{kind=link}
See https://proceedings.neurips.cc/paper/2020/file/ee23e7ad9b473ad072d57aaa9b2a5222-Paper.pdf
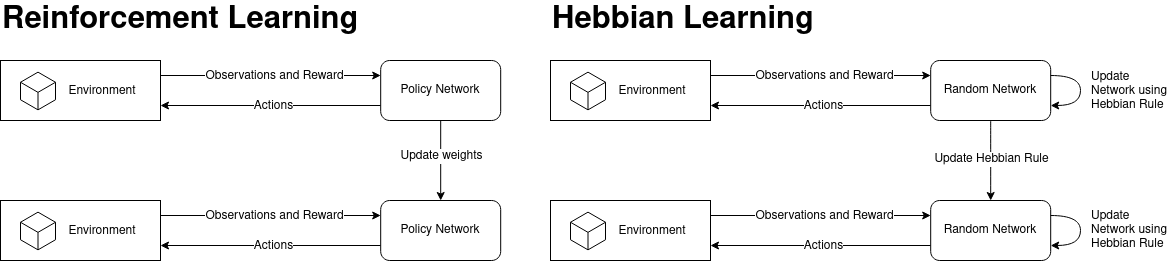
Recent research suggests that our brain doesn't operate based on a global update rule, as proposed with the gradient descent algorithm, but on a "simple" local update rule. Thus comes the urge to find new and biologically more accurate training mechanisms.
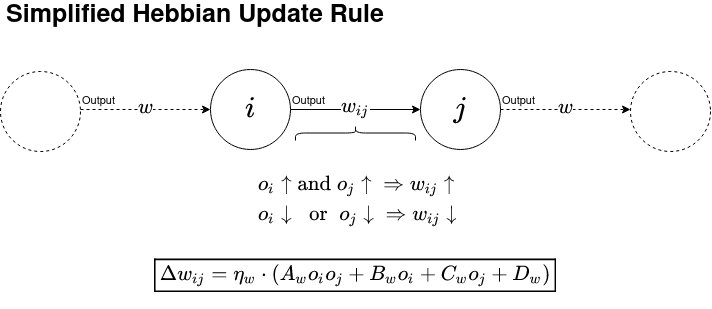
One approach, which I will implement in this notebook, is based on a postulate from Donald Hebb in his book The Organization of Behavior, realeased in 1949.
Unlike in classical reinforcement learning, our goal is not to learn a static weighted policy network, but a hebbian update rule, which adjusts our network based on the inputs at runtime.