We describe how to evaluate models for shift-invariance.
- Download the ImageNet dataset and move validation images to labeled subfolders
- To do this, you can use the following script: https://raw.githubusercontent.com/soumith/imagenetloader.torch/master/valprep.sh
python main.py --data /PTH/TO/ILSVRC2012 -a alexnet_lpf4 --pretrained -e --gpu 0
python main.py --data /PTH/TO/ILSVRC2012 -a vgg11_lpf4 --pretrained -e
python main.py --data /PTH/TO/ILSVRC2012 -a vgg13_lpf4 --pretrained -e
python main.py --data /PTH/TO/ILSVRC2012 -a vgg16_lpf4 --pretrained -e
python main.py --data /PTH/TO/ILSVRC2012 -a vgg19_lpf4 --pretrained -e
python main.py --data /PTH/TO/ILSVRC2012 -a vgg11_bn_lpf4 --pretrained -e
python main.py --data /PTH/TO/ILSVRC2012 -a vgg13_bn_lpf4 --pretrained -e
python main.py --data /PTH/TO/ILSVRC2012 -a vgg16_bn_lpf4 --pretrained -e
python main.py --data /PTH/TO/ILSVRC2012 -a vgg19_bn_lpf4 --pretrained -e
python main.py --data /PTH/TO/ILSVRC2012 -a resnet18_lpf4 --pretrained -e
python main.py --data /PTH/TO/ILSVRC2012 -a resnet34_lpf4 --pretrained -e
python main.py --data /PTH/TO/ILSVRC2012 -a resnet50_lpf4 --pretrained -e
python main.py --data /PTH/TO/ILSVRC2012 -a resnet101_lpf4 --pretrained -e
python main.py --data /PTH/TO/ILSVRC2012 -a resnet152_lpf4 --pretrained -e
python main.py --data /PTH/TO/ILSVRC2012 -a resnext50_32x4d --pretrained -e
python main.py --data /PTH/TO/ILSVRC2012 -a resnext101_32x8d --pretrained -e
python main.py --data /PTH/TO/ILSVRC2012 -a wide_resnet50_2_lpf4 --pretrained -e
python main.py --data /PTH/TO/ILSVRC2012 -a wide_resnet101_2_lpf4 --pretrained -e
python main.py --data /PTH/TO/ILSVRC2012 -a densenet121_lpf4 --pretrained -e
python main.py --data /PTH/TO/ILSVRC2012 -a densenet169_lpf4 --pretrained -e
python main.py --data /PTH/TO/ILSVRC2012 -a densenet201_lpf4 --pretrained -e
python main.py --data /PTH/TO/ILSVRC2012 -a densenet161_lpf4 --pretrained -e
python main.py --data /PTH/TO/ILSVRC2012 -a mobilenet_v2_lpf4 --pretrained -eSame as above, but flag -es evaluates the shift-consistency -- how often two random 224x224 crops are classified the same.
python main.py --data /PTH/TO/ILSVRC2012 -a alexnet_lpf4 --pretrained -es -b 8 --gpu 0
python main.py --data /PTH/TO/ILSVRC2012 -a vgg11_lpf4 --pretrained -es -b 8
python main.py --data /PTH/TO/ILSVRC2012 -a vgg13_lpf4 --pretrained -es -b 8
python main.py --data /PTH/TO/ILSVRC2012 -a vgg16_lpf4 --pretrained -es -b 8
python main.py --data /PTH/TO/ILSVRC2012 -a vgg19_lpf4 --pretrained -es -b 8
python main.py --data /PTH/TO/ILSVRC2012 -a vgg11_bn_lpf4 --pretrained -es -b 8
python main.py --data /PTH/TO/ILSVRC2012 -a vgg13_bn_lpf4 --pretrained -es -b 8
python main.py --data /PTH/TO/ILSVRC2012 -a vgg16_bn_lpf4 --pretrained -es -b 8
python main.py --data /PTH/TO/ILSVRC2012 -a vgg19_bn_lpf4 --pretrained -es -b 8
python main.py --data /PTH/TO/ILSVRC2012 -a resnet18_lpf4 --pretrained -es -b 8
python main.py --data /PTH/TO/ILSVRC2012 -a resnet34_lpf4 --pretrained -es -b 8
python main.py --data /PTH/TO/ILSVRC2012 -a resnet50_lpf4 --pretrained -es -b 8
python main.py --data /PTH/TO/ILSVRC2012 -a resnet101_lpf4 --pretrained -es -b 8
python main.py --data /PTH/TO/ILSVRC2012 -a resnet152_lpf4 --pretrained -es -b 8
python main.py --data /PTH/TO/ILSVRC2012 -a resnext50_32x4d --pretrained -es -b 8
python main.py --data /PTH/TO/ILSVRC2012 -a resnext101_32x8d --pretrained -es -b 8
python main.py --data /PTH/TO/ILSVRC2012 -a wide_resnet50_2_lpf4 --pretrained -es -b 8
python main.py --data /PTH/TO/ILSVRC2012 -a wide_resnet101_2_lpf4 --pretrained -es -b 8
python main.py --data /PTH/TO/ILSVRC2012 -a densenet121_lpf4 --pretrained -es -b 8
python main.py --data /PTH/TO/ILSVRC2012 -a densenet169_lpf4 --pretrained -es -b 8
python main.py --data /PTH/TO/ILSVRC2012 -a densenet201_lpf4 --pretrained -es -b 8
python main.py --data /PTH/TO/ILSVRC2012 -a densenet161_lpf4 --pretrained -es -b 8
python main.py --data /PTH/TO/ILSVRC2012 -a mobilenet_v2_lpf4 --pretrained -es -b 8Some notes:
- These line commands are very similar to the base PyTorch repository. Change
_lpf#with filter size (2,3,4,5). - The example commands use our pretrained. You can them from your own training checkpoints by subsituting
--pretrainedfor--resume PTH/TO/CHECKPOINT.
In the paper, we experimented with filter size. For AlexNet, VGG16, VGG16bn, ResNet18,34,50,101, DenseNet121, and MobileNetv2, we provide models with filter sizes 2, 3, 4 (default), 5.
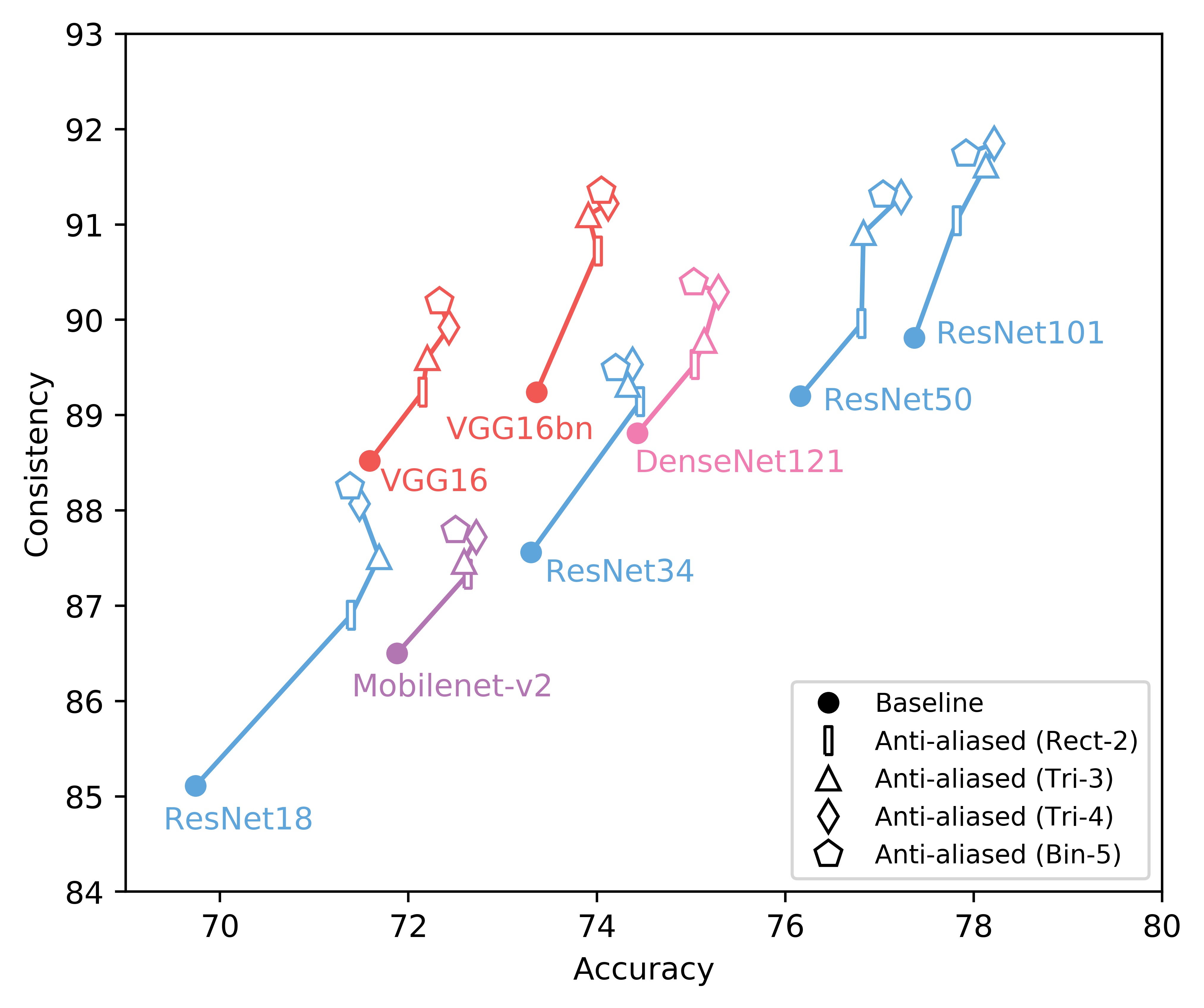
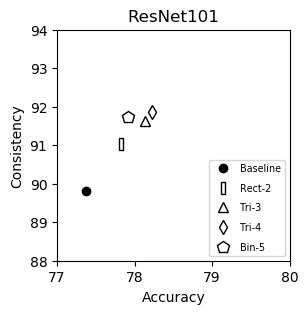
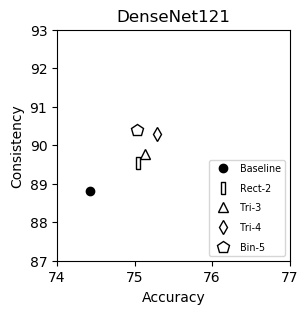
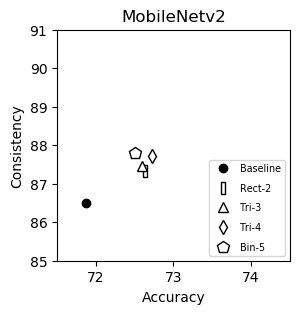
We show consistency (y-axis) vs accuracy (x-axis) for various networks. Up and to the right is good. Training and testing instructions are here.
We italicize a variant if it is not on the Pareto front -- that is, it is strictly dominated in both aspects by another variant. We bold a variant if it is on the Pareto front. We bold highest values per column.
These results are all trained from scratch. Add a --force_nonfinetuned flag to reproduce them.
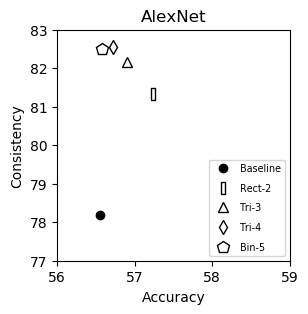
AlexNet (plot)
| Accuracy | Consistency | |
|---|---|---|
| Baseline | 56.55 | 78.18 |
| Rect-2 | 57.24 | 81.33 |
| Tri-3 | 56.90 | 82.15 |
| Tri-4 | 56.72 | 82.54 |
| Bin-5 | 56.58 | 82.51 |
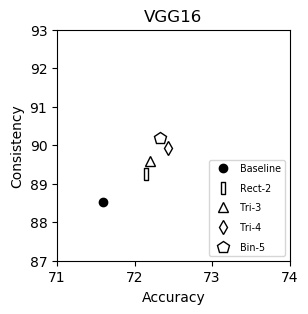
VGG16 (plot)
| Accuracy | Consistency | |
|---|---|---|
| Baseline | 71.59 | 88.52 |
| Rect-2 | 72.15 | 89.24 |
| Tri-3 | 72.20 | 89.60 |
| Tri-4 | 72.43 | 89.92 |
| Bin-5 | 72.33 | 90.19 |
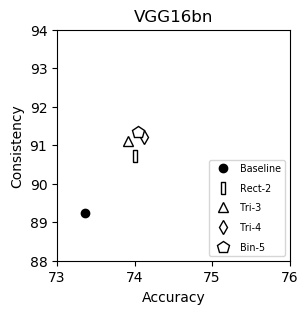
VGG16bn (plot)
| Accuracy | Consistency | |
|---|---|---|
| Baseline | 73.36 | 89.24 |
| Rect-2 | 74.01 | 90.72 |
| Tri-3 | 73.91 | 91.10 |
| Tri-4 | 74.12 | 91.22 |
| Bin-5 | 74.05 | 91.35 |
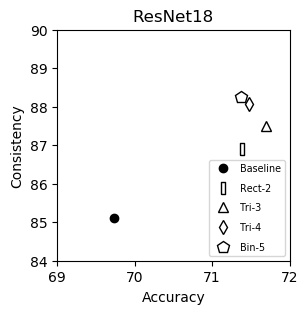
ResNet18 (plot)
| Accuracy | Consistency | |
|---|---|---|
| Baseline | 69.74 | 85.11 |
| Rect-2 | 71.39 | 86.90 |
| Tri-3 | 71.69 | 87.51 |
| Tri-4 | 71.48 | 88.07 |
| Bin-5 | 71.38 | 88.25 |
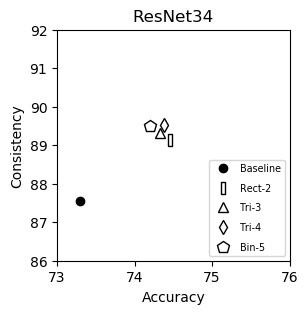
ResNet34 (plot)
| Accuracy | Consistency | |
|---|---|---|
| Baseline | 73.30 | 87.56 |
| Rect-2 | 74.46 | 89.14 |
| Tri-3 | 74.33 | 89.32 |
| Tri-4 | 74.38 | 89.53 |
| Bin-5 | 74.20 | 89.49 |
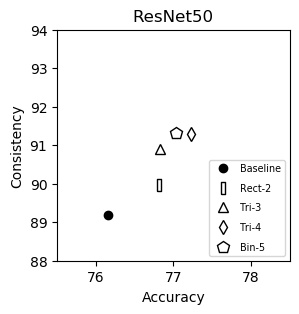
ResNet50 (plot)
| Accuracy | Consistency | |
|---|---|---|
| Baseline | 76.16 | 89.20 |
| Rect-2 | 76.81 | 89.96 |
| Tri-3 | 76.83 | 90.91 |
| Tri-4 | 77.23 | 91.29 |
| Bin-5 | 77.04 | 91.31 |
ResNet101 (plot)
| Accuracy | Consistency | |
|---|---|---|
| Baseline | 77.37 | 89.81 |
| Rect-2 | 77.82 | 91.04 |
| Tri-3 | 78.13 | 91.62 |
| Tri-4 | 78.22 | 91.85 |
| Bin-5 | 77.92 | 91.74 |
DenseNet121 (plot)
| Accuracy | Consistency | |
|---|---|---|
| Baseline | 74.43 | 88.81 |
| Rect-2 | 75.04 | 89.53 |
| Tri-3 | 75.14 | 89.78 |
| Tri-4 | 75.29 | 90.29 |
| Bin-5 | 75.03 | 90.39 |
MobileNet-v2 (plot)
| Accuracy | Consistency | |
|---|---|---|
| Baseline | 71.88 | 86.50 |
| Rect-2 | 72.63 | 87.33 |
| Tri-3 | 72.59 | 87.46 |
| Tri-4 | 72.72 | 87.72 |
| Bin-5 | 72.50 | 87.79 |
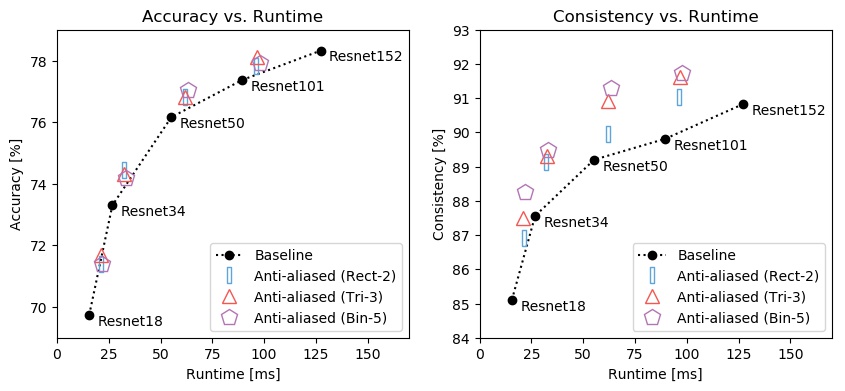
Extra Run-Time
Antialiasing requires extra computation (but no extra parameters). Below, we measure run-time (x-axis, both plots) on a forward pass of batch of 48 images of 224x224 resolution on a RTX 2080 Ti. In this case, gains in accuracy (y-axis, left) and consistency (y-axis, right) end up justifying the increased computation.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The following commands train antialiased AlexNet, VGG16, VGG16bn, ResNet18,34,50, and Densenet121 models with filter size 4 from scratch. Best checkpoint will be saved [[OUT_DIR]]/model_best.pth.tar.
# Training from scratch
python main.py --data /PTH/TO/ILSVRC2012 -a alexnet_lpf4 --out-dir alexnet_lpf4 --gpu 0 --lr .01
python main.py --data /PTH/TO/ILSVRC2012 -a vgg16_lpf4 --out-dir vgg16_lpf4 --lr .01 -b 128 -ba 2
python main.py --data /PTH/TO/ILSVRC2012 -a vgg16_bn_lpf4 --out-dir vgg16_bn_lpf4 --lr .05 -b 128 -ba 2
python main.py --data /PTH/TO/ILSVRC2012 -a resnet18_lpf4 --out-dir resnet18_lpf4
python main.py --data /PTH/TO/ILSVRC2012 -a resnet34_lpf4 --out-dir resnet34_lpf4
python main.py --data /PTH/TO/ILSVRC2012 -a resnet50_lpf4 --out-dir resnet50_lpf4
python main.py --data /PTH/TO/ILSVRC2012 -a resnet101_lpf4 --out-dir resnet101_lpf4
python main.py --data /PTH/TO/ILSVRC2012 -a densenet121_lpf4 --out-dir densenet121_lpf4
python main.py --data /PTH/TO/ILSVRC2012 -a mobilenet_v2_lpf4 --out-dir mobilenet_v2_lpf4 --lr .05 --cos_lr --wd 4e-5 --ep 150New (Oct 2020) The commands above train from scratch. You can now fine-tune antialiased models starting from baseline model weights. I do this by turning on the --finetune flag, and performing the last 2/3 of training; by default, this means lr lowered by 10 times and we use 60 epochs. This gets better results than training from scratch.
# Training from baseline weights
python main.py --data /PTH/TO/ILSVRC2012 -a resnet50_lpf4 --out-dir resnet50_lpf4 --lr .01 -ep 60 --finetuneSome notes:
- As suggested by the official repository, AlexNet and VGG16 require lower learning rates of
0.01(default is0.1). - VGG16_bn also required a slightly lower learning rate of
0.05. - I train AlexNet on a single GPU (the network is fast, so preprocessing becomes the limiting factor if multiple GPUs are used).
- MobileNet was trained with the training recipe from here.
- Default batch size is
256. Some extra memory is added for the antialiasing layers, so the default batchsize may no longer fit in memory. To get around this, we simply accumulate gradients over 2 smaller batches-b 128with flag--ba 2. You may find this useful, even for the default models, if you are training with smaller/fewer GPUs. It is not exactly identical to training with a large batch, as the batchnorm statistics will be computed with a smaller batch.
Checkpoint vs weights:
- To resume training session, use flag
--resume [[OUT_DIR]]/checkpoint_[[NUM]].pth.tar. This flag can be used instead of--weightsin the evaluation scripts above. - Saved checkpoints include model weights and optimizer parameters. Also, if you trained with parallelization, then the weights/optimizer dicts will include parallelization. To strip optimizer parameters away and 'deparallelize' the model weights, run the following command (with appropriate substitution) afterwards:
python main.py -a resnet18_lpf4 --resume resnet18_lpf4/model_best.pth.tar --save_weights resnet18_lpf4/weights.pth.tarI used this postprocessing step to provide the pretrained weights. As seen here, weights should be loaded before parallelizing the model. Meanwhile, the checkpoint is loaded after parallelizing the model.
Results are here.