- Différences entre BI et "Big" Data
- Concepts d’architecture Décisionnelle
- Concepts d’architecture Data
- Rapide chronologie de la "Big" Data
- Définition du "Big Data" et 3V + 2
- Les grands types de traitement de la Big Data
- Le Data pipeline
- Les acteurs de la Data
- Exemples de use cases par secteur d’activité
- Théorème CAP des systèmes distribués
- Garantie de traitement des messages
- Data lake vs Data warehouse vs Data lakehouse
- Data Mesh vs Data Fabric
- Data management
- Ressources
- Ressources full list
- Lexique
La BI (Business Intelligence, ou Informatique Décisionnelle) correspond à un ensemble d’outils et de procédés ayant pour finalité de capturer et valoriser les données afin de les mettre à disposition d’une organisation.
La BI va sélectionner les données jugées utiles, et les structurer de façon à rendre possible et aisé leur analyse, puis à proposer les résultats de cette analyse sous forme de différents schémas et dashboards.
La BI va principalement se baser sur des statistiques descriptives, permettant de décrire les données que l’on a (le passé).
De son côté la "Big" Data, discipline plus récente que la BI, va potentiellement faire la même chose, MAIS en en étendant les possibilités, en supprimant certaines contraintes, AU PRIX DE CERTAINS COMPROMIS.
En l’occurrence, les systèmes "Big" Data ne vont PLUS sélectionner (filtrer) et structurer les données au moment de leur collecte, ils vont les ingérer telles quelles (ingestion extrêmement massive de données au format brut).
Du temps de la création des systèmes BI, il était physiquement impossible de stocker pareille volumétrie, d’où les phases préalables de sélection / filtrage, que l’on pouvait dès lors faire suivre d’une phase de structuration qui permettait à la donnée d’être directement requêtable.
Néanmoins, si les systèmes "Big" Data "rendent possible ce qui ne l’était pas avec la BI", c’est au prix d’une plus grande complexité de manipulation des données (gestion de données hétérogènes là où la BI ne traite que des données structurées) et des architectures associées (systèmes distribués).
La "Big" Data ne permet PAS de traiter 20 ans d’historique de données en 1 claquement de doigts, mais elle rend possible la collecte et le traitement de ces 20 ans de données en un certains temps.
La "Big" Data va également s’appuyer sur des statistiques différentielles, et de plus fortes capacités prédictives afin de pouvoir se projeter dans le futur (domaine de la Data Science et de ses prédictions).
Ressources :
-
définition Big Data : https://www.cnil.fr/fr/definition/big-data
-
différences Big Data et BI :
Les utilisateurs finaux de ces derniers sont généralement des clients (internes ou externes).
Si des traitements coûteux sont réalisés sur ces outils en plus des opérations de clients, l’expérience utilisateur pourrait être dégradée.
|
❗
|
Grand principe : on ne doit JAMAIS dégrader l’expérience utilisateur. |
Un modèle de données applicatif doit être pensé pour faciliter le fonctionnement de l’application à laquelle il est associé.
Exemples : création d’utilisateur, validation et enregistrement d’une transaction bancaire, etc.
Un modèle de données décisionnel doit être pensé pour faciliter l’analyse transverse des informations du domaine étudié.
Ce domaine peut regrouper les données de plusieurs applications différentes, chacune possédant leur propre modèle de données applicatif.
Aussi, il s’agit bien de modèles DIFFERENTS.
Le modèle de données applicatif est très souvent représenté par des tables liées les unes ou autres par de multiples relations (Foreign Key), sur un niveau de profondeur pouvant être élevé.
Ce modèle n’est PAS adapté à un requêtage analytique, qui va avoir pour but de rassembler les données suivant certains critères préétablis (une même région, un même type d’utilisateur, etc.)
Il est techniquement possible d’exécuter une requête analytique sur un modèle applicatif, mais celle-ci pourrait alors être très consommatrice de ressources, et dégrader les opérations réalisées en parallèle par les utilisateurs finaux, ce qui est A PROSCRIRE.
Pour permettre un requêtage de données efficace, le modèle de données décisionnel va chercher à dénormaliser, c’est à dire à "mettre à plat", les données du modèle applicatif.
Cette mise à plat va donner lieu à la création d’une table principale, contenant les informations fonctionnelles que l’on souhaite requêter, ce qu’on appelle une table de faits.
Cette table principale ne pouvant pas non plus contenir à elle seule toutes les données du modèle applicatif, les données correspondant aux regroupements dont nous aurons besoin formeront un ensemble de tables directement liées à la table de faits, qu’on appelle les tables satellites ou dimensions.
Exemple :
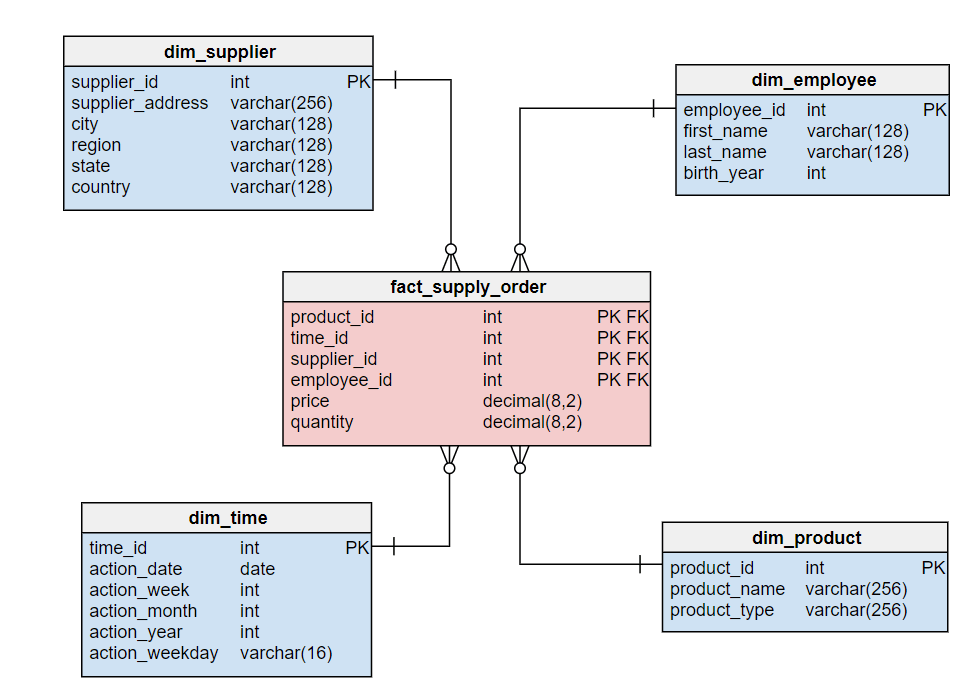
Comme expliqué plus haut, la plupart des modèles de données applicatifs (utilisés par la majorité des outils de gestion) sont des modèles relationnels normalisés, à savoir des modèles proches des outils transactionnels et basés sur la notion de dépendance fonctionnelle (entité - relation).
Avantages :
-
Ces modèles sont conçus et performants pour l'ajout, la mise à jour et la suppression de petites quantités de données.
-
Le requêtage s’effectue de façon presque systématique avec le langage SQL, dont les bases sont connues par la plupart
Inconvénients :
-
Les informations peuvent être "noyées dans la masse" : beaucoup de tables et beaucoup de relations entre elles
-
Les entités modélisées ne correspondent pas forcément aux centres d’intérêt des analystes métier (normal, elles ont été initialement conçues pour correspondre à un use case, et non aux besoins des analystes)
-
Les potentiellement nombreuses jointures nécessaires à la récupération / agrégation des données peuvent avoir un impact fort sur les performances
De son côté, le modèle en étoile est une modélisation dimensionnelle devant permettre de dissocier technologie (stack technique) et modélisation, et de structurer l’information en vue de son analyse. Cette modélisation est particulièrement bien adaptée aux besoins des systèmes d’information décisionnels qui la choisissent quasi systématiquement.
Cette modélisation contient 2 éléments :
-
des tables de faits : ces dernières contiennent les mesures le long des attributs d’une table de dimensions.
-
Ces mesures sont souvent des valeurs numériques pouvant être la cible d’une fonction (la plus courante étant une simple addition)
-
-
des tables de dimensions : ces dernières contiennent les attributs le long desquels la table de faits calcule la métrique.
-
Ces attributs sont souvent des informations de type alphanumérique.
-
Avantages :
-
Donne une vision métier de l’information
-
Facilite la navigation dans le modèle (à des fins exploratoire)
-
Les jointures étant limitées, les performances sont améliorées
-
La complexité des requêtes est moindre, comparée à un modèle relationnel, pour l’obtention d’un même résultat (l’accès à la donnée est plus "directe" : table de faits → dimensions)
-
La modification du modèle est (plus) aisée (il est facile d’ajouter une nouvelle table de faits ou de dimensions)
Inconvénients :
-
Contrairement aux données normalisées du modèle relationnel, la duplication de données existe au sein des tables de dimensions.
-
Ce modèle est avant tout dédié à des use cases d’analyse métier (récupération, "lecture" de données). Il n’est pas adapté à des besoins de mises à jour fréquentes (du fait des données dupliquées)
-
Son alimentation peut être complexe (car elle est souvent réalisée à partir d’un modèle relationnel, normalisé, correspondant aux outils de gestion en amont. Il faut donc faire rentrer des "ronds dans des carrés").
La modélisation en étoile est recommandée par tous les outils de BI (PowerBI, Tableau, Qlick Sense, etc.).
Les tables de dimensions prennent en charge le filtrage et le regroupement des données, et les tables de faits prennent en charge les opérations / totalisations pouvant apparaître dans le rapport.
Ressources :
-
Différences entre tables de faits et tables de dimensions : https://fr.gadget-info.com/difference-between-fact-table
-
1997 : 1ere apparition du terme "Big Data" à la NASA, pour désigner les nouveaux défis associés au travail avec de larges volumes de données non structurées
-
1998 : 1ere apparition du terme NoSQL avec la création de la BDD "Strozzi NoSQL" par Carlo Strozzi
Cette base n’est PAS à assimiler avec les BDD dites "NoSQL" (Not Only SQL) qui datent plutôt de 2009. A l’époque Carlo lui a donné ce nom car elle n’utilisait PAS le SQL pour le requêtage (mais c’est néanmoins la 1ere apparition du terme "NoSQL")
Pour rappel, les BDD dites "NoSQL" sont regroupées en 4 principaux types : clé / valeur, orienté colonnes, documents, et graphes. -
2000 : création de la BDD NoSQL orientée graphe Neo4j
-
2001 : 1ere définition du "Big Data" (avec ses 3V) par Gartner
-
2005 : création de Hadoop
-
2005 : création de CouchDB (BDD NoSQL orientée documents)
-
2006 : publication par Google de son papier de recherche "Google Bigtable"
-
2006 : Amazon commence à proposer des services de Cloud computing via Amazon EC2 (Elastic Compute Cloud)
-
2007 : création de la BDD NoSQL HBase (de type wide column stores)
-
2007 : création de la BDD orientée colonnes Amazon Dynamo
-
2007 : création de MongoDB (BDD NoSQL orientée documents), et de la société 10Gen la développant (devenue de nos jours MongoDB Inc)
-
2008 : lancement de Google App Engine
-
2008 : création de la BDD NoSQL Cassandra (de type wide column stores)
-
2008 : création de la distribution Hadoop Cloudera
-
2008 : Hadoop bat le record "Terabyte sort Benchmark"
-
2009 : création du framework de traitement de données Flink, très orienté stream-processing
-
2009 : création de la BDD NoSQL clé / valeur Redis
-
2009 : création de la société MapR, éditant la distribution Hadoop du même nom
-
2009 : création d’Apache Mesos (gestionnaire de ressources, clusters)
-
2009 : création de Spark (framework de traitement de données en parallèle, devenu aujourd’hui le leader du marché)
-
2010 : création de la BDD NoSQL Cassandra, et de la société DataStax l’éditant
-
2010 : lancement de Microsoft Azure
-
2010 : Le stream processing commence à prendre le dessus sur le batch processing (avec la montée en puissance des smartphones et de l’IoT)
-
2011 : création de la société Hortonworks, éditant la distribution Hadoop du même nom
-
2011 : lancement de Google Cloud Platform
-
2012 : YARN est créé et devient le gestionnaire de ressources des stacks Hadoop (dites Hadoop v2)
-
2012 : création de Apache Kafka, distributed messaging system à très haut débit (utilisé dans presque tous les workflows Data orientés streaming)
-
2013 : création de la société DataBricks, principal contributeur du framework Spark
-
2013 : l’IoT (Internet of Things) se généralise et commence à toucher tous les domaines
-
2013 : le marché de la "Big Data" est estimé à 10 milliards $
-
2014 : Spark bat le record "Terabyte sort Benchmark"
-
2014 : L’Internet mobile dépasse l’Internet sur desktop
-
2014 : On essaye de gérer en même temps batch processing et stream processing (architectures Lambda et assimilées), reste compliqué
-
2016 : avènement du Cloud computing
-
2017 : sortie de Hadoop v3.0, et "début de la fin" pour Hadoop (principalement pour causes de complexité)
-
2018 : les entreprises utilisant des solutions étiquetées "Big Data" sont passées de 17% en 2015 à 59% en 2018
-
2020 : le marché de la "Big Data" est estimé à 200 milliards $
-
2020 : on estime à 10 milliards le nombre d’appareils connectés à Internet
-
2027 : le marché de la "Big Data" est estimé à 420 milliards de $
Par Big Data, on entend la production massive et hétérogène de données numériques par les entreprises et les particuliers, dont les caractéristiques (très grand volume, diversité de forme, vitesse attendue de traitement) requièrent de nouveaux moyens de stockage et d’analyse.
Comment savoir si vous êtes dans un cas de "Big Data" ? Et comment définir ces ensembles de données ?
Depuis l’apparition de ce terme en 1997 du côté de la NASA, les ensembles de données traités correspondant à la définition du "big data" répondent à 3 caractéristiques principales, appelées les "3V" : volume, vélocité et variété.
-
Volume : qualifie une volumétrie importante qui ne peut pas être traitée par les solutions classiques (les "anciennes" du monde de la BI).
On commence généralement à parler de "big" data à partir de plusieurs dizaines de Tera octets, et il n’y a pas de plafond (plusieurs dizaines d’Exa octets pour le stockage total de YouTube par exemple)
La règle dite des 3 "100" est également utilisée pour qualifier comme des systèmes comme "Big" Data ou pas.Avec nombre d’éléments = nombre de lignes x nombre de colonnes :-
de 10 à 100 millions d’éléments : Excel ou JSON
-
de 10 à 100 milliards d’éléments : BDDR (Postgre / Oracle)
-
plus de 100 milliards d’éléments : on sort les "vraies" techno "Big" Data
-
-
Vélocité : capacité à traiter des données en quasi temps réel.
Le besoin de performance impliqué par cette caractéristique tire souvent les concepts d’IA et de Machine Learning (analyse prédictive et approximative sur un échantillon de données) -
Variété : capacité à stocker et traiter des données hétérogène, structurées (tables de BDDR), semi-structurées (JSON, CSV), non structurées (texte sans schéma, binaires)
A ces 3 caractéristiques principales, d’autres sont venues s’ajouter avec les années, dont les plus 2 plus courantes sont la véracité et la valeur :
-
Véracité : l’un des enjeux majeur de l’exploitation des "Big" Data, tiré par l’actualité et les besoins croissants en matière de sécurité.
Face aux faux profils sur les réseaux sociaux, aux différentes tentatives de fraudes, ou simplement aux fautes d’orthographe, il est nécessaire de multiplier les précautions (recoupement et enrichissement des données) pour minimiser les biais liés au manque de fiabilité des "Big" Data ("on commence par tout stocker, et on ne traite, et donc contrôle, qu’après"). -
Valeur : Les données stockées n’ont de sens que si elles apportent de la valeur ajoutée. Si on n’exploite ces données, c’est pour répondre à des objectifs business.
Cette caractéristique tire les concepts de MDM (Meta Data Management) et Data Governance, où l’on va chercher à qualifier la data (que veut-elle dire, notion de data dictionary, gestion des schémas des données ,etc.
-
Batch : Les traitements vont analyser l’ensemble des données disponibles depuis leur collection jusqu’à maintenant.
Ces traitements sont associés aux plus grandes volumétrie de données, avec des historiques de données de plusieurs années ou dizaines d’années.
Il s’agit du use case originel de la "Big" Data (traitement de logs)
Les données en entrée sont généralement des fichiers (stockés dans un système de fichiers distribué comme un HDFS (on-premise), Amazon S3, Azure ADLS ou Google Cloud Storage.
La durée des traitements peut aller de la minute à plusieurs heures. -
Micro-batch : Les traitement vont analyser de petits groupes de données, ou des données mises à disposition sur un (court) intervalle de temps donné.
Les données en entrée sont généralement de petits fichiers, où mises à disposition via un système de messaging (comme Kafka)
La durée des traitements est généralement de l’ordre de quelques secondes (peut-être moins)
Exemple de technologie : Spark Streaming, qui contrairement à son nom fait du micro-batch et PAS du "vrai" streaming / TR (micro-batch d’une durée minimale de 500 ms)
-
Temps réel (streaming) : Les traitements vont analyser les données au fur et à mesure de leur disponibilité (la donnée est traitée unitairement, dès que disponible).
Les données en entrée proviennent quasi exclusivement de systèmes de messaging comme Kafka.
Les résultats sont disponibles au fur et à mesure de l’exécution des traitements.


/filters:no_upscale()/articles/how-to-choose-stream-processor/en/resources/2how-to-choose-stream-processor-1-1534951780033.jpg "How to Choose a Stream Processor for Your App")
Une architecture Data sera toujours rapprochée, à un moment ou un autre, à un pipeline de traitement des données (Data pipeline) constitué des couches suivantes :
-
ingestion
-
traitement
-
analyse / visualisation
-
stockage

-
Data Engineer :
Le data engineer est responsable du développement des programmes d'ingestion et de traitement de la donnée.
Cela inclut :-
Conception
-
Développement
-
Déploiement
-
Test
-
Maintenance du code
Il convertit les données dans des formats pouvant être stockés dans le cluster, puis analysés pour résultat (dataviz / BI).
Les langages de programmation généralement utilisés sont Java, Scala et Python.
La programmation fonctionnelle est très adaptée à l’implémentation des transformations sur les données. -
-
Administrateur :
L’administrateur Data est responsable de l’installation et de la maintenance des composants matériels et logiciels utilisés dans le Data pipeline.
Suivant les technologies utilisées (Cloud ou on-premise (Hadoop)), cela inclut :-
Configuration des nodes du cluster
-
Gestion des utilisateurs
-
Gestion de la sécurité
-
Tests de la performance de la solution (benchmarks)
-
Mise à jour logicielle
-
Plan de reprise d’activité
-
Gestion du stockage physique (le matériel, les serveurs) et logique (organisation des données en topologies) des données
Il doit avoir de bonnes connaissances en langages de script, et connaître les systèmes Linux.
-
-
Data Scientist :
Le Data scientist a la lourde tâche de révéler (ou créer) la valeur ajoutée potentiellement cachée dans grands volumes de données (souvent non structurées)
Parmi ses missions on retrouve :-
Collecter et convertir de larges quantités de données en informations exploitables
-
Détecter des tendances dans les ensembles de données
-
Communiquer avec les différents responsables de l’entreprise, ce qui inclut la création de rapports destinés à la direction
-
-
Data Analyst :
Le Data analyst est responsable de l’analyse des données.
Cela inclut :-
Data mining
-
Extraction des données
-
Normalisation
-
Filtrage
-
Agrégation
-
Requêtage
-
Interprétation
-
Production de graphiques
-
Réalisation de prédictions
Ils fournissent les capacités de Business Intelligence (BI), et utilisent les outils de visualisation associés (PowerBI, Tableau, etc.) pour créer des graphiques et présentations permettant d’exposer leurs conclusions.
Le Data analyst connaît bien les langages fonctionnels et de scripting tel que Python, R, ainsi que le SQL.
Il a un gros bagage mathématique (statistiques) -
-
Data Steward (coordinateur de données) :
le Data steward est un nouveau rôle (~2020), poussé par la maturité croissante du monde de la Data, et la prise en compte de certains nouveaux problèmes : données inutiles, failles de sécurité, données non maîtrisées (data swamps), etc.
Les principales missions du Data steward concernent l'organisation et la qualité des données :-
Organiser les données : réception, stockage, transmission
-
vérifier que chaque donnée est bien identifiée / référencée, et est prête à être utilisée
-
Assurer la qualité de la data : supprimer les doublons et les parties inutiles, la mettre à jour régulièrement
-
Gérer l’accès aux données (tout particulièrement la sécurisation de l’accès aux données)
-
-
Data Architect :
Le Data architect est responsable de la définition globale de la solution Big Data à mettre en place pour répondre aux besoins du projet.
C’est principalement lui qui définit les blocs logiciels du data pipeline, et comment ces derniers interagissent. -
Chief Data Officer (directeur des données) :
Le CDO est l’interface entre les équipes Data et la direction.
Il doit définir et s’assurer de la mise en place d’un environnement permettant à chaque personne de l’entreprise d’accéder aux données dont elle a besoin facilement et en toute sécurité.
Ses missions consistent donc à :-
Créer un environnement "Big" Data adapté à son entreprise
-
Développer une stratégie Data driven (Data Management Strategy), et choisir les données à analyser
-
Assurer la qualité et la cohérence des données (gouvernance des données)
-
acquérir de nouvelles sources de données permettant à l’entreprise d’atteindre ses objectifs
-
| Secteur d’activité | Use Cases |
|---|---|
Secteur public |
Analyse des fraudes, analyse des risques |
Service financier (banque / assurance) |
Fidélisation, analyse des fraudes, analyse de réputation, scoring, analyse des risques |
Santé |
Analyse des fraudes, diagnostique, suivi épidémiologique |
Télécoms |
Analyse des fraudes, ciblage marketing, analyse de conformité, optimisation des prix (dynamic pricing) |
e-commerce |
Fidélisation, réduction du Time To Market, vue client 360, amélioration du taux de transformation en achat, optimisation de prix (dynamic pricing) |
Transports |
Optimisation des trajets / livraison, maintenance prédictive, optimisation des prix (dynamic pricing) |
Energie |
Optimisation de la consommation énergétique, vue client 360, ciblage marketing |
Le théorème CAP explique qu’un système informatique de traitement/stockage distribué ne peut PAS garantir en même temps les 3 contraintes suivantes :
-
Consistency (cohérence) : Tous les noeuds du système voient exactement les mêmes données au même moment.
En cas d’écriture sur un noeud A, une lecture sur le noeud B renvoie la nouvelle valeur instantanément (ce qui exclut donc de fait les architectures décentralisées) -
Availability (disponibilité) : Garantie que toutes les requêtes reçoivent une réponse (que ce soit un succès ou un échec).
-
Partition tolerance (tolérance au partitionnement) : Aucune défaillance de tout ou partie des noeuds du cluster ne doit empêcher le système de répondre correctement.
En cas de morcellement en sous-réseaux, chacun doit pouvoir fonctionner de manière autonome.
D’après ce théorème, un système distribué ne peut garantir à un instant "t" que 2 de ces contraintes, mais PAS les 3.
Un compromis est donc à définir lors de l’analyse de toute nouvelle solution, devant déboucher sur un choix parmi 3 catégories :
-
Les systèmes CP
-
Les systèmes AP
-
Les systèmes CA
|
📎
|
Il est à noter que le "P", la tolérance au partitionnement est une composante essentielle de tout système distribué. |
Ces systèmes privilégient la cohérence, le "C", à la disponibilité, le "A".
Ils vont avant tout éviter de retourner une donnée périmée (à savoir ne correspondant pas à la toute dernière modification apportée), et même préférer retourner une erreur.
Si la donnée est présente sur n noeuds, alors tous les n doivent être opérationnels.
Les cas d’utilisation privilégiés de ces solutions sont les systèmes où la valeur de la donnée est préférable à une haute disponibilité.
Ils ne sont donc pas conseillés dans des systèmes e-commerce, mais beaucoup plus adaptés aux domaines bancaire et santé.
Exemple de systèmes CP : MongoDB, HBase, Hazelcast
Ces systèmes privilégient la disponibilité ("A") plutôt que la cohérence, même si ce choix peut souvent se décider au moment de la configuration du système.
Ces systèmes ne vont donc pas obligatoirement retourner la dernière valeur d’une donnée (du fait du temps de réplication de la valeur dans le cluster).
Ce délai, appelé entropie, est souvent très faible (de l’ordre de la ms), mais bien réel.
Du fait de cette désynchro, ces systèmes sont à privilégier quand la disponibilité est la principale problématique (ex : site marchand)
Cette catégorie, ne comprenant PAS la tolérance au partitionnement (le "P") regroupe tous les systèmes de type maître / esclave, ou non distribués.
Les données ne sont PAS répliquées, ou le sont obligatoirement de manière synchrone.
On privilégie la fraîcheur et la disponibilité des données aux performances.
Ces systèmes ne sont donc pas adaptés à des besoins de temps réel, et l’indisponibilité en cas de crash peut être conséquente.
-
CAP theorem :
-
transactions ACID : https://searchsqlserver.techtarget.com/definition/ACID
📎Rappel sur les transactions ACIDACID (atomicity, consistency, isolation, and durability) is an acronym and mnemonic device for learning and remembering the four primary attributes ensured to any transaction by a transaction manager (which is also called a transaction monitor).
These attributes are:-
Atomicity : In a transaction involving two or more discrete pieces of information, either all of the pieces are committed or none are.
-
Consistency : A transaction either creates a new and valid state of data, or, if any failure occurs, returns all data to its state before the transaction was started.
-
Isolation : A transaction in process and not yet committed must remain isolated from any other transaction.
-
Durability : Committed data is saved by the system such that, even in the event of a failure and system restart, the data is available in its correct state.
-
Les systèmes de traitements distribués sont souvent répartis en différentes catégories fonction de leurs garanties de traitement (ou garanties de livraison) des messages :
-
Pas de garantie : chaque message peut être traité / délivré 1 fois, plusieurs fois, ou pas du tout
-
At least once : chaque message peut être traité / délivré au moins 1 fois
-
At most once : chaque message est traité / délivré exactement 1 fois OU pas du tout (d’où des pertes possibles).
C’est la garantie dite du "best effort". -
Exactly once : chaque message est traité / délivré exactement 1 fois
-
Effectively once : la version "pragmatique" de l'"exactly once", qui peut être très difficile à obtenir "au pied de la lettre" dans un système distribué ("pour 1 message, je ne fais qu'1 tentative de traitement qui donne bien lieu à 1 unique traitement").
L’effectively once s’appuie sur le concept d'idempotence du traitement du message (l’état du système reste le même après un ou plusieurs appels du traitement, comme par exemple une instruction "upsert"). On pourra donc traiter plusieurs fois un même message, MAIS le résultat sera toujours le même.
Un autre moyen d’atteindre l'"effectively once", à partir de systèmes at least once (systèmes très courants) ne pouvant utiliser d’opérations idempotentes, est d’ajouter une phase de déduplication aux traitements (on vient supprimer le doublon provenant du "retraitement" d’un message)
Idéalement, nous souhaitons un système de type exactly once, qui est la garantie la plus facile à intégrer dans une architecture (elle garantie de facto l’absence de doublons de data), mais qui est également la garantie la plus difficile à obtenir techniquement dans un système distribué.
La garantie effectively once peut représenter un bon compromis, même si pouvant également être difficile à obtenir.
Si votre système supporte la duplication données, s’appuyer sur des systèmes at least once serait la solution à privilégier dans la plupart de cas. Ces systèmes sont faciles à implémenter et très largement répandus dans la plupart des outils.
Et pour peu que vous puissiez tendre vers des opérations idempotentes, vous pourriez au final obtenir un système garantissant l'effectively once.
Les Data warehouses sont conçus pour stocker des données structurées, connues et bien définies, qu’ils vont organiser sous forme de datasets dans tables et colonnes.
Ces données sont dès lors facilement exploitables par les utilisateurs pour de la BI classique, via dashboards et reportings.
Classiquement, les Data warehouse s’appuient sur une architecture 3 tiers :
-
Bottom tier : cette couche de persistance va permettre de regrouper et de structurer les données en provenance des différentes sources (notion de staging area).
Cette porte d’entrée du data warehouse est souvent feedée par un ETL (Extract / Transformation / Load), permettant de réaliser les opérations de structuration de données dans la foulée de leur ingestion. -
Middle tier : la couche des traitements OLAP (OnLine Analytical Processing, les fameux "cubes" bien connus du monde de la BI), visant à réorganiser les données dans un format multidimensionnel adapté à des traitements rapides.
-
Top tier : la couche d’API et des différents outils de dataviz se connectant à la couche Middle.

A ces 3 couches, il faut également ajouter 3 composants particulièrement importants dans un DWH :
-
Les datamarts : ces derniers représentent des sous-ensembles de données issues du DWH, et sont spécifiquement conçus pour répondre à un besoin métier précis.
-
L'Operational Data Store (ODS) : il s’agit d’un conteneur (repo) de données mettant à disposition un snapshot des données les plus récentes de l’organisation, pour du reporting opérationnel, ou des requêtes simples. Quand présent, on le retrouve souvent entre les sources de données et le DWH
-
les metadata : ces données particulières ont pour but de décrire les données (métier) présentes dans le DWH, et sont stockées dans la couche bottom.
Historiquement, les DWH étaient (et restent) des solutions chères en termes de licences (très souvent propriétaires), d’infrastructure (système conjuguant espace de stockage et forte puissance de calcul) et de maintenance (ressources formées sur une technologie propriétaire).
Les grands Use Cases des DWH :
-
Transactional reporting pour fournir une vision de la performance du métier (pour analyser ce qui s’est déjà passé)
-
Reportings et analyses ad-hoc pour répondre à des besoins spécifiques
-
Data mining (fouille ou exploration de données en français) pour extraire la connaissance "cachée" dans la donnée,
Pour une définition plus technique du Data mining, il s’agit du procédé permettant de trouver des corrélations ou des patterns entre de nombreuses bases de données relationnelles. -
Dataviz (Data visualization) dynamique
-
Drill down des dimensions de la data (littéralement la possibilité de passer d’une vue générale sur les données à une vue beaucoup plus spécifique en exploitant les dimensions mises en place)
L'alimentation d’un DWH est très souvent le résultat d’un traitement batch, qui va donner aux données la structure attendue en une phase, qui sera elle-même suivie par une phase d’analyse opéré par le DWH ("pre-processing" permettant aux données d’être "préparées à l’avance" en vue de la dataviz). Durant cette dernière, les données peuvent ne plus être disponibles le temps que les calculs soient terminés.
Les systèmes de type data lake permettent d’adresser en partie cette problématique, sur la base de compromis (cf les "3V" de la Big Data, on ne peut pas tous les avoir en même temps, on ne pourra jamais traiter en 2 sec 20 ans d’historique, sauf à payer des ressources complètement indécentes…)
Les Data lakes ont pour principal but le stockage, la centralisation de tout type de données brutes, à savoir dans leur format d’origine (celui de la source), sans aucune altération.
Ces données peuvent être aussi bien structurées (donneées d’une BDDR) que semi (JSON, CSV) ou non structurées (texte libre, binaires, images)
Elles sont stockées sans créer de lien ou de structure entre elles, ce que l’on va appeler un schéma dans le monde du data warehouse (et des BDDR).
Cette absence de "perte d’information sur la donnée" (toute transformation est une perte d’information en soi) va rendre l’utilisation du data lake pertinent pour les traitements de Machine Learning.
De plus, l’absence d’une phase d’ingestion longue (pas de temps passé à transformer / structurer la donnée) va également faciliter la mise en place de traitements en temps réel / streaming (où une très forte vélocité est attendue)
L’architecture d’un Data lake est quasiment tout le temps séparée en 3 zones :
-
zone Bronze (ou espace "Raw" / landing zone) : C’est là qu’atterrissent les données après avoir été ingérées dans le Data lake, dans leur format d’origine (celui de leur source, ou "as-if" / "as-of"), sans filtrage (on garde tout) ni transformation d’aucune sorte.
Dans le cas de workflow spécifiques de streaming, les données seront agrégées en plusieurs datasets (on ne peut pas réaliser une opération d’écriture par évènement reçu si on en reçoit des millions par seconde…).
Les données de la zone Bronze sont privées, uniquement accessibles à la source de données, qui est responsable de leur ingestion. -
zone Silver (ou espace "Lake") : il s’agit de la zone qui correspond le plus au concept de "Data lake", à savoir un espace où toutes les données se trouvent, ET où elles sont accessibles à tous.
La zone Silver est normalement la seule zone partagée, accessible à tous, d’un Data lake.
Elle est alimentée à partir des données de la zone Bronze, que l’on va formater de façon à les rendre "le plus exploitable possible" par toutes et tous.
C’est toute la difficulté de ce formatage, on ne peut pas rentrer dans la tête de tous pour savoir ce qui lui conviendrait le mieux, ni réussir à trouver un format qui fasse l’unanimité.
Le but est ici de "faire au mieux" et de rendre les données exploitables, et non directement adaptées à l’usage pour un projet spécifique.
L’alimentation de la zone Silver et le formatage des données s’y trouvant sont également la responsabilité de la source des données. -
zone Gold (ou espace "App") : Il s’agit de la zone où les projets, services, applications viennent stocker les données qu’elles auront spécifiquement transformées pour répondre à leurs besoins, depuis la zone Silver.
Tout comme les données d’un DWH, les données de cette zone ont été sélectionnées et structurées. Ainsi, il n’est pas rare que cette zone participe à la mise en place d’un ODS (Operational Data Store), dans le cadre d’une architecture de SID basé sur un Data lake → Data Warehouse (et ODS en "porte d’entrée") → datamarts.
Les données de la zone Gold sont privées, uniquement accessibles au projet les utilisant (logique, c’est ce même projet qui a structuré ces dernières spécifiquement pour réponse à ses besoins) -
Sandbox : cette zone est moins répandue que les 3 dernières, et, comme son nom l’indique, sert pour valider des hypothèses et réaliser des tests.
Il est courant qu’elle intègre la zone Gold (étant donné qu’on a le plus souvent besoin de réaliser des tests sur SES données applicatives, donc celles de la zone Gold).

Si l’on s’en tient strictement aux éléments présentés ci-dessus, un Data lake ne contient pas naturellement de composant permettant des calculs ou un requêtage analytique ou BI.
Aussi il est fréquent de le coupler à d’autres outils assurant ces fonctionnalités, comme un Data warehouse, un notebook, un environnement de calculs analytiques (SAS), etc.
Pour s’assurer que le Data lake ne devienne pas un "dépotoir à données" (data swamp), il est capital de définir dès sa conception la stratégie de gestion de la données (data management strategy) à suivre, qui devra permettre de garantir une bonne qualité de données (data quality).
Cette dernière s’appuie principalement sur 2 piliers : la gouvernance des données (data governance) et la gestion des metadonnées (metadata management).
Dans l’idéal, les données stockées dans un Data lake devraient toutes (via le transit bronze / silver / gold) être cataloguées, indexées, validées et rendues facilement accessibles aux utilisateurs.
Cette stratégie de données a trop souvent été négligée dans la mise en place d’un data lake, ce qui est une des principales raisons pour laquelle nombre de ces projets ont échoués au cours des années passées.
Les grands Use Cases des Data lakes :
-
Implémenter des traitements analytiques complexes et spécifiques sur une très grande volumétrie de données (historique de données)
-
Réaliser des root cause analysis pour remonter à la cause de certains problèmes (analyse rendue possible étant donné que le data lake stocke TOUTES les données)
-
Implémenter des traitements analytiques en streaming
-
Construire des Data pipelines sur-mesure pour répondre à des besoins spécifiques
-
Implémenter des projets de Machine Learning, d'IA (analyse prédictive)
-
Alimenter un Data warehouse
La création de Data pipelines exploitant correctement un Data lake nécessite des compétences de data engineering poussées.
Néanmoins, ces derniers rendent possible d’aller "creuser" la data afin de déceler et de faire émerger une valeur non atteignable avec des outils de type Data warehouse.
Ces Data pipelines permettent de traiter aussi bien des données extrêmement volumineuses (web logs), que des données issues d’un streaming très véloce (capteurs dans un cadre IoT), des use cases inaccessibles aux outils de la BI traditionnelle (Data warehouse).
Pour de nombreux besoins métiers, Data lakes et Data warehouses sont souvent utilisés de concert, pour stocker sans contrainte les données (Data lake), et permettre leur traitement avec des outils classiques et bien connus de la plupart (Data warehouses).
|
📎
|
Architecture d’un data lake dans le Cloud
Schéma simple et clair d’une architecture data lake dans le Cloud, Azure ici : Cette image provient d’un très bon article de 2020 de Lynn Langit sur la construction de data pipelines pour les charges de travail à échelle génomique (donc très grande échelle) : |

Pour rapprocher Data lakes et Data warehouses, et bénéficier de leurs avantages, sans souffrir (ou en souffrant moins) de leurs inconvénients, un nouveau concept est apparu il y a quelques années : le Data lakehouse.
L’architecture d’un Data lakehouse est généralement constituée des éléments suivants :
-
couche de stockage : permet de stocker des données de tout type (structurées, semi-structurées et non structurées), ce en quoi elle peut être assimilée à un Data lake, MAIS en étant découplée de la couche de traitement.
-
couche de traitement : cette couche est responsable des capacités / fonctionnalités d’analyse de données (Data warehousing), de gestion des metadata, des schémas, de transactions ACID (Atomicity, Consistency, Reliability, Durability, caractéristiques d’une transaction pour une base de données relationnelle).
Il est important de noter que dans une architecture lakehouse, les données ne sont PAS recopiées entre couche de stockage (data lake) et couche de traitement (data warehouse).
Seules les données de la couche de stockage sont utilisées, afin d’éviter toute problématique de duplication (et donc de synchronisation). -
couche de service (APIs) : couche permettant l’accès aux services du Data lakehousing (via ses APIs), avec prise en compte de la gouvernance des données (Data Catalog)
La différence clé entre une architecture lakehouse et une architecture "data lake + data warehouse" repose sur l'intégration avancée de ces 2 outils dans le lakehouse, qui permet d’éviter tout mouvement de la donnée en son sein (pas besoin de copier la donnée au sein du lakehouse).
Cette intégration est rendue possible au travers d’une gestion poussée des metadata (Data dictionnaire, Data catalogue), permettant d'unifier les données (structurées ET semi-structurées ET non structurées)

|
📎
|
Un peu d’histoire, d’où vient le terme "Data lakehouse"
Le concept de "Data lakehouse" a été introduit en 2017 par Snowflake, qui édite une solution de Cloud Data warehousing parmi les plus connues et utilisées. |
Comme dit plus haut, le data lakehouse a été conçu afin de "combiner le meilleur des 2 mondes", data warehouses et data lakes, en adressant les problématiques suivantes :
-
Data warehouses :
-
Difficulté des DWH à effectuer des traitements analytiques sur des données autres qu'uniquement structurées.
-
Coûts de scaling conséquents de ces technologies qui ne séparent pas couche de stockage et couche de traitement, d’où une couche de traitement toujours "up" même si non utilisée, avec les coûts allant avec.
-
-
Data lakes :
-
Problèmes de qualité de données (donc duplication de données) des data lakes.
-
Intégration / connexion à de nombreux systèmes / outils tiers.
Le data lake est par définition au centre de tout et doit donc être cherché à être le plus facilement accessible par ces derniers (outils d’analytics ou de dataviz)
-
Avec la montée en puissance de l’IA et des besoins en calculs prédictifs, le data lakehouse, qui permet ce type de traitements, semble promis à un bel avenir, là où Data warehouse et Data lakes montrent de plus en plus leurs limites.
Les traitements proposés par les Data warehouses, basés sur des données structurées, ne permettent pas ou très mal la gestion du temps réel (smart analytics), tandis que les Data lakes ne permettent que difficilement la mise en place de pratiques robustes de Data gouvernance, de sécurité ainsi que de transactions ACID.
L’un des gros inconvénients du Data lakehouse réside dans la complexité de cette solution, qui, sauf à disposer de robustes ressources ITs pour l’implémenter en interne, impose de passer par une solution / plateforme progicielle "clé en main" (comme Snowflake) avec les problématiques "d’enfermement" technologique qui en découle.
| Caractéristiques | Data warehouse | Data lake | Data lakehouse |
|---|---|---|---|
Types de données |
Données structurées uniquement |
Tout type de données (structurées, semi-structurées et non structurées) |
Idem Data lake |
Schéma |
Schéma prédéfini obligatoire ("schema-on-write") |
Schéma requis uniquement au moment de l’utilisation / analyse des données ("shema-on-read") |
Comme pour le DWH, un schéma est requis pour certains types de traitement, MAIS les données sont ingérées de préférence brutes afin de les traitements de type ML |
Data quality |
Données épurées, qualifiées, structurées |
Données brutes par principe à l’ingestion (raw data), avec risque de "data swamp" en l’absence de la mise en place d’une bonne gouvernance des données |
Idem Data lake, mais les données brutes devront absolument être transformées pour permettre des traitements analytiques de type Data warehouse, d’où l’obligation d’une solide Data governance |
Requêtage |
Requêtage poussé et performant dès la fin de l’ingestion des données dans le DWH |
Requêtage analytique peu performant sans une phase conséquente de préparation des données (elles sont brutes à la base). Néanmoins, ces mêmes données brutes rendent possible tous les traitements de type ML (nécessitant des données transformées / filtrées le moins possible) |
Une fois les données brutes transformées / structurées, on retrouve un requêtage optimisé et performant, analogue à celui des Data warehouse. |
Utilisateurs |
Utilisateurs "métier", sans besoin de connaissances techniques poussées, sauf langage SQL |
Analystes métier, data scientists, data engineers, data architectes, etc. |
Utilisateurs "métiers" et équipes IT |
Facilité d’usage / prise en main |
La présence d’un schéma défini à l’avance rend les données faciles à appréhender et à requêter (quand le schéma est bien conçu !) |
Toute utilisation des données nécessite une préparation préalable requérant des compétences techniques pouvant être très poussées. |
Les data lakehouses proposent une prise en main et des interfaces proches de celles des DWH, avec une extension aux traitements de type AI / ML. |
Types de traitements (analytics) |
Reporting, BI, dashboards |
Traitements analytiques avancés (mais complexes à mettre en oeuvre) : analyse exploratoire, analyse prédictive, ML, streaming, analyse sur historique complet, etc. |
Tout types de traitements supportés : du reporting / BI à des traitements analytiques complexes. |
Scaling |
Scaling compliqué, cher car souvent uniquement vertical du fait d’une absence de découplage entre couche de stockage et couche de traitement. |
Scaling facilité, à coût réduit / contrôlé du fait d’un découplage par design des couches de stockage et de traitement. |
Capacité de scaling analogues à celles des Data lakes (là aussi du fait du découplage stockage / traitement) |
Que l’on cherche à recréer "from scratch" un nouveau SI décisionnel, ou simplement à modifier un système legacy, la réponse à cette question n’a rien d’évident.
Ces solutions ont chacune des avantages et des inconvénients, ainsi que des points communs et des différences (marquées).
De plus, cet écosystème est en évolution rapide ces dernières années (surtout depuis l’arrivée des data lakehouses qui a "secoué" le marché).
La question essentielle à se poser n’est pas tant technique que métier : "Que dois-je faire avec mes données ?"
Voici quelques pistes pour aiguiller son choix de solution en fonction de la réponse précédente :
-
Si l’on est sûr de l’usage attendu de ses données, et des résultats à fournir, préférer un data warehouse (car pas "d’aléatoire" et de besoin de faire "émerger" des données quelque chose que l’on ne connaît pas encore)
-
Dans le cas d’une activité très réglementée (c’est à dire avec des régulateurs qui imposent un même résultat à tous), impliquant des besoins forts en reporting, préférer également un data warehouse
-
Pour tout besoin d’exploration de données ("on ne sait pas encore exactement ce qu’on veut, mais on sait que c’est dans nos données"), préférer un data lake ou un data lakehouse.
Ce dernier sera à préférer si les résultats obtenus devront eux-mêmes être manipulés pour donner naissance à de nouveaux résultats (data mining) -
Pour tout besoin de calcul prédictif (Machine Learning, IA, etc.) préférer un data lake ou un data lakehouse.
-
data lake vs data warehouse : https://itrexgroup.com/blog/data-warehouse-vs-data-lake-vs-data-lakehouse-differences-use-cases-tips/
-
exemple d'architecture data lake dans le Cloud (Azure) : https://lynnlangit.medium.com/azure-for-genomic-scale-workloads-ad3c989a3d0b
-
data lakehouse :
Il s’agit là de concepts récents, et donc de débats récents…
Pour une très bonne comparaison des 2, voir https://www.datanami.com/2021/10/25/data-mesh-vs-data-fabric-understanding-the-differences/
-
Data Fabric :
"Conceptually, a big data fabric is essentially a metadata-driven way of connecting a disparate collection of data tools that address key pain points in big data projects in a cohesive and self-service manner. Specifically, data fabric solutions deliver capabilities in the areas of data access, discovery, transformation, integration, security, governance, lineage, and orchestration. Graph is often used to link data assets and users, too." -
Data Mesh :
"While the data fabric seeks to build a single, virtual management layer atop distributed data, the data mesh encourages distributed groups of teams to manage data as they see fit, albeit with some common governance provisions."
"The core principle driving the data mesh is rectifying the incongruence between the data lake and the data warehouse"
"data transformation cannot be hardwired into the data by engineers, but instead should be a sort of filter that is applied on a common set of data that’s available to all users. So instead of building a complex set of ETL pipelines to move and transform data to specialized repositories where the various communities can analyze it, the data is retained in roughly its original form, and a series of domain-specific teams take ownership of that data as they shape the data into a product."
Key differences between Data Fabric and Data Mesh :
-
A data mesh is basically an API-driven solution for developers, unlike data fabric
-
Data fabric is the opposite of data mesh, where you’re writing code for the APIs to interface.
On the other hand, data fabric is low-code, no-code, which means that the API integration is happening inside of the fabric without actually leveraging it directly, as opposed to data mesh. -
A data fabric and a data mesh both provide an architecture to access data across multiple technologies and platforms, but a data fabric is technology-centric, while a data mesh focuses on organizational change.
-
A data mesh is more about people and process than architecture, while a data fabric is an architectural approach that tackles the complexity of data and metadata in a smart way that works well together.

|
📎
|
Pour réaliser ce schéma, Denise s’est appuyé sur le "DMBOK2", à savoir le Data Management Book Of Knowledge de la DAMA (Data Management Association). |
La gouvernance des données représente un programme d’entreprise (ensemble de pratiques et de process) ayant pour but de contrôler toute la gestion des données et des ressources associées (data assets) de l’entreprise.
L’objectif de ce programme est de réduire les différents risques associés à la manipulation des données : confidentialité, régulations, sécurité de la data (SSI)
Cela inclut :
-
La mise en place de plusieurs politiques et standards centrés sur la Data :
-
gestion des metadata
-
gestion des master data (données référentielles et vocabulaire métier commun)
-
accès à la donnée
-
sécurisation de la donnée
-
usage de la donnée
-
qualité de la donnée
-
-
La conformité avec les exigences des différentes régulations (RGPD, CCPA, LPM, HIPAA, etc.)
-
La mise en place d’un monitoring (définition d’indicateurs) et d'audits des usages de la data, ainsi que d’une démarche d'amélioration continue des pratiques associées à la Data (Data stewardship)
-
La mise en place d’une gestion des incidents (avec un mécanisme de gestion de tickets ou similaire)
-
Le suivi des contrats associés à la Data : hébergement et services Cloud, acquisition de données externes, ventes de Data, etc.
La Data architecture a pour objectif de définir la structure des données de l’entreprise, des ressources associées, et d’en schématiser les interactions (définition des flux de données du SI).
L’architecture Data doit également définir les grands principes de gestion de la Data à appliquer dans toute l’entreprise.
Le Data development (ou data modeling) a trait aux activités de d'analyse, de modélisation, développement, tests et maintenance des flux de données.
Cela inclut la réalisation des modèles de données conceptuel (MCD), logique (MLD) et physique (MPD).
Parmi les objectifs recherchés, on retrouve la mise à disposition d’un vocabulaire commun de la donnée, ainsi que la documentation des actifs de la donnée (Data assets) de l’entreprise.
Cette catégorie regroupe Le design, l’implémentation et la maintenance de la donnée "stockée" (la persistance de la donnée à proprement parler et les outils utilisés pour cela).
Cela implique :
-
définir les caractéristiques que la solution de persistance (Base de données et autres) devra posséder pour bien répondre aux besoins
-
définir les besoins en termes d’usages, de résilience et d’accès à la donnée
-
gérer les performances de la BDD
-
gérer les migrations de données
L’objectif est ici de permettre de :
-
garantir la disponibilité des données tout au long de leur cycle de vie
-
garantir l’intégrité des données
-
garantir l’efficacité des transactions
Cette catégorie regroupe les politiques et procédures de sécurité ayant pour but de garantir et vérifier l'authentification, l'autorisation, les droits d’accès et l'audit des data assets.
La data security est le garant du respect des régulations, des contrats et des exigences métiers ciblant les données.
Elle doit également s’efforcer de prémunir l’entreprise de toute perte financière découlant d’une faille de sécurité (attaque, malware, exfiltration de données, etc.)
Les "master data" regroupe les données de l’entreprise représentant les concepts métier clés associés à son activité (clients, fournisseurs, produits, partenaires, etc.). Ce sont des données non transactionnelles (un numéro de facture n’est pas une master data), et évoluant peu.
Les référentiels de données représentent une sous catégorie des master data, parfois appelés "master reference data".
Leur gestion consiste à :
-
garantir la précision des master data (elles doivent représenter au mieux les concepts métier associés, et définir des ensembles de données cohérents)
-
réduire le risque d’ambiguïtés quand à l’usage de ces master data
-
veiller à la disponibilité et à la diffusion de ces données dans l’entreprise
L’objectif est ici de :
-
améliorer la qualité de la donnée (surtout des données partagées, et donc des référentiels) en :
-
évitant les duplications (unicité des master data)
-
normalisant les concepts métiers
-
réduisant les risques d’inconsistance des données, d’écarts d’un ensemble de données à un autre (du fait de l’usage de données différentes pour manipuler un même concept)
-
-
simplifier le partage de données et l’inter connectivité des applications (via ensemble de données et de référentiels communs)
-
réduire les coûts d’intégration de nouvelles sources de données dans un SI déjà existant (les master data vont pouvoir servir de socle à l’intégration)
Pour information, une persistance de données dans laquelle ces dernières seraient stockées en garantissant un maximum leur qualité (présence de toutes les informations utiles, que de l’information vérifiée, pas de doublons) répondrait à l’appellation de Golden Data.
Ressources :
-
https://www.octopai.com/questions/whats-the-difference-between-master-data-and-metadata
-
https://www.youtube.com/watch?v=qqNsp1XmdCY : MDM vs MM (très bon, concis mais très clair)
-
https://www.semarchy.com/blog/backtobasics_data_classification/ : propose une définition de tous les types de données (master data, metadata, golden data, etc.)
-
master data :
-
https://www.youtube.com/watch?v=YmteXRMzzw4 : master data examples
-
Cette catégorie regroupe les capacités d’extraction, de nettoyage ("cleansing"), de transformation, de validation, de chargement de la donnée, ainsi que les capacités de d’analyse, de reporting et de dashboarding (data visualization ou "dataviz")
Cette catégorie représente l’enregistrement, le stockage, l’indexation, l’accès, la protection et l’usage des données non structurées, qui doivent être conservées à l’extérieur des BDD relationnelles (qui ne sont pas adaptées à ce type de données, et stocke avant tout des données structurées, voire semi-structurées dans certains cas).
Par données non structurées, on entend des données sans schéma ni format : un texte libre (comme des commentaires, des logs, la plupart des données en provenance de l’IoT), des binaires (des images et autres scans de documents administratifs par exemple).
A l’heure actuelle où les ces dernières sont de plus en plus nombreuses (80 à 90% des données de l’industrie), il est capital de pouvoir les exploiter au mieux.
L’objectif du Document management est donc :
-
de garantir une utilisation efficace des données non structurées, c’est à dire d’être capable d’en extraire facilement la partie significative, ayant de la valeur pour le métier de l’entreprise
-
de faciliter l'interopérabilité, l'usage conjugué des données structurées, semi-structures ET non structurées (capacité d’intégration dans un même pipeline)
Il s’agit ici de la gestion des "metadata", à savoir les données techniques dont le rôle est de décrire les "autres" données.
Parmi les informations contenues dans les metadata on peut citer : le type des données (varchar, integer, etc.), leur taille, leur date de création, leur provenance, quels sont les éléments / services utilisant la donnée, la fréquence de requêtage de la donnée, etc.
Les metadata sont donc des descripteurs des données métier.
L’objectif du MM est :
-
de renforcer la confiance dans les données en permettant d’en mesurer plus facilement la qualité (via l’ajout d’informations quantitatives, d’indicateurs, etc.)
-
d'accroître la valeur des master data avec lesquelles elles marchent (très) souvent en tandem (pour pouvoir définir de façon exacte l’unicité des master data, il est très souvent nécessaire d’aller chercher dans les metadata)
-
d'éviter l’usage de données périmées ou non valides
-
optimiser le requêtage (les metadata permettant d’orienter la requête)
-
de faciliter la communication entre les utilisateurs de la donnée et les équipes IT
-
d'améliorer les temps de développement des services / systèmes / applications (les metadata permettant de préciser les données sans le besoin de traitements supplémentaires), et donc le ROI
-
de faciliter le respect de la conformité réglementaire (les metadata permettent de plus facilement vérifier que l’on s’est bien conformé aux exigences du régulateur)
Un shift important ayant lieu depuis peu (mi 2021) :
"The paradigm shift: Going from passive to active metadata"
-
côté Gartner, cela donne ça :
"Gartner took a huge step toward this by scrapping its Magic Quadrant for Metadata Management Solutions and replacing it with a Market Guide for Active Metadata."
Nous sommes en train de passer à des "active metadata platforms". -
La raison de cet échec d’une gestion traditionnelle des metadata : cette gestion était passive (d’où le nouveau nom de l’étude du Gartner : "Market Guide for Active Metadata")
Ressources :
-
L’évolution du metadata management vers une gestion "moins passive plus active" (mi 2021) : https://towardsdatascience.com/the-gartner-magic-quadrant-for-metadata-management-was-just-scrapped-d84b2543f989 :
-
Liste des solutions actuelles de data catalog (data discovery) : https://www.notion.so/atlanhq/The-Ultimate-Repository-of-Data-Discovery-Solutions-149b0ea2a2ed401d84f2b71681c5a369
La Data Quality désigne l’aptitude des caractéristiques intrinsèques des données à satisfaire des exigences, aussi bien internes (pilotage, prise de décision) qu’externes (réglementations) à l’organisation.
Elle regroupe toutes les actions permettant de s’assurer que les données sont correctes, tout au long de leur cycle de vie (perennnité).
Il est ici aussi bien question des caractéristiques des données que des processus et outils permettant de garantir ces dernières.
Parmi les caractéristiques des données ayant trait à la qualité on peut citer : l’unicité, la complétude, l’exactitude, la conformité, la cohérence, l’intégrité, la fraîcheur, l’accessibilité, la pertinence, la compréhensibilité.
Parmi les processus et outils, on peut citer :
-
le monitoring des données : cette analyse de la qualité s’appuie sur un ensemble de critères et d’objectifs ayant pour but de dégager des domaines d’amélioration de la qualité de donnée (profilage).
-
la surveillance des données : permet de détecter une éventuelle détérioration des données, via la mise en place d’indicateurs et de règles.
C’est un domaine en fort développement, ciblé par de plus en plus d’éditeurs logiciels. -
le suppression des doublons ("matching")
-
l'enrichissement : dont le but est d'obtenir la complétude des données. L’enrichissement peut être réaliser de différentes façons, en utilisant des données déjà présentes dans la persistance elle-même (dans d’autres tables de la BDD), ou en appellant des services extérieurs (appels API à des sources OpenData)
-
la standardisation : via la mise en place de standards permettant une représentation adéquate des données (répondant aux caractéristiques citées précédemment)
-
le nettoyage ("cleansing") : il s’agit de la correction des données erronées, étape essentielle de la phase de "préparation de la donnée" (très consommatrice en temps)
-
la mise en place de tests, à différentes étapes du traitement des données, aussi bien quantitatifs ("j’avais 100 données du côté de ma source, ai-je bien ingéré 100 données dans mon système cible ?") que qualitatifs ("ce champ était une date en entrée, ai-je bien récupéré une date après intégration dans ma cible ?")
Les objectifs de la data quality visent à :
-
faciliter l'atteinte des performances fixées pour le SI.
-
éviter des pertes financières dues à des données incorrectes.
-
éviter la perte d’opportunités du fait de données ne répondant pas de façon satisfaisante aux besoins.
Ressources :
Data management strategy :
-
https://itrexgroup.com/blog/data-management-strategy-benefits-principles-steps/
-
https://www.datasciencecentral.com/reframing-data-management-data-management-2-0/
-
Voir également les publications de la DAMA (Data Management Association) : https://www.dama.org/cpages/home
-
Voici un overview de la 2e édition du DAMA DMBOK2 (Data Management Book Of Knowledge - 2017 - 590 pages) : https://www.dama-dk.org/onewebmedia/DAMA%20DMBOK2_PDF.pdf
-
Et voici une très bonne [explication vidéo des Knowledge Areas du DMBOK2 en v1](https://youtu.be/5xw_OjVx5gQ?t=658) (par Denise Harders)
-
Le schéma présenté dans les dernières secondes est également disponible ici : https://www.slideshare.net/DeniseHarders/data-mangement-what-is-it-print-a3-115004805
-
-
Pour rappel, cf Peter Ghavani dans "Big Data Management: Data Governance Principles for Big Data Analytics" :
"The data management DMBOK1 guide was released in 2009, and DMBOK2 in 2011 with an update in 2017 (v2)"
-
-
Le livre "Big Data Management: Data Governance Principles for Big Data Analytics" (2020/11), de Peter Ghavani, dont l’on peut lire des extraits dans Google Books : https://books.google.fr/books?id=oK4HEAAAQBAJ&pg=PT40
Plusieurs des sujets traités par ce livre sont très intéressants : différence entre BI et Analytics, les 4 couches classiques d’une plateforme analytique (data connection layer, data management layer, analytics layer, presentation layer) -
Data management - data architecture : https://www.redsen-consulting.com/data-analyse/data-management-data-architecture/
-
Data management - gouverner les données : https://www.redsen-consulting.com/data-analyse/data-management-gouverner-les-donnees/
-
définition Big Data : https://www.cnil.fr/fr/definition/big-data
-
data lake vs data warehouse : https://itrexgroup.com/blog/data-warehouse-vs-data-lake-vs-data-lakehouse-differences-use-cases-tips/
-
data lakehouse :
-
Data Mesh vs Data Fabric : https://www.datanami.com/2021/10/25/data-mesh-vs-data-fabric-understanding-the-differences/
-
Ippon Big Data 2016 : https://fr.ippon.tech/publications/livre-blanc/explore-big-data
-
HDFS vs Cloud Object storage, pros and cons : https://cloud.google.com/blog/products/storage-data-transfer/hdfs-vs-cloud-storage-pros-cons-and-migration-tips
-
Data management strategy :
-
https://itrexgroup.com/blog/data-management-strategy-benefits-principles-steps/
-
https://www.datasciencecentral.com/reframing-data-management-data-management-2-0/
-
Voir également les publications de la DAMA (Data Management Association) : https://www.dama.org/cpages/home
-
Voici un overview de la 2e édition du DAMA DMBOK2 (Data Management Book Of Knowledge - 2017 - 590 pages) : https://www.dama-dk.org/onewebmedia/DAMA%20DMBOK2_PDF.pdf
-
Et voici une très bonne [explication vidéo des Knowledge Areas du DMBOK2 en v1](https://youtu.be/5xw_OjVx5gQ?t=658) (par Denise Harders)
-
Le schéma présenté dans les dernières secondes est également disponible ici : https://www.slideshare.net/DeniseHarders/data-mangement-what-is-it-print-a3-115004805
-
-
Pour rappel, cf Peter Ghavani dans "Big Data Management: Data Governance Principles for Big Data Analytics" :
"The data management DMBOK1 guide was released in 2009, and DMBOK2 in 2011 with an update in 2017 (v2)"
-
-
Le livre "Big Data Management: Data Governance Principles for Big Data Analytics" (2020/11), de Peter Ghavani, dont l’on peut lire des extraits dans Google Books : https://books.google.fr/books?id=oK4HEAAAQBAJ&pg=PT40
Plusieurs des sujets traités par ce livre sont très intéressants : différence entre BI et Analytics, les 4 couches classiques d’une plateforme analytique (data connection layer, data management layer, analytics layer, presentation layer) -
Data management - data architecture : https://www.redsen-consulting.com/data-analyse/data-management-data-architecture/
-
Data management - gouverner les données : https://www.redsen-consulting.com/data-analyse/data-management-gouverner-les-donnees/
-
-
différences Big Data et BI :
-
Modèle Conceptuel de données (MCD) vs Modèle Logique de données (MLD) vs Modèle Physique de données (MPD) : http://www.turrier.fr/articles/mysql-modeliser-une-base-de-donnees/mysql-modeliser-base-de-donnees.php
-
micro-batch vs streaming : https://hazelcast.com/glossary/micro-batch-processing/
-
streaming with Spark : https://spark.apache.org/docs/latest/streaming-programming-guide.html
-
-
modélisation en étoile, et différence entre data warehouse et datamarts : https://www.cartelis.com/blog/data-warehouse-modelisation-etoile/
-
Différences entre tables de faits et tables de dimensions : https://fr.gadget-info.com/difference-between-fact-table
-
Modélisation dimensionnelle (différences entre modèle en étoile et modèle en flocon) : http://formations.imt-atlantique.fr/bi/bi_modelisation_dimensionnelle_introduction.html
-
-
garantie de traitement des systèmes distribués (basé sur kafka, exactly once, at least once, etc.) : https://medium.com/@andy.bryant/processing-guarantees-in-kafka-12dd2e30be0e
-
master data vs metadata :
-
https://www.octopai.com/questions/whats-the-difference-between-master-data-and-metadata
-
https://www.youtube.com/watch?v=qqNsp1XmdCY : MDM vs MM (très bon, concis mais très clair)
-
https://www.semarchy.com/blog/backtobasics_data_classification/ : propose une définition de tous les types de données (master data, metadata, golden data, etc.)
-
master data :
-
https://www.youtube.com/watch?v=YmteXRMzzw4 : master data examples
-
-
-
CAP theorem :
-
transactions ACID : https://searchsqlserver.techtarget.com/definition/ACID
-
Policies vs standards vs procedures vs controls : https://www.complianceforge.com/faq/word-crimes/policy-vs-standard-vs-control-vs-procedure
-
Data quality : https://www.next-decision.fr/wiki/qu-est-ce-que-la-data-quality