👋 你好!Mabuhay!Hola!本指南由2023 DLC AI 居民编写!
👋 本指南由BBrianZhang翻译!
- 在使用神经网络进行训练、评估和推理时,有一些超参数需要考虑。虽然 DLC 试图设置“全球适用于所有人的”参数,但你可能需要更改它们。因此,在本指南中,我们将回顾与神经网络模型及其相关数据增强相关的 pose 配置参数。
pose_cfg.yaml文件提供了方便用户根据使用的数据集和任务调整训练参数的途径。- 你可以在 dlc-models > test 和 train 子目录中找到这个文件。在 GUI 中也有一个按钮可以直接打开此文件。
- 本指南旨在帮助普通用户了解这些超参数以及解决相关问题的直觉。
默认值分别是 1500 和 64。
💡专业提示:💡
- 当视频分辨率高于1500x1500或者
scale_jitter_up可能超过该值时,更改max_input_size。 - 当视频分辨率小于64x64或者
scale_jitter_lo可能低于该值时,更改min_input_size。
默认值是 0.8。 这是训练队列中所有图像发生的最基本的首次缩放。
💡专业提示:💡
- 对于分辨率低或者细节不足的图像,将
global_scale增加到1可能更有效,以保持原始大小并尽可能保留更多信息。
默认情况下,单个动物项目的batch_size是1,对于多动物深度学习(maDLC)项目则是8。它是每次训练迭代使用的帧数。
在这两种情况下,你可以根据 GPU 内存的限制增加batch_size并减少训练迭代的次数。迭代次数与batch_size之间的关系不是线性的,因此batch_size: 8并不意味着你可以训练迭代次数减少8倍,但如同每次训练一样,平稳的损失可以作为达到最佳性能的指标。
💡专业提示:💡
- 较高的
batch_size在模型的泛化方面可能有益。
上面提到的值和增强参数往往是直观的,了解我们自己的数据,我们才能决定哪些参数有利而那些参数无益。不幸的是,不是所有的超参数都这么简单或直观。在一些具有挑战性的数据集上可能需要调整的两个参数是pafwidth 和 pos_dist_thresh。
默认值是 17。它是一个窗口的大小,在这个窗口内的检测被视为正面训练样本,意味着它们告诉模型它正在朝着正确的方向发展。
默认值是 20。 PAF 代表部分亲和场。这是一种通过保留肢体(两个关键点之间的连接)的位置和方向来学习身体部位之间关联的方法。这种学习到的部分亲和力有助于正确组装动物,使模型不太可能将一个个体的身体部位与另一个个体的混合。 1
从最简单的形式来看,我们可以将数据增强视为类似于想象或梦想的东西。人类根据经验想象不同的场景,最终帮助我们更好地理解我们的世界。2, 3, 4
同样,我们训练我们的模型对不同类型的“想象”场景进行响应,这些场景我们限制在可预见的范围内,因此我们最终获得的模型能够更有可能处理新的数据和场景。
数据增强的类别,由它们的性质给出,包括:
几何变换 such as 翻转, 旋转, 平移, 裁剪, 缩放, and 注入噪声,这些都非常适合训练数据中存在的位置偏差。
尺度抖动 在给定的大小范围内调整图像的大小。这允许模型学习场景中不同大小的对象,因此增加了它对新场景或对象大小的泛化能力。
下面的图像,从3检索,展示了两种尺度抖动方法的区别。
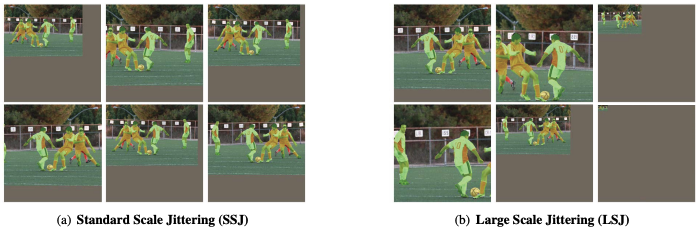
在训练过程中,每张图像都在[scale_jitter_lo, scale_jitter_up]范围内随机缩放,以增强训练数据。这两个参数的默认值为:
scale_jitter_lo = 0.5scale_jitter_up = 1.25
💡专业提示:💡
-
⭐⭐⭐ 如果目标动物在整个视频中没有极大的变化(例如,跳跃或向静止的摄像机移动),保持默认值不变将为数据提供足够的多样性,使模型更好的泛化。 ✅
-
⭐⭐然而,如果你想要你的模型能够做到以下要求,你可能需要调整这些参数:
- 处理可能**比原始数据大25%**的动物对象的新数据 ➡️ 在这种情况下,增加scale_jitter_up的值
- 处理可能**比原始数据小50%**的动物对象的新数据 ➡️ 在这种情况下,减小scale_jitter_lo的值。
- 在几乎不需要预训练的情况下,在新的设置/环境中很好地泛化
⚠️ 但结果可能是, 训练时间会更长。😔🕒
-
⭐如果你有一个完全静止的摄像机设置,并且动物的大小变化不大,你也可以尝试缩短 这个范围以 减少训练时间。😃🕒(
⚠️ 但结果是,你的模型可能只适用于你的数据而不能很好地泛化)
旋转增强是通过将图像在$1^{\circ}$到$359^{\circ}$之间的轴上向右或向左旋转来完成的。旋转增强的安全性主要由旋转角度参数决定。轻微的旋转,例如在$+1^{\circ}$ 到
下图摘自2,说明了不同旋转角度之间的差异。

在训练过程中,每张图像会根据设置的rotation角度参数进行$+/-$旋转。默认情况下,这个参数设置为25,这意味着图像会增强为自身的$+25^{\circ}$旋转和$+25^{\circ}$。如果你想选择不进行这种增强,请将rotation值设置为False。
💡专业提示:💡
-
⭐如果你已经标记了所有可能的动物旋转角度,那么保持默认值不变就足够了。 ✅
-
然而,如果你想要你的模型能够做到以下要求,你可能需要调整这些参数:
- 处理带有新旋转角度的动物对象的新数据
- 处理你最少标记数据中可能未标记的旋转角度
- 但结果是,你增加旋转角度越多,原始关键点标签可能越不能保持。
在DLC模块中,此参数表示从训练数据中采样进行增强的数据百分比。默认值设置为0.4或$40%$。这意味着当前批次中的图像有$40%$的几率会被旋转。
💡专业提示:💡
- ⭐ 通常,保持默认值不变是足够的。✅
镜像,也称为水平轴翻转,比垂直轴翻转更为常见。这种增强方法是最容易实现的之一,并且在CIFAR-10和ImageNet等数据集上证明是有用的。然而,在设计文本识别的数据集(如MNIST或SVHN)上,这不是一种保留标签的变换。
下图展示了这一特性(在最右边的列中显示)。
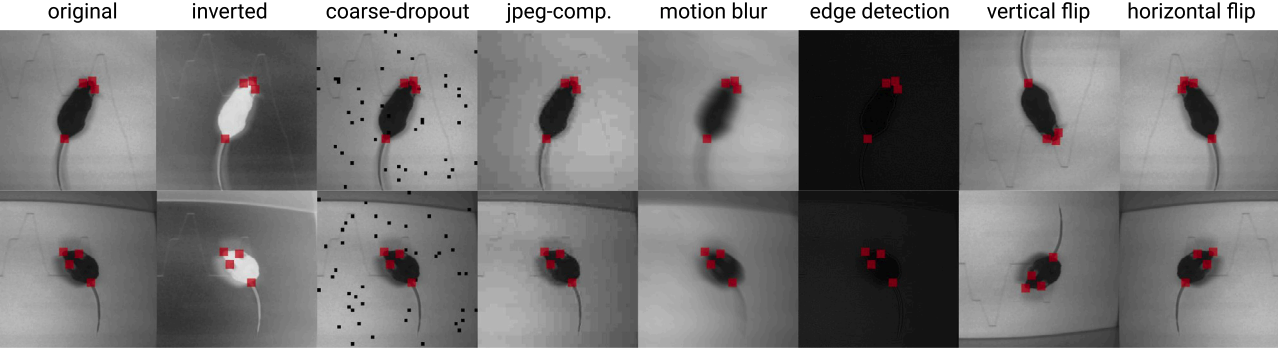
此参数随机水平翻转图像以增强训练数据。
默认情况下,此参数设置为False,特别是在具有镜像对称关节的姿势上(例如,避免左右手被交换)。
💡专业提示:💡
- ⭐ 如果你的标签中有对称关节,保持默认值不变——除非数据集有偏差(例如动物主要向一个方向移动,但有时会向相反方向移动)✅
- 保持默认值为
False在大多数情况下都能正常工作。
裁剪是指从图像中移除不需要的像素,从而选择图像的一部分并丢弃其余部分,以减少输入的尺寸。
在DeepLabCut的pose_config.yaml文件中,默认情况下crop_size设置为(400,400),分别为宽度和高度。这意味着它将裁剪出改尺寸的图像部分。
💡专业提示:💡
- 如果你的图像非常大,你可以考虑增加裁剪尺寸。然而,请注意你需要一块性能强劲的GPU,否则会遇到内存错误!
- 如果你的图像非常小,你可以考虑减小裁剪尺寸。
另外,裁剪的帧数由变量cropratio定义,默认设置为0.4。这意味着有$40%$当前批次中的图像将被裁剪。默认情况下,这个值可以正常工作。
每个裁剪图像之间的裁剪位移由max_shift变量定义,该变量表示相对于裁剪中心位置的最大相对位移。默认情况下为0.4,这意味着在训练过程中,每次遇到相同图像时,它将从中心最大偏移40%,以避免每次应用相同的裁剪——这对于density和 hybrid裁剪方法尤为重要。
下图经过修改自2。
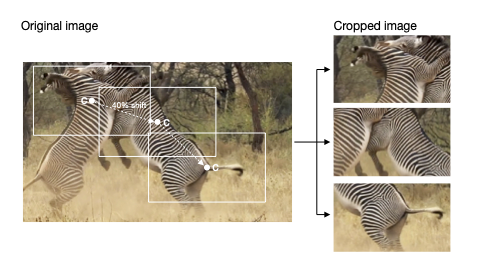
同样,根据图像的不同外观,我们可以使用不同的裁剪采样方法(crop_sampling)。
💡专业提示:💡
- 对于高度拥挤的场景,
hybrid和density方法效果最佳.。 uniform将随机裁剪图像的部分,完全不考虑注释。- 以一个随机关键点为中心并基于该位置进行裁剪——如果使用合理的 crop_size,可能是保留整个动物的最佳选择。
在图像处理中,核滤波器非常流行,用于锐化和模糊图像。直观地讲,模糊图像可能会增加测试过程中对运动模糊的抵抗力。另一方面,用于数据增强的锐化可以捕捉更多感兴趣对象的细节。
在DeepLabCut的pose_config.yaml文件中,默认情况下,sharpening设置为False,但如果我们想使用这种数据增强,可以将其设置为True并指定sharpenratio,默认值为 0.3。模糊在pose_config.yaml文件中没有定义,但如果用户觉得方便,可以将其添加到数据增强管道中。
下图修改自2.

关于锐度,我们还有一个额外的参数,edge增强,它可以增强图像的边缘对比度以提高其表观锐度。同样,默认情况下,此参数设置为False,但如果你想包含它,只需将其设置为True。
- Cao, Z., Simon, T., Wei, S. E., & Sheikh, Y. (2017). Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (pp. 7291-7299).https://openaccess.thecvf.com/content_cvpr_2017/html/Cao_Realtime_Multi-Person_2D_CVPR_2017_paper.html
- Mathis, A., Schneider, S., Lauer, J., & Mathis, M. W. (2020). A Primer on Motion Capture with Deep Learning: Principles, Pitfalls, and Perspectives. In Neuron (Vol. 108, Issue 1, pp. 44-65). https://doi.org/10.1016/j.neuron.2020.09.017
- Ghiasi, G., Cui, Y., Srinivas, A., Qian, R., Lin, T.-Y., Cubuk, E. D., Le, Q. V., & Zoph, B. (2020). Simple Copy-Paste is a Strong Data Augmentation Method for Instance Segmentation (Version 2). arXiv. https://doi.org/10.48550/ARXIV.2012.07177
- Shorten, C., & Khoshgoftaar, T. M. (2019). A survey on Image Data Augmentation for Deep Learning. In Journal of Big Data (Vol. 6, Issue 1). https://doi.org/10.1186/s40537-019-0197-0