Computer Vision¶
约 8852 个字 167 张图片 预计阅读时间 44 分钟 共被读过 次
This note is based on GitHub - DaizeDong/Stanford-CS231n-2021-and-2022: Notes and slides for Stanford CS231n 2021 & 2022 in English. I merged the contents together to get a better version. Assignments are not included. 斯坦福 cs231n 的课程笔记 ( 英文版本,不含实验代码 ),将 2021 与 2022 两年的课程进行了合并,分享以供交流。
And I will add some blogs, articles and other understanding.
| Topic | Chapter |
|---|---|
| Deep Learning Basics | 2 - 4 |
| Perceiving and Understanding the Visual World | 5 - 12 |
| Reconstructing and Interacting with the Visual World | 13 - 16 |
| Human-Centered Applications and Implications | 17 - 18 |
1 - Introduction¶
A brief history of computer vision & deep learning...
2 - Image Classification¶
Image Classification: A core task in Computer Vision. The main drive to the progress of CV.
Challenges: Viewpoint variation, background clutter, illumination, occlusion, deformation, intra-class variation...
K Nearest Neighbor¶
Hyperparameters: Distance metric (\(p\) norm), \(k\) number.
Choose hyperparameters using validation set.
Never use k-Nearest Neighbor with pixel distance.

Linear Classifier¶
Pass...
3 - Loss Functions and Optimization¶
Loss Functions¶
| Dataset | \(\big\{(x_i,y_i)\big\}_{i=1}^N\\\) |
|---|---|
| Loss Function | \(L=\frac{1}{N}\sum_{i=1}^NL_i\big(f(x_i,W),y_i\big)\\\) |
| Loss Function with Regularization | \(L=\frac{1}{N}\sum_{i=1}^NL_i\big(f(x_i,W),y_i\big)+\lambda R(W)\\\) |
Motivation: Want to interpret raw classifier scores as probabilities.
| Softmax Classifier | \(p_i=Softmax(y_i)=\frac{\exp(y_i)}{\sum_{j=1}^N\exp(y_j)}\\\) |
|---|---|
| Cross Entropy Loss | \(L_i=-y_i\log p_i\\\) |
| Cross Entropy Loss with Regularization | \(L=-\frac{1}{N}\sum_{i=1}^Ny_i\log p_i+\lambda R(W)\\\) |

Optimization¶
SGD with Momentum¶
Problems that SGD can't handle:
- Inequality of gradient in different directions.
- Local minima and saddle point (much more common in high dimension).
- Noise of gradient from mini-batch.
Momentum: Build up “velocity” \(v_t\) as a running mean of gradients.
| SGD | SGD + Momentum |
|---|---|
| \(x_{t+1}=x_t-\alpha\nabla f(x_t)\) | \(\begin{align}&v_{t+1}=\rho v_t+\nabla f(x_t)\\&x_{t+1}=x_t-\alpha v_{t+1}\end{align}\) |
| Naive gradient descent. | \(\rho\) gives "friction", typically \(\rho=0.9,0.99,0.999,...\) |
Nesterov Momentum: Use the derivative on point \(x_t+\rho v_t\) as gradient instead point \(x_t\).
| Momentum | Nesterov Momentum |
|---|---|
| \(\begin{align}&v_{t+1}=\rho v_t+\nabla f(x_t)\\&x_{t+1}=x_t-\alpha v_{t+1}\end{align}\) | \(\begin{align}&v_{t+1}=\rho v_t+\nabla f(x_t+\rho v_t)\\&x_{t+1}=x_t-\alpha v_{t+1}\end{align}\) |
| Use gradient at current point. | Look ahead for the gradient in velocity direction. |

AdaGrad and RMSProp¶
AdaGrad: Accumulate squared gradient, and gradually decrease the step size.
RMSProp: Accumulate squared gradient while decaying former ones, and gradually decrease the step size. ("Leaky AdaGrad")
| AdaGrad | RMSProp |
|---|---|
| \(\begin{align}\text{Initialize:}&\\&r:=0\\\text{Update:}&\\&r:=r+\Big[\nabla f(x_t)\Big]^2\\&x_{t+1}=x_t-\alpha\frac{\nabla f(x_t)}{\sqrt{r}}\end{align}\) | \(\begin{align}\text{Initialize:}&\\&r:=0\\\text{Update:}&\\&r:=\rho r+(1-\rho)\Big[\nabla f(x_t)\Big]^2\\&x_{t+1}=x_t-\alpha\frac{\nabla f(x_t)}{\sqrt{r}}\end{align}\) |
| Continually accumulate squared gradients. | \(\rho\) gives "decay rate", typically \(\rho=0.9,0.99,0.999,...\) |
Adam¶
Sort of like "RMSProp + Momentum".
| Adam (simple version) | Adam (full version) |
|---|---|
| \(\begin{align}\text{Initialize:}&\\&r_1:=0\\&r_2:=0\\\text{Update:}&\\&r_1:=\beta_1r_1+(1-\beta_1)\nabla f(x_t)\\&r_2:=\beta_2r_2+(1-\beta_2)\Big[\nabla f(x_t)\Big]^2\\&x_{t+1}=x_t-\alpha\frac{r_1}{\sqrt{r_2}}\end{align}\) | \(\begin{align}\text{Initialize:}\\&r_1:=0\\&r_2:=0\\\text{For }i\text{:}\\&r_1:=\beta_1r_1+(1-\beta_1)\nabla f(x_t)\\&r_2:=\beta_2r_2+(1-\beta_2)\Big[\nabla f(x_t)\Big]^2\\&r_1'=\frac{r_1}{1-\beta_1^i}\\&r_2'=\frac{r_2}{1-\beta_2^i}\\&x_{t+1}=x_t-\alpha\frac{r_1'}{\sqrt{r_2'}}\end{align}\) |
| Build up “velocity” for both gradient and squared gradient. | Correct the "bias" that \(r_1=r_2=0\) for the first few iterations. |
Overview¶
 |  |
|---|---|
Learning Rate Decay¶
Reduce learning rate at a few fixed points to get a better convergence over time.
\(\alpha_0\) : Initial learning rate.
\(\alpha_t\) : Learning rate in epoch \(t\).
\(T\) : Total number of epochs.
| Method | Equation | Picture |
|---|---|---|
| Step | Reduce \(\alpha_t\) constantly in a fixed step. | 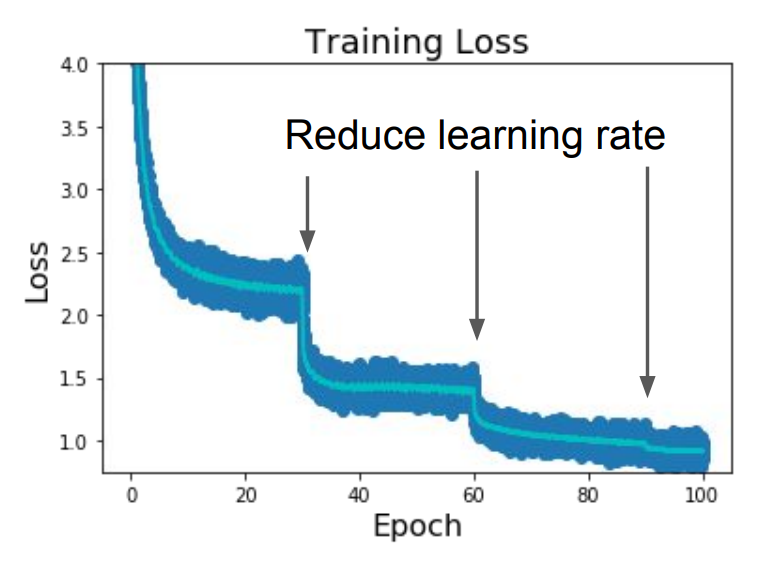 |
| Cosine | \(\begin{align}\alpha_t=\frac{1}{2}\alpha_0\Bigg[1+\cos(\frac{t\pi}{T})\Bigg]\end{align}\) |  |
| Linear | \(\begin{align}\alpha_t=\alpha_0\Big(1-\frac{t}{T}\Big)\end{align}\) |  |
| Inverse Sqrt | \(\begin{align}\alpha_t=\frac{\alpha_0}{\sqrt{t}}\end{align}\) |  |
High initial learning rates can make loss explode, linearly increasing learning rate in the first few iterations can prevent this.
Learning rate warm up:

Empirical rule of thumb: If you increase the batch size by \(N\), also scale the initial learning rate by \(N\) .
Second-Order Optimization¶
| Picture | Time Complexity | Space Complexity | |
|---|---|---|---|
| First Order |  | \(O(n)\) | \(O(n)\) |
| Second Order |  | \(O(n^2)\) with BGFS optimization | \(O(n)\) with L-BGFS optimization |
L-BGFS : Limited memory BGFS.
- Works very well in full batch, deterministic \(f(x)\).
- Does not transfer very well to mini-batch setting.
Summary¶
| Method | Performance |
|---|---|
| Adam | Often chosen as default method. Work ok even with constant learning rate. |
| SGD + Momentum | Can outperform Adam. Require more tuning of learning rate and schedule. |
| L-BGFS | If can afford to do full batch updates then try out. |
- An article about gradient descent: Anoverview of gradient descent optimization algorithms
- A blog: An updated overview of recent gradient descent algorithms – John Chen – ML at Rice University
4 - Neural Networks and Backpropagation¶
Neural Networks¶
Motivation: Inducted bias can appear to be high when using human-designed features.
Activation: Sigmoid, tanh, ReLU, LeakyReLU...
Architecture: Input layer, hidden layer, output layer.
Do not use the size of a neural network as the regularizer. Use regularization instead!
Gradient Calculation: Computational Graph + Backpropagation.
Backpropagation¶
Using Jacobian matrix to calculate the gradient of each node in a computation graph.
Suppose that we have a computation flow like this:

| Input X | Input W | Output Y |
|---|---|---|
| \(X=\begin{bmatrix}x_1\\x_2\\\vdots\\x_n\end{bmatrix}\) | \(W=\begin{bmatrix}w_{11}&w_{12}&\cdots&w_{1n}\\w_{21}&w_{22}&\cdots&w_{2n}\\\vdots&\vdots&\ddots&\vdots\\w_{m1}&w_{m2}&\cdots&w_{mn}\end{bmatrix}\) | \(Y=\begin{bmatrix}y_1\\y_2\\\vdots\\y_m\end{bmatrix}\) |
| \(n\times 1\) | \(m\times n\) | \(m\times 1\) |
After applying feed forward, we can calculate gradients like this:

| Derivative Matrix of X | Jacobian Matrix of X | Derivative Matrix of Y |
|---|---|---|
| \(D_X=\begin{bmatrix}\frac{\partial L}{\partial x_1}\\\frac{\partial L}{\partial x_2}\\\vdots\\\frac{\partial L}{\partial x_n}\end{bmatrix}\) | \(J_X=\begin{bmatrix}\frac{\partial y_1}{\partial x_1}&\frac{\partial y_1}{\partial x_2}&\cdots&\frac{\partial y_1}{\partial x_n}\\\frac{\partial y_2}{\partial x_1}&\frac{\partial y_2}{\partial x_2}&\cdots&\frac{\partial y_2}{\partial x_n}\\\vdots&\vdots&\ddots&\vdots\\\frac{\partial y_m}{\partial x_1}&\frac{\partial y_m}{\partial x_2}&\cdots&\frac{\partial y_m}{\partial x_n}\end{bmatrix}\) | \(D_Y=\begin{bmatrix}\frac{\partial L}{\partial y_1}\\\frac{\partial L}{\partial y_2}\\\vdots\\\frac{\partial L}{\partial y_m}\end{bmatrix}\) |
| \(n\times 1\) | \(m\times n\) | \(m\times 1\) |
| Derivative Matrix of W | Jacobian Matrix of W | Derivative Matrix of Y |
|---|---|---|
| \(W=\begin{bmatrix}\frac{\partial L}{\partial w_{11}}&\frac{\partial L}{\partial w_{12}}&\cdots&\frac{\partial L}{\partial w_{1n}}\\\frac{\partial L}{\partial w_{21}}&\frac{\partial L}{\partial w_{22}}&\cdots&\frac{\partial L}{\partial w_{2n}}\\\vdots&\vdots&\ddots&\vdots\\\frac{\partial L}{\partial w_{m1}}&\frac{\partial L}{\partial w_{m2}}&\cdots&\frac{\partial L}{\partial w_{mn}}\end{bmatrix}\) | \(J_W^{(k)}=\begin{bmatrix}\frac{\partial y_k}{\partial w_{11}}&\frac{\partial y_k}{\partial w_{12}}&\cdots&\frac{\partial y_k}{\partial w_{1n}}\\\frac{\partial y_k}{\partial w_{21}}&\frac{\partial y_k}{\partial w_{22}}&\cdots&\frac{\partial y_k}{\partial w_{2n}}\\\vdots&\vdots&\ddots&\vdots\\\frac{\partial y_k}{\partial w_{m1}}&\frac{\partial y_k}{\partial w_{m2}}&\cdots&\frac{\partial y_k}{\partial w_{mn}}\end{bmatrix}\) \(J_W=\begin{bmatrix}J_W^{(1)}&J_W^{(2)}&\cdots&J_W^{(m)}\end{bmatrix}\) | \(D_Y=\begin{bmatrix}\frac{\partial L}{\partial y_1}\\\frac{\partial L}{\partial y_2}\\\vdots\\\frac{\partial L}{\partial y_m}\end{bmatrix}\) |
| \(m\times n\) | \(m\times m\times n\) | $ m\times 1$ |
For each element in \(D_X\) , we have:
\(D_{Xi}=\frac{\partial L}{\partial x_i}=\sum_{j=1}^m\frac{\partial L}{\partial y_j}\frac{\partial y_j}{\partial x_i}\\\)
5 - Convolutional Neural Networks¶
Convolution Layer¶
Introduction¶
Convolve a filter with an image: Slide the filter spatially within the image, computing dot products in each region.
Giving a \(32\times32\times3\) image and a \(5\times5\times3\) filter, a convolution looks like:

Convolve six \(5\times5\times3\) filters to a \(32\times32\times3\) image with step size \(1\), we can get a \(28\times28\times6\) feature:

With an activation function after each convolution layer, we can build the ConvNet with a sequence of convolution layers:

By changing the step size between each move for filters, or adding zero-padding around the image, we can modify the size of the output:

\(1\times1\) Convolution Layer¶
This kind of layer makes perfect sense. It is usually used to change the dimension (channel) of features.
A \(1\times1\) convolution layer can also be treated as a full-connected linear layer.

Summary¶
| Input | |
|---|---|
| image size | \(W_1\times H_1\times C\) |
| filter size | \(F\times F\times C\) |
| filter number | \(K\) |
| stride | \(S\) |
| zero padding | \(P\) |
| Output | |
| output size | \(W_2\times H_2\times K\) |
| output width | \(W_2=\frac{W_1-F+2P}{S}+1\\\) |
| output height | \(H_2=\frac{H_1-F+2P}{S}+1\\\) |
| Parameters | |
| parameter number (weight) | \(F^2CK\) |
| parameter number (bias) | \(K\) |
Pooling layer¶
Make the representations smaller and more manageable.
An example of max pooling:

| Input | |
|---|---|
| image size | \(W_1\times H_1\times C\) |
| spatial extent | \(F\times F\) |
| stride | \(S\) |
| Output | |
| output size | \(W_2\times H_2\times C\) |
| output width | \(W_2=\frac{W_1-F}{S}+1\\\) |
| output height | \(H_2=\frac{H_1-F}{S}+1\\\) |
Convolutional Neural Networks (CNN)¶
CNN stack CONV, POOL, FC layers.
CNN Trends:
- Smaller filters and deeper architectures.
- Getting rid of POOL/FC layers (just CONV).
Historically architectures of CNN looked like:

where usually \(m\) is large, \(0\le n\le5\), \(0\le k\le2\).
Recent advances such as ResNet / GoogLeNet have challenged this paradigm.
6 - CNN Architectures¶
Best model in ImageNet competition:

AlexNet¶
8 layers.
First use of ConvNet in image classification problem.
Filter size decreases in deeper layer.
Channel number increases in deeper layer.


VGG¶
19 layers. (also provide 16 layers edition)
Static filter size (\(3\times3\)) in all layers:
- The effective receptive field expands with the layer gets deeper.
- Deeper architecture gets more non-linearities and few parameters.

Most memory is in early convolution layers.
Most parameter is in late FC layers.


GoogLeNet¶
22 layers.
No FC layers, only 5M parameters. ( \(8.3\%\) of AlexNet, \(3.7\%\) of VGG )
Devise efficient "inception module".
Inception Module¶
Design a good local network topology (network within a network) and then stack these modules on top of each other.
Naive Inception Module:
- Apply parallel filter operations on the input from previous layer.
- Concatenate all filter outputs together channel-wise.
- Problem: The depth (channel number) increases too fast, costing expensive computation.

Inception Module with Dimension Reduction:
- Add "bottle neck" layers to reduce the dimension.
- Also get fewer computation cost.

Architecture¶


ResNet¶
152 layers for ImageNet.
Devise "residual connections".
Use BN in place of dropout.
Residual Connections¶
Hypothesis: Deeper models have more representation power than shallow ones. But they are harder to optimize.
Solution: Use network layers to fit a residual mapping instead of directly trying to fit a desired underlying mapping.

It is necessary to use ReLU as activation function, in order to apply identity mapping when \(F(x)=0\) .
Architecture¶


SENet¶
Using ResNeXt-152 as a base architecture.
Add a “feature recalibration” module. (adjust weights of each channel)
Using the global avg-pooling layer + FC layers to determine feature map weights.
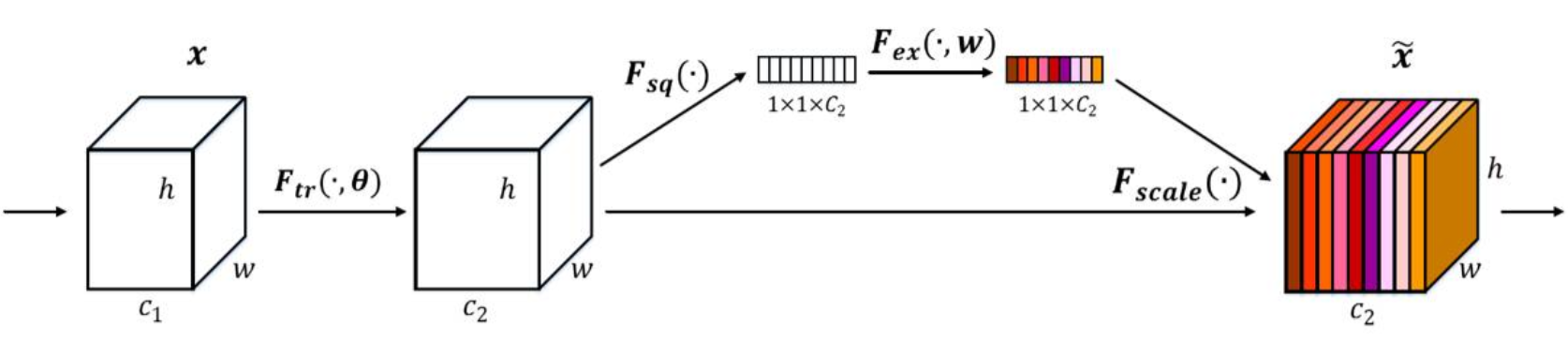

Improvements of ResNet¶
Wide Residual Networks, ResNeXt, DenseNet, MobileNets...
Other Interesting Networks¶
NASNet: Neural Architecture Search with Reinforcement Learning.
EfficientNet: Smart Compound Scaling.
7 - Training Neural Networks¶
Activation Functions¶
| Activation | Usage |
|---|---|
| Sigmoid, tanh | Do not use. |
| ReLU | Use as default. |
| Leaky ReLU, Maxout, ELU, SELU | Replace ReLU to squeeze out some marginal gains. |
| Swish | No clear usage. |
Data Processing¶
Apply centralization and normalization before training.
In practice for pictures, usually we apply channel-wise centralization only.
Weight Initialization¶
Assume that we have 6 layers in a network.
\(D_i\) : input size of layer \(i\)
\(W_i\) : weights in layer \(i\)
\(X_i\) : output after activation of layer \(i\), we have \(X_i=g(Z_i)=g(W_iX_{i-1}+B_i)\)
We initialize each parameter in \(W_i\) randomly in \([-k_i,k_i]\) .
| Tanh Activation | Output Distribution |
|---|---|
| \(k_i=0.01\) |  |
| \(k_i=0.05\) |  |
| Xavier Initialization \(k_i=\frac{1}{\sqrt{D_i}\\}\) |  |
When \(k_i=0.01\), the variance keeps decreasing as the layer gets deeper. As a result, the output of each neuron in deep layer will all be 0. The partial derivative \(\frac{\partial Z_i}{\partial W_i}=X_{i-1}=0\\\). (no gradient)
When \(k_i=0.05\), most neurons is saturated. The partial derivative \(\frac{\partial X_i}{\partial Z_i}=g'(Z_i)=0\\\). (no gradient)
To solve this problem, We need to keep the variance same in each layer.
Assuming that \(Var\big(X_{i-1}^{(1)}\big)=Var\big(X_{i-1}^{(2)}\big)=\dots=Var\big(X_{i-1}^{(D_i)}\big)\)
We have \(Z_i=X_{i-1}^{(1)}W_i^{(:,1)}+X_{i-1}^{(2)}W_i^{(:,2)}+\dots+X_{i-1}^{(D_i)}W_i^{(:,D_i)}=\sum_{n=1}^{D_i}X_{i-1}^{(n)}W_i^{(:,n)}\\\)
We want \(Var\big(Z_i\big)=Var\big(X_{i-1}^{(n)}\big)\)
Let's do some conduction:
\(\begin{aligned}Var\big(Z_i\big)&=Var\Bigg(\sum_{n=1}^{D_i}X_{i-1}^{(n)}W_i^{(:,n)}\Bigg)\\&=D_i\ Var\Big(X_{i-1}^{(n)}W_i^{(:,n)}\Big)\\&=D_i\ Var\Big(X_{i-1}^{(n)}\Big)\ Var\Big(W_i^{(:,n)}\Big)\end{aligned}\)
So \(Var\big(Z_i\big)=Var\big(X_{i-1}^{(n)}\big)\) only when \(Var\Big(W_i^{(:,n)}\Big)=\frac{1}{D_i}\\\), that is to say \(k_i=\frac{1}{\sqrt{D_i}}\\\)
| ReLU Activation | Output Distribution |
|---|---|
| Xavier Initialization \(k_i=\frac{1}{\sqrt{D_i}\\}\) |  |
| Kaiming Initialization \(k_i=\sqrt{2D_i}\) |  |
For ReLU activation, when using xavier initialization, there still exist "variance decreasing" problem.
We can use kaiming initialization instead to fix this.
Batch Normalization¶
Force the inputs to be "nicely scaled" at each layer.
\(N\) : batch size
\(D\) : feature size
\(x\) : input with shape \(N\times D\)
\(\gamma\) : learnable scale and shift parameter with shape \(D\)
\(\beta\) : learnable scale and shift parameter with shape \(D\)
The procedure of batch normalization:
- Calculate channel-wise mean \(\mu_j=\frac{1}{N}\sum_{i=1}^Nx_{i,j}\\\) . The result \(\mu\) with shape \(D\) .
- Calculate channel-wise variance \(\sigma_j^2=\frac{1}{N}\sum_{i=1}^N(x_{i,j}-\mu_j)^2\\\) . The result \(\sigma^2\) with shape \(D\) .
- Calculate normalized \(\hat{x}_{i,j}=\frac{x_{i,j}-\mu_j}{\sqrt{\sigma_j^2+\epsilon}}\\\) . The result \(\hat{x}\) with shape \(N\times D\) .
- Scale normalized input to get output \(y_{i,j}=\gamma_j\hat{x}_{i,j}+\beta_j\) . The result \(y\) with shape \(N\times D\) .
Why scale: The constraint "zero-mean, unit variance" may be too hard.

Pros:
- Makes deep networks much easier to train!
- Improves gradient flow.
- Allows higher learning rates, faster convergence.
- Networks become more robust to initialization.
- Acts as regularization during training.
- Zero overhead at test-time: can be fused with conv!
Cons:
Behaves differently during training and testing: this is a very common source of bugs!

Transfer Learning¶
Train on a pre-trained model with other datasets.
An empirical suggestion:
| very similar dataset | very different dataset | |
|---|---|---|
| very little data | Use Linear Classifier on top layer. | You’re in trouble… Try linear classifier from different stages. |
| quite a lot of data | Finetune a few layers. | Finetune a larger number of layers. |
Regularization¶
Common Pattern of Regularization¶
Training: Add some kind of randomness. \(y=f(x,z)\)
Testing: Average out randomness (sometimes approximate). \(y=f(x)=E_z\big[f(x,z)\big]=\int p(z)f(x,z)dz\\\)
Regularization Term¶
L2 regularization: \(R(W)=\sum_k\sum_lW_{k,l}^2\) (weight decay)
L1 regularization: \(R(W)=\sum_k\sum_l|W_{k,l}|\)
Elastic net : \(R(W)=\sum_k\sum_l\big(\beta W_{k,l}^2+|W_{k,l}|\big)\) (L1+L2)
Dropout¶
Training: Randomly set some neurons to 0 with a probability \(p\) .
Testing: Each neuron multiplies by dropout probability \(p\) . (scale the output back)
More common: Scale the output with \(\frac{1}{p}\) when training, keep the original output when testing.

Why dropout works:
- Forces the network to have a redundant representation. Prevents co-adaptation of features.
- Another interpretation: Dropout is training a large ensemble of models (that share parameters).

Batch Normalization¶
See above.
Data Augmentation¶
- Horizontal Flips
- Random Crops and Scales
- Color Jitter
- Rotation
- Stretching
- Shearing
- Lens Distortions
- ...
There also exists automatic data augmentation method using neural networks.
Other Methods and Summary¶
DropConnect: Drop connections between neurons.
Fractional Max Pooling: Use randomized pooling regions.
Stochastic Depth: Skip some layers in the network.
Cutout: Set random image regions to zero.
Mixup: Train on random blends of images.
| Regularization Method | Usage |
|---|---|
| Dropout | For large fully-connected layers. |
| Batch Normalization & Data Augmentation | Almost always a good idea. |
| Cutout & Mixup | For small classification datasets. |
Hyperparameter Tuning¶
| Most Common Hyperparameters | Less Sensitive Hyperparameters |
|---|---|
| learning rate learning rate decay schedule weight decay | setting of momentum ... |
Tips on hyperparameter tuning:
- Prefer one validation fold to cross-validation.
- Search for hyperparameters on log scale. (e.g. multiply the hyperparameter by a fixed number \(k\) at each search)
- Prefer random search to grid search.
- Careful with best values on border.
- Stage your search from coarse to fine.

Implementation¶
Have a worker that continuously samples random hyperparameters and performs the optimization. During the training, the worker will keep track of the validation performance after every epoch, and writes a model checkpoint to a file.
Have a master that launches or kills workers across a computing cluster, and may additionally inspect the checkpoints written by workers and plot their training statistics.
Common Procedures¶
- Check initial loss.
Turn off weight decay, sanity check loss at initialization \(\log(C)\) for softmax with \(C\) classes.
- Overfit a small sample. (important)
Try to train to 100% training accuracy on a small sample of training data.
Fiddle with architecture, learning rate, weight initialization.
- Find learning rate that makes loss go down.
Use the architecture from the previous step, use all training data, turn on small weight decay, find a learning rate that makes the loss drop significantly within 100 iterations.
Good learning rates to try: \(0.1,0.01,0.001,0.0001,\dots\)
- Coarse grid, train for 1-5 epochs.
Choose a few values of learning rate and weight decay around what worked from Step 3, train a few models for 1-5 epochs.\
Good weight decay to try: \(0.0001,0.00001,0\)
- Refine grid, train longer.
Pick best models from Step 4, train them for longer (10-20 epochs) without learning rate decay.
- Look at loss and accuracy curves.
- GOTO step 5.
Gradient Checks¶
CS231n Convolutional Neural Networks for Visual Recognition
Compute analytical gradient manually using \(f_a'=\frac{\partial f(x)}{\partial x}=\frac{f(x-h)-f(x+h)}{2h}\\\)
Get relative error between numerical gradient \(f_n'\) and analytical gradient \(f_a'\) using \(E=\frac{|f_n'-f_a'|}{\max{|f_n'|,|f_a'|}}\\\)
| Relative Error | Result |
|---|---|
| \(E>10^{-2}\) | Probably \(f_n'\) is wrong. |
| \(10^{-2}>E>10^{-4}\) | Not good, should check the gradient. |
| \(10^{-4}>E>10^{-6}\) | Okay for objectives with kinks. (e.g. ReLU) Not good for objectives with no kink. (e.g. softmax, tanh) |
| \(10^{-7}>E\) | Good. |
Tips on gradient checks:
- Use double precision.
- Use only few data points.
- Careful about kinks in the objective. (e.g. \(x=0\) for ReLU activation)
- Careful with the step size \(h\).
- Use gradient check after the loss starts to go down.
- Remember to turn off anything that may affect the gradient. (e.g. regularization / dropout / augmentations)
- Check only few dimensions for every parameter. (reduce time cost)
8 - Visualizing and Understanding¶
Feature Visualization and Inversion¶
Visualizing what models have learned¶
| Visualize Areas | |
|---|---|
| Filters | Visualize the raw weights of each convolution kernel. (better in the first layer) |
| Final Layer Features | Run dimensionality reduction for features in the last FC layer. (PCA, t-SNE...) |
| Activations | Visualize activated areas. (Understanding Neural Networks Through Deep Visualization) |
Understanding input pixels¶
Maximally Activating Patches¶
- Pick a layer and a channel.
- Run many images through the network, record values of the chosen channel.
- Visualize image patches that correspond to maximal activation features.
For example, we have a layer with shape \(128\times13\times13\). We pick the 17th channel from all 128 channels. Then we run many pictures through the network. During each run we can find a maximal activation feature among all the \(13\times13\) features in channel 17. We then record the corresponding picture patch for each maximal activation feature. At last, we visualize all picture patches for each feature.
This will help us find the relationship between each maximal activation feature and its corresponding picture patches.
(each row of the following picture represents a feature)

Saliency via Occlusion¶
Mask part of the image before feeding to CNN, check how much predicted probabilities change.

Saliency via Backprop¶
- Compute gradient of (unnormalized) class score with respect to image pixels.
- Take absolute value and max over RGB channels to get saliency maps.


Intermediate Features via Guided Backprop¶
- Pick a single intermediate neuron. (e.g. one feature in a \(128\times13\times13\) feature map)
- Compute gradient of neuron value with respect to image pixels.
Striving for Simplicity: The All Convolutional Net
Just like "Maximally Activating Patches", this could find the part of an image that a neuron responds to.


Gradient Ascent¶
Generate a synthetic image that maximally activates a neuron.
- Initialize image \(I\) to zeros.
- Forward image to compute current scores \(S_c(I)\) (for class \(c\) before softmax).
- Backprop to get gradient of neuron value with respect to image pixels.
- Make a small update to the image.
Objective: \(\max S_c(I)-\lambda\lVert I\lVert^2\)
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps


Adversarial Examples¶
Find an fooling image that can make the network misclassify correctly-classified images when it is added to the image.
- Start from an arbitrary image.
- Pick an arbitrary class.
- Modify the image to maximize the class.
- Repeat until network is fooled.

DeepDream and Style Transfer¶
Feature Inversion¶
Given a CNN feature vector \(\Phi_0\) for an image, find a new image \(x\) that:
- Features of new image \(\Phi(x)\) matches the given feature vector \(\Phi_0\).
- "looks natural”. (image prior regularization)
Objective: \(\min \lVert\Phi(x)-\Phi_0\lVert+\lambda R(x)\)
Understanding Deep Image Representations by Inverting Them

DeepDream: Amplify Existing Features¶
Given an image, amplify the neuron activations at a layer to generate a new one.
- Forward: compute activations at chosen layer.
- Set gradient of chosen layer equal to its activation.
- Backward: Compute gradient on image.
- Update image.

Texture Synthesis¶
Nearest Neighbor¶
- Generate pixels one at a time in scanline order
- Form neighborhood of already generated pixels, copy the nearest neighbor from input.

Neural Texture Synthesis¶
Gram Matrix: 格拉姆矩阵(Gram matrix)详细解读
- Pretrain a CNN on ImageNet.
- Run input texture forward through CNN, record activations on every layer.
Layer \(i\) gives feature map of shape \(C_i\times H_i\times W_i\).
- At each layer compute the Gram matrix \(G_i\) giving outer product of features.
- Reshape feature map at layer \(i\) to \(C_i\times H_iW_i\).
- Compute the Gram matrix \(G_i\) with shape \(C_i\times C_i\).
- Initialize generated image from random noise.
- Pass generated image through CNN, compute Gram matrix \(\hat{G}_l\) on each layer.
- Compute loss: Weighted sum of L2 distance between Gram matrices.
- \(E_l=\frac{1}{aN_l^2M_l^2}\sum_{i,j}\Big(G_i^{(i,j)}-\hat{G}_i^{(i,j)}\Big)^2\\\)
- \(\mathcal{L}(\vec{x},\hat{\vec{x}})=\sum_{l=0}^L\omega_lE_l\\\)
- Backprop to get gradient on image.
- Make gradient step on image.
- GOTO 5.
Texture Synthesis Using Convolutional Neural Networks


Style Transfer¶
Feature + Gram Reconstruction¶
![]()
![]()
Problem: Style transfer requires many forward / backward passes. Very slow!
Fast Style Transfer¶
![]()
![]()
9 - Object Detection and Image Segmentation¶
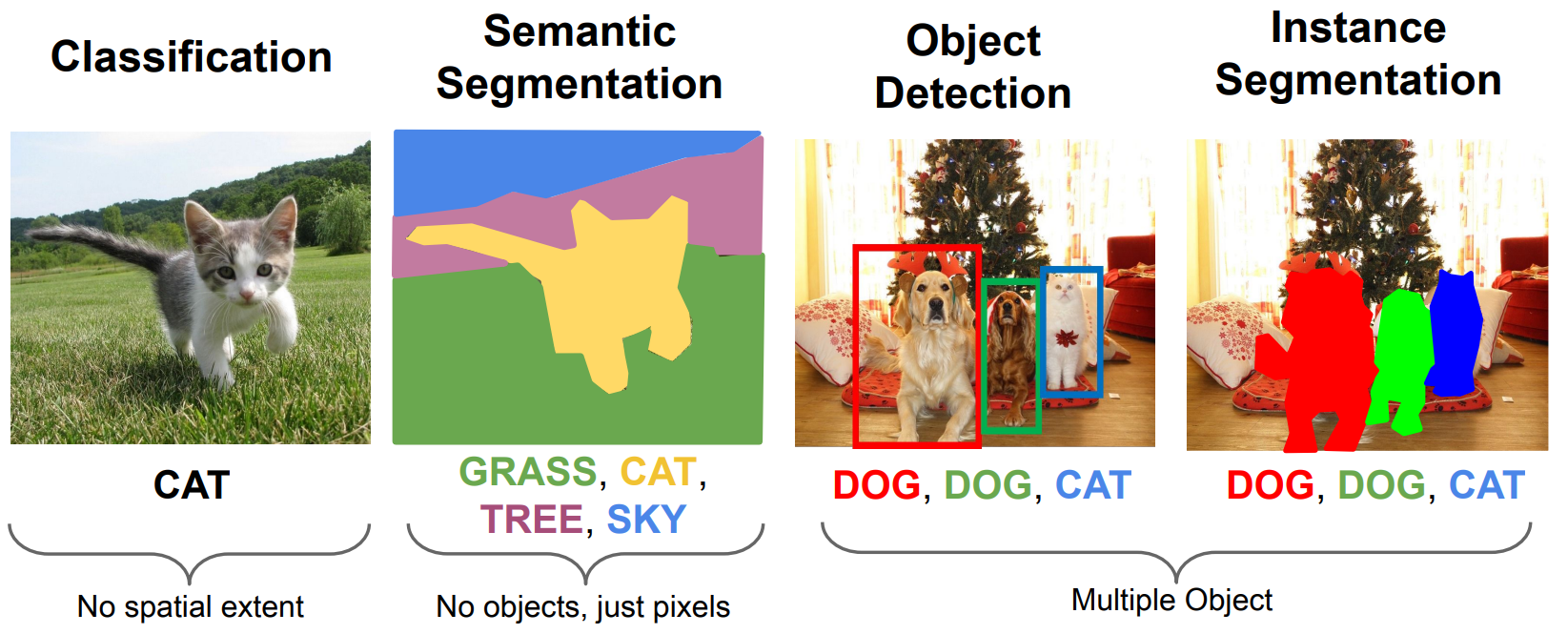
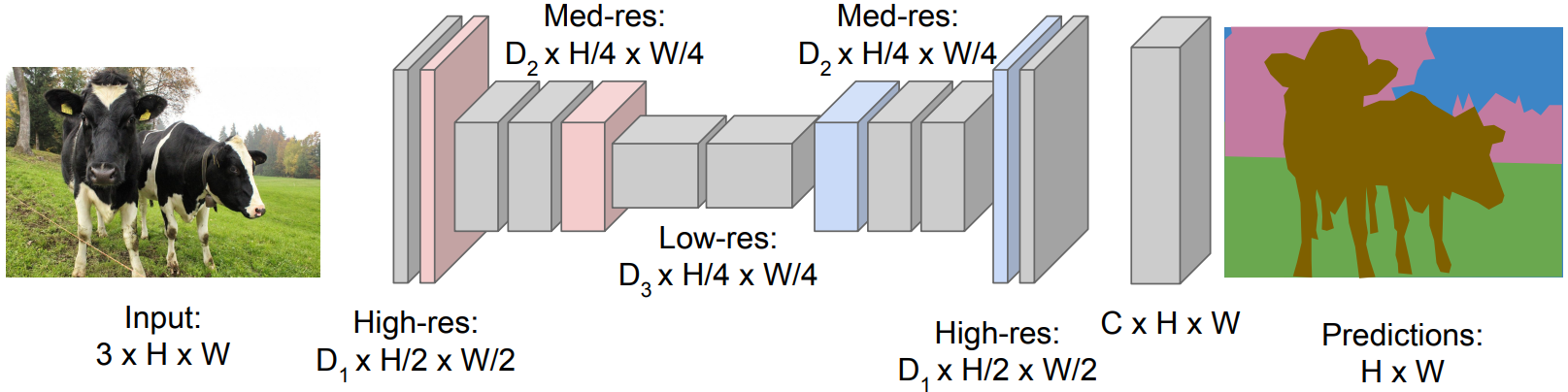
Semantic Segmentation¶
Paired Training Data: For each training image, each pixel is labeled with a semantic category.

Fully Convolutional Network: Design a network with only convolutional layers without downsampling operators to make predictions for pixels all at once!

Problem: Convolutions at original image resolution will be very expensive...
Solution: Design fully convolutional network with downsampling and upsampling inside it!
- Downsampling: Pooling, strided convolution.
- Upsampling: Unpooling, transposed convolution.
Unpooling:
| Nearest Neighbor | "Bed of Nails" | "Position Memory" |
|---|---|---|
 |  |  |
Transposed Convolution: (example size \(3\times3\), stride \(2\), pad \(1\))
| Normal Convolution | Transposed Convolution |
|---|---|
Object Detection¶
Single Object¶
Classification + Localization. (classification + regression problem)

Multiple Object¶
R-CNN¶
Using selective search to find “blobby” image regions that are likely to contain objects.
- Find regions of interest (RoI) using selective search. (region proposal)
- Forward each region through ConvNet.
- Classify features with SVMs.
Problem: Very slow. Need to do 2000 independent forward passes for each image!

Fast R-CNN¶
Pass the image through ConvNet before cropping. Crop the conv feature instead.
- Run whole image through ConvNet.
- Find regions of interest (RoI) from conv features using selective search. (region proposal)
- Classify RoIs using CNN.
Problem: Runtime is dominated by region proposals. (about \(90\%\) time cost)

Faster R-CNN¶
Insert Region Proposal Network (RPN) to predict proposals from features.
Otherwise same as Fast R-CNN: Crop features for each proposal, classify each one.
Region Proposal Network (RPN) : Slide many fixed windows over ConvNet features.
- Treat each point in the feature map as the anchor.
We have \(k\) fixed windows (anchor boxes) of different size/scale centered with each anchor.
- For each anchor box, predict whether it contains an object.
For positive boxes, also predict a corrections to the ground-truth box.
- Slide anchor over the feature map, get the “objectness” score for each box at each point.
- Sort the “objectness” score, take top \(300\) as the proposals.

Faster R-CNN is a Two-stage object detector:
- First stage: Run once per image
Backbone network
Region proposal network
- Second stage: Run once per region
Crop features: RoI pool / align
Predict object class
Prediction bbox offset

Single-Stage Object Detectors: YOLO¶
You Only Look Once: Unified, Real-Time Object Detection
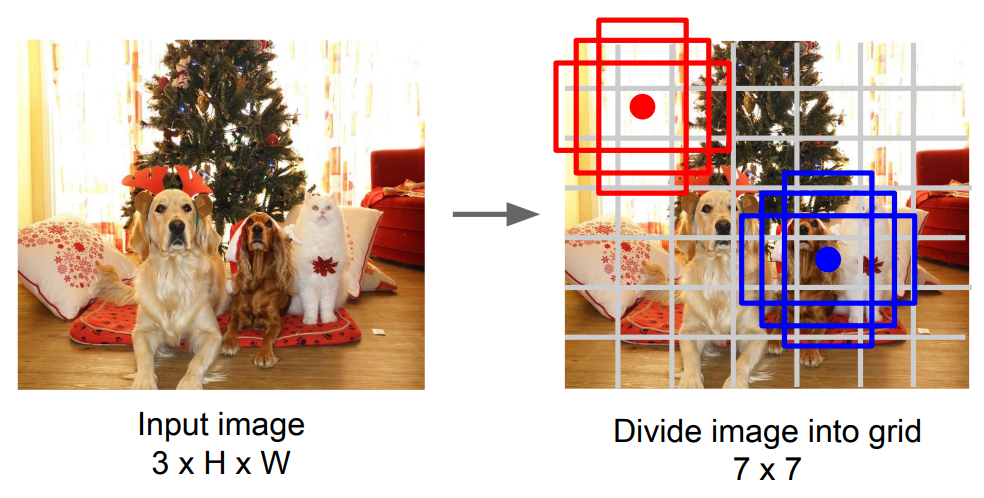
- Divide image into grids. (example image grids shape \(7\times7\))
- Set anchors in the middle of each grid.
- For each grid: - Using \(B\) anchor boxes to regress \(5\) numbers: \(\text{dx, dy, dh, dw, confidence}\). - Predict scores for each of \(C\) classes.
- Finally the output is \(7\times7\times(5B+C)\).
Instance Segmentation¶
Mask R-CNN: Add a small mask network that operates on each RoI and predicts a \(28\times28\) binary mask.

Mask R-CNN performs very good results!

10 - Recurrent Neural Networks¶
Supplement content added according to Deep Learning Book - RNN.
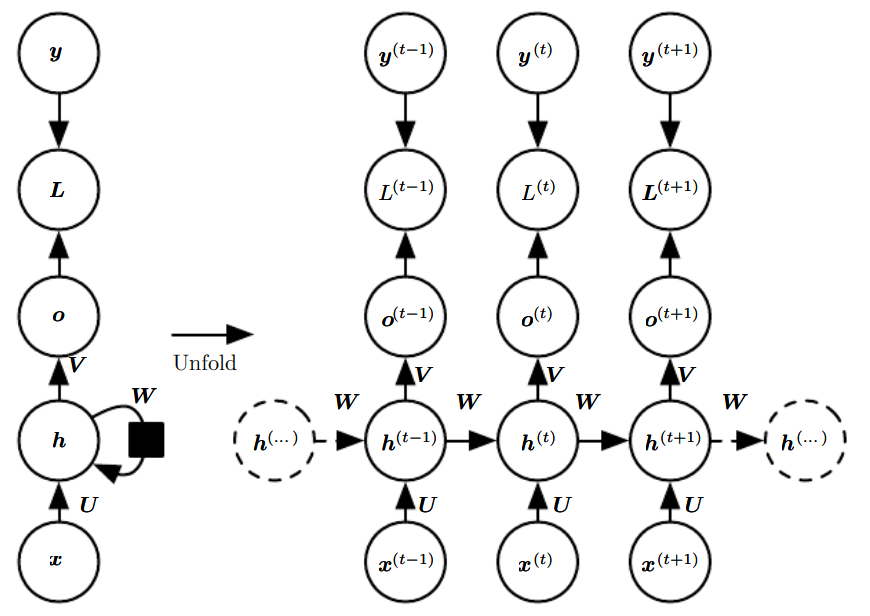
Recurrent Neural Network (RNN)¶
Motivation: Sequence Processing¶
| One to One | One to Many | Many to One | Many to Many | Many to Many |
|---|---|---|---|---|
 |  |  |  |  |
| Vanilla Neural Networks | Image Captioning | Action Prediction | Video Captioning | Video Classification on Frame Level |
Vanilla RNN¶
\(x^{(t)}\) : Input at time \(t\).
\(h^{(t)}\) : State at time \(t\).
\(o^{(t)}\) : Output at time \(t\).
\(y^{(t)}\) : Expected output at time \(t\).
Many to One¶

| Calculation | |
|---|---|
| State Transition | \(h^{(t)}=\tanh(Wh^{(t-1)}+Ux^{(t)}+b)\) |
| Output Calculation | \(o^{(\tau)}=\text{sigmoid}\ \big(Vh^{(\tau)}+c\big)\) |
Many to Many (type 2)¶
| Calculation | |
|---|---|
| State Transition | \(h^{(t)}=\tanh(Wh^{(t-1)}+Ux^{(t)}+b)\) |
| Output Calculation | \(o^{(t)}=\text{sigmoid}\ \big(Vh^{(t)}+c\big)\) |
RNN with Teacher Forcing¶
Update current state according to last-time output instead of last-time state.

| Calculation | |
|---|---|
| State Transition | \(h^{(t)}=\tanh(Wo^{(t-1)}+Ux^{(t)}+b)\) |
| Output Calculation | \(o^{(t)}=\text{sigmoid}\ \big(Vh^{(t)}+c\big)\) |
RNN with "Output Forwarding"¶
We can also combine last-state output with this-state input together.

| Calculation | |
|---|---|
| State Transition (training) | \(h^{(t)}=\tanh(Wh^{(t-1)}+Ux^{(t)}+Ry^{(t-1)}+b)\) |
| State Transition (testing) | \(h^{(t)}=\tanh(Wh^{(t-1)}+Ux^{(t)}+Ro^{(t-1)}+b)\) |
| Output Calculation | \(o^{(t)}=\text{sigmoid}\ \big(Vh^{(t)}+c\big)\) |
Usually we use \(o^{(t-1)}\) in place of \(y^{(t-1)}\) at testing time.
Bidirectional RNN¶
When dealing with a whole input sequence, we can process features from two directions.

| Calculation | |
|---|---|
| State Transition (forward) | \(h^{(t)}=\tanh(W_1h^{(t-1)}+U_1x^{(t)}+b_1)\) |
| State Transition (backward) | \(g^{(t)}=\tanh(W_2g^{(t+1)}+U_2x^{(t)}+b_2)\) |
| Output Calculation | \(o^{(t)}=\text{sigmoid}\ \big(Vh^{(t)}+Wg^{(t)}+c\big)\) |
Encoder-Decoder Sequence to Sequence RNN¶
This is a many-to-many structure (type 1).
First we encode information according to \(x\) with no output.
Later we decode information according to \(y\) with no input.
\(C\) : Context vector, often \(C=h^{(T)}\) (last state of encoder).

| Calculation | |
|---|---|
| State Transition (encode) | \(h^{(t)}=\tanh(W_1h^{(t-1)}+U_1x^{(t)}+b_1)\) |
| State Transition (decode, training) | \(s^{(t)}=\tanh(W_2s^{(t-1)}+U_2y^{(t)}+TC+b_2)\) |
| State Transition (decode, testing) | \(s^{(t)}=\tanh(W_2s^{(t-1)}+U_2o^{(t)}+TC+b_2)\) |
| Output Calculation | \(o^{(t)}=\text{sigmoid}\ \big(Vs^{(t)}+c\big)\) |
Example: Image Captioning¶

Summary¶
Advantages of RNN:
- Can process any length input.
- Computation for step \(t\) can (in theory) use information from many steps back.
- Model size doesn’t increase for longer input.
- Same weights applied on every timestep, so there is symmetry in how inputs are processed.
Disadvantages of RNN:
- Recurrent computation is slow.
- In practice, difficult to access information from many steps back.
- Problems with gradient exploding and gradient vanishing. (check Deep Learning Book - RNN Page 396, Chap 10.7)
Long Short Term Memory (LSTM)¶
Add a "cell block" to store history weights.
\(c^{(t)}\) : Cell at time \(t\).
\(f^{(t)}\) : Forget gate at time \(t\). Deciding whether to erase the cell.
\(i^{(t)}\) : Input gate at time \(t\). Deciding whether to write to the cell.
\(g^{(t)}\) : External input gate at time \(t\). Deciding how much to write to the cell.
\(o^{(t)}\) : Output gate at time \(t\). Deciding how much to reveal the cell.

| Calculation (Gate) | |
|---|---|
| Forget Gate | \(f^{(t)}=\text{sigmoid}\ \big(W_fh^{(t-1)}+U_fx^{(t)}+b_f\big)\) |
| Input Gate | \(i^{(t)}=\text{sigmoid}\ \big(W_ih^{(t-1)}+U_ix^{(t)}+b_i\big)\) |
| External Input Gate | \(g^{(t)}=\tanh(W_gh^{(t-1)}+U_gx^{(t)}+b_g)\) |
| Output Gate | \(o^{(t)}=\text{sigmoid}\ \big(W_oh^{(t-1)}+U_ox^{(t)}+b_o\big)\) |
| Calculation (Main) | |
|---|---|
| Cell Transition | \(c^{(t)}=f^{(t)}\odot c^{(t-1)}+i^{(t)}\odot g^{(t)}\) |
| State Transition | \(h^{(t)}=o^{(t)}\odot\tanh(c^{(t)})\) |
| Output Calculation | \(O^{(t)}=\text{sigmoid}\ \big(Vh^{(t)}+c\big)\) |

Other RNN Variants¶
GRU...
11 - Attention and Transformers¶
RNN with Attention¶
Encoder-Decoder Sequence to Sequence RNN Problem:
Input sequence bottlenecked through a fixed-sized context vector \(C\). (e.g. \(T=1000\))

Intuitive Solution:
Generate new context vector \(C_t\) at each step \(t\) !
\(e_{t,i}\) : Alignment score for input \(i\) at state \(t\). (scalar)
\(a_{t,i}\) : Attention weight for input \(i\) at state \(t\).
\(C_t\) : Context vector at state \(t\).


| Calculation | |
|---|---|
| Alignment Score | \(e_i^{(t)}=f(s^{(t-1)},h^{(i)})\). Where \(f\) is an MLP. |
| Attention Weight | \(a_i^{(t)}=\text{softmax}\ (e_i^{(t)})\). Softmax includes all \(e_i\) at state \(t\). |
| Context Vector | \(C^{(t)}=\sum_i a_i^{(t)}h^{(i)}\) |
| Decoder State Transition | \(s^{(t)}=\tanh(Ws^{(t-1)}+Uy^{(t)}+TC^{(t)}+b)\) |
Example on Image Captioning:


General Attention Layer¶
Add linear transformations to the input vector before attention.

Notice:
- Number of queries \(q\) is variant. (can be different from the number of keys \(k\))
- Number of outputs \(y\) is equal to the number of queries \(q\).
Each \(y\) is a linear weighting of values \(v\).
- Alignment \(e\) is divided by \(\sqrt{D}\) to avoid "explosion of softmax", where \(D\) is the dimension of input feature.
Self-attention Layer¶
The query vectors \(q\) are also generated from the inputs.

In this way, the shape of \(y\) is equal to the shape of \(x\).
Example with CNN:

Positional Encoding¶
Self-attention layer doesn’t care about the orders of the inputs!

To encode ordered sequences like language or spatially ordered image features, we can add positional encoding to the inputs.

We use a function \(P:R\rightarrow R^d\) to process the position \(i\) into a d-dimensional vector \(p_i=P(i)\).
| Constraint Condition of \(P\) | |
|---|---|
| Uniqueness | \(P(i)\ne P(j)\) |
| Equidistance | \(\lVert P(i+k)-P(i)\rVert^2=\lVert P(j+k)-P(j)\rVert^2\) |
| Boundness | \(P(i)\in[a,b]\) |
| Determinacy | \(P(i)\) is always a static value. (function is not dynamic) |
We can either train a encoder model, or design a fixed function.
A Practical Positional Encoding Method: Using \(\sin\) and \(\cos\) with different frequency \(\omega\) at different dimension.
\(P(t)=\begin{bmatrix}\sin(\omega_1,t)\\\cos(\omega_1,t)\\\\\sin(\omega_2,t)\\\cos(\omega_2,t)\\\vdots\\\sin(\omega_{\frac{d}{2}},t)\\\cos(\omega_{\frac{d}{2}},t)\end{bmatrix}\), where frequency \(\omega_k=\frac{1}{10000^{\frac{2k}{d}}}\\\). (wave length \(\lambda=\frac{1}{\omega}=10000^{\frac{2k}{d}}\\\))
\(P(t)=\begin{bmatrix}\sin(1/10000^{\frac{2}{d}},t)\\\cos(1/10000^{\frac{2}{d}},t)\\\\\sin(1/10000^{\frac{4}{d}},t)\\\cos(1/10000^{\frac{4}{d}},t)\\\vdots\\\sin(1/10000^1,t)\\\cos(1/10000^1,t)\end{bmatrix}\), after we substitute \(\omega_k\) into the equation.
\(P(t)\) is a vector with size \(d\), where \(d\) is a hyperparameter to choose according to the length of input sequence.
An intuition of this method is the binary encoding of numbers.

[lecture 11d] 注意力和 transformer (positional encoding 补充,代码实现,距离计算 )
It is easy to prove that \(P(t)\) satisfies "Equidistance": (set \(d=2\) for example)
\(\begin{aligned}\lVert P(i+k)-P(i)\rVert^2&=\big[\sin(\omega_1,i+k)-\sin(\omega_1,i)\big]^2+\big[\cos(\omega_1,i+k)-\cos(\omega_1,i)\big]^2\\&=2-2\sin(\omega_1,i+k)\sin(\omega_1,i)-2\cos(\omega_1,i+k)\cos(\omega_1,i)\\&=2-2\cos(\omega_1,k)\end{aligned}\)
So the distance is not associated with \(i\), we have \(\lVert P(i+k)-P(i)\rVert^2=\lVert P(j+k)-P(j)\rVert^2\).
Visualization of \(P(t)\) features: (set \(d=32\), \(x\) axis represents the position of sequence)

Masked Self-attention Layer¶
To prevent vectors from looking at future vectors, we manually set alignment scores to \(-\infty\).

Multi-head Self-attention Layer¶
Multiple self-attention heads in parallel.

Transformer¶
Encoder Block¶
Inputs: Set of vectors \(z\). (in which \(z_i\) can be a word in a sentence, or a pixel in a picture...)
Output: Set of context vectors \(c\). (encoded features of \(z\))
![]()
The number of blocks \(N=6\) in original paper.
Notice:
- Self-attention is the only interaction between vectors \(x_0,x_1,\dots,x_n\).
- Layer norm and MLP operate independently per vector.
- Highly scalable, highly parallelizable, but high memory usage.
Decoder Block¶
Inputs: Set of vectors \(y\). (\(y_i\) can be a word in a sentence, or a pixel in a picture...)
Inputs: Set of context vectors \(c\).
Output: Set of vectors \(y'\). (decoded result, \(y'_i=y_{i+1}\) for the first \(n-1\) number of \(y'\))
![]()
The number of blocks \(N=6\) in original paper.
Notice:
- Masked self-attention only interacts with past inputs.
- Multi-head attention block is NOT self-attention. It attends over encoder outputs.
- Highly scalable, highly parallelizable, but high memory usage. (same as encoder)
Why we need mask in decoder:
- Needs for the special formation of output \(y'_i=y_{i+1}\).
- Needs for parallel computation.
在测试或者预测时,Transformer 里 decoder 为什么还需要 seq mask?
Example on Image Captioning (Only with Transformers)¶
![]()
Comparing RNNs to Transformer¶
| RNNs | Transformer | |
|---|---|---|
| Pros | LSTMs work reasonably well for long sequences. | 1. Good at long sequences. Each attention calculation looks at all inputs. 2. Can operate over unordered sets or ordered sequences with positional encodings. 3. Parallel computation: All alignment and attention scores for all inputs can be done in parallel. |
| Cons | 1. Expects an ordered sequences of inputs. 2. Sequential computation: Subsequent hidden states can only be computed after the previous ones are done. | Requires a lot of memory: \(N\times M\) alignment and attention scalers need to be calculated and stored for a single self-attention head. |
Comparing ConvNets to Transformer¶
ConvNets strike back!
![]()
12 - Video Understanding¶
Video Classification¶
Take video classification task for example.

Input size: \(C\times T\times H\times W\).
The problem is, videos are quite big. We can't afford to train on raw videos, instead we train on video clips.
| Raw Videos | Video Clips |
|---|---|
| \(1920\times1080,\ 30\text{fps}\) | \(112\times112,\ 5\text{f}/3.2\text{s}\) |
| \(10\text{GB}/\text{min}\) | \(588\text{KB}/\text{min}\) |

Plain CNN Structure¶
Single Frame 2D-CNN¶
Train a normal 2D-CNN model.
Classify each frame independently.
Average the result of each frame as the final result.

Late Fusion¶
Get high-level appearance of each frame, and combine them.
Run 2D-CNN on each frame, pool features and feed to Linear Layers.

Problem: Hard to compare low-level motion between frames.

Early Fusion¶
Compare frames with very first Conv Layer, after that normal 2D-CNN.

Problem: One layer of temporal processing may not be enough!
3D-CNN¶
Convolve on 3 dimensions: Height, Width, Time.
Input size: \(C_{in}\times T\times H\times W\).
Kernel size: \(C_{in}\times C_{out}\times 3\times 3\times 3\).
Output size: \(C_{out}\times T\times H\times W\). (with zero paddling)

C3D (VGG of 3D-CNNs)¶
The cost is quite expensive...
| Network | Calculation |
|---|---|
| AlexNet | 0.7 GFLOP |
| VGG-16 | 13.6 GFLOP |
| C3D | 39.5 GFLOP |
Two-Stream Networks¶
Separate motion and appearance.

I3D (Inflating 2D Networks to 3D)¶
Take a 2D-CNN architecture.
Replace each 2D conv/pool layer with a 3D version.

Modeling Long-term Temporal Structure¶
Recurrent Convolutional Network¶
Similar to multi-layer RNN, we replace the dot-product operation with convolution.

Feature size in layer \(L\), time \(t-1\): \(W_h\times H\times W\).
Feature size in layer \(L-1\), time \(t\): \(W_x\times H\times W\).
Feature size in layer \(L\), time \(t\): \((W_h+W_x)\times H\times W\).

Problem: RNNs are slow for long sequences. (can’t be parallelized)
Spatio-temporal Self-attention¶
Introduce self-attention into video classification problems.


Vision Transformers for Video¶
Factorized attention: Attend over space / time.
So many papers...
![]()
Visualizing Video Models¶


Multimodal Video Understanding¶
Temporal Action Localization¶
Given a long untrimmed video sequence, identify frames corresponding to different actions.

Spatio-Temporal Detection¶
Given a long untrimmed video, detect all the people in both space and time and classify the activities they are performing.
Visually-guided Audio Source Separation¶

And So on...
13 - Generative Models¶

PixelRNN and PixelCNN¶
Fully Visible Belief Network (FVBN)¶
\(p(x)\) : Likelihood of image \(x\).
\(p(x_1,x_2,\dots,x_n)\) : Joint likelihood of all \(n\) pixels in image \(x\).
\(p(x_i|x_1,x_2,\dots,x_{i-1})\) : Probability of pixel \(i\) value given all previous pixels.
For explicit density models, we have \(p(x)=p(x_1,x_2,\dots,x_n)=\prod_{i=1}^np(x_i|x_1,x_2,\dots,x_{i-1})\\\).
Objective: Maximize the likelihood of training data.

PixelRNN¶
Generate image pixels starting from corner.
Dependency on previous pixels modeled using an RNN (LSTM).
Drawback: Sequential generation is slow in both training and inference!
![]()
PixelCNN¶
Still generate image pixels starting from corner.
Dependency on previous pixels modeled using a CNN over context region (masked convolution).
Drawback: Though its training is faster, its generation is still slow. (pixel by pixel)
![]()
Variational Autoencoder¶
Supplement content added according to Tutorial on Variational Autoencoders. (paper with notes: VAE Tutorial.pdf)
Autoencoder¶
Learn a lower-dimensional feature representation with unsupervised approaches.
\(x\rightarrow z\) : Dimension reduction for input features.
\(z\rightarrow \hat{x}\) : Reconstruct input features.

After training, we throw the decoder away and use the encoder for transferring.
![]()
For generative models, there is a problem:
We can’t generate new images from an autoencoder because we don’t know the space of \(z\).
Variational Autoencoder¶
Character Description¶
\(X\) : Images. (random variable)
\(Z\) : Latent representations. (random variable)
\(P(X)\) : True distribution of all training images \(X\).
\(P(Z)\) : True distribution of all latent representations \(Z\).
\(P(X|Z)\) : True posterior distribution of all images \(X\) with condition \(Z\).
\(P(Z|X)\) : True prior distribution of all latent representations \(Z\) with condition \(X\).
\(Q(Z|X)\) : Approximated prior distribution of all latent representations \(Z\) with condition \(X\).
\(x\) : A specific image.
\(z\) : A specific latent representation.
\(\theta\): Learned parameters in decoder network.
\(\phi\): Learned parameters in encoder network.
\(p_\theta(x)\) : Probability that \(x\sim P(X)\).
\(p_\theta(z)\) : Probability that \(z\sim P(Z)\).
\(p_\theta(x|z)\) : Probability that \(x\sim P(X|Z)\).
\(p_\theta(z|x)\) : Probability that \(z\sim P(Z|X)\).
\(q_\phi(z|x)\) : Probability that \(z\sim Q(Z|X)\).
Decoder¶
Objective:
Generate new images from \(\mathscr{z}\).
- Generate a value \(z^{(i)}\) from the prior distribution \(P(Z)\).
- Generate a value \(x^{(i)}\) from the conditional distribution \(P(X|Z)\).
Lemma:
Any distribution in \(d\) dimensions can be generated by taking a set of \(d\) variables that are normally distributed and mapping them through a sufficiently complicated function. (source: Tutorial on Variational Autoencoders, Page 6)
Solutions:
- Choose prior distribution \(P(Z)\) to be a simple distribution, for example \(P(Z)\sim N(0,1)\).
- Learn the conditional distribution \(P(X|Z)\) through a neural network (decoder) with parameter \(\theta\).

Encoder¶
Objective:
Learn \(\mathscr{z}\) with training images.
Given: (From the decoder, we can deduce the following probabilities.)
- data likelihood: \(p_\theta(x)=\int p_\theta(x|z)p_\theta(z)dz\).
- posterior density: \(p_\theta(z|x)=\frac{p_\theta(x|z)p_\theta(z)}{p_\theta(x)}=\frac{p_\theta(x|z)p_\theta(z)}{\int p_\theta(x|z)p_\theta(z)dz}\).
Problem:
Both \(p_\theta(x)\) and \(p_\theta(z|x)\) are intractable. (can't be optimized directly as they contain integral operation)
Solution:
Learn \(Q(Z|X)\) to approximate the true posterior \(P(Z|X)\).
Use \(q_\phi(z|x)\) in place of \(p_\theta(z|x)\).

Variational Autoencoder (Combination of Encoder and Decoder)¶
Objective:
Maximize \(p_\theta(x)\) for all \(x^{(i)}\) in the training set.
$$ \begin{aligned} \log p_\theta\big(x^{(i)}\big)&=\mathbb{E}{z\sim q\phi\big(z|x^{(i)}\big)}\Big[\log p_\theta\big(x^{(i)}\big)\Big]\
&=\mathbb{E}z\Bigg[\log\frac{p\theta\big(x^{(i)}|z\big)p_\theta\big(z\big)}{p_\theta\big(z|x^{(i)}\big)}\Bigg]\quad\text{(Bayes' Rule)}\
&=\mathbb{E}z\Bigg[\log\frac{p\theta\big(x^{(i)}|z\big)p_\theta\big(z\big)}{p_\theta\big(z|x^{(i)}\big)}\frac{q_\phi\big(z|x^{(i)}\big)}{q_\phi\big(z|x^{(i)}\big)}\Bigg]\quad\text{(Multiply by Constant)}\
&=\mathbb{E}z\Big[\log p\theta\big(x^{(i)}|z\big)\Big]-\mathbb{E}z\Bigg[\log\frac{q\phi\big(z|x^{(i)}\big)}{p_\theta\big(z\big)}\Bigg]+\mathbb{E}z\Bigg[\log\frac{p\theta\big(z|x^{(i)}\big)}{q_\phi\big(z|x^{(i)}\big)}\Bigg]\quad\text{(Logarithm)}\
&=\mathbb{E}z\Big[\log p\theta\big(x^{(i)}|z\big)\Big]-D_{\text{KL}}\Big[q_\phi\big(z|x^{(i)}\big)||p_\theta\big(z\big)\Big]+D_{\text{KL}}\Big[p_\theta\big(z|x^{(i)}\big)||q_\phi\big(z|x^{(i)}\big)\Big]\quad\text{(KL Divergence)} \end{aligned} $$
Analyze the Formula by Term:
\(\mathbb{E}_z\Big[\log p_\theta\big(x^{(i)}|z\big)\Big]\): Decoder network gives \(p_\theta\big(x^{(i)}|z\big)\), can compute estimate of this term through sampling.
\(D_{\text{KL}}\Big[q_\phi\big(z|x^{(i)}\big)||p_\theta\big(z\big)\Big]\): This KL term (between Gaussians for encoder and \(z\) prior) has nice closed-form solution!
\(D_{\text{KL}}\Big[p_\theta\big(z|x^{(i)}\big)||q_\phi\big(z|x^{(i)}\big)\Big]\): The part \(p_\theta\big(z|x^{(i)}\big)\) is intractable. However, we know KL divergence always \(\ge0\).
Tractable Lower Bound:
We can maximize the lower bound of that formula.
As \(D_{\text{KL}}\Big[p_\theta\big(z|x^{(i)}\big)||q_\phi\big(z|x^{(i)}\big)\Big]\ge0\) , we can deduce that:
$$ \begin{aligned} \log p_\theta\big(x^{(i)}\big)&=\mathbb{E}z\Big[\log p\theta\big(x^{(i)}|z\big)\Big]-D_{\text{KL}}\Big[q_\phi\big(z|x^{(i)}\big)||p_\theta\big(z\big)\Big]+D_{\text{KL}}\Big[p_\theta\big(z|x^{(i)}\big)||q_\phi\big(z|x^{(i)}\big)\Big]\
&\ge\mathbb{E}z\Big[\log p\theta\big(x^{(i)}|z\big)\Big]-D_{\text{KL}}\Big[q_\phi\big(z|x^{(i)}\big)||p_\theta\big(z\big)\Big] \end{aligned} $$
So the loss function \(\mathcal{L}\big(x^{(i)},\theta,\phi\big)=-\mathbb{E}_z\Big[\log p_\theta\big(x^{(i)}|z\big)\Big]+D_{\text{KL}}\Big[q_\phi\big(z|x^{(i)}\big)||p_\theta\big(z\big)\Big]\).
\(\mathbb{E}_z\Big[\log p_\theta\big(x^{(i)}|z\big)\Big]\): Decoder, reconstruct the input data.
\(D_{\text{KL}}\Big[q_\phi\big(z|x^{(i)}\big)||p_\theta\big(z\big)\Big]\): Encoder, make approximate posterior distribution close to prior.

Generative Adversarial Networks (GANs)¶
Motivation & Modeling¶
Objective: Not modeling any explicit density function.
Problem: Want to sample from complex, high-dimensional training distribution. No direct way to do this!
Solution: Sample from a simple distribution, e.g. random noise. Learn the transformation to training distribution.

Problem: We can't learn the mapping relation between sample \(z\) and training images.
Solution: Use a discriminator network to tell whether the generate image is within data distribution or not.

Discriminator network: Try to distinguish between real and fake images.
Generator network: Try to fool the discriminator by generating real-looking images.

\(x\) : Real data.
\(y\) : Fake data, which is generated by the generator network. \(y=G_{\theta_g}(z)\).
\(D_{\theta_d}(x)\) : Discriminator score, which is the likelihood of real image. \(D_{\theta_d}(x)\in[0,1]\).
Objective of discriminator network:
\(\max_{\theta_d}\bigg[\mathbb{E}_x\Big(\log D_{\theta_d}(x)\Big)+\mathbb{E}_{z\sim p(z)}\Big(\log\big(1-D_{\theta_d}(y)\big)\Big)\bigg]\)
Objective of generator network:
\(\min_{\theta_g}\max_{\theta_d}\bigg[\mathbb{E}_x\Big(\log D_{\theta_d}(x)\Big)+\mathbb{E}_{z\sim p(z)}\Big(\log\big(1-D_{\theta_d}(y)\big)\Big)\bigg]\)
Training Strategy¶
Two combine this two networks together, we can train them alternately:
- Gradient ascent on discriminator.
\(\max_{\theta_d}\bigg[\mathbb{E}_x\Big(\log D_{\theta_d}(x)\Big)+\mathbb{E}_{z\sim p(z)}\Big(\log\big(1-D_{\theta_d}(y)\big)\Big)\bigg]\)
- Gradient descent on generator.
\(\min_{\theta_g}\bigg[\mathbb{E}_{z\sim p(z)}\Big(\log\big(1-D_{\theta_d}(y)\big)\Big)\bigg]\)
However, the gradient of generator decreases with the value itself, making it hard to optimize.

So we replace \(\log\big(1-D_{\theta_d}(y)\big)\) with \(-\log D_{\theta_d}(y)\), and use gradient ascent instead.
- Gradient ascent on discriminator.
\(\max_{\theta_d}\bigg[\mathbb{E}_x\Big(\log D_{\theta_d}(x)\Big)+\mathbb{E}_{z\sim p(z)}\Big(\log\big(1-D_{\theta_d}(y)\big)\Big)\bigg]\)
- Gradient ascent on generator.
\(\max_{\theta_g}\bigg[\mathbb{E}_{z\sim p(z)}\Big(\log D_{\theta_d}(y)\Big)\bigg]\)
Summary¶
Pros: Beautiful, state-of-the-art samples!
Cons:
- Trickier / more unstable to train.
- Can’t solve inference queries such as \(p(x), p(z|x)\).
14 - Self-supervised Learning¶
Aim: Solve “pretext” tasks that produce good features for downstream tasks.
Application:
- Learn a feature extractor from pretext tasks. (self-supervised)
- Attach a shallow network on the feature extractor.
- Train the shallow network on target task with small amount of labeled data. (supervised)

Pretext Tasks¶
Labels are generated automatically.
Rotation¶
Train a classifier on randomly rotated images.

Rearrangement¶
Train a classifier on randomly shuffled image pieces.
Predict the location of image pieces.

Inpainting¶
Mask part of the image, train a network to predict the masked area.
Method referencing Context Encoders: Feature Learning by Inpainting.
Combine two types of loss together to get better performance:
- Reconstruction loss (L2 loss): Used for reconstructing global features.
- Adversarial loss: Used for generating texture features.

Coloring¶
Transfer between greyscale images and colored images.
Cross-channel predictions for images: Split-Brain Autoencoders.

Video coloring: Establish mappings between reference and target frames in a learned feature space. Tracking Emerges by Colorizing Videos.

Summary for Pretext Tasks¶
- Pretext tasks focus on “visual common sense”.
- The models are forced learn good features about natural images.
- We don’t care about the performance of these pretext tasks.
What we care is the performance of downstream tasks.
Problems of Specific Pretext Tasks¶
- Coming up with individual pretext tasks is tedious.
- The learned representations may not be general.
Intuitive Solution: Contrastive Learning.
Contrastive Representation Learning¶
Local additional references: Contrastive Learning.md.

Objective:
Given a chosen score function \(s\), we aim to learn an encoder function \(f\) that yields:
- For each sample \(x\), increase the similarity \(s\big(f(x),f(x^+)\big)\) between \(x\) and positive samples \(x^+\).
- Finally we want \(s\big(f(x),f(x^+)\big)\gg s\big(f(x),f(x^-)\big)\).
Loss Function:
Given \(1\) positive sample and \(N-1\) negative samples:
| InfoNCE Loss | Cross Entropy Loss |
|---|---|
| \(\begin{aligned}\mathcal{L}=-\mathbb{E}_X\Bigg[\log\frac{\exp{s\big(f(x),f(x^+)\big)}}{\exp{s\big(f(x),f(x^+)\big)}+\sum_{j=1}^{N-1}\exp{s\big(f(x),f(x^+)\big)}}\Bigg]\\\end{aligned}\) | \(\begin{aligned}\mathcal{L}&=-\sum_{i=1}^Np(x_i)\log q(x_i)\\&=-\mathbb{E}_X\big[\log q(x)\big]\\&=-\mathbb{E}_X\Bigg[\log\frac{\exp(x)}{\sum_{j=1}^N\exp(x_j)}\Bigg]\end{aligned}\) |
The InfoNCE Loss is a lower bound on the mutual information between \(f(x)\) and \(f(x^+)\):
\(\text{MI}\big[f(x),f(x^+)\big]\ge\log(N)-\mathcal{L}\)
The larger the negative sample size \(N\), the tighter the bound.
So we use \(N-1\) negative samples.
Instance Contrastive Learning¶
SimCLR¶
Use a projection function \(g(\cdot)\) to project features to a space where contrastive learning is applied.
The extra projection contributes a lot to the final performance.

Score Function: Cos similarity \(s(u,v)=\frac{u^Tv}{||u||||v||}\\\).
Positive Pair: Pair of augmented data.

Momentum Contrastive Learning (MoCo)¶
There are mainly \(3\) training strategy in contrastive learning:
- end-to-end: Keys are updated together with queries, e.g. SimCLR.
(limited by GPU size)
- memory bank: Store last-time keys for sampling.
(inconsistency between \(q\) and \(k\))
- MoCo: Use momentum methods to encode keys.
(combination of end-to-end & memory bank)

Key differences to SimCLR:
- Keep a running queue of keys (negative samples).
- Compute gradients and update the encoder only through the queries.
- Decouple min-batch size with the number of keys: can support a large number of negative samples.
- The key encoder is slowly progressing through the momentum update rules:
\(\theta_k\leftarrow m\theta_k+(1-m)\theta_q\)

Sequence Contrastive Learning¶
Contrastive Predictive Coding (CPC)¶
Contrastive: Contrast between “right” and “wrong” sequences using contrastive learning.
Predictive: The model has to predict future patterns given the current context.
Coding: The model learns useful feature vectors, or “code”, for downstream tasks, similar to other self-supervised methods.

Other Examples (Frontier)¶
Contrastive Language Image Pre-training (CLIP)¶
Contrastive learning between image and natural language sentences.

15 - Low-Level Vision¶
Pass...
16 - 3D Vision¶
Representation¶
Explicit vs Implicit¶
Explicit: Easy to sample examples, hard to do inside/outside check.
Implicit: Hard to sample examples, easy to do inside/outside check.
| Non-parametric | Parametric | |
|---|---|---|
| Explicit | Points. Meshes. | Splines. Subdivision Surfaces. |
| Implicit | Level Sets. Voxels. | Algebraic Surfaces. Constructive Solid Geometry. |
Point Clouds¶
The simplest representation.
Collection of \((x,y,z)\) coordinates.
Cons:
- Difficult to draw in under-sampled regions.
- No simplification or subdivision.
- No direction smooth rendering.
- No topological information.

Polygonal Meshes¶
Collection of vertices \(v\) and edges \(e\).
Pros:
- Can apply downsampling or upsampling on meshes.
- Error decreases by \(O(n^2)\) while meshes increase by \(O(n)\).
- Can approximate arbitrary topology.
- Efficient rendering.

Splines¶
Use specific functions to approximate the surface. (e.g. Bézier Curves)

Algebraic Surfaces¶
Use specific functions to represent the surface.

Constructive Solid Geometry¶
Combine implicit geometry with Boolean operations.

Level Sets¶
Store a grim of values to approximate the function.
Surface is found where interpolated value equals to \(0\).

Voxels¶
Binary thresholding the volumetric grid.

AI + 3D¶
Pass...
wnc's café
Computer Vision¶
约 8852 个字 167 张图片 预计阅读时间 44 分钟 共被读过 次
This note is based on GitHub - DaizeDong/Stanford-CS231n-2021-and-2022: Notes and slides for Stanford CS231n 2021 & 2022 in English. I merged the contents together to get a better version. Assignments are not included. 斯坦福 cs231n 的课程笔记 ( 英文版本,不含实验代码 ),将 2021 与 2022 两年的课程进行了合并,分享以供交流。
And I will add some blogs, articles and other understanding.
| Topic | Chapter |
|---|---|
| Deep Learning Basics | 2 - 4 |
| Perceiving and Understanding the Visual World | 5 - 12 |
| Reconstructing and Interacting with the Visual World | 13 - 16 |
| Human-Centered Applications and Implications | 17 - 18 |
1 - Introduction¶
A brief history of computer vision & deep learning...
2 - Image Classification¶
Image Classification: A core task in Computer Vision. The main drive to the progress of CV.
Challenges: Viewpoint variation, background clutter, illumination, occlusion, deformation, intra-class variation...
K Nearest Neighbor¶
Hyperparameters: Distance metric (\(p\) norm), \(k\) number.
Choose hyperparameters using validation set.
Never use k-Nearest Neighbor with pixel distance.
Linear Classifier¶
Pass...
3 - Loss Functions and Optimization¶
Loss Functions¶
| Dataset | \(\big\{(x_i,y_i)\big\}_{i=1}^N\\\) |
|---|---|
| Loss Function | \(L=\frac{1}{N}\sum_{i=1}^NL_i\big(f(x_i,W),y_i\big)\\\) |
| Loss Function with Regularization | \(L=\frac{1}{N}\sum_{i=1}^NL_i\big(f(x_i,W),y_i\big)+\lambda R(W)\\\) |
Motivation: Want to interpret raw classifier scores as probabilities.
| Softmax Classifier | \(p_i=Softmax(y_i)=\frac{\exp(y_i)}{\sum_{j=1}^N\exp(y_j)}\\\) |
|---|---|
| Cross Entropy Loss | \(L_i=-y_i\log p_i\\\) |
| Cross Entropy Loss with Regularization | \(L=-\frac{1}{N}\sum_{i=1}^Ny_i\log p_i+\lambda R(W)\\\) |
Optimization¶
SGD with Momentum¶
Problems that SGD can't handle:
- Inequality of gradient in different directions.
- Local minima and saddle point (much more common in high dimension).
- Noise of gradient from mini-batch.
Momentum: Build up “velocity” \(v_t\) as a running mean of gradients.
| SGD | SGD + Momentum |
|---|---|
| \(x_{t+1}=x_t-\alpha\nabla f(x_t)\) | \(\begin{align}&v_{t+1}=\rho v_t+\nabla f(x_t)\\&x_{t+1}=x_t-\alpha v_{t+1}\end{align}\) |
| Naive gradient descent. | \(\rho\) gives "friction", typically \(\rho=0.9,0.99,0.999,...\) |
Nesterov Momentum: Use the derivative on point \(x_t+\rho v_t\) as gradient instead point \(x_t\).
| Momentum | Nesterov Momentum |
|---|---|
| \(\begin{align}&v_{t+1}=\rho v_t+\nabla f(x_t)\\&x_{t+1}=x_t-\alpha v_{t+1}\end{align}\) | \(\begin{align}&v_{t+1}=\rho v_t+\nabla f(x_t+\rho v_t)\\&x_{t+1}=x_t-\alpha v_{t+1}\end{align}\) |
| Use gradient at current point. | Look ahead for the gradient in velocity direction. |
AdaGrad and RMSProp¶
AdaGrad: Accumulate squared gradient, and gradually decrease the step size.
RMSProp: Accumulate squared gradient while decaying former ones, and gradually decrease the step size. ("Leaky AdaGrad")
| AdaGrad | RMSProp |
|---|---|
| \(\begin{align}\text{Initialize:}&\\&r:=0\\\text{Update:}&\\&r:=r+\Big[\nabla f(x_t)\Big]^2\\&x_{t+1}=x_t-\alpha\frac{\nabla f(x_t)}{\sqrt{r}}\end{align}\) | \(\begin{align}\text{Initialize:}&\\&r:=0\\\text{Update:}&\\&r:=\rho r+(1-\rho)\Big[\nabla f(x_t)\Big]^2\\&x_{t+1}=x_t-\alpha\frac{\nabla f(x_t)}{\sqrt{r}}\end{align}\) |
| Continually accumulate squared gradients. | \(\rho\) gives "decay rate", typically \(\rho=0.9,0.99,0.999,...\) |
Adam¶
Sort of like "RMSProp + Momentum".
| Adam (simple version) | Adam (full version) |
|---|---|
| \(\begin{align}\text{Initialize:}&\\&r_1:=0\\&r_2:=0\\\text{Update:}&\\&r_1:=\beta_1r_1+(1-\beta_1)\nabla f(x_t)\\&r_2:=\beta_2r_2+(1-\beta_2)\Big[\nabla f(x_t)\Big]^2\\&x_{t+1}=x_t-\alpha\frac{r_1}{\sqrt{r_2}}\end{align}\) | \(\begin{align}\text{Initialize:}\\&r_1:=0\\&r_2:=0\\\text{For }i\text{:}\\&r_1:=\beta_1r_1+(1-\beta_1)\nabla f(x_t)\\&r_2:=\beta_2r_2+(1-\beta_2)\Big[\nabla f(x_t)\Big]^2\\&r_1'=\frac{r_1}{1-\beta_1^i}\\&r_2'=\frac{r_2}{1-\beta_2^i}\\&x_{t+1}=x_t-\alpha\frac{r_1'}{\sqrt{r_2'}}\end{align}\) |
| Build up “velocity” for both gradient and squared gradient. | Correct the "bias" that \(r_1=r_2=0\) for the first few iterations. |
Overview¶
| |
|---|---|
Learning Rate Decay¶
Reduce learning rate at a few fixed points to get a better convergence over time.
\(\alpha_0\) : Initial learning rate.
\(\alpha_t\) : Learning rate in epoch \(t\).
\(T\) : Total number of epochs.
| Method | Equation | Picture |
|---|---|---|
| Step | Reduce \(\alpha_t\) constantly in a fixed step. | |
| Cosine | \(\begin{align}\alpha_t=\frac{1}{2}\alpha_0\Bigg[1+\cos(\frac{t\pi}{T})\Bigg]\end{align}\) | |
| Linear | \(\begin{align}\alpha_t=\alpha_0\Big(1-\frac{t}{T}\Big)\end{align}\) | |
| Inverse Sqrt | \(\begin{align}\alpha_t=\frac{\alpha_0}{\sqrt{t}}\end{align}\) | |
High initial learning rates can make loss explode, linearly increasing learning rate in the first few iterations can prevent this.
Learning rate warm up:
Empirical rule of thumb: If you increase the batch size by \(N\), also scale the initial learning rate by \(N\) .
Second-Order Optimization¶
| Picture | Time Complexity | Space Complexity | |
|---|---|---|---|
| First Order | | \(O(n)\) | \(O(n)\) |
| Second Order | | \(O(n^2)\) with BGFS optimization | \(O(n)\) with L-BGFS optimization |
L-BGFS : Limited memory BGFS.
- Works very well in full batch, deterministic \(f(x)\).
- Does not transfer very well to mini-batch setting.
Summary¶
| Method | Performance |
|---|---|
| Adam | Often chosen as default method. Work ok even with constant learning rate. |
| SGD + Momentum | Can outperform Adam. Require more tuning of learning rate and schedule. |
| L-BGFS | If can afford to do full batch updates then try out. |
- An article about gradient descent: Anoverview of gradient descent optimization algorithms
- A blog: An updated overview of recent gradient descent algorithms – John Chen – ML at Rice University
4 - Neural Networks and Backpropagation¶
Neural Networks¶
Motivation: Inducted bias can appear to be high when using human-designed features.
Activation: Sigmoid, tanh, ReLU, LeakyReLU...
Architecture: Input layer, hidden layer, output layer.
Do not use the size of a neural network as the regularizer. Use regularization instead!
Gradient Calculation: Computational Graph + Backpropagation.
Backpropagation¶
Using Jacobian matrix to calculate the gradient of each node in a computation graph.
Suppose that we have a computation flow like this:
| Input X | Input W | Output Y |
|---|---|---|
| \(X=\begin{bmatrix}x_1\\x_2\\\vdots\\x_n\end{bmatrix}\) | \(W=\begin{bmatrix}w_{11}&w_{12}&\cdots&w_{1n}\\w_{21}&w_{22}&\cdots&w_{2n}\\\vdots&\vdots&\ddots&\vdots\\w_{m1}&w_{m2}&\cdots&w_{mn}\end{bmatrix}\) | \(Y=\begin{bmatrix}y_1\\y_2\\\vdots\\y_m\end{bmatrix}\) |
| \(n\times 1\) | \(m\times n\) | \(m\times 1\) |
After applying feed forward, we can calculate gradients like this:
| Derivative Matrix of X | Jacobian Matrix of X | Derivative Matrix of Y |
|---|---|---|
| \(D_X=\begin{bmatrix}\frac{\partial L}{\partial x_1}\\\frac{\partial L}{\partial x_2}\\\vdots\\\frac{\partial L}{\partial x_n}\end{bmatrix}\) | \(J_X=\begin{bmatrix}\frac{\partial y_1}{\partial x_1}&\frac{\partial y_1}{\partial x_2}&\cdots&\frac{\partial y_1}{\partial x_n}\\\frac{\partial y_2}{\partial x_1}&\frac{\partial y_2}{\partial x_2}&\cdots&\frac{\partial y_2}{\partial x_n}\\\vdots&\vdots&\ddots&\vdots\\\frac{\partial y_m}{\partial x_1}&\frac{\partial y_m}{\partial x_2}&\cdots&\frac{\partial y_m}{\partial x_n}\end{bmatrix}\) | \(D_Y=\begin{bmatrix}\frac{\partial L}{\partial y_1}\\\frac{\partial L}{\partial y_2}\\\vdots\\\frac{\partial L}{\partial y_m}\end{bmatrix}\) |
| \(n\times 1\) | \(m\times n\) | \(m\times 1\) |
| Derivative Matrix of W | Jacobian Matrix of W | Derivative Matrix of Y |
|---|---|---|
| \(W=\begin{bmatrix}\frac{\partial L}{\partial w_{11}}&\frac{\partial L}{\partial w_{12}}&\cdots&\frac{\partial L}{\partial w_{1n}}\\\frac{\partial L}{\partial w_{21}}&\frac{\partial L}{\partial w_{22}}&\cdots&\frac{\partial L}{\partial w_{2n}}\\\vdots&\vdots&\ddots&\vdots\\\frac{\partial L}{\partial w_{m1}}&\frac{\partial L}{\partial w_{m2}}&\cdots&\frac{\partial L}{\partial w_{mn}}\end{bmatrix}\) | \(J_W^{(k)}=\begin{bmatrix}\frac{\partial y_k}{\partial w_{11}}&\frac{\partial y_k}{\partial w_{12}}&\cdots&\frac{\partial y_k}{\partial w_{1n}}\\\frac{\partial y_k}{\partial w_{21}}&\frac{\partial y_k}{\partial w_{22}}&\cdots&\frac{\partial y_k}{\partial w_{2n}}\\\vdots&\vdots&\ddots&\vdots\\\frac{\partial y_k}{\partial w_{m1}}&\frac{\partial y_k}{\partial w_{m2}}&\cdots&\frac{\partial y_k}{\partial w_{mn}}\end{bmatrix}\) \(J_W=\begin{bmatrix}J_W^{(1)}&J_W^{(2)}&\cdots&J_W^{(m)}\end{bmatrix}\) | \(D_Y=\begin{bmatrix}\frac{\partial L}{\partial y_1}\\\frac{\partial L}{\partial y_2}\\\vdots\\\frac{\partial L}{\partial y_m}\end{bmatrix}\) |
| \(m\times n\) | \(m\times m\times n\) | $ m\times 1$ |
For each element in \(D_X\) , we have:
\(D_{Xi}=\frac{\partial L}{\partial x_i}=\sum_{j=1}^m\frac{\partial L}{\partial y_j}\frac{\partial y_j}{\partial x_i}\\\)
5 - Convolutional Neural Networks¶
Convolution Layer¶
Introduction¶
Convolve a filter with an image: Slide the filter spatially within the image, computing dot products in each region.
Giving a \(32\times32\times3\) image and a \(5\times5\times3\) filter, a convolution looks like:
Convolve six \(5\times5\times3\) filters to a \(32\times32\times3\) image with step size \(1\), we can get a \(28\times28\times6\) feature:
With an activation function after each convolution layer, we can build the ConvNet with a sequence of convolution layers:
By changing the step size between each move for filters, or adding zero-padding around the image, we can modify the size of the output:
\(1\times1\) Convolution Layer¶
This kind of layer makes perfect sense. It is usually used to change the dimension (channel) of features.
A \(1\times1\) convolution layer can also be treated as a full-connected linear layer.
Summary¶
| Input | |
|---|---|
| image size | \(W_1\times H_1\times C\) |
| filter size | \(F\times F\times C\) |
| filter number | \(K\) |
| stride | \(S\) |
| zero padding | \(P\) |
| Output | |
| output size | \(W_2\times H_2\times K\) |
| output width | \(W_2=\frac{W_1-F+2P}{S}+1\\\) |
| output height | \(H_2=\frac{H_1-F+2P}{S}+1\\\) |
| Parameters | |
| parameter number (weight) | \(F^2CK\) |
| parameter number (bias) | \(K\) |
Pooling layer¶
Make the representations smaller and more manageable.
An example of max pooling:
| Input | |
|---|---|
| image size | \(W_1\times H_1\times C\) |
| spatial extent | \(F\times F\) |
| stride | \(S\) |
| Output | |
| output size | \(W_2\times H_2\times C\) |
| output width | \(W_2=\frac{W_1-F}{S}+1\\\) |
| output height | \(H_2=\frac{H_1-F}{S}+1\\\) |
Convolutional Neural Networks (CNN)¶
CNN stack CONV, POOL, FC layers.
CNN Trends:
- Smaller filters and deeper architectures.
- Getting rid of POOL/FC layers (just CONV).
Historically architectures of CNN looked like:
where usually \(m\) is large, \(0\le n\le5\), \(0\le k\le2\).
Recent advances such as ResNet / GoogLeNet have challenged this paradigm.
6 - CNN Architectures¶
Best model in ImageNet competition:
AlexNet¶
8 layers.
First use of ConvNet in image classification problem.
Filter size decreases in deeper layer.
Channel number increases in deeper layer.
VGG¶
19 layers. (also provide 16 layers edition)
Static filter size (\(3\times3\)) in all layers:
- The effective receptive field expands with the layer gets deeper.
- Deeper architecture gets more non-linearities and few parameters.
Most memory is in early convolution layers.
Most parameter is in late FC layers.
GoogLeNet¶
22 layers.
No FC layers, only 5M parameters. ( \(8.3\%\) of AlexNet, \(3.7\%\) of VGG )
Devise efficient "inception module".
Inception Module¶
Design a good local network topology (network within a network) and then stack these modules on top of each other.
Naive Inception Module:
- Apply parallel filter operations on the input from previous layer.
- Concatenate all filter outputs together channel-wise.
- Problem: The depth (channel number) increases too fast, costing expensive computation.
Inception Module with Dimension Reduction:
- Add "bottle neck" layers to reduce the dimension.
- Also get fewer computation cost.
Architecture¶
ResNet¶
152 layers for ImageNet.
Devise "residual connections".
Use BN in place of dropout.
Residual Connections¶
Hypothesis: Deeper models have more representation power than shallow ones. But they are harder to optimize.
Solution: Use network layers to fit a residual mapping instead of directly trying to fit a desired underlying mapping.
It is necessary to use ReLU as activation function, in order to apply identity mapping when \(F(x)=0\) .
Architecture¶
SENet¶
Using ResNeXt-152 as a base architecture.
Add a “feature recalibration” module. (adjust weights of each channel)
Using the global avg-pooling layer + FC layers to determine feature map weights.
Improvements of ResNet¶
Wide Residual Networks, ResNeXt, DenseNet, MobileNets...
Other Interesting Networks¶
NASNet: Neural Architecture Search with Reinforcement Learning.
EfficientNet: Smart Compound Scaling.
7 - Training Neural Networks¶
Activation Functions¶
| Activation | Usage |
|---|---|
| Sigmoid, tanh | Do not use. |
| ReLU | Use as default. |
| Leaky ReLU, Maxout, ELU, SELU | Replace ReLU to squeeze out some marginal gains. |
| Swish | No clear usage. |
Data Processing¶
Apply centralization and normalization before training.
In practice for pictures, usually we apply channel-wise centralization only.
Weight Initialization¶
Assume that we have 6 layers in a network.
\(D_i\) : input size of layer \(i\)
\(W_i\) : weights in layer \(i\)
\(X_i\) : output after activation of layer \(i\), we have \(X_i=g(Z_i)=g(W_iX_{i-1}+B_i)\)
We initialize each parameter in \(W_i\) randomly in \([-k_i,k_i]\) .
| Tanh Activation | Output Distribution |
|---|---|
| \(k_i=0.01\) | |
| \(k_i=0.05\) | |
| Xavier Initialization \(k_i=\frac{1}{\sqrt{D_i}\\}\) | |
When \(k_i=0.01\), the variance keeps decreasing as the layer gets deeper. As a result, the output of each neuron in deep layer will all be 0. The partial derivative \(\frac{\partial Z_i}{\partial W_i}=X_{i-1}=0\\\). (no gradient)
When \(k_i=0.05\), most neurons is saturated. The partial derivative \(\frac{\partial X_i}{\partial Z_i}=g'(Z_i)=0\\\). (no gradient)
To solve this problem, We need to keep the variance same in each layer.
Assuming that \(Var\big(X_{i-1}^{(1)}\big)=Var\big(X_{i-1}^{(2)}\big)=\dots=Var\big(X_{i-1}^{(D_i)}\big)\)
We have \(Z_i=X_{i-1}^{(1)}W_i^{(:,1)}+X_{i-1}^{(2)}W_i^{(:,2)}+\dots+X_{i-1}^{(D_i)}W_i^{(:,D_i)}=\sum_{n=1}^{D_i}X_{i-1}^{(n)}W_i^{(:,n)}\\\)
We want \(Var\big(Z_i\big)=Var\big(X_{i-1}^{(n)}\big)\)
Let's do some conduction:
\(\begin{aligned}Var\big(Z_i\big)&=Var\Bigg(\sum_{n=1}^{D_i}X_{i-1}^{(n)}W_i^{(:,n)}\Bigg)\\&=D_i\ Var\Big(X_{i-1}^{(n)}W_i^{(:,n)}\Big)\\&=D_i\ Var\Big(X_{i-1}^{(n)}\Big)\ Var\Big(W_i^{(:,n)}\Big)\end{aligned}\)
So \(Var\big(Z_i\big)=Var\big(X_{i-1}^{(n)}\big)\) only when \(Var\Big(W_i^{(:,n)}\Big)=\frac{1}{D_i}\\\), that is to say \(k_i=\frac{1}{\sqrt{D_i}}\\\)
| ReLU Activation | Output Distribution |
|---|---|
| Xavier Initialization \(k_i=\frac{1}{\sqrt{D_i}\\}\) | |
| Kaiming Initialization \(k_i=\sqrt{2D_i}\) | |
For ReLU activation, when using xavier initialization, there still exist "variance decreasing" problem.
We can use kaiming initialization instead to fix this.
Batch Normalization¶
Force the inputs to be "nicely scaled" at each layer.
\(N\) : batch size
\(D\) : feature size
\(x\) : input with shape \(N\times D\)
\(\gamma\) : learnable scale and shift parameter with shape \(D\)
\(\beta\) : learnable scale and shift parameter with shape \(D\)
The procedure of batch normalization:
- Calculate channel-wise mean \(\mu_j=\frac{1}{N}\sum_{i=1}^Nx_{i,j}\\\) . The result \(\mu\) with shape \(D\) .
- Calculate channel-wise variance \(\sigma_j^2=\frac{1}{N}\sum_{i=1}^N(x_{i,j}-\mu_j)^2\\\) . The result \(\sigma^2\) with shape \(D\) .
- Calculate normalized \(\hat{x}_{i,j}=\frac{x_{i,j}-\mu_j}{\sqrt{\sigma_j^2+\epsilon}}\\\) . The result \(\hat{x}\) with shape \(N\times D\) .
- Scale normalized input to get output \(y_{i,j}=\gamma_j\hat{x}_{i,j}+\beta_j\) . The result \(y\) with shape \(N\times D\) .
Why scale: The constraint "zero-mean, unit variance" may be too hard.
Pros:
- Makes deep networks much easier to train!
- Improves gradient flow.
- Allows higher learning rates, faster convergence.
- Networks become more robust to initialization.
- Acts as regularization during training.
- Zero overhead at test-time: can be fused with conv!
Cons:
Behaves differently during training and testing: this is a very common source of bugs!
Transfer Learning¶
Train on a pre-trained model with other datasets.
An empirical suggestion:
| very similar dataset | very different dataset | |
|---|---|---|
| very little data | Use Linear Classifier on top layer. | You’re in trouble… Try linear classifier from different stages. |
| quite a lot of data | Finetune a few layers. | Finetune a larger number of layers. |
Regularization¶
Common Pattern of Regularization¶
Training: Add some kind of randomness. \(y=f(x,z)\)
Testing: Average out randomness (sometimes approximate). \(y=f(x)=E_z\big[f(x,z)\big]=\int p(z)f(x,z)dz\\\)
Regularization Term¶
L2 regularization: \(R(W)=\sum_k\sum_lW_{k,l}^2\) (weight decay)
L1 regularization: \(R(W)=\sum_k\sum_l|W_{k,l}|\)
Elastic net : \(R(W)=\sum_k\sum_l\big(\beta W_{k,l}^2+|W_{k,l}|\big)\) (L1+L2)
Dropout¶
Training: Randomly set some neurons to 0 with a probability \(p\) .
Testing: Each neuron multiplies by dropout probability \(p\) . (scale the output back)
More common: Scale the output with \(\frac{1}{p}\) when training, keep the original output when testing.
Why dropout works:
- Forces the network to have a redundant representation. Prevents co-adaptation of features.
- Another interpretation: Dropout is training a large ensemble of models (that share parameters).
Batch Normalization¶
See above.
Data Augmentation¶
- Horizontal Flips
- Random Crops and Scales
- Color Jitter
- Rotation
- Stretching
- Shearing
- Lens Distortions
- ...
There also exists automatic data augmentation method using neural networks.
Other Methods and Summary¶
DropConnect: Drop connections between neurons.
Fractional Max Pooling: Use randomized pooling regions.
Stochastic Depth: Skip some layers in the network.
Cutout: Set random image regions to zero.
Mixup: Train on random blends of images.
| Regularization Method | Usage |
|---|---|
| Dropout | For large fully-connected layers. |
| Batch Normalization & Data Augmentation | Almost always a good idea. |
| Cutout & Mixup | For small classification datasets. |
Hyperparameter Tuning¶
| Most Common Hyperparameters | Less Sensitive Hyperparameters |
|---|---|
| learning rate learning rate decay schedule weight decay | setting of momentum ... |
Tips on hyperparameter tuning:
- Prefer one validation fold to cross-validation.
- Search for hyperparameters on log scale. (e.g. multiply the hyperparameter by a fixed number \(k\) at each search)
- Prefer random search to grid search.
- Careful with best values on border.
- Stage your search from coarse to fine.
Implementation¶
Have a worker that continuously samples random hyperparameters and performs the optimization. During the training, the worker will keep track of the validation performance after every epoch, and writes a model checkpoint to a file.
Have a master that launches or kills workers across a computing cluster, and may additionally inspect the checkpoints written by workers and plot their training statistics.
Common Procedures¶
- Check initial loss.
Turn off weight decay, sanity check loss at initialization \(\log(C)\) for softmax with \(C\) classes.
- Overfit a small sample. (important)
Try to train to 100% training accuracy on a small sample of training data.
Fiddle with architecture, learning rate, weight initialization.
- Find learning rate that makes loss go down.
Use the architecture from the previous step, use all training data, turn on small weight decay, find a learning rate that makes the loss drop significantly within 100 iterations.
Good learning rates to try: \(0.1,0.01,0.001,0.0001,\dots\)
- Coarse grid, train for 1-5 epochs.
Choose a few values of learning rate and weight decay around what worked from Step 3, train a few models for 1-5 epochs.\
Good weight decay to try: \(0.0001,0.00001,0\)
- Refine grid, train longer.
Pick best models from Step 4, train them for longer (10-20 epochs) without learning rate decay.
- Look at loss and accuracy curves.
- GOTO step 5.
Gradient Checks¶
CS231n Convolutional Neural Networks for Visual Recognition
Compute analytical gradient manually using \(f_a'=\frac{\partial f(x)}{\partial x}=\frac{f(x-h)-f(x+h)}{2h}\\\)
Get relative error between numerical gradient \(f_n'\) and analytical gradient \(f_a'\) using \(E=\frac{|f_n'-f_a'|}{\max{|f_n'|,|f_a'|}}\\\)
| Relative Error | Result |
|---|---|
| \(E>10^{-2}\) | Probably \(f_n'\) is wrong. |
| \(10^{-2}>E>10^{-4}\) | Not good, should check the gradient. |
| \(10^{-4}>E>10^{-6}\) | Okay for objectives with kinks. (e.g. ReLU) Not good for objectives with no kink. (e.g. softmax, tanh) |
| \(10^{-7}>E\) | Good. |
Tips on gradient checks:
- Use double precision.
- Use only few data points.
- Careful about kinks in the objective. (e.g. \(x=0\) for ReLU activation)
- Careful with the step size \(h\).
- Use gradient check after the loss starts to go down.
- Remember to turn off anything that may affect the gradient. (e.g. regularization / dropout / augmentations)
- Check only few dimensions for every parameter. (reduce time cost)
8 - Visualizing and Understanding¶
Feature Visualization and Inversion¶
Visualizing what models have learned¶
| Visualize Areas | |
|---|---|
| Filters | Visualize the raw weights of each convolution kernel. (better in the first layer) |
| Final Layer Features | Run dimensionality reduction for features in the last FC layer. (PCA, t-SNE...) |
| Activations | Visualize activated areas. (Understanding Neural Networks Through Deep Visualization) |
Understanding input pixels¶
Maximally Activating Patches¶
- Pick a layer and a channel.
- Run many images through the network, record values of the chosen channel.
- Visualize image patches that correspond to maximal activation features.
For example, we have a layer with shape \(128\times13\times13\). We pick the 17th channel from all 128 channels. Then we run many pictures through the network. During each run we can find a maximal activation feature among all the \(13\times13\) features in channel 17. We then record the corresponding picture patch for each maximal activation feature. At last, we visualize all picture patches for each feature.
This will help us find the relationship between each maximal activation feature and its corresponding picture patches.
(each row of the following picture represents a feature)
Saliency via Occlusion¶
Mask part of the image before feeding to CNN, check how much predicted probabilities change.
Saliency via Backprop¶
- Compute gradient of (unnormalized) class score with respect to image pixels.
- Take absolute value and max over RGB channels to get saliency maps.
Intermediate Features via Guided Backprop¶
- Pick a single intermediate neuron. (e.g. one feature in a \(128\times13\times13\) feature map)
- Compute gradient of neuron value with respect to image pixels.
Striving for Simplicity: The All Convolutional Net
Just like "Maximally Activating Patches", this could find the part of an image that a neuron responds to.
Gradient Ascent¶
Generate a synthetic image that maximally activates a neuron.
- Initialize image \(I\) to zeros.
- Forward image to compute current scores \(S_c(I)\) (for class \(c\) before softmax).
- Backprop to get gradient of neuron value with respect to image pixels.
- Make a small update to the image.
Objective: \(\max S_c(I)-\lambda\lVert I\lVert^2\)
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps
Adversarial Examples¶
Find an fooling image that can make the network misclassify correctly-classified images when it is added to the image.
- Start from an arbitrary image.
- Pick an arbitrary class.
- Modify the image to maximize the class.
- Repeat until network is fooled.
DeepDream and Style Transfer¶
Feature Inversion¶
Given a CNN feature vector \(\Phi_0\) for an image, find a new image \(x\) that:
- Features of new image \(\Phi(x)\) matches the given feature vector \(\Phi_0\).
- "looks natural”. (image prior regularization)
Objective: \(\min \lVert\Phi(x)-\Phi_0\lVert+\lambda R(x)\)
Understanding Deep Image Representations by Inverting Them
DeepDream: Amplify Existing Features¶
Given an image, amplify the neuron activations at a layer to generate a new one.
- Forward: compute activations at chosen layer.
- Set gradient of chosen layer equal to its activation.
- Backward: Compute gradient on image.
- Update image.
Texture Synthesis¶
Nearest Neighbor¶
- Generate pixels one at a time in scanline order
- Form neighborhood of already generated pixels, copy the nearest neighbor from input.
Neural Texture Synthesis¶
Gram Matrix: 格拉姆矩阵(Gram matrix)详细解读
- Pretrain a CNN on ImageNet.
- Run input texture forward through CNN, record activations on every layer.
Layer \(i\) gives feature map of shape \(C_i\times H_i\times W_i\).
- At each layer compute the Gram matrix \(G_i\) giving outer product of features.
- Reshape feature map at layer \(i\) to \(C_i\times H_iW_i\).
- Compute the Gram matrix \(G_i\) with shape \(C_i\times C_i\).
- Initialize generated image from random noise.
- Pass generated image through CNN, compute Gram matrix \(\hat{G}_l\) on each layer.
- Compute loss: Weighted sum of L2 distance between Gram matrices.
- \(E_l=\frac{1}{aN_l^2M_l^2}\sum_{i,j}\Big(G_i^{(i,j)}-\hat{G}_i^{(i,j)}\Big)^2\\\)
- \(\mathcal{L}(\vec{x},\hat{\vec{x}})=\sum_{l=0}^L\omega_lE_l\\\)
- Backprop to get gradient on image.
- Make gradient step on image.
- GOTO 5.
Texture Synthesis Using Convolutional Neural Networks
Style Transfer¶
Feature + Gram Reconstruction¶
![]()
![]()
Problem: Style transfer requires many forward / backward passes. Very slow!
Fast Style Transfer¶
![]()
![]()
9 - Object Detection and Image Segmentation¶
Semantic Segmentation¶
Paired Training Data: For each training image, each pixel is labeled with a semantic category.
Fully Convolutional Network: Design a network with only convolutional layers without downsampling operators to make predictions for pixels all at once!
Problem: Convolutions at original image resolution will be very expensive...
Solution: Design fully convolutional network with downsampling and upsampling inside it!
- Downsampling: Pooling, strided convolution.
- Upsampling: Unpooling, transposed convolution.
Unpooling:
| Nearest Neighbor | "Bed of Nails" | "Position Memory" |
|---|---|---|
| | |
Transposed Convolution: (example size \(3\times3\), stride \(2\), pad \(1\))
| Normal Convolution | Transposed Convolution |
|---|---|
Object Detection¶
Single Object¶
Classification + Localization. (classification + regression problem)
Multiple Object¶
R-CNN¶
Using selective search to find “blobby” image regions that are likely to contain objects.
- Find regions of interest (RoI) using selective search. (region proposal)
- Forward each region through ConvNet.
- Classify features with SVMs.
Problem: Very slow. Need to do 2000 independent forward passes for each image!
Fast R-CNN¶
Pass the image through ConvNet before cropping. Crop the conv feature instead.
- Run whole image through ConvNet.
- Find regions of interest (RoI) from conv features using selective search. (region proposal)
- Classify RoIs using CNN.
Problem: Runtime is dominated by region proposals. (about \(90\%\) time cost)
Faster R-CNN¶
Insert Region Proposal Network (RPN) to predict proposals from features.
Otherwise same as Fast R-CNN: Crop features for each proposal, classify each one.
Region Proposal Network (RPN) : Slide many fixed windows over ConvNet features.
- Treat each point in the feature map as the anchor.
We have \(k\) fixed windows (anchor boxes) of different size/scale centered with each anchor.
- For each anchor box, predict whether it contains an object.
For positive boxes, also predict a corrections to the ground-truth box.
- Slide anchor over the feature map, get the “objectness” score for each box at each point.
- Sort the “objectness” score, take top \(300\) as the proposals.
Faster R-CNN is a Two-stage object detector:
- First stage: Run once per image
Backbone network
Region proposal network
- Second stage: Run once per region
Crop features: RoI pool / align
Predict object class
Prediction bbox offset
Single-Stage Object Detectors: YOLO¶
You Only Look Once: Unified, Real-Time Object Detection
- Divide image into grids. (example image grids shape \(7\times7\))
- Set anchors in the middle of each grid.
- For each grid: - Using \(B\) anchor boxes to regress \(5\) numbers: \(\text{dx, dy, dh, dw, confidence}\). - Predict scores for each of \(C\) classes.
- Finally the output is \(7\times7\times(5B+C)\).
Instance Segmentation¶
Mask R-CNN: Add a small mask network that operates on each RoI and predicts a \(28\times28\) binary mask.
Mask R-CNN performs very good results!
10 - Recurrent Neural Networks¶
Supplement content added according to Deep Learning Book - RNN.
Recurrent Neural Network (RNN)¶
Motivation: Sequence Processing¶
| One to One | One to Many | Many to One | Many to Many | Many to Many |
|---|---|---|---|---|
| | | | |
| Vanilla Neural Networks | Image Captioning | Action Prediction | Video Captioning | Video Classification on Frame Level |
Vanilla RNN¶
\(x^{(t)}\) : Input at time \(t\).
\(h^{(t)}\) : State at time \(t\).
\(o^{(t)}\) : Output at time \(t\).
\(y^{(t)}\) : Expected output at time \(t\).
Many to One¶
| Calculation | |
|---|---|
| State Transition | \(h^{(t)}=\tanh(Wh^{(t-1)}+Ux^{(t)}+b)\) |
| Output Calculation | \(o^{(\tau)}=\text{sigmoid}\ \big(Vh^{(\tau)}+c\big)\) |
Many to Many (type 2)¶
| Calculation | |
|---|---|
| State Transition | \(h^{(t)}=\tanh(Wh^{(t-1)}+Ux^{(t)}+b)\) |
| Output Calculation | \(o^{(t)}=\text{sigmoid}\ \big(Vh^{(t)}+c\big)\) |
RNN with Teacher Forcing¶
Update current state according to last-time output instead of last-time state.
| Calculation | |
|---|---|
| State Transition | \(h^{(t)}=\tanh(Wo^{(t-1)}+Ux^{(t)}+b)\) |
| Output Calculation | \(o^{(t)}=\text{sigmoid}\ \big(Vh^{(t)}+c\big)\) |
RNN with "Output Forwarding"¶
We can also combine last-state output with this-state input together.
| Calculation | |
|---|---|
| State Transition (training) | \(h^{(t)}=\tanh(Wh^{(t-1)}+Ux^{(t)}+Ry^{(t-1)}+b)\) |
| State Transition (testing) | \(h^{(t)}=\tanh(Wh^{(t-1)}+Ux^{(t)}+Ro^{(t-1)}+b)\) |
| Output Calculation | \(o^{(t)}=\text{sigmoid}\ \big(Vh^{(t)}+c\big)\) |
Usually we use \(o^{(t-1)}\) in place of \(y^{(t-1)}\) at testing time.
Bidirectional RNN¶
When dealing with a whole input sequence, we can process features from two directions.
| Calculation | |
|---|---|
| State Transition (forward) | \(h^{(t)}=\tanh(W_1h^{(t-1)}+U_1x^{(t)}+b_1)\) |
| State Transition (backward) | \(g^{(t)}=\tanh(W_2g^{(t+1)}+U_2x^{(t)}+b_2)\) |
| Output Calculation | \(o^{(t)}=\text{sigmoid}\ \big(Vh^{(t)}+Wg^{(t)}+c\big)\) |
Encoder-Decoder Sequence to Sequence RNN¶
This is a many-to-many structure (type 1).
First we encode information according to \(x\) with no output.
Later we decode information according to \(y\) with no input.
\(C\) : Context vector, often \(C=h^{(T)}\) (last state of encoder).
| Calculation | |
|---|---|
| State Transition (encode) | \(h^{(t)}=\tanh(W_1h^{(t-1)}+U_1x^{(t)}+b_1)\) |
| State Transition (decode, training) | \(s^{(t)}=\tanh(W_2s^{(t-1)}+U_2y^{(t)}+TC+b_2)\) |
| State Transition (decode, testing) | \(s^{(t)}=\tanh(W_2s^{(t-1)}+U_2o^{(t)}+TC+b_2)\) |
| Output Calculation | \(o^{(t)}=\text{sigmoid}\ \big(Vs^{(t)}+c\big)\) |
Example: Image Captioning¶
Summary¶
Advantages of RNN:
- Can process any length input.
- Computation for step \(t\) can (in theory) use information from many steps back.
- Model size doesn’t increase for longer input.
- Same weights applied on every timestep, so there is symmetry in how inputs are processed.
Disadvantages of RNN:
- Recurrent computation is slow.
- In practice, difficult to access information from many steps back.
- Problems with gradient exploding and gradient vanishing. (check Deep Learning Book - RNN Page 396, Chap 10.7)
Long Short Term Memory (LSTM)¶
Add a "cell block" to store history weights.
\(c^{(t)}\) : Cell at time \(t\).
\(f^{(t)}\) : Forget gate at time \(t\). Deciding whether to erase the cell.
\(i^{(t)}\) : Input gate at time \(t\). Deciding whether to write to the cell.
\(g^{(t)}\) : External input gate at time \(t\). Deciding how much to write to the cell.
\(o^{(t)}\) : Output gate at time \(t\). Deciding how much to reveal the cell.
| Calculation (Gate) | |
|---|---|
| Forget Gate | \(f^{(t)}=\text{sigmoid}\ \big(W_fh^{(t-1)}+U_fx^{(t)}+b_f\big)\) |
| Input Gate | \(i^{(t)}=\text{sigmoid}\ \big(W_ih^{(t-1)}+U_ix^{(t)}+b_i\big)\) |
| External Input Gate | \(g^{(t)}=\tanh(W_gh^{(t-1)}+U_gx^{(t)}+b_g)\) |
| Output Gate | \(o^{(t)}=\text{sigmoid}\ \big(W_oh^{(t-1)}+U_ox^{(t)}+b_o\big)\) |
| Calculation (Main) | |
|---|---|
| Cell Transition | \(c^{(t)}=f^{(t)}\odot c^{(t-1)}+i^{(t)}\odot g^{(t)}\) |
| State Transition | \(h^{(t)}=o^{(t)}\odot\tanh(c^{(t)})\) |
| Output Calculation | \(O^{(t)}=\text{sigmoid}\ \big(Vh^{(t)}+c\big)\) |
Other RNN Variants¶
GRU...
11 - Attention and Transformers¶
RNN with Attention¶
Encoder-Decoder Sequence to Sequence RNN Problem:
Input sequence bottlenecked through a fixed-sized context vector \(C\). (e.g. \(T=1000\))
Intuitive Solution:
Generate new context vector \(C_t\) at each step \(t\) !
\(e_{t,i}\) : Alignment score for input \(i\) at state \(t\). (scalar)
\(a_{t,i}\) : Attention weight for input \(i\) at state \(t\).
\(C_t\) : Context vector at state \(t\).
| Calculation | |
|---|---|
| Alignment Score | \(e_i^{(t)}=f(s^{(t-1)},h^{(i)})\). Where \(f\) is an MLP. |
| Attention Weight | \(a_i^{(t)}=\text{softmax}\ (e_i^{(t)})\). Softmax includes all \(e_i\) at state \(t\). |
| Context Vector | \(C^{(t)}=\sum_i a_i^{(t)}h^{(i)}\) |
| Decoder State Transition | \(s^{(t)}=\tanh(Ws^{(t-1)}+Uy^{(t)}+TC^{(t)}+b)\) |
Example on Image Captioning:
General Attention Layer¶
Add linear transformations to the input vector before attention.
Notice:
- Number of queries \(q\) is variant. (can be different from the number of keys \(k\))
- Number of outputs \(y\) is equal to the number of queries \(q\).
Each \(y\) is a linear weighting of values \(v\).
- Alignment \(e\) is divided by \(\sqrt{D}\) to avoid "explosion of softmax", where \(D\) is the dimension of input feature.
Self-attention Layer¶
The query vectors \(q\) are also generated from the inputs.
In this way, the shape of \(y\) is equal to the shape of \(x\).
Example with CNN:
Positional Encoding¶
Self-attention layer doesn’t care about the orders of the inputs!
To encode ordered sequences like language or spatially ordered image features, we can add positional encoding to the inputs.
We use a function \(P:R\rightarrow R^d\) to process the position \(i\) into a d-dimensional vector \(p_i=P(i)\).
| Constraint Condition of \(P\) | |
|---|---|
| Uniqueness | \(P(i)\ne P(j)\) |
| Equidistance | \(\lVert P(i+k)-P(i)\rVert^2=\lVert P(j+k)-P(j)\rVert^2\) |
| Boundness | \(P(i)\in[a,b]\) |
| Determinacy | \(P(i)\) is always a static value. (function is not dynamic) |
We can either train a encoder model, or design a fixed function.
A Practical Positional Encoding Method: Using \(\sin\) and \(\cos\) with different frequency \(\omega\) at different dimension.
\(P(t)=\begin{bmatrix}\sin(\omega_1,t)\\\cos(\omega_1,t)\\\\\sin(\omega_2,t)\\\cos(\omega_2,t)\\\vdots\\\sin(\omega_{\frac{d}{2}},t)\\\cos(\omega_{\frac{d}{2}},t)\end{bmatrix}\), where frequency \(\omega_k=\frac{1}{10000^{\frac{2k}{d}}}\\\). (wave length \(\lambda=\frac{1}{\omega}=10000^{\frac{2k}{d}}\\\))
\(P(t)=\begin{bmatrix}\sin(1/10000^{\frac{2}{d}},t)\\\cos(1/10000^{\frac{2}{d}},t)\\\\\sin(1/10000^{\frac{4}{d}},t)\\\cos(1/10000^{\frac{4}{d}},t)\\\vdots\\\sin(1/10000^1,t)\\\cos(1/10000^1,t)\end{bmatrix}\), after we substitute \(\omega_k\) into the equation.
\(P(t)\) is a vector with size \(d\), where \(d\) is a hyperparameter to choose according to the length of input sequence.
An intuition of this method is the binary encoding of numbers.
[lecture 11d] 注意力和 transformer (positional encoding 补充,代码实现,距离计算 )
It is easy to prove that \(P(t)\) satisfies "Equidistance": (set \(d=2\) for example)
\(\begin{aligned}\lVert P(i+k)-P(i)\rVert^2&=\big[\sin(\omega_1,i+k)-\sin(\omega_1,i)\big]^2+\big[\cos(\omega_1,i+k)-\cos(\omega_1,i)\big]^2\\&=2-2\sin(\omega_1,i+k)\sin(\omega_1,i)-2\cos(\omega_1,i+k)\cos(\omega_1,i)\\&=2-2\cos(\omega_1,k)\end{aligned}\)
So the distance is not associated with \(i\), we have \(\lVert P(i+k)-P(i)\rVert^2=\lVert P(j+k)-P(j)\rVert^2\).
Visualization of \(P(t)\) features: (set \(d=32\), \(x\) axis represents the position of sequence)
Masked Self-attention Layer¶
To prevent vectors from looking at future vectors, we manually set alignment scores to \(-\infty\).
Multi-head Self-attention Layer¶
Multiple self-attention heads in parallel.
Transformer¶
Encoder Block¶
Inputs: Set of vectors \(z\). (in which \(z_i\) can be a word in a sentence, or a pixel in a picture...)
Output: Set of context vectors \(c\). (encoded features of \(z\))
![]()
The number of blocks \(N=6\) in original paper.
Notice:
- Self-attention is the only interaction between vectors \(x_0,x_1,\dots,x_n\).
- Layer norm and MLP operate independently per vector.
- Highly scalable, highly parallelizable, but high memory usage.
Decoder Block¶
Inputs: Set of vectors \(y\). (\(y_i\) can be a word in a sentence, or a pixel in a picture...)
Inputs: Set of context vectors \(c\).
Output: Set of vectors \(y'\). (decoded result, \(y'_i=y_{i+1}\) for the first \(n-1\) number of \(y'\))
![]()
The number of blocks \(N=6\) in original paper.
Notice:
- Masked self-attention only interacts with past inputs.
- Multi-head attention block is NOT self-attention. It attends over encoder outputs.
- Highly scalable, highly parallelizable, but high memory usage. (same as encoder)
Why we need mask in decoder:
- Needs for the special formation of output \(y'_i=y_{i+1}\).
- Needs for parallel computation.
在测试或者预测时,Transformer 里 decoder 为什么还需要 seq mask?
Example on Image Captioning (Only with Transformers)¶
![]()
Comparing RNNs to Transformer¶
| RNNs | Transformer | |
|---|---|---|
| Pros | LSTMs work reasonably well for long sequences. | 1. Good at long sequences. Each attention calculation looks at all inputs. 2. Can operate over unordered sets or ordered sequences with positional encodings. 3. Parallel computation: All alignment and attention scores for all inputs can be done in parallel. |
| Cons | 1. Expects an ordered sequences of inputs. 2. Sequential computation: Subsequent hidden states can only be computed after the previous ones are done. | Requires a lot of memory: \(N\times M\) alignment and attention scalers need to be calculated and stored for a single self-attention head. |
Comparing ConvNets to Transformer¶
ConvNets strike back!
![]()
12 - Video Understanding¶
Video Classification¶
Take video classification task for example.
Input size: \(C\times T\times H\times W\).
The problem is, videos are quite big. We can't afford to train on raw videos, instead we train on video clips.
| Raw Videos | Video Clips |
|---|---|
| \(1920\times1080,\ 30\text{fps}\) | \(112\times112,\ 5\text{f}/3.2\text{s}\) |
| \(10\text{GB}/\text{min}\) | \(588\text{KB}/\text{min}\) |
Plain CNN Structure¶
Single Frame 2D-CNN¶
Train a normal 2D-CNN model.
Classify each frame independently.
Average the result of each frame as the final result.
Late Fusion¶
Get high-level appearance of each frame, and combine them.
Run 2D-CNN on each frame, pool features and feed to Linear Layers.
Problem: Hard to compare low-level motion between frames.
Early Fusion¶
Compare frames with very first Conv Layer, after that normal 2D-CNN.
Problem: One layer of temporal processing may not be enough!
3D-CNN¶
Convolve on 3 dimensions: Height, Width, Time.
Input size: \(C_{in}\times T\times H\times W\).
Kernel size: \(C_{in}\times C_{out}\times 3\times 3\times 3\).
Output size: \(C_{out}\times T\times H\times W\). (with zero paddling)
C3D (VGG of 3D-CNNs)¶
The cost is quite expensive...
| Network | Calculation |
|---|---|
| AlexNet | 0.7 GFLOP |
| VGG-16 | 13.6 GFLOP |
| C3D | 39.5 GFLOP |
Two-Stream Networks¶
Separate motion and appearance.
I3D (Inflating 2D Networks to 3D)¶
Take a 2D-CNN architecture.
Replace each 2D conv/pool layer with a 3D version.
Modeling Long-term Temporal Structure¶
Recurrent Convolutional Network¶
Similar to multi-layer RNN, we replace the dot-product operation with convolution.
Feature size in layer \(L\), time \(t-1\): \(W_h\times H\times W\).
Feature size in layer \(L-1\), time \(t\): \(W_x\times H\times W\).
Feature size in layer \(L\), time \(t\): \((W_h+W_x)\times H\times W\).
Problem: RNNs are slow for long sequences. (can’t be parallelized)
Spatio-temporal Self-attention¶
Introduce self-attention into video classification problems.
Vision Transformers for Video¶
Factorized attention: Attend over space / time.
So many papers...
![]()
Visualizing Video Models¶
Multimodal Video Understanding¶
Temporal Action Localization¶
Given a long untrimmed video sequence, identify frames corresponding to different actions.
Spatio-Temporal Detection¶
Given a long untrimmed video, detect all the people in both space and time and classify the activities they are performing.
Visually-guided Audio Source Separation¶
And So on...
13 - Generative Models¶
PixelRNN and PixelCNN¶
Fully Visible Belief Network (FVBN)¶
\(p(x)\) : Likelihood of image \(x\).
\(p(x_1,x_2,\dots,x_n)\) : Joint likelihood of all \(n\) pixels in image \(x\).
\(p(x_i|x_1,x_2,\dots,x_{i-1})\) : Probability of pixel \(i\) value given all previous pixels.
For explicit density models, we have \(p(x)=p(x_1,x_2,\dots,x_n)=\prod_{i=1}^np(x_i|x_1,x_2,\dots,x_{i-1})\\\).
Objective: Maximize the likelihood of training data.
PixelRNN¶
Generate image pixels starting from corner.
Dependency on previous pixels modeled using an RNN (LSTM).
Drawback: Sequential generation is slow in both training and inference!
![]()
PixelCNN¶
Still generate image pixels starting from corner.
Dependency on previous pixels modeled using a CNN over context region (masked convolution).
Drawback: Though its training is faster, its generation is still slow. (pixel by pixel)
![]()
Variational Autoencoder¶
Supplement content added according to Tutorial on Variational Autoencoders. (paper with notes: VAE Tutorial.pdf)
Autoencoder¶
Learn a lower-dimensional feature representation with unsupervised approaches.
\(x\rightarrow z\) : Dimension reduction for input features.
\(z\rightarrow \hat{x}\) : Reconstruct input features.
After training, we throw the decoder away and use the encoder for transferring.
![]()
For generative models, there is a problem:
We can’t generate new images from an autoencoder because we don’t know the space of \(z\).
Variational Autoencoder¶
Character Description¶
\(X\) : Images. (random variable)
\(Z\) : Latent representations. (random variable)
\(P(X)\) : True distribution of all training images \(X\).
\(P(Z)\) : True distribution of all latent representations \(Z\).
\(P(X|Z)\) : True posterior distribution of all images \(X\) with condition \(Z\).
\(P(Z|X)\) : True prior distribution of all latent representations \(Z\) with condition \(X\).
\(Q(Z|X)\) : Approximated prior distribution of all latent representations \(Z\) with condition \(X\).
\(x\) : A specific image.
\(z\) : A specific latent representation.
\(\theta\): Learned parameters in decoder network.
\(\phi\): Learned parameters in encoder network.
\(p_\theta(x)\) : Probability that \(x\sim P(X)\).
\(p_\theta(z)\) : Probability that \(z\sim P(Z)\).
\(p_\theta(x|z)\) : Probability that \(x\sim P(X|Z)\).
\(p_\theta(z|x)\) : Probability that \(z\sim P(Z|X)\).
\(q_\phi(z|x)\) : Probability that \(z\sim Q(Z|X)\).
Decoder¶
Objective:
Generate new images from \(\mathscr{z}\).
- Generate a value \(z^{(i)}\) from the prior distribution \(P(Z)\).
- Generate a value \(x^{(i)}\) from the conditional distribution \(P(X|Z)\).
Lemma:
Any distribution in \(d\) dimensions can be generated by taking a set of \(d\) variables that are normally distributed and mapping them through a sufficiently complicated function. (source: Tutorial on Variational Autoencoders, Page 6)
Solutions:
- Choose prior distribution \(P(Z)\) to be a simple distribution, for example \(P(Z)\sim N(0,1)\).
- Learn the conditional distribution \(P(X|Z)\) through a neural network (decoder) with parameter \(\theta\).
Encoder¶
Objective:
Learn \(\mathscr{z}\) with training images.
Given: (From the decoder, we can deduce the following probabilities.)
- data likelihood: \(p_\theta(x)=\int p_\theta(x|z)p_\theta(z)dz\).
- posterior density: \(p_\theta(z|x)=\frac{p_\theta(x|z)p_\theta(z)}{p_\theta(x)}=\frac{p_\theta(x|z)p_\theta(z)}{\int p_\theta(x|z)p_\theta(z)dz}\).
Problem:
Both \(p_\theta(x)\) and \(p_\theta(z|x)\) are intractable. (can't be optimized directly as they contain integral operation)
Solution:
Learn \(Q(Z|X)\) to approximate the true posterior \(P(Z|X)\).
Use \(q_\phi(z|x)\) in place of \(p_\theta(z|x)\).
Variational Autoencoder (Combination of Encoder and Decoder)¶
Objective:
Maximize \(p_\theta(x)\) for all \(x^{(i)}\) in the training set.
$$ \begin{aligned} \log p_\theta\big(x^{(i)}\big)&=\mathbb{E}{z\sim q\phi\big(z|x^{(i)}\big)}\Big[\log p_\theta\big(x^{(i)}\big)\Big]\
&=\mathbb{E}z\Bigg[\log\frac{p\theta\big(x^{(i)}|z\big)p_\theta\big(z\big)}{p_\theta\big(z|x^{(i)}\big)}\Bigg]\quad\text{(Bayes' Rule)}\
&=\mathbb{E}z\Bigg[\log\frac{p\theta\big(x^{(i)}|z\big)p_\theta\big(z\big)}{p_\theta\big(z|x^{(i)}\big)}\frac{q_\phi\big(z|x^{(i)}\big)}{q_\phi\big(z|x^{(i)}\big)}\Bigg]\quad\text{(Multiply by Constant)}\
&=\mathbb{E}z\Big[\log p\theta\big(x^{(i)}|z\big)\Big]-\mathbb{E}z\Bigg[\log\frac{q\phi\big(z|x^{(i)}\big)}{p_\theta\big(z\big)}\Bigg]+\mathbb{E}z\Bigg[\log\frac{p\theta\big(z|x^{(i)}\big)}{q_\phi\big(z|x^{(i)}\big)}\Bigg]\quad\text{(Logarithm)}\
&=\mathbb{E}z\Big[\log p\theta\big(x^{(i)}|z\big)\Big]-D_{\text{KL}}\Big[q_\phi\big(z|x^{(i)}\big)||p_\theta\big(z\big)\Big]+D_{\text{KL}}\Big[p_\theta\big(z|x^{(i)}\big)||q_\phi\big(z|x^{(i)}\big)\Big]\quad\text{(KL Divergence)} \end{aligned} $$
Analyze the Formula by Term:
\(\mathbb{E}_z\Big[\log p_\theta\big(x^{(i)}|z\big)\Big]\): Decoder network gives \(p_\theta\big(x^{(i)}|z\big)\), can compute estimate of this term through sampling.
\(D_{\text{KL}}\Big[q_\phi\big(z|x^{(i)}\big)||p_\theta\big(z\big)\Big]\): This KL term (between Gaussians for encoder and \(z\) prior) has nice closed-form solution!
\(D_{\text{KL}}\Big[p_\theta\big(z|x^{(i)}\big)||q_\phi\big(z|x^{(i)}\big)\Big]\): The part \(p_\theta\big(z|x^{(i)}\big)\) is intractable. However, we know KL divergence always \(\ge0\).
Tractable Lower Bound:
We can maximize the lower bound of that formula.
As \(D_{\text{KL}}\Big[p_\theta\big(z|x^{(i)}\big)||q_\phi\big(z|x^{(i)}\big)\Big]\ge0\) , we can deduce that:
$$ \begin{aligned} \log p_\theta\big(x^{(i)}\big)&=\mathbb{E}z\Big[\log p\theta\big(x^{(i)}|z\big)\Big]-D_{\text{KL}}\Big[q_\phi\big(z|x^{(i)}\big)||p_\theta\big(z\big)\Big]+D_{\text{KL}}\Big[p_\theta\big(z|x^{(i)}\big)||q_\phi\big(z|x^{(i)}\big)\Big]\
&\ge\mathbb{E}z\Big[\log p\theta\big(x^{(i)}|z\big)\Big]-D_{\text{KL}}\Big[q_\phi\big(z|x^{(i)}\big)||p_\theta\big(z\big)\Big] \end{aligned} $$
So the loss function \(\mathcal{L}\big(x^{(i)},\theta,\phi\big)=-\mathbb{E}_z\Big[\log p_\theta\big(x^{(i)}|z\big)\Big]+D_{\text{KL}}\Big[q_\phi\big(z|x^{(i)}\big)||p_\theta\big(z\big)\Big]\).
\(\mathbb{E}_z\Big[\log p_\theta\big(x^{(i)}|z\big)\Big]\): Decoder, reconstruct the input data.
\(D_{\text{KL}}\Big[q_\phi\big(z|x^{(i)}\big)||p_\theta\big(z\big)\Big]\): Encoder, make approximate posterior distribution close to prior.
Generative Adversarial Networks (GANs)¶
Motivation & Modeling¶
Objective: Not modeling any explicit density function.
Problem: Want to sample from complex, high-dimensional training distribution. No direct way to do this!
Solution: Sample from a simple distribution, e.g. random noise. Learn the transformation to training distribution.
Problem: We can't learn the mapping relation between sample \(z\) and training images.
Solution: Use a discriminator network to tell whether the generate image is within data distribution or not.
Discriminator network: Try to distinguish between real and fake images.
Generator network: Try to fool the discriminator by generating real-looking images.
\(x\) : Real data.
\(y\) : Fake data, which is generated by the generator network. \(y=G_{\theta_g}(z)\).
\(D_{\theta_d}(x)\) : Discriminator score, which is the likelihood of real image. \(D_{\theta_d}(x)\in[0,1]\).
Objective of discriminator network:
\(\max_{\theta_d}\bigg[\mathbb{E}_x\Big(\log D_{\theta_d}(x)\Big)+\mathbb{E}_{z\sim p(z)}\Big(\log\big(1-D_{\theta_d}(y)\big)\Big)\bigg]\)
Objective of generator network:
\(\min_{\theta_g}\max_{\theta_d}\bigg[\mathbb{E}_x\Big(\log D_{\theta_d}(x)\Big)+\mathbb{E}_{z\sim p(z)}\Big(\log\big(1-D_{\theta_d}(y)\big)\Big)\bigg]\)
Training Strategy¶
Two combine this two networks together, we can train them alternately:
- Gradient ascent on discriminator.
\(\max_{\theta_d}\bigg[\mathbb{E}_x\Big(\log D_{\theta_d}(x)\Big)+\mathbb{E}_{z\sim p(z)}\Big(\log\big(1-D_{\theta_d}(y)\big)\Big)\bigg]\)
- Gradient descent on generator.
\(\min_{\theta_g}\bigg[\mathbb{E}_{z\sim p(z)}\Big(\log\big(1-D_{\theta_d}(y)\big)\Big)\bigg]\)
However, the gradient of generator decreases with the value itself, making it hard to optimize.
So we replace \(\log\big(1-D_{\theta_d}(y)\big)\) with \(-\log D_{\theta_d}(y)\), and use gradient ascent instead.
- Gradient ascent on discriminator.
\(\max_{\theta_d}\bigg[\mathbb{E}_x\Big(\log D_{\theta_d}(x)\Big)+\mathbb{E}_{z\sim p(z)}\Big(\log\big(1-D_{\theta_d}(y)\big)\Big)\bigg]\)
- Gradient ascent on generator.
\(\max_{\theta_g}\bigg[\mathbb{E}_{z\sim p(z)}\Big(\log D_{\theta_d}(y)\Big)\bigg]\)
Summary¶
Pros: Beautiful, state-of-the-art samples!
Cons:
- Trickier / more unstable to train.
- Can’t solve inference queries such as \(p(x), p(z|x)\).
14 - Self-supervised Learning¶
Aim: Solve “pretext” tasks that produce good features for downstream tasks.
Application:
- Learn a feature extractor from pretext tasks. (self-supervised)
- Attach a shallow network on the feature extractor.
- Train the shallow network on target task with small amount of labeled data. (supervised)
Pretext Tasks¶
Labels are generated automatically.
Rotation¶
Train a classifier on randomly rotated images.
Rearrangement¶
Train a classifier on randomly shuffled image pieces.
Predict the location of image pieces.
Inpainting¶
Mask part of the image, train a network to predict the masked area.
Method referencing Context Encoders: Feature Learning by Inpainting.
Combine two types of loss together to get better performance:
- Reconstruction loss (L2 loss): Used for reconstructing global features.
- Adversarial loss: Used for generating texture features.
Coloring¶
Transfer between greyscale images and colored images.
Cross-channel predictions for images: Split-Brain Autoencoders.
Video coloring: Establish mappings between reference and target frames in a learned feature space. Tracking Emerges by Colorizing Videos.
Summary for Pretext Tasks¶
- Pretext tasks focus on “visual common sense”.
- The models are forced learn good features about natural images.
- We don’t care about the performance of these pretext tasks.
What we care is the performance of downstream tasks.
Problems of Specific Pretext Tasks¶
- Coming up with individual pretext tasks is tedious.
- The learned representations may not be general.
Intuitive Solution: Contrastive Learning.
Contrastive Representation Learning¶
Local additional references: Contrastive Learning.md.
Objective:
Given a chosen score function \(s\), we aim to learn an encoder function \(f\) that yields:
- For each sample \(x\), increase the similarity \(s\big(f(x),f(x^+)\big)\) between \(x\) and positive samples \(x^+\).
- Finally we want \(s\big(f(x),f(x^+)\big)\gg s\big(f(x),f(x^-)\big)\).
Loss Function:
Given \(1\) positive sample and \(N-1\) negative samples:
| InfoNCE Loss | Cross Entropy Loss |
|---|---|
| \(\begin{aligned}\mathcal{L}=-\mathbb{E}_X\Bigg[\log\frac{\exp{s\big(f(x),f(x^+)\big)}}{\exp{s\big(f(x),f(x^+)\big)}+\sum_{j=1}^{N-1}\exp{s\big(f(x),f(x^+)\big)}}\Bigg]\\\end{aligned}\) | \(\begin{aligned}\mathcal{L}&=-\sum_{i=1}^Np(x_i)\log q(x_i)\\&=-\mathbb{E}_X\big[\log q(x)\big]\\&=-\mathbb{E}_X\Bigg[\log\frac{\exp(x)}{\sum_{j=1}^N\exp(x_j)}\Bigg]\end{aligned}\) |
The InfoNCE Loss is a lower bound on the mutual information between \(f(x)\) and \(f(x^+)\):
\(\text{MI}\big[f(x),f(x^+)\big]\ge\log(N)-\mathcal{L}\)
The larger the negative sample size \(N\), the tighter the bound.
So we use \(N-1\) negative samples.
Instance Contrastive Learning¶
SimCLR¶
Use a projection function \(g(\cdot)\) to project features to a space where contrastive learning is applied.
The extra projection contributes a lot to the final performance.
Score Function: Cos similarity \(s(u,v)=\frac{u^Tv}{||u||||v||}\\\).
Positive Pair: Pair of augmented data.
Momentum Contrastive Learning (MoCo)¶
There are mainly \(3\) training strategy in contrastive learning:
- end-to-end: Keys are updated together with queries, e.g. SimCLR.
(limited by GPU size)
- memory bank: Store last-time keys for sampling.
(inconsistency between \(q\) and \(k\))
- MoCo: Use momentum methods to encode keys.
(combination of end-to-end & memory bank)
Key differences to SimCLR:
- Keep a running queue of keys (negative samples).
- Compute gradients and update the encoder only through the queries.
- Decouple min-batch size with the number of keys: can support a large number of negative samples.
- The key encoder is slowly progressing through the momentum update rules:
\(\theta_k\leftarrow m\theta_k+(1-m)\theta_q\)
Sequence Contrastive Learning¶
Contrastive Predictive Coding (CPC)¶
Contrastive: Contrast between “right” and “wrong” sequences using contrastive learning.
Predictive: The model has to predict future patterns given the current context.
Coding: The model learns useful feature vectors, or “code”, for downstream tasks, similar to other self-supervised methods.
Other Examples (Frontier)¶
Contrastive Language Image Pre-training (CLIP)¶
Contrastive learning between image and natural language sentences.
15 - Low-Level Vision¶
Pass...
16 - 3D Vision¶
Representation¶
Explicit vs Implicit¶
Explicit: Easy to sample examples, hard to do inside/outside check.
Implicit: Hard to sample examples, easy to do inside/outside check.
| Non-parametric | Parametric | |
|---|---|---|
| Explicit | Points. Meshes. | Splines. Subdivision Surfaces. |
| Implicit | Level Sets. Voxels. | Algebraic Surfaces. Constructive Solid Geometry. |
Point Clouds¶
The simplest representation.
Collection of \((x,y,z)\) coordinates.
Cons:
- Difficult to draw in under-sampled regions.
- No simplification or subdivision.
- No direction smooth rendering.
- No topological information.
Polygonal Meshes¶
Collection of vertices \(v\) and edges \(e\).
Pros:
- Can apply downsampling or upsampling on meshes.
- Error decreases by \(O(n^2)\) while meshes increase by \(O(n)\).
- Can approximate arbitrary topology.
- Efficient rendering.
Splines¶
Use specific functions to approximate the surface. (e.g. Bézier Curves)
Algebraic Surfaces¶
Use specific functions to represent the surface.
Constructive Solid Geometry¶
Combine implicit geometry with Boolean operations.
Level Sets¶
Store a grim of values to approximate the function.
Surface is found where interpolated value equals to \(0\).
Voxels¶
Binary thresholding the volumetric grid.
AI + 3D¶
Pass...
wnc's café
Image Classification-Data-driven Approach, k-Nearest Neighbor, train_val_test splits¶
约 653 个字 28 行代码 预计阅读时间 4 分钟 共被读过 次
image classification¶
- challenges
- viewpoint variation
- scale variation
- deformation
- occlusion
- illumination conditions
- background clutter
- intra-class variation
- data-driven approach
- the image classification pipeline
- input
- learning
- training a classifier
- learning a model
- evaluation
Nearest Neighbor Classifier¶
\[ d_1 (I_1, I_2) = \sum_{p} \left| I^p_1 - I^p_2 \right| \]
Python
import numpy as np
+ body[data-md-color-scheme="slate"] .gslide-desc { color: var(--md-default-fg-color);} Image Classification-Data-driven Approach, k-Nearest Neighbor, train_val_test splits¶
约 653 个字 28 行代码 预计阅读时间 4 分钟 共被读过 次
image classification¶
- challenges
- viewpoint variation
- scale variation
- deformation
- occlusion
- illumination conditions
- background clutter
- intra-class variation
- data-driven approach
- the image classification pipeline
- input
- learning
- training a classifier
- learning a model
- evaluation
Nearest Neighbor Classifier¶
\[ d_1 (I_1, I_2) = \sum_{p} \left| I^p_1 - I^p_2 \right| \] Pythonimport numpy as np
class NearestNeighbor(object):
def **init**(self):
diff --git a/AI/CS231n/Linear classification-Support Vector Machine, Softmax/index.html b/AI/CS231n/Linear classification-Support Vector Machine, Softmax/index.html
index ebfdfd52..28e4c645 100644
--- a/AI/CS231n/Linear classification-Support Vector Machine, Softmax/index.html
+++ b/AI/CS231n/Linear classification-Support Vector Machine, Softmax/index.html
@@ -7,7 +7,7 @@
.gdesc-inner { font-size: 0.75rem; }
body[data-md-color-scheme="slate"] .gdesc-inner { background: var(--md-default-bg-color);}
body[data-md-color-scheme="slate"] .gslide-title { color: var(--md-default-fg-color);}
- body[data-md-color-scheme="slate"] .gslide-desc { color: var(--md-default-fg-color);} Linear classification-Support Vector Machine, Softmax¶
约 129 个字 预计阅读时间 1 分钟 共被读过 次
Linear Classifiaction¶
\[ L_i = \sum_{j\neq y_i} \max(0, s_j - s_{y_i} + \Delta) \] \[ L = \frac{1}{N} \sum_i \sum_{j\neq y_i} \left[ \max(0, f(x_i; W)_j - f(x_i; W)_{y_i} + \Delta) \right] + \lambda \sum_k\sum_l W_{k,l}^2 \] \[ L_i = -\log\left(\frac{e^{f_{y_i}}}{ \sum_j e^{f_j} }\right) \hspace{0.5in} \text{or equivalently} \hspace{0.5in} L_i = -f_{y_i} + \log\sum_j e^{f_j} \] \[ \frac{e^{f_{y_i}}}{\sum_j e^{f_j}} = \frac{Ce^{f_{y_i}}}{C\sum_j e^{f_j}} = \frac{e^{f_{y_i} + \log C}}{\sum_j e^{f_j + \log C}} \] ![[Pasted image 20241031210509.png]]
wnc's café Linear classification-Support Vector Machine, Softmax¶
约 129 个字 预计阅读时间 1 分钟 共被读过 次
Linear Classifiaction¶
\[ L_i = \sum_{j\neq y_i} \max(0, s_j - s_{y_i} + \Delta) \] \[ L = \frac{1}{N} \sum_i \sum_{j\neq y_i} \left[ \max(0, f(x_i; W)_j - f(x_i; W)_{y_i} + \Delta) \right] + \lambda \sum_k\sum_l W_{k,l}^2 \] \[ L_i = -\log\left(\frac{e^{f_{y_i}}}{ \sum_j e^{f_j} }\right) \hspace{0.5in} \text{or equivalently} \hspace{0.5in} L_i = -f_{y_i} + \log\sum_j e^{f_j} \] \[ \frac{e^{f_{y_i}}}{\sum_j e^{f_j}} = \frac{Ce^{f_{y_i}}}{C\sum_j e^{f_j}} = \frac{e^{f_{y_i} + \log C}}{\sum_j e^{f_j + \log C}} \] ![[Pasted image 20241031210509.png]]
wnc's café Numpy
Python¶
约 49 个字 104 行代码 预计阅读时间 2 分钟 共被读过 次
string¶
Pythons = "hello"
+ body[data-md-color-scheme="slate"] .gslide-desc { color: var(--md-default-fg-color);} Numpy
Python¶
约 49 个字 104 行代码 预计阅读时间 2 分钟 共被读过 次
string¶
Pythons = "hello"
print(s.capitalize()) # Capitalize a string; prints "Hello"
print(s.upper()) # Convert a string to uppercase; prints "HELLO"
print(s.rjust(7)) # Right-justify a string, padding with spaces; prints " hello"
diff --git a/AI/Dive_into_Deep_Learning/index.html b/AI/Dive_into_Deep_Learning/index.html
index 1c97111c..589d2e48 100644
--- a/AI/Dive_into_Deep_Learning/index.html
+++ b/AI/Dive_into_Deep_Learning/index.html
@@ -7,7 +7,7 @@
.gdesc-inner { font-size: 0.75rem; }
body[data-md-color-scheme="slate"] .gdesc-inner { background: var(--md-default-bg-color);}
body[data-md-color-scheme="slate"] .gslide-title { color: var(--md-default-fg-color);}
- body[data-md-color-scheme="slate"] .gslide-desc { color: var(--md-default-fg-color);} Dive into Deep Learning¶
约 1547 个字 387 行代码 预计阅读时间 13 分钟 共被读过 次
1 引言 ¶
2 预备知识 ¶
2.1 数据操作 ¶
- tensor
- ndarray (MXNet)
- Tensor (TensorFlow)
Pythonx = torch.arrange(12)
+ body[data-md-color-scheme="slate"] .gslide-desc { color: var(--md-default-fg-color);} Dive into Deep Learning¶
约 1547 个字 387 行代码 预计阅读时间 13 分钟 共被读过 次
1 引言 ¶
2 预备知识 ¶
2.1 数据操作 ¶
- tensor
- ndarray (MXNet)
- Tensor (TensorFlow)
Pythonx = torch.arrange(12)
x.shape
x.numel()
x.reshape(3, 4)
diff --git a/AI/EECS 498-007/KNN/index.html b/AI/EECS 498-007/KNN/index.html
index 4eb1b5cc..5b1f92a3 100644
--- a/AI/EECS 498-007/KNN/index.html
+++ b/AI/EECS 498-007/KNN/index.html
@@ -7,7 +7,7 @@
.gdesc-inner { font-size: 0.75rem; }
body[data-md-color-scheme="slate"] .gdesc-inner { background: var(--md-default-bg-color);}
body[data-md-color-scheme="slate"] .gslide-title { color: var(--md-default-fg-color);}
- body[data-md-color-scheme="slate"] .gslide-desc { color: var(--md-default-fg-color);} KNN
对于一个待分类的样本,找到训练数据集中与其最接近的 K 个样本(即最近邻) ,然后根据这 K 个样本的类别来决定待分类样本的类别。
约 374 个字 100 行代码 预计阅读时间 3 分钟 共被读过 次
数学推导 ¶
假设我们有一个训练数据集 \(T = \{(x_1, y_1), (x_2, y_2), \ldots, (x_N, y_N)\}\),其中 \(x_i\) 是特征向量, \(y_i\) 是对应的类别标签。对于一个新的待分类样本 x,KNN 算法的目标是预测其类别 \(y\) 。
- 距离度量:首先,我们需要一个距离度量来计算待分类样本 \(x\) 与训练集中每个样本 \(x_i\) 之间的距离。常用的距离度量包括欧氏距离(Euclidean distance
) 、曼哈顿距离(Manhattan distance)和闵可夫斯基距离(Minkowski distance) 。以欧氏距离为例,两个样本 \(x\) 和 \(x_i\) 之间的距离定义为:
\[ d(x, x_i) = \sqrt{\sum_{j=1}^{d} (x_j - x_{i,j})^2} \] 其中, \(d\) 是特征的维度。
- 寻找最近邻:然后,我们根据计算出的距离,选择距离最近的 K 个样本,构成待分类样本的邻域 \(N_k(x)\)。
- 决策规则:最后,根据邻域 \( N_k(x) \) 中的样本类别,通过多数投票的方式来决定待分类样本的类别。即:
\[ y = \arg\max_{c_j} \sum_{x_i \in N_k(x)} I(y_i = c_j) \] 其中, \(I\) 是指示函数,当 \(y_i = c_j\) 时取值为 1,否则为 0。
作业中的实现 ¶
Pythonimport torch
+ body[data-md-color-scheme="slate"] .gslide-desc { color: var(--md-default-fg-color);} KNN
对于一个待分类的样本,找到训练数据集中与其最接近的 K 个样本(即最近邻) ,然后根据这 K 个样本的类别来决定待分类样本的类别。
约 374 个字 100 行代码 预计阅读时间 3 分钟 共被读过 次
数学推导 ¶
假设我们有一个训练数据集 \(T = \{(x_1, y_1), (x_2, y_2), \ldots, (x_N, y_N)\}\),其中 \(x_i\) 是特征向量, \(y_i\) 是对应的类别标签。对于一个新的待分类样本 x,KNN 算法的目标是预测其类别 \(y\) 。
- 距离度量:首先,我们需要一个距离度量来计算待分类样本 \(x\) 与训练集中每个样本 \(x_i\) 之间的距离。常用的距离度量包括欧氏距离(Euclidean distance
) 、曼哈顿距离(Manhattan distance)和闵可夫斯基距离(Minkowski distance) 。以欧氏距离为例,两个样本 \(x\) 和 \(x_i\) 之间的距离定义为:
\[ d(x, x_i) = \sqrt{\sum_{j=1}^{d} (x_j - x_{i,j})^2} \] 其中, \(d\) 是特征的维度。
- 寻找最近邻:然后,我们根据计算出的距离,选择距离最近的 K 个样本,构成待分类样本的邻域 \(N_k(x)\)。
- 决策规则:最后,根据邻域 \( N_k(x) \) 中的样本类别,通过多数投票的方式来决定待分类样本的类别。即:
\[ y = \arg\max_{c_j} \sum_{x_i \in N_k(x)} I(y_i = c_j) \] 其中, \(I\) 是指示函数,当 \(y_i = c_j\) 时取值为 1,否则为 0。
作业中的实现 ¶
Pythonimport torch
def compute_distances_two_loops(x_train, x_test):
num_train = x_train.shape[0]
diff --git a/AI/EECS 498-007/Pytorch/index.html b/AI/EECS 498-007/Pytorch/index.html
index 07bb889a..592684a9 100644
--- a/AI/EECS 498-007/Pytorch/index.html
+++ b/AI/EECS 498-007/Pytorch/index.html
@@ -7,7 +7,7 @@
.gdesc-inner { font-size: 0.75rem; }
body[data-md-color-scheme="slate"] .gdesc-inner { background: var(--md-default-bg-color);}
body[data-md-color-scheme="slate"] .gslide-title { color: var(--md-default-fg-color);}
- body[data-md-color-scheme="slate"] .gslide-desc { color: var(--md-default-fg-color);} pytorch 的基本使用 ¶
约 564 个字 45 行代码 预计阅读时间 3 分钟 共被读过 次
Python# Create a rank 1 tensor from a Python list
+ body[data-md-color-scheme="slate"] .gslide-desc { color: var(--md-default-fg-color);} pytorch 的基本使用 ¶
约 564 个字 45 行代码 预计阅读时间 3 分钟 共被读过 次
Python# Create a rank 1 tensor from a Python list
a = torch.tensor([[1, 2, 3], [4, 5, 6]])
print('Here is a:')
print(a)
diff --git a/AI/EECS 498-007/linear_classifer/index.html b/AI/EECS 498-007/linear_classifer/index.html
index c71420a3..f779b729 100644
--- a/AI/EECS 498-007/linear_classifer/index.html
+++ b/AI/EECS 498-007/linear_classifer/index.html
@@ -7,7 +7,7 @@
.gdesc-inner { font-size: 0.75rem; }
body[data-md-color-scheme="slate"] .gdesc-inner { background: var(--md-default-bg-color);}
body[data-md-color-scheme="slate"] .gslide-title { color: var(--md-default-fg-color);}
- body[data-md-color-scheme="slate"] .gslide-desc { color: var(--md-default-fg-color);} Linear classifer
原理 ¶
约 677 个字 216 行代码 预计阅读时间 6 分钟 共被读过 次
两种线性分类器:支持向量机(SVM)和 Softmax 分类器。这两种分类器都是监督学习算法,用于分类任务。
支持向量机(SVM)¶
SVM 的目标是找到一个超平面,它可以最大化不同类别之间的边界。这个超平面被称为最优分割超平面。对于二分类问题,SVM 的损失函数可以表示为:
\[ L(W, b) = \frac{1}{N} \sum_{i=1}^{N} \max(0, 1 - y_i (W \cdot x_i + b)) \] 其中,\(W\) 是权重向量,\(b\) 是偏置项,\(x_i\) 是输入特征,\(y_i\) 是标签(-1 或 1) ,\(N\) 是样本数量。
为了实现多分类,我们使用结构化 SVM 损失函数,它考虑了每个类别的分数,并尝试最大化正确类别的分数与次高类别分数之间的差距。损失函数可以表示为:
\[ L(W) = \frac{1}{N} \sum_{i=1}^{N} \sum_{j \neq y_i} \max(0, \text{score}_j - \text{score}_{y_i} + \Delta) \] 其中,\(\text{score}_j = W_j \cdot x_i\),\(\Delta\) 是一个常数,通常设置为 1。
Softmax 分类器 ¶
Softmax 分类器使用 Softmax 函数将输入特征映射到概率分布上。对于每个样本,Softmax 函数输出每个类别的概率。Softmax 函数定义为:
\[ \text{softmax}(z_i) = \frac{e^{z_i}}{\sum_{j=1}^{K} e^{z_j}} \] 其中,\(z_i\) 是第 \(i\) 个类别的分数,\(K\) 是类别总数。
Softmax 分类器的损失函数是交叉熵损失,可以表示为:
\[ L(W) = -\frac{1}{N} \sum_{i=1}^{N} \sum_{j=1}^{K} y_{ij} \log(\text{softmax}(z_j)) \] 其中,\(y_{ij}\) 是一个指示变量,如果样本 \(i\) 属于类别 \(j\),则为 1,否则为 0。
正则化 ¶
为了防止过拟合,我们在损失函数中添加了正则化项。L2 正则化的损失函数可以表示为:
\[ L(W) = L(W) + \lambda \lVert W \rVert^2 \] 其中,\(\lambda\) 是正则化强度。
代码实现 ¶
代码中实现了两种损失函数的朴素版本(svm_loss_naive 和 softmax_loss_naive)和向量化版本(svm_loss_vectorized 和 softmax_loss_vectorized) 。向量化版本通过避免显式循环来提高计算效率。
训练过程(train_linear_classifier)使用随机梯度下降(SGD)来优化损失函数。在每次迭代中,我们随机抽取一个批次的样本,计算损失和梯度,然后更新权重。
预测过程(predict_linear_classifier)使用训练好的权重来预测新样本的类别。
超参数搜索 ¶
代码中还包含了超参数搜索的函数(svm_get_search_params 和 softmax_get_search_params) ,它们返回不同的学习率和正则化强度的候选值,以便找到最佳的模型参数。
作业实现 ¶
Pythonimport torch
+ body[data-md-color-scheme="slate"] .gslide-desc { color: var(--md-default-fg-color);} Linear classifer
原理 ¶
约 677 个字 216 行代码 预计阅读时间 6 分钟 共被读过 次
两种线性分类器:支持向量机(SVM)和 Softmax 分类器。这两种分类器都是监督学习算法,用于分类任务。
支持向量机(SVM)¶
SVM 的目标是找到一个超平面,它可以最大化不同类别之间的边界。这个超平面被称为最优分割超平面。对于二分类问题,SVM 的损失函数可以表示为:
\[ L(W, b) = \frac{1}{N} \sum_{i=1}^{N} \max(0, 1 - y_i (W \cdot x_i + b)) \] 其中,\(W\) 是权重向量,\(b\) 是偏置项,\(x_i\) 是输入特征,\(y_i\) 是标签(-1 或 1) ,\(N\) 是样本数量。
为了实现多分类,我们使用结构化 SVM 损失函数,它考虑了每个类别的分数,并尝试最大化正确类别的分数与次高类别分数之间的差距。损失函数可以表示为:
\[ L(W) = \frac{1}{N} \sum_{i=1}^{N} \sum_{j \neq y_i} \max(0, \text{score}_j - \text{score}_{y_i} + \Delta) \] 其中,\(\text{score}_j = W_j \cdot x_i\),\(\Delta\) 是一个常数,通常设置为 1。
Softmax 分类器 ¶
Softmax 分类器使用 Softmax 函数将输入特征映射到概率分布上。对于每个样本,Softmax 函数输出每个类别的概率。Softmax 函数定义为:
\[ \text{softmax}(z_i) = \frac{e^{z_i}}{\sum_{j=1}^{K} e^{z_j}} \] 其中,\(z_i\) 是第 \(i\) 个类别的分数,\(K\) 是类别总数。
Softmax 分类器的损失函数是交叉熵损失,可以表示为:
\[ L(W) = -\frac{1}{N} \sum_{i=1}^{N} \sum_{j=1}^{K} y_{ij} \log(\text{softmax}(z_j)) \] 其中,\(y_{ij}\) 是一个指示变量,如果样本 \(i\) 属于类别 \(j\),则为 1,否则为 0。
正则化 ¶
为了防止过拟合,我们在损失函数中添加了正则化项。L2 正则化的损失函数可以表示为:
\[ L(W) = L(W) + \lambda \lVert W \rVert^2 \] 其中,\(\lambda\) 是正则化强度。
代码实现 ¶
代码中实现了两种损失函数的朴素版本(svm_loss_naive 和 softmax_loss_naive)和向量化版本(svm_loss_vectorized 和 softmax_loss_vectorized) 。向量化版本通过避免显式循环来提高计算效率。
训练过程(train_linear_classifier)使用随机梯度下降(SGD)来优化损失函数。在每次迭代中,我们随机抽取一个批次的样本,计算损失和梯度,然后更新权重。
预测过程(predict_linear_classifier)使用训练好的权重来预测新样本的类别。
超参数搜索 ¶
代码中还包含了超参数搜索的函数(svm_get_search_params 和 softmax_get_search_params) ,它们返回不同的学习率和正则化强度的候选值,以便找到最佳的模型参数。
作业实现 ¶
Pythonimport torch
import random
from abc import abstractmethod
diff --git a/AI/FFB6D/FFB6D_Conda/index.html b/AI/FFB6D/FFB6D_Conda/index.html
index b2fc1891..acd402bd 100644
--- a/AI/FFB6D/FFB6D_Conda/index.html
+++ b/AI/FFB6D/FFB6D_Conda/index.html
@@ -7,7 +7,7 @@
.gdesc-inner { font-size: 0.75rem; }
body[data-md-color-scheme="slate"] .gdesc-inner { background: var(--md-default-bg-color);}
body[data-md-color-scheme="slate"] .gslide-title { color: var(--md-default-fg-color);}
- body[data-md-color-scheme="slate"] .gslide-desc { color: var(--md-default-fg-color);} FFB6D 环境配置指南:原生系统安装 ¶
约 293 个字 96 行代码 预计阅读时间 3 分钟 共被读过 次
1. 系统要求 ¶
- Ubuntu 20.04/22.04/24.04
- NVIDIA GPU(支持 CUDA)
- 至少 8GB 内存
- 至少 30GB 磁盘空间
2. 基础环境配置 ¶
2.1 安装 NVIDIA 驱动 ¶
Bash# 添加NVIDIA包仓库
+ body[data-md-color-scheme="slate"] .gslide-desc { color: var(--md-default-fg-color);} FFB6D 环境配置指南:原生系统安装 ¶
约 293 个字 96 行代码 预计阅读时间 3 分钟 共被读过 次
1. 系统要求 ¶
- Ubuntu 20.04/22.04/24.04
- NVIDIA GPU(支持 CUDA)
- 至少 8GB 内存
- 至少 30GB 磁盘空间
2. 基础环境配置 ¶
2.1 安装 NVIDIA 驱动 ¶
Bash# 添加NVIDIA包仓库
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt-get update
diff --git a/AI/FFB6D/FFB6D_Docker/index.html b/AI/FFB6D/FFB6D_Docker/index.html
index 1fb14e6f..205c805f 100644
--- a/AI/FFB6D/FFB6D_Docker/index.html
+++ b/AI/FFB6D/FFB6D_Docker/index.html
@@ -7,7 +7,7 @@
.gdesc-inner { font-size: 0.75rem; }
body[data-md-color-scheme="slate"] .gdesc-inner { background: var(--md-default-bg-color);}
body[data-md-color-scheme="slate"] .gslide-title { color: var(--md-default-fg-color);}
- body[data-md-color-scheme="slate"] .gslide-desc { color: var(--md-default-fg-color);} Docker 从入门到实践:以 FFB6D 环境配置为例 ¶
约 653 个字 213 行代码 预计阅读时间 6 分钟 共被读过 次
1. 简介 ¶
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 或 Windows 操作系统上。本文将以配置 FFB6D(一个 3D 目标检测模型)的运行环境为例,介绍 Docker 的基本使用。
2. 环境准备 ¶
2.1 系统要求 ¶
- Ubuntu 20.04/22.04/24.04
- NVIDIA GPU(支持 CUDA)
- 至少 8GB 内存
- 至少 30GB 磁盘空间
2.2 基础组件安装 ¶
安装 Docker
Bash# 更新apt包索引
+ body[data-md-color-scheme="slate"] .gslide-desc { color: var(--md-default-fg-color);} Docker 从入门到实践:以 FFB6D 环境配置为例 ¶
约 653 个字 213 行代码 预计阅读时间 6 分钟 共被读过 次
1. 简介 ¶
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 或 Windows 操作系统上。本文将以配置 FFB6D(一个 3D 目标检测模型)的运行环境为例,介绍 Docker 的基本使用。
2. 环境准备 ¶
2.1 系统要求 ¶
- Ubuntu 20.04/22.04/24.04
- NVIDIA GPU(支持 CUDA)
- 至少 8GB 内存
- 至少 30GB 磁盘空间
2.2 基础组件安装 ¶
安装 Docker
Bash# 更新apt包索引
sudo apt-get update
# 安装必要的系统工具
diff --git a/AI/SLAM14/index.html b/AI/SLAM14/index.html
index 3466ae73..2f815b87 100644
--- a/AI/SLAM14/index.html
+++ b/AI/SLAM14/index.html
@@ -7,7 +7,7 @@
.gdesc-inner { font-size: 0.75rem; }
body[data-md-color-scheme="slate"] .gdesc-inner { background: var(--md-default-bg-color);}
body[data-md-color-scheme="slate"] .gslide-title { color: var(--md-default-fg-color);}
- body[data-md-color-scheme="slate"] .gslide-desc { color: var(--md-default-fg-color);} 视觉 SLAM 十四讲 ¶
约 14110 个字 72 行代码 20 张图片 预计阅读时间 71 分钟 共被读过 次
1 预备知识 ¶
1.1 本书讲什么 ¶
simultaneous localization and mapping
- 定位
- 地图构建
- 背景知识 :
- 射影几何
- 计算机视觉
- 状态估计理论
- 李群与李代数
1.2 如何使用本书 ¶
1.2.1 组织方式 ¶
- 数学基础篇

- 实践应用篇

1.2.2 代码 ¶
GitHub - gaoxiang12/slambook2: edition 2 of the slambook
1.2.3 面向的读者 ¶
- 基础知识 :
- 高数线代概率论
- C++ 语言基础(C++ 标准库,模板类,一部分 C++11 )
- Linux 基础
1.3 风格约定 ¶
1.4 致谢和声明 ¶
1.5 习题 ¶
- 题目:有线性方程 \(A x=b\),若已知 \(A, b\),需要求解 x,该如何求解?这对 A 和 b 有哪些要求?提示:从 A 的维度和秩角度来分析。
- 答案:线性方程组 \(Ax = b\) 可以通过多种方法求解,如高斯消元法、矩阵逆法等。要求 \(A\) 是一个方阵且可逆(即 \(A\) 的行列式不为零
) ,这样方程才有唯一解。如果 \(A\) 不是方阵,需要 \(A\) 的秩等于列数且等于增广矩阵 \(\displaystyle [A|b]\) 的秩,这样方程组才有解。 - 题目:高斯分布是什么?它的一维形式是什么样子?它的高维形式是什么样子?
- 答案:高斯分布,也称为正态分布,是一种连续概率分布。一维高斯分布的数学表达式为 \(\displaystyle f (x) = \frac{1}{\sigma\sqrt{2\pi}} e^{-\frac{(x-\mu)^2}{2\sigma^2}}\),其中 \(\displaystyle \mu\) 是均值,\(\displaystyle \sigma\) 是标准差。高维高斯分布是一维高斯分布在多维空间的推广,其概率密度函数为 \(\displaystyle N (\mathbf{x}; \mathbf{\mu}, \Sigma)\),其中 \(\displaystyle \mathbf{\mu}\) 是均值向量,\(\displaystyle \Sigma\) 是协方差矩阵。
- 题目:你知道 C++11 标准吗?你听说过或用过其中哪些新特性?有没有其他的标准?
- 答案:是的,C++11 是 C++ 语言的一个重要标准,它引入了许多新特性,如自动类型推导(auto
) 、基于范围的 for 循环、lambda 表达式、智能指针等。除了 C++11,还有 C++14、C++17 和 C++20 等后续标准,它们也引入了新的特性和改进。 - 题目:如何在 Ubuntu 系统中安装软件(不打开软件中心的情况下
) ?这些软件被安装在什么地方?如果只知道模糊的软件名称(比如想要装一个名称中含有 Eigen 的库) ,应该如何安装它? - 答案:
- 软件安装:在 Ubuntu 中,可以使用命令行工具
apt 来安装软件。基本命令为 sudo apt install [package-name]。 - 安装位置:软件通常被安装在
/usr/ 目录下,但具体的文件可能分布在多个子目录中。 - 模糊名称安装:如果只知道软件名称的一部分,可以使用
apt search 命令来搜索。例如,sudo apt search eigen 可以帮助找到所有包含 "eigen" 的软件包。 - 题目:* 花一个小时学习 Vim,因为你迟早会用它。你可以在终端中输入 vimtutor 阅读一遍所有内容。我们不需要你非常熟练地操作它,只要能够在学习本书的过程中使用它输入代码即可。不要在它的插件上浪费时间,不要想着把 Vim 用成 IDE,我们只用它做文本编辑的工作。
- 答案:
- vim 根本不熟练捏
2 初识 SLAM ¶
2.1 引子 : 小萝卜的例子 ¶
- 自主运动能力
- 感知周边环境
- 状态
- 环境
- 安装于环境中(不太好反正)
- 机器人本体上
- 激光 SLAM
- 视觉 SLAM(本书重点)
- 单目(Monocular)
- 只能用一个摄像头
- 距离感
- motion
- Structure
- Disparity
- Scale
- Scale Ambiguity
- 但是无法确定深度
- 双目(Sterco)
- 两个相机的距离(基线 Baseline)已知
- 配置与标定比较复杂
- 深度(RGB-D)
- 红外结构关 Time-of-Flight(ToF)
- 主要用在室内,室外会有很多影响
- 还有一些非主流的 : 全景,Event
2.2 经典视觉 SLAM 框架 ¶

- 在外界换几个比较稳定的情况下,SLAM 技术已经比较成熟
2.2.1 视觉里程计 ¶
- 只通过视觉里程计来估计轨迹会出现累积漂移(Accumulating Drift
) 。 - 所以需要回环检测与后端优化
2.2.2 后端优化 ¶
- 最大后验概率估计(Maximum-a-Posteriori MAP)
- 前端
- 图像的特征提取与匹配
- 后端
- 滤波与非线性算法
- 对运动主体自身和周围环境空间不确定性的估计
2.2.3 回环检测 ¶
- 闭环检测
- 识别到过的场景
- 利用图像的相似性
2.2.4 建图 ¶
- 度量地图
- Sparse
- Landmark
- 定位用
- Dense
- Grid / Vocel
- 导航用
- 拓扑地图
Graph
2.3 SLAM 问题的数学表述 ¶
- 运动方程
- \(\displaystyle \quad\boldsymbol{x}_k=f\left(\boldsymbol{x}_{k-1},\boldsymbol{u}_k,\boldsymbol{w}_k\right).\)
- \(\displaystyle \boldsymbol{u}_{k}\) 是运动传感器的输入
- \(\displaystyle \boldsymbol{w}_{k}\) 是过程中加入的噪声
- 观测方程
- \(\displaystyle \boldsymbol{z}_{k,j} = h (\boldsymbol{y}_{j},\boldsymbol{x}_{k},\boldsymbol{v}_{k,j})\)
- \(\displaystyle \boldsymbol{v}_{k,j}\) 是观测里的噪声
- 又很多参数化的方式
- 可以总结为如下两个方程
\[ \begin{cases}\boldsymbol{x}_k=f\left(\boldsymbol{x}_{k-1},\boldsymbol{u}_k,\boldsymbol{w}_k\right),&k=1,\cdots,K\\\boldsymbol{z}_{k,j}=h\left(\boldsymbol{y}_j,\boldsymbol{x}_k,\boldsymbol{v}_{k,j}\right),&(k,j)\in\mathcal{O}\end{cases}. \] - 知道运动测量的读数 \(\displaystyle \boldsymbol{u}\) 和传感器的读数 \(\displaystyle \boldsymbol{z}\),如何求解定位问题和建图问题。
- 状态估计问题 : 如何通过带有噪声的测量数据,估计内部的、隐藏着的状态变量
- Linear Gaussian -> Kalman Filter
- Non-Linear Non-Gaussian -> Extended Kalman Filter 和非线性优化
- EKF -> Particle Filter -> Graph Optimization
2.4 实践 : 编程基础 ¶
2.4.1 安装 Linux 操作系统 ¶
2.4.2 Hello SLAM¶
2.4.3 使用 cmake ¶
Text Onlycmake_minimum_required( VERSION 2.8)
+ body[data-md-color-scheme="slate"] .gslide-desc { color: var(--md-default-fg-color);} 视觉 SLAM 十四讲 ¶
约 14110 个字 72 行代码 20 张图片 预计阅读时间 71 分钟 共被读过 次
1 预备知识 ¶
1.1 本书讲什么 ¶
simultaneous localization and mapping
- 定位
- 地图构建
- 背景知识 :
- 射影几何
- 计算机视觉
- 状态估计理论
- 李群与李代数
1.2 如何使用本书 ¶
1.2.1 组织方式 ¶
- 数学基础篇
- 实践应用篇
1.2.2 代码 ¶
GitHub - gaoxiang12/slambook2: edition 2 of the slambook
1.2.3 面向的读者 ¶
- 基础知识 :
- 高数线代概率论
- C++ 语言基础(C++ 标准库,模板类,一部分 C++11 )
- Linux 基础
1.3 风格约定 ¶
1.4 致谢和声明 ¶
1.5 习题 ¶
- 题目:有线性方程 \(A x=b\),若已知 \(A, b\),需要求解 x,该如何求解?这对 A 和 b 有哪些要求?提示:从 A 的维度和秩角度来分析。
- 答案:线性方程组 \(Ax = b\) 可以通过多种方法求解,如高斯消元法、矩阵逆法等。要求 \(A\) 是一个方阵且可逆(即 \(A\) 的行列式不为零
) ,这样方程才有唯一解。如果 \(A\) 不是方阵,需要 \(A\) 的秩等于列数且等于增广矩阵 \(\displaystyle [A|b]\) 的秩,这样方程组才有解。 - 题目:高斯分布是什么?它的一维形式是什么样子?它的高维形式是什么样子?
- 答案:高斯分布,也称为正态分布,是一种连续概率分布。一维高斯分布的数学表达式为 \(\displaystyle f (x) = \frac{1}{\sigma\sqrt{2\pi}} e^{-\frac{(x-\mu)^2}{2\sigma^2}}\),其中 \(\displaystyle \mu\) 是均值,\(\displaystyle \sigma\) 是标准差。高维高斯分布是一维高斯分布在多维空间的推广,其概率密度函数为 \(\displaystyle N (\mathbf{x}; \mathbf{\mu}, \Sigma)\),其中 \(\displaystyle \mathbf{\mu}\) 是均值向量,\(\displaystyle \Sigma\) 是协方差矩阵。
- 题目:你知道 C++11 标准吗?你听说过或用过其中哪些新特性?有没有其他的标准?
- 答案:是的,C++11 是 C++ 语言的一个重要标准,它引入了许多新特性,如自动类型推导(auto
) 、基于范围的 for 循环、lambda 表达式、智能指针等。除了 C++11,还有 C++14、C++17 和 C++20 等后续标准,它们也引入了新的特性和改进。 - 题目:如何在 Ubuntu 系统中安装软件(不打开软件中心的情况下
) ?这些软件被安装在什么地方?如果只知道模糊的软件名称(比如想要装一个名称中含有 Eigen 的库) ,应该如何安装它? - 答案:
- 软件安装:在 Ubuntu 中,可以使用命令行工具
apt 来安装软件。基本命令为 sudo apt install [package-name]。 - 安装位置:软件通常被安装在
/usr/ 目录下,但具体的文件可能分布在多个子目录中。 - 模糊名称安装:如果只知道软件名称的一部分,可以使用
apt search 命令来搜索。例如,sudo apt search eigen 可以帮助找到所有包含 "eigen" 的软件包。 - 题目:* 花一个小时学习 Vim,因为你迟早会用它。你可以在终端中输入 vimtutor 阅读一遍所有内容。我们不需要你非常熟练地操作它,只要能够在学习本书的过程中使用它输入代码即可。不要在它的插件上浪费时间,不要想着把 Vim 用成 IDE,我们只用它做文本编辑的工作。
- 答案:
- vim 根本不熟练捏
2 初识 SLAM ¶
2.1 引子 : 小萝卜的例子 ¶
- 自主运动能力
- 感知周边环境
- 状态
- 环境
- 安装于环境中(不太好反正)
- 机器人本体上
- 激光 SLAM
- 视觉 SLAM(本书重点)
- 单目(Monocular)
- 只能用一个摄像头
- 距离感
- motion
- Structure
- Disparity
- Scale
- Scale Ambiguity
- 但是无法确定深度
- 双目(Sterco)
- 两个相机的距离(基线 Baseline)已知
- 配置与标定比较复杂
- 深度(RGB-D)
- 红外结构关 Time-of-Flight(ToF)
- 主要用在室内,室外会有很多影响
- 还有一些非主流的 : 全景,Event
2.2 经典视觉 SLAM 框架 ¶
- 在外界换几个比较稳定的情况下,SLAM 技术已经比较成熟
2.2.1 视觉里程计 ¶
- 只通过视觉里程计来估计轨迹会出现累积漂移(Accumulating Drift
) 。 - 所以需要回环检测与后端优化
2.2.2 后端优化 ¶
- 最大后验概率估计(Maximum-a-Posteriori MAP)
- 前端
- 图像的特征提取与匹配
- 后端
- 滤波与非线性算法
- 对运动主体自身和周围环境空间不确定性的估计
2.2.3 回环检测 ¶
- 闭环检测
- 识别到过的场景
- 利用图像的相似性
2.2.4 建图 ¶
- 度量地图
- Sparse
- Landmark
- 定位用
- Dense
- Grid / Vocel
- 导航用
- 拓扑地图
Graph
2.3 SLAM 问题的数学表述 ¶
- 运动方程
- \(\displaystyle \quad\boldsymbol{x}_k=f\left(\boldsymbol{x}_{k-1},\boldsymbol{u}_k,\boldsymbol{w}_k\right).\)
- \(\displaystyle \boldsymbol{u}_{k}\) 是运动传感器的输入
- \(\displaystyle \boldsymbol{w}_{k}\) 是过程中加入的噪声
- 观测方程
- \(\displaystyle \boldsymbol{z}_{k,j} = h (\boldsymbol{y}_{j},\boldsymbol{x}_{k},\boldsymbol{v}_{k,j})\)
- \(\displaystyle \boldsymbol{v}_{k,j}\) 是观测里的噪声
- 又很多参数化的方式
- 可以总结为如下两个方程
\[ \begin{cases}\boldsymbol{x}_k=f\left(\boldsymbol{x}_{k-1},\boldsymbol{u}_k,\boldsymbol{w}_k\right),&k=1,\cdots,K\\\boldsymbol{z}_{k,j}=h\left(\boldsymbol{y}_j,\boldsymbol{x}_k,\boldsymbol{v}_{k,j}\right),&(k,j)\in\mathcal{O}\end{cases}. \] - 知道运动测量的读数 \(\displaystyle \boldsymbol{u}\) 和传感器的读数 \(\displaystyle \boldsymbol{z}\),如何求解定位问题和建图问题。
- 状态估计问题 : 如何通过带有噪声的测量数据,估计内部的、隐藏着的状态变量
- Linear Gaussian -> Kalman Filter
- Non-Linear Non-Gaussian -> Extended Kalman Filter 和非线性优化
- EKF -> Particle Filter -> Graph Optimization
2.4 实践 : 编程基础 ¶
2.4.1 安装 Linux 操作系统 ¶
2.4.2 Hello SLAM¶
2.4.3 使用 cmake ¶
Text Onlycmake_minimum_required( VERSION 2.8)
project(HelloSLAM)
diff --git a/AI/index.html b/AI/index.html
index 43a9192e..02e70e21 100644
--- a/AI/index.html
+++ b/AI/index.html
@@ -7,7 +7,7 @@
.gdesc-inner { font-size: 0.75rem; }
body[data-md-color-scheme="slate"] .gdesc-inner { background: var(--md-default-bg-color);}
body[data-md-color-scheme="slate"] .gslide-title { color: var(--md-default-fg-color);}
- body[data-md-color-scheme="slate"] .gslide-desc { color: var(--md-default-fg-color);} Artificial Intelligence¶
Abstract
本部分内容(除特别声明外)采用 署名 - 非商业性使用 - 保持一致 4.0 国际 (CC BY-NC-SA 4.0) 许可协议进行许可。
- 653 213 5 mins 1734024510
- 293 96 2 mins 1734024510
- 564 45 2 mins 1734024510
- 374 100 2 mins 1734012860
- 0 0 mins 0
- 49 104 1 mins 1734024510
- 8852 30 mins 1734012860
- 3356 11 mins 1734012860
- 1547 387 10 mins 1734720663
- 14110 72 48 mins 1734720663
Artificial Intelligence¶
Abstract
本部分内容(除特别声明外)采用 署名 - 非商业性使用 - 保持一致 4.0 国际 (CC BY-NC-SA 4.0) 许可协议进行许可。
- 653 213 5 mins 1734024510
- 293 96 2 mins 1734024510
- 564 45 2 mins 1734024510
- 374 100 2 mins 1734012860
- 0 0 mins 0
- 49 104 1 mins 1734024510
- 8852 30 mins 1734012860
- 3356 11 mins 1734012860
- 1547 387 10 mins 1734720663
- 14110 72 48 mins 1734720663
统计学习方法 ¶
约 3356 个字 43 张图片 预计阅读时间 17 分钟 共被读过 次
1 统计学习方法概论 ¶
1.1 统计学习 ¶
- 统计学习的特点
- 以计算机及网络为平台
- 以数据为研究对象
- 目的是对数据进行预测与分析
- 交叉学科
- 统计学习的对象
- 是数据
- 统计学习的目的
- 统计学习的方法
- 主要有
- 监督学习(本书主要讨论)
- 非监督学习
- 半监督学习
- 强化学习
- 三要素
- 模型
- 策略
- 算法
- 实现步骤
- 得到一个训练数据集合
- 确定学习模型的集合
- 确定学习的策略
- 确定学习的算法
- 通过学习方法选择最优模型
- 利用学习的最优模型对新数据进行预测或分析
- 统计学习的研究
- 方法
- 理论
- 应用
- 统计学习的重要性
1.2 监督学习 ¶
1.2.1 基本概念 ¶
- 输入空间、特征空间与输出空间
- 每个输入是一个实例,通常由特征向量表示
- 监督学习从训练数据集合中学习模型,对测试数据进行预测
- 根据输入变量和输出变量的不同类型
- 回归问题 : 都连续
- 分类问题 : 输出有限离散
- 标注问题 : 都是变量序列
- 联合概率分布
- 假设空间
- 模型属于由输入空间到输出空间的映射的集合,这个集合就是假设空间
- 模型可以是(非)概率模型
1.2.2 问题的形式化 ¶
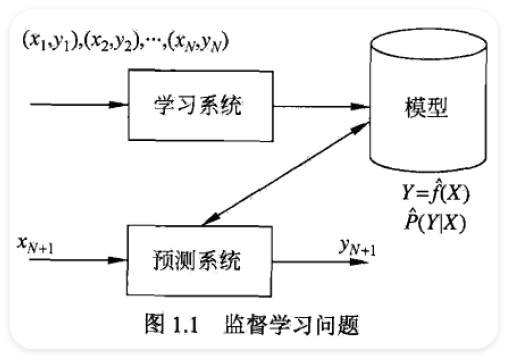
1.3 统计学习三要读 ¶
- 方法 = 模型 + 策略 + 算法
1.3.1 模型 ¶
- 模型就是索要学习的条件概率分布或决策函数
\[ \mathcal{F}=\{f\mid Y=f(X)\} \] - 参数空间
\[ \mathcal{F}=\{f | Y=f_{\theta}(X),\theta\in\mathbf{R}^{n}\} \] - 同样可以定义为条件概率的集合
\[ \mathcal{F}=\{P|P(Y|X)\} \] \[ \mathcal{F}=\{P\mid P_{\theta}(Y\mid X),\theta\in\mathbf{R}^{n}\} \] 1.3.2 策略 ¶
- 损失函数和风险函数
- loos function or cost function \(\displaystyle L(Y,f(X))\)
- 0-1 loss function
- \(\displaystyle L(Y,f(X))=\begin{cases}1,&Y\neq f(X)\\0,&Y=f(X)\end{cases}\)
- quadratic loss function
- \(\displaystyle L(Y,f(X))=(Y-f(X))^{2}\)
- absolute loss function
- \(\displaystyle L(Y,f(X))=|Y-f(X)|\)
- logarithmic loss function or log-likelihood loss function
- \(\displaystyle L(Y,P(Y\mid X))=-\log P(Y\mid X)\)
- \(\displaystyle R_{\exp}(f)=E_{P}[L(Y,f(X))]=\int_{x\times y}L(y,f(x))P(x,y)\mathrm{d}x\mathrm{d}y\)
- risk function or expected loss
- 但是联合分布位置,所以要学习,但是这样以来风险最小又要用到联合分布,那么这就成为了病态问题 (ill-formed problem)
- empirical risk or empirical loss
- \(\displaystyle R_{\mathrm{emp}}(f)=\frac{1}{N}\sum_{i=1}^{N}L(y_{i},f(x_{i}))\)
- 当 \(\displaystyle N\) 趋于无穷时,经验风险趋于期望风险
- 这就关系到两个基本策略 :
- 经验风险最小化
- 结构风险最小化
- 经验风险最小化与结构风险最小化
- empirical risk minimization (样本容量比较大的时候)
- \(\displaystyle \min_{f\in\mathcal{F}} \frac{1}{N}\sum_{i=1}^{N}L(y_{i},f(x_{i}))\)
- maximum likelihood estimation
- structural risk minimization
- regularization
- \(\displaystyle R_{\mathrm{sm}}(f)=\frac{1}{N}\sum_{i=1}^{N}L(y_{i},f(x_{i}))+\lambda J(f)\)
- 复杂度表示了对复杂模型的乘法
- maximum posterior probability estimation
1.3.3 算法 ¶
1.4 模型评估与模型选择 ¶
1.4.1 训练误差与测试误差 ¶
\[ R_{\mathrm{emp}}(\hat{f})=\frac{1}{N}\sum_{i=1}^{N}L(y_{i},\hat{f}(x_{i})) \] \[ e_{\mathrm{test}}=\frac{1}{N^{\prime}}\sum_{i=1}^{N^{\prime}}L(y_{i},\hat{f}(x_{i})) \] \[ r_{\mathrm{test}}+e_{\mathrm{test}}=1 \] - generalization ability
1.4.2 过拟合与模型选择 ¶
- model selection
- over-fitting
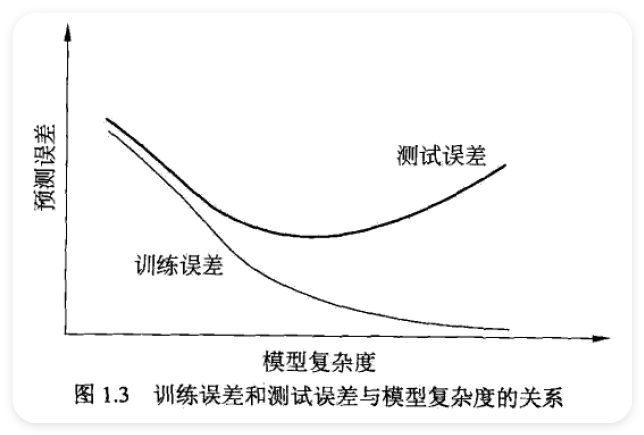
1.5 正则化与交叉验证 ¶
1.5.1 正则化 ¶
\[ L(w)=\frac{1}{N}\sum_{i=1}^{N}(f(x_{i};w)-y_{i})^{2}+\frac{\lambda}{2}\parallel w\parallel^{2} \] 1.5.2 交叉验证 ¶
- cross validation
- 数据集
- 训练集
- 验证集
- 测试集 1. 简单交叉验证 2. \(\displaystyle S\) 折交叉验证 3. 留一交叉验证
1.6 泛化能力 ¶
1.6.1 泛化误差 ¶
- generalization error
\[ R_{\exp}(\hat{f})=E_{P}[L(Y,\hat{f}(X))]=\int_{R\times y}L(y,\hat{f}(x))P(x,y)\mathrm{d}x\mathrm{d}y \] 1.6.2 泛化误差上界 ¶
- generalization error bound
- 样本容量增加时,泛化上界趋于 0
- 假设空间越大,泛化误差上界越大

- 这个定理只适用于假设空间包含有限个函数
1.7 生成模型与判别模型 ¶
- generative model
- 还原出联合概率分布 \(\displaystyle P(X,Y)\)
- 朴素贝叶斯法
- 隐马尔可夫模型
- 收敛速度快
- discriminative model
- 直接学习决策函数或条件概率分布 \(\displaystyle P(Y|X)\)
- \(\displaystyle k\) 近邻法
- 感知机
- 决策树
- 逻辑斯谛回归模型
- 最大熵模型
- 支持向量机
- 提升方法
- 条件随机场
- 准确度高
1.8 分类问题 ¶
- precision \(\displaystyle P=\frac{TP}{TP+FP}\)
- recall \(\displaystyle R=\frac{TP}{TP+FN}\)

\[ \frac{2}{F_{1}}=\frac{1}{P}+\frac{1}{R} \] \[ F_{1}=\frac{2TP}{2TP+FP+FN} \] - text classification
1.9 标注问题 ¶
- tagging 是 classificationd 一个推广
- 是 structure prediction 的简单形式
- 隐马尔可夫模型
- 条件随机场
1.10 回归问题 ¶
- regression
- (非)线性回归,一元回归,多元回归
2 感知机 ¶
- perception
- 感知机对应于输入空间中将实例划分成正负两类的分离超平面,属于判别模型
- 原始形式和对偶形式
2.1 感知机模型 ¶

- 假设空间是定义在特征空间中所有的线性分类模型(linear classification model)\(\displaystyle \{f|f(x) = w \cdot x+b\}\)
- separating hyperplane
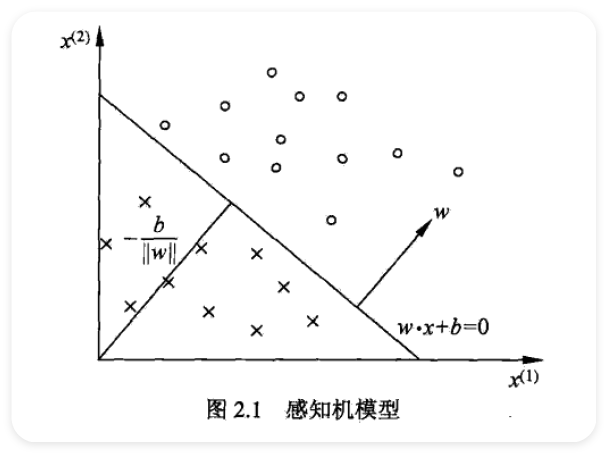
2.2 感知机学习策略 ¶
2.2.1 数据集的线性可分性 ¶

2.2.2 感知机学习策略 ¶
- 定义损失函数并将损失函数极小化
\[ L(w,b)=-\sum_{x_{i}\in M}y_{i}(w\cdot x_{i}+b) \] 2.2.3 感知机学习算法 ¶
2.2.4 感知机学习算法的原始形式 ¶
\[ \min_{w,b}L(w,b)=-\sum_{x_{i}\in M}y_{i}(w\cdot x_{i}+b) \] - stochastic gradient descent
\[ \nabla_{_w}L(w,b)=-\sum_{x_{i}\in M}y_{i}x_{i} \] \[ \nabla_{b}L(w,b)=-\sum_{x_{i}eM}y_{i} \] \[ w\leftarrow w+\eta y_{i}x_{i} \] \[ b\leftarrow b+\eta y_{i} \] - \(\displaystyle \eta\) 被称为学习率(learning rate)

2.2.5 算法的收敛性 ¶

- 为了得到唯一的超平面,需要对分离超平面增加约束条件,即线性支持向量机
- 如果训练集线性不可分,那么感知机学习算法不收敛
2.2.6 感知机学习算法的对偶形式 ¶
\[ \begin{aligned}&w\leftarrow w+\eta y_{i}x_{i}\\&b\leftarrow b+\eta y_{i}\end{aligned} \] \[ w=\sum_{i=1}^{N}\alpha_{i}y_{i}x_{i} \] \[ b=\sum_{i=1}^{N}\alpha_{i}y_{i} \] 

- Gram matrix
\[ G=[x_{i}\cdot x_{j}]_{N\times N} \] 3 \(\displaystyle k\) 近邻法 ¶
- k-nearest neighbor
3.1 \(\displaystyle k\) 近邻算法 ¶

3.2 \(\displaystyle k\) 近邻模型 ¶
3.2.1 模型 ¶
- cell
- class label
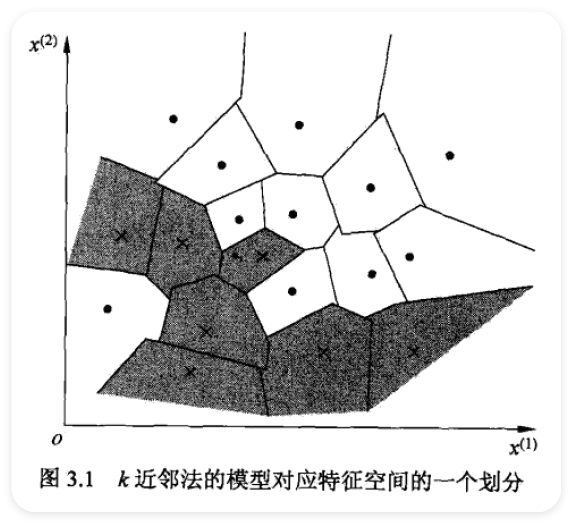
3.3 距离度量 ¶
- \(\displaystyle L_{p}\) distance or Minkowski distamce
- \(\displaystyle L_{p}(x_{i},x_{j})=\left(\sum_{l=1}^{n}\mid x_{i}^{(l)}-x_{j}^{(l)}\mid^{p}\right)^{\frac{1}{p}}\)
- \(\displaystyle L_{2}(x_{i},x_{j})=\left(\sum_{i=1}^{n}\mid x_{i}^{(l)}-x_{j}^{(l)}\mid^{2}\right)^{\frac{1}{2}}\)
- \(\displaystyle L_{1}(x_{i}, x_{j})=\sum_{l=1}^{n}\mid x_{i}^{(l)}-x_{j}^{(l)}\mid\)
- \(\displaystyle L_{\infty}(x_{i}, x_{j})=\max_{l}\mid x_{i}^{(l)}-x_{j}^{(l)}\mid\)
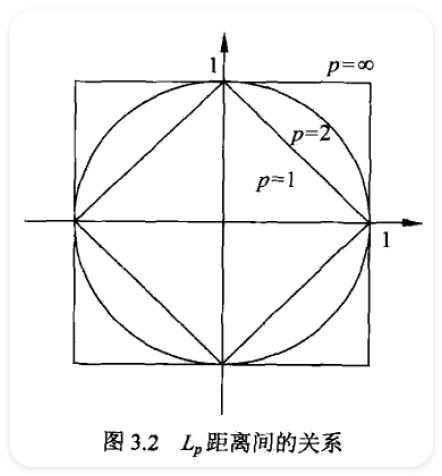
3.3.1 \(\displaystyle k\) 值的选择 ¶
- if k is small, then the approximation error will reduce
- estimation error
- \(\displaystyle k\) 值的减小就意味着整体模型变得复杂,容易发生过拟合
- 在应用中 , \(\displaystyle k\) 值一般取一个比较小的数值,通常采用交叉验证法来选取最优的 \(\displaystyle k\) 值
3.3.2 分类决策规则 ¶
- 多数表决规则(majority voting rule)

3.4 \(\displaystyle k\) 近邻法的实现 : \(\displaystyle kd\) 树 ¶
- linear scan
- kd tree
3.4.1 构造 \(\displaystyle kd\) 树 ¶
- \(\displaystyle kd\) 树是一二叉树,表示对 \(\displaystyle k\) 维空间的一个划分(partition)
- 通常选择训练实例点在选定坐标轴上的中位数为切分点,虽然这样得到的树是平衡的,但效率未必是最优的


有意思
3.4.2 搜索 \(\displaystyle kd\) 树 ¶


4 朴素贝叶斯法 ¶
- 基于贝叶斯定理与特征条件独立假设的分类方法
4.1 朴素贝叶斯法的学习与分类 ¶
4.1.1 基本方法 ¶
- 学习先验概率分布和条件概率分布于是学习到联合概率分布
\[ P(X=x\mid Y=c_{k})=P(X^{(1)}=x^{(1)},\cdots,X^{(n)}=x^{(n)}\mid Y=c_{k}),\quad k=1,2,\cdots,K \] - 引入了条件独立性假设
\[ \begin{aligned} P(X=x|Y=c_{k})& =P(X^{(1)}=x^{(1)},\cdots,X^{(n)}=x^{(n)}\mid Y=c_{k}) \\ &=\prod_{j=1}^{n}P(X^{(j)}=x^{(j)}\mid Y=c_{k}) \end{aligned} \] \[ P(Y=c_{k}\mid X=x)=\frac{P(X=x\mid Y=c_{k})P(Y=c_{k})}{\sum_{k}P(X=x\mid Y=c_{k})P(Y=c_{k})} \] \[ P(Y=c_{k}\mid X=x)=\frac{P(Y=c_{k})\prod_{j}P(X^{(j)}=x^{(j)}\mid Y=c_{k})}{\sum_{k}P(Y=c_{k})\prod_{j}P(X^{(j)}=x^{(j)}\mid Y=c_{k})},\quad k=1,2,\cdots,K \] \[ y=f(x)=\arg\max_{c_{k}}\frac{P(Y=c_{k})\prod_{j}P(X^{(j)}=x^{(j)}\mid Y=c_{k})}{\sum_{k}P(Y=c_{k})\prod_{j}P(X^{(j)}=x^{(j)}\mid Y=c_{k})} \] \[ y=\arg\max_{c_{k}}P(Y=c_{k})\prod_{j}P(X^{(j)}=x^{(j)}\mid Y=c_{k}) \] 4.1.2 后验概率最大化的含义 ¶
\[ L(Y,f(X))=\begin{cases}1,&Y\neq f(X)\\0,&Y=f(X)\end{cases} \] \[ R_{\exp}(f)=E[L(Y,f(X))] \] \[ R_{\exp}(f)=E_{\chi}\sum_{k=1}^{K}[L(c_{k},f(X))]P(c_{k}\mid X) \] \[ \begin{align} f(x) &=\arg\min_{y\in\mathcal{Y}}\sum_{k=1}^{K}L(c_{k},y)P(c_{k}\mid X=x) \\ &=\arg\min_{y\in\mathcal{Y}}\sum_{k=1}^{K}P(y\neq c_{k}\mid X=x) \\ &=\arg\min_{y\in\mathcal{Y}}(1-P(y=c_{k}\mid X=x)) \\ &=\arg\max_{y\in\mathcal{Y}}P(y=c_{k}\mid X=x) \end{align} \] \[ f(x)=\arg\max_{c_{k}}P(c_{k}\mid X=x) \] - 期望风险最小化准则就得到联考后验概率最大化准则
4.2 朴素贝叶斯法的参数估计 ¶
4.2.1 极大似然估计 ¶
\[ P(Y=c_{k})=\frac{\sum_{i=1}^{N}I(y_{i}=c_{k})}{N} , k=1,2,\cdots,K \] \[ P(X^{(j)}=a_{ji}\mid Y=c_{k})=\frac{\sum_{i=1}^{N}I(x_{i}^{(j)}=a_{ji},y_{i}=c_{k})}{\sum_{i=1}^{N}I(y_{i}=c_{k})}\\j=1,2,\cdots,n ;\quad l=1,2,\cdots,S_{j} ;\quad k=1,2,\cdots,K \] 4.2.2 学习与分类算法 ¶

4.2.3 贝叶斯估计 ¶
- 极大似然估计可能会出现所要估计的概率值为 0 的情况
- 条件概率的贝叶斯估计
\[ P_{\lambda}(X^{(j)}=a_{ji}\mid Y=c_{k})=\frac{\sum_{i=1}^{N}I(x_{i}^{(j)}=a_{ji},y_{i}=c_{k})+\lambda}{\sum_{i=1}^{N}I(y_{i}=c_{k})+S_{j}\lambda} \] - when \(\displaystyle \lambda = 0\), it's called Laplace smoothing
\[ \begin{aligned}&P_{\lambda}(X^{(j)}=a_{jl}\mid Y=c_{k})>0\\&\sum_{l=1}^{s_{j}}P(X^{(j)}=a_{jl}\mid Y=c_{k})=1\end{aligned} \] - 表明贝叶斯估计确实是一种概率分布
- 先验概率的贝叶斯估计
\[ P_{\lambda}(Y=c_{k})=\frac{\sum_{i=1}^{N}I(y_{i}=c_{k})+\lambda}{N+K\lambda} \] 5 决策树 ¶
- decision tree
- 特征选择
- 决策树的生成
- 决策树的修剪
5.1 决策树模型与学习 ¶
5.1.1 决策树模型 ¶

5.1.2 决策树与 if-then 规则 ¶
- 互斥且完备
- 每一个实例都被一条路径会规则所覆盖,而且只被一条路径或一条规则所覆盖
5.1.3 决策树与条件概率分布 ¶
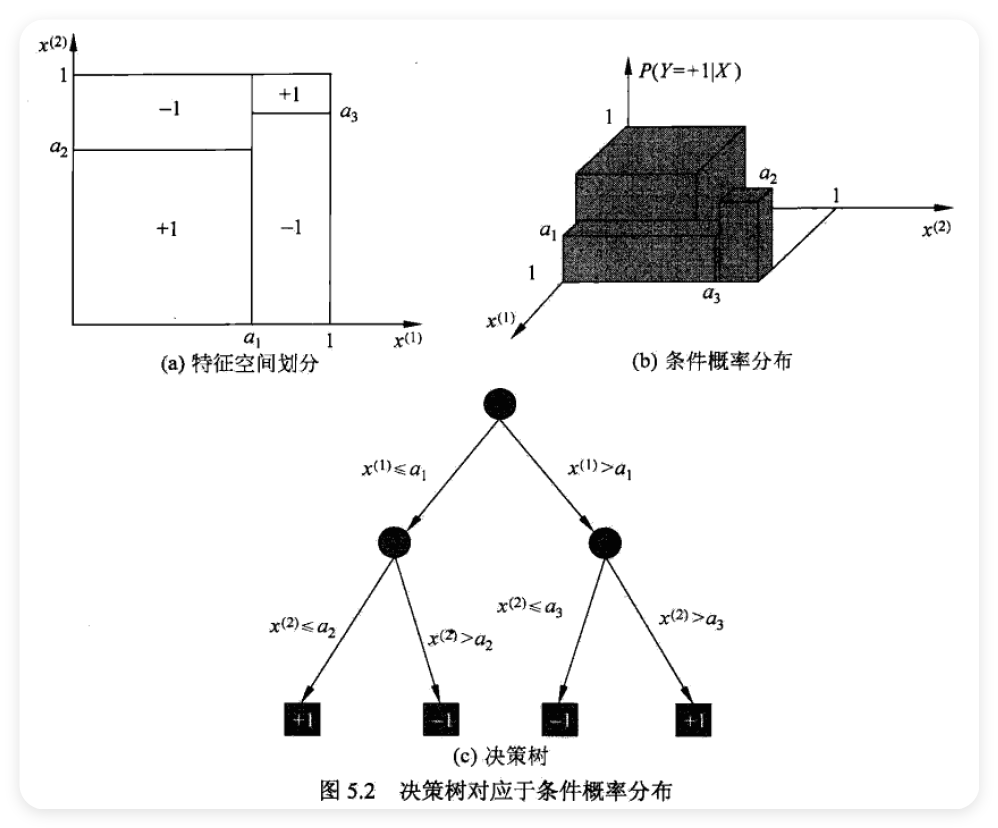
5.1.4 决策树学习 ¶
- 决策树学习本质上是从训练数据集中归纳出一组分类规则
- 在损失函数意义下选择最优决策树的问题,是 NP 完全问题,采用启发式方法,近似求解,这样得到的决策树是次最优(sub-optimal)
- 为了防止过拟合,我们需要对已生成的树自上而下进行剪枝
- 决策树的生成值考虑局部最优,剪枝则考虑全局最优
5.2 特征选择 ¶
5.2.1 特征选择问题 ¶
- 通常特征选择的准则是信息增益或信息增益比
- information gain
5.2.2 信息增益 ¶
- 熵和条件熵
\[ P(X=x_{i})=p_{i} ,\quad i=1,2,\cdots,n \] \[ H(X)=-\sum_{i=1}^{n}p_{i}\log p_{i} \] \[ H(p)=-\sum_{i=1}^{n}p_{i}\log p_{i} \] \[ 0\leqslant H(p)\leqslant\log n \] \[ P(X=x_{i},Y=y_{j})=p_{ij} ,\quad i=1,2,\cdots,n ;\quad j=1,2,\cdots,m \] \[ H(Y\mid X)=\sum_{i=1}^{n}p_{i}H(Y\mid X=x_{i}) \] 
- mutual information


5.2.3 信息增益比 ¶

5.3 决策树的生成 ¶
5.3.1 ID 3 算法 ¶


- ID 3 算法只有树的生成,所以该算法生成的树容易产生过拟合
5.3.2 C 4.5 的生成算法 ¶

5.4 决策树的剪枝 ¶
- pruning
\[ C_{\alpha}(T)=\sum_{t=1}^{|T|}N_{t}H_{t}(T)+\alpha|T| \] \[ H_{t}(T)=-\sum_{k}\frac{N_{ik}}{N_{t}}\log\frac{N_{ik}}{N_{t}} \] \[ C(T)=\sum_{t=1}^{|T|}N_{t}H_{t}(T)=-\sum_{t=1}^{|T|}\sum_{k=1}^{K}N_{tk}\log\frac{N_{tk}}{N_{t}} \] \[ C_{\alpha}(T)=C(T)+\alpha|T| \] 
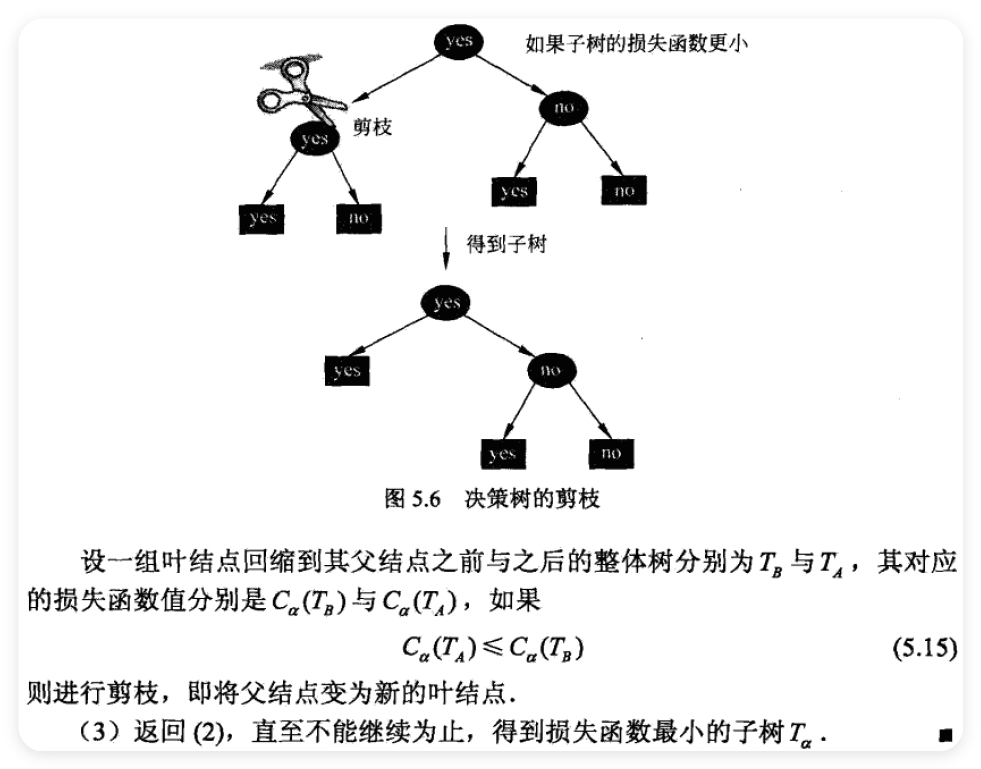
5.5 CART 算法 ¶
- 分裂与回归树(classification and regression tree)
5.5.1 CART 生成 ¶
- 对回归树用平方误差最小化准则
- 对分类树用基尼指数(Gini index)最小化准则 1. 回归树的生成
\[ f(x)=\sum_{m=1}^{M}c_{m}I(x\in R_{m}) \] \[ \hat{c}_{m}=\mathrm{ave}(y_{i}\mid x_{i}\in R_{m}) \] - splitting variable
- splitting point
\[ R_{1}(j,s)=\{x\mid x^{(j)}\leqslant s\}\quad\text{和}\quad R_{2}(j,s)=\{x\mid x^{(j)}>s\} \] \[ \min_{j,s}\biggl[\min_{c_{1}}\sum_{x_{i}\in R_{i}(j,s)}(y_{i}-c_{1})^{2}+\min_{c_{2}}\sum_{x_{i}\in R_{2}(j,s)}(y_{i}-c_{2})^{2}\biggr] \] \[ \hat{c}_{1}=\mathrm{ave}(y_{i}\mid x_{i}\in R_{1}(j,s))\quad\hat{\text{和}}\quad\hat{c}_{2}=\mathrm{ave}(y_{i}\mid x_{i}\in R_{2}(j,s)) \] - least squares regression tree
 1. 分类树的生成
1. 分类树的生成

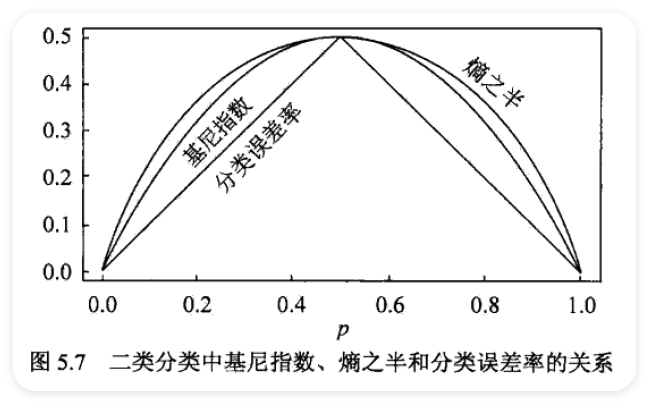

5.5.2 CART 剪枝 ¶
- 剪枝,形成一个子树序列
\[ C_{\alpha}(T)=C(T)+\alpha\left|T\right| \] \[ g(t)=\frac{C(t)-C(T_{t})}{\mid T_{t}\mid-1} \] - 在剪枝得到的子树序列 \(\displaystyle T_0,T_1,\cdots,T_n\) 中通过交叉验证选取最优子树 \(\displaystyle T_{\alpha}\)

6 逻辑斯谛回归与最大熵模型 ¶
- logistic regression
- maximum entropy model
- 逻辑斯谛回归模型和最大熵模型都属于对数线性模型
6.1 逻辑斯谛回归模型 ¶
6.1.1 逻辑斯谛分布 ¶
- logistic distribution

6.1.2 二项逻辑斯谛回归模型 ¶
- binomial logistic regression model

7 支持向量机 ¶
8 提升方法 ¶
9 \(\displaystyle \boldsymbol{EM}\) 算法及其推广 ¶
10 隐马尔可夫模型 ¶
11 条件随机场 ¶
wnc's café 统计学习方法 ¶
约 3356 个字 43 张图片 预计阅读时间 17 分钟 共被读过 次
1 统计学习方法概论 ¶
1.1 统计学习 ¶
- 统计学习的特点
- 以计算机及网络为平台
- 以数据为研究对象
- 目的是对数据进行预测与分析
- 交叉学科
- 统计学习的对象
- 是数据
- 统计学习的目的
- 统计学习的方法
- 主要有
- 监督学习(本书主要讨论)
- 非监督学习
- 半监督学习
- 强化学习
- 三要素
- 模型
- 策略
- 算法
- 实现步骤
- 得到一个训练数据集合
- 确定学习模型的集合
- 确定学习的策略
- 确定学习的算法
- 通过学习方法选择最优模型
- 利用学习的最优模型对新数据进行预测或分析
- 统计学习的研究
- 方法
- 理论
- 应用
- 统计学习的重要性
1.2 监督学习 ¶
1.2.1 基本概念 ¶
- 输入空间、特征空间与输出空间
- 每个输入是一个实例,通常由特征向量表示
- 监督学习从训练数据集合中学习模型,对测试数据进行预测
- 根据输入变量和输出变量的不同类型
- 回归问题 : 都连续
- 分类问题 : 输出有限离散
- 标注问题 : 都是变量序列
- 联合概率分布
- 假设空间
- 模型属于由输入空间到输出空间的映射的集合,这个集合就是假设空间
- 模型可以是(非)概率模型
1.2.2 问题的形式化 ¶
1.3 统计学习三要读 ¶
- 方法 = 模型 + 策略 + 算法
1.3.1 模型 ¶
- 模型就是索要学习的条件概率分布或决策函数
\[ \mathcal{F}=\{f\mid Y=f(X)\} \] - 参数空间
\[ \mathcal{F}=\{f | Y=f_{\theta}(X),\theta\in\mathbf{R}^{n}\} \] - 同样可以定义为条件概率的集合
\[ \mathcal{F}=\{P|P(Y|X)\} \] \[ \mathcal{F}=\{P\mid P_{\theta}(Y\mid X),\theta\in\mathbf{R}^{n}\} \] 1.3.2 策略 ¶
- 损失函数和风险函数
- loos function or cost function \(\displaystyle L(Y,f(X))\)
- 0-1 loss function
- \(\displaystyle L(Y,f(X))=\begin{cases}1,&Y\neq f(X)\\0,&Y=f(X)\end{cases}\)
- quadratic loss function
- \(\displaystyle L(Y,f(X))=(Y-f(X))^{2}\)
- absolute loss function
- \(\displaystyle L(Y,f(X))=|Y-f(X)|\)
- logarithmic loss function or log-likelihood loss function
- \(\displaystyle L(Y,P(Y\mid X))=-\log P(Y\mid X)\)
- \(\displaystyle R_{\exp}(f)=E_{P}[L(Y,f(X))]=\int_{x\times y}L(y,f(x))P(x,y)\mathrm{d}x\mathrm{d}y\)
- risk function or expected loss
- 但是联合分布位置,所以要学习,但是这样以来风险最小又要用到联合分布,那么这就成为了病态问题 (ill-formed problem)
- empirical risk or empirical loss
- \(\displaystyle R_{\mathrm{emp}}(f)=\frac{1}{N}\sum_{i=1}^{N}L(y_{i},f(x_{i}))\)
- 当 \(\displaystyle N\) 趋于无穷时,经验风险趋于期望风险
- 这就关系到两个基本策略 :
- 经验风险最小化
- 结构风险最小化
- 经验风险最小化与结构风险最小化
- empirical risk minimization (样本容量比较大的时候)
- \(\displaystyle \min_{f\in\mathcal{F}} \frac{1}{N}\sum_{i=1}^{N}L(y_{i},f(x_{i}))\)
- maximum likelihood estimation
- structural risk minimization
- regularization
- \(\displaystyle R_{\mathrm{sm}}(f)=\frac{1}{N}\sum_{i=1}^{N}L(y_{i},f(x_{i}))+\lambda J(f)\)
- 复杂度表示了对复杂模型的乘法
- maximum posterior probability estimation
1.3.3 算法 ¶
1.4 模型评估与模型选择 ¶
1.4.1 训练误差与测试误差 ¶
\[ R_{\mathrm{emp}}(\hat{f})=\frac{1}{N}\sum_{i=1}^{N}L(y_{i},\hat{f}(x_{i})) \] \[ e_{\mathrm{test}}=\frac{1}{N^{\prime}}\sum_{i=1}^{N^{\prime}}L(y_{i},\hat{f}(x_{i})) \] \[ r_{\mathrm{test}}+e_{\mathrm{test}}=1 \] - generalization ability
1.4.2 过拟合与模型选择 ¶
- model selection
- over-fitting
1.5 正则化与交叉验证 ¶
1.5.1 正则化 ¶
\[ L(w)=\frac{1}{N}\sum_{i=1}^{N}(f(x_{i};w)-y_{i})^{2}+\frac{\lambda}{2}\parallel w\parallel^{2} \] 1.5.2 交叉验证 ¶
- cross validation
- 数据集
- 训练集
- 验证集
- 测试集 1. 简单交叉验证 2. \(\displaystyle S\) 折交叉验证 3. 留一交叉验证
1.6 泛化能力 ¶
1.6.1 泛化误差 ¶
- generalization error
\[ R_{\exp}(\hat{f})=E_{P}[L(Y,\hat{f}(X))]=\int_{R\times y}L(y,\hat{f}(x))P(x,y)\mathrm{d}x\mathrm{d}y \] 1.6.2 泛化误差上界 ¶
- generalization error bound
- 样本容量增加时,泛化上界趋于 0
- 假设空间越大,泛化误差上界越大
- 这个定理只适用于假设空间包含有限个函数
1.7 生成模型与判别模型 ¶
- generative model
- 还原出联合概率分布 \(\displaystyle P(X,Y)\)
- 朴素贝叶斯法
- 隐马尔可夫模型
- 收敛速度快
- discriminative model
- 直接学习决策函数或条件概率分布 \(\displaystyle P(Y|X)\)
- \(\displaystyle k\) 近邻法
- 感知机
- 决策树
- 逻辑斯谛回归模型
- 最大熵模型
- 支持向量机
- 提升方法
- 条件随机场
- 准确度高
1.8 分类问题 ¶
- precision \(\displaystyle P=\frac{TP}{TP+FP}\)
- recall \(\displaystyle R=\frac{TP}{TP+FN}\)
\[ \frac{2}{F_{1}}=\frac{1}{P}+\frac{1}{R} \] \[ F_{1}=\frac{2TP}{2TP+FP+FN} \] - text classification
1.9 标注问题 ¶
- tagging 是 classificationd 一个推广
- 是 structure prediction 的简单形式
- 隐马尔可夫模型
- 条件随机场
1.10 回归问题 ¶
- regression
- (非)线性回归,一元回归,多元回归
2 感知机 ¶
- perception
- 感知机对应于输入空间中将实例划分成正负两类的分离超平面,属于判别模型
- 原始形式和对偶形式
2.1 感知机模型 ¶
- 假设空间是定义在特征空间中所有的线性分类模型(linear classification model)\(\displaystyle \{f|f(x) = w \cdot x+b\}\)
- separating hyperplane
2.2 感知机学习策略 ¶
2.2.1 数据集的线性可分性 ¶
2.2.2 感知机学习策略 ¶
- 定义损失函数并将损失函数极小化
\[ L(w,b)=-\sum_{x_{i}\in M}y_{i}(w\cdot x_{i}+b) \] 2.2.3 感知机学习算法 ¶
2.2.4 感知机学习算法的原始形式 ¶
\[ \min_{w,b}L(w,b)=-\sum_{x_{i}\in M}y_{i}(w\cdot x_{i}+b) \] - stochastic gradient descent
\[ \nabla_{_w}L(w,b)=-\sum_{x_{i}\in M}y_{i}x_{i} \] \[ \nabla_{b}L(w,b)=-\sum_{x_{i}eM}y_{i} \] \[ w\leftarrow w+\eta y_{i}x_{i} \] \[ b\leftarrow b+\eta y_{i} \] - \(\displaystyle \eta\) 被称为学习率(learning rate)
2.2.5 算法的收敛性 ¶
- 为了得到唯一的超平面,需要对分离超平面增加约束条件,即线性支持向量机
- 如果训练集线性不可分,那么感知机学习算法不收敛
2.2.6 感知机学习算法的对偶形式 ¶
\[ \begin{aligned}&w\leftarrow w+\eta y_{i}x_{i}\\&b\leftarrow b+\eta y_{i}\end{aligned} \] \[ w=\sum_{i=1}^{N}\alpha_{i}y_{i}x_{i} \] \[ b=\sum_{i=1}^{N}\alpha_{i}y_{i} \]
- Gram matrix
\[ G=[x_{i}\cdot x_{j}]_{N\times N} \] 3 \(\displaystyle k\) 近邻法 ¶
- k-nearest neighbor
3.1 \(\displaystyle k\) 近邻算法 ¶
3.2 \(\displaystyle k\) 近邻模型 ¶
3.2.1 模型 ¶
- cell
- class label
3.3 距离度量 ¶
- \(\displaystyle L_{p}\) distance or Minkowski distamce
- \(\displaystyle L_{p}(x_{i},x_{j})=\left(\sum_{l=1}^{n}\mid x_{i}^{(l)}-x_{j}^{(l)}\mid^{p}\right)^{\frac{1}{p}}\)
- \(\displaystyle L_{2}(x_{i},x_{j})=\left(\sum_{i=1}^{n}\mid x_{i}^{(l)}-x_{j}^{(l)}\mid^{2}\right)^{\frac{1}{2}}\)
- \(\displaystyle L_{1}(x_{i}, x_{j})=\sum_{l=1}^{n}\mid x_{i}^{(l)}-x_{j}^{(l)}\mid\)
- \(\displaystyle L_{\infty}(x_{i}, x_{j})=\max_{l}\mid x_{i}^{(l)}-x_{j}^{(l)}\mid\)
3.3.1 \(\displaystyle k\) 值的选择 ¶
- if k is small, then the approximation error will reduce
- estimation error
- \(\displaystyle k\) 值的减小就意味着整体模型变得复杂,容易发生过拟合
- 在应用中 , \(\displaystyle k\) 值一般取一个比较小的数值,通常采用交叉验证法来选取最优的 \(\displaystyle k\) 值
3.3.2 分类决策规则 ¶
- 多数表决规则(majority voting rule)
3.4 \(\displaystyle k\) 近邻法的实现 : \(\displaystyle kd\) 树 ¶
- linear scan
- kd tree
3.4.1 构造 \(\displaystyle kd\) 树 ¶
- \(\displaystyle kd\) 树是一二叉树,表示对 \(\displaystyle k\) 维空间的一个划分(partition)
- 通常选择训练实例点在选定坐标轴上的中位数为切分点,虽然这样得到的树是平衡的,但效率未必是最优的
有意思
3.4.2 搜索 \(\displaystyle kd\) 树 ¶
4 朴素贝叶斯法 ¶
- 基于贝叶斯定理与特征条件独立假设的分类方法
4.1 朴素贝叶斯法的学习与分类 ¶
4.1.1 基本方法 ¶
- 学习先验概率分布和条件概率分布于是学习到联合概率分布
\[ P(X=x\mid Y=c_{k})=P(X^{(1)}=x^{(1)},\cdots,X^{(n)}=x^{(n)}\mid Y=c_{k}),\quad k=1,2,\cdots,K \] - 引入了条件独立性假设
\[ \begin{aligned} P(X=x|Y=c_{k})& =P(X^{(1)}=x^{(1)},\cdots,X^{(n)}=x^{(n)}\mid Y=c_{k}) \\ &=\prod_{j=1}^{n}P(X^{(j)}=x^{(j)}\mid Y=c_{k}) \end{aligned} \] \[ P(Y=c_{k}\mid X=x)=\frac{P(X=x\mid Y=c_{k})P(Y=c_{k})}{\sum_{k}P(X=x\mid Y=c_{k})P(Y=c_{k})} \] \[ P(Y=c_{k}\mid X=x)=\frac{P(Y=c_{k})\prod_{j}P(X^{(j)}=x^{(j)}\mid Y=c_{k})}{\sum_{k}P(Y=c_{k})\prod_{j}P(X^{(j)}=x^{(j)}\mid Y=c_{k})},\quad k=1,2,\cdots,K \] \[ y=f(x)=\arg\max_{c_{k}}\frac{P(Y=c_{k})\prod_{j}P(X^{(j)}=x^{(j)}\mid Y=c_{k})}{\sum_{k}P(Y=c_{k})\prod_{j}P(X^{(j)}=x^{(j)}\mid Y=c_{k})} \] \[ y=\arg\max_{c_{k}}P(Y=c_{k})\prod_{j}P(X^{(j)}=x^{(j)}\mid Y=c_{k}) \] 4.1.2 后验概率最大化的含义 ¶
\[ L(Y,f(X))=\begin{cases}1,&Y\neq f(X)\\0,&Y=f(X)\end{cases} \] \[ R_{\exp}(f)=E[L(Y,f(X))] \] \[ R_{\exp}(f)=E_{\chi}\sum_{k=1}^{K}[L(c_{k},f(X))]P(c_{k}\mid X) \] \[ \begin{align} f(x) &=\arg\min_{y\in\mathcal{Y}}\sum_{k=1}^{K}L(c_{k},y)P(c_{k}\mid X=x) \\ &=\arg\min_{y\in\mathcal{Y}}\sum_{k=1}^{K}P(y\neq c_{k}\mid X=x) \\ &=\arg\min_{y\in\mathcal{Y}}(1-P(y=c_{k}\mid X=x)) \\ &=\arg\max_{y\in\mathcal{Y}}P(y=c_{k}\mid X=x) \end{align} \] \[ f(x)=\arg\max_{c_{k}}P(c_{k}\mid X=x) \] - 期望风险最小化准则就得到联考后验概率最大化准则
4.2 朴素贝叶斯法的参数估计 ¶
4.2.1 极大似然估计 ¶
\[ P(Y=c_{k})=\frac{\sum_{i=1}^{N}I(y_{i}=c_{k})}{N} , k=1,2,\cdots,K \] \[ P(X^{(j)}=a_{ji}\mid Y=c_{k})=\frac{\sum_{i=1}^{N}I(x_{i}^{(j)}=a_{ji},y_{i}=c_{k})}{\sum_{i=1}^{N}I(y_{i}=c_{k})}\\j=1,2,\cdots,n ;\quad l=1,2,\cdots,S_{j} ;\quad k=1,2,\cdots,K \] 4.2.2 学习与分类算法 ¶
4.2.3 贝叶斯估计 ¶
- 极大似然估计可能会出现所要估计的概率值为 0 的情况
- 条件概率的贝叶斯估计
\[ P_{\lambda}(X^{(j)}=a_{ji}\mid Y=c_{k})=\frac{\sum_{i=1}^{N}I(x_{i}^{(j)}=a_{ji},y_{i}=c_{k})+\lambda}{\sum_{i=1}^{N}I(y_{i}=c_{k})+S_{j}\lambda} \] - when \(\displaystyle \lambda = 0\), it's called Laplace smoothing
\[ \begin{aligned}&P_{\lambda}(X^{(j)}=a_{jl}\mid Y=c_{k})>0\\&\sum_{l=1}^{s_{j}}P(X^{(j)}=a_{jl}\mid Y=c_{k})=1\end{aligned} \] - 表明贝叶斯估计确实是一种概率分布
- 先验概率的贝叶斯估计
\[ P_{\lambda}(Y=c_{k})=\frac{\sum_{i=1}^{N}I(y_{i}=c_{k})+\lambda}{N+K\lambda} \] 5 决策树 ¶
- decision tree
- 特征选择
- 决策树的生成
- 决策树的修剪
5.1 决策树模型与学习 ¶
5.1.1 决策树模型 ¶
5.1.2 决策树与 if-then 规则 ¶
- 互斥且完备
- 每一个实例都被一条路径会规则所覆盖,而且只被一条路径或一条规则所覆盖
5.1.3 决策树与条件概率分布 ¶
5.1.4 决策树学习 ¶
- 决策树学习本质上是从训练数据集中归纳出一组分类规则
- 在损失函数意义下选择最优决策树的问题,是 NP 完全问题,采用启发式方法,近似求解,这样得到的决策树是次最优(sub-optimal)
- 为了防止过拟合,我们需要对已生成的树自上而下进行剪枝
- 决策树的生成值考虑局部最优,剪枝则考虑全局最优
5.2 特征选择 ¶
5.2.1 特征选择问题 ¶
- 通常特征选择的准则是信息增益或信息增益比
- information gain
5.2.2 信息增益 ¶
- 熵和条件熵
\[ P(X=x_{i})=p_{i} ,\quad i=1,2,\cdots,n \] \[ H(X)=-\sum_{i=1}^{n}p_{i}\log p_{i} \] \[ H(p)=-\sum_{i=1}^{n}p_{i}\log p_{i} \] \[ 0\leqslant H(p)\leqslant\log n \] \[ P(X=x_{i},Y=y_{j})=p_{ij} ,\quad i=1,2,\cdots,n ;\quad j=1,2,\cdots,m \] \[ H(Y\mid X)=\sum_{i=1}^{n}p_{i}H(Y\mid X=x_{i}) \]
- mutual information
5.2.3 信息增益比 ¶
5.3 决策树的生成 ¶
5.3.1 ID 3 算法 ¶
- ID 3 算法只有树的生成,所以该算法生成的树容易产生过拟合
5.3.2 C 4.5 的生成算法 ¶
5.4 决策树的剪枝 ¶
- pruning
\[ C_{\alpha}(T)=\sum_{t=1}^{|T|}N_{t}H_{t}(T)+\alpha|T| \] \[ H_{t}(T)=-\sum_{k}\frac{N_{ik}}{N_{t}}\log\frac{N_{ik}}{N_{t}} \] \[ C(T)=\sum_{t=1}^{|T|}N_{t}H_{t}(T)=-\sum_{t=1}^{|T|}\sum_{k=1}^{K}N_{tk}\log\frac{N_{tk}}{N_{t}} \] \[ C_{\alpha}(T)=C(T)+\alpha|T| \]
5.5 CART 算法 ¶
- 分裂与回归树(classification and regression tree)
5.5.1 CART 生成 ¶
- 对回归树用平方误差最小化准则
- 对分类树用基尼指数(Gini index)最小化准则 1. 回归树的生成
\[ f(x)=\sum_{m=1}^{M}c_{m}I(x\in R_{m}) \] \[ \hat{c}_{m}=\mathrm{ave}(y_{i}\mid x_{i}\in R_{m}) \] - splitting variable
- splitting point
\[ R_{1}(j,s)=\{x\mid x^{(j)}\leqslant s\}\quad\text{和}\quad R_{2}(j,s)=\{x\mid x^{(j)}>s\} \] \[ \min_{j,s}\biggl[\min_{c_{1}}\sum_{x_{i}\in R_{i}(j,s)}(y_{i}-c_{1})^{2}+\min_{c_{2}}\sum_{x_{i}\in R_{2}(j,s)}(y_{i}-c_{2})^{2}\biggr] \] \[ \hat{c}_{1}=\mathrm{ave}(y_{i}\mid x_{i}\in R_{1}(j,s))\quad\hat{\text{和}}\quad\hat{c}_{2}=\mathrm{ave}(y_{i}\mid x_{i}\in R_{2}(j,s)) \] - least squares regression tree
1. 分类树的生成
5.5.2 CART 剪枝 ¶
- 剪枝,形成一个子树序列
\[ C_{\alpha}(T)=C(T)+\alpha\left|T\right| \] \[ g(t)=\frac{C(t)-C(T_{t})}{\mid T_{t}\mid-1} \] - 在剪枝得到的子树序列 \(\displaystyle T_0,T_1,\cdots,T_n\) 中通过交叉验证选取最优子树 \(\displaystyle T_{\alpha}\)
6 逻辑斯谛回归与最大熵模型 ¶
- logistic regression
- maximum entropy model
- 逻辑斯谛回归模型和最大熵模型都属于对数线性模型
6.1 逻辑斯谛回归模型 ¶
6.1.1 逻辑斯谛分布 ¶
- logistic distribution
6.1.2 二项逻辑斯谛回归模型 ¶
- binomial logistic regression model
7 支持向量机 ¶
8 提升方法 ¶
9 \(\displaystyle \boldsymbol{EM}\) 算法及其推广 ¶
10 隐马尔可夫模型 ¶
11 条件随机场 ¶
wnc's café Archives¶
Archives¶
近期的一些想法
Published at: 1/20/25, 2:34 AM 一些 AI 与个人学习的思考
Published at: 1/2/25, 6:43 AM FreeSplatter 代码解读
Published at: 1/2/25, 5:22 AM Gaussian_Splatting_Code
Published at: 1/1/25, 4:11 AM Gaussian Splatting 复现
Published at: 12/31/24, 1:11 PM 工作规律
Published at: 12/29/24, 6:35 AM ULIP-2: Towards Scalable Multimodal Pre-training for 3D Understanding
Published at: 12/28/24, 7:08 AM Beyond Object Recognition: A New Benchmark towards Object Concept Learning
Published at: 12/24/24, 1:04 PM 信息
Published at: 12/21/24, 9:21 AM Total 9 posts.