Delivering data services to EOSC
The report from our workshop on how ExPaNDS is delivering its data services to PaNOSC and EOSC is being published here. It is based on the content provided by the different speakers (see linked material in agenda above) and the discussions that followed.
The Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH) is a low barrier mechanism for repository interoperability.
- OAI-PMH: is a set of six verbs or services that are invoked within HTTP
- Data Providers: are repositories that expose structured metadata via OAI-PMH. A network accessible server that can process the six OAI-PMH requests. (our facilities which implemented the OAI-PMH)
- Service Providers: then make OAI-PMH service requests to harvest that metadata. (DataCite, B2FIND, OpenAIRE…)
It enables to expose the metadata you have in your data catalogue in a standard way, and represents an easy way to integrate in B2FIND and OpenAIRE. It uses a predefined set of urls that can be invoked. Link to the OAI-PMH protocol specification.
Simplified diagram of what OAI-PMH is:
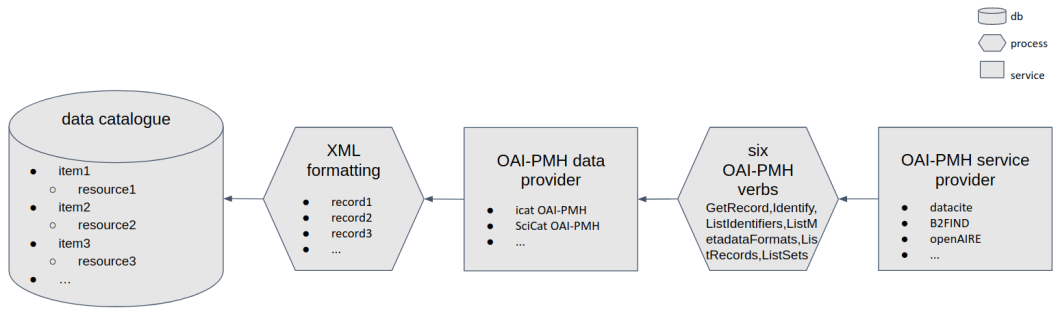
Definitions:
- Resource: data collected during an experiment
- Item: all metadata around the data (entry in a collection)
- Record: item in the standardised XML format
List of the 6 OAI-PMH verbs and their meaning:
http://<end-point-address>/oai?verb=GetRecord&metadataPrefix=[Metadata_Prefix]&identifier=[Identifier]
- Returns the metadata record the
[Identifier]points to, with the XML returned in the designated[Metadata_Prefix]. - For example: https://doi.psi.ch/oaipmh/oai?verb=GetRecord&metadataPrefix=oai_datacite&identifier=10.16907/f1285417-f190-4563-a8ee-04ebd9246a21
http://<end-point-address>/oai?verb=Identify
- Returns basic info about the repository.
- For example: https://doi.psi.ch/oaipmh/oai?verb=Identify
http://<end-point-address>/oai?verb=ListIdentifiers&metadataPrefix=[Metadata_Prefix]
- Returns a list of all record identifiers with date of last modification.
- For example: https://doi.psi.ch/oaipmh/oai?verb=ListIdentifiers&metadataPrefix=oai_dc
http://<end-point-address>/oai?verb=ListMetadataFormats
- Returns a list of all metadata formats available (with the
Metadata_Prefixused in other queries). - For example: https://doi.psi.ch/oaipmh/oai?verb=ListMetadataFormats
http://<end-point-address>/oai?verb=ListRecords&metadataPrefix=[Metadata_Prefix]
- Returns all of the metadata records for the given prefix.
- For example: https://doi.psi.ch/oaipmh/oai?verb=ListRecords&metadataPrefix=oai_dc
http://<end-point-address>/oai?verb=ListSets
- Returns list of available Sets.
- Currently not supported by the SciCat implementation.
The service provider then does a scheduled harvesting of the metadata using these urls.
| Facility | Data catalogue | Status of OAI-PMH endpoint | Link |
|---|---|---|---|
| ALBA | ICAT | Ready but not published | |
| DESY | SciCat | Integrated in SciCat in the process of installation at PETRA | |
| Diamond | ICAT | Pending on ICAT | |
| Elettra | ICAT | Ready - ICAT OAI-PMH plugin installed but not published | |
| HZB | ICAT | Working but need prior work on metadata | |
| HZDR | Invenio | In place - records available | https://rodare.hzdr.de/oai2d?verb=Identify |
| MAX IV | SciCat | In place - records available | https://scicat.maxiv.lu.se/openaire/oai?verb=Identify |
| PSI | SciCat | In place - records available | https://doi.psi.ch/oaipmh/oai?verb=Identify |
| SOLEIL | SciCat | Integrated in SciCat in the process of installation at SOLEIL | |
| ISIS | ICAT | In place - records available | https://icat-dev.isis.stfc.ac.uk/oaipmh/request?verb=Identify |
Harvesters regularly use the OAI-PMH endpoint to harvest the metadata and store it locally to make it available to the end user. There is no direct request from a user to the endpoint. B2FIND is harvesting e.g. 100 000s of metadata records every day. Flow control can be configured at the endpoint, meaning each facility can define how much you expose at a time (default: 50).
🚧
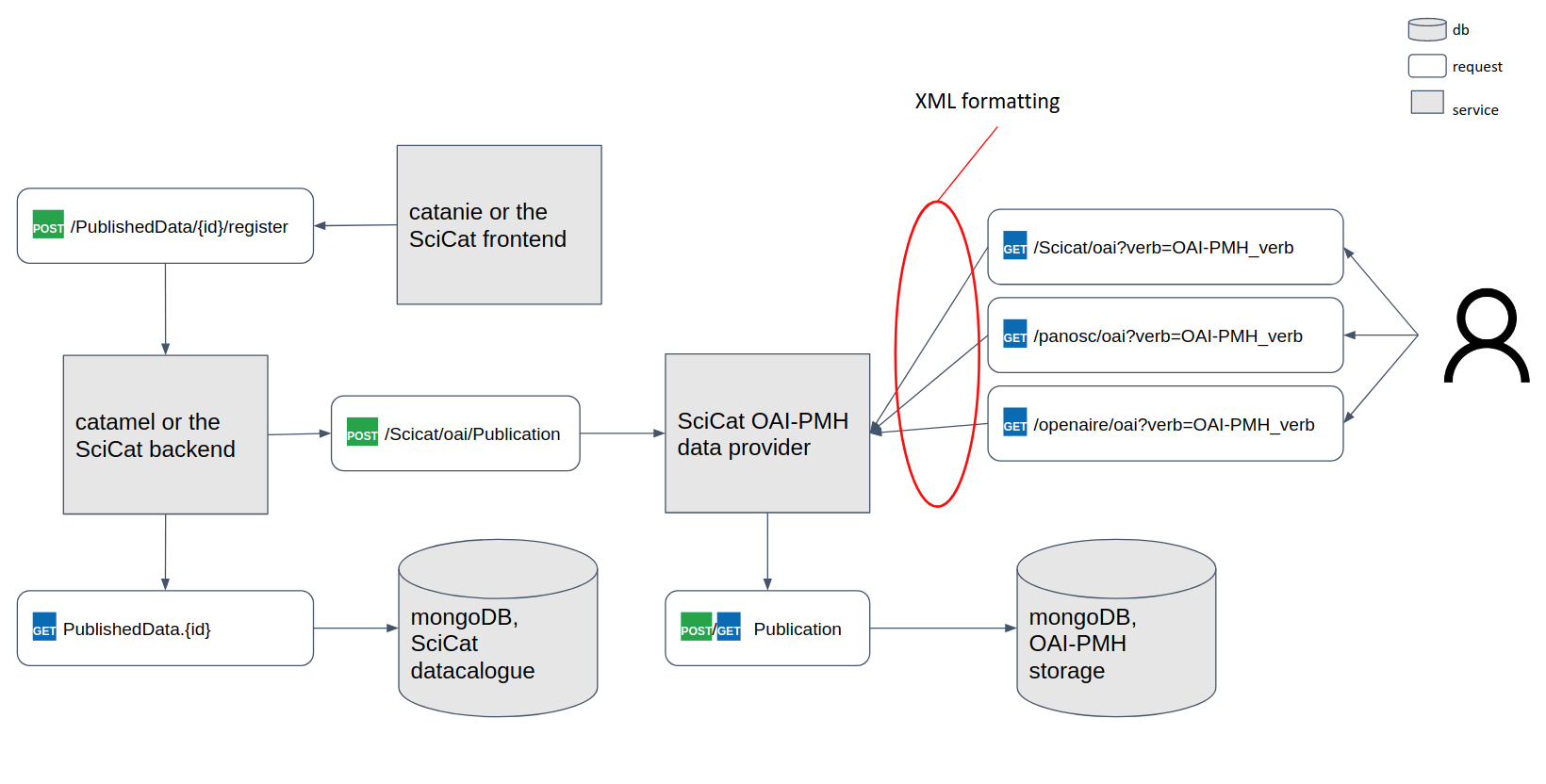 Explaining the diagram above:
Explaining the diagram above:
- Using catanie the user decides what publication to publish.
Note: Having the SciCat front-end (catanie) is not required, catamel endpoints can be called in any other way.
- The
/PublishedData/{id}/registerendpoint of catamel is called, which draws the aforementioned publication by ID from the datacalogue MongoDB. - The
/Scicat/oai/Publicationendpoint of the SciCat OAI-PMH is called, which copies the publication of (2) to the SciCat OAI-PMH mongoDB.
Note: The SciCat OAI-PMH MongoDB can be the same as the datacalogue MongoDB, this is an implementation choice.
- Depending on the need, one of the endpoints
/Scicat/oai?verb=OAI-PMH_verb,/openaire/oai?verb=OAI-PMH_verb,/panosc/oai?verb=OAI-PMH_verbis invoked. Each of them draws the publication(s) of interest from the SciCat OAI-PMH mongoDB and formats it (them) in the corresponding XML format.
Note: The XML formatting depends on the route you set. Currently three different formats are implemented:
- OpenAIRE compatible -
/openaire/route - (datacite XML format)- B2FIND compatible -
/Scicat/route - (dc XML format) and- panosc -
/panosc/route - (don’t know of any use).In case a new formatting will be required, e.g. DCAT, the SciCat OAI-PMH architecture requires to define a new XML mapper class to be added to the existing mappers and to expose it defining a new route. The XML formatting is thus quite flexible and scalable.
- Such XML formatted publications can be consumed by B2FIND, OpenAIRE, etc. via their scheduled harvesting functionality.
- Clone the SciCat OAI-PMH repository.
- Customise the mongo connection parameters here to point to the mongoDB instance to use.
- Add the key value pair:
oaiProviderRoute: '$url:$port/Scicat/oai/Publication'to themodule.exportsmap in theconfig.local.jsfile of your catamel service deployment, using the url and port from (2). - Run
npm install+nodeor build the Dockerfile image and run it. - Restart the catamel service.
ICAT is a metadata catalogue for PaN facilities developed and maintained by the ICAT project. The main component is an API layer on a relational database (RDBMS). Its main components are:
-
icat.server: main component, the metadata catalogue -
ids.server: manages the storage, provides access (HTTP upload and download) to data files. -
topcat: web user interface.
Overview of the ICAT architecture:
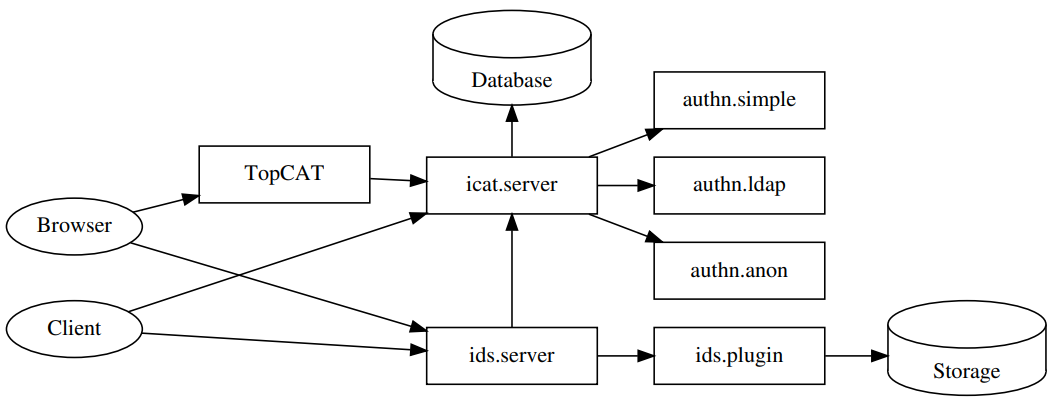
PaN facilities using ICAT have a common database schema but it is used a bit differently. Different semantics in the entity classes present in the schema can be applied and different types of objects can also be used:
- investigation: it is a proposal for some facilities, only a visit for others
- study: not used at all except ISIS who is using it for proposals
- dataset: usually represents a measurement within an investigation
- data publication: not present in the ICAT schema yet, but there is a pending proposal for schema extension
Which leads to a whole set of options in terms of data we would want to expose.
If we want to expose our public datasets to whoever is interested to harvest and present these metadata records to the wider public, we may want to be able to comply with different schemas. For example, DublinCore is required by the OAI-PMH as the least common denominator that every endpoint must support and DataCite is required for OpenAIRE. And there will be other use cases in the future, because these schemas only cover the "bibliographic" metadata and not the "physical" metadata of the experiment (ex: the PaN search API).
We need something flexible and configurable.
As an answer to these challenges, an additional ICAT component was developed at HZB to map metadata in the catalogue onto metadata standards requested by the harvesters using OAI-PMH. The latest release version of the OAI-PMH component icat.oaipmh can be found here, with detailed instructions to install and download the component.
It is designed as a new separate component and connects to the icat.server as a normal client via the standard API.
3 steps for the flexible mapping:
- In a configuration file, select the entity classes that shall be exposed, along with relevant attributes and related objects
- Out of that,
icat.oaipmhgenerates an internal XML representation of this data using a one-to-one mapping from the ICAT schema - Use XSLT (extended schema language translation) provided as a separate configuration file to generate the output from that internal XML representation, transforming it into whatever we expose, mapping to any metadata standard you want
Example XSLT files for the most relevant cases (mapping generic ICAT investigation onto Dublin Core and DataCite e.g.) are provided as a starting point to write facility specific customised versions. Which means that ICAT-using facilities would only need to tweak the example XSLT files according to how they represent their data and would already be set, at least for Dublin Core and DataCite schemas.
A practical example of a run.properties configuration file:
# The metadata formats to be supported
metadataPrefixes = oai_dc oai_datacite
oai_dc.xslt = /path/to/oai_dc.xslt
oai_datacite.xslt = /path/to/oai_datacite.xslt
# Identifiers for metadata configuration
data.configurations = inv stud
data.inv.metadataPrefixes = oai_dc oai_datacite
data.stud.metadataPrefixes = oai_dc
# Relevant data objects and properties
data.inv.mainObject = Investigation
data.inv.stringProperties = summary doi title
data.inv.subPropertyLists = investigationUsers
data.inv.investigationUsers.stringProperties = role
data.inv.investigationUsers.subPropertyLists = user
data.inv.investigationUsers.user.stringProperties = fullName givenName familyName orcidId affiliation
From this list, the internal XML representation will be created (step 2 above) and the right XSLT file will be used to generate the external XML file for that specific harvester (step 3 above).
- is separate, which means there is no need to change anything from the
icat.serverand it deploys in the same way as other components. - support sets (which is important for OpenAIRE).
- support selective harvesting by datestamps and by sets.
- support flow control using
resumptionToken. - no support for maintaining information about deleted records (deliberate).
- configurable to disseminate any object class present in ICAT.
- support multiple metadata formats by virtue of on-the-fly transformation using XSLT.
- Completely stateless, doing everything “on the fly” during the request process.
- no access control in
icat.oaipmh, use standard authorization rules inicat.serverto control whaticat.oaipmhas a client is allowed to see (and thus to disseminate).
What about custom data catalogues?
B2FIND produced training material to deploy an OAI-PMH on any catalogue:
- Data catalogue to XML formatting
- Exposing of the metadata to the OAI-PMH set of verbs
Careful, this documentation is outdated but the principles are still valid: https://github.com/EUDAT-Training/B2FIND-Training
B2FIND is an interdisciplinary discovery tool for research data, running since 2014.
Useful links:
- B2FIND portal
- B2FIND guidelines for data provider
- B2FIND in GitHub
- B2FIND metadata schema concordance
- B2FIND classification for disciplines
It harvests communities, which in our case is a facility data catalogue, preferably via OAI-PMH because it offers good functionalities for harvesting but they also support REST APIs.
Since recently, all metadata in B2FIND is now also automatically in OpenAIRE.
-
Option 1 (default): OAI-PMH
Having an OAI-PMH endpoint is a common goal set by ExPaNDS/PaNOSC facilities which is followed as a KPI. See here for PaNOSC facilities and in the table above for ExPaNDS. -
Option 2: PaN search API?
The PaN search API is not thought for this use case but more for an interactive search with a user. To be discussed.
Refer to B2FIND's guidelines for metadata mapping. The metadata schema used by B2FIND is almost exactly DataCite with a few expections. For example, it does not require the "Identifier" to be a DOI but accepts DOI, PID or even a url. It also has an additional element which is "Instrument".
- Option 1 (default): DataCite
- Option 2 (minimal): DublinCore
- Option 3 (but not available yet): DCAT - it will be integrated in B2FIND in the frame of FAIRsFAIR and may offer more possibilities - see the outcome of the use case being developed with Alejandra (STFC)
- Option 4: Custom, on a case-by-case basis
N.B: The metadata standard chosen can depend on the class of metadata we deliver, e.g. DataCite for publication data but DublinCore for raw data.
When DataCite standard can be used to "transport" additional information and B2FIND is aware of it, it will also be displayed. We just need to agree on where and how we declare this additional information. In the following paragraphs we give a few examples:
If we want to use the DataCite schema on data which does not have a DOI, it is possible with B2FIND, using alternateIdentifier.
In DataCite there is a possibility to expose the instrument linked to a dataset, which can be relevant for PaN and which is also in B2FIND's schema.
Add a "RelatedIdentifier" with relationType="IsCompiledBy" to the dataset’s metadata, pointing to the PID of the instrument.
N.B: Building a registry for PIDs for instruments is a dedicated task in the DICE project where our PaN community will be involved, as an example user.
In case our facility's data policy allows the publication of metadata during the embargo period, it may be desirable (and FAIR) to have it harvested as well.
On a practical level, we then suggest to use "Date" with dateType="Available" for DataCite to indicate when the embargo period has ended or will end in the future.
More explanation: DataCite metadata has the property "Date" defined as "Different dates relevant to the work". The semantic of that date is indicated with the subproperty "dateType". The types include, among others:
- "Created" (the date the resource was put together),
- "Submitted" (the date the resource was submitted to the publisher),
- "Accepted" (the date the publisher accepted the resource),
- "Issued" (the date that the resource is published; DataCite uses this to indicate the date that the DOI has been minted),
- "Available" (the date the resource is made publicly available, the date the embargo period ends).
Thus, Date with dateType=Available is the designated way to indicate the end of embargo. It is possible to set this date in the future, if you mint a DOI for data that is still under embargo.
Reference: DataCite Metadata Working Group. (2021). DataCite Metadata Schema Documentation for the Publication and Citation of Research Data and Other Research Outputs. Version 4.4. DataCite e.V. https://doi.org/10.14454/3w3z-sa82 - Appendix 1 Controlled List Definitions, Table 6: Description of dateType.
As what is happening with EOSC-Nordic, we have the possibility to integrate all ExPaNDS and PaNOSC facilities within one group in B2FIND and users will be able to narrow down search to that group. Different underlying mappings are still possible, it is quite transparent and easy to implement.
More details on the discovery and re-use of Nordic community specific data in EOSC can be found in this deliverable.
Direct link to Andreas presentation. The Bielefeld University Library is responsible for the data source integration in OpenAIRE since 2010, it has a long experience in harmonisation of metadata and metadata quality.
OpenAIRE aggregates published metadata from all over the world, from more than 12,000 data sources, mainly on OAI-PMH. There is "direct" harvesting from the data source itself or "indirect" harvest from aggregators like Microsoft Academic Graph, DataCite (without selection), CrossRef, also from aggregators like La Referencia and national aggregators. All this metadata is processed to produce the OpenAIRE research graph. In particular, metadata is:
- deduplicated, while keeping all original metadata from each source but showing the richest version to the user,
- enriched using an open source full-text mining tools to find e.g. links to funders and projects.
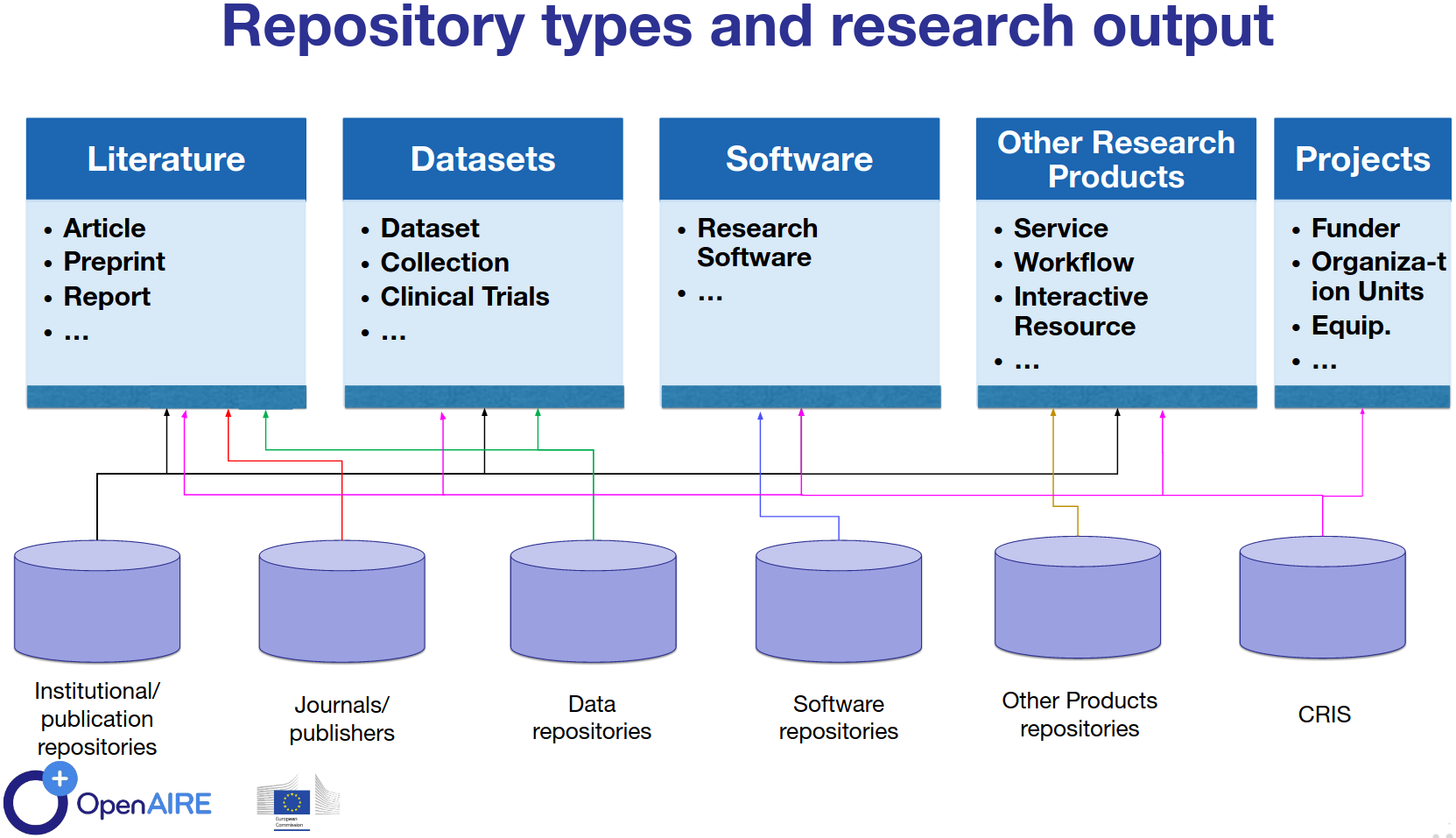
Landscape of repositories and resource types in OpenAIRE
In the last years, Current Research Information Systems or CRIS have become more and more important around the world. These repository types are also exposing metadata for projects, funders, patents, organization units, and equipment/instruments.
The OpenAIRE research graph itself is also open source, accessible as DUMP or via API, and interlinks the available metadata whenever possible. The graph is the core element for other OpenAIRE services:
- OpenAIRE EXPLORE: exploring metadata
- OpenAIRE CONNECT: service for communities (see below)
- OpenAIRE DEVELOP: APIs, e.g. this is how the participant portal of the European Commission is collecting metadata on publications
- OpenAIRE MONITOR: monitoring observations about the metadata and more generally the evolution of open access and open science
For directly harvested, registered sources managers, OpenAIRE offers a dashboard, called the PROVIDE dashboard. This dashboard and the control over our metadata are the two main arguments for our facilities data repositories to register as OpenAIRE providers (and not only have our metadata appear in OpenAIRE thanks to B2FIND).
OpenAIRE provides a service to validate data sources, checking it is exposing its contents using global standards. All the documentation is available here.
Until 2018, only Open Access records were harvested by OpenAIRE but since the new Content Acquisition policy [10.5281/zenodo.1446408], both Open Access and non-Open Access material are included. It still only accepts published research outputs though.
If validation (via OAI-PMH for data sources) succeeds, the repository can be registered for regular aggregation and indexing in OpenAIRE. Note: The registration process is in internal discussions about CRIS systems, to see how to integrate them in a more efficient way. OpenAIRE is collaborating with euroCRIS on this topic.
Once registered, the repository manager has access to aggregated usage statistics, in a nicely wrapped user interface. We can also have access to the log of the last harvesting, the number of records harvested, which version is currently in the OpenAIRE graph (the "indexed version").
And last but not least, the repository manager gets access to OpenAIRE's metadata improvement tools. There are 2 groups of events:
- more information about your record: the dashboard shows what differs between your repository and the other data sources found,
- missing information in your repository: e.g. OpenAIRE found another PID linked to a particular record and will suggest you to add it. Additional links to other research outputs is currently in development.
There is an API to collect the information from this "broker", so automatical updates of our repositories can be triggered. This can be very useful for a repository manager.
In OpenAIRE CONNECT, there are currently 10 curated communities. The service gathers the output of the OpenAIRE research graph for all records relevant to these specific communities. It can also link to other existing communities in, e.g. Zenodo. OpenAIRE Community Calls take place every first Wednesday of the month.
 This project received funding from the European Union's Horizon 2020 research and innovation programme under grant agreement #857641.
This project received funding from the European Union's Horizon 2020 research and innovation programme under grant agreement #857641.