Pipeline Strategy with SAIL AutoML
Given that AutoML methods typically optimize a specific objective function using fixed batch data, certain adjustments are necessary to apply them to the evolving data. As described in (Celik 2021), various adaptation strategies can be applied to adapt AutoML methods to data drift and guide to faster convergence. SAIL adapts the strategies explained in this paper to distributed pipeline selection in an AutoML setting. Pipeline strategies in SAIL help find the Machine Learning Pipeline with the best accuracy and in the best time possible with given resource constraints. Each of the pipeline strategies is defined below.
This pipeline strategy finds the best pipeline through SAIL AutoML, monitors pipeline performance and warm-start base estimator, i.e. incrementally fit, when the drift occurs. Only the base model is re-tuned; there is no pipeline tuning when drift is detected. Initially, an instance of the SAIL pipeline is created. It consists of a chain of transformers and a final estimator. SAIL AutoML is run on this pipeline instance using the Ray Tune API. Since this strategy incrementally trains the estimator, only incremental learning algorithms i.e., learners that can continue to train on new data, can be used.
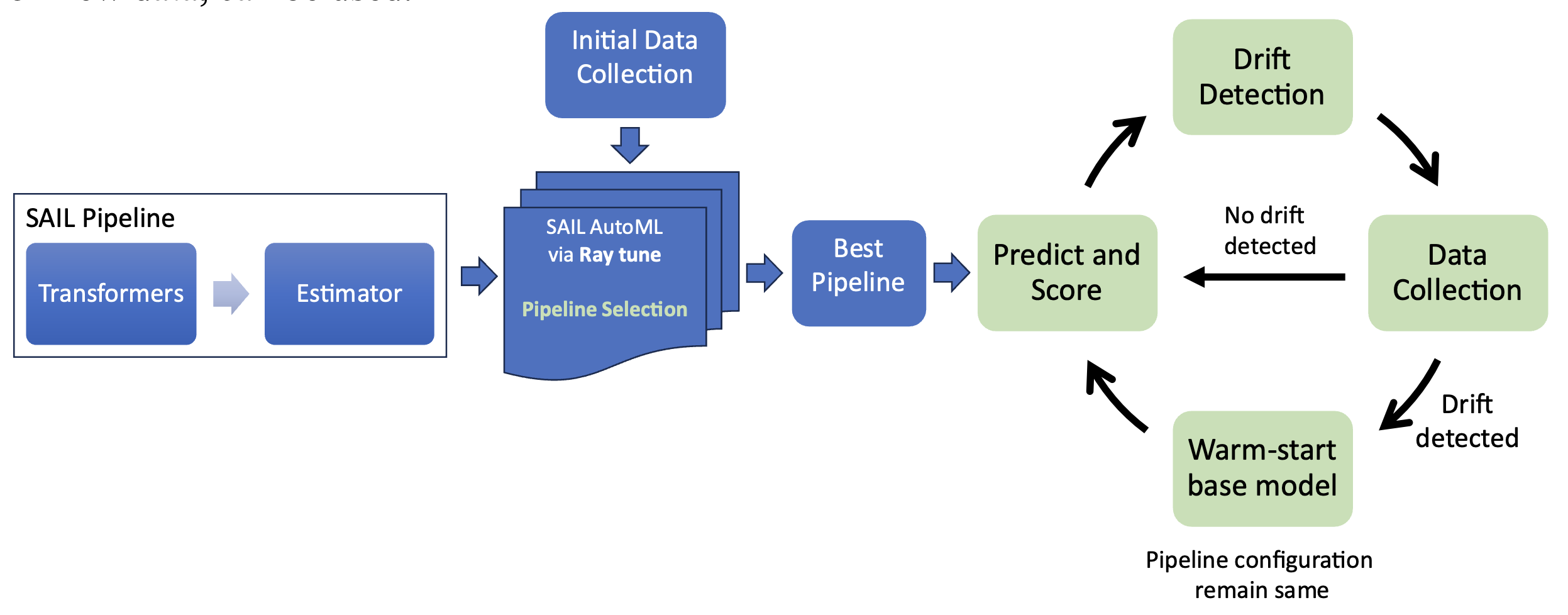 The strategy collects an initial data batch, finds the best pipeline through SAIL AutoML, and monitors its performance using the scoring function. If the data drift occurs, only the base estimator is fitted incrementally on the new data. The configuration of the pipelines remains the same. After the initial run, the strategy runs in a cycle, indicated by green boxes, as shown in the above figure. This pipeline strategy assumes that the initial pipeline configuration will remain useful and only the base estimator needs to be updated in case the pipeline performance declines because of concept drift. This approach speeds up the retraining process and boosts the performance of the overall pipeline.
The strategy collects an initial data batch, finds the best pipeline through SAIL AutoML, and monitors its performance using the scoring function. If the data drift occurs, only the base estimator is fitted incrementally on the new data. The configuration of the pipelines remains the same. After the initial run, the strategy runs in a cycle, indicated by green boxes, as shown in the above figure. This pipeline strategy assumes that the initial pipeline configuration will remain useful and only the base estimator needs to be updated in case the pipeline performance declines because of concept drift. This approach speeds up the retraining process and boosts the performance of the overall pipeline.
This is similar to Detect and Retrain, but refit the base estimator instead of warm-start when the drift occurs. Initially, an instance of the SAIL pipeline is created. It consists of a chain of transformers and a final estimator. SAIL AutoML is run on this pipeline instance using the Ray Tune API. In this strategy, incremental and other machine learning algorithms can be used as base estimators, as the model is re-fitted every time drift occurs.

The strategy collects an initial data batch, finds the best pipeline through SAIL AutoML, and monitors its performance using the scoring function. If the data drift occurs, the base estimator is re-fitted from scratch on the new data. The configuration of the SAIL Pipeline remains the same. After the initial run, the strategy runs in a cycle, indicated by green boxes, as shown in the above figure. This pipeline strategy also assumes that the initial pipeline configuration will remain useful and only the base estimator needs to be fitted in case the pipeline performance declines because of concept drift.
This pipeline strategy finds the best pipeline through SAIL AutoML, monitors pipeline performance, and warm-start SAIL AutoML, i.e., re-run with previously best configurations when the drift occurs. It ultimately produces a new best pipeline. Initially, an instance of the SAIL pipeline is created. It consists of a chain of transformers and a final estimator. SAIL AutoML is run on this pipeline instance using the Ray Tune API.
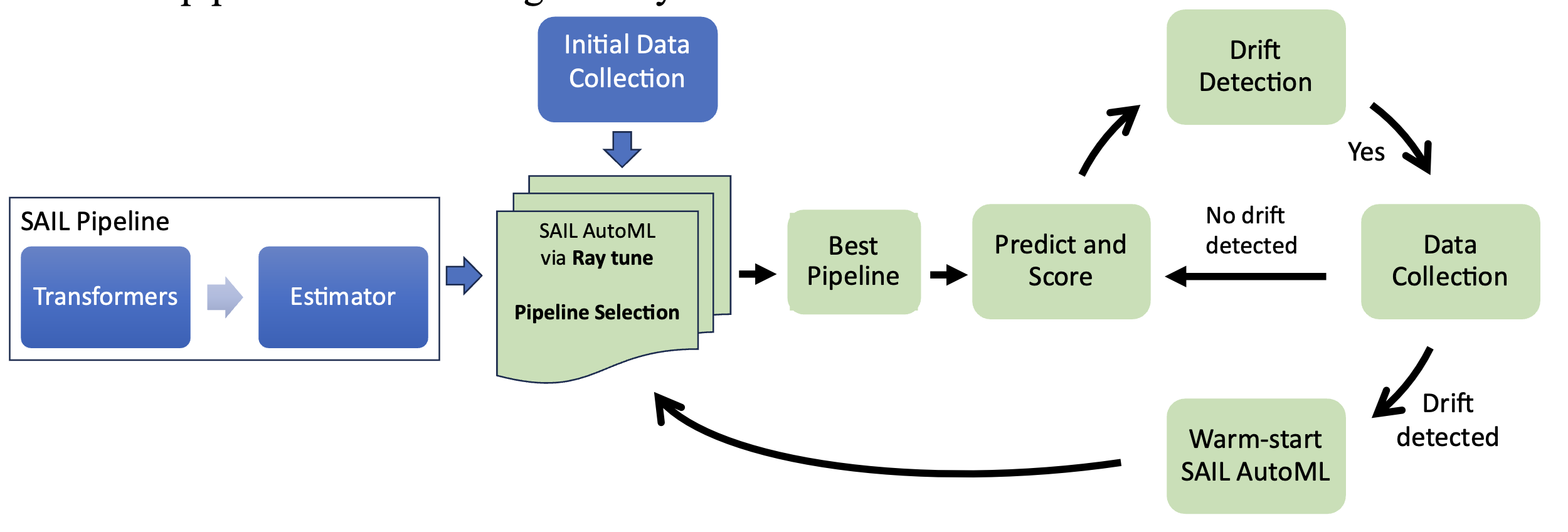
The strategy collects an initial data batch, finds the best pipeline through SAIL AutoML, and monitors its performance using the scoring function. If the data drift occurs, SAIL AutoML is re-run on the new data using the best earlier evaluated pipeline configurations. This process produces a new best pipeline. After the initial run, the strategy runs in a cycle, indicated by green boxes, as shown in the above figure. This strategy assumes that the initial pipeline configurations are no longer optimal after concept drift, and a warm start AutoML can lead to faster convergence with constrained time and compute budgets.
This pipeline strategy finds the best pipeline through SAIL AutoML, monitors pipeline performance, and re-start SAIL AutoML, i.e., re-run from scratch when the drift occurs. It ultimately produces a new best pipeline. Initially, an instance of the SAIL pipeline is created. It consists of a chain of transformers and a final estimator. SAIL AutoML is run on this pipeline instance using the Ray Tune API.
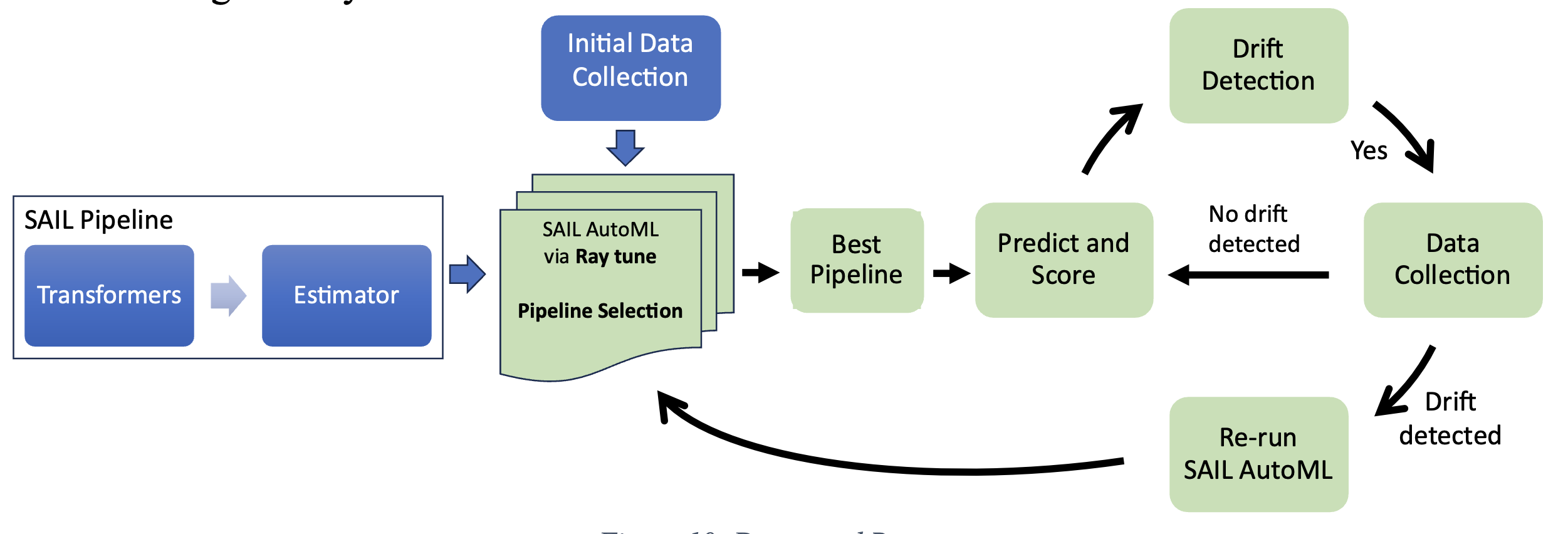
The strategy collects an initial data batch, finds the best pipeline through SAIL AutoML, and monitors its performance using the scoring function. If the data drift occurs, SAIL AutoML is re-run on the new data from scratch with newly found configurations. This process produces a new best pipeline. After the initial run, the strategy runs in a cycle, indicated by green boxes, as shown in the above figure. This strategy assumes that the initial pipeline configurations are no longer optimal after concept drift, and a re-run of AutoML can help find a better pipeline configuration at the cost of resources and time. This strategy has the possibility of finding a pipeline with the best performance.
This is the most extreme case of all the pipeline strategies. It should only be used when no other pipeline strategies work. It is similar to Detect and Restart, but runs SAIL AutoML on every batch of data.

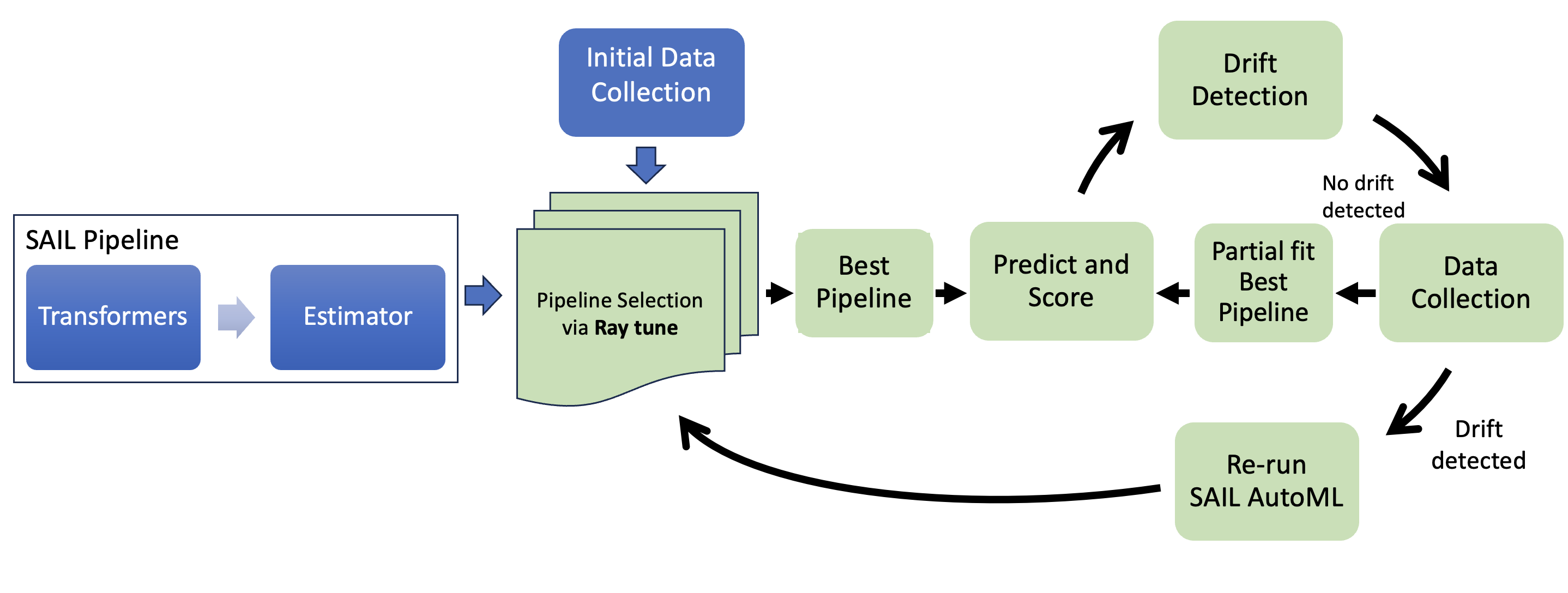
The strategy collects an initial data batch, finds the best pipeline through SAIL AutoML, and monitors its performance using the scoring function. There is no drift detection. It re-run SAIL AutoML from scratch on the next batch of data. After the initial run, the strategy runs in a cycle, indicated by green boxes, as shown in the above figure.
Prequential pipeline selection is available for SAIL Pipeline. It enables incremental learning i.e. test-then-train paradigm for the given pipeline. In incremental learning, arriving data batch is used to calculate the performance (test) and then partially updating the model (train) in the next step.
In SAIL, prequential learning can occur over a batch, which uses data chunks of size n instead of individual instances. Accuracy changes incrementally as new data batch arrives. This method is useful to evaluate models in case of sudden concept drift. Although the machine learning pipeline is shown to yield lower accuracy at the beginning, the accuracy eventually increases as new data arrives.
Pipeline Strategy helps adapt AutoML methods to data drift and guide them to faster convergence. Pipeline strategy act as a blueprint for AutoML training. It defines all the aspects of pipeline training, from data collection to tuning pipelines to monitoring and re-training. The following manual show a step-by-step guide to implementing a Pipeline Strategy class in SAIL AutoML.
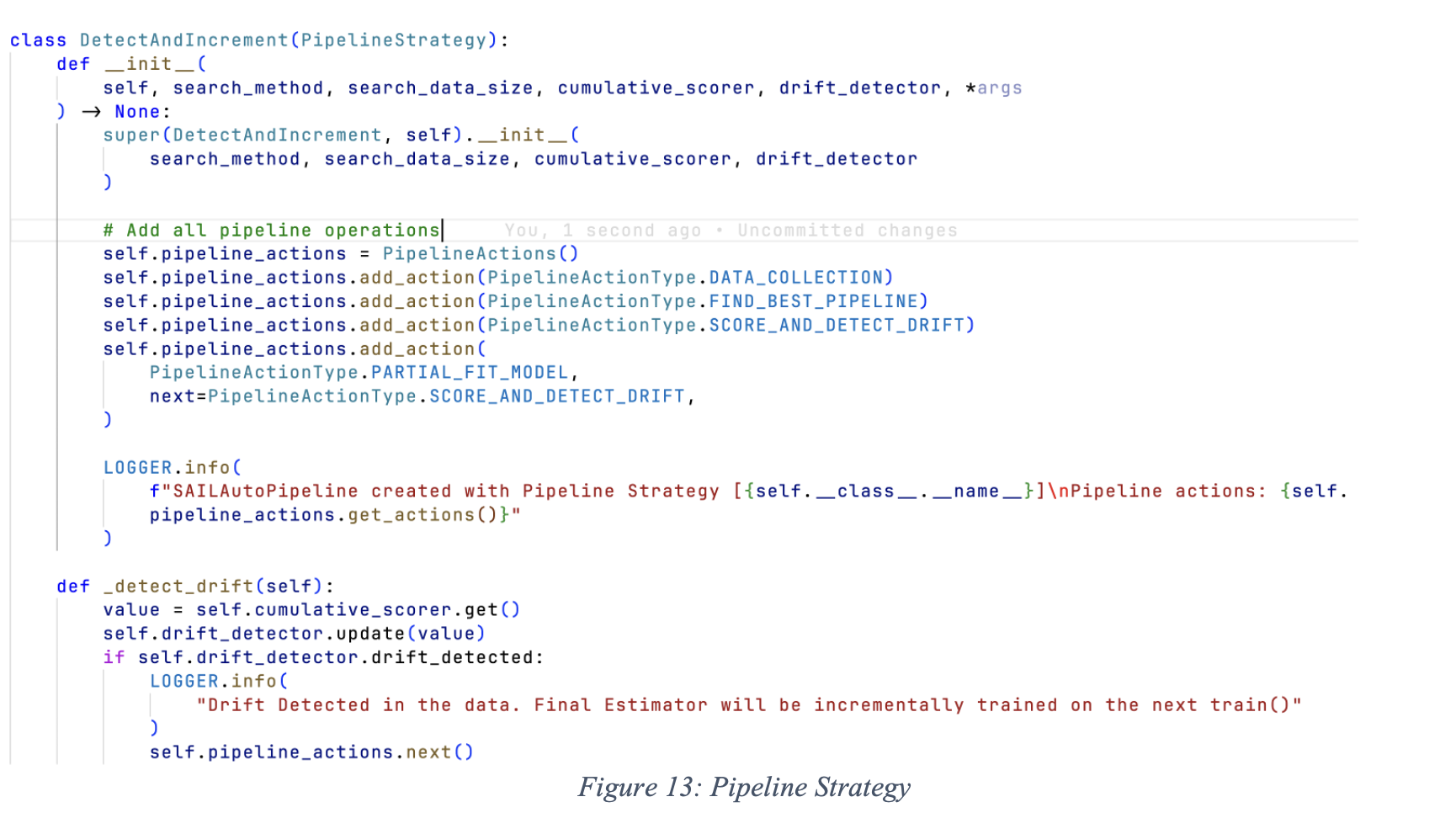
- Create a pipeline strategy class in pipeline_strategy.py (e.g. DetectAndIncrement)
src/sail/models/auto_ml/pipeline_strategy.py
-
As shown in step 1, every pipeline strategy class needs to extend base PipelineStrategy. The mandatory arguments are search_method, search_data_size, cumulative_scorer and drift_detector. Information about these parameters is available in Section 3.3.
-
Pipeline operations are defined as an element of a LinkedList. Create a LinkedList of the type PipelineActions. Add pipeline operations as an action to the PipelineActions. You can select any pipeline operation from the PipelineActionType Enums. A new operation should go here first.
src/sail/models/auto_ml/base_strategy.py

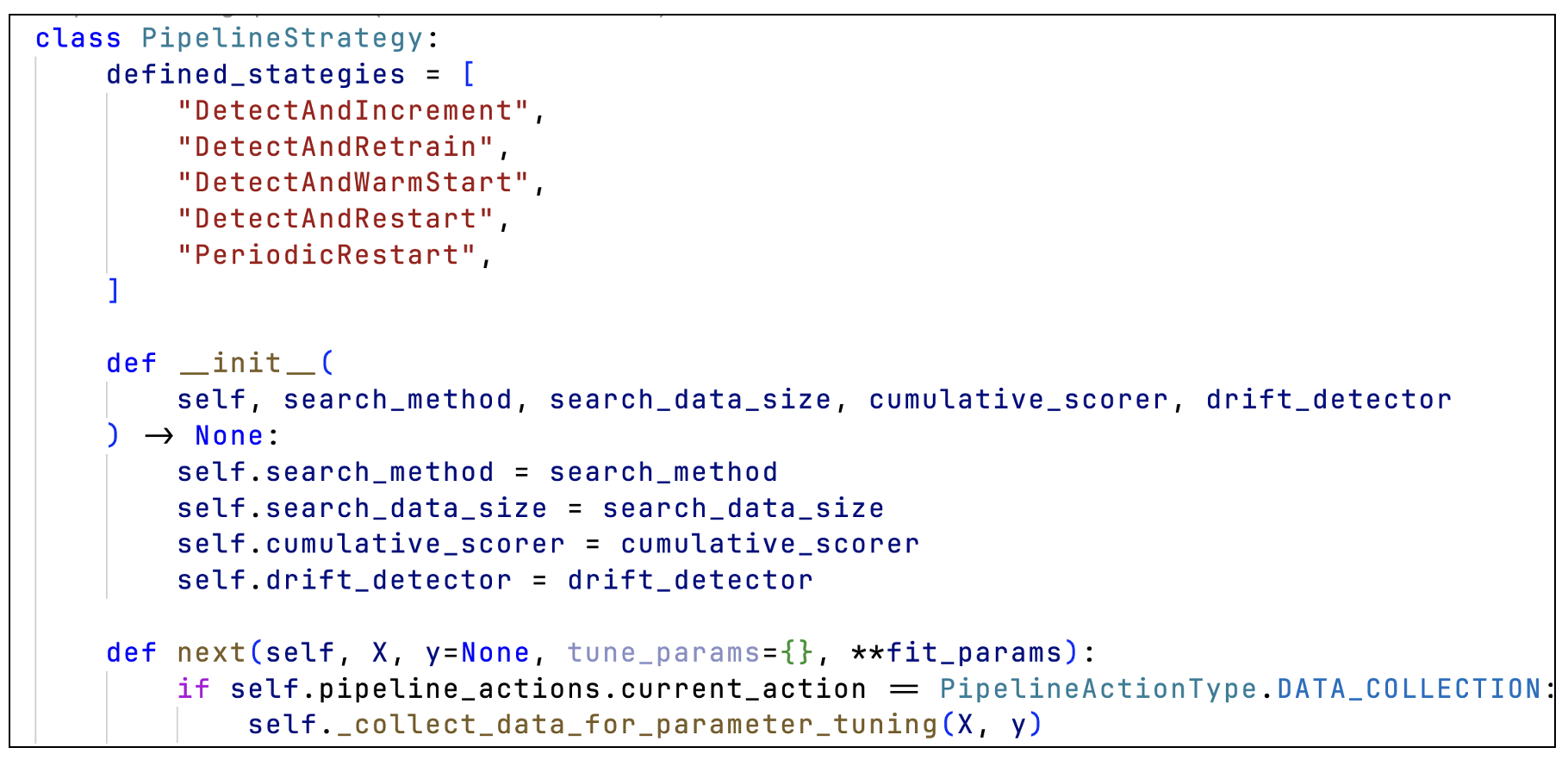
- Add your pipeline strategy class as a string in the defined_strategies class variable of the base class.
src/sail/models/auto_ml/base_strategy.py

- You can override any base class methods (i.e. default pipeline operation implementations) in your pipeline strategy class as per the need. For example, _detect_drift is overridden in DetectAndIncrement, shown in step 1. Methods that can be overridden are as follows:
src/sail/models/auto_ml/base_strategy.py
class: PipelineStrategy
methods:
- _find_best_pipeline
- _cumulative_scoring
- _partial_fit_model
- _fit_model
- _detect_drift
- If you add a new pipeline operation by defining a new Enum in PipelineActionType, operation implementation must exist in the next() method. See the DATA_COLLECTION operation below.
src/sail/models/auto_ml/base_strategy.py
- That’s all the details. The pipeline strategy is called internally by SAILAutoPipeline class during the training phase. The steps defined in the PipelineActions execute in the order.