_size+j+2]) &&
+ (x>=r[(i-1)*x_size+j-2]) &&
+ (x>=r[(i-1)*x_size+j-1]) &&
+ (x>=r[(i-1)*x_size+j ]) &&
+ (x>=r[(i-1)*x_size+j+1]) &&
+ (x>=r[(i )*x_size+j-2]) &&
+ (x>=r[(i )*x_size+j-1]) &&
+ (x>=r[(i+1)*x_size+j-2]) )
+#endif
+#ifdef SEVEN_SUPP
+ if (
+ (x>r[(i-3)*x_size+j-3]) &&
+ (x>r[(i-3)*x_size+j-2]) &&
+ (x>r[(i-3)*x_size+j-1]) &&
+ (x>r[(i-3)*x_size+j ]) &&
+ (x>r[(i-3)*x_size+j+1]) &&
+ (x>r[(i-3)*x_size+j+2]) &&
+ (x>r[(i-3)*x_size+j+3]) &&
+
+ (x>r[(i-2)*x_size+j-3]) &&
+ (x>r[(i-2)*x_size+j-2]) &&
+ (x>r[(i-2)*x_size+j-1]) &&
+ (x>r[(i-2)*x_size+j ]) &&
+ (x>r[(i-2)*x_size+j+1]) &&
+ (x>r[(i-2)*x_size+j+2]) &&
+ (x>r[(i-2)*x_size+j+3]) &&
+
+ (x>r[(i-1)*x_size+j-3]) &&
+ (x>r[(i-1)*x_size+j-2]) &&
+ (x>r[(i-1)*x_size+j-1]) &&
+ (x>r[(i-1)*x_size+j ]) &&
+ (x>r[(i-1)*x_size+j+1]) &&
+ (x>r[(i-1)*x_size+j+2]) &&
+ (x>r[(i-1)*x_size+j+3]) &&
+
+ (x>r[(i)*x_size+j-3]) &&
+ (x>r[(i)*x_size+j-2]) &&
+ (x>r[(i)*x_size+j-1]) &&
+ (x>=r[(i)*x_size+j+1]) &&
+ (x>=r[(i)*x_size+j+2]) &&
+ (x>=r[(i)*x_size+j+3]) &&
+
+ (x>=r[(i+1)*x_size+j-3]) &&
+ (x>=r[(i+1)*x_size+j-2]) &&
+ (x>=r[(i+1)*x_size+j-1]) &&
+ (x>=r[(i+1)*x_size+j ]) &&
+ (x>=r[(i+1)*x_size+j+1]) &&
+ (x>=r[(i+1)*x_size+j+2]) &&
+ (x>=r[(i+1)*x_size+j+3]) &&
+
+ (x>=r[(i+2)*x_size+j-3]) &&
+ (x>=r[(i+2)*x_size+j-2]) &&
+ (x>=r[(i+2)*x_size+j-1]) &&
+ (x>=r[(i+2)*x_size+j ]) &&
+ (x>=r[(i+2)*x_size+j+1]) &&
+ (x>=r[(i+2)*x_size+j+2]) &&
+ (x>=r[(i+2)*x_size+j+3]) &&
+
+ (x>=r[(i+3)*x_size+j-3]) &&
+ (x>=r[(i+3)*x_size+j-2]) &&
+ (x>=r[(i+3)*x_size+j-1]) &&
+ (x>=r[(i+3)*x_size+j ]) &&
+ (x>=r[(i+3)*x_size+j+1]) &&
+ (x>=r[(i+3)*x_size+j+2]) &&
+ (x>=r[(i+3)*x_size+j+3]) )
+#endif
+{
+corner_list[n].info=0;
+corner_list[n].x=j;
+corner_list[n].y=i;
+corner_list[n].dx=cgx[i*x_size+j];
+corner_list[n].dy=cgy[i*x_size+j];
+corner_list[n].I=in[i*x_size+j];
+n++;
+if(n==MAX_CORNERS){
+ fprintf(stderr,"Too many corners.\n");
+ exit(1);
+ }}}}
+corner_list[n].info=7;
+
+free(cgx);
+free(cgy);
+
+}
+
+/* }}} */
+/* {{{ susan_quick(in,r,sf,max_no,corner_list) */
+
+void susan_corners_quick(uchar* in, int* r, uchar* bp,
+ int max_no, CORNER_LIST corner_list,
+ int x_size, int y_size)
+{
+int n,x,y,i,j;
+uchar *p,*cp;
+
+ memset (r,0,x_size * y_size * sizeof(int));
+
+ for (i=7;i0) {
+ /* 5x5 mask */
+#ifdef FIVE_SUPP
+ if (
+ (x>r[(i-1)*x_size+j+2]) &&
+ (x>r[(i )*x_size+j+1]) &&
+ (x>r[(i )*x_size+j+2]) &&
+ (x>r[(i+1)*x_size+j-1]) &&
+ (x>r[(i+1)*x_size+j ]) &&
+ (x>r[(i+1)*x_size+j+1]) &&
+ (x>r[(i+1)*x_size+j+2]) &&
+ (x>r[(i+2)*x_size+j-2]) &&
+ (x>r[(i+2)*x_size+j-1]) &&
+ (x>r[(i+2)*x_size+j ]) &&
+ (x>r[(i+2)*x_size+j+1]) &&
+ (x>r[(i+2)*x_size+j+2]) &&
+ (x>=r[(i-2)*x_size+j-2]) &&
+ (x>=r[(i-2)*x_size+j-1]) &&
+ (x>=r[(i-2)*x_size+j ]) &&
+ (x>=r[(i-2)*x_size+j+1]) &&
+ (x>=r[(i-2)*x_size+j+2]) &&
+ (x>=r[(i-1)*x_size+j-2]) &&
+ (x>=r[(i-1)*x_size+j-1]) &&
+ (x>=r[(i-1)*x_size+j ]) &&
+ (x>=r[(i-1)*x_size+j+1]) &&
+ (x>=r[(i )*x_size+j-2]) &&
+ (x>=r[(i )*x_size+j-1]) &&
+ (x>=r[(i+1)*x_size+j-2]) )
+#endif
+#ifdef SEVEN_SUPP
+ if (
+ (x>r[(i-3)*x_size+j-3]) &&
+ (x>r[(i-3)*x_size+j-2]) &&
+ (x>r[(i-3)*x_size+j-1]) &&
+ (x>r[(i-3)*x_size+j ]) &&
+ (x>r[(i-3)*x_size+j+1]) &&
+ (x>r[(i-3)*x_size+j+2]) &&
+ (x>r[(i-3)*x_size+j+3]) &&
+
+ (x>r[(i-2)*x_size+j-3]) &&
+ (x>r[(i-2)*x_size+j-2]) &&
+ (x>r[(i-2)*x_size+j-1]) &&
+ (x>r[(i-2)*x_size+j ]) &&
+ (x>r[(i-2)*x_size+j+1]) &&
+ (x>r[(i-2)*x_size+j+2]) &&
+ (x>r[(i-2)*x_size+j+3]) &&
+
+ (x>r[(i-1)*x_size+j-3]) &&
+ (x>r[(i-1)*x_size+j-2]) &&
+ (x>r[(i-1)*x_size+j-1]) &&
+ (x>r[(i-1)*x_size+j ]) &&
+ (x>r[(i-1)*x_size+j+1]) &&
+ (x>r[(i-1)*x_size+j+2]) &&
+ (x>r[(i-1)*x_size+j+3]) &&
+
+ (x>r[(i)*x_size+j-3]) &&
+ (x>r[(i)*x_size+j-2]) &&
+ (x>r[(i)*x_size+j-1]) &&
+ (x>=r[(i)*x_size+j+1]) &&
+ (x>=r[(i)*x_size+j+2]) &&
+ (x>=r[(i)*x_size+j+3]) &&
+
+ (x>=r[(i+1)*x_size+j-3]) &&
+ (x>=r[(i+1)*x_size+j-2]) &&
+ (x>=r[(i+1)*x_size+j-1]) &&
+ (x>=r[(i+1)*x_size+j ]) &&
+ (x>=r[(i+1)*x_size+j+1]) &&
+ (x>=r[(i+1)*x_size+j+2]) &&
+ (x>=r[(i+1)*x_size+j+3]) &&
+
+ (x>=r[(i+2)*x_size+j-3]) &&
+ (x>=r[(i+2)*x_size+j-2]) &&
+ (x>=r[(i+2)*x_size+j-1]) &&
+ (x>=r[(i+2)*x_size+j ]) &&
+ (x>=r[(i+2)*x_size+j+1]) &&
+ (x>=r[(i+2)*x_size+j+2]) &&
+ (x>=r[(i+2)*x_size+j+3]) &&
+
+ (x>=r[(i+3)*x_size+j-3]) &&
+ (x>=r[(i+3)*x_size+j-2]) &&
+ (x>=r[(i+3)*x_size+j-1]) &&
+ (x>=r[(i+3)*x_size+j ]) &&
+ (x>=r[(i+3)*x_size+j+1]) &&
+ (x>=r[(i+3)*x_size+j+2]) &&
+ (x>=r[(i+3)*x_size+j+3]) )
+#endif
+{
+corner_list[n].info=0;
+corner_list[n].x=j;
+corner_list[n].y=i;
+x = in[(i-2)*x_size+j-2] + in[(i-2)*x_size+j-1] + in[(i-2)*x_size+j] + in[(i-2)*x_size+j+1] + in[(i-2)*x_size+j+2] +
+ in[(i-1)*x_size+j-2] + in[(i-1)*x_size+j-1] + in[(i-1)*x_size+j] + in[(i-1)*x_size+j+1] + in[(i-1)*x_size+j+2] +
+ in[(i )*x_size+j-2] + in[(i )*x_size+j-1] + in[(i )*x_size+j] + in[(i )*x_size+j+1] + in[(i )*x_size+j+2] +
+ in[(i+1)*x_size+j-2] + in[(i+1)*x_size+j-1] + in[(i+1)*x_size+j] + in[(i+1)*x_size+j+1] + in[(i+1)*x_size+j+2] +
+ in[(i+2)*x_size+j-2] + in[(i+2)*x_size+j-1] + in[(i+2)*x_size+j] + in[(i+2)*x_size+j+1] + in[(i+2)*x_size+j+2];
+
+corner_list[n].I=x/25;
+/*corner_list[n].I=in[i*x_size+j];*/
+x = in[(i-2)*x_size+j+2] + in[(i-1)*x_size+j+2] + in[(i)*x_size+j+2] + in[(i+1)*x_size+j+2] + in[(i+2)*x_size+j+2] -
+ (in[(i-2)*x_size+j-2] + in[(i-1)*x_size+j-2] + in[(i)*x_size+j-2] + in[(i+1)*x_size+j-2] + in[(i+2)*x_size+j-2]);
+x += x + in[(i-2)*x_size+j+1] + in[(i-1)*x_size+j+1] + in[(i)*x_size+j+1] + in[(i+1)*x_size+j+1] + in[(i+2)*x_size+j+1] -
+ (in[(i-2)*x_size+j-1] + in[(i-1)*x_size+j-1] + in[(i)*x_size+j-1] + in[(i+1)*x_size+j-1] + in[(i+2)*x_size+j-1]);
+
+y = in[(i+2)*x_size+j-2] + in[(i+2)*x_size+j-1] + in[(i+2)*x_size+j] + in[(i+2)*x_size+j+1] + in[(i+2)*x_size+j+2] -
+ (in[(i-2)*x_size+j-2] + in[(i-2)*x_size+j-1] + in[(i-2)*x_size+j] + in[(i-2)*x_size+j+1] + in[(i-2)*x_size+j+2]);
+y += y + in[(i+1)*x_size+j-2] + in[(i+1)*x_size+j-1] + in[(i+1)*x_size+j] + in[(i+1)*x_size+j+1] + in[(i+1)*x_size+j+2] -
+ (in[(i-1)*x_size+j-2] + in[(i-1)*x_size+j-1] + in[(i-1)*x_size+j] + in[(i-1)*x_size+j+1] + in[(i-1)*x_size+j+2]);
+corner_list[n].dx=x/15;
+corner_list[n].dy=y/15;
+n++;
+if(n==MAX_CORNERS){
+ fprintf(stderr,"Too many corners.\n");
+ exit(1);
+ }}}}
+corner_list[n].info=7;
+}
+
+/* }}} */
+
+/* }}} */
+/* {{{ main(argc, argv) */
+
+int main(int argc, char* argv[])
+{
+/* {{{ vars */
+
+char *tcp;
+uchar *in, *bp, *mid;
+float dt=4.0;
+int *r,
+ argindex=3,
+ bt=20,
+ principle=0,
+ thin_post_proc=1,
+ three_by_three=0,
+ drawing_mode=0,
+ susan_quick=0,
+ max_no_corners=1850,
+ max_no_edges=2650,
+ mode = 0,
+ x_size, y_size;
+CORNER_LIST corner_list;
+
+/* }}} */
+
+ long ct_repeat=0;
+ long ct_repeat_max=1;
+ int ct_return=0;
+
+#ifdef OPENME
+ openme_init(NULL,NULL,NULL,0);
+ openme_callback("PROGRAM_START", NULL);
+#endif
+#ifdef XOPENME
+ xopenme_init(1,2);
+#endif
+
+ if (getenv("CT_REPEAT_MAIN")!=NULL) ct_repeat_max=atol(getenv("CT_REPEAT_MAIN"));
+
+ if (argc<3)
+ usage();
+
+ get_image(argv[1],&in,&x_size,&y_size);
+
+#ifdef XOPENME
+ xopenme_add_var_i(0, " \"image_size_x\":%u", x_size);
+ xopenme_add_var_i(1, " \"image_size_y\":%u", y_size);
+#endif
+
+// printf("Size X=%u Size Y=%u\n", x_size, y_size);
+ /* FGG - changing dataset size */
+// x_size=8;
+// y_size=8;
+// printf("Size X=%u Size Y=%u\n", x_size, y_size);
+
+ /* {{{ look at options */
+
+ while (argindex < argc)
+ {
+ tcp = argv[argindex];
+ if (*tcp == '-')
+ switch (*++tcp)
+ {
+ case 's': /* smoothing */
+ mode=0;
+ break;
+ case 'e': /* edges */
+ mode=1;
+ break;
+ case 'c': /* corners */
+ mode=2;
+ break;
+ case 'p': /* principle */
+ principle=1;
+ break;
+ case 'n': /* thinning post processing */
+ thin_post_proc=0;
+ break;
+ case 'b': /* simple drawing mode */
+ drawing_mode=1;
+ break;
+ case '3': /* 3x3 flat mask */
+ three_by_three=1;
+ break;
+ case 'q': /* quick susan mask */
+ susan_quick=1;
+ break;
+ case 'd': /* distance threshold */
+ if (++argindex >= argc){
+ printf ("No argument following -d\n");
+ exit(0);}
+ dt=atof(argv[argindex]);
+ if (dt<0) three_by_three=1;
+ break;
+ case 't': /* brightness threshold */
+ if (++argindex >= argc){
+ printf ("No argument following -t\n");
+ exit(0);}
+ bt=atoi(argv[argindex]);
+ break;
+ }
+ else
+ usage();
+ argindex++;
+ }
+
+ if ( (principle==1) && (mode==0) )
+ mode=1;
+
+/* }}} */
+ /* {{{ main processing */
+
+#ifdef OPENME
+ openme_callback("KERNEL_START", NULL);
+#endif
+#ifdef XOPENME
+ xopenme_clock_start(0);
+#endif
+
+ for (ct_repeat=0; ct_repeat
+Click if you want to use Python virtual environment
+
+We suggest you to install a python virtual environment via CM though it's not strictly necessary
+(CM can automatically detect and reuse your Python installation and environments):
+```bash
+cm run script "install python-venv" --name=loadgen
+```
+
+You can also install a specific version of Python on your system via:
+```bash
+cm run script "install python-venv" --name=loadgen --version=3.10.7
+```
+
+By default, CM will be asking users to select one from all detected and installed Python versions
+including the above one, any time a script with python dependency is run. To avoid that, you
+can set up the following environment variable with the name of the current virtual environment:
+
+```bash
+export CM_SCRIPT_EXTRA_CMD="--adr.python.name=loadgen"
+```
+
+The `--adr` flag stands for "Add to all Dependencies Recursively" and will find all sub-dependencies on other CM scripts
+
+
+
+
+### Install dependencies via CM (optional)
+
+
+Click if you want to install specific versions of dependencies
+
+You can skip this sub-section if you want CM to automatically detect already installed
+ONNX runtime on your system. Otherwise, follow the next steps to install the latest or specific
+version of ONNX runtime.
+
+
+### Download LoadGen sources from MLPerf inference benchmark
+
+```bash
+cm run script "get mlperf inference src" --version=r3.1
+```
+
+### Install MLPerf LoadGen
+We can now install loadgen via CM while forcing compiler dependency to GCC:
+
+```bash
+cm run script "get mlperf loadgen"
+```
+
+### ONNX, CPU
+
+```bash
+cm run script "get generic-python-lib _onnxruntime"
+```
+
+or
+
+```bash
+cm run script "get generic-python-lib _onnxruntime" --version=1.13.1
+```
+
+or
+
+```bash
+cm run script "get generic-python-lib _onnxruntime" --version_min=1.10.0
+```
+
+
+### Benchmark standard MLPerf model
+
+You can use CM variations prefixed by `_` to benchmark an official MLPerf model
+(_resnet50 or _retinanet):
+
+```
+cm run script "python app loadgen-generic _onnxruntime _retinanet" --samples=5
+cmr "python app loadgen-generic _onnxruntime _resnet50"
+```
+
+Normally, you should see the following performance report from the loadgen:
+
+
+
+
+
+Click to open
+
+```bash
+
+2022-12-06 16:51:39,279 INFO MainThread - __main__ main: Model: /home/gfursin/CM/repos/local/cache/9c825a0a06fb48e2/resnet50_v1.onnx
+2022-12-06 16:51:39,279 INFO MainThread - __main__ main: Runner: inline, Concurrency: 4
+2022-12-06 16:51:39,279 INFO MainThread - __main__ main: Results: results/resnet50_v1.onnx/inline
+2022-12-06 16:51:39,279 INFO MainThread - __main__ main: Test Started
+2022-12-06 16:51:39,399 INFO MainThread - loadgen.harness load_query_samples: Loaded 100 samples
+2022-12-06 16:51:55,723 INFO MainThread - loadgen.harness issue_query: Queries issued 550
+2022-12-06 16:51:55,725 INFO MainThread - loadgen.harness flush_queries: Queries flushed
+2022-12-06 16:51:55,731 INFO MainThread - loadgen.harness unload_query_samples: Unloaded samples
+================================================
+MLPerf Results Summary
+================================================
+SUT name : PySUT
+Scenario : Offline
+Mode : PerformanceOnly
+Samples per second: 33.6903
+Result is : VALID
+ Min duration satisfied : Yes
+ Min queries satisfied : Yes
+ Early stopping satisfied: Yes
+
+================================================
+Additional Stats
+================================================
+Min latency (ns) : 16325180169
+Max latency (ns) : 16325180169
+Mean latency (ns) : 16325180169
+50.00 percentile latency (ns) : 16325180169
+90.00 percentile latency (ns) : 16325180169
+95.00 percentile latency (ns) : 16325180169
+97.00 percentile latency (ns) : 16325180169
+99.00 percentile latency (ns) : 16325180169
+99.90 percentile latency (ns) : 16325180169
+
+================================================
+Test Parameters Used
+================================================
+samples_per_query : 550
+target_qps : 50
+target_latency (ns): 0
+max_async_queries : 1
+min_duration (ms): 10000
+max_duration (ms): 0
+min_query_count : 1
+max_query_count : 0
+qsl_rng_seed : 0
+sample_index_rng_seed : 0
+schedule_rng_seed : 0
+accuracy_log_rng_seed : 0
+accuracy_log_probability : 0
+accuracy_log_sampling_target : 0
+print_timestamps : 0
+performance_issue_unique : 0
+performance_issue_same : 0
+performance_issue_same_index : 0
+performance_sample_count : 100
+
+No warnings encountered during test.
+
+No errors encountered during test.
+2022-12-06 16:51:55,753 INFO MainThread - __main__ main: Observed QPS: 33.6903
+2022-12-06 16:51:55,753 INFO MainThread - __main__ main: Result: VALID
+2022-12-06 16:51:55,753 INFO MainThread - __main__ main: Test Completed
+
+ - Running postprocess ...
+ - running time of script "app,loadgen,generic,loadgen-generic,python": 370.87 sec.
+
+```
+
+
+
+
+### Benchmark custom model
+
+You can also specify any custom onnx model file as follows:
+
+```bash
+cm run script "python app loadgen-generic _onnxruntime" --modelpath=
+```
+
+### Benchmark Hugging Face model
+
+```bash
+cmr "python app loadgen-generic _onnxruntime _custom _huggingface _model-stub.ctuning/mlperf-inference-bert-onnx-fp32-squad-v1.1" --adr.hf-downloader.model_filename=model.onnx
+```
+
+*See more examples to download Hugging Face models via CM [here](../get-ml-model-huggingface-zoo/README-extra.md).*
+
+### Benchmark using ONNX CUDA
+
+```bash
+cm rm cache -f
+cmr "python app loadgen-generic _onnxruntime _cuda _retinanet" --quiet
+cmr "python app loadgen-generic _onnxruntime _cuda _custom _huggingface _model-stub.ctuning/mlperf-inference-bert-onnx-fp32-squad-v1.1" --adr.hf-downloader.model_filename=model.onnx
+```
+
+These cases worked on Windows and Linux but may require GPU with > 8GB memory:
+```bash
+cmr "python app loadgen-generic _onnxruntime _cuda _custom _huggingface _model-stub.steerapi/Llama-2-7b-chat-hf-onnx-awq-w8" --adr.hf-downloader.model_filename=onnx/decoder_model_merged_quantized.onnx,onnx/decoder_model_merged_quantized.onnx_data --samples=2
+cmr "python app loadgen-generic _onnxruntime _cuda _custom _huggingface _model-stub.alpindale/Llama-2-13b-ONNX" --adr.hf-downloader.model_filename=FP32/LlamaV2_13B_float32.onnx --adr.hf-downloader.full_subfolder=FP32 --samples=2
+cmr "python app loadgen-generic _onnxruntime _cuda _custom _huggingface _model-stub.Intel/gpt-j-6B-int8-static" --adr.hf-downloader.model_filename=model.onnx --adr.hf-downloader.full_subfolder=. --samples=2
+```
+
+TBD: some cases that are not yet fully supported (data types, input mismatch, etc):
+```bash
+cmr "python app loadgen-generic _onnxruntime _custom _huggingface _model-stub.runwayml/stable-diffusion-v1-5" --adr.hf-downloader.revision=onnx --adr.hf-downloader.model_filename=unet/model.onnx,unet/weights.pb --samples=2
+cmr "python app loadgen-generic _onnxruntime _cuda _custom _huggingface _model-stub.microsoft/Mistral-7B-v0.1-onnx" --adr.hf-downloader.model_filename=Mistral-7B-v0.1.onnx,Mistral-7B-v0.1.onnx.data --samples=2
+cmr "python app loadgen-generic _onnxruntime _cuda _custom _huggingface _model-stub.alpindale/Llama-2-7b-ONNX" --adr.hf-downloader.model_filename=FP16/LlamaV2_7B_float16.onnx --adr.hf-downloader.full_subfolder=FP16 --samples=2
+```
+
+### Other variations and flags:
+
+You can obtain help about flags and variations from CMD:
+
+```bash
+cm run script "python app loadgen-generic" --help
+
+Available variations:
+
+ _cpu
+ _cuda
+ _custom
+ _custom,huggingface
+ _huggingface
+ _model-stub.#
+ _onnxruntime
+ _pytorch
+ _resnet50
+ _retinanet
+
+Available flags mapped to environment variables:
+
+ --concurrency -> --env.CM_MLPERF_CONCURRENCY
+ --ep -> --env.CM_MLPERF_EXECUTION_PROVIDER
+ --execmode -> --env.CM_MLPERF_EXEC_MODE
+ --interop -> --env.CM_MLPERF_INTEROP
+ --intraop -> --env.CM_MLPERF_INTRAOP
+ --modelpath -> --env.CM_ML_MODEL_FILE_WITH_PATH
+ --output_dir -> --env.CM_MLPERF_OUTPUT_DIR
+ --runner -> --env.CM_MLPERF_RUNNER
+ --samples -> --env.CM_MLPERF_LOADGEN_SAMPLES
+ --scenario -> --env.CM_MLPERF_LOADGEN_SCENARIO
+
+```
+
+## Running this app via Docker
+
+```bash
+cm docker script "python app loadgen-generic _onnxruntime _custom _huggingface _model-stub.ctuning/mlperf-inference-bert-onnx-fp32-squad-v1.1" --adr.hf-downloader.model_filename=model.onnx --samples=2 --output_dir=new_results --docker_cm_repo=ctuning@mlcommons-ck
+```
+
+## Tuning CPU performance via CM experiment
+
+```bash
+cm run experiment --tags=loadgen,python,llama2 -- cmr script "python app loadgen-generic _onnxruntime _cuda _custom _huggingface _model-stub.steerapi/Llama-2-7b-chat-hf-onnx-awq-w8" --adr.hf-downloader.model_filename=onnx/decoder_model_merged_quantized.onnx,onnx/decoder_model_merged_quantized.onnx_data --samples=2 --intraop={{CM_OPT_INTRAOP{[1,2,4]}}} --interop={{CM_OPT_INTEROP{[1,2,4]}}} --quiet
+cm run experiment --tags=loadgen,python,llama2 -- cmr "python app loadgen-generic _onnxruntime" --modelpath={PATH TO ONNX MODEL} --samples=2 --intraop={{CM_OPT_INTRAOP{[1,2,4]}}} --interop={{CM_OPT_INTEROP{[1,2,4]}}} --quiet
+```
+
+
+## Developers
+
+* [Gaz Iqbal](https://www.linkedin.com/in/gaziqbal)
+* [Arjun Suresh](https://www.linkedin.com/in/arjunsuresh)
+* [Grigori Fursin](https://cKnowledge.org/gfursin)
+
+## Get in touch
+
+* [MLCommons Task Force on Automation and Reproducibility](../../../docs/taskforce.md)
+* [Public Discord server](https://discord.gg/JjWNWXKxwT)
diff --git a/script/app-loadgen-generic-python/README.md b/script/app-loadgen-generic-python/README.md
new file mode 100644
index 0000000000..443404358d
--- /dev/null
+++ b/script/app-loadgen-generic-python/README.md
@@ -0,0 +1,322 @@
+Automatically generated README for this automation recipe: **app-loadgen-generic-python**
+
+Category: **Modular MLPerf inference benchmark pipeline**
+
+License: **Apache 2.0**
+
+Developers: [Gaz Iqbal](https://www.linkedin.com/in/gaziqbal), [Arjun Suresh](https://www.linkedin.com/in/arjunsuresh), [Grigori Fursin](https://cKnowledge.org/gfursin)
+
+---
+*[ [Online info and GUI to run this CM script](https://access.cknowledge.org/playground/?action=scripts&name=app-loadgen-generic-python,d3d949cc361747a6) ] [ [Notes from the authors, contributors and users](README-extra.md) ]*
+
+---
+#### Summary
+
+* CM GitHub repository: *[mlcommons@ck](https://github.com/mlcommons/ck/tree/dev/cm-mlops)*
+* GitHub directory for this script: *[GitHub](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-loadgen-generic-python)*
+* CM meta description for this script: *[_cm.yaml](_cm.yaml)*
+* All CM tags to find and reuse this script (see in above meta description): *python,app,generic,loadgen*
+* Output cached? *False*
+* See [pipeline of dependencies](#dependencies-on-other-cm-scripts) on other CM scripts
+
+
+---
+### Reuse this script in your project
+
+#### Install MLCommons CM automation meta-framework
+
+* [Install CM](https://access.cknowledge.org/playground/?action=install)
+* [CM Getting Started Guide](https://github.com/mlcommons/ck/blob/master/docs/getting-started.md)
+
+#### Pull CM repository with this automation recipe (CM script)
+
+```cm pull repo mlcommons@ck```
+
+#### Print CM help from the command line
+
+````cmr "python app generic loadgen" --help````
+
+#### Customize and run this script from the command line with different variations and flags
+
+`cm run script --tags=python,app,generic,loadgen`
+
+`cm run script --tags=python,app,generic,loadgen[,variations] [--input_flags]`
+
+*or*
+
+`cmr "python app generic loadgen"`
+
+`cmr "python app generic loadgen [variations]" [--input_flags]`
+
+
+* *See the list of `variations` [here](#variations) and check the [Gettings Started Guide](https://github.com/mlcommons/ck/blob/dev/docs/getting-started.md) for more details.*
+
+
+#### Input Flags
+
+* --**modelpath**=Full path to file with model weights
+* --**modelcodepath**=(for PyTorch models) Full path to file with model code and cmc.py
+* --**modelcfgpath**=(for PyTorch models) Full path to JSON file with model cfg
+* --**modelsamplepath**=(for PyTorch models) Full path to file with model sample in pickle format
+* --**ep**=ONNX Execution provider
+* --**scenario**=MLPerf LoadGen scenario
+* --**samples**=Number of samples (*2*)
+* --**runner**=MLPerf runner
+* --**execmode**=MLPerf exec mode
+* --**output_dir**=MLPerf output directory
+* --**concurrency**=MLPerf concurrency
+* --**intraop**=MLPerf intra op threads
+* --**interop**=MLPerf inter op threads
+
+**Above CLI flags can be used in the Python CM API as follows:**
+
+```python
+r=cm.access({... , "modelpath":...}
+```
+#### Run this script from Python
+
+
+Click here to expand this section.
+
+```python
+
+import cmind
+
+r = cmind.access({'action':'run'
+ 'automation':'script',
+ 'tags':'python,app,generic,loadgen'
+ 'out':'con',
+ ...
+ (other input keys for this script)
+ ...
+ })
+
+if r['return']>0:
+ print (r['error'])
+
+```
+
+
+
+
+#### Run this script via GUI
+
+```cmr "cm gui" --script="python,app,generic,loadgen"```
+
+Use this [online GUI](https://cKnowledge.org/cm-gui/?tags=python,app,generic,loadgen) to generate CM CMD.
+
+#### Run this script via Docker (beta)
+
+`cm docker script "python app generic loadgen[variations]" [--input_flags]`
+
+___
+### Customization
+
+
+#### Variations
+
+ * *No group (any variation can be selected)*
+
+ Click here to expand this section.
+
+ * `_cmc`
+ - Environment variables:
+ - *CM_CUSTOM_MODEL_CMC*: `True`
+ - Workflow:
+ * `_custom,cmc`
+ - Workflow:
+ 1. ***Read "deps" on other CM scripts***
+ * get,ml-model,cmc
+ - *Warning: no scripts found*
+ * `_custom,huggingface`
+ - Workflow:
+ 1. ***Read "deps" on other CM scripts***
+ * get,ml-model,huggingface
+ * CM names: `--adr.['hf-downloader']...`
+ - CM script: [get-ml-model-huggingface-zoo](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-ml-model-huggingface-zoo)
+ * `_huggingface`
+ - Environment variables:
+ - *CM_CUSTOM_MODEL_SOURCE*: `huggingface`
+ - Workflow:
+ * `_model-stub.#`
+ - Environment variables:
+ - *CM_ML_MODEL_STUB*: `#`
+ - Workflow:
+
+
+
+
+ * Group "**backend**"
+
+ Click here to expand this section.
+
+ * **`_onnxruntime`** (default)
+ - Environment variables:
+ - *CM_MLPERF_BACKEND*: `onnxruntime`
+ - Workflow:
+ * `_pytorch`
+ - Environment variables:
+ - *CM_MLPERF_BACKEND*: `pytorch`
+ - Workflow:
+
+
+
+
+ * Group "**device**"
+
+ Click here to expand this section.
+
+ * **`_cpu`** (default)
+ - Environment variables:
+ - *CM_MLPERF_DEVICE*: `cpu`
+ - *CM_MLPERF_EXECUTION_PROVIDER*: `CPUExecutionProvider`
+ - Workflow:
+ * `_cuda`
+ - Environment variables:
+ - *CM_MLPERF_DEVICE*: `gpu`
+ - *CM_MLPERF_EXECUTION_PROVIDER*: `CUDAExecutionProvider`
+ - Workflow:
+
+
+
+
+ * Group "**models**"
+
+ Click here to expand this section.
+
+ * `_custom`
+ - Environment variables:
+ - *CM_MODEL*: `custom`
+ - Workflow:
+ * `_resnet50`
+ - Environment variables:
+ - *CM_MODEL*: `resnet50`
+ - Workflow:
+ * `_retinanet`
+ - Environment variables:
+ - *CM_MODEL*: `retinanet`
+ - Workflow:
+
+
+
+
+#### Default variations
+
+`_cpu,_onnxruntime`
+
+#### Script flags mapped to environment
+
+Click here to expand this section.
+
+* `--concurrency=value` → `CM_MLPERF_CONCURRENCY=value`
+* `--ep=value` → `CM_MLPERF_EXECUTION_PROVIDER=value`
+* `--execmode=value` → `CM_MLPERF_EXEC_MODE=value`
+* `--interop=value` → `CM_MLPERF_INTEROP=value`
+* `--intraop=value` → `CM_MLPERF_INTRAOP=value`
+* `--loadgen_duration_sec=value` → `CM_MLPERF_LOADGEN_DURATION_SEC=value`
+* `--loadgen_expected_qps=value` → `CM_MLPERF_LOADGEN_EXPECTED_QPS=value`
+* `--modelcfg=value` → `CM_ML_MODEL_CFG=value`
+* `--modelcfgpath=value` → `CM_ML_MODEL_CFG_WITH_PATH=value`
+* `--modelcodepath=value` → `CM_ML_MODEL_CODE_WITH_PATH=value`
+* `--modelpath=value` → `CM_ML_MODEL_FILE_WITH_PATH=value`
+* `--modelsamplepath=value` → `CM_ML_MODEL_SAMPLE_WITH_PATH=value`
+* `--output_dir=value` → `CM_MLPERF_OUTPUT_DIR=value`
+* `--runner=value` → `CM_MLPERF_RUNNER=value`
+* `--samples=value` → `CM_MLPERF_LOADGEN_SAMPLES=value`
+* `--scenario=value` → `CM_MLPERF_LOADGEN_SCENARIO=value`
+
+**Above CLI flags can be used in the Python CM API as follows:**
+
+```python
+r=cm.access({... , "concurrency":...}
+```
+
+
+
+#### Default environment
+
+
+Click here to expand this section.
+
+These keys can be updated via `--env.KEY=VALUE` or `env` dictionary in `@input.json` or using script flags.
+
+* CM_MLPERF_EXECUTION_MODE: `parallel`
+* CM_MLPERF_BACKEND: `onnxruntime`
+
+
+
+___
+### Dependencies on other CM scripts
+
+
+ 1. ***Read "deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-loadgen-generic-python/_cm.yaml)***
+ * detect,os
+ - CM script: [detect-os](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/detect-os)
+ * detect,cpu
+ - CM script: [detect-cpu](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/detect-cpu)
+ * get,python3
+ * CM names: `--adr.['python', 'python3']...`
+ - CM script: [get-python3](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-python3)
+ * get,generic-python-lib,_psutil
+ - CM script: [get-generic-python-lib](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-generic-python-lib)
+ * get,generic-python-lib,_package.numpy
+ - CM script: [get-generic-python-lib](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-generic-python-lib)
+ * get,cuda
+ * `if (CM_MLPERF_DEVICE == gpu)`
+ - CM script: [get-cuda](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-cuda)
+ * get,loadgen
+ * CM names: `--adr.['loadgen']...`
+ - CM script: [get-mlperf-inference-loadgen](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-mlperf-inference-loadgen)
+ * get,generic-python-lib,_onnxruntime
+ * `if (CM_MLPERF_BACKEND == onnxruntime AND CM_MLPERF_DEVICE == cpu)`
+ * CM names: `--adr.['onnxruntime']...`
+ - CM script: [get-generic-python-lib](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-generic-python-lib)
+ * get,generic-python-lib,_onnxruntime_gpu
+ * `if (CM_MLPERF_BACKEND == onnxruntime AND CM_MLPERF_DEVICE == gpu)`
+ * CM names: `--adr.['onnxruntime']...`
+ - CM script: [get-generic-python-lib](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-generic-python-lib)
+ * get,generic-python-lib,_onnx
+ * `if (CM_MLPERF_BACKEND == onnxruntime)`
+ * CM names: `--adr.['onnx']...`
+ - CM script: [get-generic-python-lib](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-generic-python-lib)
+ * get,generic-python-lib,_torch
+ * `if (CM_MLPERF_BACKEND == pytorch AND CM_MLPERF_DEVICE == cpu)`
+ * CM names: `--adr.['torch']...`
+ - CM script: [get-generic-python-lib](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-generic-python-lib)
+ * get,generic-python-lib,_torchvision
+ * `if (CM_MLPERF_BACKEND == pytorch AND CM_MLPERF_DEVICE == cpu)`
+ * CM names: `--adr.['torchvision']...`
+ - CM script: [get-generic-python-lib](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-generic-python-lib)
+ * get,generic-python-lib,_torch_cuda
+ * `if (CM_MLPERF_BACKEND == pytorch AND CM_MLPERF_DEVICE == gpu)`
+ * CM names: `--adr.['torch']...`
+ - CM script: [get-generic-python-lib](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-generic-python-lib)
+ * get,generic-python-lib,_torchvision_cuda
+ * `if (CM_MLPERF_BACKEND == pytorch AND CM_MLPERF_DEVICE == gpu)`
+ * CM names: `--adr.['torchvision']...`
+ - CM script: [get-generic-python-lib](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-generic-python-lib)
+ * get,ml-model,resnet50,_onnx
+ * `if (CM_MODEL == resnet50)`
+ - CM script: [get-ml-model-resnet50](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-ml-model-resnet50)
+ * get,ml-model,retinanet,_onnx,_fp32
+ * `if (CM_MODEL == retinanet)`
+ - CM script: [get-ml-model-retinanet](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-ml-model-retinanet)
+ * get,ml-model,retinanet,_onnx,_fp32
+ * `if (CM_MODEL == retinanet)`
+ - CM script: [get-ml-model-retinanet](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-ml-model-retinanet)
+ 1. ***Run "preprocess" function from [customize.py](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-loadgen-generic-python/customize.py)***
+ 1. Read "prehook_deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-loadgen-generic-python/_cm.yaml)
+ 1. ***Run native script if exists***
+ * [run.bat](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-loadgen-generic-python/run.bat)
+ * [run.sh](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-loadgen-generic-python/run.sh)
+ 1. Read "posthook_deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-loadgen-generic-python/_cm.yaml)
+ 1. ***Run "postrocess" function from [customize.py](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-loadgen-generic-python/customize.py)***
+ 1. Read "post_deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-loadgen-generic-python/_cm.yaml)
+
+___
+### Script output
+`cmr "python app generic loadgen [,variations]" [--input_flags] -j`
+#### New environment keys (filter)
+
+* `CM_MLPERF_*`
+#### New environment keys auto-detected from customize
diff --git a/script/app-loadgen-generic-python/_cm.yaml b/script/app-loadgen-generic-python/_cm.yaml
new file mode 100644
index 0000000000..08b63927ff
--- /dev/null
+++ b/script/app-loadgen-generic-python/_cm.yaml
@@ -0,0 +1,322 @@
+# Identification of this CM script
+alias: app-loadgen-generic-python
+uid: d3d949cc361747a6
+
+automation_alias: script
+automation_uid: 5b4e0237da074764
+
+category: "Modular MLPerf inference benchmark pipeline"
+
+developers: "[Gaz Iqbal](https://www.linkedin.com/in/gaziqbal), [Arjun Suresh](https://www.linkedin.com/in/arjunsuresh), [Grigori Fursin](https://cKnowledge.org/gfursin)"
+
+
+# User-friendly tags to find this CM script
+tags:
+ - app
+ - loadgen
+ - generic
+ - loadgen-generic
+ - python
+
+tags_help: "python app generic loadgen"
+
+
+# Default environment
+default_env:
+ CM_MLPERF_EXECUTION_MODE: parallel
+ CM_MLPERF_BACKEND: onnxruntime
+
+# Map script inputs to environment variables
+input_mapping:
+ modelpath: CM_ML_MODEL_FILE_WITH_PATH
+ modelcodepath: CM_ML_MODEL_CODE_WITH_PATH
+ modelcfgpath: CM_ML_MODEL_CFG_WITH_PATH
+ modelcfg: CM_ML_MODEL_CFG
+ modelsamplepath: CM_ML_MODEL_SAMPLE_WITH_PATH
+ output_dir: CM_MLPERF_OUTPUT_DIR
+ scenario: CM_MLPERF_LOADGEN_SCENARIO
+ runner: CM_MLPERF_RUNNER
+ concurrency: CM_MLPERF_CONCURRENCY
+ ep: CM_MLPERF_EXECUTION_PROVIDER
+ intraop: CM_MLPERF_INTRAOP
+ interop: CM_MLPERF_INTEROP
+ execmode: CM_MLPERF_EXEC_MODE
+ samples: CM_MLPERF_LOADGEN_SAMPLES
+ loadgen_expected_qps: CM_MLPERF_LOADGEN_EXPECTED_QPS
+ loadgen_duration_sec: CM_MLPERF_LOADGEN_DURATION_SEC
+
+# New env keys exported from this script
+new_env_keys:
+ - CM_MLPERF_*
+
+# Dependencies on other CM scripts
+
+deps:
+
+ # Detect host OS features
+ - tags: detect,os
+
+ # Detect host CPU features
+ - tags: detect,cpu
+
+ # Get Python
+ - tags: get,python3
+ names:
+ - python
+ - python3
+
+ # Extra package
+ - tags: get,generic-python-lib,_psutil
+ - tags: get,generic-python-lib,_package.numpy
+
+ # Detect CUDA if required
+ - tags: get,cuda
+ enable_if_env:
+ CM_MLPERF_DEVICE:
+ - gpu
+
+ # Install loadgen
+ - tags: get,loadgen
+ names:
+ - loadgen
+
+ ########################################################################
+ # Install ML engines via CM
+ # ONNX
+ - enable_if_env:
+ CM_MLPERF_BACKEND:
+ - onnxruntime
+ CM_MLPERF_DEVICE:
+ - cpu
+ tags: get,generic-python-lib,_onnxruntime
+ names:
+ - onnxruntime
+
+ - enable_if_env:
+ CM_MLPERF_BACKEND:
+ - onnxruntime
+ CM_MLPERF_DEVICE:
+ - gpu
+ tags: get,generic-python-lib,_onnxruntime_gpu
+ names:
+ - onnxruntime
+
+ - enable_if_env:
+ CM_MLPERF_BACKEND:
+ - onnxruntime
+ tags: get,generic-python-lib,_onnx
+ names:
+ - onnx
+
+ ########################################################################
+ # Install ML engines via CM
+ # PyTorch
+
+ # CPU
+
+ - enable_if_env:
+ CM_MLPERF_BACKEND:
+ - pytorch
+ CM_MLPERF_DEVICE:
+ - cpu
+ tags: get,generic-python-lib,_torch
+ names:
+ - torch
+
+ - enable_if_env:
+ CM_MLPERF_BACKEND:
+ - pytorch
+ CM_MLPERF_DEVICE:
+ - cpu
+ tags: get,generic-python-lib,_torchvision
+ names:
+ - torchvision
+
+ # CUDA/GPU
+
+ - enable_if_env:
+ CM_MLPERF_BACKEND:
+ - pytorch
+ CM_MLPERF_DEVICE:
+ - gpu
+ tags: get,generic-python-lib,_torch_cuda
+ names:
+ - torch
+
+ - enable_if_env:
+ CM_MLPERF_BACKEND:
+ - pytorch
+ CM_MLPERF_DEVICE:
+ - gpu
+ tags: get,generic-python-lib,_torchvision_cuda
+ names:
+ - torchvision
+
+
+
+ ########################################################################
+ # Install MLPerf models
+ - enable_if_env:
+ CM_MODEL:
+ - resnet50
+ tags: get,ml-model,resnet50,_onnx
+
+ - enable_if_env:
+ CM_MODEL:
+ - retinanet
+ tags: get,ml-model,retinanet,_onnx,_fp32
+
+ - enable_if_env:
+ CM_MODEL:
+ - retinanet
+ tags: get,ml-model,retinanet,_onnx,_fp32
+
+
+
+
+# Customize this CM script
+variations:
+
+ pytorch:
+ group: backend
+ env:
+ CM_MLPERF_BACKEND:
+ pytorch
+
+ onnxruntime:
+ group: backend
+ default: true
+ env:
+ CM_MLPERF_BACKEND:
+ onnxruntime
+
+
+
+ cpu:
+ group:
+ device
+ default:
+ true
+ env:
+ CM_MLPERF_DEVICE:
+ cpu
+ CM_MLPERF_EXECUTION_PROVIDER:
+ CPUExecutionProvider
+
+ cuda:
+ docker:
+ all_gpus: 'yes'
+ base_image: nvcr.io/nvidia/pytorch:24.03-py3
+ group:
+ device
+ env:
+ CM_MLPERF_DEVICE:
+ gpu
+ CM_MLPERF_EXECUTION_PROVIDER:
+ CUDAExecutionProvider
+
+
+
+ retinanet:
+ group:
+ models
+ env:
+ CM_MODEL: retinanet
+
+ resnet50:
+ group:
+ models
+ env:
+ CM_MODEL: resnet50
+
+ custom:
+ group:
+ models
+ env:
+ CM_MODEL: custom
+
+
+
+ huggingface:
+ env:
+ CM_CUSTOM_MODEL_SOURCE: huggingface
+
+ custom,huggingface:
+ deps:
+ - tags: get,ml-model,huggingface
+ names:
+ - hf-downloader
+ update_tags_from_env_with_prefix:
+ "_model-stub.":
+ - CM_ML_MODEL_STUB
+
+ model-stub.#:
+ env:
+ CM_ML_MODEL_STUB: "#"
+
+
+ cmc:
+ env:
+ CM_CUSTOM_MODEL_CMC: yes
+
+
+ custom,cmc:
+ deps:
+ - tags: get,ml-model,cmc
+ names:
+ - cmc-model
+
+
+input_description:
+ modelpath:
+ desc: Full path to file with model weights
+ modelcodepath:
+ desc: (for PyTorch models) Full path to file with model code and cmc.py
+ modelcfgpath:
+ desc: (for PyTorch models) Full path to JSON file with model cfg
+ modelsamplepath:
+ desc: (for PyTorch models) Full path to file with model sample in pickle format
+ ep:
+ desc: ONNX Execution provider
+ scenario:
+ desc: MLPerf LoadGen scenario
+ samples:
+ desc: Number of samples
+ default: 2
+ runner:
+ desc: MLPerf runner
+ execmode:
+ desc: MLPerf exec mode
+ output_dir:
+ desc: MLPerf output directory
+ concurrency:
+ desc: MLPerf concurrency
+ intraop:
+ desc: MLPerf intra op threads
+ interop:
+ desc: MLPerf inter op threads
+
+
+docker:
+ skip_run_cmd: 'no'
+ input_paths:
+ - modelpath
+ - modelsamplepath
+ - env.CM_ML_MODEL_FILE_WITH_PATH
+ - env.CM_ML_MODEL_CODE_WITH_PATH
+ - output_dir
+ skip_input_for_fake_run:
+ - modelpath
+ - modelsamplepath
+ - env.CM_ML_MODEL_FILE_WITH_PATH
+ - env.CM_ML_MODEL_CODE_WITH_PATH
+ - output_dir
+ - scenario
+ - runner
+ - concurrency
+ - intraop
+ - interop
+ - execmode
+ - samples
+ - modelcfg.num_classes
+ - modelcfg.config
diff --git a/script/app-loadgen-generic-python/customize.py b/script/app-loadgen-generic-python/customize.py
new file mode 100644
index 0000000000..c8810dcd7b
--- /dev/null
+++ b/script/app-loadgen-generic-python/customize.py
@@ -0,0 +1,101 @@
+# Developer: Grigori Fursin
+
+from cmind import utils
+import os
+import shutil
+
+def preprocess(i):
+
+ os_info = i['os_info']
+
+ env = i['env']
+
+
+ if 'CM_ML_MODEL_FILE_WITH_PATH' not in env:
+ return {'return': 1, 'error': 'Please select a variation specifying the model to run'}
+
+ run_opts = env.get('CM_RUN_OPTS', '')
+
+ if env.get('CM_MLPERF_BACKEND', '') != '':
+ run_opts +=" -b "+env['CM_MLPERF_BACKEND']
+
+ if env.get('CM_MLPERF_RUNNER', '') != '':
+ run_opts +=" -r "+env['CM_MLPERF_RUNNER']
+
+ if env.get('CM_MLPERF_CONCURRENCY', '') != '':
+ run_opts +=" --concurrency "+env['CM_MLPERF_CONCURRENCY']
+
+ if env.get('CM_MLPERF_EXECUTION_PROVIDER', '') != '':
+ run_opts +=" --ep "+env['CM_MLPERF_EXECUTION_PROVIDER']
+
+ if env.get('CM_MLPERF_INTRAOP', '') != '':
+ run_opts +=" --intraop "+env['CM_MLPERF_INTRAOP']
+
+ if env.get('CM_MLPERF_INTEROP', '') != '':
+ run_opts +=" --interop "+env['CM_MLPERF_INTEROP']
+
+ if env.get('CM_MLPERF_EXECMODE', '') != '':
+ run_opts +=" --execmode "+env['CM_MLPERF_EXECUTION_MODE']
+
+ if env.get('CM_MLPERF_LOADGEN_SAMPLES', '') != '':
+ run_opts +=" --samples "+env['CM_MLPERF_LOADGEN_SAMPLES']
+
+ if env.get('CM_MLPERF_LOADGEN_EXPECTED_QPS', '') != '':
+ run_opts +=" --loadgen_expected_qps "+env['CM_MLPERF_LOADGEN_EXPECTED_QPS']
+
+ if env.get('CM_MLPERF_LOADGEN_DURATION_SEC', '') != '':
+ run_opts +=" --loadgen_duration_sec "+env['CM_MLPERF_LOADGEN_DURATION_SEC']
+
+ if env.get('CM_MLPERF_OUTPUT_DIR', '') != '':
+ run_opts +=" --output "+env['CM_MLPERF_OUTPUT_DIR']
+
+ if env.get('CM_ML_MODEL_CODE_WITH_PATH', '') != '':
+ run_opts +=" --model_code "+env['CM_ML_MODEL_CODE_WITH_PATH']
+
+
+ if env.get('CM_ML_MODEL_CFG_WITH_PATH', '') != '':
+ run_opts +=" --model_cfg "+env['CM_ML_MODEL_CFG_WITH_PATH']
+ else:
+ # Check cfg from command line
+ cfg = env.get('CM_ML_MODEL_CFG', {})
+ if len(cfg)>0:
+ del (env['CM_ML_MODEL_CFG'])
+
+ import json, tempfile
+ tfile = tempfile.NamedTemporaryFile(mode="w+", suffix='.json')
+
+ fd, tfile = tempfile.mkstemp(suffix='.json', prefix='cm-cfg-')
+ os.close(fd)
+
+ with open(tfile, 'w') as fd:
+ json.dump(cfg, fd)
+
+ env['CM_APP_LOADGEN_GENERIC_PYTHON_TMP_CFG_FILE'] = tfile
+
+ run_opts +=" --model_cfg " + tfile
+
+ if env.get('CM_ML_MODEL_SAMPLE_WITH_PATH', '') != '':
+ run_opts +=" --model_sample_pickle "+env['CM_ML_MODEL_SAMPLE_WITH_PATH']
+
+ # Add path to file model weights at the end of command line
+
+ run_opts += ' '+env['CM_ML_MODEL_FILE_WITH_PATH']
+
+ env['CM_RUN_OPTS'] = run_opts
+
+ print ('')
+ print ('Assembled flags: {}'.format(run_opts))
+ print ('')
+
+ return {'return':0}
+
+def postprocess(i):
+
+ env = i['env']
+
+ tfile = env.get('CM_APP_LOADGEN_GENERIC_PYTHON_TMP_CFG_FILE', '')
+
+ if tfile!='' and os.path.isfile(tfile):
+ os.remove(tfile)
+
+ return {'return':0}
diff --git a/script/app-loadgen-generic-python/run.bat b/script/app-loadgen-generic-python/run.bat
new file mode 100644
index 0000000000..3d4b5d58b3
--- /dev/null
+++ b/script/app-loadgen-generic-python/run.bat
@@ -0,0 +1,4 @@
+rem native script
+
+%CM_PYTHON_BIN_WITH_PATH% %CM_TMP_CURRENT_SCRIPT_PATH%\src\main.py %CM_RUN_OPTS%
+IF %ERRORLEVEL% NEQ 0 EXIT %ERRORLEVEL%
diff --git a/script/app-loadgen-generic-python/run.sh b/script/app-loadgen-generic-python/run.sh
new file mode 100644
index 0000000000..2a13312f07
--- /dev/null
+++ b/script/app-loadgen-generic-python/run.sh
@@ -0,0 +1,4 @@
+#!/bin/bash
+
+${CM_PYTHON_BIN_WITH_PATH} ${CM_TMP_CURRENT_SCRIPT_PATH}/src/main.py ${CM_RUN_OPTS}
+test $? -eq 0 || exit 1
diff --git a/script/app-loadgen-generic-python/src/backend_onnxruntime.py b/script/app-loadgen-generic-python/src/backend_onnxruntime.py
new file mode 100644
index 0000000000..e95e467b9f
--- /dev/null
+++ b/script/app-loadgen-generic-python/src/backend_onnxruntime.py
@@ -0,0 +1,89 @@
+import typing
+
+import numpy as np
+import onnx
+import onnxruntime as ort
+
+from loadgen.model import Model, ModelFactory, ModelInput, ModelInputSampler
+
+xinput = input
+
+ONNX_TO_NP_TYPE_MAP = {
+ "tensor(bool)": bool,
+ "tensor(int)": np.int32,
+ "tensor(int32)": np.int32,
+ "tensor(int8)": np.int8,
+ "tensor(uint8)": np.uint8,
+ "tensor(int16)": np.int16,
+ "tensor(uint16)": np.uint16,
+ "tensor(uint64)": np.uint64,
+ "tensor(int64)": np.int64,
+ "tensor(float16)": np.float16,
+ "tensor(float)": np.float32,
+ "tensor(double)": np.float64,
+ "tensor(string)": np.string_,
+}
+
+
+class XModel(Model):
+ def __init__(self, session: ort.InferenceSession):
+ assert session is not None
+ self.session = session
+
+ def predict(self, input: ModelInput):
+ output = self.session.run(None, input)
+ return output
+
+
+class XModelFactory(ModelFactory):
+ def __init__(
+ self,
+ model_path: str,
+ execution_provider="CPUExecutionProvider",
+ execution_mode="",
+ intra_op_threads=0,
+ inter_op_threads=0,
+ model_code='', # Not used here
+ model_cfg={}, # Not used here
+ model_sample_pickle='' # Not used here
+ ):
+ self.model_path = model_path
+ self.execution_provider = execution_provider
+ self.session_options = ort.SessionOptions()
+ if execution_mode.lower() == "sequential":
+ self.session_options.execution_mode = ort.ExecutionMode.ORT_SEQUENTIAL
+ elif execution_mode.lower() == "parallel":
+ self.session_options.execution_mode = ort.ExecutionMode.ORT_PARALLEL
+ self.session_options.intra_op_num_threads = intra_op_threads
+ self.session_options.inter_op_num_threads = inter_op_threads
+
+ def create(self) -> Model:
+ print ('Loading model: {}'.format(self.model_path))
+# model = onnx.load(self.model_path)
+ session_eps = [self.execution_provider]
+ session = ort.InferenceSession(
+# model.SerializeToString(), self.session_options, providers=session_eps
+ self.model_path, self.session_options, providers=session_eps
+ )
+ return XModel(session)
+
+
+class XModelInputSampler(ModelInputSampler):
+ def __init__(self, model_factory: XModelFactory):
+ model = model_factory.create()
+ input_defs = model.session.get_inputs()
+ self.inputs: typing.Dict[str, typing.Tuple[np.dtype, typing.List[int]]] = dict()
+ for input in input_defs:
+ input_name = input.name
+ input_type = ONNX_TO_NP_TYPE_MAP[input.type]
+ input_dim = [
+ 1 if (x is None or (type(x) is str)) else x for x in input.shape
+ ]
+ self.inputs[input_name] = (input_type, input_dim)
+
+ def sample(self, id_: int) -> ModelInput:
+ input = dict()
+ for name, spec in self.inputs.items():
+ val = np.random.random_sample(spec[1]).astype(spec[0])
+ input[name] = val
+ return input
diff --git a/script/app-loadgen-generic-python/src/backend_pytorch.py b/script/app-loadgen-generic-python/src/backend_pytorch.py
new file mode 100644
index 0000000000..1fef350b44
--- /dev/null
+++ b/script/app-loadgen-generic-python/src/backend_pytorch.py
@@ -0,0 +1,126 @@
+# Developer: Grigori Fursin
+
+import typing
+import importlib
+import os
+import psutil
+
+import utils
+
+import numpy as np
+
+import torch
+
+from loadgen.model import Model, ModelFactory, ModelInput, ModelInputSampler
+
+
+xinput = input
+
+class XModel(Model):
+ def __init__(self, session):
+ assert session is not None
+ self.session = session
+
+ def predict(self, input: ModelInput):
+
+ print ('')
+ utils.print_host_memory_use('Host memory used')
+
+ print ('Running inference ...')
+ with torch.no_grad():
+ output = self.session(input)
+
+ utils.print_host_memory_use('Host memory used')
+
+ return output
+
+
+class XModelFactory(ModelFactory):
+ def __init__(
+ self,
+ model_path: str,
+ execution_provider="CPUExecutionProvider",
+ execution_mode="",
+ intra_op_threads=0,
+ inter_op_threads=0,
+ model_code='',
+ model_cfg={},
+ model_sample_pickle=''
+ ):
+
+ self.model_path = model_path
+ self.model_code = model_code
+ self.model_cfg = model_cfg
+ self.model_sample_pickle = model_sample_pickle
+ self.execution_provider = execution_provider
+
+
+ def create(self) -> Model:
+ print ('')
+ print ('Loading model: {}'.format(self.model_path))
+
+ if self.execution_provider == 'CPUExecutionProvider':
+ torch_provider = 'cpu'
+ elif self.execution_provider == 'CUDAExecutionProvider':
+ torch_provider = 'cuda'
+ if not torch.cuda.is_available():
+ raise Exception('Error: CUDA is forced but not available or installed in PyTorch!')
+ else:
+ raise Exception('Error: execution provider is unknown ({})!'.format(self.execution_provider))
+
+ checkpoint = torch.load(self.model_path, map_location=torch.device(torch_provider))
+
+ if self.model_code == '':
+ raise Exception('Error: path to model code was not provided!')
+
+ if self.model_sample_pickle == '':
+ raise Exception('Error: path to model sample pickle was not provided!')
+
+ # Load sample
+ import pickle
+ with open (self.model_sample_pickle, 'rb') as handle:
+ self.input_sample = pickle.load(handle)
+
+ # Check if has CM connector
+ cm_model_module = os.path.join(self.model_code, 'cmc.py')
+ if not os.path.isfile(cm_model_module):
+ raise Exception('cm.py interface for a PyTorch model was not found in {}'.format(self.model_code))
+
+ print ('')
+ print ('Collective Mind Connector for the model found: {}'.format(cm_model_module))
+
+
+ # Load CM interface for the model
+ import sys
+ sys.path.insert(0, self.model_code)
+ model_module=importlib.import_module('cmc')
+ del(sys.path[0])
+
+ # Init model
+ if len(self.model_cfg)>0:
+ print ('Model cfg: {}'.format(self.model_cfg))
+
+ r = model_module.model_init(checkpoint, self.model_cfg)
+ if r['return']>0:
+ raise Exception('Error: {}'.format(r['error']))
+
+ model = r['model']
+
+ if torch_provider=='cuda':
+ model.cuda()
+
+ model.eval()
+
+ return XModel(model)
+
+
+class XModelInputSampler(ModelInputSampler):
+ def __init__(self, model_factory: XModelFactory):
+ model = model_factory.create()
+ self.input_sample = model_factory.input_sample
+ return
+
+ def sample(self, id_: int) -> ModelInput:
+ input = self.input_sample
+ return input
+
diff --git a/script/app-loadgen-generic-python/src/loadgen/harness.py b/script/app-loadgen-generic-python/src/loadgen/harness.py
new file mode 100644
index 0000000000..69edd2ba95
--- /dev/null
+++ b/script/app-loadgen-generic-python/src/loadgen/harness.py
@@ -0,0 +1,76 @@
+import abc
+import contextlib
+import logging
+import typing
+
+import mlperf_loadgen
+
+from loadgen.model import ModelInput, ModelInputSampler
+
+logger = logging.getLogger(__name__)
+
+
+QueryInput = typing.Dict[int, ModelInput]
+QueryResult = typing.Dict[int, typing.Any]
+
+
+class ModelRunner(contextlib.AbstractContextManager):
+ @abc.abstractmethod
+ def issue_query(self, query: QueryInput) -> typing.Optional[QueryResult]:
+ pass
+
+ # Optional method to flush pending queries
+ def flush_queries(self) -> typing.Optional[QueryResult]:
+ pass
+
+ def __exit__(self, _exc_type, _exc_value, _traceback):
+ logger.info(f"{self} : Exited")
+ return None
+
+
+class Harness:
+ def __init__(self, sampler: ModelInputSampler, runner: ModelRunner):
+ self.sampler = sampler
+ self.runner = runner
+ self.samples = None
+
+ def load_query_samples(self, query_samples):
+ assert self.samples is None
+ self.samples = dict()
+ for query_id in query_samples:
+ self.samples[query_id] = self.sampler.sample(query_id)
+ logger.info(f"Loaded {len(self.samples)} samples")
+
+ def unload_query_samples(self, _query_samples):
+ assert self.samples is not None
+ logger.info(f"Unloaded samples")
+ self.samples = None
+
+ def issue_query(self, query_samples):
+ query_input = dict()
+ for q in query_samples:
+ # logger.info(f"Query Id: {q.id}, SampleIndex: {q.index}")
+ input = self.samples[q.index]
+ query_input[q.id] = input
+ result = self.runner.issue_query(query_input)
+ logger.info(f"Queries issued {len(query_input)}")
+ if result is not None:
+ self._complete_query(result)
+
+ # Called after the last call to issue queries in a series is made.
+ # Client can use this to flush any deferred queries rather than waiting for a timeout.
+ def flush_queries(self):
+ result = self.runner.flush_queries()
+ logger.info(f"Queries flushed")
+ if result is not None:
+ self._complete_query(result)
+
+ def _complete_query(self, result: QueryResult):
+ responses = []
+ for query_id, _query_result in result.items():
+ response_data, response_size = 0, 0
+ response = mlperf_loadgen.QuerySampleResponse(
+ query_id, response_data, response_size
+ )
+ responses.append(response)
+ mlperf_loadgen.QuerySamplesComplete(responses)
diff --git a/script/app-loadgen-generic-python/src/loadgen/model.py b/script/app-loadgen-generic-python/src/loadgen/model.py
new file mode 100644
index 0000000000..8bb7dbf04c
--- /dev/null
+++ b/script/app-loadgen-generic-python/src/loadgen/model.py
@@ -0,0 +1,24 @@
+import abc
+import typing
+
+import numpy as np
+
+ModelInput = typing.Dict[str, np.array]
+
+
+class Model(abc.ABC):
+ @abc.abstractmethod
+ def predict(self, input: ModelInput) -> typing.Any:
+ pass
+
+
+class ModelFactory(abc.ABC):
+ @abc.abstractmethod
+ def create(self) -> Model:
+ pass
+
+
+class ModelInputSampler(abc.ABC):
+ @abc.abstractmethod
+ def sample(self, id: int) -> ModelInput:
+ pass
diff --git a/script/app-loadgen-generic-python/src/loadgen/runners.py b/script/app-loadgen-generic-python/src/loadgen/runners.py
new file mode 100644
index 0000000000..1b78acba15
--- /dev/null
+++ b/script/app-loadgen-generic-python/src/loadgen/runners.py
@@ -0,0 +1,186 @@
+import abc
+import concurrent.futures
+import logging
+import multiprocessing
+import threading
+import typing
+
+from loadgen.harness import ModelRunner, QueryInput, QueryResult
+from loadgen.model import Model, ModelFactory, ModelInput
+
+logger = logging.getLogger(__name__)
+
+######## Runner implementations
+
+
+class ModelRunnerInline(ModelRunner):
+ def __init__(self, model_factory: ModelFactory):
+ self.model = model_factory.create()
+
+ def issue_query(self, queries: QueryInput) -> typing.Optional[QueryResult]:
+ result = dict()
+ for query_id, model_input in queries.items():
+ output = self.model.predict(model_input)
+ result[query_id] = output
+ return result
+
+
+class ModelRunnerPoolExecutor(ModelRunner):
+ def __init__(self):
+ self.executor: concurrent.futures.Executor = None
+ self.futures = None
+
+ def __exit__(self, _exc_type, _exc_value, _traceback):
+ if self.executor:
+ self.executor.shutdown(True)
+ return super().__exit__(_exc_type, _exc_value, _traceback)
+
+ def issue_query(self, queries: QueryInput) -> typing.Optional[QueryResult]:
+ self.futures = dict()
+ predictor_fn = self.get_predictor()
+ for query_id, model_input in queries.items():
+ f = self.executor.submit(predictor_fn, model_input)
+ self.futures[f] = query_id
+ return None
+
+ def flush_queries(self) -> typing.Optional[QueryResult]:
+ result = dict()
+ for future in concurrent.futures.as_completed(self.futures.keys()):
+ query_id = self.futures[future]
+ query_result = future.result()
+ result[query_id] = query_result
+ return result
+
+ @abc.abstractmethod
+ def get_predictor(self) -> typing.Callable[[ModelInput], typing.Any]:
+ pass
+
+
+class ModelRunnerThreadPoolExecutor(ModelRunnerPoolExecutor):
+ def __init__(self, model_factory: ModelFactory, max_concurrency: int):
+ super().__init__()
+ self.model = model_factory.create()
+ self.max_concurrency = max_concurrency
+
+ def __enter__(self):
+ self.executor = concurrent.futures.ThreadPoolExecutor(
+ max_workers=self.max_concurrency, thread_name_prefix="LoadGen"
+ )
+ return self
+
+ def get_predictor(self) -> typing.Callable[[ModelInput], typing.Any]:
+ return self.model.predict
+
+
+class ModelRunnerThreadPoolExecutorWithTLS(ModelRunnerPoolExecutor):
+ tls: threading.local
+
+ def __init__(self, model_factory: ModelFactory, max_concurrency: int):
+ super().__init__()
+ self.model_factory = model_factory
+ self.max_concurrency = max_concurrency
+
+ def __enter__(self):
+ self.executor = concurrent.futures.ThreadPoolExecutor(
+ max_workers=self.max_concurrency,
+ thread_name_prefix="LoadGen",
+ initializer=ModelRunnerThreadPoolExecutorWithTLS._tls_init,
+ initargs=(self.model_factory,),
+ )
+ return self
+
+ def get_predictor(self) -> typing.Callable[[ModelInput], typing.Any]:
+ return ModelRunnerThreadPoolExecutorWithTLS._tls_predict
+
+ @staticmethod
+ def _tls_init(model_factory: ModelFactory):
+ ModelRunnerThreadPoolExecutorWithTLS.tls = threading.local()
+ ModelRunnerThreadPoolExecutorWithTLS.tls.model = model_factory.create()
+
+ @staticmethod
+ def _tls_predict(input: ModelInput):
+ return ModelRunnerThreadPoolExecutorWithTLS.tls.model.predict(input)
+
+
+class ModelRunnerProcessPoolExecutor(ModelRunnerPoolExecutor):
+ _model: Model
+
+ def __init__(self, model_factory: ModelFactory, max_concurrency: int):
+ super().__init__()
+ self.max_concurrency = max_concurrency
+ ModelRunnerProcessPoolExecutor._model = model_factory.create()
+
+ def __enter__(self):
+ self.executor = concurrent.futures.ProcessPoolExecutor(
+ max_workers=self.max_concurrency
+ )
+ return self
+
+ def get_predictor(self) -> typing.Callable[[ModelInput], typing.Any]:
+ return ModelRunnerProcessPoolExecutor._predict
+
+ @staticmethod
+ def _predict(input: ModelInput):
+ result = ModelRunnerProcessPoolExecutor._model.predict(input)
+ return result
+
+
+class ModelRunnerMultiProcessingPool(ModelRunner):
+ _model: Model
+
+ def __init__(
+ self,
+ model_factory: ModelFactory,
+ max_concurrency: int,
+ ):
+ self.max_concurrency = max_concurrency
+ self.task: multiprocessing.ApplyResult = None
+ ModelRunnerMultiProcessingPool._model = model_factory.create()
+
+ def __enter__(self):
+ self.pool = multiprocessing.Pool(self.max_concurrency)
+
+ def __exit__(self, _exc_type, _exc_value, _traceback):
+ if self.pool:
+ self.pool.terminate()
+ return super().__exit__(_exc_type, _exc_value, _traceback)
+
+ def issue_query(self, queries: QueryInput) -> typing.Optional[QueryResult]:
+ if hasattr(self, "tasks"):
+ assert len(self.tasks) == 0
+ for query_id, model_input in queries.items():
+ task = self.pool.apply_async(
+ ModelRunnerMultiProcessingPool._predict, (model_input,)
+ )
+ self.tasks[task] = query_id
+ else:
+ assert self.task is None
+ inputs = [
+ [query_id, model_input] for query_id, model_input in queries.items()
+ ]
+ self.task = self.pool.starmap_async(
+ ModelRunnerMultiProcessingPool._predict_with_id, inputs
+ )
+ return None
+
+ def flush_queries(self) -> typing.Optional[QueryResult]:
+ if hasattr(self, "tasks"):
+ result = dict()
+ for task, query_id in self.tasks.items():
+ task_result = task.get()
+ result[query_id] = task_result
+ return result
+ else:
+ task_result = self.task.get()
+ result = {query_id: query_result for query_id, query_result in task_result}
+ return result
+
+ @staticmethod
+ def _predict(input: ModelInput):
+ result = ModelRunnerMultiProcessingPool._model.predict(input)
+ return result
+
+ @staticmethod
+ def _predict_with_id(query_id: int, input: ModelInput):
+ result = ModelRunnerMultiProcessingPool._model.predict(input)
+ return (query_id, result)
diff --git a/script/app-loadgen-generic-python/src/main.py b/script/app-loadgen-generic-python/src/main.py
new file mode 100644
index 0000000000..0055ecaf2f
--- /dev/null
+++ b/script/app-loadgen-generic-python/src/main.py
@@ -0,0 +1,238 @@
+import argparse
+import contextlib
+import logging
+import os
+import re
+import typing
+
+import mlperf_loadgen
+import psutil
+
+from loadgen.harness import Harness, ModelRunner
+from loadgen.runners import (
+ ModelRunnerInline,
+ ModelRunnerMultiProcessingPool,
+ ModelRunnerProcessPoolExecutor,
+ ModelRunnerThreadPoolExecutor,
+ ModelRunnerThreadPoolExecutorWithTLS,
+)
+
+logger = logging.getLogger(__name__)
+
+
+def main(
+ backend: str,
+ model_path: str,
+ model_code: str,
+ model_cfg: str,
+ model_sample_pickle: str,
+ output_path: typing.Optional[str],
+ runner_name: str,
+ runner_concurrency: int,
+ execution_provider: str,
+ execution_mode: str,
+ intraop_threads: int,
+ interop_threads: int,
+ samples: int,
+ loadgen_expected_qps: float,
+ loadgen_duration_sec: float
+):
+
+ print ('=====================================================================')
+
+ if backend == 'onnxruntime':
+ from backend_onnxruntime import XModelFactory
+ from backend_onnxruntime import XModelInputSampler
+ elif backend == 'pytorch':
+ from backend_pytorch import XModelFactory
+ from backend_pytorch import XModelInputSampler
+ else:
+ raise Exception("Error: backend is not recognized.")
+
+ # Load model cfg
+ model_cfg_dict = {}
+ if model_cfg!='':
+ import json
+
+ with open(model_cfg) as mc:
+ model_cfg_dict = json.load(mc)
+
+ model_factory = XModelFactory(
+ model_path,
+ execution_provider,
+ execution_mode,
+ interop_threads,
+ intraop_threads,
+ model_code,
+ model_cfg_dict,
+ model_sample_pickle
+ )
+
+ model_dataset = XModelInputSampler(model_factory)
+
+ runner: ModelRunner = None
+ if runner_name == "inline":
+ runner = ModelRunnerInline(model_factory)
+ elif runner_name == "threadpool":
+ runner = ModelRunnerThreadPoolExecutor(
+ model_factory, max_concurrency=runner_concurrency
+ )
+ elif runner_name == "threadpool+replication":
+ runner = ModelRunnerThreadPoolExecutorWithTLS(
+ model_factory, max_concurrency=runner_concurrency
+ )
+ elif runner_name == "processpool":
+ runner = ModelRunnerProcessPoolExecutor(
+ model_factory, max_concurrency=runner_concurrency
+ )
+ elif runner_name == "processpool+mp":
+ runner = ModelRunnerMultiProcessingPool(
+ model_factory, max_concurrency=runner_concurrency
+ )
+ else:
+ raise ValueError(f"Invalid runner {runner}")
+
+ settings = mlperf_loadgen.TestSettings()
+
+ settings.scenario = mlperf_loadgen.TestScenario.Offline
+ settings.mode = mlperf_loadgen.TestMode.PerformanceOnly
+ settings.offline_expected_qps = loadgen_expected_qps
+ settings.min_query_count = samples
+ settings.max_query_count = samples
+ settings.min_duration_ms = loadgen_duration_sec * 1000
+ # Duration isn't enforced in offline mode
+ # Instead, it is used to determine total sample count via
+ # target_sample_count = Slack (1.1) * TargetQPS (1) * TargetDuration ()
+ # samples_per_query = Max(min_query_count, target_sample_count)
+
+ output_path = "results" if not output_path else output_path
+ output_path = os.path.join(output_path, os.path.basename(model_path), runner_name)
+ os.makedirs(output_path, exist_ok=True)
+
+ output_settings = mlperf_loadgen.LogOutputSettings()
+ output_settings.outdir = output_path
+ output_settings.copy_summary_to_stdout = True
+
+ log_settings = mlperf_loadgen.LogSettings()
+ log_settings.log_output = output_settings
+ log_settings.enable_trace = False
+
+ logger.info(f"Model: {model_path}")
+ logger.info(f"Runner: {runner_name}, Concurrency: {runner_concurrency}")
+ logger.info(f"Results: {output_path}")
+
+ with contextlib.ExitStack() as stack:
+ stack.enter_context(runner)
+ harness = Harness(model_dataset, runner)
+
+ query_sample_libary = mlperf_loadgen.ConstructQSL(
+ samples, # Total sample count
+ samples, # Num to load in RAM at a time
+ harness.load_query_samples,
+ harness.unload_query_samples,
+ )
+ system_under_test = mlperf_loadgen.ConstructSUT(
+ harness.issue_query, harness.flush_queries
+ )
+
+ print ('=====================================================================')
+ logger.info("Test Started")
+
+ mlperf_loadgen.StartTestWithLogSettings(
+ system_under_test, query_sample_libary, settings, log_settings
+ )
+
+ logger.info("Test Finished")
+ print ('=====================================================================')
+
+ # Parse output file
+ output_summary = {}
+ output_summary_path = os.path.join(output_path, "mlperf_log_summary.txt")
+ with open(output_summary_path, "r") as output_summary_file:
+ for line in output_summary_file:
+ m = re.match(r"^\s*([\w\s.\(\)\/]+)\s*\:\s*([\w\+\.]+).*", line)
+ if m:
+ output_summary[m.group(1).strip()] = m.group(2).strip()
+ logger.info("Observed QPS: " + output_summary.get("Samples per second"))
+ logger.info("Result: " + output_summary.get("Result is"))
+
+ mlperf_loadgen.DestroySUT(system_under_test)
+ mlperf_loadgen.DestroyQSL(query_sample_libary)
+ logger.info("Test Completed")
+ print ('=====================================================================')
+
+
+if __name__ == "__main__":
+ print ('')
+
+ logging.basicConfig(
+ level=logging.DEBUG,
+ format="%(asctime)s %(levelname)s %(threadName)s - %(name)s %(funcName)s: %(message)s",
+ )
+
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "model_path", help="path to input model", default="models/yolov5s.onnx"
+ )
+ parser.add_argument("-b", "--backend", help="backend", default="onnxruntime")
+ parser.add_argument("-o", "--output", help="path to store loadgen results")
+ parser.add_argument(
+ "-r",
+ "--runner",
+ help="model runner",
+ choices=[
+ "inline",
+ "threadpool",
+ "threadpool+replication",
+ "processpool",
+ "processpool+mp",
+ ],
+ default="inline",
+ )
+ parser.add_argument(
+ "--concurrency",
+ help="concurrency count for runner",
+ default=psutil.cpu_count(False),
+ type=int,
+ )
+ parser.add_argument(
+ "--ep", help="Execution Provider", default="CPUExecutionProvider"
+ )
+ parser.add_argument("--intraop", help="IntraOp threads", default=0, type=int)
+ parser.add_argument("--interop", help="InterOp threads", default=0, type=int)
+ parser.add_argument(
+ "--execmode",
+ help="Execution Mode",
+ choices=["sequential", "parallel"],
+ default="sequential",
+ )
+ parser.add_argument(
+ "--samples",
+ help="number of samples",
+ default=100,
+ type=int,
+ )
+ parser.add_argument("--loadgen_expected_qps", help="Expected QPS", default=1, type=float)
+ parser.add_argument("--loadgen_duration_sec", help="Expected duration in sec.", default=1, type=float)
+ parser.add_argument("--model_code", help="(for PyTorch models) path to model code with cmc.py", default="")
+ parser.add_argument("--model_cfg", help="(for PyTorch models) path to model's configuration in JSON file", default="")
+ parser.add_argument("--model_sample_pickle", help="(for PyTorch models) path to a model sample in pickle format", default="")
+
+ args = parser.parse_args()
+ main(
+ args.backend,
+ args.model_path,
+ args.model_code,
+ args.model_cfg,
+ args.model_sample_pickle,
+ args.output,
+ args.runner,
+ args.concurrency,
+ args.ep,
+ args.execmode,
+ args.intraop,
+ args.interop,
+ args.samples,
+ args.loadgen_expected_qps,
+ args.loadgen_duration_sec
+ )
diff --git a/script/app-loadgen-generic-python/src/utils.py b/script/app-loadgen-generic-python/src/utils.py
new file mode 100644
index 0000000000..8c182650c5
--- /dev/null
+++ b/script/app-loadgen-generic-python/src/utils.py
@@ -0,0 +1,16 @@
+# Developer: Grigori Fursin
+
+import os
+import psutil
+
+def print_host_memory_use(text=''):
+
+ pid = os.getpid()
+ python_process = psutil.Process(pid)
+ memoryUse = python_process.memory_info()[0]
+
+ if text == '': text = 'host memory use'
+
+ print('{}: {} MB'.format(text, int(memoryUse/1000000)))
+
+ return
diff --git a/script/app-loadgen-generic-python/tests/modular-cm-containers/_common.bat b/script/app-loadgen-generic-python/tests/modular-cm-containers/_common.bat
new file mode 100644
index 0000000000..c7154832fb
--- /dev/null
+++ b/script/app-loadgen-generic-python/tests/modular-cm-containers/_common.bat
@@ -0,0 +1,7 @@
+rem set CM_CACHE=--no-cache
+
+set CM_DOCKER_ORG=modularcm
+set CM_DOCKER_NAME=loadgen-generic-python
+set CM_OS_NAME=ubuntu
+set CM_HW_TARGET=cpu
+set CM_OS_VERSION=22.04
diff --git a/script/app-loadgen-generic-python/tests/modular-cm-containers/_common.sh b/script/app-loadgen-generic-python/tests/modular-cm-containers/_common.sh
new file mode 100644
index 0000000000..5f49d3be9b
--- /dev/null
+++ b/script/app-loadgen-generic-python/tests/modular-cm-containers/_common.sh
@@ -0,0 +1,10 @@
+#! /bin/bash
+
+#export CM_CACHE="--no-cache"
+
+export CM_DOCKER_ORG=modularcm
+export CM_DOCKER_NAME="loadgen-generic-python"
+export CM_OS_NAME="ubuntu"
+export CM_HW_TARGET="cpu"
+export CM_OS_VERSION="22.04"
+
diff --git a/script/app-loadgen-generic-python/tests/modular-cm-containers/build.bat b/script/app-loadgen-generic-python/tests/modular-cm-containers/build.bat
new file mode 100644
index 0000000000..f51ea46b64
--- /dev/null
+++ b/script/app-loadgen-generic-python/tests/modular-cm-containers/build.bat
@@ -0,0 +1,16 @@
+call _common.bat
+
+docker build -f %CM_DOCKER_NAME%--%CM_OS_NAME%-%CM_HW_TARGET%.Dockerfile ^
+ -t %CM_DOCKER_ORG%/%CM_DOCKER_NAME%-%CM_HW_TARGET%:%CM_OS_NAME%-%CM_OS_VERSION% ^
+ --build-arg cm_os_name=%CM_OS_NAME% ^
+ --build-arg cm_hw_target=%CM_HW_TARGET% ^
+ --build-arg cm_os_version=%CM_OS_VERSION% ^
+ --build-arg cm_version="" ^
+ --build-arg cm_automation_repo="ctuning@mlcommons-ck" ^
+ --build-arg cm_automation_checkout="" ^
+ --build-arg cm_python_version="3.10.8" ^
+ --build-arg cm_mlperf_inference_loadgen_version="" ^
+ --build-arg cm_mlperf_inference_src_tags="" ^
+ --build-arg cm_mlperf_inference_src_version="" ^
+ --build-arg CM_ONNXRUNTIME_VERSION="1.13.1" ^
+ %CM_CACHE% .
diff --git a/script/app-loadgen-generic-python/tests/modular-cm-containers/build.sh b/script/app-loadgen-generic-python/tests/modular-cm-containers/build.sh
new file mode 100644
index 0000000000..186a0eae94
--- /dev/null
+++ b/script/app-loadgen-generic-python/tests/modular-cm-containers/build.sh
@@ -0,0 +1,18 @@
+#! /bin/bash
+
+. ./_common.sh
+
+time docker build -f ${CM_DOCKER_NAME}--${CM_OS_NAME}-${CM_HW_TARGET}.Dockerfile \
+ -t ${CM_DOCKER_ORG}/${CM_DOCKER_NAME}-${CM_HW_TARGET}:${CM_OS_NAME}-${CM_OS_VERSION} \
+ --build-arg cm_os_name=${CM_OS_NAME} \
+ --build-arg cm_hw_target=${CM_HW_TARGET} \
+ --build-arg cm_os_version=${CM_OS_VERSION} \
+ --build-arg cm_version="" \
+ --build-arg cm_automation_repo="ctuning@mlcommons-ck" \
+ --build-arg cm_automation_checkout="" \
+ --build-arg cm_python_version="3.10.8" \
+ --build-arg cm_mlperf_inference_loadgen_version="" \
+ --build-arg cm_mlperf_inference_src_tags="" \
+ --build-arg cm_mlperf_inference_src_version="" \
+ --build-arg CM_ONNXRUNTIME_VERSION="1.13.1" \
+ ${CM_CACHE} .
diff --git a/script/app-loadgen-generic-python/tests/modular-cm-containers/loadgen-generic-python--ubuntu-cpu.Dockerfile b/script/app-loadgen-generic-python/tests/modular-cm-containers/loadgen-generic-python--ubuntu-cpu.Dockerfile
new file mode 100644
index 0000000000..c82296c664
--- /dev/null
+++ b/script/app-loadgen-generic-python/tests/modular-cm-containers/loadgen-generic-python--ubuntu-cpu.Dockerfile
@@ -0,0 +1,96 @@
+# Modular MLPerf container with the MLCommons CM automation meta-framework
+
+# Preparing OS
+ARG cm_os_name="ubuntu"
+ARG cm_os_version="22.04"
+
+FROM ${cm_os_name}:${cm_os_version}
+
+# Maintained by the MLCommons taskforce on automation and reproducibility and OctoML
+LABEL github="https://github.com/mlcommons/ck"
+LABEL maintainer="https://cKnowledge.org/mlcommons-taskforce"
+
+# Customization
+ARG CM_GH_TOKEN
+
+# Prepare shell and entry point
+SHELL ["/bin/bash", "-c"]
+ENTRYPOINT ["/bin/bash", "-c"]
+
+# Install system dependencies
+# Notes: https://runnable.com/blog/9-common-dockerfile-mistakes
+RUN apt-get update -y
+RUN apt-get install -y lsb-release
+RUN apt-get install -y python3 python3-pip git wget sudo
+
+# Extra python deps
+RUN python3 -m pip install requests
+
+# CM version
+ARG cm_version=""
+ENV CM_VERSION="${cm_version}"
+RUN if [ "${CM_VERSION}" != "" ] ; then \
+ python3 -m pip install cmind==${CM_VERSION} ; \
+ else \
+ python3 -m pip install cmind ; \
+ fi
+
+# Setup docker environment
+ENTRYPOINT ["/bin/bash", "-c"]
+ENV TZ=US/Pacific
+RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ >/etc/timezone
+
+# Setup docker user
+# See example in https://github.com/mlcommons/GaNDLF/blob/master/Dockerfile-CPU
+RUN groupadd --gid 10001 cm
+RUN useradd --uid 10000 -g cm --create-home --shell /bin/bash cmuser
+RUN echo "cmuser ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
+
+USER cmuser:cm
+WORKDIR /home/cmuser
+
+# Check CM installation
+RUN lsb_release -a > sys-version-os.log
+RUN uname -a > sys-version-kernel.log
+RUN python3 --version > sys-version-python3.log
+RUN cm version > sys-version-cm.log
+
+################################################################################
+# Get CM automation repository
+ARG cm_automation_repo="mlcommons@ck"
+ARG cm_automation_repo_checkout=""
+ENV CM_AUTOMATION_REPO=${cm_automation_repo}
+ENV CM_AUTOMATION_REPO_CHECKOUT=${cm_automation_repo_checkout}
+RUN echo ${CM_AUTOMATION_REPO}
+RUN cm pull repo ${CM_AUTOMATION_REPO} --checkout=${CM_AUTOMATION_REPO_CHECKOUT}
+
+################################################################################
+# Install CM system dependencies
+RUN cm run script "get sys-utils-cm" --quiet
+
+# Detect/install python
+ARG cm_python_version=""
+RUN cm run script "get python3" --version=${cm_python_version}
+
+################################################################################
+# Build MLPerf loadgen
+ARG cm_mlperf_inference_loadgen_version=""
+RUN cm run script "get mlperf loadgen" --adr.compiler.tags=gcc --version=${cm_mlperf_inference_loadgen_version} --adr.inference-src-loadgen.version=${cm_mlperf_inference_loadgen_version} -v
+
+################################################################################
+# Install ONNX runtime
+ARG CM_ONNXRUNTIME_VERSION=""
+RUN cm run script "get generic-python-lib _onnxruntime" --version=${CM_ONNXRUNTIME_VERSION}
+
+ARG CM_MLPERF_CHOICE_BACKEND="onnxruntime"
+ARG CM_MLPERF_CHOICE_DEVICE="cpu"
+
+RUN cm run script --tags=python,app,loadgen-generic,_onnxruntime,_resnet50 \
+ --adr.compiler.tags=gcc \
+ --adr.python.version_min=3.8 \
+ --quiet \
+ --fake_run
+
+################################################################################
+# CMD entry point
+CMD /bin/bash
diff --git a/script/app-loadgen-generic-python/tests/modular-cm-containers/loadgen-generic-python-auto.Dockerfile b/script/app-loadgen-generic-python/tests/modular-cm-containers/loadgen-generic-python-auto.Dockerfile
new file mode 100644
index 0000000000..195acdec6a
--- /dev/null
+++ b/script/app-loadgen-generic-python/tests/modular-cm-containers/loadgen-generic-python-auto.Dockerfile
@@ -0,0 +1,33 @@
+FROM ubuntu:20.04
+SHELL ["/bin/bash", "-c"]
+ARG CM_GH_TOKEN
+
+# Notes: https://runnable.com/blog/9-common-dockerfile-mistakes
+# Install system dependencies
+RUN apt-get update -y
+RUN apt-get install -y python3 python3-pip git sudo wget
+
+# Install python packages
+RUN python3 -m pip install cmind requests
+
+# Setup docker environment
+ENTRYPOINT ["/bin/bash", "-c"]
+ENV TZ=US/Pacific
+ENV PATH=${PATH}:$HOME/.local/bin
+RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ >/etc/timezone
+
+# Setup docker user
+RUN groupadd cm
+RUN useradd -g cm --create-home --shell /bin/bash cmuser
+RUN echo "cmuser ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
+USER cmuser:cm
+WORKDIR /home/cmuser
+
+# Download CM repo for scripts
+RUN cm pull repo ctuning@mlcommons-ck
+
+# Install all system dependencies
+RUN cm run script --quiet --tags=get,sys-utils-cm
+
+# Run commands
+RUN cm run script --quiet --tags=python,app,loadgen-generic,_onnxruntime,_resnet50 --fake_run
diff --git a/script/app-loadgen-generic-python/tests/modular-cm-containers/run.bat b/script/app-loadgen-generic-python/tests/modular-cm-containers/run.bat
new file mode 100644
index 0000000000..171aeecab9
--- /dev/null
+++ b/script/app-loadgen-generic-python/tests/modular-cm-containers/run.bat
@@ -0,0 +1,3 @@
+call _common.bat
+
+docker run -it %CM_DOCKER_ORG%/%CM_DOCKER_NAME%-%CM_HW_TARGET%:%CM_OS_NAME%-%CM_OS_VERSION%
diff --git a/script/app-loadgen-generic-python/tests/modular-cm-containers/run.sh b/script/app-loadgen-generic-python/tests/modular-cm-containers/run.sh
new file mode 100644
index 0000000000..c82d4b7b12
--- /dev/null
+++ b/script/app-loadgen-generic-python/tests/modular-cm-containers/run.sh
@@ -0,0 +1,3 @@
+. ./_common.sh
+
+docker run -it ${CM_DOCKER_ORG}/${CM_DOCKER_NAME}-%CM_HW_TARGET%:${CM_OS_NAME}-${CM_OS_VERSION}
diff --git a/script/app-mlperf-inference-ctuning-cpp-tflite/README.md b/script/app-mlperf-inference-ctuning-cpp-tflite/README.md
new file mode 100644
index 0000000000..a36fc20dc8
--- /dev/null
+++ b/script/app-mlperf-inference-ctuning-cpp-tflite/README.md
@@ -0,0 +1,368 @@
+Automatically generated README for this automation recipe: **app-mlperf-inference-ctuning-cpp-tflite**
+
+Category: **Modular MLPerf inference benchmark pipeline**
+
+License: **Apache 2.0**
+
+Maintainers: [Public MLCommons Task Force on Automation and Reproducibility](https://github.com/mlcommons/ck/blob/master/docs/taskforce.md)
+
+---
+*[ [Online info and GUI to run this CM script](https://access.cknowledge.org/playground/?action=scripts&name=app-mlperf-inference-ctuning-cpp-tflite,415904407cca404a) ]*
+
+---
+#### Summary
+
+* CM GitHub repository: *[mlcommons@ck](https://github.com/mlcommons/ck/tree/dev/cm-mlops)*
+* GitHub directory for this script: *[GitHub](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-mlperf-inference-ctuning-cpp-tflite)*
+* CM meta description for this script: *[_cm.json](_cm.json)*
+* All CM tags to find and reuse this script (see in above meta description): *app,mlperf,inference,tflite-cpp*
+* Output cached? *False*
+* See [pipeline of dependencies](#dependencies-on-other-cm-scripts) on other CM scripts
+
+
+---
+### Reuse this script in your project
+
+#### Install MLCommons CM automation meta-framework
+
+* [Install CM](https://access.cknowledge.org/playground/?action=install)
+* [CM Getting Started Guide](https://github.com/mlcommons/ck/blob/master/docs/getting-started.md)
+
+#### Pull CM repository with this automation recipe (CM script)
+
+```cm pull repo mlcommons@ck```
+
+#### Print CM help from the command line
+
+````cmr "app mlperf inference tflite-cpp" --help````
+
+#### Customize and run this script from the command line with different variations and flags
+
+`cm run script --tags=app,mlperf,inference,tflite-cpp`
+
+`cm run script --tags=app,mlperf,inference,tflite-cpp[,variations] [--input_flags]`
+
+*or*
+
+`cmr "app mlperf inference tflite-cpp"`
+
+`cmr "app mlperf inference tflite-cpp [variations]" [--input_flags]`
+
+
+* *See the list of `variations` [here](#variations) and check the [Gettings Started Guide](https://github.com/mlcommons/ck/blob/dev/docs/getting-started.md) for more details.*
+
+#### Run this script from Python
+
+
+Click here to expand this section.
+
+```python
+
+import cmind
+
+r = cmind.access({'action':'run'
+ 'automation':'script',
+ 'tags':'app,mlperf,inference,tflite-cpp'
+ 'out':'con',
+ ...
+ (other input keys for this script)
+ ...
+ })
+
+if r['return']>0:
+ print (r['error'])
+
+```
+
+
+
+
+#### Run this script via GUI
+
+```cmr "cm gui" --script="app,mlperf,inference,tflite-cpp"```
+
+Use this [online GUI](https://cKnowledge.org/cm-gui/?tags=app,mlperf,inference,tflite-cpp) to generate CM CMD.
+
+#### Run this script via Docker (beta)
+
+`cm docker script "app mlperf inference tflite-cpp[variations]" [--input_flags]`
+
+___
+### Customization
+
+
+#### Variations
+
+ * *No group (any variation can be selected)*
+
+ Click here to expand this section.
+
+ * `_armnn`
+ - Environment variables:
+ - *CM_MLPERF_TFLITE_USE_ARMNN*: `yes`
+ - *CM_TMP_LINK_LIBS*: `tensorflowlite,armnn`
+ - Workflow:
+ * `_armnn,tflite`
+ - Environment variables:
+ - *CM_MLPERF_BACKEND*: `armnn_tflite`
+ - *CM_MLPERF_BACKEND_VERSION*: `<<>>`
+ - *CM_MLPERF_SUT_NAME_IMPLEMENTATION_PREFIX*: `tflite_armnn_cpp`
+ - *CM_TMP_LINK_LIBS*: `tensorflowlite,armnn,armnnTfLiteParser`
+ - *CM_TMP_SRC_FOLDER*: `armnn`
+ - Workflow:
+
+
+
+
+ * Group "**backend**"
+
+ Click here to expand this section.
+
+ * `_tf`
+ - Environment variables:
+ - *CM_MLPERF_BACKEND*: `tf`
+ - Workflow:
+ * **`_tflite`** (default)
+ - Environment variables:
+ - *CM_MLPERF_BACKEND*: `tflite`
+ - *CM_MLPERF_BACKEND_VERSION*: `master`
+ - *CM_TMP_LINK_LIBS*: `tensorflowlite`
+ - *CM_TMP_SRC_FOLDER*: `src`
+ - Workflow:
+
+
+
+
+ * Group "**device**"
+
+ Click here to expand this section.
+
+ * **`_cpu`** (default)
+ - Environment variables:
+ - *CM_MLPERF_DEVICE*: `cpu`
+ - Workflow:
+ * `_gpu`
+ - Environment variables:
+ - *CM_MLPERF_DEVICE*: `gpu`
+ - *CM_MLPERF_DEVICE_LIB_NAMESPEC*: `cudart`
+ - Workflow:
+
+
+
+
+ * Group "**loadgen-scenario**"
+
+ Click here to expand this section.
+
+ * **`_singlestream`** (default)
+ - Environment variables:
+ - *CM_MLPERF_LOADGEN_SCENARIO*: `SingleStream`
+ - Workflow:
+
+
+
+
+ * Group "**model**"
+
+ Click here to expand this section.
+
+ * `_efficientnet`
+ - Environment variables:
+ - *CM_MODEL*: `efficientnet`
+ - Workflow:
+ * `_mobilenet`
+ - Environment variables:
+ - *CM_MODEL*: `mobilenet`
+ - Workflow:
+ * **`_resnet50`** (default)
+ - Environment variables:
+ - *CM_MODEL*: `resnet50`
+ - Workflow:
+
+
+
+
+ * Group "**optimization-target**"
+
+ Click here to expand this section.
+
+ * `_use-neon`
+ - Environment variables:
+ - *CM_MLPERF_SUT_NAME_RUN_CONFIG_SUFFIX1*: `using_neon`
+ - *CM_MLPERF_TFLITE_USE_NEON*: `1`
+ - Workflow:
+ * `_use-opencl`
+ - Environment variables:
+ - *CM_MLPERF_SUT_NAME_RUN_CONFIG_SUFFIX1*: `using_opencl`
+ - *CM_MLPERF_TFLITE_USE_OPENCL*: `1`
+ - Workflow:
+
+
+
+
+ * Group "**precision**"
+
+ Click here to expand this section.
+
+ * **`_fp32`** (default)
+ - Environment variables:
+ - *CM_MLPERF_MODEL_PRECISION*: `float32`
+ - Workflow:
+ * `_int8`
+ - Environment variables:
+ - *CM_DATASET_COMPRESSED*: `on`
+ - *CM_MLPERF_MODEL_PRECISION*: `int8`
+ - Workflow:
+ * `_uint8`
+ - Environment variables:
+ - *CM_DATASET_COMPRESSED*: `on`
+ - *CM_MLPERF_MODEL_PRECISION*: `uint8`
+ - Workflow:
+
+
+
+
+#### Default variations
+
+`_cpu,_fp32,_resnet50,_singlestream,_tflite`
+
+#### Script flags mapped to environment
+
+Click here to expand this section.
+
+* `--compressed_dataset=value` → `CM_DATASET_COMPRESSED=value`
+* `--count=value` → `CM_MLPERF_LOADGEN_QUERY_COUNT=value`
+* `--mlperf_conf=value` → `CM_MLPERF_CONF=value`
+* `--mode=value` → `CM_MLPERF_LOADGEN_MODE=value`
+* `--output_dir=value` → `CM_MLPERF_OUTPUT_DIR=value`
+* `--performance_sample_count=value` → `CM_MLPERF_LOADGEN_PERFORMANCE_SAMPLE_COUNT=value`
+* `--scenario=value` → `CM_MLPERF_LOADGEN_SCENARIO=value`
+* `--user_conf=value` → `CM_MLPERF_USER_CONF=value`
+* `--verbose=value` → `CM_VERBOSE=value`
+
+**Above CLI flags can be used in the Python CM API as follows:**
+
+```python
+r=cm.access({... , "compressed_dataset":...}
+```
+
+
+
+#### Default environment
+
+
+Click here to expand this section.
+
+These keys can be updated via `--env.KEY=VALUE` or `env` dictionary in `@input.json` or using script flags.
+
+* CM_DATASET_COMPRESSED: `off`
+* CM_DATASET_INPUT_SQUARE_SIDE: `224`
+* CM_FAST_COMPILATION: `yes`
+* CM_LOADGEN_BUFFER_SIZE: `1024`
+* CM_MLPERF_LOADGEN_MODE: `accuracy`
+* CM_MLPERF_LOADGEN_SCENARIO: `SingleStream`
+* CM_MLPERF_LOADGEN_TRIGGER_COLD_RUN: `0`
+* CM_MLPERF_OUTPUT_DIR: `.`
+* CM_MLPERF_SUT_NAME_IMPLEMENTATION_PREFIX: `tflite_cpp`
+* CM_MLPERF_TFLITE_USE_NEON: `0`
+* CM_MLPERF_TFLITE_USE_OPENCL: `0`
+* CM_ML_MODEL_GIVEN_CHANNEL_MEANS: `123.68 116.78 103.94`
+* CM_ML_MODEL_NORMALIZE_DATA: `0`
+* CM_ML_MODEL_SUBTRACT_MEANS: `1`
+* CM_VERBOSE: `0`
+
+
+
+___
+### Dependencies on other CM scripts
+
+
+ 1. ***Read "deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-mlperf-inference-ctuning-cpp-tflite/_cm.json)***
+ * detect,os
+ - CM script: [detect-os](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/detect-os)
+ * detect,cpu
+ - CM script: [detect-cpu](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/detect-cpu)
+ * get,sys-utils-cm
+ - CM script: [get-sys-utils-cm](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-sys-utils-cm)
+ * get,cuda
+ * `if (CM_MLPERF_DEVICE == gpu)`
+ - CM script: [get-cuda](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-cuda)
+ * get,loadgen
+ * CM names: `--adr.['loadgen']...`
+ - CM script: [get-mlperf-inference-loadgen](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-mlperf-inference-loadgen)
+ * get,mlcommons,inference,src
+ * CM names: `--adr.['inference-src']...`
+ - CM script: [get-mlperf-inference-src](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-mlperf-inference-src)
+ * get,ml-model,mobilenet,raw,_tflite
+ * `if (CM_MLPERF_BACKEND in ['tflite', 'armnn_tflite'] AND CM_MODEL == mobilenet)`
+ * CM names: `--adr.['ml-model', 'tflite-model', 'mobilenet-model']...`
+ - CM script: [get-ml-model-mobilenet](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-ml-model-mobilenet)
+ * get,ml-model,resnet50,raw,_tflite,_no-argmax
+ * `if (CM_MLPERF_BACKEND in ['tflite', 'armnn_tflite'] AND CM_MODEL == resnet50)`
+ * CM names: `--adr.['ml-model', 'tflite-model', 'resnet50-model']...`
+ - CM script: [get-ml-model-resnet50](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-ml-model-resnet50)
+ * get,ml-model,resnet50,raw,_tf
+ * `if (CM_MLPERF_BACKEND == tf AND CM_MODEL == resnet50)`
+ * CM names: `--adr.['ml-model', 'tflite-model', 'resnet50-model']...`
+ - CM script: [get-ml-model-resnet50](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-ml-model-resnet50)
+ * get,ml-model,efficientnet,raw,_tflite
+ * `if (CM_MLPERF_BACKEND in ['tflite', 'armnn_tflite'] AND CM_MODEL == efficientnet)`
+ * CM names: `--adr.['ml-model', 'tflite-model', 'efficientnet-model']...`
+ - CM script: [get-ml-model-efficientnet-lite](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-ml-model-efficientnet-lite)
+ * get,tensorflow,lib,_tflite
+ - CM script: [install-tensorflow-from-src](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/install-tensorflow-from-src)
+ * get,lib,armnn
+ * `if (CM_MLPERF_TFLITE_USE_ARMNN == yes)`
+ * CM names: `--adr.['armnn', 'lib-armnn']...`
+ - CM script: [get-lib-armnn](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-lib-armnn)
+ 1. ***Run "preprocess" function from [customize.py](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-mlperf-inference-ctuning-cpp-tflite/customize.py)***
+ 1. ***Read "prehook_deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-mlperf-inference-ctuning-cpp-tflite/_cm.json)***
+ * generate,user-conf,mlperf,inference
+ * CM names: `--adr.['user-conf-generator']...`
+ - CM script: [generate-mlperf-inference-user-conf](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/generate-mlperf-inference-user-conf)
+ * get,dataset,preprocessed,imagenet,_for.resnet50,_rgb32,_NHWC
+ * `if (CM_MLPERF_SKIP_RUN == no AND CM_MODEL == resnet50) AND (CM_DATASET_COMPRESSED != on)`
+ * CM names: `--adr.['imagenet-preprocessed', 'preprocessed-dataset']...`
+ - CM script: [get-preprocessed-dataset-imagenet](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-preprocessed-dataset-imagenet)
+ * get,dataset,preprocessed,imagenet,_for.mobilenet,_rgb32,_NHWC
+ * `if (CM_MLPERF_SKIP_RUN == no AND CM_MODEL in ['mobilenet', 'efficientnet']) AND (CM_DATASET_COMPRESSED != on)`
+ * CM names: `--adr.['imagenet-preprocessed', 'preprocessed-dataset']...`
+ - CM script: [get-preprocessed-dataset-imagenet](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-preprocessed-dataset-imagenet)
+ * get,dataset,preprocessed,imagenet,_for.mobilenet,_rgb8,_NHWC
+ * `if (CM_DATASET_COMPRESSED == on AND CM_MLPERF_SKIP_RUN == no AND CM_MODEL in ['mobilenet', 'efficientnet'])`
+ * CM names: `--adr.['imagenet-preprocessed', 'preprocessed-dataset']...`
+ - CM script: [get-preprocessed-dataset-imagenet](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-preprocessed-dataset-imagenet)
+ * get,dataset,preprocessed,imagenet,_for.resnet50,_rgb8,_NHWC
+ * `if (CM_DATASET_COMPRESSED == on AND CM_MLPERF_SKIP_RUN == no AND CM_MODEL == resnet50)`
+ * CM names: `--adr.['imagenet-preprocessed', 'preprocessed-dataset']...`
+ - CM script: [get-preprocessed-dataset-imagenet](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/get-preprocessed-dataset-imagenet)
+ 1. ***Run native script if exists***
+ 1. Read "posthook_deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-mlperf-inference-ctuning-cpp-tflite/_cm.json)
+ 1. ***Run "postrocess" function from [customize.py](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-mlperf-inference-ctuning-cpp-tflite/customize.py)***
+ 1. ***Read "post_deps" on other CM scripts from [meta](https://github.com/mlcommons/ck/tree/dev/cm-mlops/script/app-mlperf-inference-ctuning-cpp-tflite/_cm.json)***
+ * compile,program
+ * `if (CM_MLPERF_SKIP_RUN != yes)`
+ * CM names: `--adr.['compiler-program']...`
+ - CM script: [compile-program](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/compile-program)
+ * benchmark-mlperf
+ * `if (CM_MLPERF_SKIP_RUN != yes)`
+ * CM names: `--adr.['mlperf-runner']...`
+ - CM script: [benchmark-program-mlperf](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/benchmark-program-mlperf)
+ * save,mlperf,inference,state
+ * CM names: `--adr.['save-mlperf-inference-state']...`
+ - CM script: [save-mlperf-inference-implementation-state](https://github.com/mlcommons/ck/tree/master/cm-mlops/script/save-mlperf-inference-implementation-state)
+
+___
+### Script output
+`cmr "app mlperf inference tflite-cpp [,variations]" [--input_flags] -j`
+#### New environment keys (filter)
+
+* `CM_HW_NAME`
+* `CM_MLPERF_*`
+* `CM_ML_MODEL_*`
+#### New environment keys auto-detected from customize
+
+* `CM_MLPERF_CONF`
+* `CM_MLPERF_DEVICE`
+* `CM_MLPERF_SUT_NAME_RUN_CONFIG_SUFFIX2`
+* `CM_MLPERF_USER_CONF`
\ No newline at end of file
diff --git a/script/app-mlperf-inference-ctuning-cpp-tflite/_cm.json b/script/app-mlperf-inference-ctuning-cpp-tflite/_cm.json
new file mode 100644
index 0000000000..17caa8047a
--- /dev/null
+++ b/script/app-mlperf-inference-ctuning-cpp-tflite/_cm.json
@@ -0,0 +1,427 @@
+{
+ "alias": "app-mlperf-inference-ctuning-cpp-tflite",
+ "automation_alias": "script",
+ "automation_uid": "5b4e0237da074764",
+ "category": "Modular MLPerf inference benchmark pipeline",
+ "default_env": {
+ "CM_DATASET_COMPRESSED": "off",
+ "CM_DATASET_INPUT_SQUARE_SIDE": "224",
+ "CM_FAST_COMPILATION": "yes",
+ "CM_LOADGEN_BUFFER_SIZE": "1024",
+ "CM_MLPERF_LOADGEN_MODE": "accuracy",
+ "CM_MLPERF_LOADGEN_SCENARIO": "SingleStream",
+ "CM_MLPERF_LOADGEN_TRIGGER_COLD_RUN": "0",
+ "CM_MLPERF_OUTPUT_DIR": ".",
+ "CM_MLPERF_SUT_NAME_IMPLEMENTATION_PREFIX": "tflite_cpp",
+ "CM_MLPERF_TFLITE_USE_NEON": "0",
+ "CM_MLPERF_TFLITE_USE_OPENCL": "0",
+ "CM_ML_MODEL_GIVEN_CHANNEL_MEANS": "123.68 116.78 103.94",
+ "CM_ML_MODEL_NORMALIZE_DATA": "0",
+ "CM_ML_MODEL_SUBTRACT_MEANS": "1",
+ "CM_VERBOSE": "0"
+ },
+ "deps": [
+ {
+ "tags": "detect,os"
+ },
+ {
+ "tags": "detect,cpu"
+ },
+ {
+ "tags": "get,sys-utils-cm"
+ },
+ {
+ "enable_if_env": {
+ "CM_MLPERF_DEVICE": [
+ "gpu"
+ ]
+ },
+ "tags": "get,cuda"
+ },
+ {
+ "names": [
+ "loadgen"
+ ],
+ "tags": "get,loadgen"
+ },
+ {
+ "names": [
+ "inference-src"
+ ],
+ "tags": "get,mlcommons,inference,src"
+ },
+ {
+ "enable_if_env": {
+ "CM_MLPERF_BACKEND": [
+ "tflite",
+ "armnn_tflite"
+ ],
+ "CM_MODEL": [
+ "mobilenet"
+ ]
+ },
+ "names": [
+ "ml-model",
+ "tflite-model",
+ "mobilenet-model"
+ ],
+ "tags": "get,ml-model,mobilenet,raw,_tflite"
+ },
+ {
+ "enable_if_env": {
+ "CM_MLPERF_BACKEND": [
+ "tflite",
+ "armnn_tflite"
+ ],
+ "CM_MODEL": [
+ "resnet50"
+ ]
+ },
+ "names": [
+ "ml-model",
+ "tflite-model",
+ "resnet50-model"
+ ],
+ "tags": "get,ml-model,resnet50,raw,_tflite,_no-argmax"
+ },
+ {
+ "enable_if_env": {
+ "CM_MLPERF_BACKEND": [
+ "tf"
+ ],
+ "CM_MODEL": [
+ "resnet50"
+ ]
+ },
+ "names": [
+ "ml-model",
+ "tflite-model",
+ "resnet50-model"
+ ],
+ "tags": "get,ml-model,resnet50,raw,_tf"
+ },
+ {
+ "enable_if_env": {
+ "CM_MLPERF_BACKEND": [
+ "tflite",
+ "armnn_tflite"
+ ],
+ "CM_MODEL": [
+ "efficientnet"
+ ]
+ },
+ "names": [
+ "ml-model",
+ "tflite-model",
+ "efficientnet-model"
+ ],
+ "tags": "get,ml-model,efficientnet,raw,_tflite"
+ },
+ {
+ "tags": "get,tensorflow,lib,_tflite"
+ },
+ {
+ "enable_if_env": {
+ "CM_MLPERF_TFLITE_USE_ARMNN": [
+ "yes"
+ ]
+ },
+ "names": [
+ "armnn",
+ "lib-armnn"
+ ],
+ "tags": "get,lib,armnn"
+ }
+ ],
+ "input_mapping": {
+ "compressed_dataset": "CM_DATASET_COMPRESSED",
+ "count": "CM_MLPERF_LOADGEN_QUERY_COUNT",
+ "mlperf_conf": "CM_MLPERF_CONF",
+ "mode": "CM_MLPERF_LOADGEN_MODE",
+ "output_dir": "CM_MLPERF_OUTPUT_DIR",
+ "performance_sample_count": "CM_MLPERF_LOADGEN_PERFORMANCE_SAMPLE_COUNT",
+ "scenario": "CM_MLPERF_LOADGEN_SCENARIO",
+ "user_conf": "CM_MLPERF_USER_CONF",
+ "verbose": "CM_VERBOSE"
+ },
+ "new_env_keys": [
+ "CM_MLPERF_*",
+ "CM_ML_MODEL_*",
+ "CM_HW_NAME"
+ ],
+ "new_state_keys": [
+ "CM_SUT_*"
+ ],
+ "post_deps": [
+ {
+ "names": [
+ "compiler-program"
+ ],
+ "skip_if_env": {
+ "CM_MLPERF_SKIP_RUN": [
+ "yes"
+ ]
+ },
+ "tags": "compile,program"
+ },
+ {
+ "names": [
+ "mlperf-runner"
+ ],
+ "skip_if_env": {
+ "CM_MLPERF_SKIP_RUN": [
+ "yes"
+ ]
+ },
+ "tags": "benchmark-mlperf"
+ },
+ {
+ "names": [
+ "save-mlperf-inference-state"
+ ],
+ "tags": "save,mlperf,inference,state"
+ }
+ ],
+ "prehook_deps": [
+ {
+ "names": [
+ "user-conf-generator"
+ ],
+ "tags": "generate,user-conf,mlperf,inference"
+ },
+ {
+ "enable_if_env": {
+ "CM_MLPERF_SKIP_RUN": [
+ "no"
+ ],
+ "CM_MODEL": [
+ "resnet50"
+ ]
+ },
+ "names": [
+ "imagenet-preprocessed",
+ "preprocessed-dataset"
+ ],
+ "skip_if_env": {
+ "CM_DATASET_COMPRESSED": [
+ "on"
+ ]
+ },
+ "tags": "get,dataset,preprocessed,imagenet,_for.resnet50,_rgb32,_NHWC",
+ "update_tags_from_env": [
+ "CM_DATASET_PREPROCESSED_IMAGENET_DEP_TAGS"
+ ]
+ },
+ {
+ "enable_if_env": {
+ "CM_MLPERF_SKIP_RUN": [
+ "no"
+ ],
+ "CM_MODEL": [
+ "mobilenet",
+ "efficientnet"
+ ]
+ },
+ "names": [
+ "imagenet-preprocessed",
+ "preprocessed-dataset"
+ ],
+ "skip_if_env": {
+ "CM_DATASET_COMPRESSED": [
+ "on"
+ ]
+ },
+ "tags": "get,dataset,preprocessed,imagenet,_for.mobilenet,_rgb32,_NHWC",
+ "update_tags_from_env": [
+ "CM_DATASET_PREPROCESSED_IMAGENET_DEP_TAGS"
+ ]
+ },
+ {
+ "enable_if_env": {
+ "CM_DATASET_COMPRESSED": [
+ "on"
+ ],
+ "CM_MLPERF_SKIP_RUN": [
+ "no"
+ ],
+ "CM_MODEL": [
+ "mobilenet",
+ "efficientnet"
+ ]
+ },
+ "names": [
+ "imagenet-preprocessed",
+ "preprocessed-dataset"
+ ],
+ "tags": "get,dataset,preprocessed,imagenet,_for.mobilenet,_rgb8,_NHWC",
+ "update_tags_from_env": [
+ "CM_DATASET_PREPROCESSED_IMAGENET_DEP_TAGS"
+ ]
+ },
+ {
+ "enable_if_env": {
+ "CM_DATASET_COMPRESSED": [
+ "on"
+ ],
+ "CM_MLPERF_SKIP_RUN": [
+ "no"
+ ],
+ "CM_MODEL": [
+ "resnet50"
+ ]
+ },
+ "names": [
+ "imagenet-preprocessed",
+ "preprocessed-dataset"
+ ],
+ "tags": "get,dataset,preprocessed,imagenet,_for.resnet50,_rgb8,_NHWC",
+ "update_tags_from_env": [
+ "CM_DATASET_PREPROCESSED_IMAGENET_DEP_TAGS"
+ ]
+ }
+ ],
+ "tags": [
+ "app",
+ "mlcommons",
+ "mlperf",
+ "inference",
+ "tflite-cpp"
+ ],
+ "tags_help": "app mlperf inference tflite-cpp",
+ "uid": "415904407cca404a",
+ "variations": {
+ "armnn": {
+ "default_variations": {
+ "optimization-target": "use-neon"
+ },
+ "env": {
+ "CM_MLPERF_TFLITE_USE_ARMNN": "yes",
+ "CM_TMP_LINK_LIBS": "tensorflowlite,armnn"
+ }
+ },
+ "armnn,tflite": {
+ "env": {
+ "CM_MLPERF_BACKEND": "armnn_tflite",
+ "CM_MLPERF_BACKEND_VERSION": "<<>>",
+ "CM_MLPERF_SUT_NAME_IMPLEMENTATION_PREFIX": "tflite_armnn_cpp",
+ "CM_TMP_LINK_LIBS": "tensorflowlite,armnn,armnnTfLiteParser",
+ "CM_TMP_SRC_FOLDER": "armnn"
+ }
+ },
+ "cpu": {
+ "default": true,
+ "env": {
+ "CM_MLPERF_DEVICE": "cpu"
+ },
+ "group": "device"
+ },
+ "efficientnet": {
+ "env": {
+ "CM_MODEL": "efficientnet"
+ },
+ "group": "model"
+ },
+ "fp32": {
+ "adr": {
+ "ml-model": {
+ "tags": "_fp32"
+ },
+ "preprocessed-dataset": {
+ "tags": "_float32"
+ }
+ },
+ "default": true,
+ "env": {
+ "CM_MLPERF_MODEL_PRECISION": "float32"
+ },
+ "group": "precision"
+ },
+ "gpu": {
+ "env": {
+ "CM_MLPERF_DEVICE": "gpu",
+ "CM_MLPERF_DEVICE_LIB_NAMESPEC": "cudart"
+ },
+ "group": "device"
+ },
+ "int8": {
+ "adr": {
+ "ml-model": {
+ "tags": "_int8"
+ },
+ "preprocessed-dataset": {
+ "tags": "_int8"
+ }
+ },
+ "env": {
+ "CM_DATASET_COMPRESSED": "on",
+ "CM_MLPERF_MODEL_PRECISION": "int8"
+ },
+ "group": "precision"
+ },
+ "mobilenet": {
+ "env": {
+ "CM_MODEL": "mobilenet"
+ },
+ "group": "model"
+ },
+ "resnet50": {
+ "default": true,
+ "env": {
+ "CM_MODEL": "resnet50"
+ },
+ "group": "model"
+ },
+ "singlestream": {
+ "default": true,
+ "env": {
+ "CM_MLPERF_LOADGEN_SCENARIO": "SingleStream"
+ },
+ "group": "loadgen-scenario"
+ },
+ "tf": {
+ "env": {
+ "CM_MLPERF_BACKEND": "tf"
+ },
+ "group": "backend"
+ },
+ "tflite": {
+ "default": true,
+ "env": {
+ "CM_MLPERF_BACKEND": "tflite",
+ "CM_MLPERF_BACKEND_VERSION": "master",
+ "CM_TMP_LINK_LIBS": "tensorflowlite",
+ "CM_TMP_SRC_FOLDER": "src"
+ },
+ "group": "backend"
+ },
+ "uint8": {
+ "adr": {
+ "ml-model": {
+ "tags": "_uint8"
+ },
+ "preprocessed-dataset": {
+ "tags": "_int8"
+ }
+ },
+ "env": {
+ "CM_DATASET_COMPRESSED": "on",
+ "CM_MLPERF_MODEL_PRECISION": "uint8"
+ },
+ "group": "precision"
+ },
+ "use-neon": {
+ "env": {
+ "CM_MLPERF_SUT_NAME_RUN_CONFIG_SUFFIX1": "using_neon",
+ "CM_MLPERF_TFLITE_USE_NEON": "1"
+ },
+ "group": "optimization-target"
+ },
+ "use-opencl": {
+ "env": {
+ "CM_MLPERF_SUT_NAME_RUN_CONFIG_SUFFIX1": "using_opencl",
+ "CM_MLPERF_TFLITE_USE_OPENCL": "1"
+ },
+ "group": "optimization-target"
+ }
+ }
+}
diff --git a/script/app-mlperf-inference-ctuning-cpp-tflite/armnn/classification.cpp b/script/app-mlperf-inference-ctuning-cpp-tflite/armnn/classification.cpp
new file mode 100644
index 0000000000..c641e9d1e7
--- /dev/null
+++ b/script/app-mlperf-inference-ctuning-cpp-tflite/armnn/classification.cpp
@@ -0,0 +1,399 @@
+/*
+ * Copyright (c) 2018 cTuning foundation.
+ * See CK COPYRIGHT.txt for copyright details.
+ *
+ * See CK LICENSE for licensing details.
+ * See CK COPYRIGHT for copyright details.
+ */
+
+#include
+#include
+#include
+
+#include "armnn/ArmNN.hpp"
+#include "armnn/Exceptions.hpp"
+#include "armnn/Tensor.hpp"
+#include "armnn/INetwork.hpp"
+#include "armnnTfLiteParser/ITfLiteParser.hpp"
+
+#include "loadgen.h"
+#include "query_sample_library.h"
+#include "system_under_test.h"
+#include "test_settings.h"
+
+
+#include "benchmark.h"
+
+#include "tensorflow/lite/kernels/register.h"
+#include "tensorflow/lite/model.h"
+
+using namespace std;
+using namespace CK;
+
+
+template
+
+class ArmNNBenchmark : public Benchmark {
+public:
+ ArmNNBenchmark(const BenchmarkSettings* settings, TData *in_ptr, TData *out_ptr)
+ : Benchmark(settings, in_ptr, out_ptr) {
+ }
+};
+
+armnn::InputTensors MakeInputTensors(const std::pair& input, const void* inputTensorData)
+{
+ return { {input.first, armnn::ConstTensor(input.second, inputTensorData) } };
+}
+
+armnn::OutputTensors MakeOutputTensors(const std::pair& output, void* outputTensorData)
+{
+ return { {output.first, armnn::Tensor(output.second, outputTensorData) } };
+}
+
+class Program {
+public:
+ Program () : runtime( armnn::IRuntime::Create(options) ) {
+
+ bool use_neon = getenv_b("CM_MLPERF_TFLITE_USE_NEON");
+ bool use_opencl = getenv_b("CM_MLPERF_TFLITE_USE_OPENCL");
+ string input_layer_name = getenv_s("CM_ML_MODEL_INPUT_LAYER_NAME");
+ string output_layer_name = getenv_s("CM_ML_MODEL_OUTPUT_LAYER_NAME");
+
+ settings = new BenchmarkSettings(MODEL_TYPE::LITE);
+
+ session = new BenchmarkSession(settings);
+
+ armnnTfLiteParser::ITfLiteParserPtr parser = armnnTfLiteParser::ITfLiteParser::Create();
+
+ // Optimize the network for a specific runtime compute device, e.g. CpuAcc, GpuAcc
+ //std::vector optOptions = {armnn::Compute::CpuAcc, armnn::Compute::GpuAcc};
+ std::vector optOptions = {armnn::Compute::CpuRef};
+ if( use_neon && use_opencl) {
+ optOptions = {armnn::Compute::CpuAcc, armnn::Compute::GpuAcc};
+ } else if( use_neon ) {
+ optOptions = {armnn::Compute::CpuAcc};
+ } else if( use_opencl ) {
+ optOptions = {armnn::Compute::GpuAcc};
+ }
+
+ cout << "\nLoading graph..." << endl;
+
+ armnn::INetworkPtr network = parser->CreateNetworkFromBinaryFile(settings->graph_file().c_str());
+ if (!network)
+ throw "Failed to load graph from file";
+
+ armnnTfLiteParser::BindingPointInfo inputBindingInfo = parser->GetNetworkInputBindingInfo(0, input_layer_name);
+ armnnTfLiteParser::BindingPointInfo outputBindingInfo = parser->GetNetworkOutputBindingInfo(0, output_layer_name);
+
+ armnn::TensorShape inShape = inputBindingInfo.second.GetShape();
+ armnn::TensorShape outShape = outputBindingInfo.second.GetShape();
+ std::size_t inSize = inShape[0] * inShape[1] * inShape[2] * inShape[3];
+ std::size_t outSize = outShape[0] * outShape[1];
+
+ armnn::IOptimizedNetworkPtr optNet = armnn::Optimize(*network, optOptions, runtime->GetDeviceSpec());
+
+ runtime->LoadNetwork(networkIdentifier, std::move(optNet));
+
+ armnn::DataType input_type = inputBindingInfo.second.GetDataType();
+ armnn::DataType output_type = outputBindingInfo.second.GetDataType();
+ if (input_type != output_type)
+ throw format("Type of graph's input (%d) does not match type of its output (%d).", int(input_type), int(output_type));
+
+ void* input = input_type == armnn::DataType::Float32 ? (void*)new float[inSize] : (void*)new uint8_t[inSize];
+ void* output = output_type == armnn::DataType::Float32 ? (void*)new float[outSize] : (void*)new uint8_t[outSize];
+
+ inputTensor = MakeInputTensors(inputBindingInfo, input);
+ outputTensor = MakeOutputTensors(outputBindingInfo, output);
+
+ switch (input_type) {
+ case armnn::DataType::Float32:
+ if (settings->skip_internal_preprocessing) {
+ cout << "************* Type 1" << endl;
+ benchmark.reset(new ArmNNBenchmark(settings, (float*)input, (float*)output));
+ } else {
+ cout << "************* Type 2" << endl;
+ benchmark.reset(new ArmNNBenchmark(settings, (float*)input, (float*)output));
+ }
+ break;
+
+ case armnn::DataType::QAsymmU8:
+ benchmark.reset(new ArmNNBenchmark(settings, (uint8_t*)input, (uint8_t*)output));
+ break;
+
+ default:
+ throw format("Unsupported type of graph's input: %d. "
+ "Supported types are: Float32 (%d), UInt8 (%d)",
+ int(input_type), int(armnn::DataType::Float32), int(armnn::DataType::QAsymmU8));
+ }
+
+ int out_num = outShape[0];
+ int out_classes = outShape[1];
+ cout << format("Output tensor dimensions: %d*%d", out_num, out_classes) << endl;
+ if (out_classes != settings->num_classes && out_classes != settings->num_classes+1)
+ throw format("Unsupported number of classes in graph's output tensor. Supported numbers are %d and %d",
+ settings->num_classes, settings->num_classes+1);
+ benchmark->has_background_class = out_classes == settings->num_classes+1;
+ }
+
+ ~Program() {
+ }
+
+ //bool is_available_batch() {return session? session->get_next_batch(): false; }
+
+ void LoadNextBatch(const std::vector& img_indices) {
+ auto vl = settings->verbosity_level;
+
+ if( vl > 1 ) {
+ cout << "LoadNextBatch([";
+ for( auto idx : img_indices) {
+ cout << idx << ' ';
+ }
+ cout << "])" << endl;
+ } else if( vl ) {
+ cout << 'B' << flush;
+ }
+ session->load_filenames(img_indices);
+ benchmark->load_images( session );
+
+ if( vl ) {
+ cout << endl;
+ }
+ }
+
+ void ColdRun() {
+ auto vl = settings->verbosity_level;
+
+ if( vl > 1 ) {
+ cout << "Triggering a Cold Run..." << endl;
+ } else if( vl ) {
+ cout << 'C' << flush;
+ }
+
+ if (runtime->EnqueueWorkload(networkIdentifier, inputTensor, outputTensor) != armnn::Status::Success)
+ throw "Failed to invoke the classifier";
+ }
+
+ int InferenceOnce(int img_idx) {
+ benchmark->get_random_image( img_idx );
+
+ if (runtime->EnqueueWorkload(networkIdentifier, inputTensor, outputTensor) != armnn::Status::Success)
+ throw "Failed to invoke the classifier";
+
+ return benchmark->get_next_result();
+ }
+
+ void UnloadBatch(const std::vector& img_indices) {
+ auto b_size = img_indices.size();
+
+ auto vl = settings->verbosity_level;
+
+ if( vl > 1 ) {
+ cout << "Unloading a batch[" << b_size << "]" << endl;
+ } else if( vl ) {
+ cout << 'U' << flush;
+ }
+
+ benchmark->unload_images(b_size);
+ //benchmark->save_results( );
+ }
+
+ const int available_images_max() { return settings->list_of_available_imagefiles().size(); }
+ const int images_in_memory_max() { return settings->images_in_memory_max; }
+
+ BenchmarkSettings *settings;
+private:
+ BenchmarkSession *session;
+ unique_ptr benchmark;
+ armnn::NetworkId networkIdentifier;
+ armnn::OutputTensors outputTensor;
+ armnn::InputTensors inputTensor;
+ armnn::IRuntime::CreationOptions options;
+ armnn::IRuntimePtr runtime;
+};
+
+class SystemUnderTestSingleStream : public mlperf::SystemUnderTest {
+public:
+ SystemUnderTestSingleStream(Program *_prg) : mlperf::SystemUnderTest() {
+ prg = _prg;
+ query_counter = 0;
+ };
+
+ ~SystemUnderTestSingleStream() override = default;
+
+ const std::string& Name() { return name_; }
+
+ void IssueQuery(const std::vector& samples) override {
+
+ ++query_counter;
+ auto vl = prg->settings->verbosity_level;
+ if( vl > 1 ) {
+ cout << query_counter << ") IssueQuery([" << samples.size() << "]," << samples[0].id << "," << samples[0].index << ")" << endl;
+ } else if ( vl ) {
+ cout << 'Q' << flush;
+ }
+
+ std::vector responses;
+ responses.reserve(samples.size());
+ float encoding_buffer[samples.size()];
+ int i=0;
+ for (auto s : samples) {
+ int predicted_class = prg->InferenceOnce(s.index);
+
+ if( vl > 1 ) {
+ cout << "Query image index: " << s.index << " -> Predicted class: " << predicted_class << endl << endl;
+ } else if ( vl ) {
+ cout << 'p' << flush;
+ }
+
+ /* This would be the correct way to pass in one integer index:
+ */
+// int single_value_buffer[] = { (int)predicted_class };
+
+ /* This conversion is subtly but terribly wrong
+ yet we use it here in order to use Guenther's parsing script:
+ */
+ encoding_buffer[i] = (float)predicted_class;
+ responses.push_back({s.id, uintptr_t(&encoding_buffer[i]), sizeof(encoding_buffer[i])});
+ ++i;
+ }
+ mlperf::QuerySamplesComplete(responses.data(), responses.size());
+ }
+
+ void FlushQueries() override {
+ auto vl = prg->settings->verbosity_level;
+ if ( vl ) {
+ cout << endl;
+ }
+ }
+
+ void ReportLatencyResults(const std::vector& latencies_ns) {
+
+ size_t size = latencies_ns.size();
+ uint64_t avg = accumulate(latencies_ns.begin(), latencies_ns.end(), uint64_t(0) )/size;
+
+ std::vector sorted_lat(latencies_ns.begin(), latencies_ns.end());
+ sort(sorted_lat.begin(), sorted_lat.end());
+
+ cout << endl << "------------------------------------------------------------";
+ cout << endl << "| LATENCIES (in nanoseconds and fps) |";
+ cout << endl << "------------------------------------------------------------";
+ size_t p50 = size * 0.5;
+ size_t p90 = size * 0.9;
+ cout << endl << "Number of queries run: " << size;
+ cout << endl << "Min latency: " << sorted_lat[0] << "ns (" << 1e9/sorted_lat[0] << " fps)";
+ cout << endl << "Median latency: " << sorted_lat[p50] << "ns (" << 1e9/sorted_lat[p50] << " fps)";
+ cout << endl << "Average latency: " << avg << "ns (" << 1e9/avg << " fps)";
+ cout << endl << "90 percentile latency: " << sorted_lat[p90] << "ns (" << 1e9/sorted_lat[p90] << " fps)";
+
+ if(!prg->settings->trigger_cold_run) {
+ cout << endl << "First query (cold model) latency: " << latencies_ns[0] << "ns (" << 1e9/latencies_ns[0] << " fps)";
+ }
+ cout << endl << "Max latency: " << sorted_lat[size-1] << "ns (" << 1e9/sorted_lat[size-1] << " fps)";
+ cout << endl << "------------------------------------------------------------ " << endl;
+ }
+
+private:
+ std::string name_{"TFLite_SUT"};
+ Program *prg;
+ long query_counter;
+};
+
+class QuerySampleLibrarySingleStream : public mlperf::QuerySampleLibrary {
+public:
+ QuerySampleLibrarySingleStream(Program *_prg) : mlperf::QuerySampleLibrary() {
+ prg = _prg;
+ };
+
+ ~QuerySampleLibrarySingleStream() = default;
+
+ const std::string& Name() override { return name_; }
+
+ size_t TotalSampleCount() override { return prg->available_images_max(); }
+
+ size_t PerformanceSampleCount() override { return prg->images_in_memory_max(); }
+
+ void LoadSamplesToRam( const std::vector& samples) override {
+ prg->LoadNextBatch(samples);
+ return;
+ }
+
+ void UnloadSamplesFromRam( const std::vector& samples) override {
+ prg->UnloadBatch(samples);
+ return;
+ }
+
+private:
+ std::string name_{"TFLite_QSL"};
+ Program *prg;
+};
+
+void TestSingleStream(Program *prg) {
+ SystemUnderTestSingleStream sut(prg);
+ QuerySampleLibrarySingleStream qsl(prg);
+
+ const std::string mlperf_conf_path = getenv_s("CM_MLPERF_CONF");
+ const std::string user_conf_path = getenv_s("CM_MLPERF_USER_CONF");
+
+ std::string model_name = getenv_opt_s("CM_MODEL", "unknown_model");
+ std::string logs_dir = getenv_opt_s("CM_MLPERF_LOADGEN_LOGS_DIR", "");
+
+ const std::string scenario_string = getenv_s("CM_MLPERF_LOADGEN_SCENARIO");
+ const std::string mode_string = getenv_s("CM_MLPERF_LOADGEN_MODE");
+
+ std::cout << "Path to mlperf.conf : " << mlperf_conf_path << std::endl;
+ std::cout << "Path to user.conf : " << user_conf_path << std::endl;
+ std::cout << "Model Name: " << model_name << std::endl;
+ std::cout << "LoadGen Scenario: " << scenario_string << std::endl;
+ std::cout << "LoadGen Mode: " << ( mode_string != "" ? mode_string : "(empty string)" ) << std::endl;
+
+ mlperf::TestSettings ts;
+
+ // This should have been done automatically inside ts.FromConfig() !
+ ts.scenario = ( scenario_string == "SingleStream") ? mlperf::TestScenario::SingleStream
+ : ( scenario_string == "MultiStream") ? mlperf::TestScenario::MultiStream
+ : ( scenario_string == "Server") ? mlperf::TestScenario::Server
+ : ( scenario_string == "Offline") ? mlperf::TestScenario::Offline : mlperf::TestScenario::SingleStream;
+
+ if( mode_string != "")
+ ts.mode = ( mode_string == "SubmissionRun") ? mlperf::TestMode::SubmissionRun
+ : ( mode_string == "accuracy") ? mlperf::TestMode::AccuracyOnly
+ : ( mode_string == "performance") ? mlperf::TestMode::PerformanceOnly
+ : ( mode_string == "findpeakperformance") ? mlperf::TestMode::FindPeakPerformance : mlperf::TestMode::SubmissionRun;
+
+ if (ts.FromConfig(mlperf_conf_path, model_name, scenario_string)) {
+ std::cout << "Issue with mlperf.conf file at " << mlperf_conf_path << std::endl;
+ exit(1);
+ }
+
+ if (ts.FromConfig(user_conf_path, model_name, scenario_string)) {
+ std::cout << "Issue with user.conf file at " << user_conf_path << std::endl;
+ exit(1);
+ }
+
+ mlperf::LogSettings log_settings;
+ log_settings.log_output.outdir = logs_dir;
+ log_settings.log_output.prefix_with_datetime = false;
+ log_settings.enable_trace = false;
+
+
+ if (prg->settings->trigger_cold_run) {
+ prg->ColdRun();
+ }
+
+ mlperf::StartTest(&sut, &qsl, ts, log_settings);
+}
+
+int main(int argc, char* argv[]) {
+ try {
+ Program *prg = new Program();
+ TestSingleStream(prg);
+ delete prg;
+ }
+ catch (const string& error_message) {
+ cerr << "ERROR: " << error_message << endl;
+ return -1;
+ }
+ return 0;
+}
diff --git a/script/app-mlperf-inference-ctuning-cpp-tflite/customize.py b/script/app-mlperf-inference-ctuning-cpp-tflite/customize.py
new file mode 100644
index 0000000000..ebd588c9f2
--- /dev/null
+++ b/script/app-mlperf-inference-ctuning-cpp-tflite/customize.py
@@ -0,0 +1,96 @@
+from cmind import utils
+import os
+import shutil
+
+def preprocess(i):
+
+ os_info = i['os_info']
+
+ if os_info['platform'] == 'windows':
+ return {'return':1, 'error': 'Windows is not supported in this script yet'}
+ env = i['env']
+
+ if env.get('CM_MLPERF_SKIP_RUN', '') == "yes":
+ return {'return':0}
+
+ if 'CM_MODEL' not in env:
+ return {'return': 1, 'error': 'Please select a variation specifying the model to run'}
+ if 'CM_MLPERF_BACKEND' not in env:
+ return {'return': 1, 'error': 'Please select a variation specifying the backend'}
+ if 'CM_MLPERF_DEVICE' not in env:
+ return {'return': 1, 'error': 'Please select a variation specifying the device to run on'}
+
+ source_files = []
+ script_path = i['run_script_input']['path']
+
+ env['CM_SOURCE_FOLDER_PATH'] = os.path.join(script_path, env['CM_TMP_SRC_FOLDER'])
+
+ for file in os.listdir(env['CM_SOURCE_FOLDER_PATH']):
+ if file.endswith(".c") or file.endswith(".cpp"):
+ source_files.append(file)
+
+ env['CM_CXX_SOURCE_FILES'] = ";".join(source_files)
+
+ if '+CPLUS_INCLUDE_PATH' not in env:
+ env['+CPLUS_INCLUDE_PATH'] = []
+
+ env['+CPLUS_INCLUDE_PATH'].append(os.path.join(script_path, "inc"))
+ env['+C_INCLUDE_PATH'].append(os.path.join(script_path, "inc"))
+
+ # TODO: get cuda path ugly fix
+ if env['CM_MLPERF_DEVICE'] == 'gpu':
+ env['+C_INCLUDE_PATH'].append(env['CM_CUDA_PATH_INCLUDE'])
+ env['+CPLUS_INCLUDE_PATH'].append(env['CM_CUDA_PATH_INCLUDE'])
+ env['+LD_LIBRARY_PATH'].append(env['CM_CUDA_PATH_LIB'])
+ env['+DYLD_FALLBACK_LIBRARY_PATH'].append(env['CM_CUDA_PATH_INCLUDE'])
+
+ if '+ CXXFLAGS' not in env:
+ env['+ CXXFLAGS'] = []
+ env['+ CXXFLAGS'].append("-std=c++17")
+
+ # add preprocessor flag like "#define CM_MODEL_RESNET50"
+ env['+ CXXFLAGS'].append('-DCM_MODEL_' + env['CM_MODEL'].upper())
+ # add preprocessor flag like "#define CM_MLPERF_BACKEND_ONNXRUNTIME"
+ env['+ CXXFLAGS'].append('-DCM_MLPERF_BACKEND_' + env['CM_MLPERF_BACKEND'].upper())
+ # add preprocessor flag like "#define CM_MLPERF_DEVICE_CPU"
+ env['+ CXXFLAGS'].append('-DCM_MLPERF_DEVICE_' + env['CM_MLPERF_DEVICE'].upper())
+
+ if '+ LDCXXFLAGS' not in env:
+ env['+ LDCXXFLAGS'] = [ ]
+
+ env['+ LDCXXFLAGS'] += [
+ "-lmlperf_loadgen",
+ "-lpthread"
+ ]
+ # e.g. -lonnxruntime
+ if 'CM_MLPERF_BACKEND_LIB_NAMESPEC' in env:
+ env['+ LDCXXFLAGS'].append('-l' + env['CM_MLPERF_BACKEND_LIB_NAMESPEC'])
+ # e.g. -lcudart
+ if 'CM_MLPERF_DEVICE_LIB_NAMESPEC' in env:
+ env['+ LDCXXFLAGS'].append('-l' + env['CM_MLPERF_DEVICE_LIB_NAMESPEC'])
+
+ if env.get('CM_TMP_LINK_LIBS', []):
+ libs = env['CM_TMP_LINK_LIBS'].split(",")
+ for lib in libs:
+ env['+ LDCXXFLAGS'].append(' -l'+lib)
+
+ env['CM_LINKER_LANG'] = 'CXX'
+ env['CM_RUN_DIR'] = os.getcwd()
+
+ if 'CM_MLPERF_CONF' not in env:
+ env['CM_MLPERF_CONF'] = os.path.join(env['CM_MLPERF_INFERENCE_SOURCE'], "mlperf.conf")
+ if 'CM_MLPERF_USER_CONF' not in env:
+ env['CM_MLPERF_USER_CONF'] = os.path.join(env['CM_MLPERF_INFERENCE_CLASSIFICATION_AND_DETECTION_PATH'], "user.conf")
+
+ if env.get('CM_DATASET_COMPRESSED', "no").lower() in [ "yes", "on", "true"] and "float" in env.get('CM_MLPERF_MODEL_PRECISION', ''):
+ env['CM_HOST_USE_ALL_CORES'] = "yes" #Use all cores for input preprocessing
+ env['CM_MLPERF_SUT_NAME_RUN_CONFIG_SUFFIX2'] = "with_live_preprocessing"
+
+ return {'return':0}
+
+def postprocess(i):
+
+ env = i['env']
+ state = i['state']
+
+ return {'return':0}
diff --git a/script/app-mlperf-inference-ctuning-cpp-tflite/inc/benchmark.h b/script/app-mlperf-inference-ctuning-cpp-tflite/inc/benchmark.h
new file mode 100644
index 0000000000..76f1209a80
--- /dev/null
+++ b/script/app-mlperf-inference-ctuning-cpp-tflite/inc/benchmark.h
@@ -0,0 +1,488 @@
+/*
+ * Copyright (c) 2018 cTuning foundation.
+ * See CK COPYRIGHT.txt for copyright details.
+ *
+ * See CK LICENSE for licensing details.
+ * See CK COPYRIGHT for copyright details.
+ */
+
+#pragma once
+
+#include
+#include
+
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include