-
Notifications
You must be signed in to change notification settings - Fork 0
/
Copy path04-developper-fr.Rmd
419 lines (253 loc) · 28.6 KB
/
04-developper-fr.Rmd
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
# Développer {#developper-fr}
## Directives
Ce guide est conçu pour aider les équipes de développement lors de la création et de la modification du contenu des ateliers R du CSBQ. Nous voulons nous assurer que les personnes qui assistent aux ateliers peuvent se concentrer sur le contenu présenté sans distraction par des questions de style, de grammaire, de ponctuation et/ou de structure.
Veuillez lire attentivement ce guide avant de commencer et vous y référer régulièrement pendant votre travail.
### Principales priorités
Nous avons établi ici une liste de priorités pour les personnes qui souhaitent contribuer aux ateliers `R`. L'idéal serait que les équipes de développement accomplissent toutes ces tâches, mais si les circonstances rendent cela impossible, il est important de se concentrer sur les changements structurels avant les questions de style.
>Une version de cette liste sous forme de liste de contrôle a été ouverte en tant que besoin dans le dépôt [GitHub](https://github.com/QCBSRworkshops) pour chaque atelier respectif. Nous vous suggérons d'utiliser ces listes de contrôle comme un moyen de suivre votre progression tout en travaillant et en vous coordonnant avec votre collègue développeur, le cas échéant. Elles peuvent également être utilisées comme référence pour rapporter le travail accompli aux coordinateurs de la série d'ateliers R du CSBQ, ou pour demander des heures supplémentaires.
```{r, echo=FALSE}
# **Spécifique à l'adaptation des ateliers au cadre à distance:**
#
# 1. Les ateliers doivent s'adapter à un nouveau format de 3 heures (comprenant des exercices et une ou deux pauses de cinq minutes). Pour cela, vous pouvez cacher les diapositives des ateliers existants pour les adapter à ce format. Par exemple, vous pouvez masquer les exemples répétitifs, les diapositives non essentielles ou certaines des diapositives avancées supplémentaires qui sont incluses à la fin des ateliers. Nous sommes conscients que certains ateliers seront plus difficiles à raccourcir que d'autres; ce n'est pas un problème que les ateliers durent un peu plus de 3 heures pour garantir des informations précises et complètes. (*Utilisez votre jugement*).
#
# 2. **Ne supprimez pas les diapositives**. Pour cacher une diapositive pour l'instruction à distance, utilisez la balise `exclude: true`. Voir un exemple ci-dessous :
#
#```
#---
#exclude: true
#
# Titre de la diapositive : J'adore les statistiques !
#
### Contenu : Incroyable !
#---
#```
#
# 3. Développez de nouveaux exercices ou adaptez les exercices actuels pour mieux répondre au format d'atelier à distance et à l'utilisation des salles de discussion. Les exercices doivent être informatifs et attrayants. N'oubliez pas de prévoir et de laisser le temps nécessaire pour travailler sur les exercices et de poser des questions.
```
**Priorités générales:**
1. Traiter les problèmes existants soumis à GitHub, qui sont notés dans la section "Issues" du dépot GitHub.
2. S'assurer que le code fonctionne correctement et que le code correspond à la présentation de l'atelier. Continuez à vérifier cela au fur et à mesure que vous apportez des modifications.
3. S'assurer que les versions francophone et anglophone d'un atelier sont toutes les deux mises à jour et que le contenu est équivalent.
4. Les ateliers ne doivent pas contenir des fautes d'orthographe, de grammaire ou de ponctuation.
5. Veiller à ce que les diapositives des ateliers soient rédigées dans un style cohérent, ce qui facilite le déroulement des ateliers et la compréhension. Cela est particulièrement important lorsque l'on travaille en collaboration dans une équipe de développement.
6. Dans la mesure du possible, ajoutez des [*notes de présentation*](https://bookdown.org/yihui/rmarkdown/xaringan-format.html#xaringan-notes) aux diapositives que vous modifiez. Vous pouvez écrire des notes que vous pourrez lire vous-même en mode présentation quand vous appuyez sur le raccourci clavier `P`. Ces notes sont écrites sous trois points d'interrogation `???`, avant la fin d'une diapositive. Voir l'exemple ci-dessous :
```
---
Le contenu de cet atelier est essentiel.
???
Note : _Chantez cette diapositive_.
---
```
### Règles structurelles
1. Ne laissez pas le contenu des diapositives déborder de l'écran.
2. Le code utilisé pour générer un résultat (chiffre ou calcul) doit correspondre au code affiché.
3. Utilisez les cochettes de retour `` ` `` chaque fois que vous mentionnez une fonction, un objet ou un paquet dans votre prose.
4. Utilisez les trois dernières cases à cocher ` ``` ` pour séparer les morceaux de code de la prose.
5. Faites attention à la fluidité et aux distractions.
### Grammaire et style
1. Faites attention à la ponctuation, à l'orthographe et à la grammaire.
2. Faites votre mieux pour être clair et concis. Évitez les phrases trop longues.
3. Relisez l'atelier dans son intégralité pour vous assurer que le flux est bon.
4. N'hésitez pas à demander à votre pair en développement de réviser votre texte.
### Apprentissage active
Les ateliers doivent être interactifs et comprendre des exercices et des sondages. Nous présentons ci-dessous quelques exemples d'exercices, de modes d'apprentissage fondés sur des données probantes et de stratégies efficaces pour organiser des ateliers à distance.
Nous vous recommandons de prendre votre temps et de bien planifier l'élaboration des exercices. Veillez à ce que les objectifs de l'exercice soient en adéquation avec ceux de l'atelier.
> Rappelez-vous que tout ce qui est écrit dessous le `???` est une note pour la personne qui présente et n'apparaîtra donc pas dans la diapositive de présentation, mais apparaîtra dans la fenêtre du mode présentation.
#### Sondages simples
Voir ci-dessous quelques exemples de deux diapositives contenant un exercice suivi de leurs solutions.
**Exemple 1**
Contexte : Les personnes participant à l'atelier viennent d'apprendre quelles fonctions utiliser pour effectuer des comparaisons entre groupes dépendants et indépendants, et ont également été initiés à la vérification d'hypothèses unilatérales et bilatérales.
Objectif : évaluer les connaissances des personnes participant à l'atelier et les rendre plus confiantes dans le choix du test à deux échantillons approprié dans leur recherche.
Elaboré par : [Pedro Henrique P. Braga](mailto:ph.pereirabraga@gmail.com)
```
---
Nous souhaitons évaluer si nous trouvons plus d'acromanthules dans les zones boisées et ombragées par rapport aux zones ouvertes. Nous sommes allés sur le terrain et avons compté le nombre d'individus (variable : `abundance`) dans dix paysages forestiers et ouverts répartis de manière aléatoire (variable : `type_of_area`). Laquelle des fonctions suivantes serait appropriée pour tester notre hypothèse ?
1. `t.test(type_of_area, abundance, data = acromantula_experiment, alternative = "two.sided")`;
2. `t.test(type_of_area, abundance, data = acromantula_experiment, paired = TRUE, alternative = "two.sided").`
3. `t.test(type_of_area, abundance, data = acromantula_experiment, alternative = "one.sided")`;
???
Note : Pendant ce moment, un sondage doit être ouvert. Une fois que vous avez obtenu les réponses de votre public, montrez-leur la bonne réponse. Vous pouvez demander à quelqu'un d'expliquer sa réponse.
---
Nous souhaitons évaluer si nous trouvons plus d'acromanthules dans les zones boisées et ombragées par rapport aux zones ouvertes. Nous sommes allés sur le terrain et avons compté le nombre d'individus (variable : `abundance`) dans dix paysages forestiers et ouverts répartis de manière aléatoire (variable : `type_of_area`). Laquelle des fonctions suivantes serait appropriée pour tester notre hypothèse ?
1. `t.test(type_of_area, abundance, data = acromantula_experiment, alternative = "two.sided")`;
2. `t.test(type_of_area, abundance, data = acromantula_experiment, paired = TRUE, alternative = "two.sided").`
3. `t.test(type_of_area, abundance, data = acromantula_experiment, alternative = "one.sided")`; #<<
???
Note : Vous devez préciser la distinction entre les tests d'hypothèse bilatéraux et unilatéraux (i.e. one-sided and two-sided; dans le contexte du problème). En outre, vous devez également rappeler les différences entre les mesures dépendantes et indépendantes (en rapport avec l'argument `paired`).
---
```
**Exemple 2**
Contexte : Les personnes participant à l'atelier ont été initiés aux modèles linéaires généralisés, et viennent d'apprendre la distribution de Poisson, ses hypothèses selon lesquelles la variance est égale à la moyenne, et comment la sur-dispersion de leurs données peut être un problème lors de l'ajustement de ces modèles. Ils ont été initiés à la famille quasi-Poisson et à la possibilité d'appliquer une correction de sur-dispersion pour les données binaires avec l'objet de famille "quasibinomial".
Objectif : Évaluer la capacité à appliquer le concept de correction de la sur-dispersion à différents types de données, pour aider à mieux comprendre la relation entre les objets de famille et les fonctions de liaison, et pour renforcer l'idée que les modèles peuvent être mis à jour sans avoir à en créer de nouveaux.
Elaboré par : [Esteban Góngora](mailto:esteban.gongora@mail.mcgill.ca)
```
---
Nous avons maintenant réalisé que l'exemple de proportion pour les cerfs infectés peut avoir des problèmes de surdispersion (la variance augmente beaucoup plus vite que la moyenne). Laquelle des fonctions suivantes serait une mise à jour appropriée pour tenir compte de la surdispersion dans nos données sur les proportions ?
1. `prop.reg.quasi <- glm(prop.infected ~ res.avail, family = quasipoisson(link = "logit"), weights = n.total)` ;
2. `prop.reg.quasi <- glm(prop.infected ~ res.avail, famille = quasibinomial, poids = n.total)` ;
3.`prop.reg.quasi <- update(prop.reg2, family=quasibinomial(link = "logit"))` ;
???
Note : Pendant ce moment, un sondage devrait être ouvert. Une fois que vous avez obtenu les réponse de votre public, montrez-leur la bonne réponse. Vous pouvez demander à quelqu'un d'expliquer sa réponse.
---
Nous avons maintenant réalisé que l'exemple de proportion pour les cerfs infectés peut avoir des problèmes de surdispersion (la variance augmente beaucoup plus vite que la moyenne). Laquelle des fonctions suivantes serait une mise à jour appropriée pour tenir compte de la surdispersion dans nos données sur les proportions ?
1. `prop.reg.quasi <- glm(prop.infected ~ res.avail, family = quasipoisson(link = "logit"), weights = n.total)` ;
2. `prop.reg.quasi <- glm(prop.infected ~ res.avail, famille = quasibinomial, poids = n.total)` ;
3. `prop.reg.quasi <- update(prop.reg2, family=quasibinomial(link = "logit")) #<<` ;
???
Note : Vous pouvez maintenant expliquer que nous pouvons obtenir le modèle corrigé avec les options 2 et 3. Cependant, l'option 3 est le bon choix car vous aviez demandé de mettre à jour le modèle `prop.reg2`. Vous pouvez également rappeler que chaque distribution a une fonction de lien par défaut, donc l'utilisation de `family = quasibinomial` et `family=quasibinomial(link = "logit")` produira le même résultat que `logit` est la fonction de lien par défaut pour la distribution quasibinomiale.
---
```
#### Exercice de groupe
Le travail en petits groupes permet d'exploiter les forces de chaque membre du groupe et d'améliorer le succès du cadre collectif. Cet exercice exige un répartition au hasard de l'audience dans des salles de discussion (idéalement, 5 personnes par salle) et doit comprendre une activité se rapportant à un point de discussion. À la fin de cet exercice, les groupes sont reconvoqués et une personne de chaque salle de discussion doit faire un rapport et résumer la discussion. Cette activité doit durer environ 10 minutes (parfois moins si elle est très simple) et doit utiliser les informations qui ont été fournies pendant l'atelier.
Voir ci-dessous deux exemples de diapositives contenant un exercice suivi de sa solution :
**Exemple 1**
Contexte : Cet exercice doit être fourni pour préparer le terrain aux discussions lors d'un atelier de visualisation de données. Il n'exige pas une connaissance solide de la visualisation de données.
Objectif : Encourager la réflexion critique autour de la visualisation de données.
Élaboré par : [Pedro Henrique P. Braga](mailto:ph.pereirabraga@gmail.com)
```
---
Discussion de groupe : Vous trouverez ci-dessous trois graphiques compilés à partir d'un livre de visualisation (référence indiquée dans la diapositive suivante). Ouvrez et observez les tableaux et discutez avec votre groupe pour répondre aux questions suivantes :
(a) Quels problèmes voyez-vous dans chacun des tableaux ?
(b) Quelles sont les conséquences de ces problèmes que vous avez identifiés ?
(c) Que changeriez-vous dans chacun d'eux pour améliorer leur information ?
### Ajoutez ces images côte à côte.
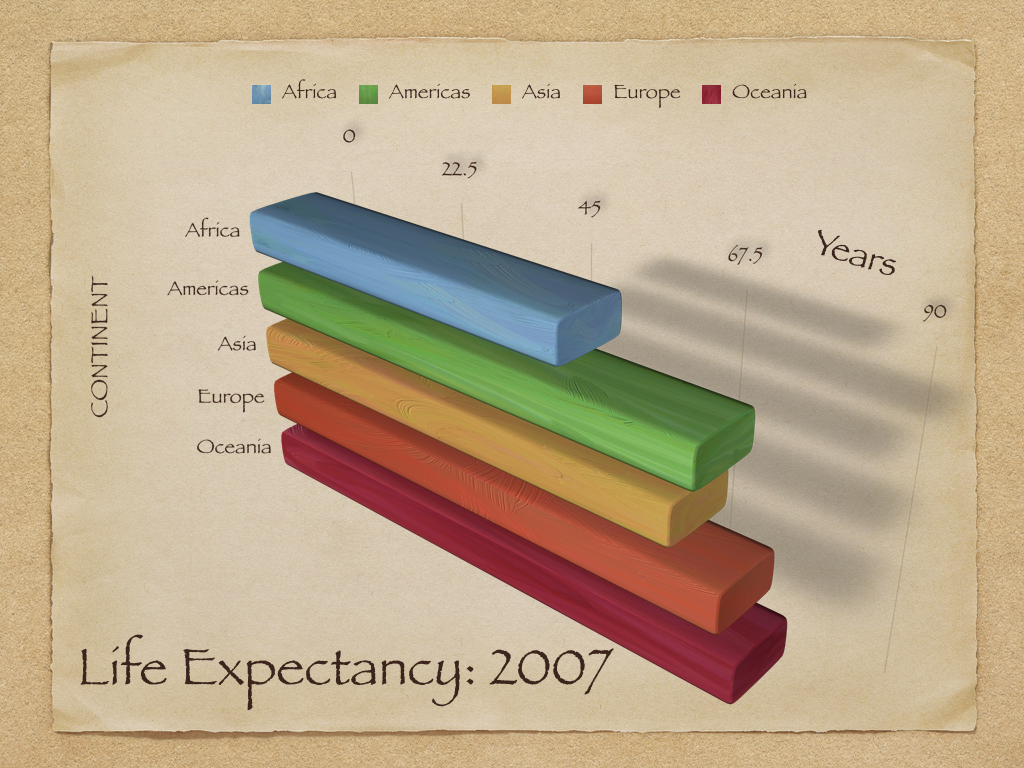
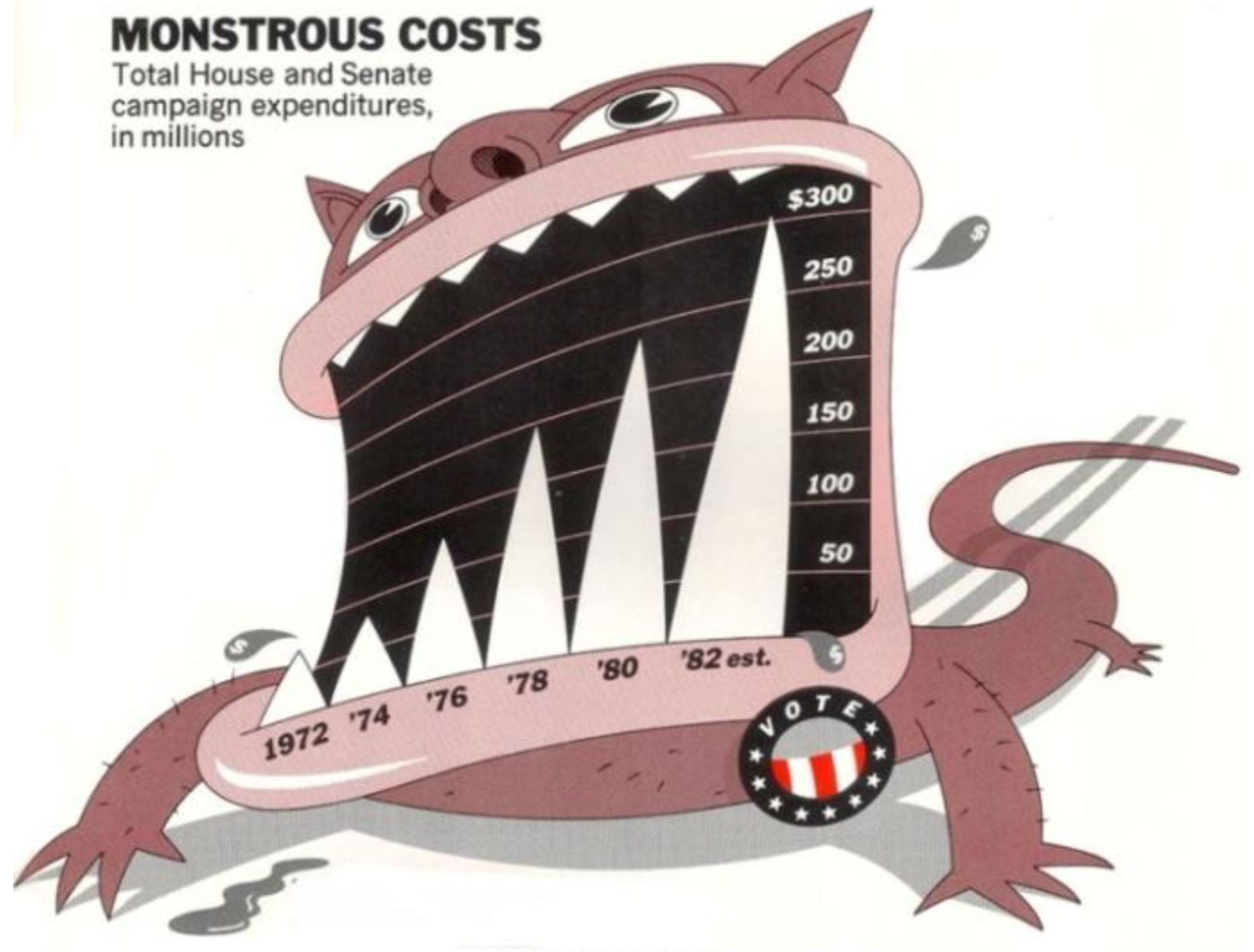
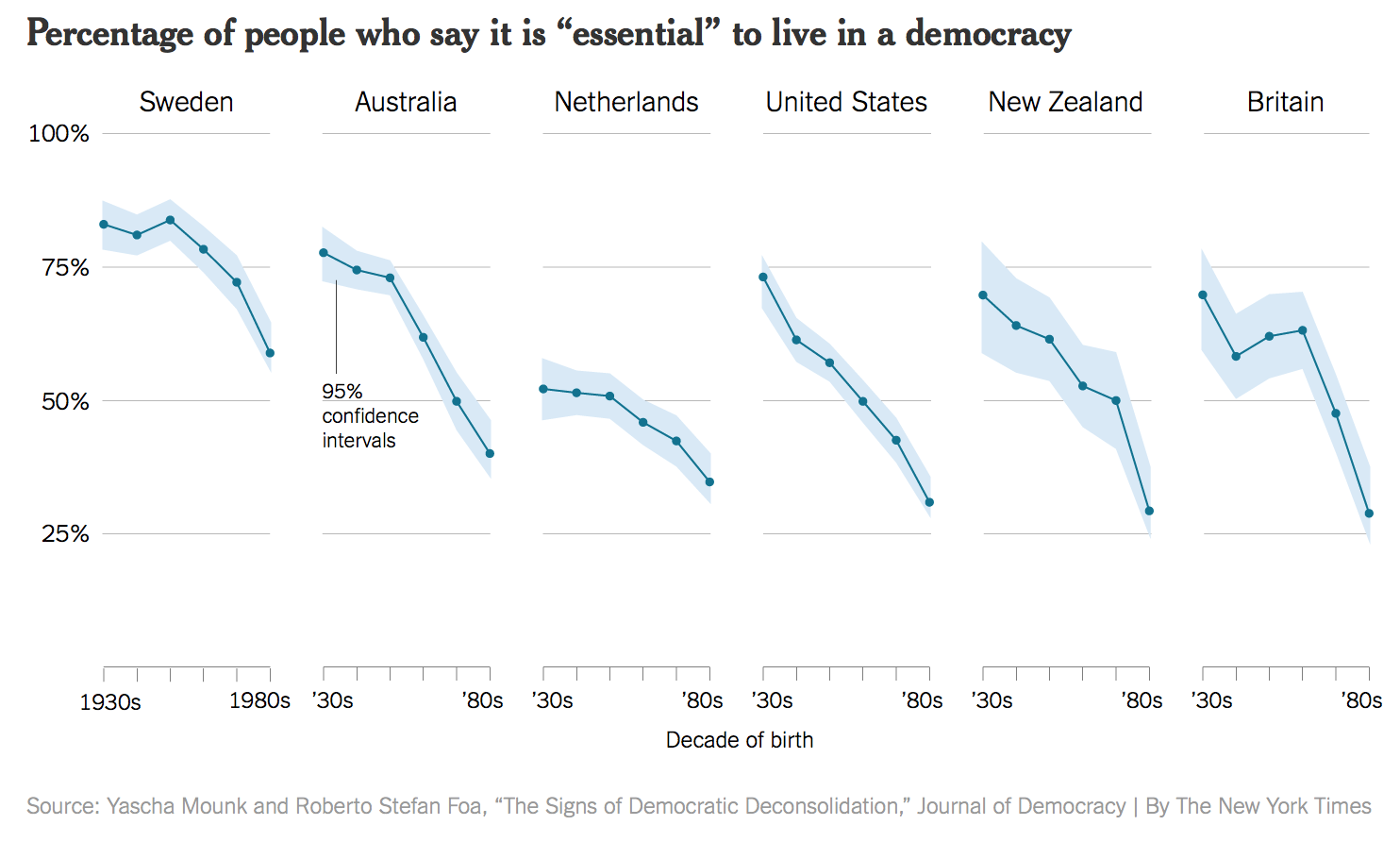
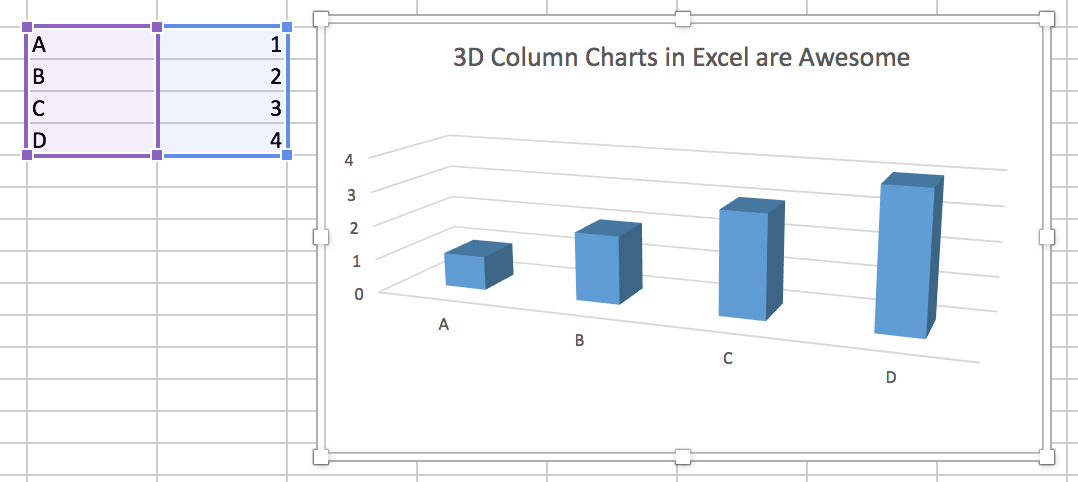
???
Note : Lisez clairement l'exercice. Demandez un résumé des réponses et qu'une personne doit ensuite faire un compte rendu de la discussion lorsque la classe est convoquée. Vous pouvez prévoir 5 à 8 minutes pour la discussion dans les salles de discussion (en fonction de la taille du groupe) car il s'agit d'un exemple très simple.
---
Discussion de groupe : Vous trouverez ci-dessous trois graphiques compilés à partir d'un (livre de visualisation) [https://socviz.co/lookatdata.html]. Ouvrez et observez les tableaux et discutez avec votre groupe pour répondre aux questions suivantes :
(a) Quels problèmes voyez-vous dans chacun des tableaux ?
(b) Quelles sont les conséquences de ces problèmes que vous avez identifiés ?
(b) Que changeriez-vous dans chacun d'eux pour améliorer leur information ?
### Afficher les images côte à côte

???
Note : Les chiffres en question ne sont pas seulement une question de mauvais goût (subjectif), mais ont des problèmes liés à la manière dont ils transmettent l'information. Dans cet exemple, le problème n'est pas dû à une différence dans la façon dont l'axe des y est dessiné. Il s'agit plutôt d'une mesure différente : nous examinons maintenant la tendance du score moyen, plutôt que la tendance de la réponse la plus élevée possible.
---
```
**Exemple 2**
Contexte : Les personnes qui participent viennent d'être initiés aux analyses multivariées, et viennent de voir le [tableau récapitulatif](http://r.qcbs.ca/workshop09/pres-fr/workshop09-pres-fr.html#141) des principales caractéristiques des ordinations sans contrainte.
Objectif : Permettre auxpersonnes qui participent d'appliquer de manière critique les informations présentées dans cet atelier en déterminant quel type d'étude/données correspondrait le mieux aux différents types d'ordinations.
Elaboré par : [Esteban Gongora Bernoske](mailto:esteban.gongora@mail.mcgill.ca)
```
---
Discussion de groupe : Chaque groupe se verra attribuer au hasard un type d'ordination. Vous discuterez au sein de votre groupe des types d'ensembles de données possibles qui correspondent le mieux au type d'ordination qui vous a été attribué. Chaque groupe présentera un exemple concret de projet/étude/expérience qui serait utilisé avec sa méthode d'ordination.
### Inclure le tableau récapitulatif pour référence.
)
???
Note : Lisez clairement l'exercice et attribuez à chaque salle de discussion un type d'ordination. Suggérez l'utlisation des caractéristiques du tableau récapitulatif pour trouver la réponse, puis une personne doit faire un compte rendu de la discussion lorsque la classe est convoquée en présentant l'exemple choisi et en mentionnant brièvement la raison pour laquelle elle l'a choisi. Vous pouvez prévoir 5 à 8 minutes pour la discussion dans les salles de discussion (en fonction de la taille du groupe). Pendant les discussions en sous-groupes, pensez à des exemples possibles que vous pourriez leur donner au cas où la discussion ne se déroulerait pas comme prévu (n'oubliez pas que c'est la fin de l'atelier et que votre public peut donc être déjà fatigué).
---
Discussion de groupe : Chaque groupe se verra attribuer au hasard un type d'ordination. Vous discuterez au sein de votre groupe des types d'ensembles de données possibles qui correspondent le mieux au type d'ordination qui vous a été attribué. Chaque groupe présentera un exemple concret de projet/étude/expérience qui serait utilisé avec sa méthode d'ordination.
### Inclure le tableau récapitulatif pour référence.
)
???
Note : Mentionnez quelques exemples ou utilisez les exercices présentés pendant l'atelier pour conclure la discussion.
---
```
#### Exercice individuel
Des exercices individuels simples demandent à chacun de pratiquer un peu par soi-même. En fonction de la difficulté des exercices, pensez à prévoir entre 5 et 10 minutes pour leur exécution.
Bien que ces exercices aident à assimiler le contenu, certaines personnes peuvent être moins motivées pour les exécuter (contrairement aux exercices de groupe). C'est pourquoi il faut envisager d'inclure d'autres types d'exercices en plus de ceux-ci.
À la fin de ces exercices, donnez l'occasion à une ou quelques personnes de présenter et de discuter leurs réponses.
Ci-dessous, nous pouvons voir un exemple d'exercice indépendant et sa solution :
Contexte : L'atelier vient d'aborder les familles de distribution, les fonctions de liens et des exemples du fonctionnement des fonctions `glm()` et `manyglm()`.
Objectif : Encourager l'observation les tracés de diagnostic lors du choix de modèle.
Élaboré par : [Pedro Henrique P. Braga](mailto:ph.pereirabraga@gmail.com).
```
---
Utilisez `manyglm()` pour estimer les réponses de la composition de la communauté d'acariens à toutes les variables environnementales associées à l'ensemble de données sur les `acariens`. Quelles familles d'erreurs (gaussiennes, de poisson ou binomiales négatives) correspondent le mieux aux données ?
N'oubliez pas de charger les bibliothèques `vegan` et `mvabund`, et d'utiliser `data(mite)` et `data(mite.env)` pour charger les ensembles de données.
Conseil : Souvenez-vous de ce que nous avons dit sur les hypothèses de modèle !
???
Note : L'objectif de cet exercice est de permettre d'écrire indépendamment les modèles, d'assigner les arguments appropriés liés aux familles de distribution et de réaliser qu'ils doivent tracer les résidus par rapport aux valeurs ajustées pour décider du meilleur modèle. Rappelez ce que les deux ensembles de données comprennent. Vous pouvez aider votre public à se rendre compte des arguments possibles en suggérant la fonction d'aide "?`". À la fin de cet exercice, invitez quelques personnes à partager leur réponse et demandez-leur comment ils l'ont obtenue.
---
Utilisez `manyglm()` pour estimer les réponses de la composition de la communauté d'acariens à toutes les variables environnementales associées à l'ensemble de données sur les `acariens`. Quelles familles d'erreurs (gaussiennes, de poisson ou binomiales négatives) correspondent le mieux aux données ?
Solution :
### À afficher à l'intérieur d'un bloc de code:
mitedat <- mvabund(mite)
mite.gaussian.glm <- manyglm(mitedat ~ SubsDens + WatrCont + Substrat + Arbuste + Topo, data = mite.env, family='gaussian')
mite.poisson.glm <- manyglm(mitedat ~ SubsDens + WatrCont + Substrat + Arbuste + Topo, data = mite.env, family='poisson')
mite.nb.glm <- manyglm(mitedat ~ SubsDens + WatrCont + Substrat + Arbuste + Topo, data = mite.env, family='negative.binomial')
# Afficher les tracés de diagnostic côte à côte :
par(mfrow=c(1,3))
plot(mite.gaussian.glm)
plot(mite.poisson.glm)
plot(mite.nb.glm)
### Fin de la partie du code
???
Note : Montrez clairement quels arguments ont changé entre les fonctions et ce qu'ils impliquent. Expliquez comment les hypothèses de distribution des résidus et des valeurs prédites doivent encore être satisfaites pour que les modèles soient considérés comme valables.
---
```
## Comment développer des ateliers
Cette section vous guide à travers le processus de contribution aux présentations des ateliers R du CSBQ.
### Pour commencer
Les ateliers R du CSBQ sont des présentations créées en utilisant [xaringan](https://bookdown.org/yihui/rmarkdown/xaringan.html), donc la première étape est d'installer la bibliotèque `R` `xaringan`.
```{r install-xaringan-fr, eval=FALSE}
if(!require(devtools)) install.packages('devtools')
devtools::install_github('yihui/xaringan')
```
Ensuite, vous devez créer une copie locale du répertoire de l'atelier sur lequel vous travaillerez, que vous trouverez [ici](https://github.com/QCBSRworkshops). Pour ce faire, vous pouvez [cloner le répertoire GitHub](https://help.github.com/articles/cloning-a-repository/) sur votre ordinateur.
Pour ce faire, vous pouvez utiliser la ligne de commande (plus de détails [ici](https://docs.github.com/en/free-pro-team@latest/github/creating-cloning-and-archiving-repositories/cloning-a-repository#cloning-a-repository-using-the-command-line)) :
```{bash, eval=FALSE}
git clone https://github.com/QCBSRworkshops/workshop01.git
# changez ce lien en fonction de l'atelier sur lequel vous travaillez !
```
Si vous n'êtes pas à l'aise avec la ligne de commande, vous pouvez cloner ce dépôt d'archives en utilisant [GitHub Desktop](https://desktop.github.com/), en suivant les instructions [ici](https://docs.github.com/en/free-pro-team@latest/github/creating-cloning-and-archiving-repositories/cloning-a-repository#cloning-a-repository-to-github-desktop).
Une fois que vous avez cloné le dépôt d'archives, vous êtes prêt à commencer le développement !
### Flux de travail GitHub
GitHub crée des dépôt d'archives avec une seule branche par défaut, nommée `dev` (si vous travaillez en ligne de commande) ou `main` (si vous travaillez dans GitHub Desktop). C'est la branche que vous voyez quand vous visitez le dépôt d'archives.
Nous vous recommandons fortement de travailler sur une **nouvelle branche**, qui vous permet de développer les ateliers sans affecter la branche principale du dépôt d'archives. Travailler sur une branche distincte signifie que les changements ne sont mis en œuvre dans le contenu original qu'une fois que vos contributions ont été examinées. C'est une façon "plus sécuritaire" de développer les ateliers, particulièrement lorsque plusieurs personnes collaborent sur un atelier en même temps.
1. **Créer et publier une nouvelle branche**. Choisissez un nom qui décrit explicitement ce que vous modifiez, *par exemple * `workshop1_intro` si vous travaillez sur l'introduction de l'atelier 1.
Sur la ligne de commande :
```{bash, eval=FALSE}
git branch workshop1_intro # créer une nouvelle branche
```
Github Desktop ([instructions ici](https://docs.github.com/en/free-pro-team@latest/desktop/contributing-and-collaborating-using-github-desktop/managing-branches#creating-a-branch)).
2. **Passer à cette branche**. Assurez-vous que vous travaillez sur votre nouvelle branche !
Sur la ligne de commande :
```{bash, eval = FALSE}
git checkout workshop1_intro # passer à cette branche
# Notez que vous pouvez créer et changer de branche en une seule ligne :
git checkout -b workshop1_intro
```
GitHub Desktop ([instructions ici](https://docs.github.com/en/free-pro-team@latest/desktop/contributing-and-collaborating-using-github-desktop/managing-branches#switching-between-branches)).
3. **Effectuez vos modifications**, en suivant les [lignes directrices](#directives) énumérées ci-dessus.
4. **Ajoutez et validez vos modifications**. Une fois que vous avez terminé de faire des changements sur votre branche, ajoutez-les et validez-les pour enregistrer ces changements. Lorsque vous validez des modifications, il est essentiel d'inclure un message de validation qui résume brièvement ce que vous avez fait. Soyez bref mais informatif !
Sur la ligne de commande :
```{bash, eval=FALSE}
git add -A # ajoutez tous vos changements
git commit -m "fix code for plot in Challenge 1" # commettez vos changements avec un message
```
Vous pouvez également utiliser GitHub Desktop pour ajouter des modifications ([instructions ici](https://docs.github.com/en/free-pro-team@latest/desktop/contributing-and-collaborating-using-github-desktop/committing-and-reviewing-changes-to-your-project#2-selecting-changes-to-include-in-a-commit)) et les valider ([instructions ici](https://docs. github.com/fr/free-pro-team@latest/desktop/contributing-and-collaborating-using-github-desktop/committing-and-reviewing-changes-to-your-project#3-write-a-commit-message-and-push-your-changes)).
5. **Synchronisez votre branche principale avec le référentiel distant**. Il est important de s'assurer que votre branche principale est à jour avant de la modifier. Retournez à la branche principale et récupérez les modifications qui ont été faites depuis la dernière copie du dépôt d'archives.
Tirez le `dev` sur la ligne de commande :
```{bash, eval=FALSE}
git checkout dev # retour à la branche principale
pull git # tirez les changements faits sur la branche principale
```
Tirez la branche `main` sur GitHub Desktop ([instructions ici](https://docs.github.com/en/free-pro-team@latest/desktop/contributing-and-collaborating-using-github-desktop/syncing-your-branche#pulling-to-your-local-branche-de-la-distance)).
6. **Fusionnez votre branche avec la branche principale locale**. Retournez à votre branche (par exemple `workshop1_intro`) et fusionnez-la avec votre branche principale locale. S'il y a des conflits, veuillez les résoudre !
Vous pouvez fusionner votre branche avec la branche `dev` en utilisant la ligne de commande :
```{bash, eval=FALSE}
git checkout workshop1_intro # retournez à votre branche
git merge dev # fusionner la branche principale avec votre branche
```
Fusionnez votre branche avec la branche `main` dans GitHub Desktop ([instructions ici](https://docs.github.com/en/free-pro-team@latest/desktop/contributing-and-collaborating-using-github-desktop/syncing-your-branch#merging-another-branch-into-your-projet-branch)).
7. **Poussez votre branche fusionnée localement vers le dépôt d'archives GitHub distant**.
En ligne de commande, vous pouvez pousser votre branche fusionnée localement (par exemple `workshop1_intro`) vers le dépôt d'archives distant comme ceci :
```{bash, eval=FALSE}
git push --set-upstream origin workshop1_intro # poussez vers le dépôt !
```
Poussez votre branche (par exemple `workshop1_intro`) vers le dépôt d'archives distant dans GitHub Desktop ([voir étape #4](https://docs.github.com/en/free-pro-team@latest/desktop/contributing-and-collaborating-using-github-desktop/syncing-your-branche#immergeant une autre branche dans votre branche-projet)).
8. **Ouvrez une [demande d'extraction](https://help.github.com/articles/about-pull-requests/)**.
Les *pull requests* ou demandes d'extraction sont un moyen de faire connaître à votre équipe de développement les changements que vous avez poussés vers une branche du dépôt Github. Une fois que vous avez ouvert une demande d'extraction, nous pouvons examiner les changements potentiels et ajouter des commandes de suivi (si nécessaire) avant que vos changements ne soient fusionnés dans la branche principale.
Pour ouvrir une demande d'extraction pour votre branche (par exemple `workshop1_intro`), veuillez suivre ces [instructions](https://docs.github.com/en/free-pro-team@latest/github/collaborating-with-issues-and-pull-requests/creating-a-pull-request#creating-the-pull-request).
9. **Assignez** votre demande d'extraction à l'équipe de coordination des ateliers R du CSBQ. Votre demande sera révisée et fusionnée avec le dépôt principal.
10. Une fois que la demande d'extraction est fusionnée, n'oubliez pas de **tirer la branche principale** !
Un guide visuel du flux de travail GitHub est aussi accessible [ici](https://guides.github.com/introduction/flow/).
## Contribuer autrement
Si vous n'êtes pas à l'aise avec GitHub, vous pouvez toujours nous aider à améliorer les ateliers !
Si vous trouvez des erreurs ou des incohérences, ou si vous souhaitez faire une suggestion, que ce soit sur la forme ou le contenu, vous êtes invités à ouvrir un [numéro](https://help.github.com/articles/about-issues/). Vous pouvez suivre ces étapes simples pour créer un nouveau [numéro](https://help.github.com/articles/creating-an-issue/).