{kind=link}
This repo provides the tools to clean and correct the test sets for ten of the most common ML benchmark test sets: ImageNet, MNIST, CIFAR-10, CIFAR-100, Caltech-256, QuickDraw, IMDB, Amazon Reviews, 20News, and AudioSet.
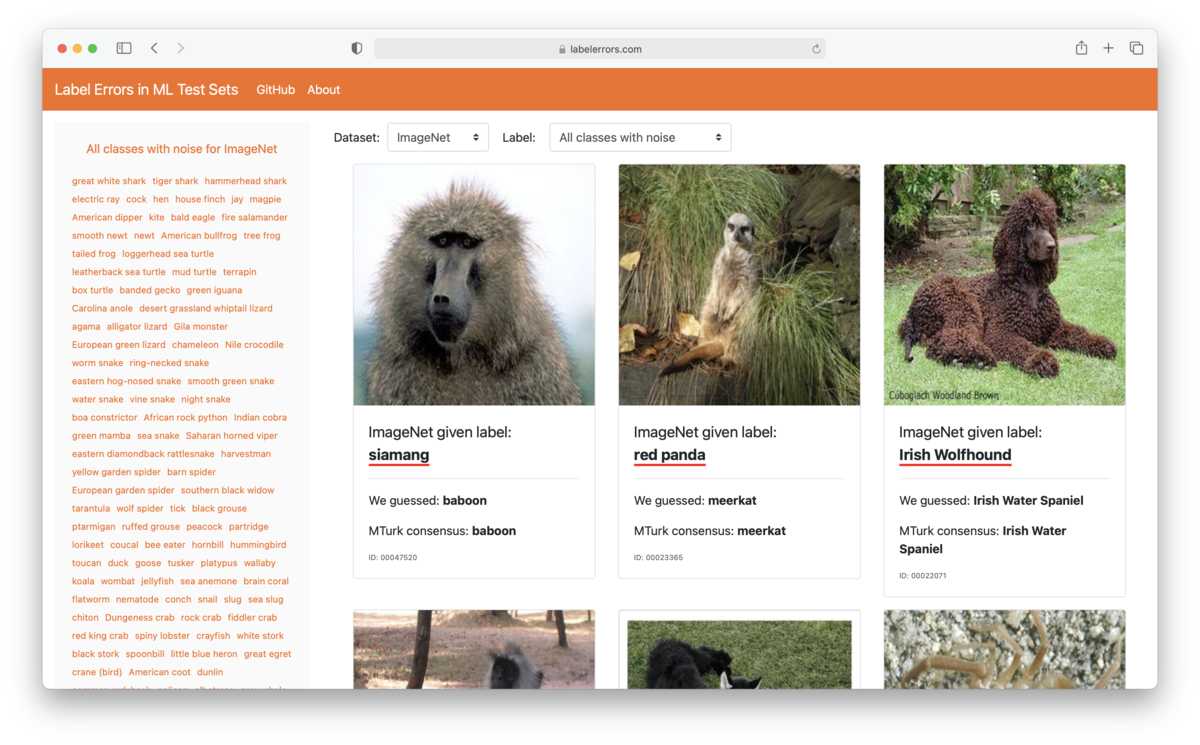
Browse the label errors at https://labelerrors.com
Reproduce the label errors in each dataset via label-errors/examples/Tutorial - How To Find Label Errors With CleanLab.ipynb.
Corrections are better than the datasets' given test labels, but they are NOT 100% perfect, nor are they intended to be. Some mistakes still exist. Please report errors (with corrections) [here].
Label errors are found based on confident learning via the open-source cleanlab package. Specifically, cleanlab v1.0 was used, which you need to install to run any cleanlab code from this repo.
In this repo, we provide the following for each of the ten datasets:
- label-errors/cross_validated_predicted_labels/
- type:
np.array<np.float16>of shapenum_examples x num_classes
- type:
- label-errors/cross_validated_predicted_probabilities/
- type:
np.array<np.uint16>of lengthnum_examples(np.arrayofnp.arraysfor AudioSet because it is multi-label)
- type:
- label-errors/original_test_labels/
- type:
np.array<np.uint16>of lengthnum_examples(np.arrayofnp.arraysfor AudioSet because it is multi-label)
- type:
- label-errors/mturk/
- type: JSON (varying schemas)
- Contains the mTurk human-validated corrected labels for each test set.
- label-errors/dataset_indexing/
- type: JSON (varying schemas)
- Indexes files in datasets which lack a global index to map the corrected labels to the original test set examples.
- For a tutorial which uses these files to find label errors for each dataset, start [here].
The pyx.npy, original_labels.npy, and predicted_labels.npy files in these folders all share the same index/order of examples for each test set. Their indices match the mechanical turk corrected labels in label-errors/mturk/. These four folders reconstruct the corrected test sets. We provide labels/probabilities for the entire dataset when the dataset does not have a pre-defined test set. To minimize file size, all labels are quantized and stored as np.uint16 and all probabilities are quantized and stored as np.float16. Note this quantization can (very slightly) affect error identification (e.g. on CIFAR-10, quantization changes the number of label errors found by 1).
Why do we provide the components to construct corrected test sets (instead of releasing a single corrected test set for each dataset)? ML practioners may need to make different decisions when correcting a test set. You may need to include multi-label examples in the corrected test set whereas we removed these examples in our analysis. You may want to only correct examples where all (5 of the 5) mTurk workers agree on a new label, or you may want to correct the label as long as a consensus (3 out of 5) is reached. The label-errors/mturk/ files support both options. For the large Amazon Reviews and QuickDraw datasets which had too many label errors to correct, we provide the tools to find the label errors.
Get started here: Tutorial - How To Find Label Errors With CleanLab.ipynb
For each dataset, I've shared code (or step-by-step instructions) to obtain the train set and test set (if a separate test set exists). Click the drop-down for each dataset to see how to download, prepare, and index/access each example in the dataset uniquely.
MNIST
from torchvision import datasets
data_dir = PATH_TO_STORE_THE_DATASET
# Obtain the test set (what we correct in this repo)
test_data = datasets.MNIST(data_dir, train=False, download=True).data.numpy()
test_labels = datasets.MNIST(data_dir, train=False, download=True).targets.numpy()
# We don't provide corrected train sets, but if interested, here is how to obtain the train set.
train_data = datasets.MNIST(data_dir, train=True, download=True).data.numpy()
train_labels = datasets.MNIST(data_dir, train=True, download=True).targets.numpy()CIFAR-10
import keras as keras
from keras.datasets import cifar10
# Obtain the test set (what we correct in this repo)
_, (test_data, test_labels) = cifar10.load_data()
# We don't provide corrected train sets, but if interested, here is how to obtain the train set.
(train_data, train_labels), _ = cifar10.load_data()CIFAR-100
import keras as keras
from keras.datasets import cifar100
# Obtain the test set (what we correct in this repo)
_, (test_data, test_labels) = cifar100.load_data()
# We don't provide corrected train sets, but if interested, here is how to obtain the train set.
(train_data, train_labels), _ = cifar100.load_data()ImageNet
You can download the ImageNet validation set (what we correct in this repo), using this link:
https://image-net.org/data/ILSVRC/2012/ILSVRC2012_img_val.tar
Or from the terminal:
wget https://image-net.org/data/ILSVRC/2012/ILSVRC2012_img_val.tarWe do not correct the train set, but if the train set is obtained similarly, using this link:
https://image-net.org/data/ILSVRC/2012/ILSVRC2012_img_train.tar
If any of the above links stop working, go here: https://image-net.org/challenges/LSVRC/2012/2012-downloads.php Create an account, and download the datasets directly from the site. Be sure to download the 2012 version of the dataset!
Source of these instructions (copied below): https://github.com/soumith/imagenet-multiGPU.torch#data-processing
These instructions prepare the ImageNet dataset for the PyTorch dataloader using the convention: SubFolderName == ClassName. So, for example: if you have classes {cat,dog}, cat images go into the folder dataset/cat and dog images go into dataset/dog
The training images for imagenet are already in appropriate subfolders (like n07579787, n07880968). You need to get the validation groundtruth and move the validation images into appropriate subfolders. To do this, download ILSVRC2012_img_train.tar ILSVRC2012_img_val.tar and use the following commands:
# extract train data -- SKIP THIS IF YOU WANT, WE ONLY CORRECT THE VALIDATION SET
mkdir train && mv ILSVRC2012_img_train.tar train/ && cd train
tar -xvf ILSVRC2012_img_train.tar && rm -f ILSVRC2012_img_train.tar
find . -name "*.tar" | while read NAME ; do mkdir -p "${NAME%.tar}"; tar -xvf "${NAME}" -C "${NAME%.tar}"; rm -f "${NAME}"; done
# extract validation data -- (what we correct in this repo)
cd ../ && mkdir val && mv ILSVRC2012_img_val.tar val/ && cd val && tar -xvf ILSVRC2012_img_val.tar
wget -qO- https://raw.githubusercontent.com/soumith/imagenetloader.torch/master/valprep.sh | bashIf your imagenet dataset is on HDD or a slow SSD, run this command to resize all the images such that the smaller dimension is 256 and the aspect ratio is intact. This helps with loading the data from disk faster.
find . -name "*.JPEG" | xargs -I {} convert {} -resize "256^>" {}Caltech-256
You can download the Caltech-256 dataset using this link:
http://www.vision.caltech.edu/Image_Datasets/Caltech256/256_ObjectCategories.tar
To extract the images, via terminal:
tar -xvf 256_ObjectCategories.tarThere is no specified test set, so we correct the entire dataset.
QuickDraw
We use the numpy bitmap representation of the Google QuickDraw dataset. Download it here:
https://console.cloud.google.com/storage/browser/quickdraw_dataset/full/numpy_bitmap?pli=1
The dataset is also available on Kaggle, here: https://www.kaggle.com/drbeane/quickdraw-np
Please download the dataset into a folder called quickdraw/numpy_bitmap/.
import os
import numpy as np
# !!!CHANGE THIS TO YOUR DIRECTORY WHERE YOU DOWNLOADED THE NUMPY BITMAPS
QUICKDRAW_NUMPY_BITMAP_DIR = '/datasets/datasets/quickdraw/numpy_bitmap/'
# !!!CHANGE THESE TO WHERE YOU CLONE https://github.com/cleanlab/label-errors
# Load predictions and indices of label errors
pred = np.load('/datasets/cgn/pyx/quickdraw/pred__epochs_20.npy')
le_idx = np.load('/datasets/cgn/pyx/quickdraw/label_errors_idx__epochs_20.npy')
display_predicted_label = False # Set to true to print the predicted label.
def fetch_class_counts(numpy_bitmap_dir):
# Load class counts for QuickDraw dataset.
class_counts = []
for i, f in enumerate(sorted(os.listdir(numpy_bitmap_dir))):
loc = os.path.join(numpy_bitmap_dir, f)
with open(loc, 'rb') as rf:
line = rf.readline()
cnt = int(line.split(b'(')[1].split(b',')[0])
class_counts.append(cnt)
print('Total number of examples in QuickDraw npy files: {:,}'.format(
sum(class_counts)))
assert sum(class_counts) == 50426266
return class_counts
# Get the number of examples in each class/file based on the numpy bitmap files.
class_counts = fetch_class_counts(QUICKDRAW_NUMPY_BITMAP_DIR)
# We'll use the cumulative sum of the class counts to map the
# global index to index in each file.
counts_cumsum = np.cumsum(class_counts)
# Get the list of all class names sorted corresponding to their numerical label
# make sure you sort the filenames using sorted!
label2name = [z[:-4] for z in sorted(os.listdir(QUICKDRAW_NUMPY_BITMAP_DIR))]
# Let's look at an example from the label errors site.
# https://labelerrors.com/static/quickdraw/44601012.png
# !!!CHANGE THIS TO THE ID OF ANY QUICKDRAW ERROR ON https://labelerrors.com
# You can find the id by right-clicking the image, and copying the image url
idx = 44601012
# The true class of this image is 'angel', i.e., class 7
# The given class of this image is 'triangle', i.e., class 324
if idx >= counts_cumsum[-1]:
raise ValueError('index {} must be smaller than size of dataset {}.'.format(
idx, counts_cumsum[-1]))
# !!!The next 5 lines of code are IMPORTANT.
# Here's how you map the global index (idx) to the local index within each file.
given_label = np.argmax(counts_cumsum > idx)
if given_label > 0:
# local index = global index - the cumulative items in the previous classes
local_idx = idx - counts_cumsum[given_label - 1]
else:
# Its class 0, in the first npy file, so the local index == global index
local_idx = idx
# Check the given label matches the corresponding class name
print('\nQuickdraw Given label: {} (label id: {})'.format(
label2name[given_label], given_label))
if display_predicted_label:
print('Pred label: {} (label id: {})'.format(
label2name[pred[idx]], pred[idx]))
# Visualize the example
from matplotlib import pyplot as plt
plt.imshow(
256 - np.load(QUICKDRAW_NUMPY_BITMAP_DIR + '{}.npy'.format(
label2name[given_label]),
)[local_idx].reshape(28, 28),
interpolation='nearest',
cmap='gray',
)
plt.show()
print('^ should match https://labelerrors.com/static/quickdraw/44601012.png')If this example does not work for you, please let us know [here].
Amazon Reviews
Download [this pre-prepared release of the Amazon5core Reviews dataset].
This dataset has been prepared for you already so that the indices of the label errors will match the dataset.
# Preprocess the amazon 5 core data by running this
cat amazon5core.txt | sed -e "s/\([.\!?,'/()]\)/ \1 /g" | tr "[:upper:]" "[:lower:]" > amazon5core.preprocessed.txtExamples are available in the [cleanlab/examples/amazon_reviews_dataset] module.
IMDB
Download the dataset from: https://ai.stanford.edu/~amaas/data/sentiment/
Extract aclImdb_v1.tar.gz, i.e. in your terminal, run: tar -xzvf aclImdb_v1.tar.gz
To prepare both the train and test sets:
import os
import numpy as np
import json
# !!!CHANGE THIS TO THE LOCATION WHERE YOU EXTRACTED THE IMDB DATASET
data_dir = "/datasets/datasets/imdb/"
# This stores the order we walk through the files in the dataset
walk_order = {}
# We don't deal with train set indices, so any order is fine for the train set.
walk_order['train'] = [d + z for d in ["neg/", "pos/"] \
for z in os.listdir(data_dir + 'train/' + d)]
# Test set walk order needs to match our order to map errors correctly.
with open("../dataset_indexing/imdb_test_set_index_to_filename.json", 'r') as rf:
walk_order['test'] = json.load(rf)
# This text dict stores the text data with keys ['train', 'test']
text = {}
# Read in text data for IMDB
for dataset in ['train', 'test']:
text[dataset] = []
dataset_dir = data_dir + dataset + '/'
for i, fn in enumerate(walk_order[dataset]):
with open(dataset_dir + fn, 'r') as rf:
text[dataset].append(rf.read())
# The given labels for both train and test set are the same.
labels = np.concatenate([np.zeros(12500), np.ones(12500)]).astype(int)Now you should be able to access the test set labels via labels['test']. The indices should match the indices of the label errors we provide.
20 News
from sklearn.datasets import fetch_20newsgroups
train_data = fetch_20newsgroups(subset='train')
test_data = fetch_20newsgroups(subset='test')Both train_data and test_data are dicts with keys:
['data', 'filenames', 'target_names', 'target', 'DESCR']
The indices of test_data['data'] and test_data['target'] should match the indices of the label errors we provide.
AudioSet
AudioSet provides an eval test set and pre-computed training features (128-length 8-bit quantized embeddings for every 1 second of audio, and each audio clip is 10 seconds, resulting in a 128x10 matrix representation). The original dataset embeddings are available here, but they are formatted as tfrecords. For your convenience, we preprocessed and released a Numpy version of the AudioSet Dataset formatted using only numpy matrices and python lists. Download the dataset here: https://github.com/cleanlab/label-errors/releases/tag/numpy-audioset-dataset.
Details about the Numpy AudioSet dataset (how we processed the original AudioSet dataset and what files are contained in the dataset) are available in the release.
Your AudioSet file structure should look like this (click the files you're missing to download them):
audioset/
│── audioset_v1_embeddings/ ---> Download from https://research.google.com/audioset/download.html
│ │── balanced_train_segments.csv
│ │── bal_train (optional - tfrecords version of embeddings)
│ │── eval (optional - tfrecords version of embeddings)
│ │── eval_segments.csv
│ │── unbalanced_train_segments.csv
│ '── unbal_train (optional - tfrecords version of embeddings)
│── class_labels_indices.csv
│── preprocessed/ ---> Download here: https://github.com/cleanlab/label-errors/releases/tag/numpy-audioset-dataset.
│ │── bal_train_features.p
│ │── bal_train_labels.p
│ │── bal_train_video_ids.p
│ │── eval_features.p
│ │── eval_labels.p
│ │── eval_video_ids.p
│ │── unbal_train_features.p
│ │── unbal_train_labels.p
│ '── unbal_train_video_ids.p
import numpy as np
from sklearn.preprocessing import MultiLabelBinarizer
import pandas as pd
#!!! CHANGE THIS TO YOUR AUDIOSET MAIN DIRECTORY
audioset_main_dir = "/datasets/datasets/audioset/"
def row2url(d):
'''Converts a dict-like object to a youtube URL.'''
if type(d) == pd.DataFrame:
return "http://youtu.be/{vid}?start={s}&end={e}".format(
vid = d['# YTID'].iloc[0],
s = int(d['start_seconds'].iloc[0]),
e = int(d['end_seconds'].iloc[0]),
)
else:
return "http://youtu.be/{vid}?start={s}&end={e}".format(
vid = d['# YTID'],
s = int(d['start_seconds']),
e = int(d['end_seconds']),
)
# Information about the given (potentially noisy) test labels.
test_label_info = pd.read_csv(
audioset_main_dir + "audioset_v1_embeddings/eval_segments.csv",
header=2, delimiter=", ", engine='python', )
# Read in the labels that are now easily accessible from the pickle files.
labels = np.load(audioset_main_dir + "preprocessed/eval_labels.p", allow_pickle=True)
test_video_ids = np.load(audioset_main_dir + "preprocessed/eval_video_ids.p", allow_pickle=True)
labels_one_hot = MultiLabelBinarizer().fit_transform(labels)
# Get human-readable class name mapping
# label_df = pd.read_csv("/media/ssd/datasets/datasets/audioset/class_labels_indices.csv")
label_df = pd.read_csv(audioset_main_dir + "class_labels_indices.csv")
label2mid = list(label_df["mid"].values)
label2name = list(label_df["display_name"].values)
num_unique_labels = len(set([zz for z in labels for zz in z]))
# Convert list of labels for each test example to human-readable class names
# lol = list of labels, because the AudioSet test set is multi-label
y_test_lol = [[label2name[z] \
for z in np.arange(num_unique_labels)[p.astype(bool)]] \
for p in labels_one_hot]
# Take a look at the first few label error indices/predictions we provide
label_errors_idx = np.array([11536, 2744, 3324])
predicted_labels = dict(zip(label_errors_idx, [['Wind instrument, woodwind instrument', 'Bagpipes'], ['Singing', 'Music', 'Folk music', 'Middle Eastern music'], ['Music']]))
for idx in label_errors_idx:
row = test_label_info[test_label_info["# YTID"] == test_video_ids[0]]
print('\nIndex of test/eval example:', idx)
print('YouTube URL:', row2url(row))
print('Given Labels:', y_test_lol[idx])
print('Pred/Guessed Labels:', predicted_labels[idx])Some of these datasets, like QuickDraw, do not have an explicit index, so I provide working code to simplify these cases.
Specific examples covered in the drop-down ▶ datasets above ⬆️:
- For ImageNet
- how to download the dataset and prepare it for training with PyTorch
- For QuickDraw
- a working code example that maps the global indices of label errors from https://labelerrors.com to specific rows of examples in each dataset file
- For Amazon Reviews
- released a pre-processed Amazon Reviews dataset that matches the index of the corrected test sets and label errors on https://labelerrors.com.
- For AudioSet
- released an easy-to-use Numpy version of the AudioSet Dataset with a working code example to index the dataset and view label errors / correct examples from a list of indices.
If you use this package for research, please cite the paper:
@inproceedings{northcutt2021labelerrors,
title={Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks},
author={Curtis G. Northcutt and Anish Athalye and Jonas Mueller},
month={December},
year={2021},
booktitle={Proceedings of the 35th Conference on Neural Information Processing Systems Track on Datasets and Benchmarks}
}
We gave a contributed talk of this work at the ICLR 2021 RobustML Workshop. Preliminary versions of this work were published in the NeurIPS 2020 Security and Dataset Curation Workshop and the ICLR 2021 Weakly Supervised Learning Workshop.
| deeplearning.ai | WIRED Magazine | The Register |
| Technology Review | Engadget | MIT CSAIL News |
| VentureBeat | deepnews.ai | Tech Xplore |
| News18 | Healthcare IT News | 新浪财经 |
| Sciences et Avenir | insmart.cz | Heise |
Copyright (c) 2021-2023 Cleanlab Inc.
label-errors is free software: you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version.
label-errors is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
See GNU General Public LICENSE for details.
THIS LICENSE APPLIES TO THIS VERSION AND ALL PREVIOUS VERSIONS OF label-errors.
Any data uploaded (e.g., dataset labels), which has previously been published elsewhere, adheres to the original license from which the data originated.