TPO(Test-Time Prompt Optimization)是一个用于优化大语言模型(LLM)输出文本的框架,它通过使用奖励模型和迭代反馈来指导基础模型生成结果更好的文本。
TPO-LLM-WebUI则为提供了一个友好的 WebUI,你可以通过它来加载基础模型(LLM)和奖励模型,并且内置 TPO 框架以进行实时优化基础模型,它会对你的输入数据进行多轮评估和迭代反馈,使得基础模型在推理过程中与人类偏好对齐,生成更好的结果并展示。
与人类偏好对齐,简单来说,就是让 AI 的行为(模型的推理过程/输出结果)更加符合人类的期望和价值观,生成更具价值(实用性)、安全性和真实性的结果。
举个例子:
- 假设你让AI写一首诗。
- 如果没有对齐: AI可能会写出一堆语法正确但毫无意义的句子,甚至可能包含冒犯性内容。
- 如果对齐了: AI会理解你想要一首优美、有意义的诗,并尽力创作出符合你期望的作品。
- 动态对齐人类偏好:TPO 能在模型推理时,根据奖励模型的反馈,动态调整模型的输出,更符合人类的偏好和期望。
- 无需重新训练模型:TPO 无需对模型进行重新训练或更新权重,可在推理阶段实现对模型输出的优化。
- 高效优化与可扩展性:TPO 在推理时的搜索宽度和深度上具有良好的可扩展性,能高效地优化模型输出。
- 提升模型性能:TPO 能显著提升模型在多个基准测试中的性能,更接近或超过经过训练时偏好对齐的模型。
- 增强模型的解释性和可理解性:TPO 通过文本反馈的形式,使模型的优化过程更加透明和可理解。
- 提升推理稳定性:TPO 能显著提升模型的推理稳定性,减少生成意外或有害响应的概率。
- 轻量级和高效性:TPO 是轻量级的优化方法,计算成本低,适合在实际应用中快速部署。
- 奖励信号转化为文本反馈:TPO 的核心在于将奖励模型的数值信号转化为可解释的文本反馈。具体来说,模型在每次推理时生成多个候选响应,通过奖励模型对这些响应进行评分。然后,TPO 选择得分最高(“选择”响应)和得分最低(“拒绝”响应)的响应,分析它们的优势和不足,生成“文本损失”。
- 迭代优化过程:基于“文本损失”,TPO 生成“文本梯度”,这些梯度指导模型在下一次迭代中如何改进输出。过程类似于传统的梯度下降优化,但完全在文本层面进行,而不是直接更新模型参数。通过多次迭代,使得模型的输出逐渐与人类偏好对齐。
- 依赖于模型的指令跟随能力:TPO 的成功依赖于策略模型具备基础的指令跟随能力,因为模型必须能够准确解释和响应奖励模型的反馈。如果模型缺乏这种能力,TPO 可能无法有效地工作。

优云智算是 UCloud 优刻得的GPU算力租赁平台,专注于为客户提供灵活、高效的算力资源。支持按天、按小时短期租赁及包月长期租赁,满足各类客户需求。 结合丰富的公共镜像社区,优云智算提供多种预配置的容器镜像,如LLamaFactory、SD-webUI 和 LLM 等,实现一键部署,5分钟就能快速上手 AI,助力客户快速启动和扩展项目。
在这里特别感谢 UCloud 优云智算提供的 GPU 算力支持!让项目得到了快速的部署和调试运行。
TPO-LLM-WebUI 镜像发布页:https://www.compshare.cn/images-detail?ImageID=compshareImage-18jp6iuyn436&ytag=GPU_hych_Lcsdn_csdn_display
【免费送你算力金】通过镜像发布页或下方链接注册可以额外获得40算力金,免费体验20小时顶配4090显卡,企业或高校认证后有95折和额外10元算力金。 https://passport.compshare.cn/register?referral_code=4sOb83sEXe4BLkKYqw9G4P&ytag=GPU_hych_Lcsdn_csdn_display
首先,在镜像发布页可以查看到我制作完成并分享到平台的实例镜像,通过页面右侧的使用该镜像创建实例可以快速创建一个实例。
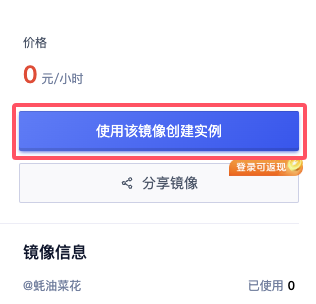
- 通过镜像可以一键部署实例,同时需要根据模型的需求来确定使用的 GPU 数量,因为可用的 GPU 数量限制了张量并行的最大数量。
- 例如,如果你只有 4 个 GPU,
--tensor-parallel-size的最大值只能是 4。
| 模型名称 | 显存需求(混合精度) | 4090 数量(24G/张) | 推荐 --tensor-parallel-size |
|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-7B | 14 GB | 4090 单卡 | 1 |
| DeepSeek-R1-Distill-Qwen-14B | 28 GB | 4090 2卡 | 2 |
| DeepSeek-R1-Distill-Qwen-32B | 64 GB | 4090 3卡 | 3 |
| DeepSeek-R1-Distill-Llama-70B | 140 GB | 4090 4卡 | 4 |
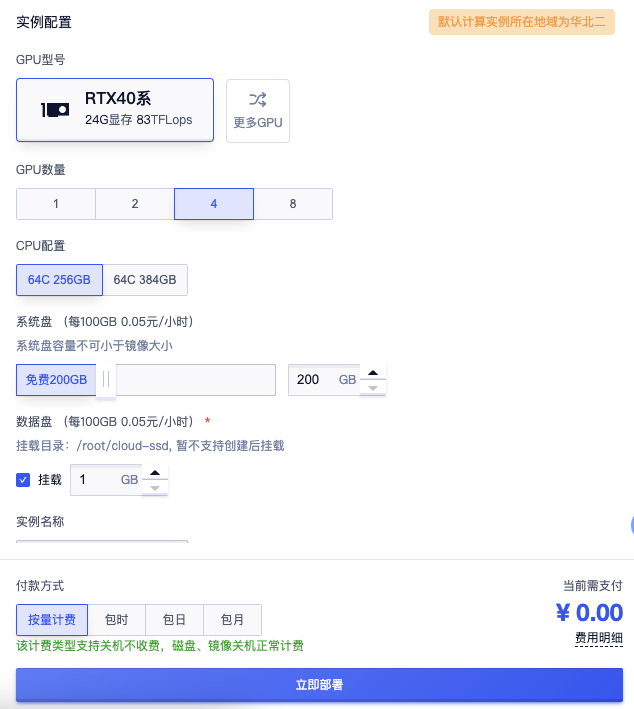
这里我选用 DeepSeek 的DeepSeek-R1-Distill-Qwen-14B 模型作为基础模型来获取更有性价比的运行结果,它需要最低配置 4090 4卡的运行环境下面的步骤都以该基础模型为例,如有出入请自行按说明修改参数配置。
如果你的 GPU 预算不高,也可以选择使用较小的模型如DeepSeek-R1-Distill-Qwen-7B,按需选择 GPU 配置后再立即部署。
稍等片刻后,实例就会自动创建并启动,通过查看实例列表可查看实例的运行状态,并支持随时关闭或启用。
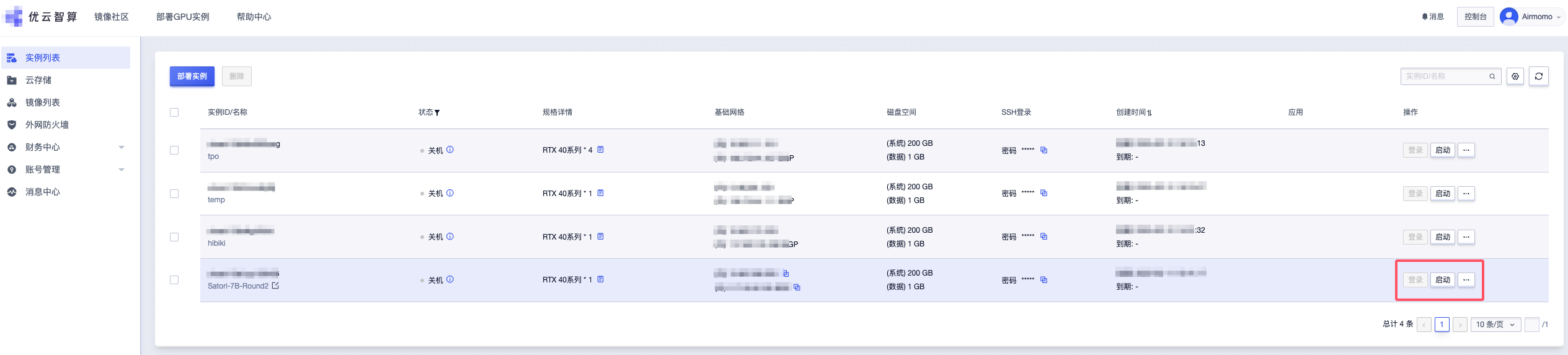
实例同时提供了一个 JupyterLab 应用作为交互式开发环境,它提供了更现代化和灵活的用户界面,方便我们继续后续的步骤。

通过镜像一键部署实例可跳过该步骤,虚拟环境及其所需的依赖均已在实例内配置完成,你可以直接跳过该步骤继续运行。
本地部署按照以下步骤配置运行环境:
- 创建虚拟环境
conda create -n tpo python=3.10
conda activate tpo没有安装conda的可以使用以下命令创建和激活虚拟环境:
python -m venv tpo
source tpo/bin/activate- 下载并安装依赖
git clone https://github.com/Airmomo/tpo-webui.git
pip install -r requirements.txt- 安装 TextGrad
cd textgrad-main
pip install -e .
cd ..通过镜像一键部署实例可跳过该步骤,运行需要的模型均在镜像内已内置,你可以直接跳过该步骤继续运行。
本地部署则需要手动下载模型放到加载模型时指定的目录路径中(如:/model/HuggingFace/...)。:
- 基础模型:https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
- 奖励模型:https://huggingface.co/sfairXC/FsfairX-LLaMA3-RM-v0.1
当然你也可以选择下载其他大语言模型(LLM)作为基础模型或其他奖励模型进行优化训练,你可以在'config.yaml'中修改使用的模型(本地路径或远程 HuggingFace 仓库的标识符),但是要注意根据自己的 GPU 配置来选择合适的模型,量力而行!
这里使用 vLLM 服务器托管将使用 TPO 进行优化的基础模型,使用 2 个 GPU 以张量并行的方式部署,将模型下载到本地后放到指定的路径中(/model/HuggingFace/...),然后在终端输入以下命令:
vllm serve /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B \
--dtype auto \
--api-key token-abc123 \
--tensor-parallel-size 2 \
--max-model-len 59968 \
--port 8000简而言之,这个命令会启动一个 vLLM 服务,加载 DeepSeek-R1-Distill-Qwen-14B 模型,使用 2 个 GPU 进行张量并行推理,最大上下文窗口支持 59968 个序列长度,并在端口 8000 上提供服务。
以下是主要参数的解释:
| 命令/参数名称 | 作用 |
|---|---|
vllm serve |
启动 vLLM 服务模式。 |
deepseek-ai/DeepSeek-R1-Distill-Qwen-14B |
指定要加载的模型。 |
--dtype auto |
自动选择模型权重的数据类型。 |
--api-key token-abc123 |
设置 API 密钥,保护服务访问,这里设置为token-abc123。 |
--tensor-parallel-size 2 |
根据当前的系统配置,设置张量并行大小为 2,即使用 2 个 GPU。 |
--max-model-len 59968 |
根据当前的系统配置,模型支持的最大序列长度为 59968。 |
--enforce-eager |
强制使用 eager 模式,便于调试,这里可不开启。 |
--port 8000 |
指定服务监听的端口号为 8000。 |
一般情况下 TPO 框架建议在单机单GPU环境中运行。若服务器资源足够,你也尝试可以在同一环境中运行。
在终端输入以下指令可以帮助你确定当前系统配置的GPU数量及显存分配情况:
watch -n 1 nvidia-smi在多 GPU 且资源有限的环境下,TPO 默认 Pytorch 会自动分配模型到多个 GPU 上。 假设分配到了一个正在被其他模型使用的 GPU 上时,则可能会发生显存溢出的情况,导致程序报错而停止运行。所以在这种多GPU的环境中,你需要确保 TPO 使用的 GPU 设备是空闲的,并且可以分配给 TPO 脚本使用。
比如在 4 个 GPU 的环境中,基础模型仅使用了 2 个 GPU (GPU 0 和 GPU 1)的情况下,我可以使用以下命令限制启动 TPO 脚本时 Pytorch 使用的 GPU 设备,如下命令表示使用第 2 个和第 3 个 GPU,注意该命令只在当前终端窗口有效:
export CUDA_VISIBLE_DEVICES=2,3TPO-LLM-WebUI 服务默认通过 7860 端口进行访问,详细可查看gradio_app.py,镜像已经配置了端口转发。
在启动 vLLM 服务后,新建一个终端窗口输入以下命令来快速启动 TPO WebUI 服务并支持公网访问:
python gradio_app.py启动后,你可以通过浏览器访问 WebUI:
- 先在
模型设置初始化模型,连接 vLLM 服务器和加载奖励模型(预计耗时1~2分钟)。
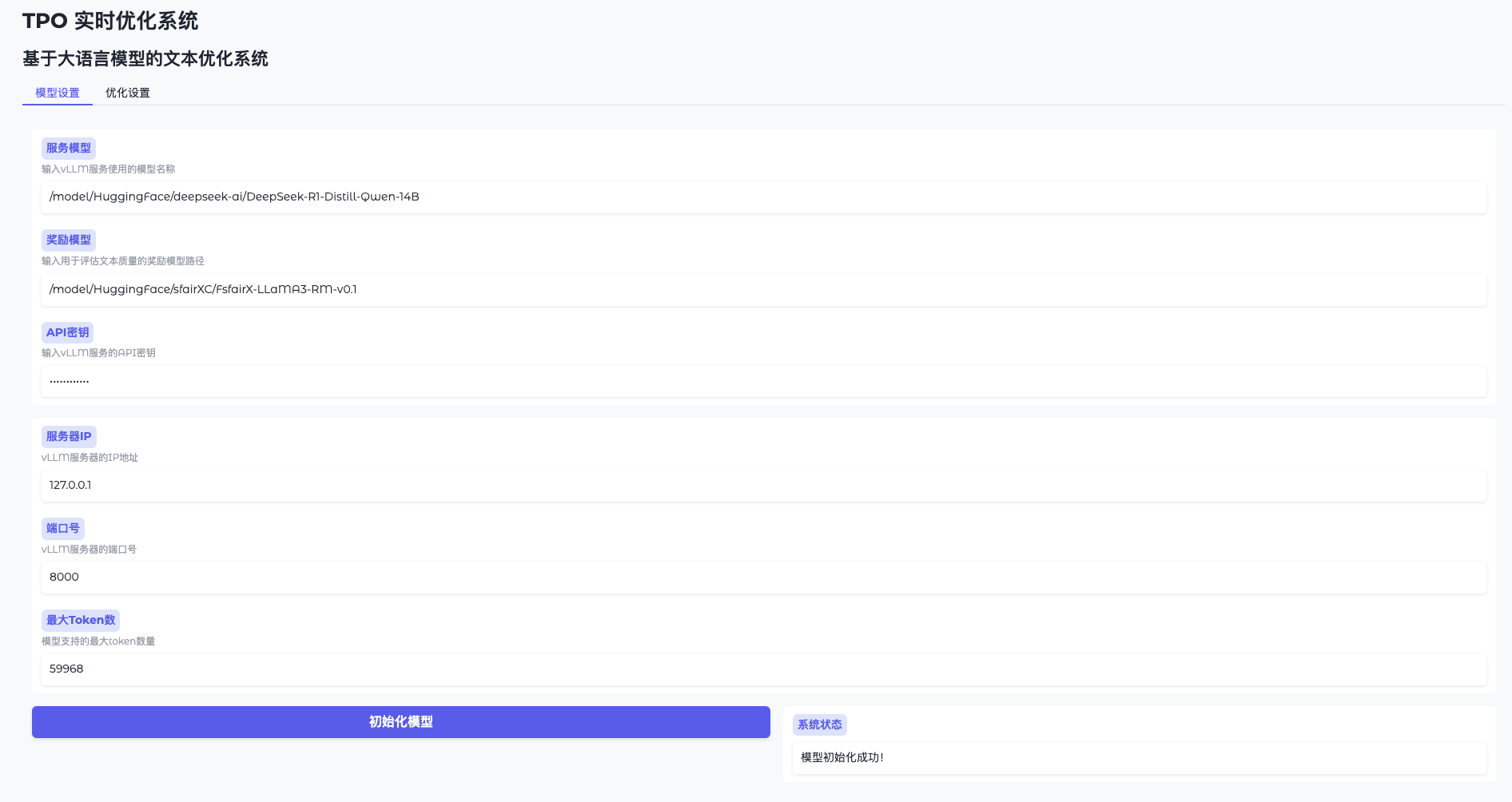
- 模型初始化成功后,就可以到
优化设置页尽情体验啦!输入问题后点击开始优化按钮即可。
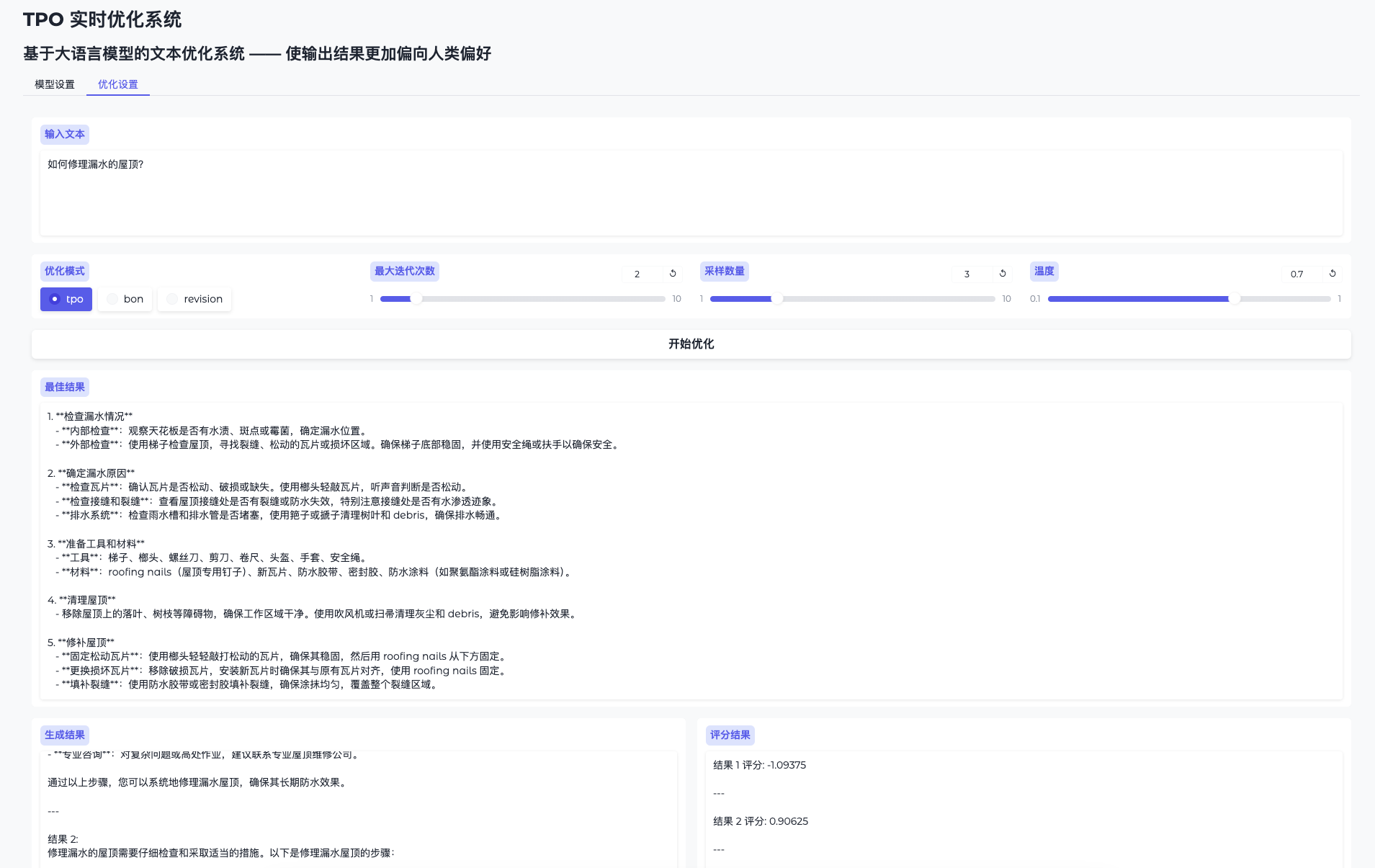
在终端输入以下命令以执行 TPO 脚本,该脚本会先加载一个奖励模型(预计耗时1~2分钟)与作为 vLLM 服务器部署的策略模型进行交互:
python run.py \
--data_path data/sample.json \
--ip 0.0.0.0 \
--port 8000 \
--server_model /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B \
--reward_model /model/HuggingFace/sfairXC/FsfairX-LLaMA3-RM-v0.1 \
--tpo_mode tpo \
--max_tokens_response 2048 \
--max_tokens_all 8192 \
--sample_size 5 \
--seed 7 \
--max_iterations 2 \
--num_threads 4- 注意:
sample_size可能会由于优化过程中的多次迭代而产生多个结果,导致最终显示的结果数量超过了设定值。
主要的参数说明如下:
| 参数名称 | 作用 |
|---|---|
data_path |
数据文件路径(JSON格式)。更多详情请参考 data/sample.json。 |
ip |
vLLM 服务器的 IP 地址,例如 localhost 或 127.0.0.1。 |
port |
vLLM 服务器的端口号,例如 8000。 |
server_model |
通过 API 提供服务的基础模型,例如 deepseek-ai/DeepSeek-R1-Distill-Qwen-14B。 |
reward_model |
奖励模型的HuggingFace仓库位置或模型的本地路径,例如 sfairXC/FsfairX-LLaMA3-RM-v0.1 或 /model/HuggingFace/sfairXC/FsfairX-LLaMA3-RM-v0.1。 |
sample_size |
每一步采样的响应数量。 |
max_iterations |
测试时优化的最大迭代次数。 |
num_threads |
用于生成的线程数。增加 num_threads 可以通过同时利用多个处理核心来加快生成速度,从而提高效率。在计算资源有限的情况下,建议设置为 1。 |
- 预处理阶段:
- 运行
run.py脚本会读取你的输入数据(通过--data_path参数指定的 JSON 文件) - 对每个输入进行多轮优化
- 运行
- 优化过程:
- 对每个输入查询,会进行
max_iterations次迭代) - 每次迭代会:
- 生成多个候选回答(由
sample_size参数控制) - 使用奖励模型评估这些回答。
- 选择最佳回答并优化提示。
- 生成多个候选回答(由
- 对每个输入查询,会进行
- 结果保存:
- 优化后的结果会保存在输出文件中,之后你可以直接使用这些优化过的结果。
运行脚本后,会在logs/目录下生成日志文件,以JSON格式存储,你可以详细地跟踪每次迭代的优化过程。