![]()

"In natural language processing, a word embedding is a representation of a word. The embedding is used in text analysis. Typically, the representation is a real-valued vector that encodes the meaning of the word in such a way that the words that are closer in the vector space are expected to be similar in meaning".
Source: Wikipedia - Word embedding
"A Vector Database is a specialized system designed to efficiently handle high-dimensional vector data. It excels at indexing, querying, and retrieving this data, enabling advanced analysis and similarity searches".
Source: Qdrant - What is a vector database?
"Sparse vectors [...] focus only on the essentials. In most sparse vectors, a large number of elements are zeros. When a feature or token is present, it’s marked—otherwise, zero. Sparse vectors, are used for exact matching and specific token-based identification".
Source: Qdrant - What is a vector database?
"Dense vectors are, quite literally, dense with information. Every element in the vector contributes to the semantic meaning, relationships and nuances of the data. [...] Together, they convey the overall meaning of the sentence, and are better for identifying contextually similar items".
Source: Qdrant - What is a vector database?
"Information retrieval (IR) in computing and information science is the task of identifying and retrieving information system resources that are relevant to an information need"
Source: Wikipedia - Information Retrieval
- Retrieval Augmented Generation (RAG) is growing in importance
- As of December 2024, more than 10,000 models are available within the sentence-transformers python library
- It's not always easy to understand what's the best embedding technique (sparse or dense) and the best embedding model for our use case
- It's often complicated to evaluate embeddings on different data types
Important
SenTrEv (Sentence Transformers Evaluator) is a python package that is aimed at running simple evaluation tests to help you choose the best embedding model for Retrieval Augmented Generation (RAG) with your text-based documents.
python3 -m pip install sentrev- Highly integrated within the Qdrant environment
- FastEmbed sparse encoding models
- Sentence Transformers dense encoding models
Important
Supports most of the text-based file formats (.docx, .pptx, .pdf, .md, .html, .xml, .csv, .xlsx)
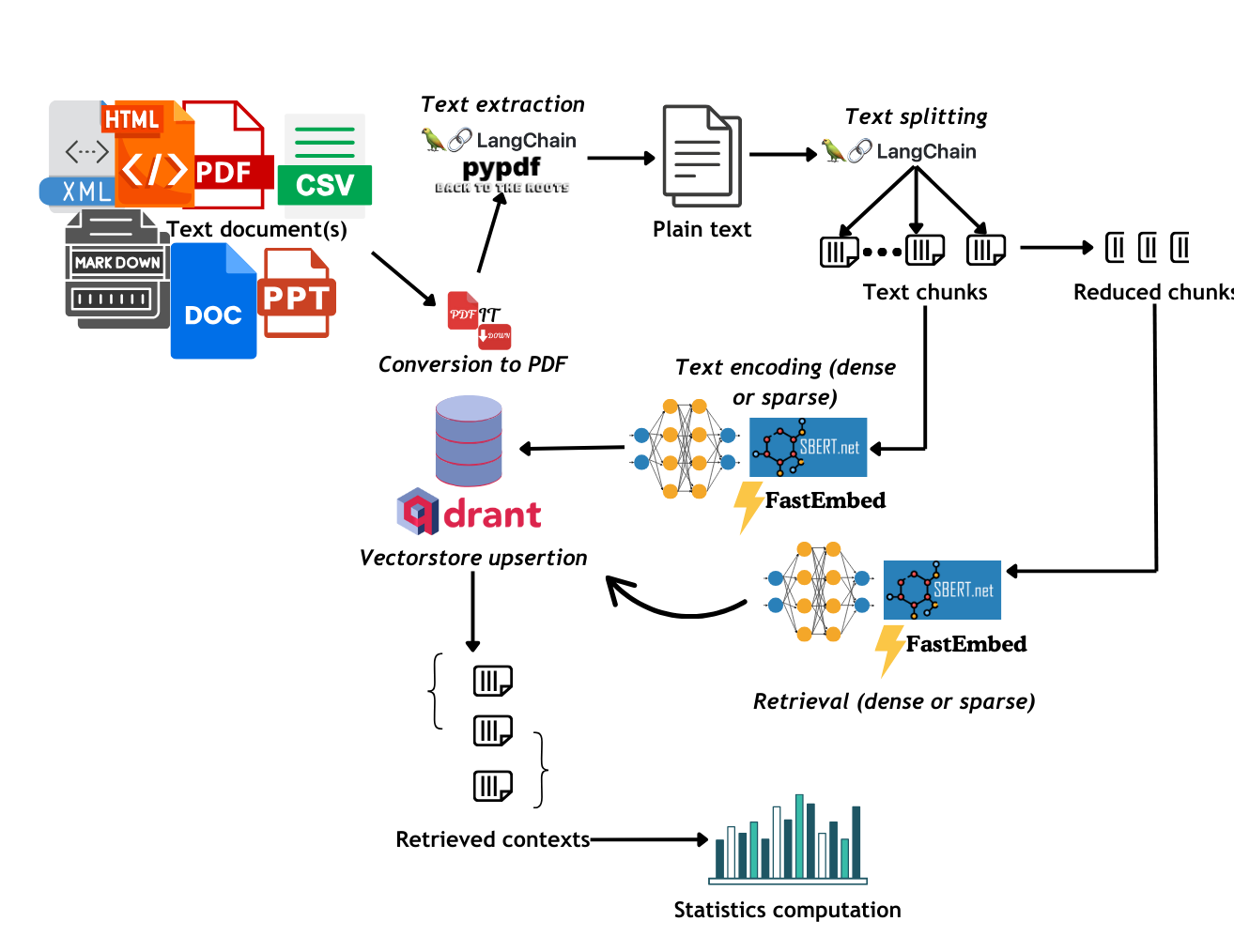

- Success rate: defined as the number retrieval operation in which the correct context was retrieved ranking top among all the retrieved contexts, out of the total retrieval operations
- Mean Reciprocal Ranking (MRR): MRR defines how high in ranking the correct context is placed among the retrieved results.
- Precision: Number of relevant documents out of the total number of retrieved documents. .
- Non-Relevant Ratio: Number of non-relevant documents out of the total number of retrieved documents
Note
Relevance is based on the "page" metadata entry: if the retrieved document comes from the same page of the query, the document is considered relevant.
- Time performance: Average duration for a retrieval operation
- Carbon emissions: Carbon emissions are calculated in gCO2eq (grams of CO2 equivalent) through the Python library
codecarbon.

Note
This simply means that there are lots of other greenhouse gases (methane, clorofluorocarbons, nitric oxide…) which all have global warming potential: despite our emissions being mainly made up by CO2, they encompass also these other gases, and it is easier for us to express everything in terms of CO2. For example: 1 kg of emitted methane can be translated into producing 25 kg of CO2e.
codecarbonworks with a scheduler and every 15s measures the carbon intensity of your running code based on the local grid (country or regional if on cloud)
"Carbon Intensity of the consumed electricity is calculated as a weighted average of the emissions from the different energy sources that are used to generate electricity, including fossil fuels and renewables." See here

from sentence_transformers import SentenceTransformer
from qdrant_client import QdrantClient
from fastembed import SparseTextEmbedding
from sentrev.evaluator import evaluate_dense_retrieval, evaluate_sparse_retrieval
import os# Load all the dense embedding models
dense_encoder1 = SentenceTransformer('sentence-transformers/all-mpnet-base-v2', device="cuda")
dense_encoder2 = SentenceTransformer('sentence-transformers/all-MiniLM-L12-v2', device="cuda")
dense_encoder3 = SentenceTransformer('sentence-transformers/LaBSE', device="cuda")
# Create a list of the dense encoders
dense_encoders = [dense_encoder1, dense_encoder2, dense_encoder3]
# Create a dictionary that maps each encoder to its name
dense_encoder_to_names = { dense_encoder1: 'all-mpnet-base-v2', dense_encoder2: 'all-MiniLM-L12-v2', dense_encoder3: 'LaBSE'}
# Load all the sparse embedding models
sparse_encoder1 = SparseTextEmbedding("Qdrant/bm25")
sparse_encoder2 = SparseTextEmbedding("prithivida/Splade_PP_en_v1")
sparse_encoder3 = SparseTextEmbedding("Qdrant/bm42-all-minilm-l6-v2-attentions")
# Create a list of the sparse encoders
sparse_encoders = [sparse_encoder1, sparse_encoder2, sparse_encoder3]
# Create a dictionary that maps each sparse encoder to its name
sparse_encoder_to_names = { sparse_encoder1: 'BM25', sparse_encoder2: 'Splade', sparse_encoder3: 'BM42'}# Collect data
files = ["~/data/attention_is_all_you_need.pdf", "~/data/generative_adversarial_nets.pdf", "~/data/narration.docx", "~/data/call-to-action.html", "~/data/test.xml"]- Pull and run Qdrant locally with Docker:
docker pull qdrant/qdrant
docker run -p 6333:6333 -p 6334:6334 qdrant/qdrant- Use the python API to create the client:
# Create Qdrant client
client = QdrantClient("http://localhost:6333")# Define CSV path where the stats will be saved
csv_path_dense = "~/evals/dense_stats.csv"
csv_path_sparse = "~/evals/sparse_stats.csv"
# Run evaluation for dense retrieval
evaluate_dense_retrieval(files, dense_encoders, dense_encoder_to_names, client, csv_path_dense, chunking_size = 1500, text_percentage=0.3, distance="dot", mrr=10, carbon_tracking="AUT", plot=True)
# Run evaluation for sparse retrieval
evaluate_sparse_retrieval(files, sparse_encoders, sparse_encoder_to_names, client, csv_path_sparse, chunking_size = 1200, text_percentage=0.4, distance="euclid", mrr=10, carbon_tracking="AUT", plot=True)Important
Find the full code reference on the GitHub repository
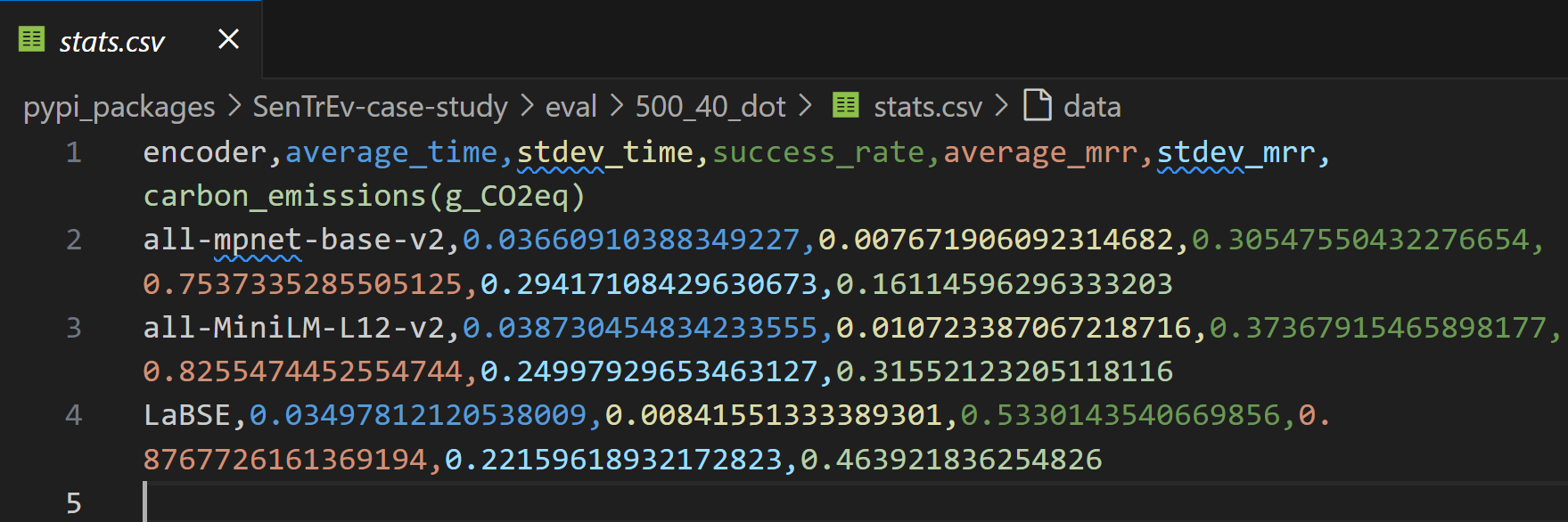
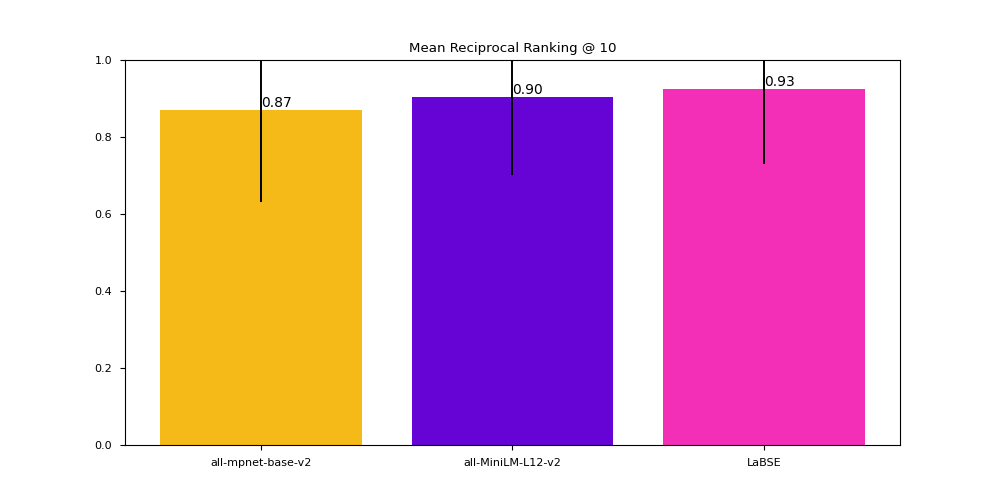
Important
Feedback and contributions are always welcome!