Detection training
Because the original dataset doesn’t provide bounding box coordinates we had to generate them based on location and pose data from annotations.
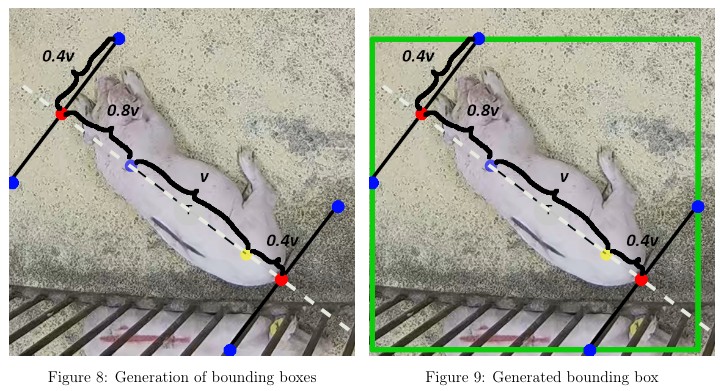
Let’s call the distance between annotated points of a single pigv. To create a bounding box first we extend given points by factors given on 8 to be outside of pig image (red points on image). Then we create points in the perpendicular direction so the pig fits in a rotated rectangle. To get an axis-aligned bounding box we calculate the minimum and maximum coordinates of points showed on the image as blue
To generate frames from video OpenCV library was used. We opened videos as streams and saved every9th frame as png image. This generated 100 images per video. Getting every 9th frame is caused by minimal differences in positions on those frames. Even a fast-moving pig is not able to move much in that time and we’re preventing from getting very similar images in the dataset that way.
Images were split into training and test sets by taking the last 33 images from each video to the test dataset.
Go to location of TensorFlow Object Detection API installed with
$ git clone https://github.com/tensorflow/models.git
cd models/researchDownload baseline detection model: SSD ResNet50 V1 FPN 640x640 (RetinaNet50) and unzip it.
In directory model/detection_model run training:
python <location to object detection library>/model_main_tf2.py --pipeline_config_path="pipeline.config" --alsologtostderr --model_dir=<location of baseline model>To export model graph to be used with application:
$ python <location to object detection library>/exporter_main_v2.py --input_type image_tensor --pipeline_config_path pipeline.config --trained_checkpoint_dir .\resnet_model\ --output_directory inference_graph